一、概述
前面我们介绍了用RNN实现语言模型,可以对时序数据进行建模,并训练。不过这里面有一个问题,就是当时序数据的长度越来越长,RNN将难以处理过长的数据,也就是说RNN无法保持长时间的记忆。RNN通过反向传播梯度,能够学习到时间方向上的依赖关系,此时梯度包含了应该学习到的有意义信息,通过反向传播这些信息,RNN可以学习长期依赖,但是如果在传播过程中这个梯度不断变小,则权重的更新会越来越小,以至于不更新,最终无法学习到特征,这就是梯度消失,为了避免梯度消失或者梯度爆炸,LSTM(长短期记忆网络)被提了出来。
二、梯度消失和梯度爆炸
梯度消失和梯度爆炸是深度学习模型中经常遇到问题,所谓梯度消失就是在训练过程中,反向传播的梯度越来越小,以至于无法更新权重,无法学习,反映出来的表现就是损失值Loss不下降了;梯度爆炸相反,随着训练的不断进行,梯度进行累积,越来越大,发生了爆炸,最终导致数值溢出,反映出来就是训练的损失值出现了None之类的值。下面通过一个程序来表示一下:
import numpy as np
import matplotlib.pyplot as pltN = 2 # batch_size
H = 3 # 隐藏状态向量的维度
T = 20 # 时间序列的长度dh = np.ones((N, H)) # 假设一个梯度
np.random.seed(3) # 随机种子
Wh = np.random.randn(H, H) # 隐藏层的权重矩阵
norm_list = [] # 梯度范数列表,用来观察梯度变化
for t in range(T):dh = np.dot(dh, Wh.T) # 隐藏层权重矩阵和梯度相乘norm = np.sqrt(np.sum(dh**2))/N # 获取梯度的范数norm_list.append(norm) # 添加到梯度列表中
# 用matplotlib可视化,这里选择类似R语言的ggplot方式
plt.style.use('ggplot')
plt.rcParams['font.sans-serif'] = 'SimHei' ## 设置字体为SimHei
plt.rcParams['axes.unicode_minus'] = False ## 防止负号显示为一个方框
plt.plot([i+1 for i in range(T)], norm_list)
plt.xlabel("时间步长")
plt.ylabel("梯度范数")
plt.xlim(0, 21)
plt.show()
可以看到,随着训练过程的推移,梯度范数越来越大,这就是所谓的梯度爆炸了。
当我们把权重矩阵初始化的时候乘以0.5,让其小于1,效果如下:
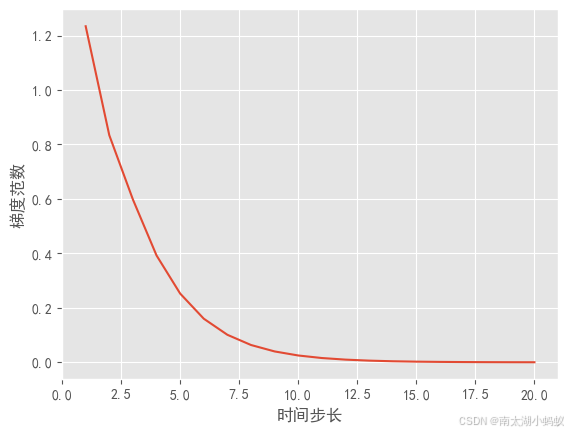
可以看到,随着训练过程的推移,梯度范数逐渐接近零,这就是梯度消失了。
处理梯度爆炸的方法一般是梯度裁剪,也就是设置一个阈值,当梯度大于阈值的时候,对梯度进行缩小,使得训练可以继续,如下面的代码所示:
