>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客**
>- **🍖 原作者:[K同学啊]**
本人往期文章可查阅: 深度学习总结
🏡 我的环境:
- 语言环境:Python3.11
- 编译器:PyCharm
- 深度学习环境:Pytorch
-
- torch==2.0.0+cu118
-
- torchvision==0.18.1+cu118
- 显卡:NVIDIA GeForce GTX 1660
本周任务:
- 根据之前的代码,为解码器添加上注意力机制
一、前期准备工作
from __future__ import unicode_literals,print_function,division
from io import open
import unicodedata,string,re,random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as Fdevice=torch.device("cuda" if torch.cuda.is_available() else "cpu")
device输出:
device(type='cuda')1. 搭建语言类
SOS_token=0 # 序列的开始
EOS_token=1 # 序列的结束# 语言类,方便对语料库进行操作
class Lang:def __init__(self,name):self.name=nameself.word2index={} # 将单词映射到索引self.word2count={} # 记录单词出现的次数self.index2word={0:"SOS",1:"EOS"} # 将索引映射到单词self.n_words=2 # Count SOS and EOS,单词的数量,初始值为2def addSentence(self,sentence):for word in sentence.split(' '):self.addWord(word)def addWord(self,word):if word not in self.word2index:self.word2index[word]=self.n_wordsself.word2count[word]=1self.index2word[self.n_words]=wordself.n_words+=1else:self.word2count[word]+=12. 文本处理函数
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD',s)if unicodedata.category(c)!='Mn')# 小写化,剔除标点与非字母符号
def normalizeString(s):s=unicodeToAscii(s.lower().strip())s=re.sub(r"([.!?])",r" \1",s)s=re.sub(r"[^a-zA-Z.!?]+",r" ",s)return s3. 文件读取函数
def readLangs(lang1,lang2,reverse=False):print("Reading lines...")# 以行为单位读取文件lines=open(r'E:\DATABASE\N-series\N9\%s-%s.txt'%(lang1,lang2),encoding='utf-8').\read().strip().split('\n')# 将每一行放入一个列表中# 一个列表中有两个元素,A语言文本与B语言文本pairs=[[normalizeString(s) for s in l.split('\t')] for l in lines]# 创建Lang实例,并确认是否反转语言顺序if reverse:pairs=[list(reversed(p)) for p in pairs]input_lang=Lang(lang2)output_lang=Lang(lang1)else:input_lang=Lang(lang1)output_lang=Lang(lang2)return input_lang,output_lang,pairs.startswith(eng_prefixes) 是字符串方法 startswith() 的调用。它用于检查一个字符串是否以指定的前缀开始。
MAX_LENGTH=10 # 定义语料最长长度eng_prefixes=("i am ","i m ","he is ","he s ","she is ","she s ","you are","you re ","we are","we re ","they are","they re "
)def filterPair(p):return len(p[0].split(' '))<MAX_LENGTH and \len(p[1].split(' '))<MAX_LENGTH and p[1].startswith(eng_prefixes)def filterPairs(pairs):# 选取仅仅包含 eng_prefixes 开头的语料return [pair for pair in pairs if filterPair(pair)]def prepareData(lang1,lang2,reverse=False):# 读取文件中的数据input_lang,output_lang,pairs=readLangs(lang1,lang2,reverse)print("Read %s sentence pairs" % len(pairs))# 按条件选取语料pairs=filterPairs(pairs[:])print("Trimmed to %s sentence pairs" % len(pairs))print("Counting words...")# 将语料保存至相应的语言类for pair in pairs:input_lang.addSentence(pair[0])output_lang.addSentence(pair[1])# 打印语言类的信息print("Counted words:")print(input_lang.name,input_lang.n_words)print(output_lang.name,output_lang.n_words)return input_lang,output_lang,pairsinput_lang,output_lang,pairs=prepareData('eng','fra',True)
print(random.choice(pairs))输出:
Reading lines...
Read 135842 sentence pairs
Trimmed to 10571 sentence pairs
Counting words...
