PyTorch深度学习框架60天进阶学习计划 - 第41天
生成对抗网络进阶(二):Wasserstein GAN的梯度惩罚机制与模式坍塌问题
欢迎回来!在上一部分中,我们深入探讨了Wasserstein GAN的梯度惩罚机制及其如何改善标准GAN的训练问题,并初步了解了条件生成与无监督生成在模式坍塌方面的差异。今天,我们将继续深入这个主题,探索更多改进模式坍塌的技术,实现更高级的GAN变体,并分析真实世界应用场景。
第二部分:高级技术与实战应用
1. 超越WGAN-GP:其他改进模式坍塌的方法
除了我们已经讨论过的WGAN-GP和条件生成外,还有许多其他技术可以帮助缓解模式坍塌问题:
1.1 多样性敏感的损失函数
标准GAN的生成器损失并不直接激励多样性。一些改进的方法引入了多样性敏感的损失函数:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MinibatchDiscrimination(nn.Module):"""小批量判别模块,用于增加生成样本的多样性"""def __init__(self, in_features, out_features, kernel_dims):super(MinibatchDiscrimination, self).__init__()self.in_features = in_featuresself.out_features = out_featuresself.kernel_dims = kernel_dims# 权重参数,用于变换特征self.T = nn.Parameter(torch.Tensor(in_features, out_features, kernel_dims))nn.init.normal_(self.T, 0, 1)def forward(self, x):# x shape: [batch_size, in_features]# 将输入特征变换为中间表示# [batch_size, out_features, kernel_dims]matrices = x.mm(self.T.view(self.in_features, -1))matrices = matrices.view(-1, self.out_features, self.kernel_dims)# 计算批次中样本两两之间的L1距离batch_size = matrices.size(0)# 为了方便计算,将M_i扩展为[batch_size, batch_size, out_features, kernel_dims]M_i = matrices.unsqueeze(1).expand(batch_size, batch_size, self.out_features, self.kernel_dims)M_j = matrices.unsqueeze(0).expand(batch_size, batch_size, self.out_features, self.kernel_dims)# 计算L1距离,得到[batch_size, batch_size, out_features]dist = torch.abs(M_i - M_j).sum(3)# 对距离应用负指数,得到[batch_size, batch_size, out_features]# 距离越大,结果越接近0;距离越小,结果越接近1K = torch.exp(-dist)# 对每个样本,删除与自身的比较mask = (1 - torch.eye(batch_size, device=x.device)).unsqueeze(2)K = K * mask# 对每个样本,求和得到[batch_size, out_features]# 这表示每个样本与批次中其他样本的相似度mb_feats = K.sum(1)# 将原始特征与小批量判别特征拼接return torch.cat([x, mb_feats], dim=1)# 使用小批量判别的判别器示例
class DiscriminatorWithMinibatch(nn.Module):def __init__(self, img_size, channels):super(DiscriminatorWithMinibatch, self).__init__()self.img_shape = (channels, img_size, img_size)# 特征提取层self.features = nn.Sequential(nn.Linear(int(np.prod(self.img_shape)), 512),nn.LeakyReLU(0.2, inplace=True),nn.Linear(512, 256),nn.LeakyReLU(0.2, inplace=True),)# 小批量判别层self.minibatch_disc = MinibatchDiscrimination(256, 32, 16)# 输出层self.output = nn.Sequential(nn.Linear(256 + 32, 1),nn.Sigmoid(),)def forward(self, img):img_flat = img.view(img.size(0), -1)features = self.features(img_flat)enhanced_features = self.minibatch_disc(features)validity = self.output(enhanced_features)return validity# 另一种多样性损失:特征匹配损失
def feature_matching_loss(real_features, fake_features):"""特征匹配损失,鼓励生成样本匹配真实样本的特征统计"""# 计算每个特征维度的均值real_mean = real_features.mean(0)fake_mean = fake_features.mean(0)# 计算均值之间的L2距离return F.mse_loss(real_mean, fake_mean)# 具有修改生成器目标的GAN训练循环示例