def clip_grads(grads, max_norm):total_norm = 0for grad in grads:total_norm += np.sum(grad**2)total_norm = np.sqrt(total_norm) # 梯度的范数rate = max_norm / (total_norm + 1e-6) # 加一个很小的数防止除以零if rate < 1: # 意味着总的梯度范数大于阈值了,进行裁剪for grad in grads:grad *= rate # 本质上就是乘以一个小于1的数,进行缩小而处理梯度消失的其中一个办法就是引入LSTM。
三、LSTM结构
LSTM最大的特点就是引入了“门”这种结构,用来控制存储信息的流转,从而接近梯度消失问题。传统的RNN,每个时刻的输入(除第一个和最后一个节点外)都是t时刻的时序数据x和上一个节点传过来的隐藏信息,并输出结果作为下一个节点的隐藏信息和当前的输出信息;而LSTM的输入和输出除了隐藏信息外,还多了一个记忆单元c,这个记忆单元c存储了t时刻LSTM的记忆,可以认为其中保存了从开始到t时刻的所有必要信息。

可以看到ct是由ct-1和ht-1以及t时刻的输入数据xt共同计算得出的,同时对ct进行tanh操作后得到ht作为隐藏信息进行输出。完整的LSTM结构如下图所示:

t时刻的时序数据输入到模型中,一共分成了四个分支,同时也形成了三个门:遗忘门、输入门、输出门以及另一个更新的分支。
直观的理解:遗忘门的作用就是模型选择要遗忘多少过去的记忆信息。输入门的作用就是对组合后的输入信息g进行取舍,而非一股脑儿都让其输入模型。输出门作用是调整ct作为下一个节点隐藏信息的多少,新的记忆单元ct经过tanh操作后变成下一个节点输入隐藏信息ht,而输出的就是在这里控制流向下一个节点的隐藏信息的多少。
用公式表示就是:
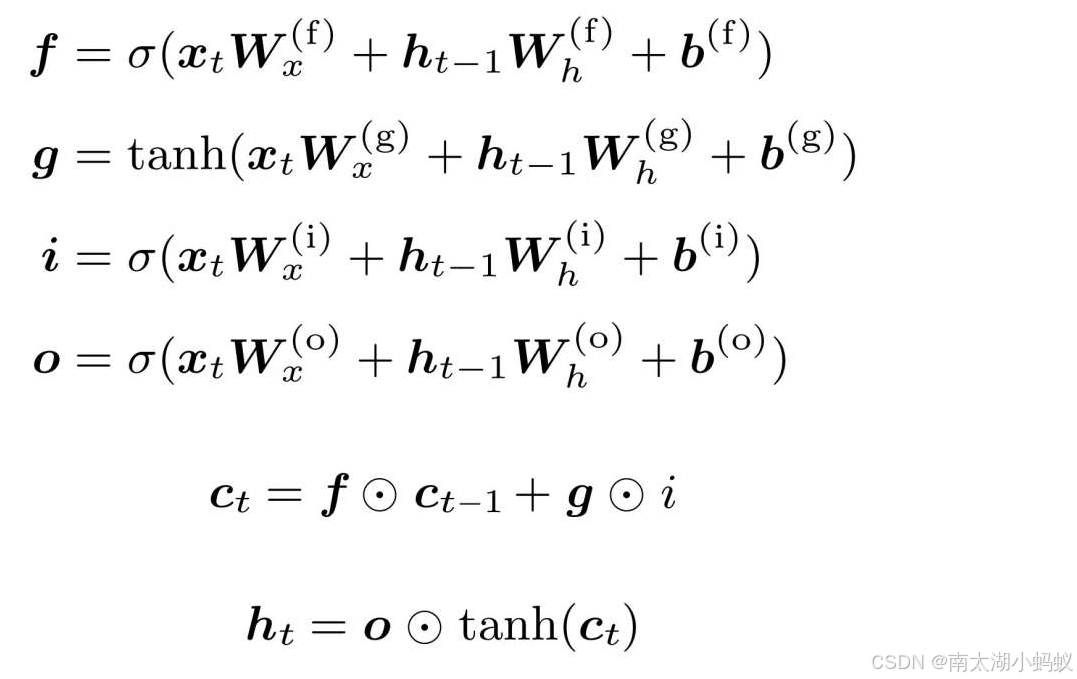
这里的f,i,o分别对应了遗忘门,输入门和输出门,g代表了组合后的输入信息,ct是新的记忆单元,ht是最终输出的隐藏信息。结构还是很清晰的。可以看到f,g,i,o都用到了xW1+hW2+b这种结构,因此把这种结构单独拎出来,这是我觉得书里面一个非常好的设计(《深度学习进阶:自然语言处理》),称为一个大矩阵A,又因为要分成四条支路,所以把A四等分,第一部分传入f遗忘门,第二部分生成新的输入g,第三部分传入输入门,第四部分传入输出门,分别作为这四个支线的权重进行计算。
四、LSTM训练
我们先根据前面的介绍,写出LSTM的程序代码:
class LSTM:def __init__(self, Wx, Wh, b):'''Parameters----------Wx: 输入`x`用的权重参数(整合了4个权重)Wh: 隐藏状态`h`用的权重参数(整合了4个权重)b: 偏置(整合了4个偏置)'''self.params = [Wx, Wh, b] # 参数矩阵self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] # 梯度self.cache = None # 正向传播的中间结果def forward(self, x, h_prev, c_prev):Wx, Wh, b = self.paramsN, H = h_prev.shapeA = np.dot(x, Wx) + np.dot(h_prev, Wh) + b # 通过大矩阵计算# 把计算结果分隔成四个子模块,分别进行不同的计算f = A[:, :H] # 流向遗忘门g = A[:, H:2*H] # 流向生成新的输入i = A[:, H*2:H*3] # 流向输入门o = A[:,3*H:] # 流向输出门f = sigmoid(f) # 遗忘门g = np.tanh(g) # 新的记忆i = sigmoid(i) # 输入门o = sigmoid(o) # 输出门c_next = f*c_prev + g*i # 新的候选是遗忘门控制需要忘记多少原来的信息,加上新的记忆h_next = o*np.tanh(c_next) # 根据新的记忆单元和输出门得到新的隐藏信息# 缓存中间信息self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)return h_next, c_nextdef backward(self, dh_next, dc_next):Wx, Wh, b = self.paramsx, h_prev, c_prev, i, f, g, o, c_next = self.cachetanh_c_next = np.tanh(c_next)# 反向传播公式ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)dc_prev = ds * fdi = ds * gdf = ds * c_prevdo = dh_next * tanh_c_nextdg = ds * idi *= i * (1 - i)df *= f * (1 - f)do *= o * (1 - o)dg *= (1 - g ** 2)# 合并为大矩阵A的梯度dA = np.hstack((df, dg, di, do))# 获取Wh,Wx和b的梯度,这里的Wh,Wx和b都整合了四个权重dWh = np.dot(h_prev.T, dA)dWx = np.dot(x.T, dA)db = dA.sum(axis=0)# 更新梯度self.grads[0][...] = dWxself.grads[1][...] = dWhself.grads[2][...] = dbdx = np.dot(dA, Wx.T)dh_prev = np.dot(dA, Wh.T)return dx, dh_prev, dc_prev如果是用Pytorch等框架来实现,非常方便,只要考虑前向网络的编写就行了,不过这里我们希望搞懂内部运行的机制,比较复杂的就是反向传播的计算。
从公式ht = O.tanh(ct),我们开始计算梯度,假设考虑对于输入门i的梯度(其他几个部分的计算是类似的),由于总的梯度来自于两部分,隐藏信息ht和记忆单元ct,所以需要分别对这两个向量计算梯度。
首先看ht,因为
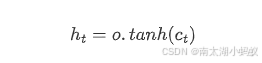
所以

另外,由于

所以

因此,总的梯度等于两者之和,也就是
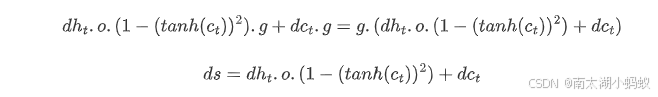
这里只是把公共服务提取出来,称为ds。同时i也是由一个线性变换进行sigmoid运算得来,这个线性变换就是正向传播中的大矩阵A,对于输入门i,我们假设这部分是A1,那么
