16. MySQL数据引擎:
引擎分类:
show engines命令查看数据库支持的存储引擎。
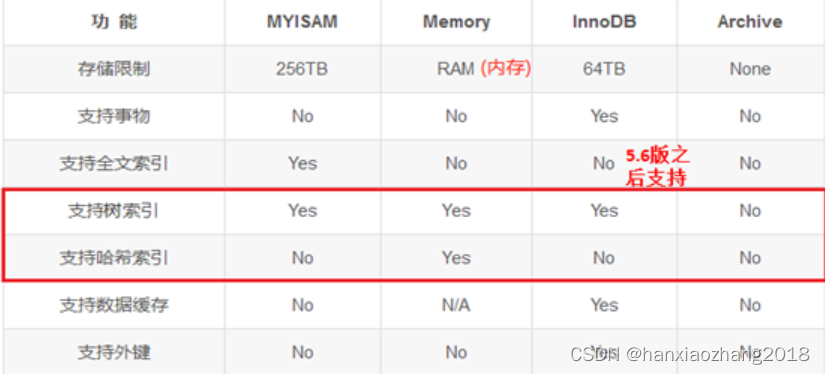
描述一下InnoDB和MyISAM的区别?**
- InnoDB存储限制64TB,而MyISAM存储限制256TB;
- InnoDB支持事物,而MyISAM不支持;
- InnoDB支持外键,而MyISAM不支持;
- InnoDB支持行级锁(默认)+表级锁,而MyISAM支持表级锁;
- InnoDB支持MVCC(多版本并发控制技术), 而MyISAM不支持;
- InnoDB即支持聚簇索引又支持非聚簇索引,而MyISAM 只支持非聚簇索引;
- InnoDB不支持全文索引(5.6版本之后支持),而MyISAM支持。
如何选择?
现在MySQL的默认存储引擎已经变成了InnoDB,推荐使用InnoDB:
- 1. 是否需要支持事务,如果需要选择InnoDB,如果不需要选择MyISAM;
- 2. 如果表的大部分请求都是读请求,可以考虑MyISAM,如果既有读也有写,使用InnoDB。
17. 描述一下MySQL主从复制的机制的原理?MySQL主从复制主要有几种模式?(没啥印象)
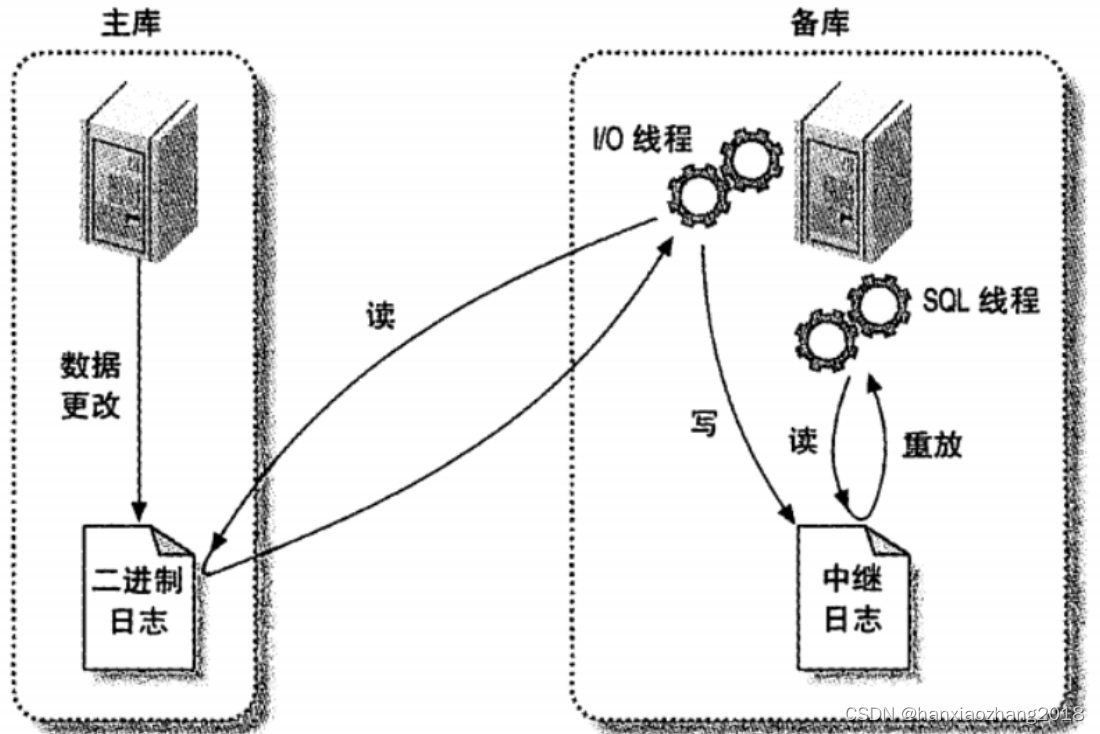
原理:
- 从库会生成两个线程:I/O线程和SQL线程;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay log(中继日志)文件中;
- SQL线程会读取relay log文件中的日志,并解析成SQL语句,并逐一执行。
- 同步时,主库会生成一个dump线程,用来给从库I/O线程传binlog。
模式:
一主一从、主主复制、一主多从、多主一从、联级复制。
主从同步延迟问题:*
- 原因:
- DML和DDL的IO操作是随机的,不是顺序,成本很高;
- 主库在高并发时,从库的SQL线程处理不过来;
- Slave中有大型Query语句产生了锁等待。
- 解决:
- 提高机器性能;
- 业务分库,一主多从;
- 加缓存层。
18. 如何优化SQL,查询计划(Explain)的结果中看哪些些关键数据?