Counted words:
fra 4345
eng 2802
['tu es fort avisee .', 'you re very wise .']二、Seq2Seq 模型
1. 编码器(Encoder)
class EncoderRNN(nn.Module):def __init__(self,input_size,hidden_size):super(EncoderRNN,self).__init__()self.hidden_size=hidden_sizeself.embedding=nn.Embedding(input_size,hidden_size)self.gru=nn.GRU(hidden_size,hidden_size)def forward(self,input,hidden):embedded=self.embedding(input).view(1,1,-1)output=embeddedoutput,hidden=self.gru(output,hidden)return output,hiddendef initHidden(self):return torch.zeros(1,1,self.hidden_size,device=device)2. 解码器(Decoder)
class AttnDecoderRNN(nn.Module):def __init__(self,hidden_size,output_size,dropout_p=0.1,max_length=MAX_LENGTH):super(AttnDecoderRNN,self).__init__()self.hidden_size=hidden_sizeself.output_size=output_sizeself.dropout_p=dropout_pself.max_length=max_lengthself.embedding=nn.Embedding(self.output_size,self.hidden_size)self.attn=nn.Linear(self.hidden_size*2,self.max_length)self.attn_combine=nn.Linear(self.hidden_size*2,self.hidden_size)self.dropout=nn.Dropout(self.dropout_p)self.gru=nn.GRU(self.hidden_size,self.hidden_size)self.out=nn.Linear(self.hidden_size,self.output_size)def forward(self,input,hidden,encoder_outputs):embedded=self.embedding(input).view(1,1,-1)embedded=self.dropout(embedded)attn_weights=F.softmax(self.attn(torch.cat((embedded[0],hidden[0]),1)),dim=1)attn_applied=torch.bmm(attn_weights.unsqueeze(0),encoder_outputs.unsqueeze(0))output=torch.cat((embedded[0],attn_applied[0]),1)output=self.attn_combine(output).unsqueeze(0)output=F.relu(output)output,hidden=self.gru(output,hidden)output=F.log_softmax(self.out(output[0]),dim=1)return output,hidden,attn_weightsdef initHidden(self):return torch.zeros(1,1,self.hidden_size,device=device)注意力机制的作用
注意力机制允许解码器在生成每个单词时,动态地关注编码器输出的不同部分。这有助于模型更好地捕捉输入和输出之间的对齐关系,尤其是在处理长序列时。注意力机制的关键步骤包括:
-
计算注意力权重:根据当前解码器状态和编码器输出,计算每个时间步的重要性。
-
应用注意力权重:将权重应用于编码器输出,得到加权的上下文向量。
-
结合上下文向量和嵌入向量:将注意力加权的上下文向量与当前输入嵌入结合,用于生成下一个单词。
三、训练
1. 数据预处理
# 将文本数字化,获取词汇index
def indexesFromSentence(lang,sentence):return [lang.word2index[word] for word in sentence.split(' ')]# 将数字化的文本,转化为tensor数据
def tensorFromSentence(lang,sentence):indexes=indexesFromSentence(lang,sentence)indexes.append(EOS_token)return torch.tensor(indexes,dtype=torch.long,device=device).view(-1,1)# 输入pair文本,输出预处理好的数据
def tensorFromPair(pair):input_tensor=tensorFromSentence(input_lang,pair[0])target_tensor=tensorFromSentence(output_lang,pair[1])return (input_tensor,target_tensor)2. 训练函数
teacher_forcing_ratio=0.5def train(input_tensor,target_tensor,encoder,decoder,encoder_optimizer,decoder_optimizer,criterion,max_length=MAX_LENGTH):# 编码器初始化encoder_hidden=encoder.initHidden()# grad 属性归零encoder_optimizer.zero_grad()decoder_optimizer.zero_grad()input_length=input_tensor.size(0)target_length=target_tensor.size(0)# 用于创建一个指定大小的全零张量(tensor),用作默认编码器输出encoder_outputs=torch.zeros(max_length,encoder.hidden_size,device=device)loss=0# 将处理好的语料送入编码器for ei in range(input_length):encoder_output,encoder_hidden=encoder(input_tensor[ei],encoder_hidden)encoder_outputs[ei]=encoder_output[0,0]# 解码器默认输出decoder_input=torch.tensor([[SOS_token]],device=device)decoder_hidden=encoder_hiddenuse_teacher_forcing=True if random.random()<teacher_forcing_ratio else False# 将编码器处理好的输出送入解码器if use_teacher_forcing:# Teacher forcing: Feed the target as the next inputfor di in range(target_length):decoder_output,decoder_hidden,decoder_attention=decoder(decoder_input,decoder_hidden,encoder_outputs)loss+=criterion(decoder_output,target_tensor[di])decoder_input=target_tensor[di] # Teacher forcingelse:# Without teacher forcing: use its own predictions as the next inputfor di in