def train_with_feature_matching(dataloader, latent_dim, generator, discriminator, g_optimizer, d_optimizer, device, n_epochs=100, lambda_fm=10.0):"""使用特征匹配损失训练GAN"""# BCE损失函数adversarial_loss = nn.BCELoss()for epoch in range(n_epochs):for i, (real_imgs, _) in enumerate(dataloader):batch_size = real_imgs.size(0)real_imgs = real_imgs.to(device)# 真实样本的标签: 1real_target = torch.ones(batch_size, 1).to(device)# 生成样本的标签: 0fake_target = torch.zeros(batch_size, 1).to(device)# -----------------# 训练判别器# -----------------d_optimizer.zero_grad()# 从判别器获取真实样本的特征和输出real_features = discriminator.features(real_imgs.view(batch_size, -1))real_pred = discriminator.output(discriminator.minibatch_disc(real_features))d_real_loss = adversarial_loss(real_pred, real_target)# 生成假样本z = torch.randn(batch_size, latent_dim).to(device)fake_imgs = generator(z)# 从判别器获取假样本的特征和输出fake_features = discriminator.features(fake_imgs.detach().view(batch_size, -1))fake_pred = discriminator.output(discriminator.minibatch_disc(fake_features))d_fake_loss = adversarial_loss(fake_pred, fake_target)# 总判别器损失d_loss = (d_real_loss + d_fake_loss) / 2d_loss.backward()d_optimizer.step()# -----------------# 训练生成器# -----------------g_optimizer.zero_grad()# 重新获取假样本的特征和输出fake_features = discriminator.features(fake_imgs.view(batch_size, -1))fake_pred = discriminator.output(discriminator.minibatch_disc(fake_features))# 标准对抗损失g_adv_loss = adversarial_loss(fake_pred, real_target)# 特征匹配损失g_fm_loss = feature_matching_loss(real_features.detach(), fake_features)# 总生成器损失g_loss = g_adv_loss + lambda_fm * g_fm_lossg_loss.backward()g_optimizer.step()# 打印训练信息if i % 100 == 0:print(f"[Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "f"[D loss: {d_loss.item():.4f}] [G adv: {g_adv_loss.item():.4f}] [G fm: {g_fm_loss.item():.4f}]")
这段代码实现了两种促进多样性的损失函数:
-
小批量判别(Minibatch Discrimination):通过让判别器能够比较批次中的样本,鼓励生成器产生彼此不同的样本。当生成器产生相似样本时,小批量判别模块会给予较低的评分。
-
特征匹配(Feature Matching):通过鼓励生成样本在判别器的中间层特征上匹配真实样本的统计特性,间接地促进多样性。
1.2 基于梯度的方法与正则化
除了梯度惩罚之外,还有其他基于梯度的方法来改善GAN训练:
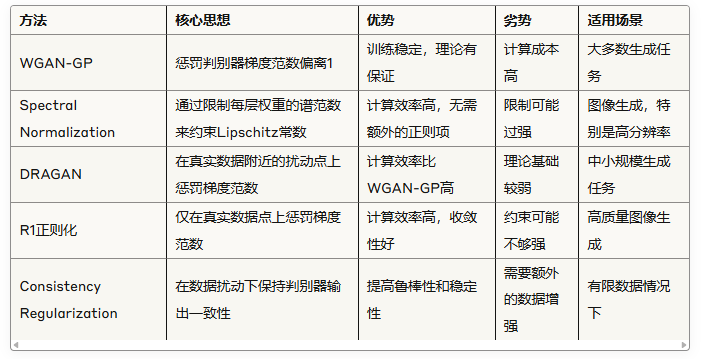
让我们详细看一下谱归一化(Spectral Normalization)的实现,这是一种计算效率高的Lipschitz约束方法:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils import spectral_norm# 使用谱归一化的判别器
class SNDiscriminator(nn.Module):def __init__(self, img_size, channels):super(SNDiscriminator, self).__init__()self.img_shape = (channels, img_size, img_size)# 使用spectral_norm包装每一层的权重self.model = nn.Sequential(spectral_norm(nn.Conv2d(channels, 64, 4, stride=2, padding=1)),nn.LeakyReLU(0.2, inplace=True),spectral_norm(nn.Conv2d(64, 128, 4, stride=2, padding=1)),nn.LeakyReLU(0.2, inplace=True),spectral_norm(nn.Conv2d(128, 256, 4, stride=2, padding=1)),nn.LeakyReLU(0.2, inplace=True),spectral_norm(nn.Conv2d(256, 512, 4, stride=2, padding=1)),nn.LeakyReLU(0.2, inplace=True),spectral_norm(nn.Conv2d(512, 1, 4, stride=1, padding=0)))def forward(self, img):validity = self.model(img)return validity.view(img.size(0), -1)# 使用自注意力机制的生成器
class SelfAttentionGenerator(nn.Module):def __init__(self, latent_dim, channels=3):super(SelfAttentionGenerator, self).__init__()self.init_size = 8 # 初始特征图大小self.l1 = nn.Sequential(nn.Linear(latent_dim, 128 * self.init_size ** 2))self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),)# 自注意力层self.attention = SelfAttention(64)self.final = nn.Sequential(nn.Conv2d(64, channels, 3, stride=1, padding=1),nn.Tanh())def forward(self, z):out = self.l1(z)out = out.view(out.shape[0], 128, self.init_size, self.init_size)out = self.conv_blocks(out)out = self.attention(out)img = self.final(out)return img# 自注意力模块
