一、介绍
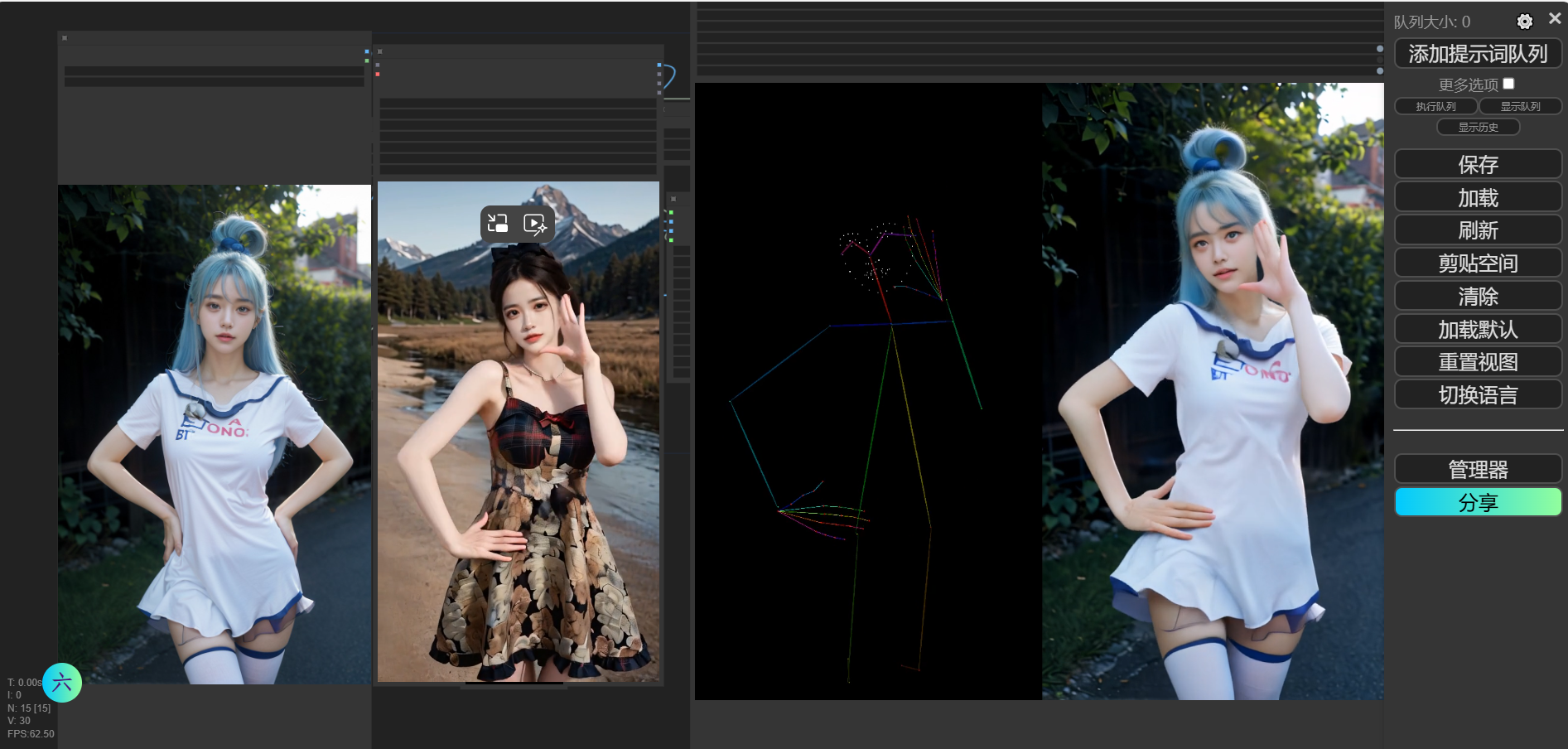
ControlNext-SVD-V2是ControlNeXt-SVD的V2模型。其中ControlNeXt-SVD模型是通过添加 ControlNet 来控制Stable Video Diffusion (SVD),使用高分辨率视频训练,具体来说它可以将图片生成与指定姿态相匹配的高质量视频。
与前一个版本相比具有以下特点:
- 收集了一个更高质量、更高分辨率的数据集来训练模型。
- 将训练和推理批处理帧扩展到 24 个。
- 将视频高度和宽度扩展到 576 × 1024 的分辨率。
- 采用 fp32。
- 在相关之后的推理中,采用姿势对齐。
二、部署过程
环境基础要求:
显存>=16G
CUDA版本>=11.8
1. 部署 ComfyUI
