本系列笔记为博主学习李超老师课程的课堂笔记,仅供参阅
课程传送门:音视频小白系统入门课 音视频基础+ffmpeg原理
往期课程笔记传送门:
- 音视频小白系统入门笔记-0
- 音视频小白系统入门笔记-1
课程实践代码仓库:传送门
音视频编解码
可以通过ffmpeg -f avfoundation -list_devices true -i "" 查看Mac设备支持的设备编号
编解码器
上下行网络一般是非对称的(下行带宽一般更大,因为大多数终端都是拉取数据)
压缩-质量 trade off
压缩方法:
-
消除冗余信息:有损压缩
-
剔除人类听觉范围外的音频 (20Hz-20kHz)
-
被遮蔽的音频信号(心理声学模型)
-
频域遮蔽
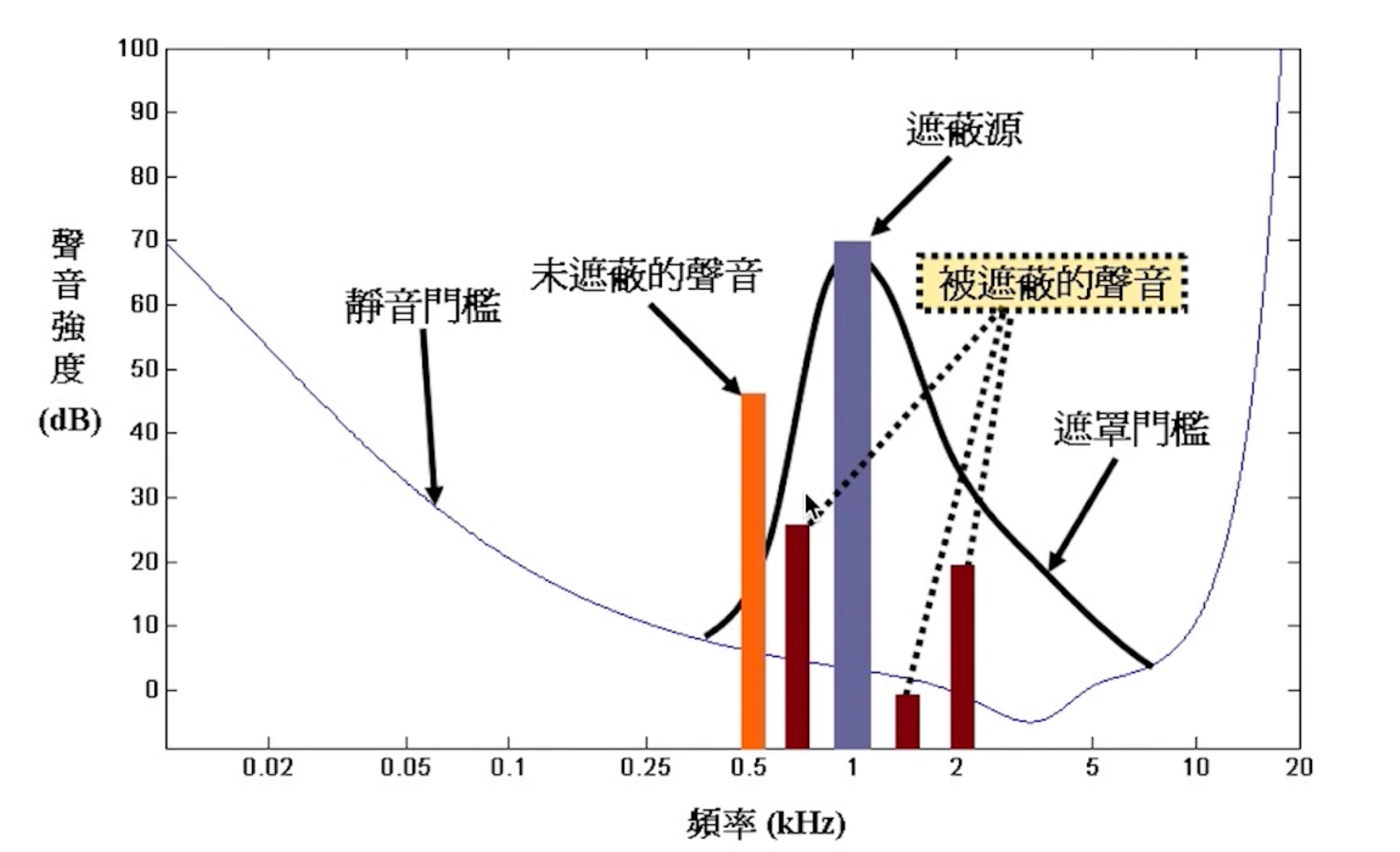
-
时域遮蔽
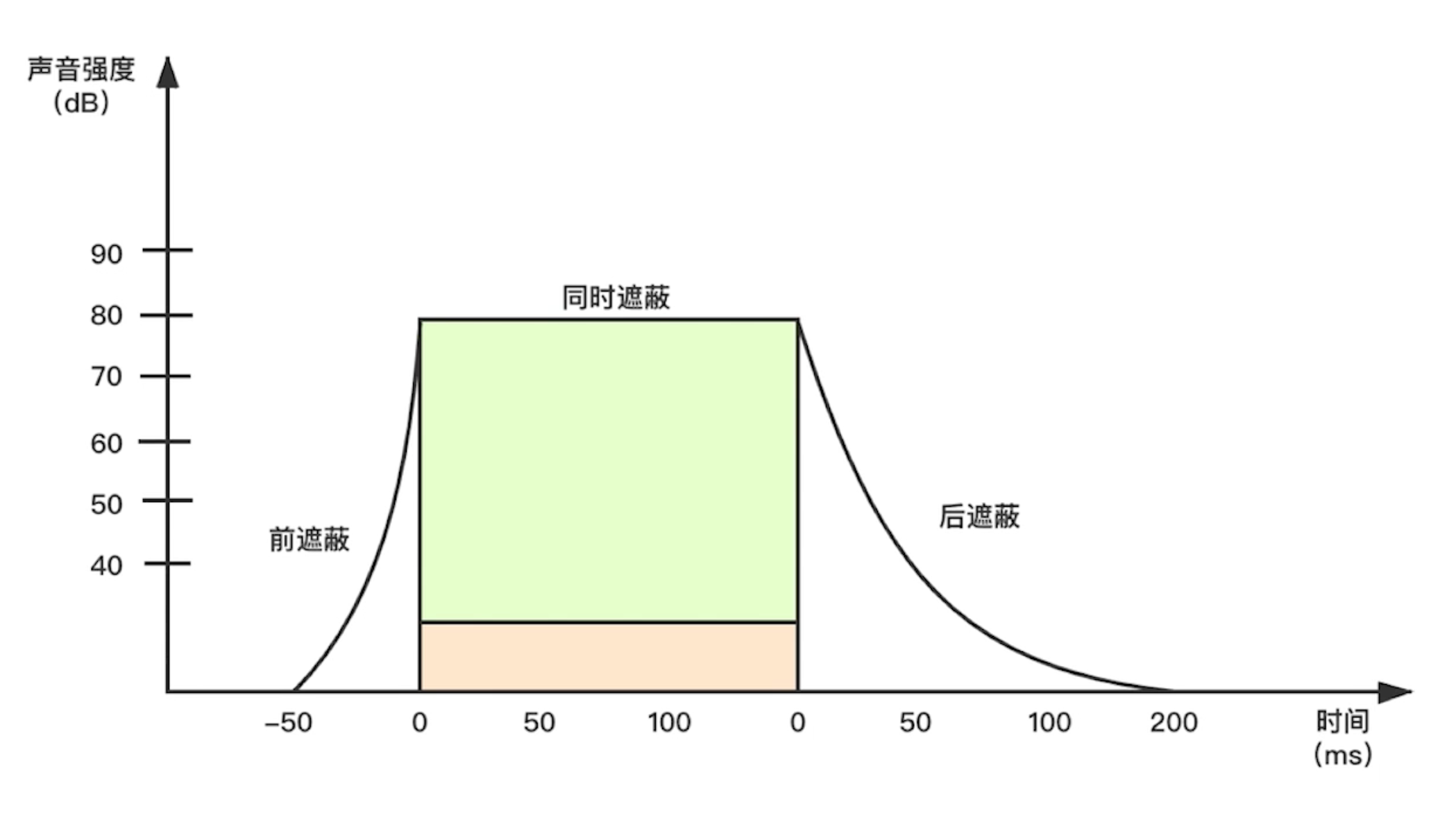
-
-
-
无损压缩:熵编码