class SelfAttention(nn.Module):""" 自注意力模块,用于关注图像不同部分之间的关系 """def __init__(self, in_dim):super(SelfAttention, self).__init__()self.query_conv = nn.Conv2d(in_dim, in_dim // 8, 1)self.key_conv = nn.Conv2d(in_dim, in_dim // 8, 1)self.value_conv = nn.Conv2d(in_dim, in_dim, 1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self, x):batch_size, C, width, height = x.size()# 计算查询、键和值proj_query = self.query_conv(x).view(batch_size, -1, width * height).permute(0, 2, 1) # B X (W*H) X C'proj_key = self.key_conv(x).view(batch_size, -1, width * height) # B X C' X (W*H)energy = torch.bmm(proj_query, proj_key) # B X (W*H) X (W*H)attention = F.softmax(energy, dim=-1) # B X (W*H) X (W*H)proj_value = self.value_conv(x).view(batch_size, -1, width * height) # B X C X (W*H)out = torch.bmm(proj_value, attention.permute(0, 2, 1)) # B X C X (W*H)out = out.view(batch_size, C, width, height) # B X C X W X H# 残差连接out = self.gamma * out + xreturn out# 使用R1梯度惩罚的函数
def compute_r1_penalty(discriminator, real_samples, device):"""仅在真实数据上计算的R1梯度惩罚"""real_samples.requires_grad = True# 计算判别器输出real_validity = discriminator(real_samples)real_validity = real_validity.mean()# 计算梯度gradients = torch.autograd.grad(outputs=real_validity,inputs=real_samples,create_graph=True,retain_graph=True,)[0]# 计算梯度的平方范数gradients = gradients.view(gradients.size(0), -1)r1_penalty = 0.5 * torch.sum(gradients ** 2, dim=1).mean()return r1_penalty# R1惩罚的训练循环示例
def train_with_r1_penalty(dataloader, latent_dim, generator, discriminator, g_optimizer, d_optimizer, device, n_epochs=100, r1_gamma=10.0):"""使用R1梯度惩罚训练GAN"""for epoch in range(n_epochs):for i, (real_imgs, _) in enumerate(dataloader):batch_size = real_imgs.size(0)real_imgs = real_imgs.to(device)# -----------------# 训练判别器# -----------------d_optimizer.zero_grad()# 计算真实样本的判别器输出real_validity = discriminator(real_imgs)# 生成假样本z = torch.randn(batch_size, latent_dim).to(device)fake_imgs = generator(z)# 计算假样本的判别器输出fake_validity = discriminator(fake_imgs.detach())# 计算WGAN损失d_loss = -torch.mean(real_validity) + torch.mean(fake_validity)# 计算R1梯度惩罚r1_penalty = compute_r1_penalty(discriminator, real_imgs, device)# 添加R1惩罚到判别器损失d_loss = d_loss + r1_gamma * r1_penaltyd_loss.backward()d_optimizer.step()# -----------------# 训练生成器# -----------------if i % 5 == 0: # 每5次判别器更新更新一次生成器g_optimizer.zero_grad()# 生成新的假样本z = torch.randn(batch_size, latent_dim).to(device)fake_imgs = generator(z)fake_validity = discriminator(fake_imgs)# 计算生成器损失g_loss = -torch.mean(fake_validity)g_loss.backward()g_optimizer.step()# 打印训练信息if i % 100 == 0:print(f"[Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}] [R1: {r1_penalty.item():.4f}]")
上面的代码展示了几种改进GAN训练的技术:
-
谱归一化(Spectral Normalization):通过约束每一层权重矩阵的谱范数(最大奇异值)来强制Lipschitz约束,无需额外的正则化项。
-
自注意力机制(Self-Attention):帮助生成器关注图像的不同部分之间的关系,生成结构更一致、细节更丰富的图像。
-
R1正则化:只在真实数据点上惩罚梯度范数的平方,计算效率高于WGAN-GP,同时保持良好的稳定性。
1.3 架构改进:自注意力和归一化
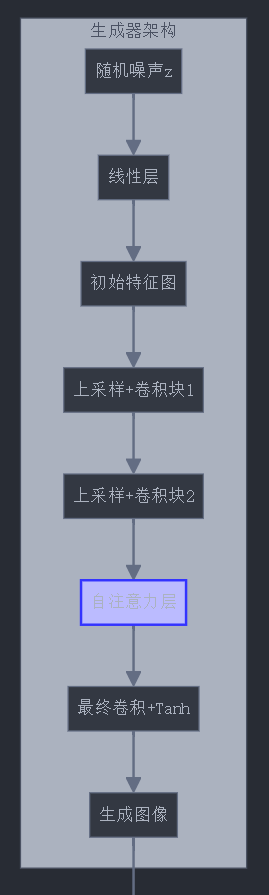
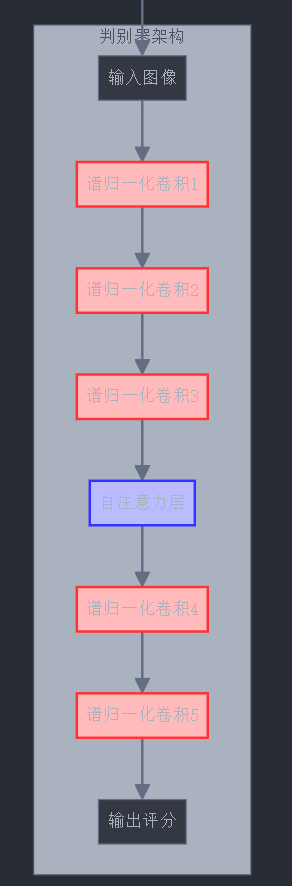
2. 条件信息的高级注入方法
在条件GAN中,如何有效地注入条件信息对于改善模式坍塌和生成质量至关重要。让我们探讨几种高级的条件注入方法:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np# 条件批归一化层
