当前,研究社区亟需全面可靠的长视频理解评估基准,以解决现有视频理解评测基准在视频长度不足、类型和任务单一等方面的局限性。因此,智源联合北邮、北大和浙大等多所高校提出首个多任务长视频理解评测基准MLVU(A Comprehensive Benchmark for Multi-Task Long Video Understanding)。MLVU拥有充足且灵活可变的的视频长度、包含多种长视频来源、涵盖多个不同维度的长视频理解任务。通过对20个最新的流行多模态大模型(MLLM)评测发现,排名第一的GPT-4o的单选正确率不足65%,揭示了现有模型在长视频理解任务上仍然面临重大挑战。我们的实证研究还探讨了多个影响大模型长视频理解能力的关键因素,期待MLVU能够推动社区对长视频理解研究的发展。
论文标题:MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding
论文链接:https://arxiv.org/abs/2406.04264
项目链接:https://github.com/FlagOpen/FlagEmbedding/tree/master/MLVU
背景介绍
使用MLLM进行长视频理解具有极大的研究和应用前景。然而,当前研究社区仍然缺乏全面和有效的长视频评测基准,它们主要存在以下问题:
1、视频时长不足:当前流行的 Video Benchmark[1,2,3] 主要针对短视频设计,大部分视频的长度都在1分钟以内。
2、视频种类和任务类型不足:现有评测基准往往专注在特定领域的视频(例如电影[4, 5],第一视角[6])和特定的视频评测任务(例如Captioning[2],Temporal Perception[7],Action Understanding[8])
3、缺乏合理的长视频理解任务设计:现有部分长视频理解评测任务往往只和局部帧有关[4];或者使用针对经典电影进行问答[9],MLLMs 可以直接凭借 text prompt 正确回答问题而不需对视频进行分析。
MLVU的构建过程
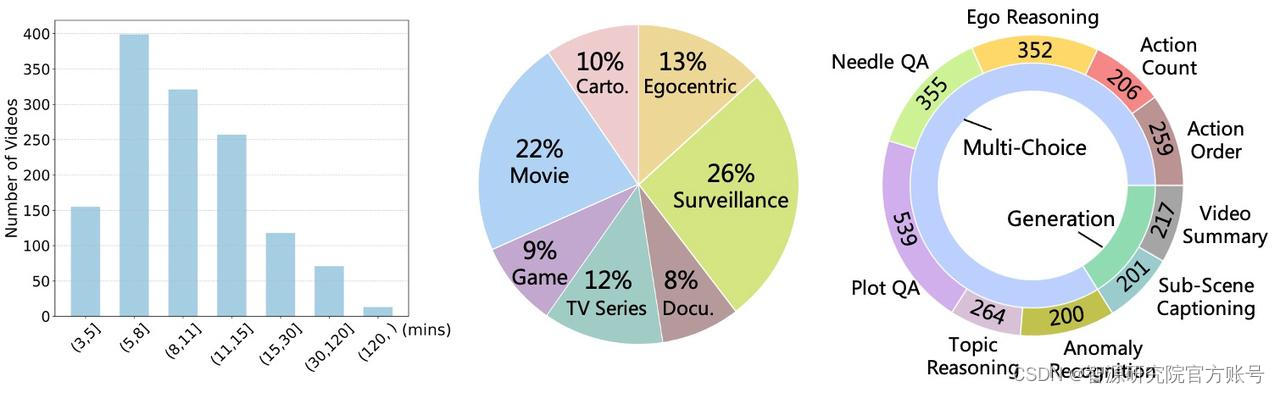
针对以上不足,我们提出了MLVU:首个全面的多任务长视频理解Benchmark。MLVU具有以下特点:
1、充足且灵活的视频时长
MLVU的视频时长覆盖了3分钟到超过2小时,平均视频时长12分钟,极大扩展了当前流行的Video Benchmark的时长范围。另外,MLVU的大部分任务标注过程中进行了片段-问题对应标注(例如,Video Summarization任务分段标注了视频的前3分钟,前6分钟...)。MLLMs可以灵活地在MLVU上选择测试不同时长情况下的长视频理解能力。