- 哈夫曼编码
- 算数编码
- 香农编码
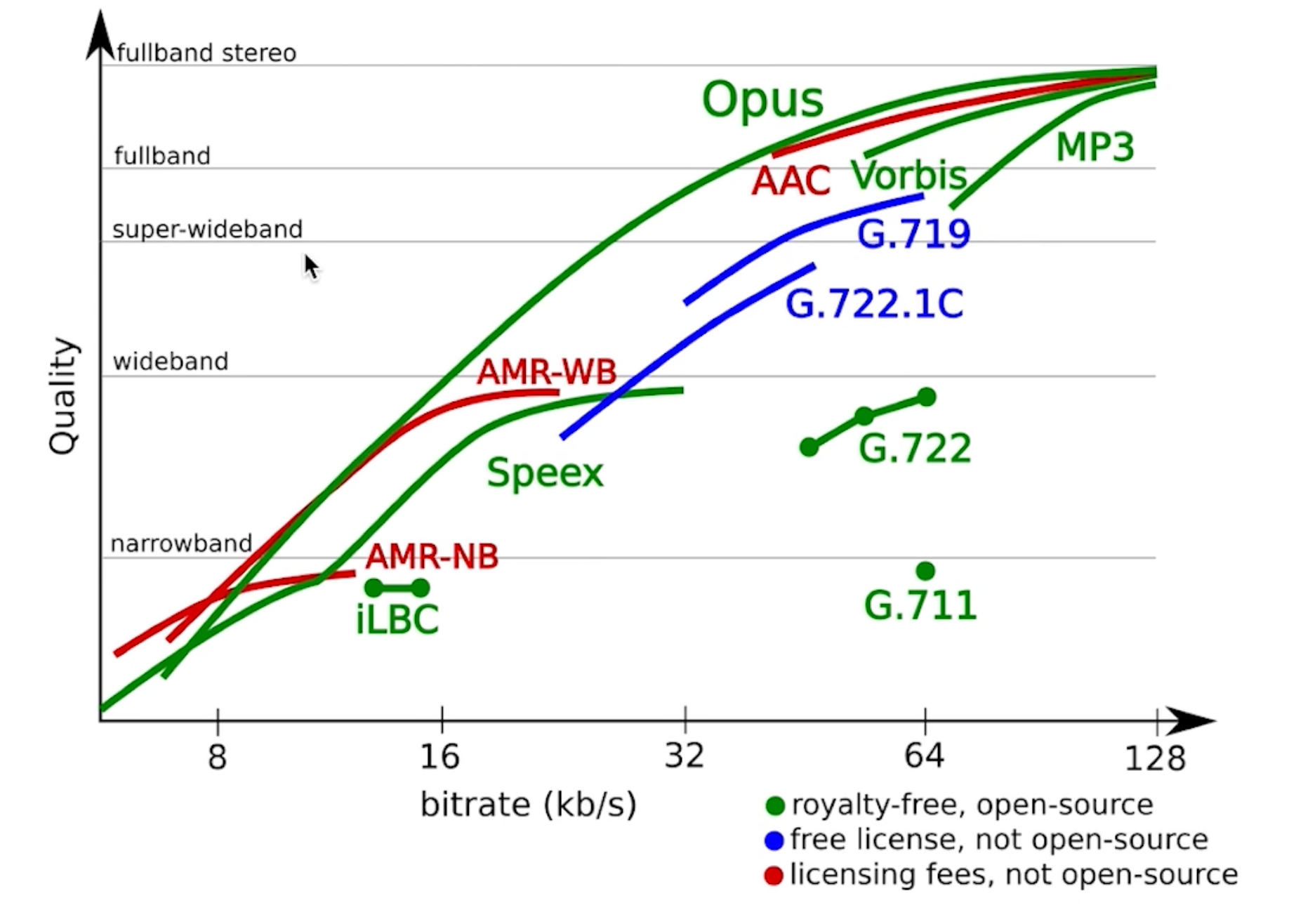
常见的音频编解码器:
- OPUS:新兴、延迟小、压缩率高,WebRTC
- AAC:应用广泛,支持好,取代mp3
- Ogg:收费
- Speex:混音消除,以前流行
- G.711:窄带音频,固定电话,声音损耗严重
压缩效果:OPUS > AAC > Ogg
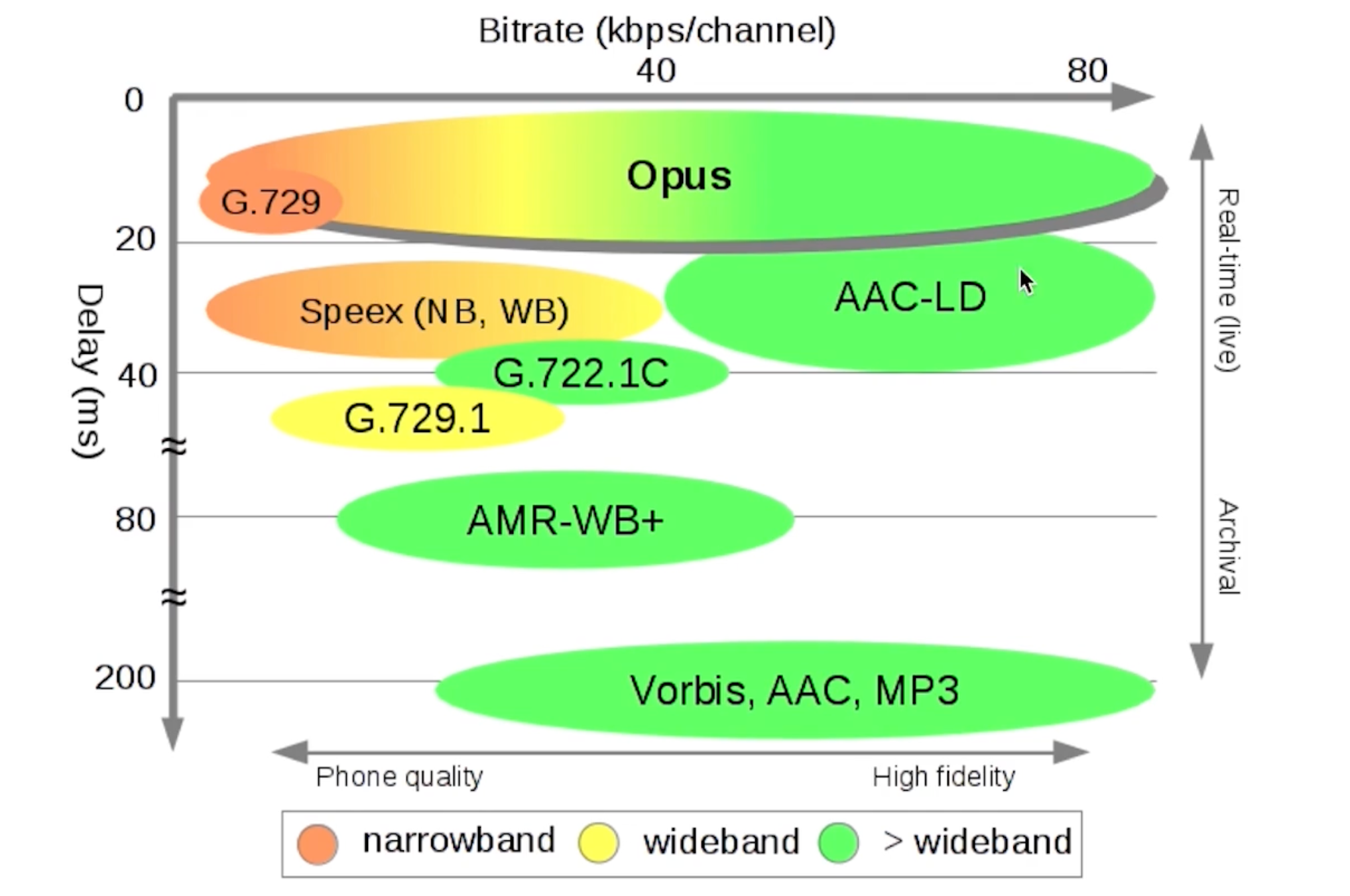
AAC编解码器:
- AAC LC(基础,128k)
- AAC HE V1(废弃,按64k左右)+ SBR技术,按频谱分开保存
- AAC HE V2(添加新技术)+ PS技术,多声道差异保存
AAC格式:
- ADIF(Audio Data Interchange Format):从头解码,多用在磁盘文件
- ADTS(Audio Data Transport Stream):每一帧有一个同步字,大一些,可以在音频流的任意位置解码
