From:https://www.big-yellow-j.top/posts/2025/04/28/QwenVL.html
本文主要介绍Qwen-vl系列模型包括:Qwen2-vl、Qwen2.5-vl
Qwen2-vl
http://arxiv.org/abs/2409.12191
模型结构:
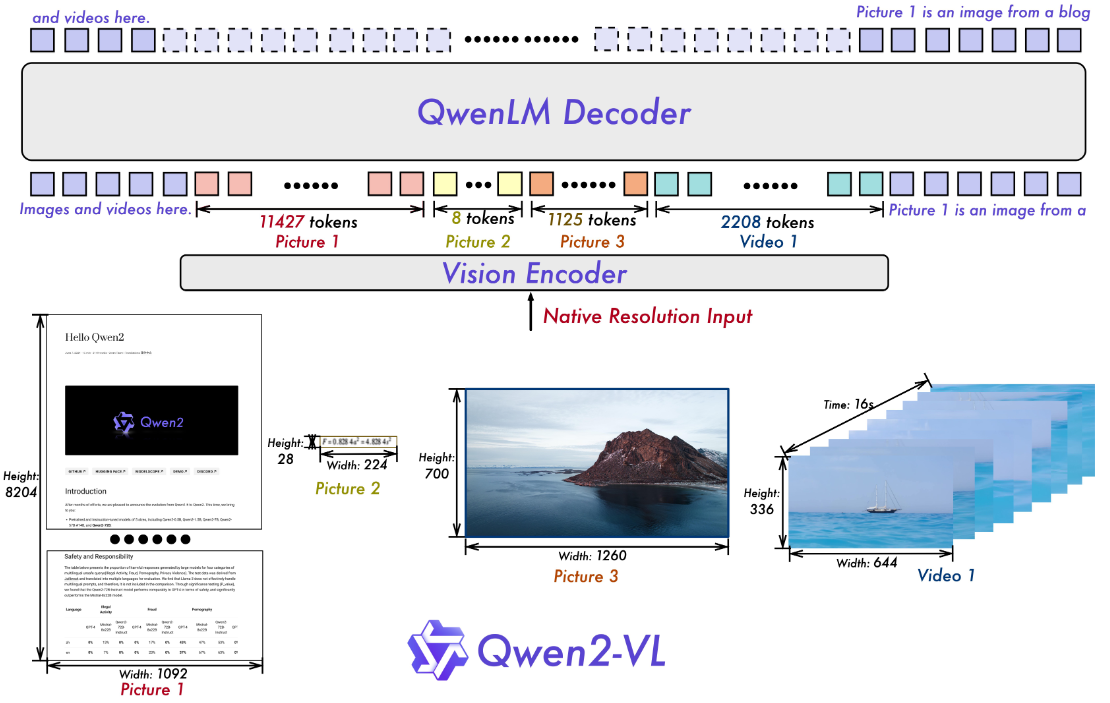
Qwen2-vl主要的改进点在于:1、使用动态分辨率(也就是说输入图像不需要再去改变图像尺寸到一个固定值),于此同时为了减少 visual-token数量,将2x2的的相邻的token进行拼接到一个token而后通过MLP层进行处理。2、使用多模态的旋转位置编码(M-RoPE),也就是将原来位置编码所携带的信息处理为:时序(temporal)、高度(height)、宽度(width)。比如下图中对于文本处理直接初始化为: ( i , i , i ) (i,i,i) (i,i,i)。但是对于图片而言就是: ( i , x , y ) (i,x,y) (i,x,y) 其中 i i i 是恒定的,而对于视频就会将 i i i 换成视频中图像的顺序

Qwen2.5-vl
http://arxiv.org/abs/2502.13923
模型结构:
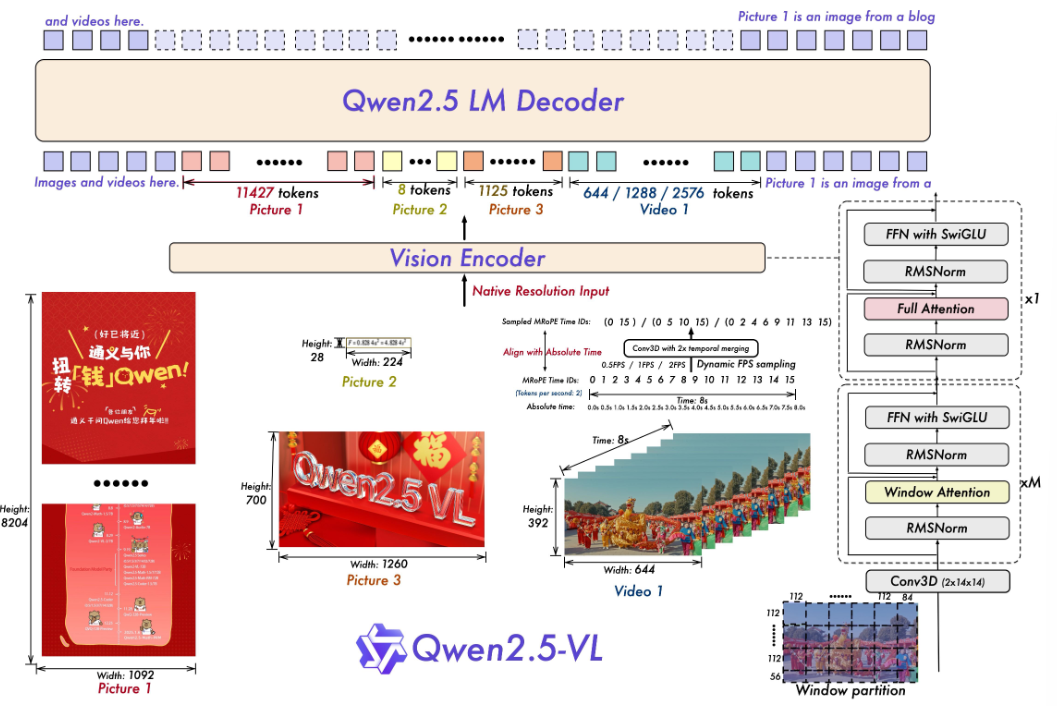
从模型结构上而言在 Qwen2.5-vl 中主要改进点在于:
- 视觉编码器上
1、改进的ViT模型(window-attention+ full-attention);2、2D-RoPE
- MLP处理
通过ViT得到所有的patch之后,直接将这些patch解析分组(4个一组)然后继续拼接在输入到两层MLP中进行处理
补充1:window-attention
https://arxiv.org/abs/2004.05150v2
前面有介绍在Kimi和DeepSeek中如何处理稀疏注意力的(🔗),他们都是通过额外的网络结构来处理注意力计算问题,而在上面提到的注意力计算则是直接通过规则范式计算注意力。
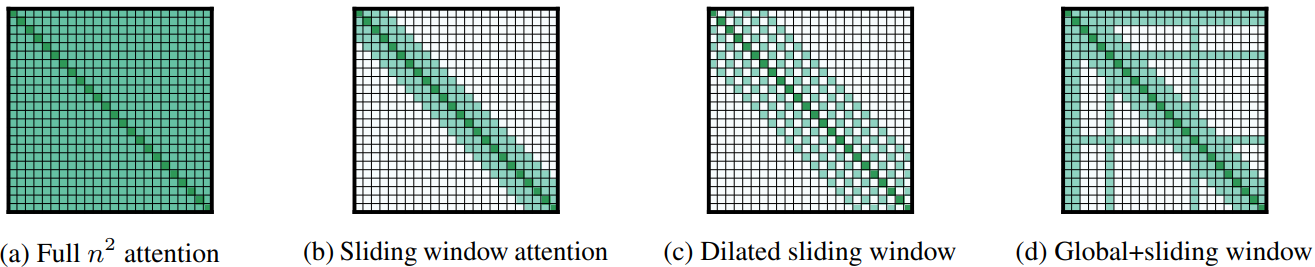
上面 window-attention 处理范式就和卷积操作类似,直接通过移动“步长”然后对“采集”得到的内容进行计算注意力。代码:⚙。代码核心点就在于划分,而后对划分结果计算注意力:
q_window = q[:, :, t:window_end, :] # (B, num_heads, window_size, head_dim)
k_window = k[:, :, t:window_end, :]
v_window = v[:, :, t:window_end, :]
介绍完这部分有必要了解一下他是如何处理数据的(毕竟说实在话,模型(无论为LLM还是MLLM在结构上创新远不如数据集重要)都是数据驱动的)以及他是如何训练模型的。
- 1、模型预训练
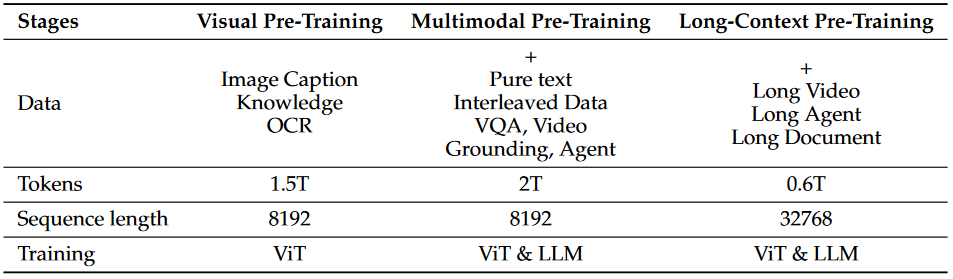
从论文里面作者提到如下几种数据以及处理范式如下:
1、Image-Text Data(图片-文本匹配数据集):保留较高评分匹配对(这里也就是说文本对于图片描述要丰富)、信息互补(图像和文本各自提供独特信息)、信息密度平衡
