系统环境及配置
| 系统环境 | 物理机/虚拟机/云/容器 | 虚拟机 |
| 网络环境 | 外网/私有网络/无网络 | 私有网络 |
| 硬件环境 | 机型 | KVM Virtual Machine |
| 处理器 | Kunpeng-920 |
| 内存 | 32 GiB |
| 整机类型/架构 | arm64 |
| 固件版本 | EFI Development Kit II / OVMF |
| 软件环境 | 具体操作系统版本 | 银河麒麟高级服务器操作系统 Kylin Linux Advanced Server release V10 (Halberd) |
| 内核版本 | 4.19.90-89.11.v2401.ky10.aarch64 |
现象描述
服务器磁盘变成只读,vda磁盘挂载到/data磁盘变只读,/data目录无法创建文件,需要分析EXT4文件系统变为只读原因。
分析过程
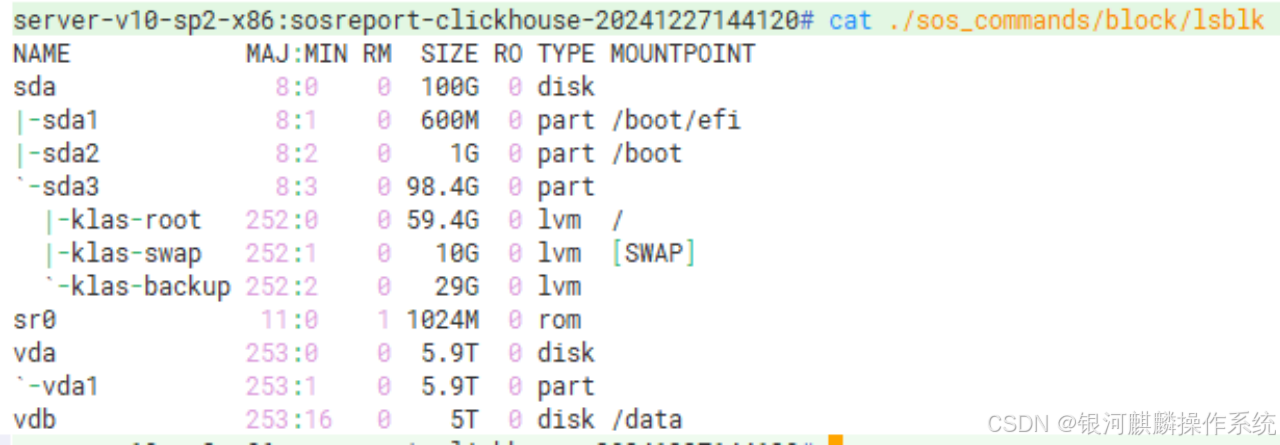
查看系统存储情况,如下图所示:
查看var/log/messages-20241212日志,在12月10日 11:45:56,vda1出现I/O错误。
| Dec 10 11:45:56 clickhouse kernel: [ 3541.839637] print_req_error: I/O error, dev vda, sector 6287898104
Dec 10 11:45:56 clickhouse rasdaemon[969]: rasdaemon: diskerror_eventstore: 0xaaada9e69ff8
// 由于发生了I/O错误,EXT4文件系统中止了其日志操作。日志是EXT4保证文件系统一致性的关键机制,中止日志意味着文件系统可能处于不一致状态。
Dec 10 11:45:56 clickhouse kernel: [ 3541.839790] Aborting journal on device vda1-8.