ADTS结构:7/9个字节,2字节CRC校验

Audio Object Types:
1 AAC Main
2 AAC LC
5 SBR : AAC HE V1
29 PS:AAC HE V2
Sampling Frequency Index:
4 44100 Hz
11 48000 HZ
ADTS头规范验证:http://p23.nl/projects/aac-header
ffmpeg -i demo.mp3 -vn -c:a libfdk_aac -ar 44100 -channel_layout mono/stereo -profile:a aac_he_v2 demo_mp3.aac-i指定输入源-vn过滤视频-c:a libfdk_aaccodec:audio 音频编码器指定为fdk_aac-ar 44100采样率44.1kHz-channel_layout stereo立体声采样-profile:a aac_he_v2设置音频编码格式
为了支持libfdk_aac库,对于brew安装的ffmpeg需要使用homebrew-ffmpeg第三方库安装支持fdk-aac的版本;对于源码安装的ffmpeg,需要在configure时打开libfdk-aac选项重新编译
音频重采样:转换音频三元组(采样率、位深/采样大小、通道数)
什么是重采样?
- 目标:将音频从一种采样格式(如
48000Hz F32LE 单声道)转换为另一种(如44100Hz S16LE 单声道)。 - 关键操作:
- 采样率转换(如 48kHz → 44.1kHz):通过插值/抽取算法(如线性插值、sinc 滤波)调整样本数量。
- 格式转换(如
F32LE→S16LE):量化位深,可能涉及缩放(如float [-1,1]→int16 [-32768,32767])。 - 声道布局调整(如 立体声 → 单声道):混合或选择声道。
为什么要重采样:
- 音频设备采集数据与编码器要求数据不一致
- 扬声器要求的音频数据和播放数据不一致
- 方便运算:混音消除等场景使用单声道会方便运算
如何知道对应设备要求的规格?
- 了解音频设备的参数
- 查看ffmpeg的源码
为什么不把swr_init合并到swr_alloc_set_opts2中?
(1) 灵活性:允许动态修改配置- 用户可能在 `alloc` 后需要 调整参数(例如根据实际输入动态修改声道布局),再调用 `swr_init()`。如果合并,每次修改都要重新分配内存,效率更低。(2) 延迟初始化:节省资源- 某些场景下,`SwrContext` 可能被创建但 不立即使用(如预初始化一组转换器)。合并会导致无用的计算(如滤波器系数)提前执行。(3) 错误处理的清晰性- 分离设计允许:- 先检查 `alloc` 是否成功(内存分配问题)。- 再检查 `init` 是否成功(参数兼容性问题)。合并后难以区分错误类型。
为什么可以逐帧处理?