前提:**
- 做好表结构设计,相关字段提前加索引。
- 业务处理,减少数据库连接;增加缓存层等。
如何优化:
- 开启慢查询日志(不说,因为没有实战经验)。
- 查询的优化:
- 减少连接次数;
- 返回更少的数据;
- 加索引,并且避免全表扫描,注意查看索引是否生效,是否效率高。
- 合理的分库分表。
- 数据库访问优化(建立数据库连接池,建索引)。
Explain作用:
模拟MySQL优化器运行SQL语句,了解MySQL如何处理你的SQL语句。分析SQL查询语句或是表结构的性能瓶颈。
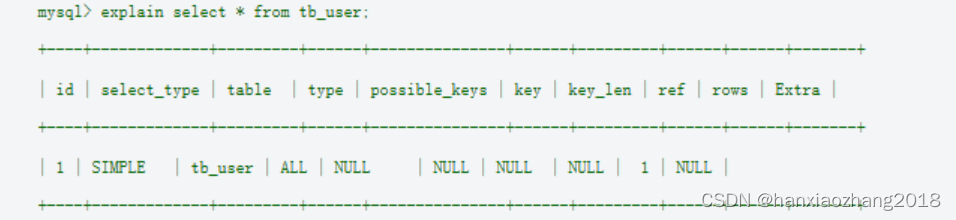
Explain解释:
- id列(数据列的执行顺序)
- select_type列(数据读取操作的操作类型)
- table列(该行数据是关于哪张表)
- type列(访问类型,重点关注):
- 由好到差system > const > eq_ref > ref > range > index > ALL,一般来说,保证查询至少达到range级别,最好能达到ref。
- system:表只有一条记录(等于系统表),这是const类型的特例,平时业务中不会出现。
- const:通过索引一次查到数据,该类型主要用于比较primary key 或者unique 索引,因为只匹配一行数据,所以很快。
- eq_ref:唯一索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或者唯一索引扫描。
- ref:非唯一索引扫描,返回匹配某个单独值得所有行,本质上是一种索引访问,它返回所有匹配某个单独值的行。
- range:只检索给定范围的行,使用一个索引来选着行。key列显示使用了哪个索引。一般在你的WHERE 语句中出现between 、< 、> 、in 等查询,这种给定范围扫描比全表扫描要好。因为他只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
- index:FUll Index Scan 扫描遍历索引树(扫描全表的索引,从索引中获取数据)。
- ALL:全表扫描 从磁盘中获取数据 百万级别的数据ALL类型的数据尽量优化。
- possible_keys列(显示可能应用在这张表的索引)
- keys列(实际使用到的索引,重点关注)
- ken_len列(索引中使用的字节数,重点关注)
- ref列(显示索引的哪一列被使用)
- rows列(每张表有多少行被优化器查询,重点关注)
- Extra列(扩展属性):Using filesort 、Using temporary 、 Using index ....
- using filesort:排序的字段没有使用索引
- Using temporary : 使用了临时表保存中间结果
https://www.cnblogs.com/gdwkong/articles/8505125.html
19. 描述一下MySQL的乐观锁和悲观锁,锁的种类?