本篇的模型部署是在 ComfyUI 的基础上进行,如果没有部署过 ComfyUI,请按照下面流程先进行部署,如已安装请跳过该步:
(1)使用命令克隆 ComfyUI
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
(2)安装 conda(如已安装则跳过)
下面需要使用 Anaconda 或 Mimiconda 创建虚拟环境,可以输入 conda --version 进行检查。下面是 Mimiconda 的安装过程:
- 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
- 遵循安装提示并初始化
按 Enter 键查看许可证条款,阅读完毕后输入 yes 接受条款,安装完成后,脚本会询问是否初始化 conda 环境,输入 yes 并按 Enter 键。
- 运行
source ~/.bashrc命令激活 conda 环境 - 再次输入
conda --version命令来验证是否安装成功,如果出现类似conda 4.10.3这样的输出就成功了。
(3)创建虚拟环境
输入下面的命令:
conda create -n comfyui
conda activate comfyui
(4)安装 pytorch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
(5)安装项目依赖
pip install -r requirements.txt
此时所需环境就已经搭建完成,通过下面命令进行启动:
python main.py
访问网址得到类似下图界面即表示成功启动:

到这里 Comfy UI 就初步搭建好了(这里只是简单实现 ComfyUI 的基础功能,如果想要安装更多细节,请看我“Comfy UI”部署教程)
2. 部署 ControlNext-SVD
如果之前就部署过Comfy UI,那么在部署开始前建议先进行更新。
(1)克隆仓库
输入以下命令克隆官方仓库中的项目内容:
cd /ComfyUI/custom_nodes/
git clone https://github.com/kijai/ComfyUI-ControlNeXt-SVD.git
cd ComfyUI-ControlNeXt-SVD
pip install requirements.txt
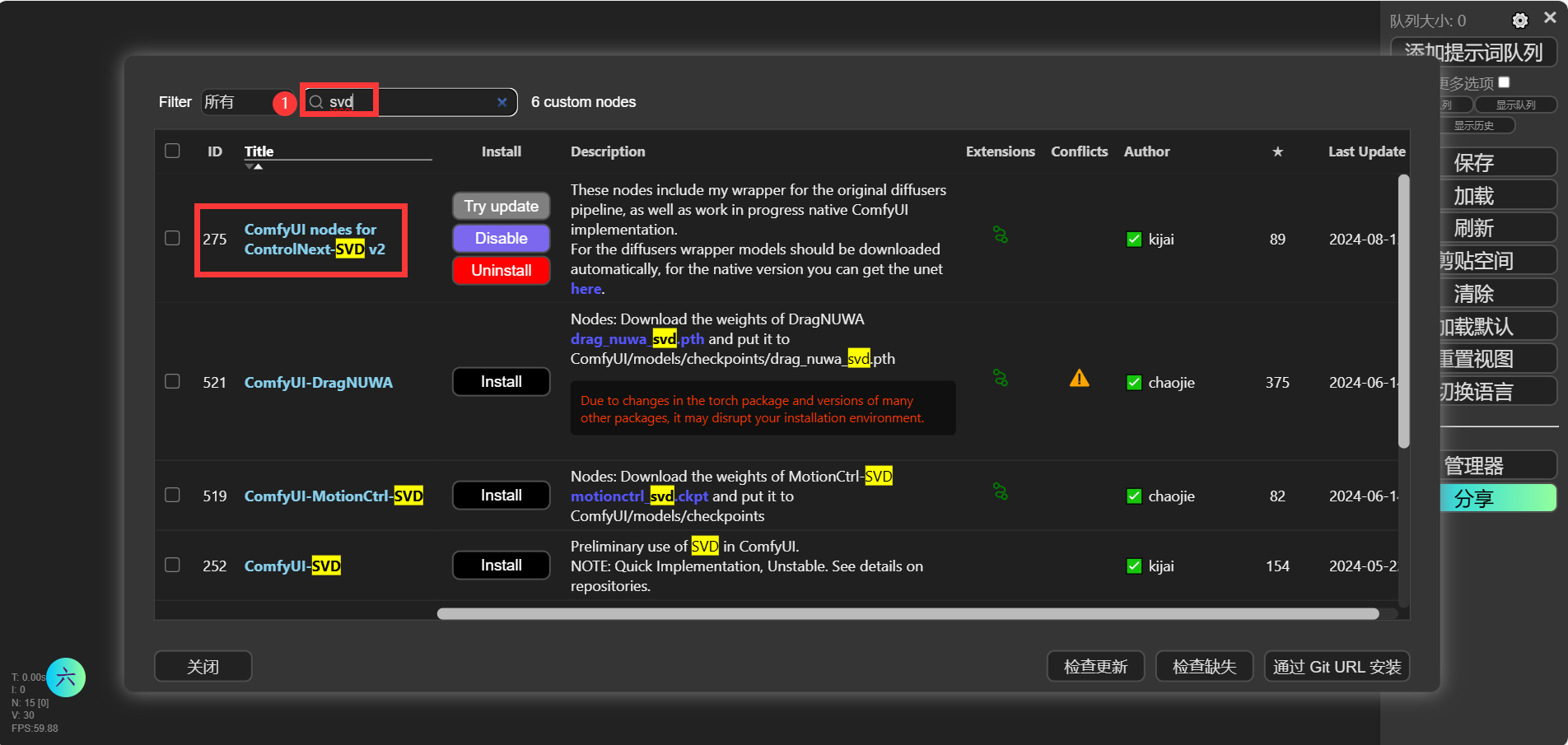
