省流 看前必读 别浪费时间 :本文只是一个记录,防止自己下次被改需求时浪费时间,在这里就随意的写了一下文章记录整个步骤,但是文章想必肯定没有对应的教程讲的详细,该文章只适合想要快速按照步骤完成一个简单的 demo 的同学,并不适合想完全掌握 yolo 的同学。
一、安装环境
前言预览:
- 环境的安装分为
anaconda、pytorch、ultralytics pytorch安装需要注意自己的显卡版本选择对应的,30、40系显卡要装cuda 11版本,16系显卡安装cuda 102版本(本文没有进行说明,可以搜搜找到适合自己显卡的版本,若是40系显卡跟着我步骤就ok)- 注意
python版本不在3.8-3.11之间则会报错(以下会有一个解决办法)
1.1 anaconda
在此建议使用Anaconda,不然本地环境配了还要换,贼麻烦,Anaconda真香,我以前是懒得用的,结果现在真香。
首先安装 Anaconda,安装完毕后直接打开,简单吧,咱们 winer 就是喜欢可视化,low 也认了,我懒。
打开后如下,然后找到 create 创建当前项目的环境:
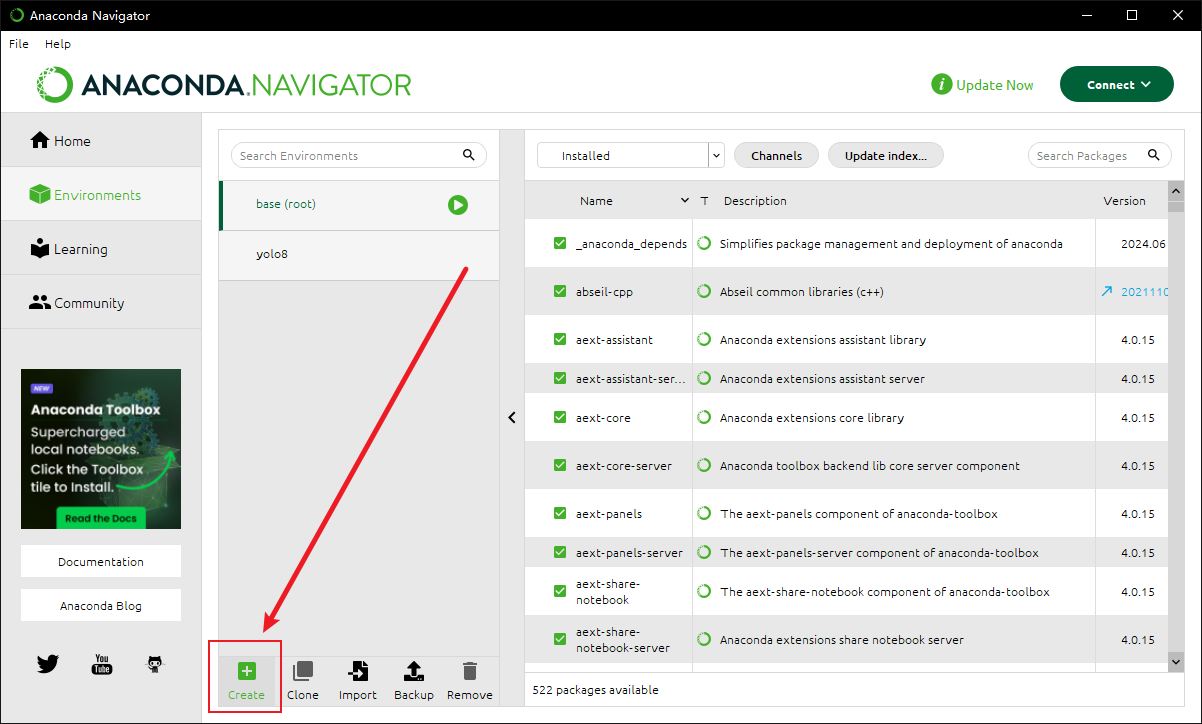
给予python对应版本号,记得有些版本不支持,我忘记了,就按照这个来吧,你可以自己搜一下会比较清楚:

