一、应用场景
在处理大量 PDF 文件时,可能只需要提取特定区域的信息,如合同中的关键条款、报表中的特定数据等。将这些提取的信息保存到 Excel 表格中,便于后续的数据分析、整理和存储。

界面设计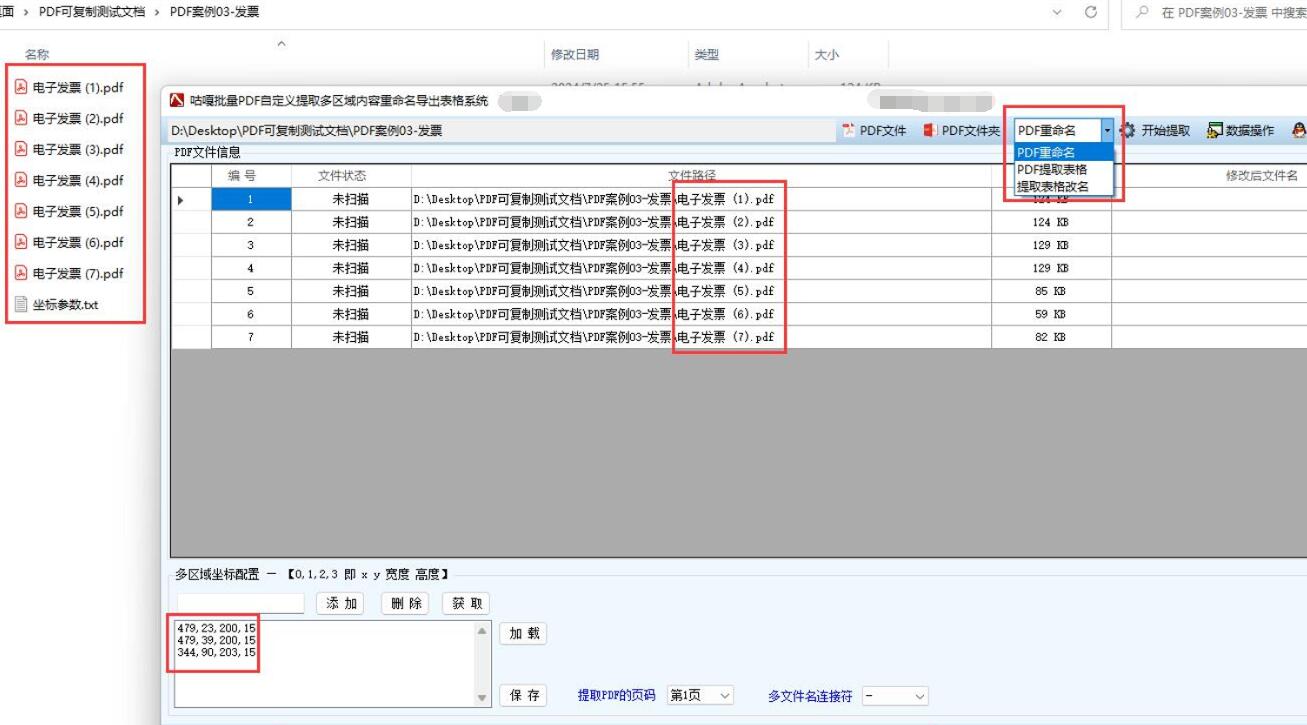
- 文件选择按钮:用于选择要处理的 PDF 文件或文件夹。
- 区域设置输入框:输入要提取内容的 PDF 页面区域位置(如左上角坐标、宽度和高度)。
- 处理按钮:点击后开始提取 PDF 指定区域的内容并保存到 Excel。
- 进度条:显示处理进度。
- 结果显示框:显示处理结果,如成功提取的文件数量、错误信息等。
详细代码步骤
步骤 1:创建 WPF 项目
在 Visual Studio 中创建一个新的 WPF 项目。
步骤 2:设计界面(MainWindow.xaml)
<Window x:Class="PdfToExcelExtractor.MainWindow"xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"Title="PDF内容提取器" Height="450" Width="800"><Grid><Button Content="选择PDF文件" HorizontalAlignment="Left" Margin="20,20,0,0" VerticalAlignment="Top" Width="150" Click="SelectPdfFiles_Click"/><Label Content="区域设置 (X, Y, Width, Height):" HorizontalAlignment="Left" Margin="20,60,0,0" VerticalAlignment="Top"/><TextBox x:Name="RegionTextBox" HorizontalAlignment="Left" Height="23" Margin="200,60,0,0" TextWrapping="Wrap" VerticalAlignment="Top" Width="200"/><Button Content="开始处理" HorizontalAlignment="Left" Margin="20,100,0,0" VerticalAlignment="Top" Width="150" Click="ProcessFiles_Click"/><ProgressBar x:Name="ProgressBar" HorizontalAlignment="Left" Height="20" Margin="20,140,0,0" VerticalAlignment="Top" Width="740"/><TextBox x:Name="ResultTextBox" HorizontalAlignment="Left" Height="250" Margin="20,180,0,0" TextWrapping="Wrap" VerticalAlignment="Top" Width="740" IsReadOnly="True"/></Grid>
</Window>
步骤 3:实现逻辑(MainWindow.xaml.cs)