class ConditionalBatchNorm2d(nn.Module):"""条件批归一化层,根据类别标签调整特征的均值和方差"""def __init__(self, num_features, num_classes):super(ConditionalBatchNorm2d, self).__init__()self.num_features = num_featuresself.bn = nn.BatchNorm2d(num_features, affine=False) # 不学习仿射参数self.embed = nn.Embedding(num_classes, num_features * 2) # 为每个类别学习gamma和beta# 初始化嵌入self.embed.weight.data[:, :num_features].normal_(1, 0.02) # gamma ~ N(1, 0.02)self.embed.weight.data[:, num_features:].zero_() # beta ~ 0def forward(self, x, y):out = self.bn(x)gamma, beta = self.embed(y).chunk(2, dim=1)gamma = gamma.view(-1, self.num_features, 1, 1)beta = beta.view(-1, self.num_features, 1, 1)return gamma * out + beta# 使用条件批归一化的生成器块
class ConcatConditionGenerator(nn.Module):"""使用条件连接的生成器"""def __init__(self, latent_dim, n_classes, img_size, channels):super(ConcatConditionGenerator, self).__init__()self.img_shape = (channels, img_size, img_size)self.latent_dim = latent_dimself.label_emb = nn.Embedding(n_classes, 50) # 标签嵌入# 初始处理self.init = nn.Sequential(nn.Linear(latent_dim + 50, 256 * 4 * 4),nn.LeakyReLU(0.2, inplace=True))# 上采样块self.conv1 = nn.Sequential(nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True))self.conv2 = nn.Sequential(nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True))self.conv3 = nn.Sequential(nn.ConvTranspose2d(64, channels, 4, stride=2, padding=1),nn.Tanh())def forward(self, z, labels):# 获取标签嵌入label_emb = self.label_emb(labels)# 连接噪声和标签嵌入x = torch.cat([z, label_emb], dim=1)# 初始处理x = self.init(x)x = x.view(x.size(0), 256, 4, 4)# 上采样x = self.conv1(x)x = self.conv2(x)img = self.conv3(x)return img# 使用条件批归一化的生成器
class CBNGenerator(nn.Module):"""使用条件批归一化的生成器"""def __init__(self, latent_dim, n_classes, img_size, channels):super(CBNGenerator, self).__init__()self.img_shape = (channels, img_size, img_size)self.latent_dim = latent_dim# 初始处理self.init = nn.Linear(latent_dim, 256 * 4 * 4)# 条件批归一化上采样块self.cbn1 = ConditionalBatchNorm2d(256, n_classes)self.conv1 = nn.Sequential(nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True))self.cbn2 = ConditionalBatchNorm2d(128, n_classes)self.conv2 = nn.Sequential(nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True))self.cbn3 = ConditionalBatchNorm2d(64, n_classes)self.conv3 = nn.Sequential(nn.ConvTranspose2d(64, channels, 4, stride=2, padding=1),nn.Tanh())def forward(self, z, labels):# 初始处理x = self.init(z)x = x.view(x.size(0), 256, 4, 4)# 条件批归一化上采样x = self.cbn1(x, labels)x = self.conv1(x)x = self.cbn2(x, labels)x = self.conv2(x)x = self.cbn3(x, labels)x = self.conv3(x)return x# 自适应实例归一化(AdaIN)条件生成器
class AdaINGenerator(nn.Module):"""使用AdaIN的生成器,常用于StyleGAN等高级GAN架构"""def __init__(self, latent_dim, style_dim, img_size, channels):super(AdaINGenerator, self).