2、覆盖真实和虚拟环境的多种视频来源
MLVU收集了包括电影、电视剧、纪录片、卡通动画片、监控视频、第一视角视频和游戏视频等多个类型的长视频。覆盖了长视频理解的多个领域范围。
3、针对长视频理解设计的全面任务类别
我们针对长视频理解设计了9类不同的任务,并进一步将他们任务分为三类:全面理解,单细节理解、多细节理解。
·全面理解任务:要求MLLMs理解和利用视频的全局信息来解决问题;
·单细节理解任务:要求MLLMs根据问题定位长视频中的某一细节,并利用该细节来解决问题;
·多细节理解任务:要去MLLMs定位和理解长视频中的多个相关片段来完成和解决问题。
此外,我们还包括了单项选择题形式和开放生成式问题,全面考察MLLMs在不同场景下的长视频理解能力。
(文末提供了MLVU的9类任务示例图参考)
4、合理的问题设置与高质量答案标注
以情节问答(Plot Question Answering)任务为例。一部分Benchmark[9, 10]使用电影/电视的角色作为问题线索来对MLLMs进行提问,然而他们使用的视频多为经典电影/电视,MLLMs可以直接使用自有知识回答问题而不需要对输入视频进行理解。另一部分Benchmark[4]试图避免这个问题,但由于长视频的复杂性,仅仅利用代词和描述性语句来指代情节细节非常困难,他们的问题非常宽泛或者需要在问题中额外指定具体的时间片段而不是让MLLMs自己根据题目寻找对应细节。
MLVU通过精细的人工标注克服了这些问题,在所有的情节问答任务中,MLVU均使用“具有详细细节的代词”来指代情节中的人物、事件或背景,避免了问题泄露带来的潜在影响,MLLMs需要根据问题提供的线索识别和定位相关片段才能进一步解决问题。此外,MLVU的Plot QA问题具备丰富的多样性,增强了评测的合理性和可靠性。

详细分析MLLMs在MLVU上的表现
我们在MLVU上对20个流行的MLLM进行了评测,包括开源模型和闭源模型。评测结果如下:
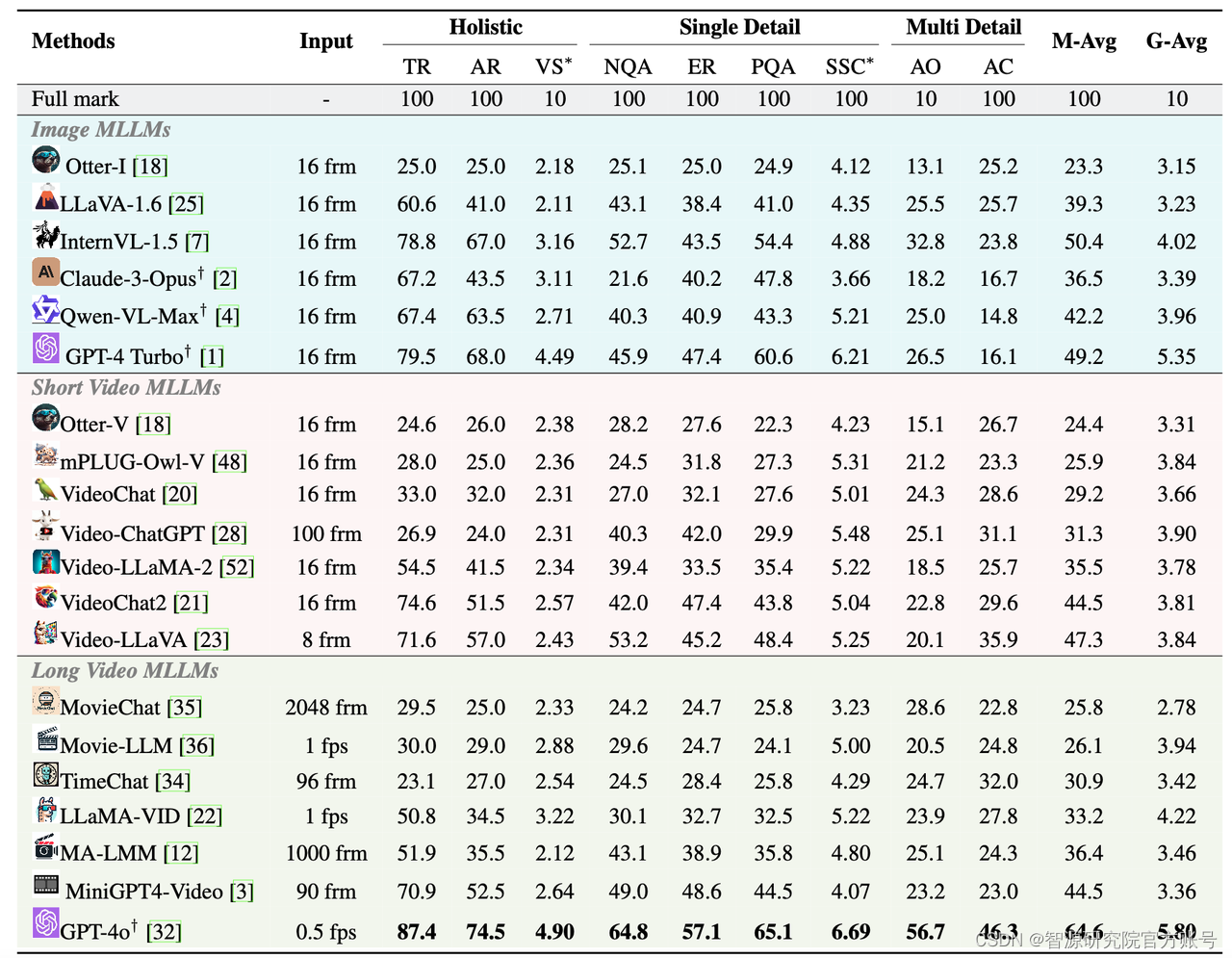
实验结果发现:
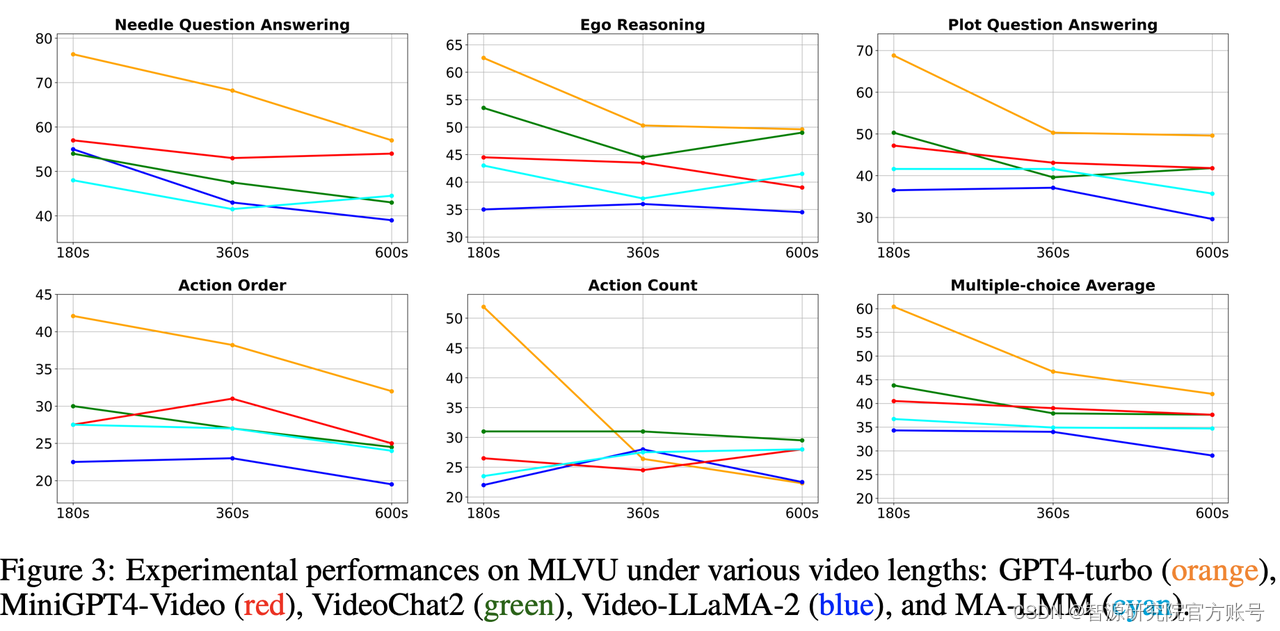
(1)长视频理解仍然是富有挑战的任务。尽管GPT-4o[11]在所有任务中均取得了第1名的成绩,然而,它的单选平均准确率只有64.6%。所有的模型都在需要细粒度理解能力的任务上(单细节、多细节理解任务)表现糟糕。此外,大部分模型的性能都会随着视频时长增加显著下降。