2、Video Data(视频数据):首先是通过动态采用方式获取视频帧;
3、图像坐标分辨率处理:直接将原始图像进行输入不去修改分辨率(固定每个patch为112x112对于不足的不去做填补,总共8x8个patches),对于里面的坐标直接使用Grounding DINO 或者SAM进行获取。
4、Omni-Parsing Data:对于文档数据集直接解析为html格式
-
3、模型后训练
-
1、监督微调 (SFT)
SFT阶段用到的instruction data包含约 200 万条数据,50% 为纯文本数据,50% 为多模态数据(图文和视频文本)。在数据过滤流程中,先使用 Qwen2-VL-Instag (一个基于Qwen2-VL的分类模型)将 QA 对分层分类为 8 个主要领域和 30 个细粒度子类别,然后对于这些细分类别,使用领域定制过滤,结合基于规则和基于模型的过滤方法。
基于规则的过滤: 删除重复模式、不完整或格式错误的条目,以及不相关或可能导致有害输出的查询和答案。
基于模型的过滤: 使用 Qwen2.5-VL 系列训练的奖励模型评估多模态 QA 对。
此外,在训练中还使用拒绝采样 (Rejection Sampling)技术,增强模型的推理能力。使用一个中间版本的 Qwen2.5-VL 模型,对带有标注(ground truth)的数据集生成响应,将模型生成的响应与标注的正确答案进行比较,只保留模型输出与正确答案匹配的样本,丢弃不匹配的样本。此外还进一步过滤掉不理想的输出,例如:代码切换 (code-switching)、过长 (excessive length)、重复模式 (repetitive patterns)等。通过这种方式,确保数据集中只包含高质量、准确的示例。
这里会不会因此丢弃掉一些好的困难样本?报告中并没有提及,似乎对于SFT阶段,正确性的要求压倒难度,并不指望通过这一阶段获得更强的能力。
- 2、直接偏好优化 (DPO)
报告中基本一笔带过。仅使用图文和纯文本数据,不使用视频数据,利用偏好数据将模型与人类偏好对齐。没有使用GRPO和基于规则的强化学习。对于数学、代码以外的任务,似乎没有特别好的规则定义方法,还是要回到基于奖励模型或者偏好数据的方法。
代码对比
两个模型在代码上差异:
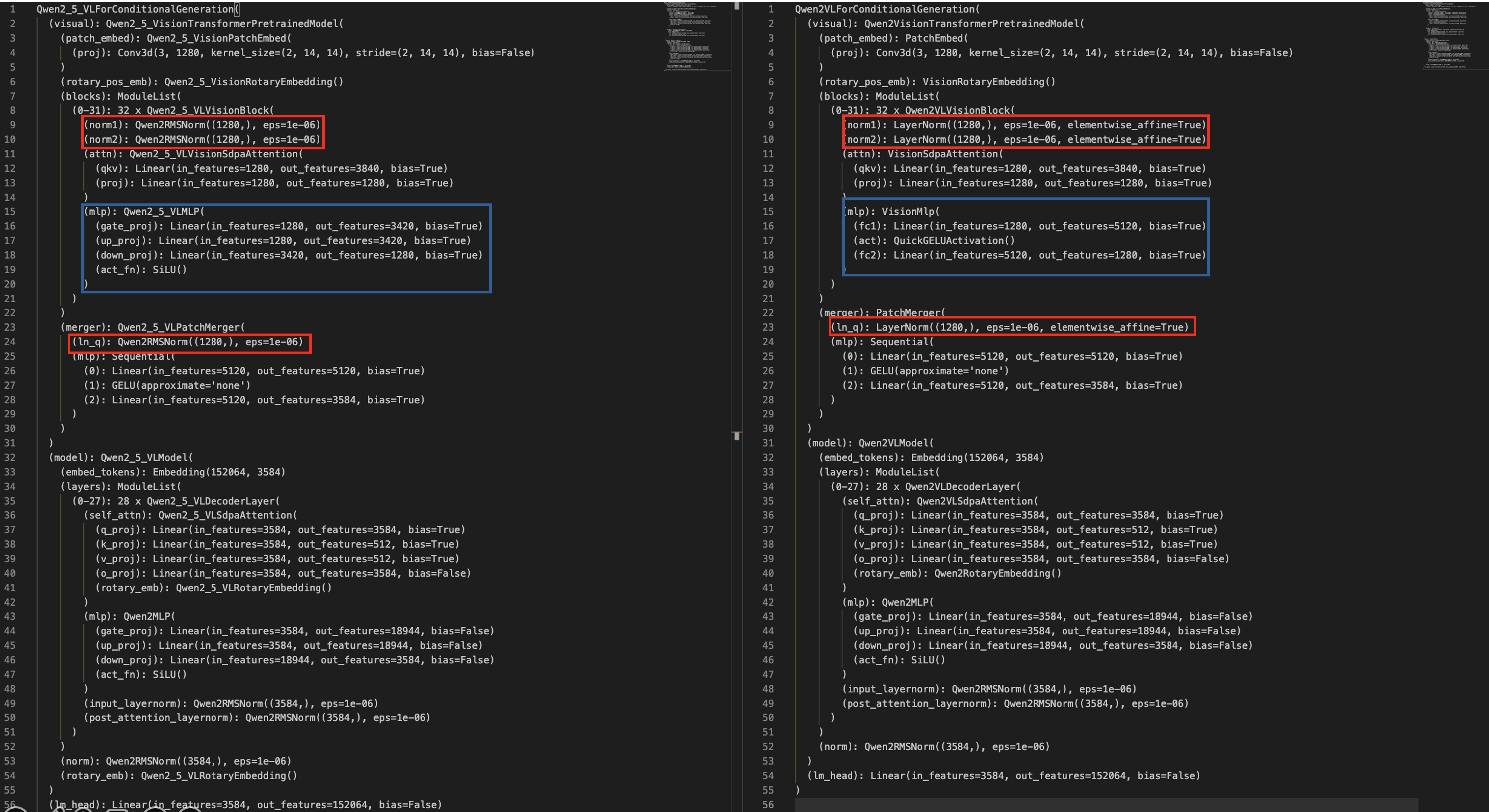
1、ViT代码
值得注意的在 Qwen2-vl中使用了拼接方式,在 Qwen2.5-vl依旧使用了这种方式来将Vit得到的token进行减少进而减小计算量。通过 Qwen2.5-vl来理解模型(Qwen2.5-vl中vit操作,代码),官方代码中划分窗口设置:
def get_window_index(self, grid_thw):window_index: list = []cu_window_seqlens: list = [0]window_index_id = 0vit_merger_window_size = self.window_size // self.spatial_merge_size // self.patch_sizefor grid_t, grid_h, grid_w in grid_thw:#(1)因为位置编码结构是t、h、w(具体描述见Qwen2-vl描述)llm_grid_h, llm_grid_w = (grid_h // self.spatial_merge_size, # spatial_merge_size:空间合并的尺寸grid_w // self.spatial_merge_size,)index = torch.arange(grid_t * llm_grid_h * llm_grid_w).reshape(grid_t, llm_grid_h, llm_grid_w)#(2)计算需要的paddingpad_h = vit_merger_window_size - llm_grid_h % vit_merger_window_sizepad_w = vit_merger_window_size - llm_grid_w % vit_merger_window_size#(3)计算padding后的窗口数量,并且用 -100 进行填补num_windows_h = (llm_grid_h + pad_h) // vit_merger_window_sizenum_windows_w = (llm_grid_w + pad_w) // vit_merger_window_sizeindex_padded = F.pad(index, (0, pad_w, 0, pad_h), "constant", -100)#(4)重塑索引为窗口形式index_padded = index_padded.reshape(grid_t,num_windows_h,vit_merger_window_size,num_windows_w,vit_merger_window_size,)index_padded = index_padded.permute(0, 1, 3, 2, 4).reshape(grid_t,num_windows_h * num_windows_w,vit_merger_window_size,vit_merger_window_size,)#(5)计算每个窗口中有效元素的数量seqlens = (index_padded != -100).sum([2, 3]).reshape(-1)index_padded = index_padded.reshape(-1)index_new = index_padded[index_padded != -100]window_index.append(index_new + window_index_id)cu_seqlens_tmp = seqlens.cumsum(0) * self.spatial_merge_unit + cu_window_seqlens[-1]# self.spatial_merge_unit = self.spatial_merge_size * self.spatial_merge_sizecu_window_seqlens.extend(cu_seqlens_tmp.tolist())window_index_id += (grid_t * llm_grid_h * llm_grid_w).item()# 合并所有的窗口索引window_index = torch.cat(window_index, dim=0)# window_index: 窗口索引;# cu_window_seqlens:每个窗口的间隔return window_index, cu_window_seqlens