1.2 pytorch
接着开始装 pytorch,地址:https://pytorch.org/get-started/locally/
截图如下:
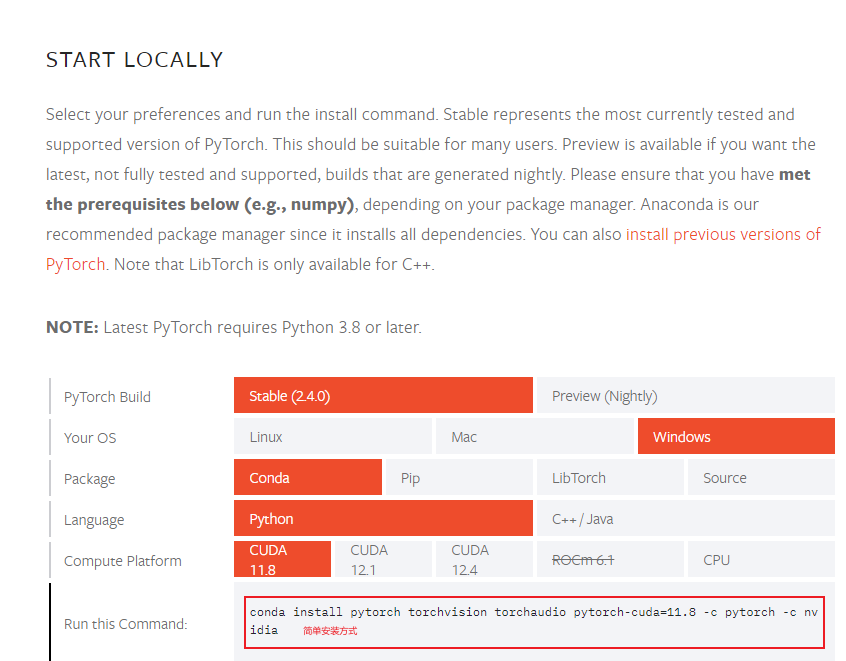
安装一些老版本会比较兼容稳定,不然太新会寄,这个我就不过多解释了,做开发的都懂:
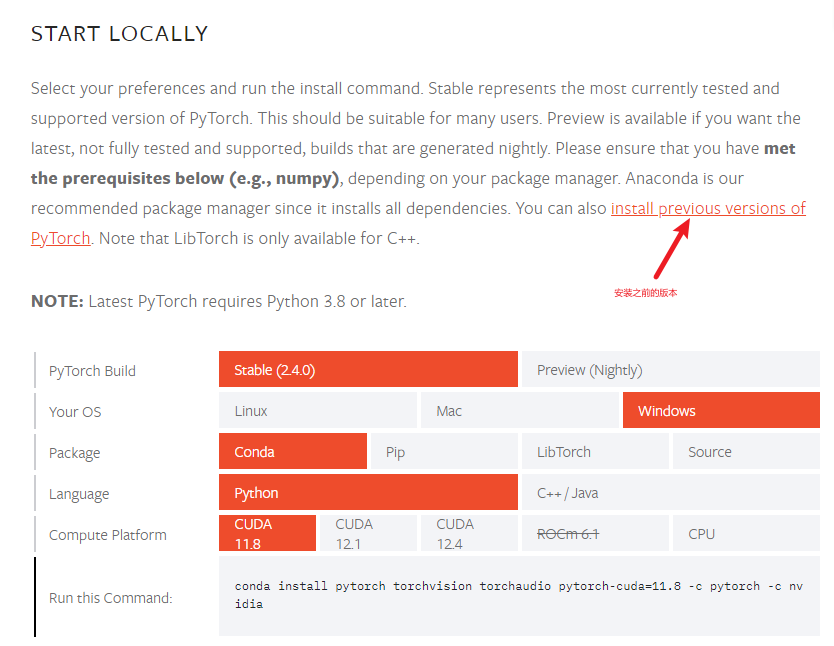
对了,这里对你的显卡啥的有版本要求,找到适合你的,我是 4060 ti ,选择了适合的版本(你可以搜,我忘记了,这篇文章就是临时做了一个小项目,顺手做个笔记,防止下次叫我改需求啥啥啥的):
这里我选择的是 cuda 11.8:
https://pytorch.org/get-started/previous-versions/
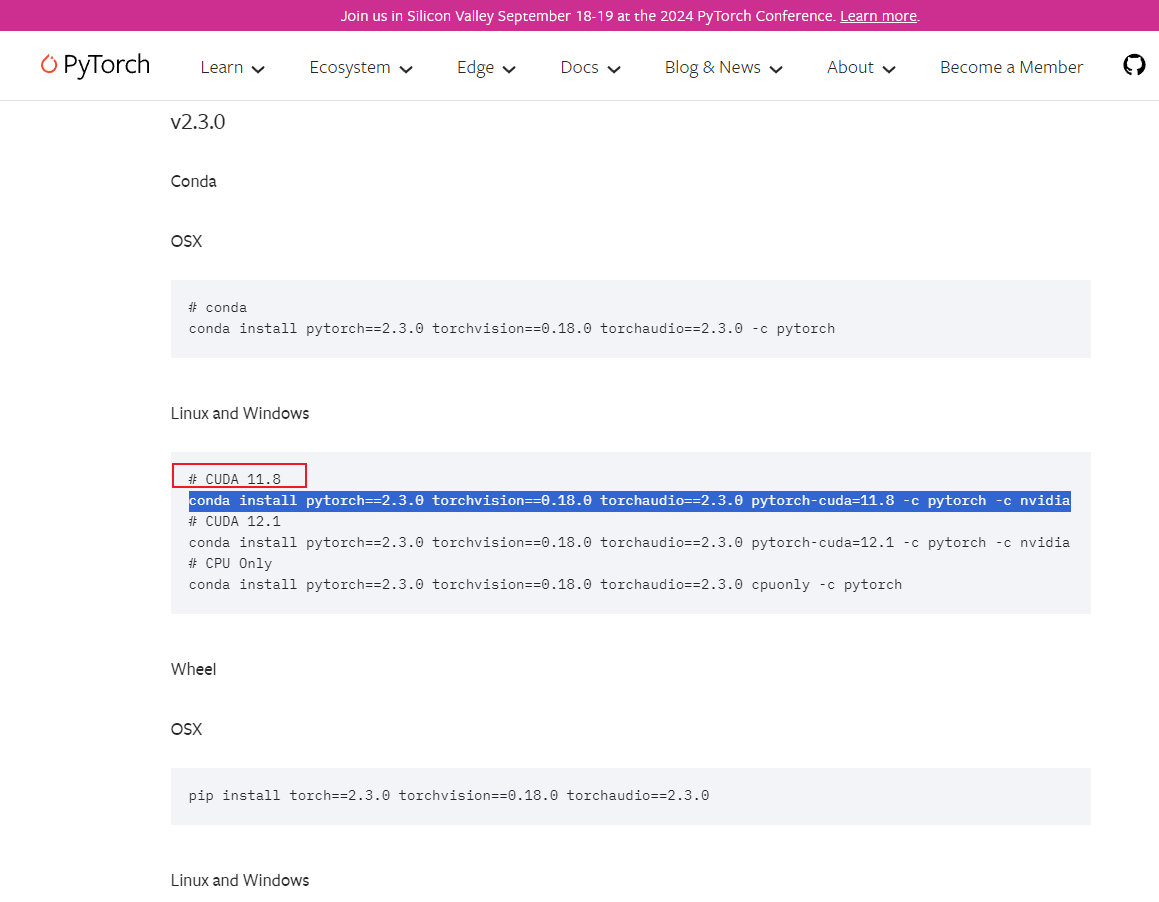
接着通过 conda 打开你的命令提示窗,就是 open Terminal:
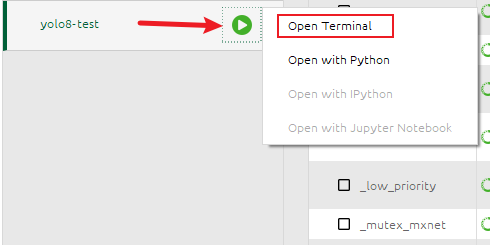
输入以下命令:
conda install pytorch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 pytorch-cuda=11.8 -c pytorch -c nvidia
复制命令,enter执行:


1.2 ultralytics
yyyyy… 后,然后安装 ultralytics:
pip install ultralytics
注意,在这几步注意你的网络,你是否设置了全局镜像源,不清楚的就切换网络试试,说不定就成了。
随后到 github 的 ultralytics 中下载那个文件,我这里直接下载了压缩包:
进入 ultralytics 解压后的文件夹 -e. 安装,注意,使用 cd 进入目录,不会的搜搜 cd 命令是干啥的用的,就是 cd 后面一个目录就进去了,进不去注意切换盘符,例如默认C盘,你进入了D盘你cd后还需要 d: 才可以(建议学学不然说不明白,从基础说起来又太多了,这里就给小白玩家一个提示。):
pip install -e .
随后就开始安装:

1.4 有报错的注意
若python版本不在3.8-3.11之间则会报错,找不到指定的模块:\site-packages\torch\lib\fbgemm.dll

解决办法:将python版本换回
在运行此命令之前尝试执行conda clean --all此操作,否则可能有缓存的原因会导致你安装不了:

安装完毕后,可以使用 yolo 命令,看看能不能用:
yolo predict model=yolov8n.pt source=ultralytics/assets/bus.jpg
以上命令是 yolo 就是表示使用 yolo ,你可以这样理解,随后 predict 表示预测,连起来就是使用 yolo 预测,model 表示选择模型是 yolov8n,.pt 就是后缀就不用理了,source 表示预测的那个图片位置,在这里选择的目录是 ultralytics/assets/ 下的 bus.jpg 文件,随后会直接进行人像的预测。
简而言之:
yolo predict model=模型选择 source=你要预测的图片
1.5 代码预测方式如下:
代码:
from ultralytics import YOLOyolo=YOLO("./yolov8n.pt",task="detect")
res=yolo(source="./ultralytics/assets/bus.jpg")
代码执行:

二、在线标注网站
2.1 导入文件
咱们在这里使用在线的标注网站,轻松方便直接标注直接使用。
打开标注网站 :
https://www.makesense.ai/
直接选择 start 开始:
把你的图片拖进来,我这里拖了51张图片:

选择目标检测 object detection:

2.2 label 标注
随后的界面会说你的当前 label 标签是空的:

点击中间创建 标签:
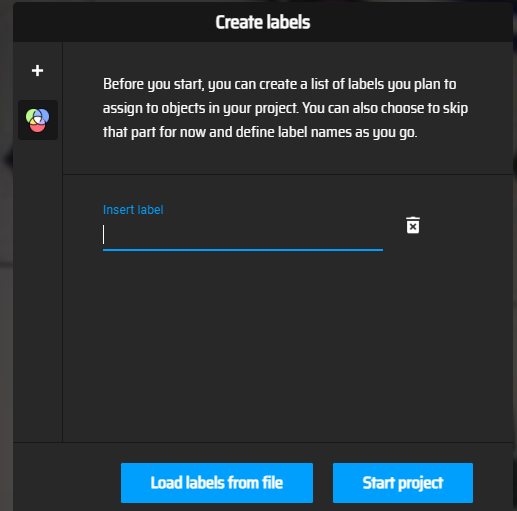
点击 + 号可以添加标签,我这里直接添加 A 和 B 标签:

之后点击接受即可:

唔然后我发现改版了这个网站,以前直接是个十字架你直接画框就好,现在要自己选,选择画框,有可能你不需要选也得:
然后鼠标放到你图片上画个框,就是你需要检测的对象长啥样,你就把他框出来(由于我图片敏感就不做演示,如果你要检测人你就框人,检测某一个特定logo你就框那个 logo):

框了后在这里选择你框出来的目标的分类:

有可能我这里标签是男人、女人,那么我这里框出来男人就选择标签为男人的选项,我这里就用A、B表示了。
随后在左上角 Action 操作中选择导出:

随后弹出来后选择 yolo 格式的 zip 文件,这个看你自己,我是需要 zip 的,txt 格式的文件:

随后导出后,会下载一个压缩包,解压后里面有 txt 的文件:
三、模型训练代
进行模型训练和预测我们需要准备好对应的目录以及标注文件,例如 dataset目录,在 dataset目录下创建对应的图片 train 训练文件夹以及验证文件夹 val。当然 dataset 目录下是分不同项目的,不同项目不同文件夹,在这里我用 gjf 表示我的项目名,在 gif 下创建对应的训练目录以及验证目录(继续往下看吧)。
3.1 目录和文件准备
训练前准备,在 yolo 根目录创建一个 dataset:

打开文件目录,在 datasets 下创建一个 gif,你可以认为 gif 为当前项目的数据集名称,毕竟需要创建不同的名称为数据集分类。
接着 在 gif下创建一个 images 文件夹,用于存放对应的图片数据集,但我们的图片数据集分为训练和验证,再次两个种类分别创建两个目录,一个为 train 用于训练,另一个叫做 val 用于验证。
接着我们需要再创建一个 label 文件夹用于存放对应的标注文件:
同样,对应的label 有用于训练的以及用于验证的,那么此时在labels 文件夹下创建两个对应的 train 和 val 文件夹:

此时我们回到存放image 文件夹下,在 train 文件下把我们拿来标注的图片复制过来:

接着我们选取几张图片进行剪切存放到 val 文件夹下:

在此我选择6张图片剪贴到 val下:
随后打开标注文件下的 train 中;

复制之前下载的标注内容到此文件夹:

此时你还记得,之前剪切到 val 中的 image 图片吗?我是 6、7、8、66、67、68 这 6 个文件,此时将他们的数据在 labels 下的 train 文件夹中进行剪切,复制到 labels 下的 val 文件夹中,因为我们要做到 labels 于 images 文件夹下的文件一一对应,这是原因:
此时还差最后一步,我们回到 labels 文件夹下创建一个 classes.txt 文件:
此文件是说明咱们训练的内容分为几个类别,在此我是两个类别,其中内容为(这里要跟你标注的标签一致,我之前使用 A、B做标签的,所以在这里应该是A、B,这是以前的项目所以就没发改了,就这样了,你理解就ok):

这个类型请按照你自己的进行自定义。
3.2 配置项
接下来开始做训练前的最后一步,创建我们 gjf 项目的配置文件,在根目录下创建一个 .yaml 文件,当然你可以自命名,我是命名为了 gif,这个文件是配置作用:
其中编写如下配置信息:

XML 如下:
path: gjf # datasets 下的哪个项目
train: images/train # 训练图片在哪
val: images/val # 验证目录在哪
test: # test images (optional)# Classes
names:0: GJF1: SQ
随后执行命令:yolo task=detect model=./yolov8n.pt data=gjf.yaml epochs=25 workers=1 batch=16
若出现文件找不到之类的问题或者模型找不到,请使用绝对路径,那样可以暂时解决你的错误,但是你还需要自己调整一下当前你的系统环境,这是另外的问题在此就不再多说,查资料就ok。
解决执行完毕后,顺利无误将会出现以下结果:

此时结果告诉我保留咋爱了某个目录下的 runs\detect… 中,best.pt 是最好的模型结果,那我们使用 best.pt 检测一下我们目标识别效果如何:
yolo detect predict model= runs/... source= ..... show=true
以上命令记得把哪个 … 啥的 路径 改成你自己的目录
3.3 代码检测某一图片是否有目标
接着我们使用代码运行查看结果 :
import cv2
from ultralytics import YOLO# 加载训练好的模型
model = YOLO("path_to_your_trained_model.pt")
# 读取图片
image_path = "path_to_your_image.jpg"
img = cv2.imread(image_path)
# 进行检测
results = model.predict(source=img, save=False)if len(results[0].boxes) > 0:print("有")
else:print("没有")
结果如下:






与卷积神经网络(CNN)的相似性和区别)