Dec 10 11:45:56 clickhouse rasdaemon[969]: rasdaemon: register inserted at db
Dec 10 11:45:56 clickhouse rasdaemon[969]: <idle>-0 [001] 0.000354: block_rq_complete: 2024-12-10 11:45:56 +0800 253:0 WS () 6287898104 + 8 [I/O error]
// 进一步确认了日志被中止
Dec 10 11:45:56 clickhouse kernel: [ 3541.916239] EXT4-fs error (device vda1): ext4_journal_check_start:61: comm ext4lazyinit: Detected aborted journal
// 为了防止进一步的数据损坏,内核将文件系统/dev/vda1重新挂载为只读模式。
Dec 10 11:45:56 clickhouse kernel: [ 3541.919341] EXT4-fs (): Remounting filesystem read-only |
在Dec 11 10:06:01, Dec 11 10:09:49, Dec 11 10:19:34这三个时间点,尝试重新挂载失败。
| //试重新挂载文件系统/dev/vda1为读写模式,但由于底层仍然存在问题,挂载操作被用户强制中止。这表明问题并没有自动恢复。
Dec 11 10:06:01 clickhouse kernel: [83947.454615] EXT4-fs error (device vda1): ext4_remount:5643: comm mount: Abort forced by user
Dec 11 10:09:49 clickhouse kernel: [84175.222579] EXT4-fs error (device vda1): ext4_remount:5643: comm mount: Abort forced by user
Dec 11 10:19:34 clickhouse kernel: [84759.838210] EXT4-fs error (device vda1): ext4_remount:5643: comm mount: Abort forced by user
//EXT4记录了自上次文件系统检查 (fsck) 以来发生的错误数量为4
Dec 12 10:36:57 clickhouse kernel: [ 310.239571] EXT4-fs (vda1): error count since last fsck: 4
// initial error at time ...和last error at time ...: 记录了首次和最后一次错误的时间戳,与之前的日志记录一致
Dec 12 10:36:57 clickhouse kernel: [ 310.239603] EXT4-fs (vda1): initial error at time 1733802356: ext4_journal_check_start:61
Dec 12 10:36:57 clickhouse kernel: [ 310.239609] EXT4-fs (vda1): last error at time 1733883574: ext4_remount:5643 |
查看var/log/messages-20241214日志,在12月12日 14:06:33第二个磁盘vdb出现I/O错误。
| Dec 12 14:06:33 clickhouse kernel: [ 216.739315] print_req_error: I/O error, dev vdb, sector 7067803944
// 在尝试写入数据到/dev/vdb上的多个inode时发生了I/O错误。这表明写操作失败,可能会导致数据丢失或损坏。
Dec 12 14:06:33 clickhouse kernel: [ 216.739340] EXT4-fs warning (device ): ext4_end_bio:325: I/O error 10 writing to inode 110434210 (offset 0 size 0 starting block 883475494)
... (大量的 ext4_end_bio 错误) ...
Dec 12 14:06:33 rasdaemon[968]: rasdaemon: diskerror_eventstore: 0xaaae75459ff8
// JBD2是EXT4的日志组件,表明在刷新数据到磁盘时也遇到了I/O错误。
Dec 12 14:06:33 kernel: [ 216.780921] JBD2: Detected IO errors while flushing file data on vdb-8 |
分析以上日志,可以得出以下结论:
问题根源是底层存储的I/O错误,print_req_error和rasdaemon的报警都指向了底层的硬件或存储层面的问题,而且/dev/vda1和/dev/vdb都出现了I/O错误,说明不是单个磁盘或文件系统的问题。
文件系统损坏是I/O错误的直接结果,由于底层存储无法正常工作,导致EXT4文件系统的日志无法正常写入,最终导致日志中止和文件系统被标记为只读。ext4_journal_check_start和ext4_end_bio的错误信息也证实了这一点。
分析结论
综合分析,虚拟机系统内部原因可能性很低,虽然虚拟机内部的驱动程序错误或配置问题可能导致I/O问题,但同时影响到两个不同的虚拟磁盘,并且有print_req_error和rasdaemon的硬件错误报告,这种可能性非常之低。虚拟机环境底层的存储资源是由云平台或宿主机提供的,以下两种情况的可能性最高:
- 宿主机存储或者存储网络等硬件可能存在故障或性能问题,导致提供给虚拟机的虚拟磁盘出现I/O错误。
- 云平台的存储服务可能存在问题,导致虚拟机的存储访问出现问题。
解决方案
根据提供的日志分析,虚拟机EXT4文件系统损坏的主要原因是底层存储的 I/O 错误。问题很可能出在宿主机的硬件层面或者云平台的存储服务上,需要进一步排查底层存储问题。



启动参数及其规则详解)


