1. 论文基本信息
-
论文标题:Masked Autoencoders Are Scalable Vision Learners
-
作者:Kaiming He∗,† Xinlei Chen∗ Saining Xie Yanghao Li Piotr Doll ́ ar Ross Girshick
-
发表时间和期刊:19 Dec 2021; arxiv
-
论文链接:Masked Autoencoders Are Scalable Vision Learners (arxiv.org)
2. 研究背景和动机
-
研究背景:NLP领域中,基于自回归的语言模型(GPT中)和带掩码的自编码器(BERT中)取得了极大的成功,它们的思想是:移除数据中的部分内容并通过学习来预测被移走的内容,例如BERT中的类似于完形填空的任务。这些方法可以使得训练一个千亿参数级别的模型。
-
研究动机:那么在视觉任务中,能否采用类似BERT的方法来处理呢?首先作者提出问题:what makes masked autoencoding different between vision and language?,即在视觉和语言两方面上带掩码的自编码器有什么不同呢?作者从三个角度回答了这个问题:
(1)架构上的差异。CV中是以卷积网络为主导,通过卷积核扫遍图片提取特定的信息,类似“mask token”这样的信息不方便加进去,而在NLP中MASK可以作为一个特定的词,会一直保存下来。ViT(Vision in Transformer)的出现减轻了架构差异这个阻碍。
(2)信息密度的不同。语言是人类产生的,带有一定的语义并具有非常高的信息密度;而图片是一种自然信号并有一定的信息冗余,比如即使遮住图片中某一小块,也可以根据邻近的块中风景、人像等信息将其补全。因此在学习中为了克服这种差异并学到有用的特征,作者采用了一种方法:遮盖掉图片中大部分的块,如遮盖比例达到75%。
(3)如(2)所说,NLP中单词信息密度是较高的,而图片中的像素语义特征程度较低,因此decoder的作用在视觉和语言上也是不同的。个人理解是decoder在视觉任务上重建的是像素级别块,相比单词来说语义特征更低,因此需要一个复杂的decoder架构来解决,做一个比较大的解码器。
3. 主要贡献
MAE的思路是:mask掉图片的一部分patch,并重建这些mask掉的块。两点核心设计:
(1)设计了一个非对称式的encoder-decoder架构,encoder只操作那些可见的patch块部分,并得到一些图片的潜在表示;而decoder从那些不可见的(也即被mask的图像块)以及encoder的输出这两部分中重建原始图像块。MAE架构如下图所示,可以注意到decoder比encoder更为轻量级,灰色块代表被mask掉的:
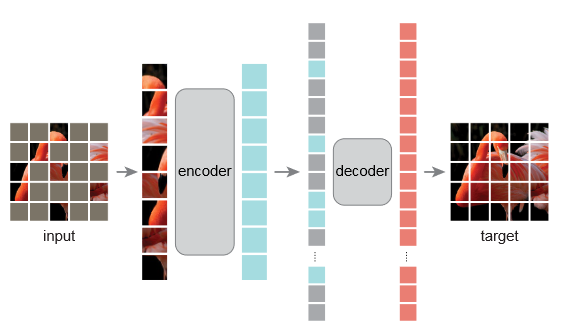
(2)mask掉图像的大部分块(如75%的遮盖率)可以创造一个有意义的自监督学习任务。仅使用剩余的少部分图像信息进行训练。这种策略不仅降低了计算成本,而且增强了模型的重建能力。MAE通过其创新的掩码策略和简洁的模型架构,展示了在自监督学习领域的巨大潜力。
4. 方法和模型
下图展示了重建图片的具体情况,每一个三元组中,左侧代表masked image,中间是MAE重建的结果,右侧是原始图片:

(1)Masking:把图像分成一系列的patch块,并随机mask掉一些patch块,下图为不同mask比率对重建图片的影响:

(2)MAE encoder:encoder是一个ViT但是只作用在没有被遮住的块,encoder会对patch进行线性投影再添加位置编码,由于只作用在小部分patch(mask比率为75%时,encoder只处理剩余的25%),减少了计算并节约内存。
(3)MAE decoder:MAE 的解码器仅在预训练过程中用于执行图像重建任务(仅使用编码器来生成用于识别的图像表示)。因此,解码器架构可以灵活设计,与编码器设计无关。作者尝试了非常小的解码器,它们比编码器更窄、更浅。
(4)Reconstruction target:MAE 通过预测每个被掩码块的像素值来重建输入。解码器输出中的每个元素都是一个代表块的像素值向量。解码器的最后一层是一个线性投影,其输出通道数等于一个块中的像素值数量。解码器的输出被重塑为一个重建图像。损失函数计算重建图像和原始图像在像素空间中的均方误差(MSE),并仅在被掩码的块上计算损失,类似于 BERT。
5. 实验和结果
略~
6. 讨论和未来工作
简单且可扩展的算法是深度学习的核心。在NLP中,简单的自监督学习方法使得模型规模呈指数级增长而受益。在计算机视觉领域,尽管自监督学习有所进展,但实用的预训练范式主要是监督式的。在本研究中观察到,在 ImageNet 和迁移学习中,自编码器——一种类似于 NLP 技术的简单自监督方法提供了可扩展的好处。自监督学习在视觉领域可能正在走上一条与 NLP 类似的轨迹。 另一方面,注意到图像和语言是性质不同的信号,这种差异必须谨慎处理。图像没有像词语那样的语义分解。我们没有尝试去除对象,而是去除随机块,这些块很可能不会形成语义片段。同样,我们的 MAE 重建像素,这些像素不是语义实体。然而,观察到 MAE 推断出复杂的、整体的重建,这表明它已经学习了许多视觉概念,即语义。我们假设这种行为是通过 MAE 内部丰富的隐藏表示发生的。我们希望这种观点能激发未来的研究工作
7. 个人理解和反思
在引言中,从“提出问题”到“回答问题”再到“提出我的想法”这种写作方式值得借鉴,结论中提到的“简单”是相对而言的,是基于ViT提出来的。利用ViT做BERT一样的自监督学习,盖住更多的块使得剩下的块之间的冗余度没有那么高;使用transformer架构的解码器直接还原原始的像素信息,使得整个流程更加简单。在ImageNet-1K上使用自监督训练的效果超过了之前的工作。简单的想法+非常好的实验结果+详细的实验决定了这是一个高质量的工作
)

)



