代码已开源,项目地址:https://github.com/KimMeen/Time-LLM
全文摘要
本文提出了T IME -LLM,一个将大型语言模型(LLMs)重新编程以进行时间序列预测的框架。该方法通过将时间序列数据转化为文本原型,结合Prompt-as-Prefix(PaP)技术,增强了LLMs对时间序列的推理能力。实验结果表明,T IME -LLM在多个基准测试中超越了现有的专用预测模型,尤其在少样本和零样本学习场景中表现优异,展示了LLMs在时间序列预测中的潜力。
研究背景
-
时间序列预测的重要性
- 时间序列预测在许多现实世界的动态系统中具有重要意义,应用广泛,包括需求规划、库存优化、能源负荷预测和气候建模等领域。
-
现有模型的局限性
- 目前的时间序列预测模型通常是为特定任务和领域量身定制的,缺乏通用性和灵活性。每个预测任务通常需要大量的领域专业知识和特定的模型设计,导致模型在不同任务和应用之间的迁移能力较弱。
-
大语言模型的潜力
- 尽管在自然语言处理和计算机视觉领域,大型语言模型(LLMs)已经取得了显著进展,但在时间序列领域的应用受到数据稀缺的限制。LLMs在处理复杂序列的模式识别和推理能力方面表现出色,但如何有效地将时间序列数据与自然语言对齐仍然是一个挑战。
-
数据稀缺性问题
- 当前的时间序列预测方法通常需要大量的领域内数据,而在许多实际应用中,历史数据可能非常有限。这使得现有方法在数据稀缺的情况下表现不佳。
-
推理能力的缺乏
- 现有的非LLM方法主要依赖统计模型,缺乏内在的推理能力,无法充分利用时间序列数据中的高层次概念进行准确预测。
-
多模态知识的整合
- 随着LLM架构和训练技术的进步,它们在视觉、语音和文本等多种模态中获得了更丰富的知识。如何有效地利用这些多模态知识进行时间序列预测仍然是一个未被充分探索的领域。
-
优化的复杂性
- 现有的时间序列模型通常需要大量的架构搜索和超参数调优,导致优化过程复杂且耗时。相比之下,LLMs经过一次大规模训练后,可以在不需要从头开始学习的情况下应用于预测任务。
-
研究目标
- 本文旨在通过重新编程LLMs,使其能够有效地进行时间序列预测,克服现有模型的局限性,提升时间序列预测的通用性、效率和可访问性。通过将时间序列数据转化为更适合LLMs处理的文本原型,并利用自然语言提示增强推理能力,探索LLMs在时间序列预测中的潜力。
研究方法
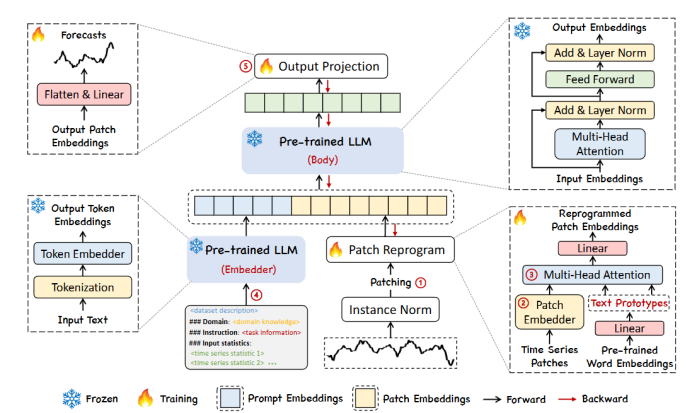
-
分片
- 输入一条历史时间序列后,将N维的时间序列划分成N个一维的时间序列,随后每个子序列单独进行处理。
-
归一化&嵌入
- 每个输入通道首先通过可逆实例归一化(RevIN)进行标准化,以消除时间序列的分布偏移。接着,时间序列被划分为多个重叠或不重叠的补丁,这些补丁被嵌入为向量表示,以便后续处理。
-
补丁重编程
- 将时间序列与自然语言进行模态对齐,将分片的嵌入向量重编译到原数据的表示空间中,以激活LLM在时序数据上的推理能力。本文在主干中使用预训练好的嵌入矩阵E进行重编译,还需要告知哪些词在目标任务中有意义的先验知识,所以需要对E做一个简单的线性变换,筛选出其中最有代表性的嵌入,得到E’
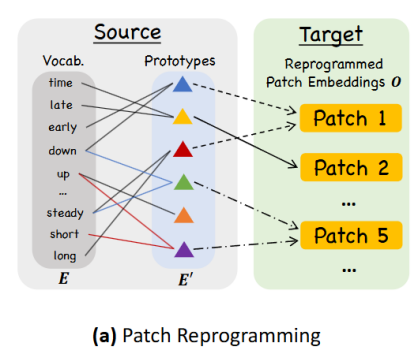