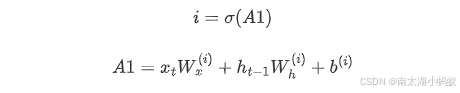
所以,如果我们把i对A1求导,得到关于线性变换A1的梯度如下:
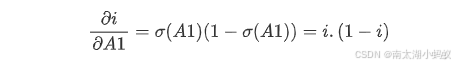
至此,我们得到了反向传播对于输入门的分支的梯度,同样的,我们可以得到另外三个分支的梯度,然后把这四个分支的梯度合并在一起,就是反向传播对于大矩阵A的梯度了。
也就是代码里面的 dA = np.hstack((df, dg, di, do)) 这句话的涵义。
其余三个门的计算过程我就省略了,对于遗忘门,假设线性变换为A2,梯度如下:

对于输出门,假设线性变换为A3,梯度如下:
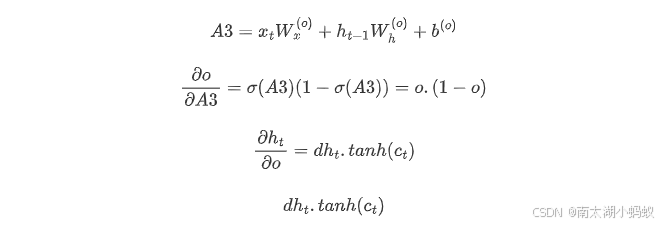
对于新的输入g,假设线性变换为A4,梯度如下:
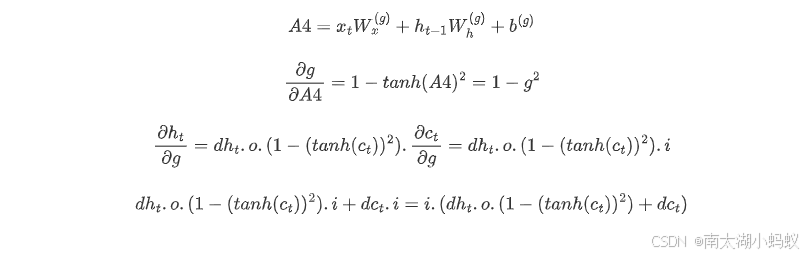
如此就完成了LSTM代码的编写,其实结构上是很清晰的,就是反向传播的公式稍微需要推理一下,建议用纸笔计算一下就很清楚了。
类似于上一篇文章(自然语言处理入门4——RNN)的实现,基于LSTM可以实现TimeLSTM以及将LSTM应用到自然语言问题中的Rnnlm,我们还是使用英文语料库ptb进行训练:
# 设定超参数
batch_size = 20
wordvec_size = 100
hidden_size = 100 # RNN的隐藏状态向量的元素个数
time_size = 35 # RNN的展开大小
lr = 20.0
max_epoch = 4
max_grad = 0.25# 读入训练数据
corpus, word_to_id, id_to_word = load_data('train')
corpus_test, _, _ = load_data('test')
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]# 生成模型
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)# 1.应用梯度裁剪进行学习
trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad,eval_interval=20)
trainer.plot(ylim=(0, 500))# 2.基于测试数据进行评价
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('test perplexity: ', ppl_test)# 3.保存参数
model.save_params()
# 输出:
| epoch 1 | iter 1 / 1327 | time 0[s] | perplexity 9999.69
| epoch 1 | iter 21 / 1327 | time 2[s] | perplexity 2965.95
| epoch 1 | iter 41 / 1327 | time 5[s] | perplexity 1247.84
... ...