争对上面代码,比如输入数据形状以及参数为:
1、grid_thw:[2,8,8];2、self.window_size = 8;3、self.spatial_merge_size=self.patch_size=2。那么每一步得到结果为:
(1)index结果为(因为要进行2x2进行合并操作):
index: tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]],[[16, 17, 18, 19],[20, 21, 22, 23],[24, 25, 26, 27],[28, 29, 30, 31]]])
(3)得到index_padded为:
index_padded: tensor([[[ 0, 1, 2, 3, -100, -100],[ 4, 5, 6, 7, -100, -100],[ 8, 9, 10, 11, -100, -100],[ 12, 13, 14, 15, -100, -100],[-100, -100, -100, -100, -100, -100],[-100, -100, -100, -100, -100, -100]],[[ 16, 17, 18, 19, -100, -100],[ 20, 21, 22, 23, -100, -100],[ 24, 25, 26, 27, -100, -100],[ 28, 29, 30, 31, -100, -100],[-100, -100, -100, -100, -100, -100],[-100, -100, -100, -100, -100, -100]]])
(5)window_size合并得到结果为:
window_index:tensor([ 0, 1, 4, 5, 2, 3, 6, 7, 8, 9, 12, 13, 10, 11, 14, 15, 16, 17,20, 21, 18, 19, 22, 23, 24, 25, 28, 29, 26, 27, 30, 31])
cu_window_seqlens:[0, 16, 32, 32, 48, 64, 64, 64, 64, 64, 80, 96, 96, 112, 128, 128, 128, 128, 128]
# 这里有重复数值,后面计算会通过 torch.unique_consecutive 去除得到:[ 0, 16, 32, 48, 64, 80, 96, 112, 128]
理解上面计算结果(处理思路和卷积神经网络很像):window_index:因为输入是 [ 2 , 8 , 8 ] [2,8,8] [2,8,8] 然后划分大小为2(self.spatial_merge_size=self.patch_size=2)就像是“卷积核”一样。因此得到序列长度就是:32(也就是0-31),其中每一个索引代表图像中的“一块”,比如说:0代表左上角2x2的区域,1:代表0右边2x2区域;cu_window_seqlens:知道每块区域索引之后还需要知道“步长”, 0 , 16 0,16 0,16 代表第一块和第二块之间间隔为16那么就可以确定有4块( 4 × 2 × 2 4\times2\times2 4×2×2 )