(2)开源模型和闭源模型之间存在较大的差距。开源模型中单项选择题性能最强的InternVL-1.5[12]单选平均准确度仅有50.4%;开放生成式题目最强的LLaMA-Vid得分仅有4.22,均远远落后于GPT-4o的64.6%和5.80。此外,现有长视频模型并没有在长视频理解任务上取得理想的成绩,说明当前的MLLMs在长视频理解任务上仍然存在较大的提升空间。
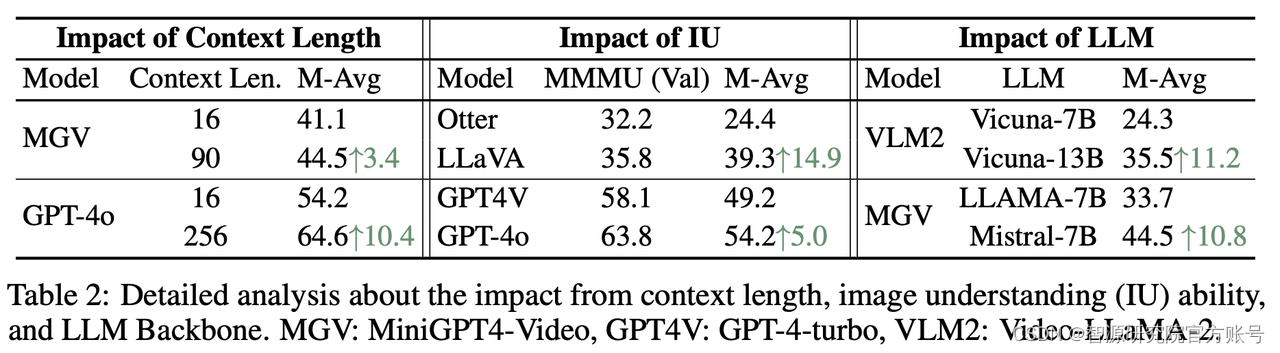
(3)上下文长度、图像理解能力、LLM Backbone 是MLLMs提升长视频理解能力的关键因素。实证研究发现,提升上下文窗口,提升MLLM的图像理解能力,以及使用更强大的LLM Backbone对长视频理解的性能具有显著的提升作用。这揭示了未来MLLMs在提升长视频理解能力的重要改进方向。
总结
我们提出MLVU,首个专为长视频理解任务设计的全面多任务评测基准。MLVU极大扩展了现有基准的视频长度、提供了丰富的视频类型,并针对长视频理解设计了多样化的评估任务,从而为MLLMs提供了一个可靠高质量的长视频理解评测平台。
通过评估当前流行的20个MLLMs,我们发现,长视频理解仍然是一个富有挑战和具有巨大提升空间的研究领域。通过实证研究,我们揭示了多个影响长视频理解能力的因素,为未来MLLMs的长视频理解能力构建提供了洞见。此外,我们将不断扩展和更新MLVU覆盖的视频类型和评估任务,期待MLVU能够促进社区对长视频理解研究的发展。
附录:MLVU的任务示例图

部分参考文献:
[1] Li K, Wang Y, He Y, et al. Mvbench: A comprehensive multi-modal video understanding benchmark[J]. arXiv preprint arXiv:2311.17005, 2023.
[2] Xu J, Mei T, Yao T, et al. Msr-vtt: A large video description dataset for bridging video and language[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5288-5296.
[3] Li B, Wang R, Wang G, et al. Seed-bench: Benchmarking multimodal llms with generative comprehension[J]. arXiv preprint arXiv:2307.16125, 2023.
[4] Song E, Chai W, Wang G, et al. Moviechat: From dense token to sparse memory for long video understanding[J]. arXiv preprint arXiv:2307.16449, 2023.
[5] Wu C Y, Krahenbuhl P. Towards long-form video understanding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1884-1894.
[6] Mangalam K, Akshulakov R, Malik J. Egoschema: A diagnostic benchmark for very long-form video language understanding[J]. Advances in Neural Information Processing Systems, 2024, 36.
[7] Yu Z, Xu D, Yu J, et al. Activitynet-qa: A dataset for understanding complex web videos via question answering[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 9127-9134.
[8] Wang Z, Blume A, Li S, et al. Paxion: Patching action knowledge in video-language foundation models[J]. Advances in Neural Information Processing Systems, 2023, 36.
[9] Li Y, Wang C, Jia J. LLaMA-VID: An image is worth 2 tokens in large language models[J]. arXiv preprint arXiv:2311.17043, 2023.
[10] Lei J, Yu L, Bansal M, et al. Tvqa: Localized, compositional video question answering[J]. arXiv preprint arXiv:1809.01696, 2018.
[11] OpenAI. Gpt-4o. https://openai.com/index/hello-gpt-4o/, May 2024.
[12] Chen Z, Wang W, Tian H, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites[J]. arXiv preprint arXiv:2404.16821, 2024.
)