- 状态保持:`SwrContext` 内部会缓存部分样本,处理跨帧的连续性(例如 48kHz → 44.1kHz 时,一帧输入可能对应不完整输出帧)。
- 增量处理:每次调用 `swr_convert()` 时:- 输入:当前帧的音频数据(如 `2048字节 F32LE`)。- 输出:尽可能多的重采样后数据(可能比输入少/多,取决于采样率比)。- 剩余未处理的样本会暂存在 `SwrContext` 中,等待下一帧输入。
nb_sample 的作用
(1)定义- `nb_sample` 表示 单次处理的音频样本数(注意是“样本数”而非“字节数”)。- 例如:若音频是单声道 `F32LE`(每个样本占4字节),`2048字节` 对应 `2048 / 4 = 512` 个样本,此时 `nb_sample = 512`。
- 它决定了每次调用 `swr_convert()` 时,输入/输出缓冲区的有效数据量。(2)为什么需要它?- 分块处理:音频数据通常是流式分块传输的(比如每次从设备读取一帧),`nb_sample` 告诉重采样器当前块有多少有效样本需要处理。
- 缓冲区管理:输入/输出缓冲区需要预分配足够空间,`nb_sample` 用于计算缓冲区大小(如 `av_samples_alloc_array_and_samples()`)。
为什么 swr_src_data 是 uint8_t**(二级指针)?
根本原因:FFmpeg 对多声道音频的通用设计FFmpeg 的音频处理 API(如 `swr_convert`、`av_samples_alloc_array_and_samples`)需要兼容 多声道音频的平面(Planar)存储格式。对于多声道音频(如立体声、5.1声道),数据可能按以下两种方式存储:- 交错(Interleaved):`[LRLRLR...]`(左右声道数据交替排列)
- 平面(Planar):`[LLLL...]` + `[RRRR...]`(每个声道单独连续存储)**内存布局示例**假设立体声(2声道)音频:- **Planar 模式**:```cswr_src_data[0] = 左声道数据指针 (LLLL...)swr_src_data[1] = 右声道数据指针 (RRRR...)```- **Interleaved 模式**:```cswr_src_data[0] = 所有声道交织数据指针 (LRLRLR...)swr_src_data[1] = NULL (未使用)```
AAC 编码器的输入要求
AAC 编码器(如 `libfdk_aac` 或 FFmpeg 内置的 `aac`)通常支持以下格式:**采样格式(Sample Format)**:- 必须为 **`AV_SAMPLE_FMT_S16`(16位整型)** 或 **`AV_SAMPLE_FMT_FLTP`(32位浮点平面格式)**。
- 如果设备采集的是其他格式(如 `AV_SAMPLE_FMT_U8`、`AV_SAMPLE_FMT_S32`),需转换。**声道布局(Channel Layout)**:- 支持单声道(`AV_CH_LAYOUT_MONO`)或立体声(`AV_CH_LAYOUT_STEREO`)。
- 若设备采集的是多声道(如5.1),需降混(Downmix)或明确编码器是否支持。**采样率(Sample Rate)**:- 常见支持 16kHz、32kHz、44.1kHz、48kHz。
- 若设备采集的采样率不匹配(如8kHz),需重采样。
AVFrame:编码前的数据
AVPacket:编码后的数据
调用libfdk_aac编码时运行报错:
[libfdk_aac @ 0x138e82c90] frame_size (2048) was not respected for a non-last frame
avcodec_send_frame error -22: Invalid argument
经过查阅资料发现,libfkd-aac编码器对每次发送帧的采样数有要求:
- 单通道:必须是2048个采样
- 双通道:必须是1024个采样
前两帧和最后一帧可以不满足条件。我们音频设备采集的一帧数据经过重采样转换往往不满足条件,因此必须做一定的缓冲处理。
Swift调用C++:https://juejin.cn/post/7265999062242033724
)
)


)