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Windows;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
using Microsoft.Office.Interop.Excel;namespace PdfToExcelExtractor
{public partial class MainWindow : Window{private List<string> pdfFiles = new List<string>();private string regionSettings;public MainWindow(){InitializeComponent();}private void SelectPdfFiles_Click(object sender, RoutedEventArgs e){var openFileDialog = new Microsoft.Win32.OpenFileDialog();openFileDialog.Multiselect = true;openFileDialog.Filter = "PDF Files (*.pdf)|*.pdf";if (openFileDialog.ShowDialog() == true){pdfFiles = openFileDialog.FileNames.ToList();ResultTextBox.Text = $"已选择 {pdfFiles.Count} 个PDF文件。";}}private void ProcessFiles_Click(object sender, RoutedEventArgs e){regionSettings = RegionTextBox.Text;if (pdfFiles.Count == 0){MessageBox.Show("请先选择PDF文件。");return;}if (string.IsNullOrEmpty(regionSettings)){MessageBox.Show("请输入区域设置。");return;}var region = ParseRegion(regionSettings);if (region == null){MessageBox.Show("区域设置格式错误,请输入 X, Y, Width, Height。");return;}var excelApp = new Application();var workbook = excelApp.Workbooks.Add();var worksheet = workbook.ActiveSheet;int row = 1;foreach (var pdfFile in pdfFiles){try{var content = ExtractPdfContent(pdfFile, region.Value);worksheet.Cells[row, 1] = Path.GetFileName(pdfFile);worksheet.Cells[row, 2] = content;row++;ProgressBar.Value = (double)pdfFiles.IndexOf(pdfFile) / pdfFiles.Count * 100;}catch (Exception ex){ResultTextBox.Text += $"\n处理 {pdfFile} 时出错: {ex.Message}";}}workbook.SaveAs("ExtractedContent.xlsx");workbook.Close();excelApp.Quit();ResultTextBox.Text += "\n处理完成,结果已保存到 ExtractedContent.xlsx。";}private System.Drawing.Rectangle? ParseRegion(string settings){var parts = settings.Split(',');if (parts.Length == 4 && int.TryParse(parts[0], out int x) && int.TryParse(parts[1], out int y) &&int.TryParse(parts[2], out int width) && int.TryParse(parts[3], out int height)){return new System.Drawing.Rectangle(x, y, width, height);}return null;}private string ExtractPdfContent(string pdfFile, System.Drawing.Rectangle region){using (var reader = new PdfReader(pdfFile)){var page = reader.GetPageN(1);var strategy = new RegionTextRenderFilter(region);var renderListener = new FilteredTextRenderListener(new LocationTextExtractionStrategy(), strategy);return PdfTextExtractor.GetTextFromPage(reader, 1, renderListener);}}}
}
总结优化
- 性能优化:处理大量 PDF 文件时,可考虑使用多线程并行处理,提高处理速度。
- 错误处理:目前的错误处理比较简单,可进一步细化,如处理 PDF 文件损坏、Excel 保存失败等情况。
- 界面优化:可以添加更多的交互提示,如鼠标悬停提示、进度条动画等,提升用户体验。
- 功能扩展:支持选择多个页面、提取多个区域的内容,以及自定义 Excel 表格的格式和布局。
注意事项
- 此代码依赖于
iTextSharp和Microsoft.Office.Interop.Excel库,需要在项目中添加相应的引用。 - 运行代码前,请确保系统中安装了 Microsoft Excel,因为使用了
Microsoft.Office.Interop.Excel进行 Excel 文件的操作。
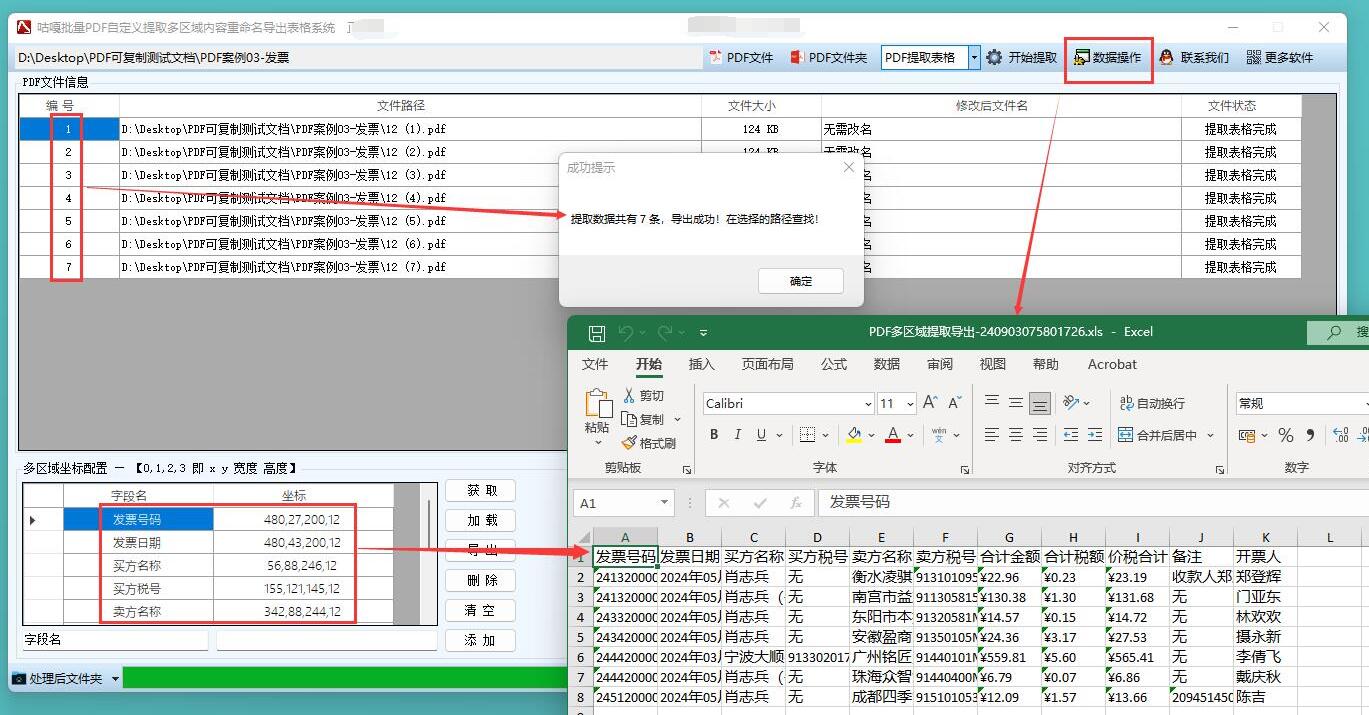
以上代码和方案可以帮助你实现批量提取 PDF 页面指定区域位置的内容,并保存到 Excel 表格的功能。