__init__()self.img_shape = (channels, img_size, img_size)# 映射网络,将潜在向量映射到样式空间self.mapping = nn.Sequential(nn.Linear(latent_dim, 256),nn.LeakyReLU(0.2),nn.Linear(256, 256),nn.LeakyReLU(0.2),nn.Linear(256, style_dim))# 初始常量特征图self.const = nn.Parameter(torch.randn(1, 512, 4, 4))# AdaIN上采样块self.adain1 = AdaIN(512, style_dim)self.conv1 = nn.Sequential(nn.Conv2d(512, 256, 3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2))self.adain2 = AdaIN(256, style_dim)self.conv2 = nn.Sequential(nn.Conv2d(256, 128, 3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2))self.adain3 = AdaIN(128, style_dim)self.conv3 = nn.Sequential(nn.Conv2d(128, 64, 3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2))# 输出层self.output = nn.Sequential(nn.Conv2d(64, channels, 1),nn.Tanh())def forward(self, z):# 映射潜在向量到样式向量w = self.mapping(z)# 从常量开始x = self.const.repeat(z.size(0), 1, 1, 1)# AdaIN风格调制x = self.adain1(x, w)x = self.conv1(x)x = self.adain2(x, w)x = self.conv2(x)x = self.adain3(x, w)x = self.conv3(x)# 输出img = self.output(x)return img# 自适应实例归一化(AdaIN)层
class AdaIN(nn.Module):"""自适应实例归一化层,用于风格转换"""def __init__(self, in_channel, style_dim):super().__init__()# 为每个通道学习缩放和偏移参数self.norm = nn.InstanceNorm2d(in_channel)self.style = nn.Linear(style_dim, in_channel * 2)# 初始化self.style.bias.data[:in_channel] = 1self.style.bias.data[in_channel:] = 0def forward(self, input, style):style = self.style(style).unsqueeze(2).unsqueeze(3)gamma, beta = style.chunk(2, 1)out = self.norm(input)out = gamma * out + betareturn out# 使用Transformer的条件GAN
class TransformerConditionGenerator(nn.Module):"""使用Transformer架构注入条件信息的生成器"""def __init__(self, latent_dim, n_classes, img_size, channels):super(TransformerConditionGenerator, self).__init__()self.img_shape = (channels, img_size, img_size)self.latent_dim = latent_dim# 类别嵌入self.class_embedding = nn.Embedding(n_classes, 128)# Transformer编码器层encoder_layer = nn.TransformerEncoderLayer(d_model=latent_dim + 128, # 噪声+类别嵌入的维度nhead=8, # 多头注意力头数dim_feedforward=512,dropout=0.1)self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=3)# 映射到初始特征图self.to_feature = nn.Linear(latent_dim + 128, 256 * 4 * 4)# 上采样块self.upsampling = nn.Sequential(nn.ConvTranspose2d(256, 128, 4, 2, 1), # 8x8nn.BatchNorm2d(128),nn.LeakyReLU(0.2, inplace=True),nn.ConvTranspose2d(128, 64, 4, 2, 1), # 16x16nn.BatchNorm2d(64),nn.LeakyReLU(0.2, inplace=True),nn.ConvTranspose2d(64, channels, 4, 2, 1), # 32x32nn.Tanh())def forward(self, z, labels):# 获取类别嵌入class_emb = self.class_embedding(labels)# 连接噪声和类别嵌入x = torch.cat([z, class_emb], dim=1)# Transformer处理 (增加序列维度)x = x.unsqueeze(0) # [1, batch_size, dim]x = self.transformer_encoder(x)x = x.squeeze(0) # [batch_size, dim]# 映射到特征图x = self.to_feature(x)x = x.view(x.size(0), 256, 4, 4)# 上采样生成图像img = self.upsampling(x)return img# 使用FiLM(Feature-wise Linear Modulation)的条件生成器
class FiLMLayer(nn.Module):"""特征线性调制层,一种简单高效的条件注入方法"""def __init__(self, num_features, condition_dim):super(FiLMLayer, self).__init__()self.film = nn.Linear(condition_dim, num_features * 2)def forward(self, x, condition):# 计算FiLM参数film_params = self.film(condition).unsqueeze(2).unsqueeze(3)gamma, beta = film_params.chunk(2, dim=1)# 应用FiLM调制return (1 + gamma) * x + betaclass FiLMGenerator(nn.Module):"""使用FiLM层的条件生成器"""def __init__(self, latent_dim, condition_dim, img_size, channels):super(FiLMGenerator, self).