乐观锁:
乐观锁并不是数据库自带的,需要自己去实现,一般情况下,我们会在表中新增一个version字段,每次更新数据version+1,在进行提交之前会判断version是否一致。
悲观锁:
MySQL中的绝大部分锁都是悲观锁,按照粒度可以分为行锁和表锁:
- 行锁:***
- 共享锁:当读取一行记录的时候,为了防止别人修改,则需要添加S锁。
- 排它锁:当修改一行记录的时候,为了防止别人同时进行修改,则需要添加X锁。

-
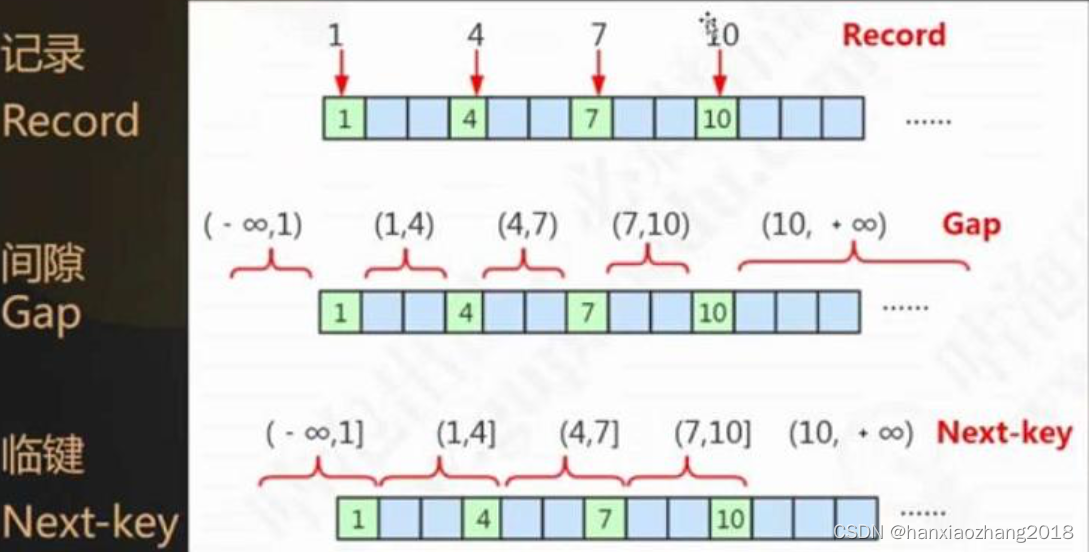
- 记录锁(Record Lock):添加在行索引上的锁。
- 间隙锁(Gap Lock):它的锁定范围是索引记录之间的间隙,针对可重复读以上隔离级别。
- 临键锁(Next-key Lock):记录锁 + 间隙锁。
- Tips:
- 如果不需要解决幻读问题,不要加临键锁和间隙锁。
- 加锁方式:SELECT ... for update;
- 表锁:
- 意向锁:在获取某行的锁之前,必须要获取表的锁,分为意向共享锁(IS),意向排它锁(IX)。
- 自增锁:对自增字段所采用的特殊表级锁。
锁的应用:
事务的隔离级别。
MySQL加锁情况分析:***
《见MySQL加锁》
锁模式(lock_mode)的含义: -> show engine innodb status\G; 查看
- IX:意向排它锁
- IS:意向共享锁
- X:锁定记录本身和记录之前的间隙,即临键锁
- S:锁定记录本身和记录之前的间隙,即临键锁
- X,REC_NOT_GAP:只锁定记录本身,即记录锁
- S,REC_NOT_GAP:只锁定记录本身,即记录锁
- X,GAP:间隙锁,不锁定记录本身
- S,GAP:间隙锁,不锁定记录本身
- X,GAP,INSERT_INTENTION:插入意向锁
20. MySQL数据库在什么情况下出现死锁?产生死锁的四个必要条件?如何解决死锁?
概念:
两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
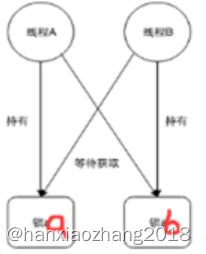
产生死锁的四个必要条件:
- 互斥条件:任何时刻一个资源只能被一个进程使用,其他进程只能等待。
- 请求和保持条件:进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己获得的其它资源保持不放。
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
- 环路等待条件:A想占有B在等待的资源(B等待A释放),B想占有A在等待的资源(A等待B释放)形成环路。
如何解决死锁?
- (1)顺序加锁、顺序访问表,可以大大降低死锁机会。
- (2)容易产生死锁的业务,可以升级锁的颗粒度(表级锁),减少死锁产生的概率。
- (3)设置超时时间,若事务超时就回滚,另一个等待的事务就能得以继续执行。




)