如果你的ComfyUI安装了Manager管理器,那就简单了:直接打开管理器的“节点管理”然后如下图搜索 ControlNext-SVD v2,点击“install”安装即可
(2)打开工作流
打开 /ComfyUI/custom_nodes/ComfyUI-ControlNeXt-SVD/examples/路径,你会看到两个 .json文件,这就是本项目的工作流。将其中的内容复制到ComfyUI的工作界面即可加载。

然后你的 ComfyUI 中应该会出选相应的工作流,类似下图:
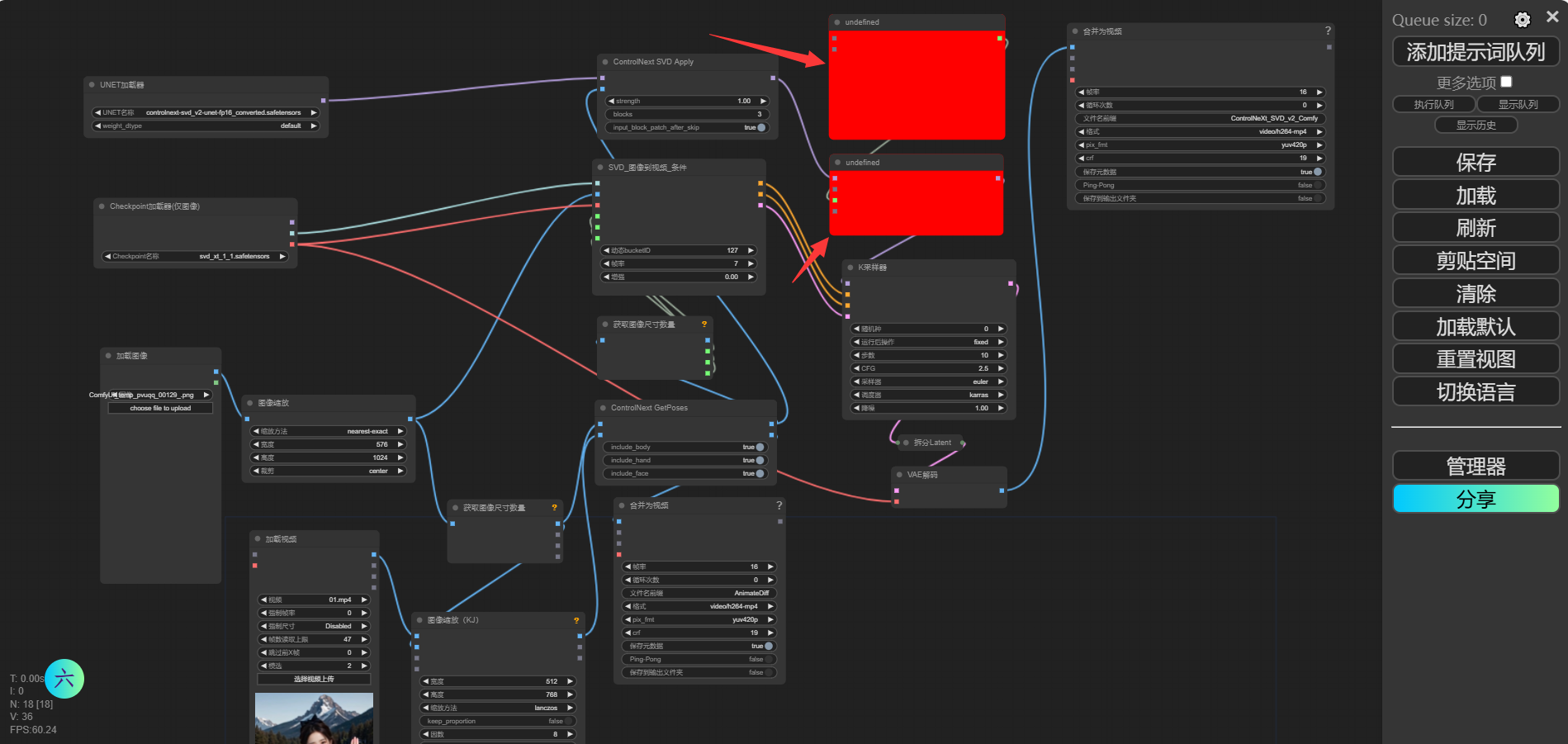
然后会爆红!此时不要慌,依旧打开Mangager管理器,点击“安装缺失节点”,然后将出现的节点进行安装,安装之后还是需要进入 /ComfyUI/custom_nodes/路径下相应的目录下执行 pip install -r requirements.txt命令。