__init__()self.img_shape = (channels, img_size, img_size)# 初始处理self.initial = nn.Sequential(nn.Linear(latent_dim, 256 * 4 * 4),nn.LeakyReLU(0.2))# 上采样块1self.conv1 = nn.Sequential(nn.ConvTranspose2d(256, 128, 4, 2, 1),nn.BatchNorm2d(128),nn.LeakyReLU(0.2))self.film1 = FiLMLayer(128, condition_dim)# 上采样块2self.conv2 = nn.Sequential(nn.ConvTranspose2d(128, 64, 4, 2, 1),nn.BatchNorm2d(64),nn.LeakyReLU(0.2))self.film2 = FiLMLayer(64, condition_dim)# 输出层self.output = nn.Sequential(nn.ConvTranspose2d(64, channels, 4, 2, 1),nn.Tanh())def forward(self, z, condition):# 初始处理x = self.initial(z)x = x.view(x.size(0), 256, 4, 4)# 应用FiLM调制的上采样x = self.conv1(x)x = self.film1(x, condition)x = self.conv2(x)x = self.film2(x, condition)# 输出img = self.output(x)return img
3. 多样性度量与评估方法
要客观地评估GAN生成的样本多样性和检测模式坍塌,我们需要可靠的度量方法:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
import numpy as np
from scipy.linalg import sqrtm
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt# 预训练特征提取器
class FeatureExtractor(nn.Module):def __init__(self, use_inception=True):super(FeatureExtractor, self).__init__()if use_inception:# 使用预训练的Inception模型self.model = models.inception_v3(pretrained=True)self.model.eval()# 使用辅助分类器之前的特征self.output_layer = self.model.Mixed_7cself.output_size = 2048else:# 使用预训练的ResNet模型self.model = models.resnet50(pretrained=True)self.model.eval()# 移除最后的全连接层self.model = nn.Sequential(*list(self.model.children())[:-1])self.output_size = 2048def forward(self, x):with torch.no_grad():if hasattr(self, 'output_layer'):# Inception模型需要特殊处理x = F.interpolate(x, size=(299, 299), mode='bilinear', align_corners=False)# 获取特定层的特征,而不是最终输出for module in self.model.children():if module == self.output_layer:breakx = module(x)x = F.adaptive_avg_pool2d(x, (1, 1))else:# ResNet直接使用x = F.interpolate(x, size=(224, 224), mode='bilinear', align_corners=False)x = self.model(x)return x.view(x.size(0), -1)# 计算Inception Score (IS)
def calculate_inception_score(images, feature_extractor, n_split=10, eps=1e-16):"""计算Inception Score参数:images: 生成图像张量,形状为[n_images, channels, height, width]feature_extractor: 特征提取器n_split: 分割批次数eps: 数值稳定性的小值返回:IS均值和标准差"""# 提取特征并获取预测概率features = feature_extractor(images)# 转换为概率分布probs = F.softmax(features, dim=1).cpu().numpy()# 计算每个分割的ISscores = []n_images = probs.shape[0]n_part = n_images // n_splitfor i in range(n_split):part = probs[i * n_part:(i + 1) * n_part]kl = part * (np.log(part + eps) - np.log(np.mean(part, axis=0, keepdims=True) + eps))kl = np.mean(np.sum(kl, axis=1))scores.append(np.exp(kl))# 返回均值和标准差return np.mean(scores), np.std(scores)# 计算Fréchet Inception Distance (FID)
def calculate_fid(real_images, fake_images, feature_extractor):"""计算Fréchet Inception Distance参数:real_images: 真实图像张量,形状为[n_images, channels, height, width]fake_images: 生成图像张量,形状为[n_images, channels, height, width]feature_extractor: 特征提取器返回:FID分数,越低越好"""# 提取真实和生成图像的特征real_features = feature_extractor(real_images).cpu().numpy()fake_features = feature_extractor(fake_images).cpu().numpy()# 计算特征的均值和协方差mu_real = np.mean(real_features, axis=0)sigma_real = np.cov(real_features, rowvar=False)mu_fake = np.mean(fake_features, axis=0)sigma_fake = np.cov(fake_features, rowvar=False)# 计算平方根项sqrt_term = sqrtm(sigma_real.dot(sigma_fake))# 确保没有复数部分(由于数值误差)if np.iscomplexobj(sqrt_term):sqrt_term = sqrt_term.real# 计算FIDfid = np.sum((mu_real - mu_fake) ** 2) + np.trace(sigma_real + sigma_fake - 2 * sqrt_term)return fid# 计算Precision和Recall