- 将时间序列与自然语言进行模态对齐,将分片的嵌入向量重编译到原数据的表示空间中,以激活LLM在时序数据上的推理能力。本文在主干中使用预训练好的嵌入矩阵E进行重编译,还需要告知哪些词在目标任务中有意义的先验知识,所以需要对E做一个简单的线性变换,筛选出其中最有代表性的嵌入,得到E’
-
Prompt-as-Prefix(PaP)
- 论文引入了“Prompt-as-Prefix”的概念,通过在输入上下文中添加额外的信息(如数据集背景、任务指令和输入统计信息),来增强模型对时间序列的推理能力。这种方法使得模型能够更好地理解输入数据的特征,并指导其进行特定任务的转换。
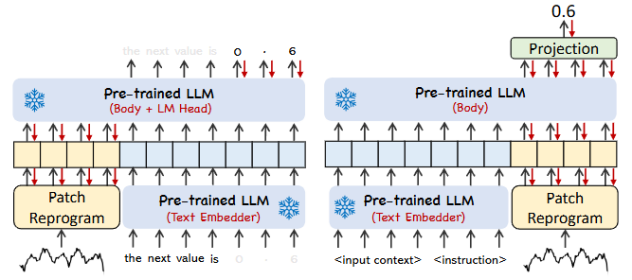
- 论文引入了“Prompt-as-Prefix”的概念,通过在输入上下文中添加额外的信息(如数据集背景、任务指令和输入统计信息),来增强模型对时间序列的推理能力。这种方法使得模型能够更好地理解输入数据的特征,并指导其进行特定任务的转换。
-
输出投影
- 在将补丁嵌入和提示信息通过冻结的LLM进行前馈处理后,模型会丢弃提示部分,获得输出表示。随后,这些输出会被展平并线性投影,以生成最终的时间序列预测。
-
模型高效性
- 该方法的一个关键优势在于,只有轻量级的输入转换和输出投影的参数会被更新,而LLM的主干模型保持不变。这种设计使得模型在进行时间序列预测时,能够在不进行大规模重新训练的情况下,快速适应新的任务和数据。
-
跨模态适应
- 论文强调了跨模态适应的重要性,通过将LLM的知识迁移到时间序列建模中,利用其在自然语言处理中的强大能力来提升时间序列预测的效果。这种方法与传统的时间序列模型相比,具有更好的通用性和灵活性。
实验结果
-
实验设置
- 长期预测:在ETTh1、ETTh2、ETTm1、ETTm2、Weather、Electricity、Traffic和ILI等八个基准数据集上进行评估。输入时间序列长度T设置为512,预测范围H为{96, 192, 336, 720}。评估指标包括均方误差(MSE)和平均绝对误差(MAE)。
- 短期预测:使用M4基准数据集,该数据集包含不同采样频率的市场数据。预测范围相对较小,设置在[6, 48]。评估指标包括对称平均绝对百分比误差(SMAPE)、平均绝对缩放误差(MASE)和整体加权平均(OWA)。
- 少量学习:评估模型在仅使用前10%训练时间步的情况下的表现,确保与其他方法的公平比较。
- 零样本学习:在跨域适应的框架下评估模型在未见过的数据集上的表现,使用长期预测协议,评估不同的跨域场景。
-
长期预测结果
- T IME -LLM在大多数情况下超越了所有基线模型,特别是在与GPT4TS和PatchTST的比较中,分别实现了12%和1.4%的MSE减少。
- 在长时间预测中,T IME -LLM在36个实例中获得了SOTA表现,显示出其作为强大时间序列预测器的潜力。
-
短期预测结果
- 在M4基准上,T IME -LLM的表现优于所有基线模型,特别是与GPT4TS相比,整体超出8.7%。
- 在与N-HiTS和PatchTST等最新模型的比较中,T IME -LLM表现出色,尤其是在M4的不同数据集上。
-
少量学习结果
- 在10%少量学习的情况下,T IME -LLM在35个案例中获得了32个SOTA表现,显示出其在数据稀缺情况下的强大能力。
- 在5%少量学习场景中,T IME -LLM同样表现优异,获得21个SOTA结果,证明了其知识激活的成功。
-
零样本学习结果
- T IME -LLM在零样本学习中表现出色,平均MSE和MAE分别减少了23.5%和12.4%。
- 在典型的跨域场景中,T IME -LLM的表现显著优于其他竞争模型,尤其是在ETTh2到ETTh1和ETTm2到ETTm1的迁移中。
-
模型分析
- 对于不同的语言模型变体,T IME -LLM在使用Llama-7B时表现最佳,显示出扩展法则在LLM重编程后的保留。
- 通过消融实验,发现去除补丁重编程或Prompt-as-Prefix会显著降低模型的知识转移能力,特别是在少量学习任务中。
-
效率比较
- T IME -LLM在训练参数数量、GPU内存消耗和训练速度方面表现出色,相比于参数高效的微调方法(如QLoRA),在多个场景中减少了71.2%的可训练参数。
通过这些实验,T IME -LLM展示了其在时间序列预测任务中的强大能力,尤其是在少量和零样本学习场景下的表现,表明其作为有效时间序列机器的潜力。

)

![[第十六届蓝桥杯 JavaB 组] 真题 + 经验分享](http://pic.xiahunao.cn/nshx/[第十六届蓝桥杯 JavaB 组] 真题 + 经验分享)


)