引言
在深度学习的发展历程中,训练深度神经网络一直是一项极具挑战性的任务。随着网络层数的增加,梯度消失、梯度爆炸以及训练过程中的内部协变量偏移(Internal Covariate Shift)问题愈发严重,极大地影响了模型的收敛速度和性能。Batch Normalization(批量归一化,简称 BN)的出现,为解决这些问题提供了一种有效的方案,它就像深度学习训练中的一剂强心针,显著提升了模型的训练效率和稳定性。
什么是 Batch Normalization
内部协变量偏移问题
在神经网络的训练过程中,每一层的输入分布会随着前一层参数的更新而发生变化。这种输入分布的变化被称为内部协变量偏移。内部协变量偏移会导致后续层需要不断地适应新的输入分布,使得训练过程变得缓慢,甚至可能导致梯度消失或爆炸,影响模型的收敛。
Batch Normalization 的原理
我们在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。而我们Batch Normalization的目的就是使我们的feature map满足均值为0,方差为1的分布规律。
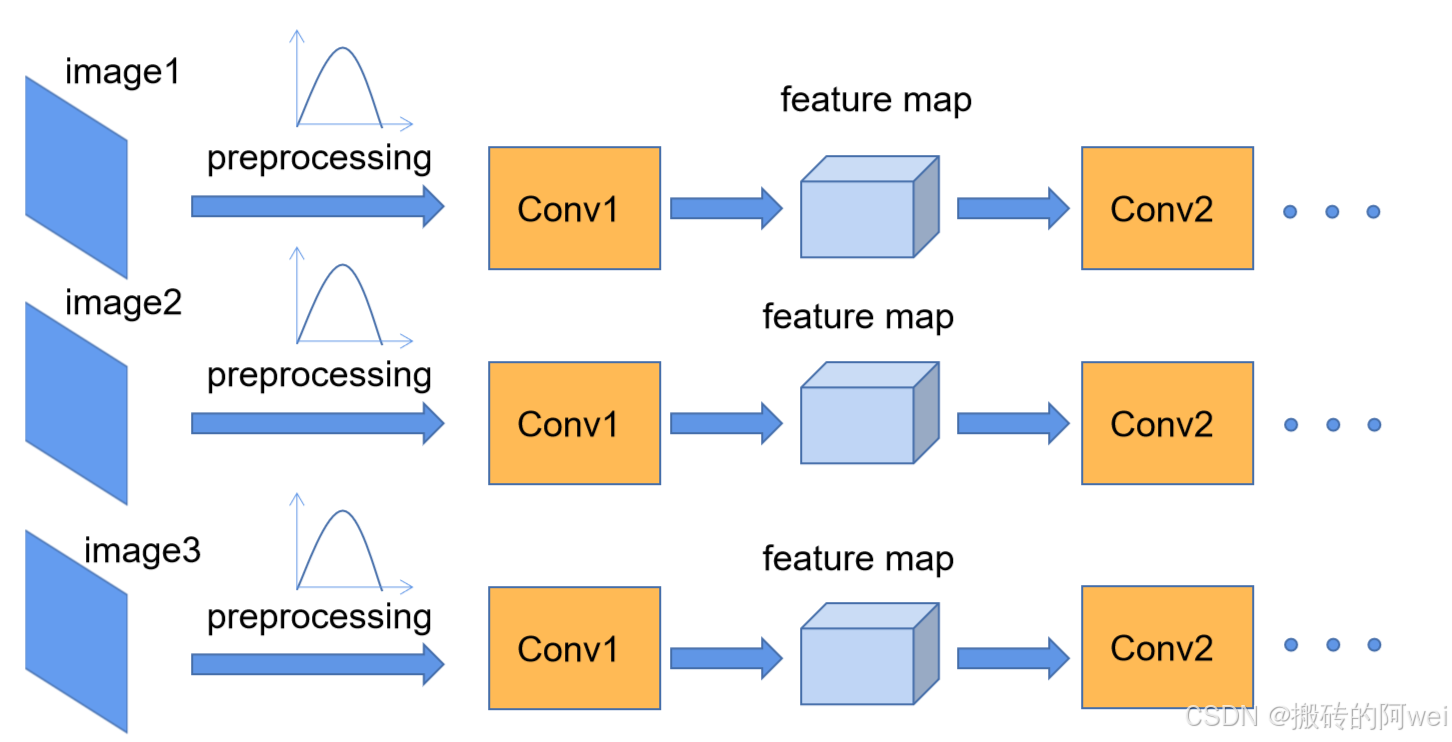
Batch Normalization 的核心思想是对每一层的输入进行归一化处理,使得输入的均值为 0,方差为 1。具体来说,对于一个包含个样本的小批量数据
,BN 层的计算步骤如下:

通过这种方式,BN 层将每一层的输入分布固定在一个相对稳定的范围内,减少了内部协变量偏移的影响,使得网络更容易训练。
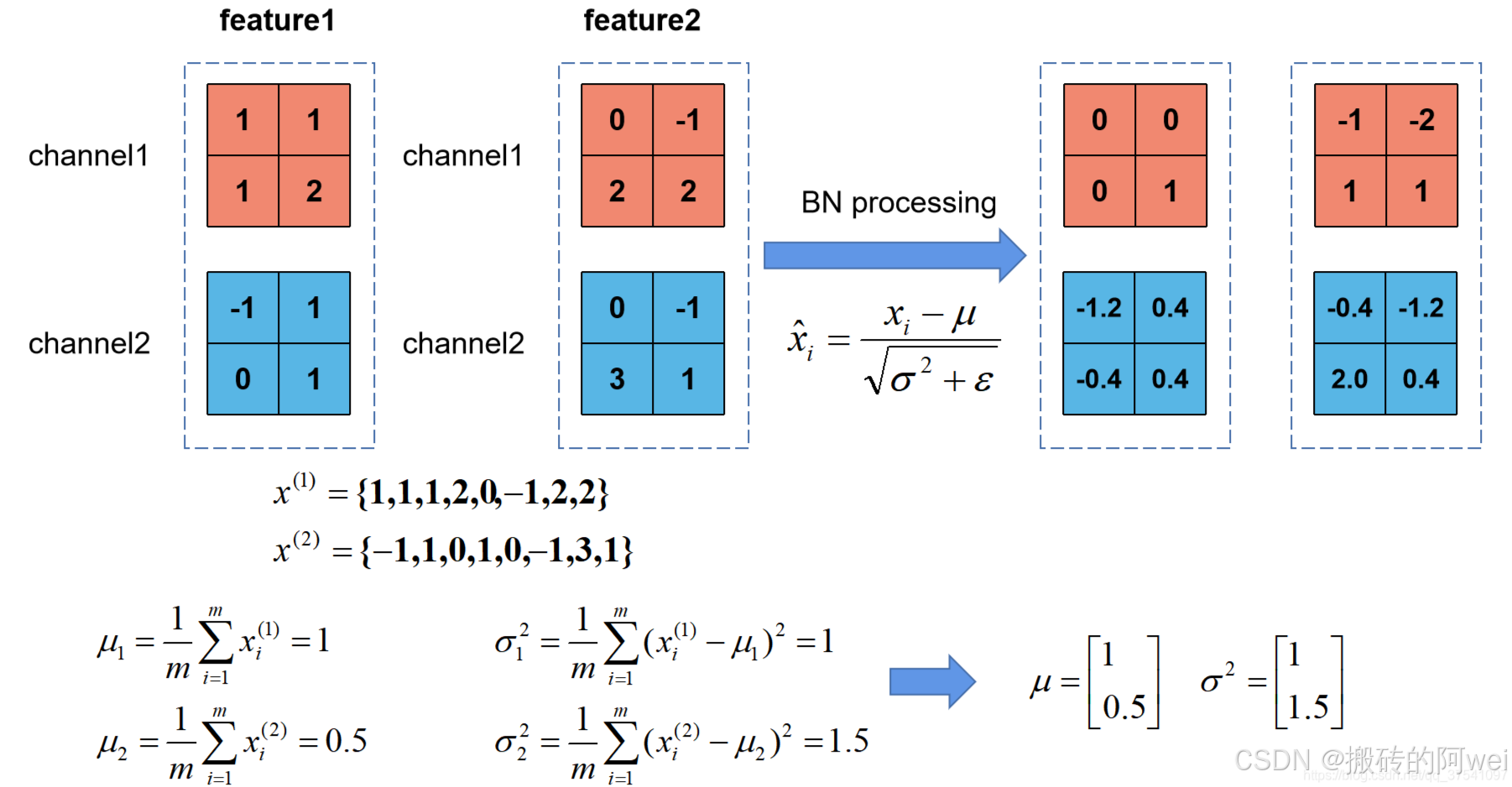
我们刚刚有说让feature map满足某一分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律,也就是说要计算出整个训练集的feature map然后在进行标准化处理,对于一个大型的数据集明显是不可能的,所以论文中说的是Batch Normalization,也就是我们计算一个Batch数据的feature map然后在进行标准化(batch越大越接近整个数据集的分布,效果越好)。我们根据上图的公式可以知道代表着我们计算的feature map每个维度(channel)的均值,注意