def calculate_precision_recall(real_features, fake_features, k=3, threshold=None):"""计算GAN的Precision和Recall参数:real_features: 真实图像特征,形状为[n_real, feature_dim]fake_features: 生成图像特征,形状为[n_fake, feature_dim]k: KNN的k值threshold: 距离阈值,默认为None(自动计算)返回:precision 和 recall"""# 规范化特征real_features = real_features / np.linalg.norm(real_features, axis=1, keepdims=True)fake_features = fake_features / np.linalg.norm(fake_features, axis=1, keepdims=True)# 计算最近邻n_real = real_features.shape[0]n_fake = fake_features.shape[0]# 计算fake到real的距离(用于precision)precision_distances = []for i in range(n_fake):# 计算与所有真实样本的余弦距离distances = 1 - fake_features[i].dot(real_features.T)# 获取K个最近邻的距离nearest_distances = np.sort(distances)[:k]precision_distances.append(np.mean(nearest_distances))# 计算real到fake的距离(用于recall)recall_distances = []for i in range(n_real):# 计算与所有生成样本的余弦距离distances = 1 - real_features[i].dot(fake_features.T)# 获取K个最近邻的距离nearest_distances = np.sort(distances)[:k]recall_distances.append(np.mean(nearest_distances))# 如果没有提供阈值,则使用距离分布计算if threshold is None:threshold = np.mean(recall_distances) + np.std(recall_distances)# 计算precision和recallprecision = np.mean(np.array(precision_distances) < threshold)recall = np.mean(np.array(recall_distances) < threshold)return precision, recall# 可视化特征分布
def visualize_feature_distribution(real_features, fake_features, title='Feature Distribution', save_path=None):"""使用t-SNE可视化特征分布参数:real_features: 真实图像特征fake_features: 生成图像特征title: 图表标题save_path: 保存路径,如果不为None则保存图像"""# 从高维特征中随机抽样,避免t-SNE计算过慢n_samples = min(1000, len(real_features), len(fake_features))real_subset = real_features[np.random.choice(len(real_features), n_samples, replace=False)]fake_subset = fake_features[np.random.choice(len(fake_features), n_samples, replace=False)]# 合并特征combined_features = np.vstack([real_subset, fake_subset])# 使用t-SNE降维到2Dfrom sklearn.manifold import TSNEtsne = TSNE(n_components=2, random_state=42)embedded = tsne.fit_transform(combined_features)# 分离真实和生成样本的嵌入real_embedded = embedded[:n_samples]fake_embedded = embedded[n_samples:]# 可视化plt.figure(figsize=(10, 8))plt.scatter(real_embedded[:, 0], real_embedded[:, 1], c='blue', label='Real', alpha=0.5)plt.scatter(fake_embedded[:, 0], fake_embedded[:, 1], c='red', label='Generated', alpha=0.5)plt.title(title)plt.legend()plt.grid(True)if save_path:plt.savefig(save_path)plt.show()# 检测模式坍塌
def detect_mode_collapse(features, n_clusters=10):"""通过特征聚类检测模式坍塌参数:features: 生成图像的特征n_clusters: 聚类数量,对应期望的模式数返回:聚类评分和聚类大小分布"""# 使用K-means聚类kmeans = KMeans(n_clusters=n_clusters, random_state=42)cluster_labels = kmeans.fit_predict(features)# 计算轮廓系数(衡量聚类质量)silhouette_avg = silhouette_score(features, cluster_labels)# 计算每个聚类的样本数cluster_sizes = np.bincount(cluster_labels, minlength=n_clusters)# 计算聚类大小的标准差(衡量分布均匀程度)cluster_std = np.std(cluster_sizes) / np.mean(cluster_sizes)# 计算最大的聚类占比max_cluster_ratio = np.max(cluster_sizes) / np.sum(cluster_sizes)results = {'silhouette_score': silhouette_avg,'cluster_std_normalized': cluster_std,'max_cluster_ratio': max_cluster_ratio,'cluster_sizes': cluster_sizes}return results# 可视化模式坍塌检测结果