得到window_size之后在forward计算中:
def forward(self, hidden_states, grid_thw):hidden_states = self.patch_embed(hidden_states)...window_index, cu_window_seqlens = self.get_window_index(grid_thw)...cu_window_seqlens = torch.unique_consecutive(cu_window_seqlens)#(1)重塑窗口化特征seq_len, _ = hidden_states.size()hidden_states = hidden_states.reshape(seq_len // self.spatial_merge_unit, self.spatial_merge_unit, -1)# 按照window_size进行排序hidden_states = hidden_states[window_index, :, :]hidden_states = hidden_states.reshape(seq_len, -1)#(2)重塑位置编码rotary_pos_emb = rotary_pos_emb.reshape(seq_len // self.spatial_merge_unit, self.spatial_merge_unit, -1)rotary_pos_emb = rotary_pos_emb[window_index, :, :]rotary_pos_emb = rotary_pos_emb.reshape(seq_len, -1)emb = torch.cat((rotary_pos_emb, rotary_pos_emb), dim=-1)position_embeddings = (emb.cos(), emb.sin())#(3)计算序列长度cu_seqlens = torch.repeat_interleave(grid_thw[:, 1] * grid_thw[:, 2], grid_thw[:, 0]).cumsum(dim=0,dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32,)cu_seqlens = F.pad(cu_seqlens, (1, 0), value=0)#(4)遍历而后计算注意力for layer_num, blk in enumerate(self.blocks):if layer_num in self.fullatt_block_indexes:cu_seqlens_now = cu_seqlenselse:cu_seqlens_now = cu_window_seqlens# 计算注意力if self.gradient_checkpointing and self.training:hidden_states = self._gradient_checkpointing_func(blk.