是一个向量不是一个值,
向量的每一个元素代表着一个维度(channel)的均值。
代表着我们计算的feature map每个维度(channel)的方差,注意
是一个向量不是一个值,
向量的每一个元素代表着一个维度(channel)的方差,然后根据
和
计算标准化处理后得到的值。下图给出了一个计算均值
和方差
的示例:

Batch Normalization 的优点
加速训练过程
BN 层可以显著加速模型的训练速度。由于归一化处理使得输入分布更加稳定,梯度在反向传播过程中不会出现剧烈的波动,从而可以使用更大的学习率进行训练,减少了训练所需的迭代次数。例如,在一些实验中,使用 BN 层的模型可以在相同的时间内达到更高的准确率。
提高模型的泛化能力
BN 层具有一定的正则化作用,可以减少过拟合的风险。通过对每一个小批量数据进行归一化处理,BN 层引入了一定的随机性,使得模型对输入数据的微小变化更加鲁棒,从而提高了模型在测试集上的泛化能力。
缓解梯度消失和梯度爆炸问题
在深度神经网络中,梯度消失和梯度爆炸是常见的问题。BN 层通过归一化处理,使得每一层的输入分布更加稳定,避免了梯度在反向传播过程中过度放大或缩小,从而缓解了梯度消失和梯度爆炸问题。
Batch Normalization 的应用场景
卷积神经网络(CNN)
在 CNN 中,BN 层通常应用于卷积层之后、激活函数之前。例如,在经典的 ResNet 网络中,BN 层被广泛使用,使得网络可以训练到更深的层数,从而取得更好的性能。
循环神经网络(RNN)
虽然 RNN 中也存在内部协变量偏移问题,但由于 RNN 的序列特性,直接应用 BN 层会遇到一些挑战。因此,在 RNN 中通常会使用一些改进的归一化方法,如 Layer Normalization(LN)、Instance Normalization(IN)等。
生成对抗网络(GAN)
在 GAN 中,BN 层可以帮助生成器和判别器更快地收敛,提高生成图像的质量。例如,在 DCGAN 中,BN 层被应用于生成器和判别器的每一层,使得模型能够生成更加逼真的图像。
Batch Normalization 的代码实现(以 PyTorch 为例)
import torch
import torch.nn as nn# 定义一个简单的卷积神经网络,包含 BN 层