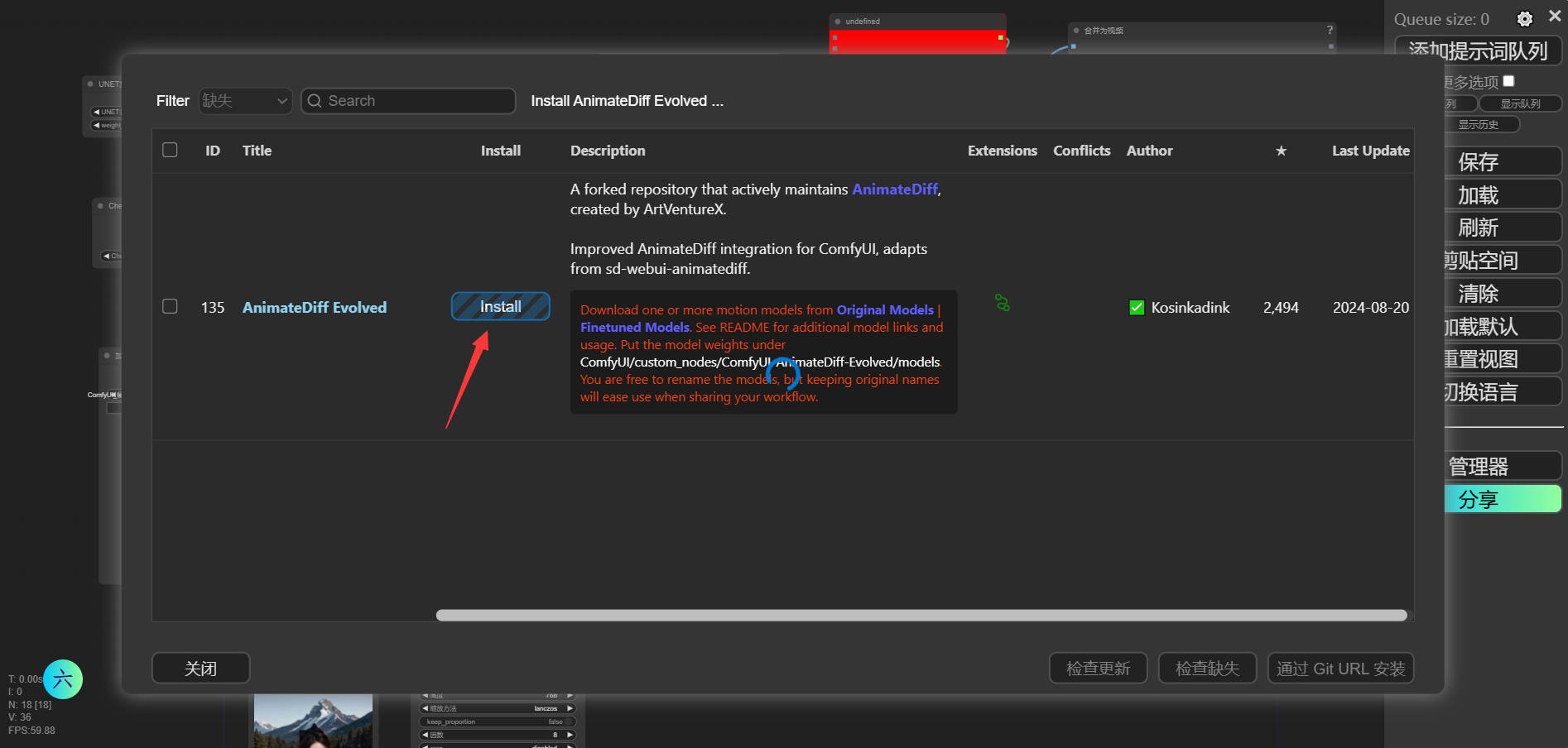
然后重启项目即可。
(3)下载模型
如果你的设备可以访问hugging face网站,那么在如下图的“加载图像”和“加载视频”的节点中导入相关内容,然后点击“添加提示词队列”,之后代码会自动下载缺失的模型,这时候只需等待即可。
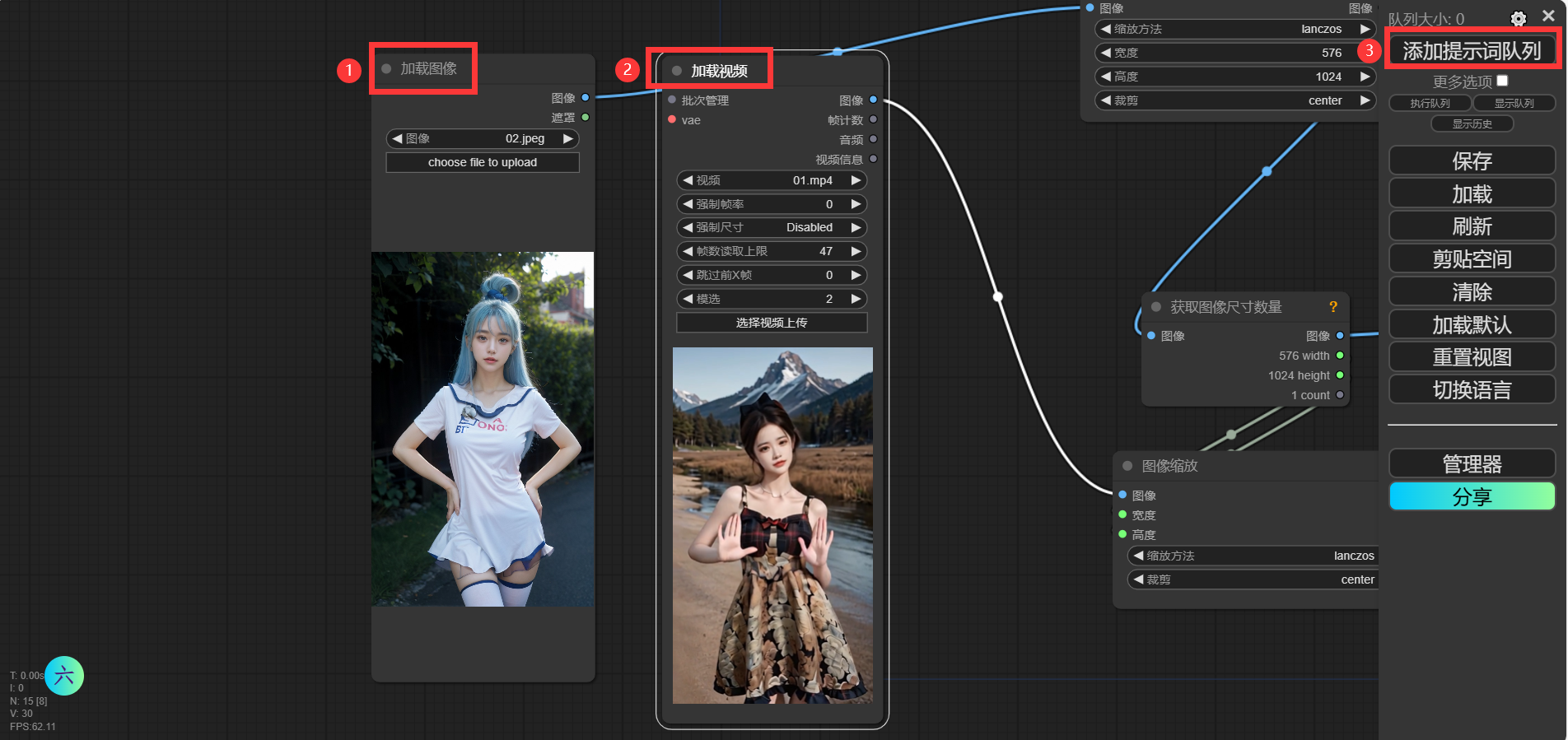
但是,如果你的设备访问不了hugging face网站,那就需要我们手动下载补齐了~
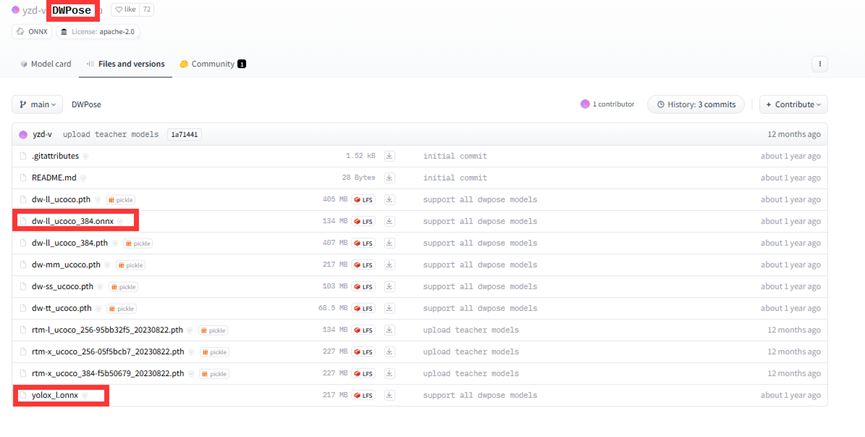
下载yolox
进入hugging face,然后搜索 yzd-v/DWPose,点击到模型界面,将下面的两个模型下载到 /ComfyUI/custom_nodes/ComfyUI-ControlNeXt-SVD/models/DWPose/目录(没有就建一个)下:
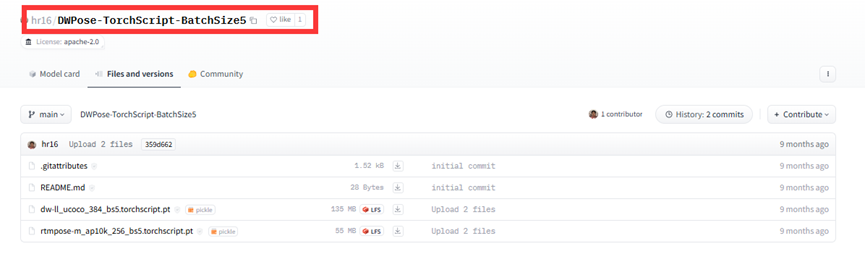
然后再搜索 hr16/hr16/DWPose-TorchScript-BatchSize5,点击到模型界面,将其中的两个模型也下载到 /ComfyUI/custom_nodes/ComfyUI-ControlNeXt-SVD/models/DWPose/目录下:
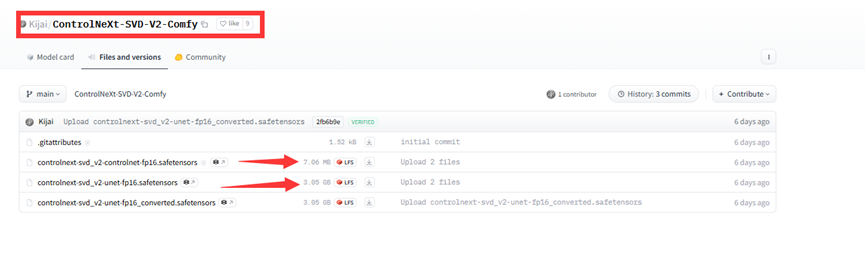
搜索 ControlNeXT-SVD-v20Comfy,将下图中模型下载到 /ComfyUI/models/diffusers/controlnext/目录下:
最后搜索 stable-video-diffusion-img2vid-xt-1-1将这个文件夹下载到 /ComfyUI/models/diffusers/路径下:
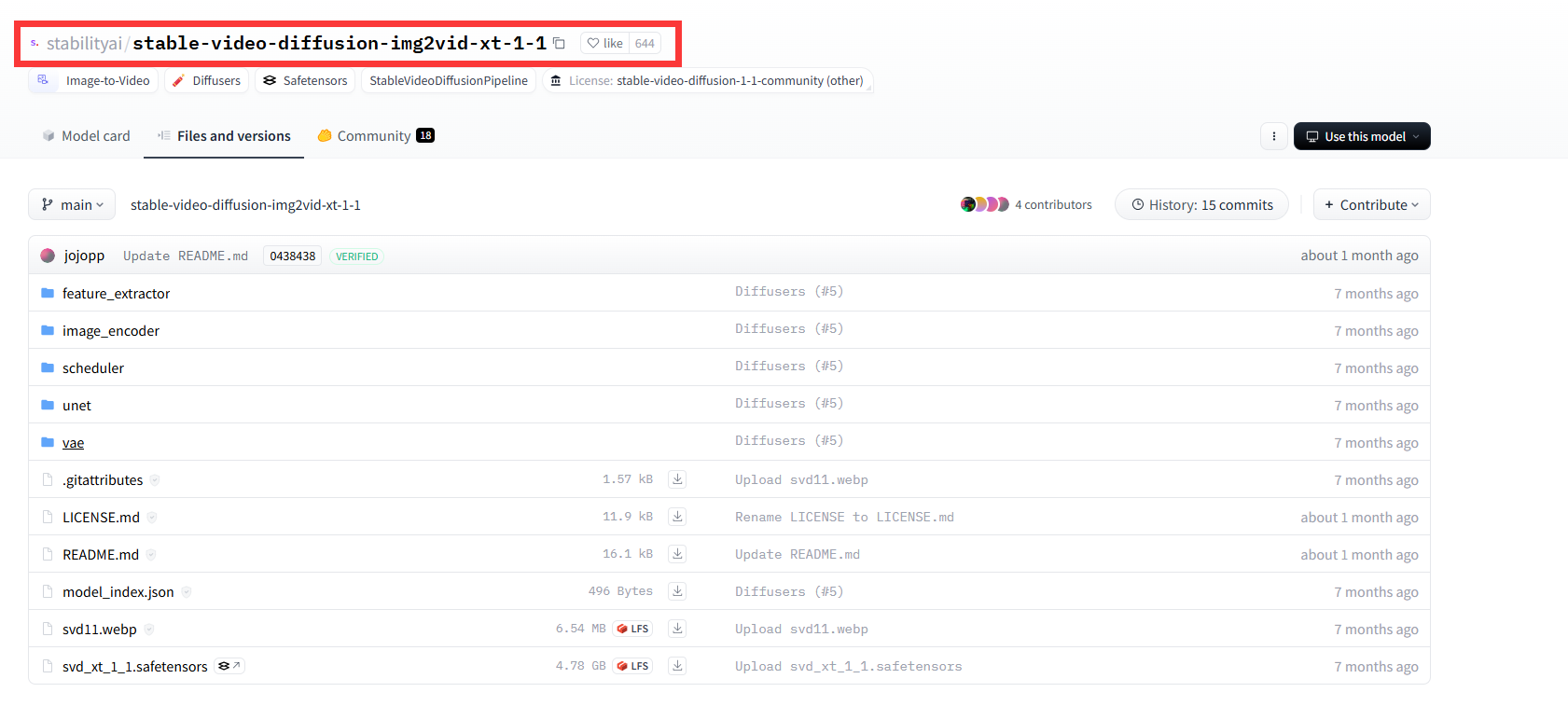
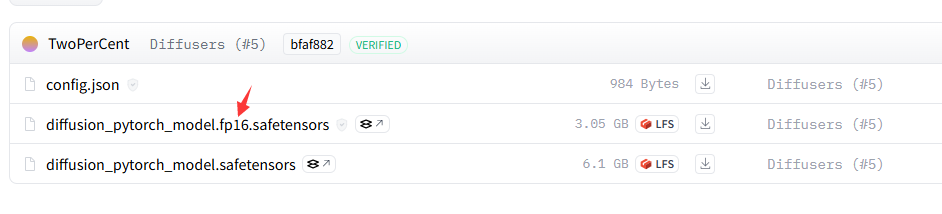
需要注意的是 stable-video-diffusion-img2vid-xt-1-1这个文件中的所有模型有fp16(量化版)两个版本,可根据自己设备情况选择:
三、启动项目
重新启动项目界面:

依旧是打开 /ComfyUI/custom_nodes/ComfyUI-ControlNeXt-SVD/examples/路径下的 .json文件,将其中的内容复制到IU界面即可出现工作流,即部署完成!
)