__call__, hidden_states, cu_seqlens_now, None, position_embeddings)else:hidden_states = blk(hidden_states, cu_seqlens=cu_seqlens_now, position_embeddings=position_embeddings)hidden_states =hidden_states = self.merger(hidden_states)reverse_indices = torch.argsort(window_index)hidden_states = hidden_states[reverse_indices, :]return hidden_states
其中self.merger为:
class Qwen2_5_VLPatchMerger(nn.Module):def __init__(self, dim: int, context_dim: int, spatial_merge_size: int = 2) -> None:super().__init__()self.hidden_size = context_dim * (spatial_merge_size**2)self.ln_q = Qwen2RMSNorm(context_dim, eps=1e-6)self.mlp = nn.Sequential(nn.Linear(self.hidden_size, self.hidden_size),nn.GELU(),nn.Linear(self.hidden_size, dim),)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))return x
总结上面代码过程如下:首先是将图像划分为不同patch(这里操作和常规的Vit操作没有区别)得到特征 hidden_states,而后去划分不同窗口,而这个窗口就是直接去对最开始图像所进行的(比如说图像为:2x8x8,2代表时间帧),首先计算需要合并的块的索引,而后将 hidden_states 根据这个索引进行排序,排序之后就需要对这些排序内容计算注意力即可(很像卷积操作:分块就是我们的卷积核,而cu_window_seqlens就是我们的步长)
grid_thw:[2,8,8];2、self.window_size = 8;3、self.spatial_merge_size=self.patch_size=2
2、位置编码
在Qwen2-VL中,时间方向每帧之间固定间隔 1 ,没有考虑到视频的采样率,例如四秒的视频每秒采样两帧和一秒的视频每秒采样八帧,这样总的帧数都是8,在原来这种编码方式中时间维度的编码都是1->8没有任何区别。Qwen-2.5VL在时间维度上引入了动态 FPS (每秒帧数)训练和绝对时间编码,将 mRoPE id 直接与时间流速对齐。描述原理见:https://spaces.ac.cn/archives/10040
参考
1、https://arxiv.org/abs/2004.05150v2
2、http://arxiv.org/abs/2309.16609
3、http://arxiv.org/abs/2409.12191
4、http://arxiv.org/abs/2502.13923
5、https://zhuanlan.zhihu.com/p/24986805514
6、https://qwenlm.github.io/zh/blog/qwen2.5-vl/




)