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(16)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(32)self.fc1 = nn.Linear(32 * 8 * 8, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.pool(self.relu(self.bn1(self.conv1(x))))x = self.pool(self.relu(self.bn2(self.conv2(x))))x = x.view(-1, 32 * 8 * 8)x = self.relu(self.fc1(x))x = self.fc2(x)return x# 创建模型实例
model = SimpleCNN()
print(model)Batch Normalization 的局限性和改进方法
局限性
- 对小批量数据敏感:BN 层的性能依赖于小批量数据的统计信息。当小批量数据较小时,计算得到的均值和方差可能不准确,从而影响模型的性能。
- 不适用于动态序列数据:在处理动态序列数据时,如自然语言处理中的变长序列,BN 层的归一化操作可能会引入不必要的偏差。
改进方法
- Layer Normalization(LN):LN 对每一个样本的所有特征进行归一化处理,不依赖于小批量数据的统计信息,因此适用于动态序列数据。
- Instance Normalization(IN):IN 对每一个样本的每一个通道进行归一化处理,常用于图像风格迁移等任务。
- Group Normalization(GN):GN 将通道分成若干组,对每组内的特征进行归一化处理,介于 BN 和 LN 之间,在小批量数据和动态序列数据上都有较好的表现。
结论
Batch Normalization 是深度学习领域的一项重要技术,它通过对输入数据进行归一化处理,解决了内部协变量偏移问题,加速了模型的训练过程,提高了模型的泛化能力。虽然 BN 层存在一些局限性,但通过不断的改进和创新,如 LN、IN、GN 等方法的提出,使得归一化技术在不同的应用场景中都能发挥出更好的效果。随着深度学习的不断发展,归一化技术也将不断完善,为深度学习的进一步发展提供有力支持。