def visualize_mode_collapse(cluster_results, title='Cluster Size Distribution', save_path=None):"""可视化聚类大小分布,帮助检测模式坍塌参数:cluster_results: detect_mode_collapse的返回结果title: 图表标题save_path: 保存路径,如果不为None则保存图像"""cluster_sizes = cluster_results['cluster_sizes']plt.figure(figsize=(12, 6))# 绘制聚类大小条形图plt.subplot(1, 2, 1)plt.bar(range(len(cluster_sizes)), cluster_sizes)plt.xlabel('Cluster')plt.ylabel('Number of Samples')plt.title('Cluster Size Distribution')# 添加文本标注collapse_info = f"Silhouette Score: {cluster_results['silhouette_score']:.4f}\n"collapse_info += f"Normalized Std: {cluster_results['cluster_std_normalized']:.4f}\n"collapse_info += f"Max Cluster Ratio: {cluster_results['max_cluster_ratio']:.4f}"plt.subplot(1, 2, 2)plt.axis('off')plt.text(0.1, 0.5, collapse_info, fontsize=12)plt.title('Mode Collapse Metrics')plt.tight_layout()if save_path:plt.savefig(save_path)plt.show()# 集成的多样性评估
def evaluate_gan_diversity(real_images, fake_images, generator, latent_dim, n_samples=1000, batch_size=50, device='cuda'):"""综合评估GAN的生成多样性参数:real_images: 真实图像样本fake_images: 生成图像样本generator: 生成器模型latent_dim: 潜在空间维度n_samples: 评估的样本数量batch_size: 批次大小device: 计算设备返回:包含多种多样性指标的字典"""# 特征提取器feature_extractor = FeatureExtractor().to(device)# 确保有足够的样本进行评估if len(fake_images) < n_samples:# 生成更多样本remaining = n_samples - len(fake_images)additional_samples = []with torch.no_grad():for i in range(0, remaining, batch_size):batch_size_i = min(batch_size, remaining - i)z = torch.randn(batch_size_i, latent_dim).to(device)samples = generator(z)additional_samples.append(samples)additional_samples = torch.cat(additional_samples, dim=0)fake_images = torch.cat([fake_images, additional_samples], dim=0)# 提取特征real_features = feature_extractor(real_images[:n_samples]).cpu().numpy()fake_features = feature_extractor(fake_images[:n_samples]).cpu().numpy()# 计算Inception Scoreis_mean, is_std = calculate_inception_score(fake_images[:n_samples], feature_extractor)# 计算FIDfid = calculate_fid(real_images[:n_samples], fake_images[:n_samples], feature_extractor)# 计算Precision和Recallprecision, recall = calculate_precision_recall(real_features, fake_features)# 检测模式坍塌collapse_results = detect_mode_collapse(fake_features)# 集成结果results = {'inception_score': (is_mean, is_std),'fid': fid,'precision': precision,'recall': recall,'mode_collapse': collapse_results}return results, real_features, fake_features
上面的代码实现了几种评估GAN生成多样性的关键指标:
-
Inception Score (IS):通过测量生成图像的类别多样性和每个图像的清晰度,评估生成质量和多样性。
-
Fréchet Inception Distance (FID):通过比较真实和生成图像在特征空间中的分布来评估生成质量,是目前最广泛使用的GAN评估指标。
-
Precision和Recall:分别衡量生成器的生成质量(precision)和覆盖度(recall),有助于检测模式坍塌。
-
特征聚类分析:通过聚类生成样本的特征并分析聚类大小分布,可以直观地检测模式坍塌。
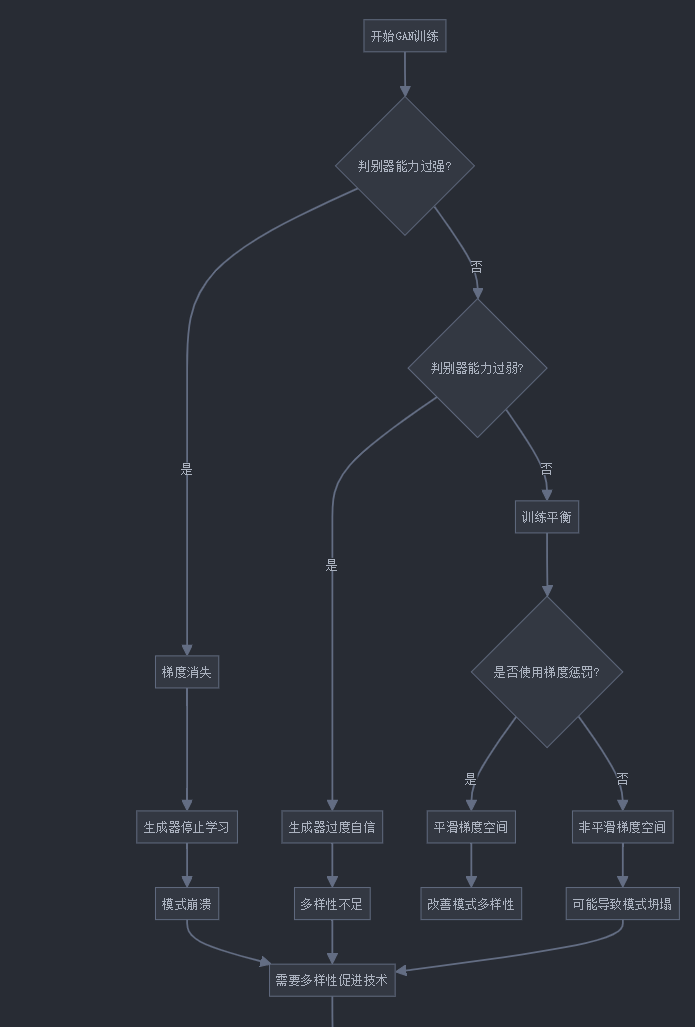
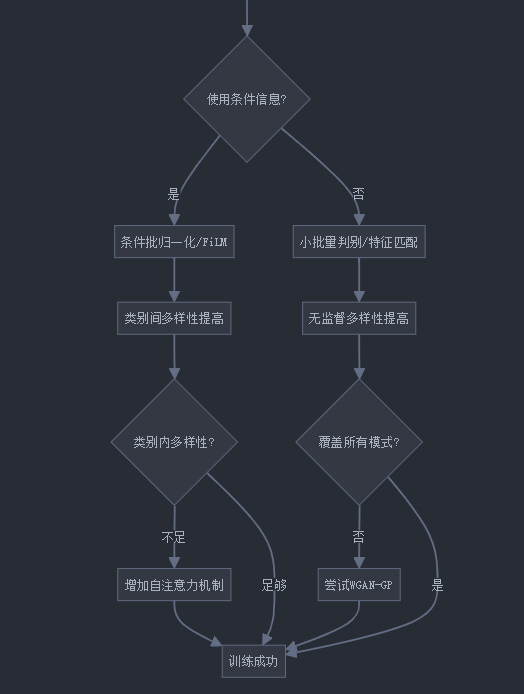
4. 实际应用中的模式坍塌解决方案
在实际应用中,如何根据不同场景选择合适的解决方案?以下是一份决策指南:
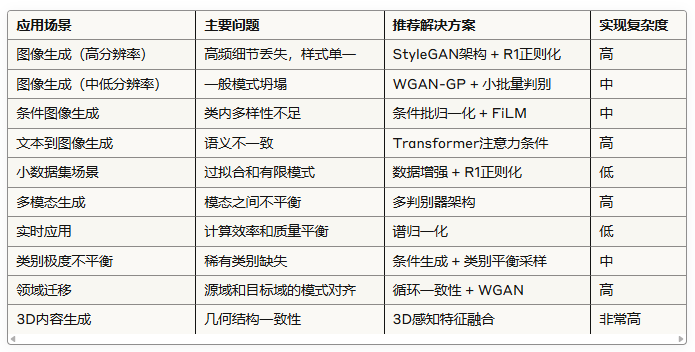
5. 模式坍塌与模型训练稳定性的关系
模式坍塌和训练稳定性紧密相关,让我们探讨它们之间的关系:
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!