| epoch 4 | iter 1301 / 1327 | time 779[s] | perplexity 110.39
| epoch 4 | iter 1321 / 1327 | time 782[s] | perplexity 108.61
可以看到,经过4个epoch的训练后,困惑度有了明显的下降。
五、LSTM改进
LSTM主要有三个地方可以改进,一个是增加多个LSTM模块,增加模型的复杂度,但是增加模型的复杂度容易发生过拟合,所以增加了Dropout模块,随机丢弃一部分神经元不参与训练,第三个地方就是把Embedding的权重和最后的Affine模块的权重共享,可以大大减少参数量。
所以改进如下:
1.增加多个LSTM模块
2.增加Dropout模块
3.Embedding模块和Affine模块共享权重
改进后代码如下:
class BetterRnnlm(BaseModel):def __init__(self, vocab_size=10000, wordvec_size=650, hidden_size=650, dropout_ratio=0.5):V,D,H = vocab_size, wordvec_size, hidden_sizern = np.random.randn# 初始化权重embed_W = (rn(V,D)/100).astype('f')lstm_Wx1 = (rn(D,H*4)/np.sqrt(D)).astype('f')lstm_Wh1 = (rn(H,H*4)/np.sqrt(H)).astype('f')lstm_b1 = np.zeros(4*H).astype('f')lstm_Wx2 = (rn(D,H*4)/np.sqrt(D)).astype('f')lstm_Wh2 = (rn(H,H*4)/np.sqrt(H)).astype('f')lstm_b2 = np.zeros(4*H).astype('f')affine_b = np.zeros(V).astype('f')# 3点改进self.layers = [TimeEmbedding(embed_W),TimeDropout(dropout_ratio),TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),TimeDropout(dropout_ratio),TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),TimeDropout(dropout_ratio),TimeAffine(embed_W.T, affine_b) # 权重共享,所以embed_W和affine_W是一样]self.loss_layer = TimeSoftmaxWithLoss()self.lstm_layers = [self.layers[2],self.layers[4]]self.drop_layers = [self.layers[1],self.layers[3],self.layers[5]]self.params,self.grads = [],[]for layer in self.layers:self.params += layer.paramsself.grads += layer.gradsdef predict(self, xs, train_flag=False):for layer in self.drop_layers:layer.train_flag = train_flagfor layer in self.layers:xs = layer.forward(xs)return xsdef forward(self,xs,ts,train_flag=True):score = self.predict(xs, train_flag)loss = self.loss_layer.forward(score,ts)return lossdef backward(self, dout=1):dout = self.loss_layer.backward(dout)for layer in reversed(self.layers):dout = layer.backward(dout)return doutdef reset_state(self):for layer in self.lstm_layers:layer.reset_state()# 设定超参数
batch_size = 20
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 20.0
max_epoch = 4
max_grad = 0.25
dropout = 0.5# 读入训练数据
corpus, word_to_id, id_to_word = load_data('train')
corpus_val, _, _ = load_data('val')
corpus_test, _, _ = load_data('test')vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,time_size=time_size, max_grad=max_grad)model.reset_state()ppl = eval_perplexity(model, corpus_val)print('valid perplexity: ', ppl)if best_ppl > ppl:best_ppl = pplmodel.save_params()else :lr /= 4.0optimizer.lr = lrmodel.reset_state()print('-' * 50)训练后的结果如下:
| epoch 4 | iter 1241 / 1327 | time 1634[s] | perplexity 109.46
| epoch 4 | iter 1261 / 1327 | time 1662[s] | perplexity 100.92
| epoch 4 | iter 1281 / 1327 | time 1685[s] | perplexity 102.03
| epoch 4 | iter 1301 / 1327 | time 1708[s] | perplexity 131.53
| epoch 4 | iter 1321 / 1327 | time 1738[s] | perplexity 126.88可以看到,训练4个epoch后,困惑度下降到100左右,而且这里的wordvec_size和hidden_size都加到了650,而不是之前的100,说明改进后的网络对于长度更长,隐藏信息更多的时间序列训练效果一样很好。
)




——Lable控件详解)
