loader机制让大模型具备实时学习的能力:
0 Loader机制
案例环境准备:
import osos.environ["OPENAI_API_KEY"] = "sk-javaedge"
os.environ["OPENAI_PROXY"] = "https://api.chatanywhere.tech"import os
from dotenv import load_dotenv
# Load environment variables from openai.env file
load_dotenv("openai.env")# Read the OPENAI_API_KEY from the environment
api_key = os.getenv("OPENAI_API_KEY")
api_base = os.getenv("OPENAI_API_BASE")
os.environ["OPENAI_API_KEY"] = api_key
os.environ["OPENAI_API_BASE"] = api_base1 加载markdown
准备一个 md 文件:
# 我是一个markdown加载示例
- 第一项目
- 第二个项目
- 第三个项目## 第一个项目
编程严选网,最厉害专业的AI研究基地## 第二个项目
AIGC打造未来AI应用天地## 第三个项目
编程严选网是一个非常牛逼的AI媒体#使用loader来加载markdown文本
from langchain.document_loaders import TextLoaderloader = TextLoader("loader.md")
loader.load()
2 加载cvs
Project,DES,Price,People,Location
AI GC培训,培训课程,500,100,北京
AI工程师认证,微软AI认证,6000,200,西安
AI应用大会,AI应用创新大会,200门票,300,深圳
AI 应用咨询服务,AI与场景结合,1000/小时,50,香港
AI项目可研,可行性报告,20000,60,上海#使用 CSVLoader 来加载 csv 文件
from langchain.document_loaders.csv_loader import CSVLoader#loader = Loader(file_path="loader.")
loader = CSVLoader(file_path="loader.csv")
data = loader.load()
print(data)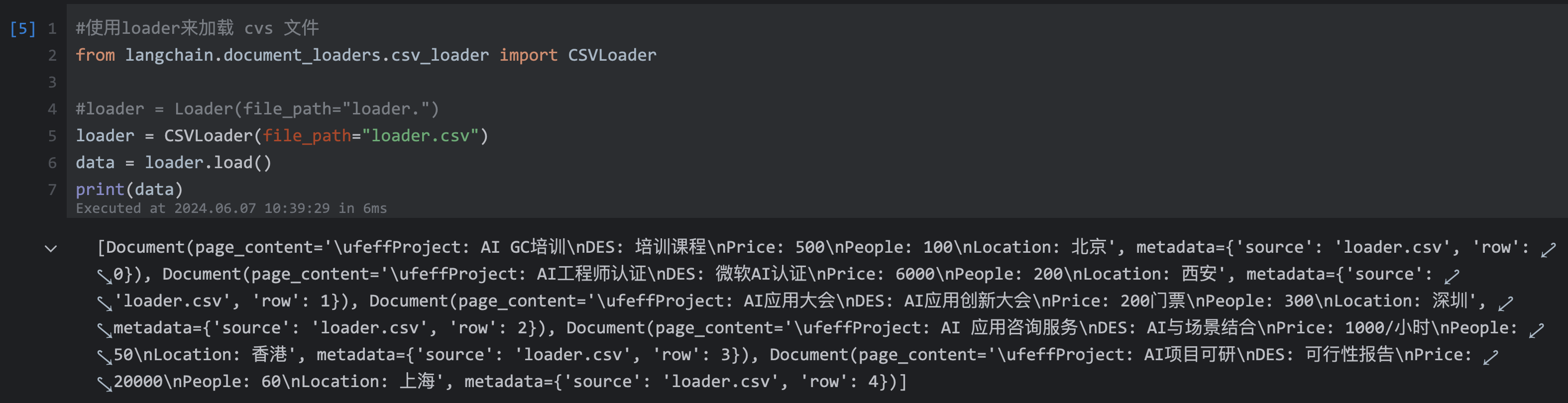
3 加载html
先下包:
! pip install "unstructured[xlsx]"加载文件目录
from langchain.document_loaders import UnstructuredHTMLLoaderloader = UnstructuredHTMLLoader("loader.html")
data = loader.load()
data会加载 html 所有内容。
from langchain.document_loaders import BSHTMLLoader
loader = BSHTMLLoader("loader.html")
data = loader.load()
data只加载去除标签后的关键内容:

4 加载JSON
先装 jq 包:
! pip install jqfrom langchain.document_loaders import JSONLoader
loader = JSONLoader(file_path = "simple_prompt.json",jq_schema=".template",text_content=True
)
data = loader.load()
print(data)
5 加载PDF
先装包:
! pip install pypdffrom langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("loader.pdf")
pages = loader.load_and_split()
pages[0]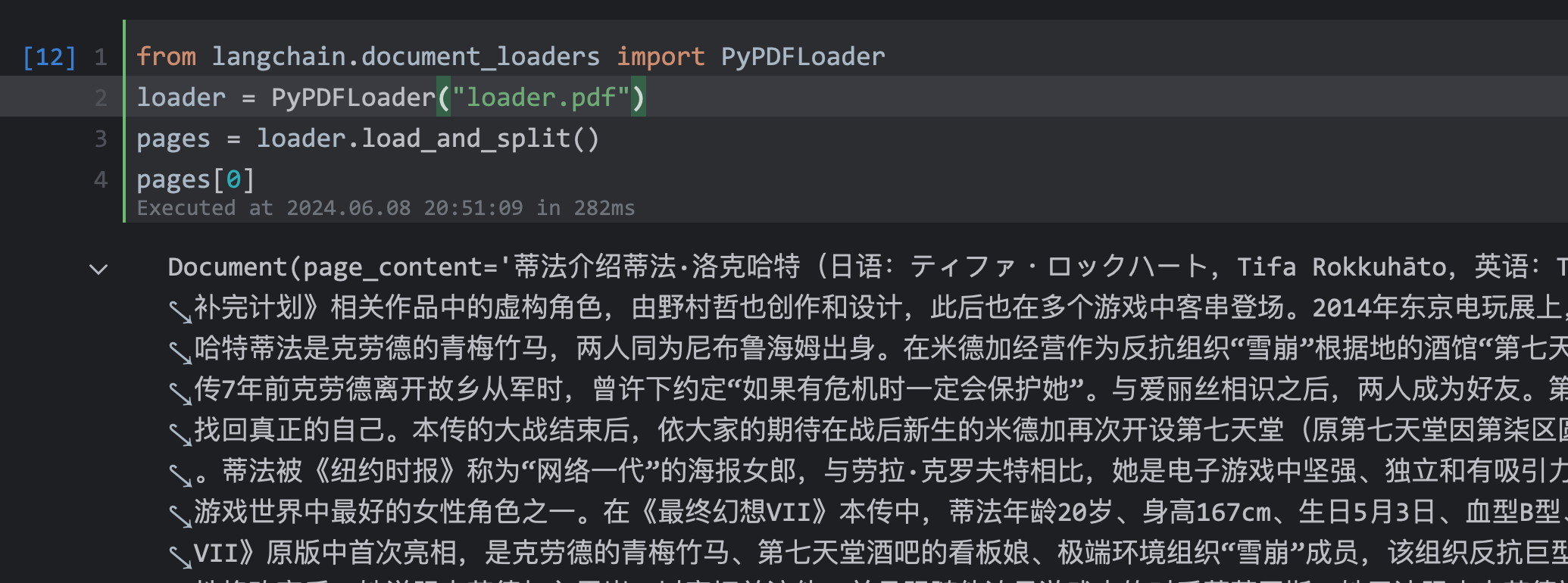
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
中央/分销预订系统性能优化
活动&券等营销中台建设
交易平台及数据中台等架构和开发设计
车联网核心平台-物联网连接平台、大数据平台架构设计及优化
LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
)


)

每日小游戏平台系列)