range(target_length):decoder_output,decoder_hidden,decoder_attention=decoder(decoder_input,decoder_hidden,encoder_outputs)topv,topi=decoder_output.topk(1)decoder_input=topi.squeeze().detach() # detach from historyloss+=criterion(decoder_output,target_tensor[di])if decoder_input.item()==EOS_token:breakloss.backward()encoder_optimizer.step()decoder_optimizer.step()return loss.item()/target_lengthimport time,mathdef asMinutes(s):m=math.floor(s/60)s-=m*60return '%dm %ds' % (m,s)def timeSince(since,percent):now=time.time()s=now-sincees=s/(percent)rs=es-sreturn '%s (- %s)' % (asMinutes(s),asMinutes(rs))def trainIters(encoder,decoder,n_iters,print_every=1000,plot_every=100,learning_rate=0.01):start=time.time()plot_losses=[]print_loss_total=0 # Reset every print_everyplot_loss_total=0 # Reset every plot_everyencoder_optimizer=optim.SGD(encoder.parameters(),lr=learning_rate)decoder_optimizer=optim.SGD(decoder.parameters(),lr=learning_rate)# 在 pairs 中随机选取 n_iters 条数据用作训练集training_pairs=[tensorFromPair(random.choice(pairs)) for i in range(n_iters)]criterion=nn.NLLLoss()for iter in range(1,n_iters+1):training_pair=training_pairs[iter-1]input_tensor=training_pair[0]target_tensor=training_pair[1]loss=train(input_tensor,target_tensor,encoder,decoder,encoder_optimizer,decoder_optimizer,criterion)print_loss_total+=lossplot_loss_total+=lossif iter % print_every==0:print_loss_avg=print_loss_total/print_everyprint_loss_total=0print('%s (%d %d%%) %.4f' % (timeSince(start,iter/n_iters),iter,iter/n_iters*100,print_loss_avg))if iter % plot_every==0:plot_loss_avg=plot_loss_total/plot_everyplot_losses.append(plot_loss_avg)plot_loss_total=0return plot_losses3. 评估
def evaluate(encoder,decoder,sentence,max_length=MAX_LENGTH):with torch.no_grad():input_tensor=tensorFromSentence(input_lang,sentence)input_length=input_tensor.size()[0]encoder_hidden=encoder.initHidden()encoder_outputs=torch.zeros(max_length,encoder.hidden_size,device=device)for ei in range(input_length):encoder_output,encoder_hidden=encoder(input_tensor[ei],encoder_hidden)encoder_outputs[ei]+=encoder_output[0,0]decoder_input=torch.tensor([[SOS_token]],device=device) # SOSdecoder_hidden=encoder_hiddendecoded_words=[]decoder_attentions=torch.zeros(max_length,max_length)for di in range(max_length):decoder_output,decoder_hidden,decoder_attention=decoder(decoder_input,decoder_hidden,encoder_outputs)decoder_attentions[di]=decoder_attention.datatopv,topi=decoder_output.data.topk(1)if topi.item()==EOS_token:decoded_words.append('<EOS>')breakelse:decoded_words.append(output_lang.index2word[topi.item()])decoder_input=topi.squeeze().detach()return decoded_words,decoder_attentions[:di+1]def evaluateRandomly(encoder,decoder,n=5):for i in range(n):pair=random.choice(pairs)print('>',pair[0])print('=',pair[1])output_words,attentions=evaluate(encoder,decoder,pair[0])output_sentence=' '.join(output_words)print('<',output_sentence)print('')四、训练与评估
hidden_size=256
encoder1=EncoderRNN(input_lang.n_words,hidden_size).to(device)
attn_decoder1=AttnDecoderRNN(hidden_size,output_lang.n_words,dropout_p=0.1).to(device)plot_losses=trainIters(encoder1,attn_decoder1,10000,print_every=5000)输出:
1m 31s (- 1m 31s) (5000 50%) 2.8547
3m 2s (- 0m 0s) (10000 100%) 2.2765evaluateRandomly(encoder1,attn_decoder1)输出:
> tu es odieux .
= you re obnoxious .
< you re resilient . <EOS>> je suis toujours fier de ma famille .
= i m always proud of my family .
< i m a of my . . <EOS>> tu es trop suspicieux de tout .
= you re too suspicious about everything .
< you re too forward to go . <EOS>> je me suis amendee .
= i m reformed .
< i m being . . <EOS>> il est desireux d aller en chine .
= he is eager to go to china .
< he s in to to . . . <EOS>1. Loss图
import matplotlib.pyplot as plt
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
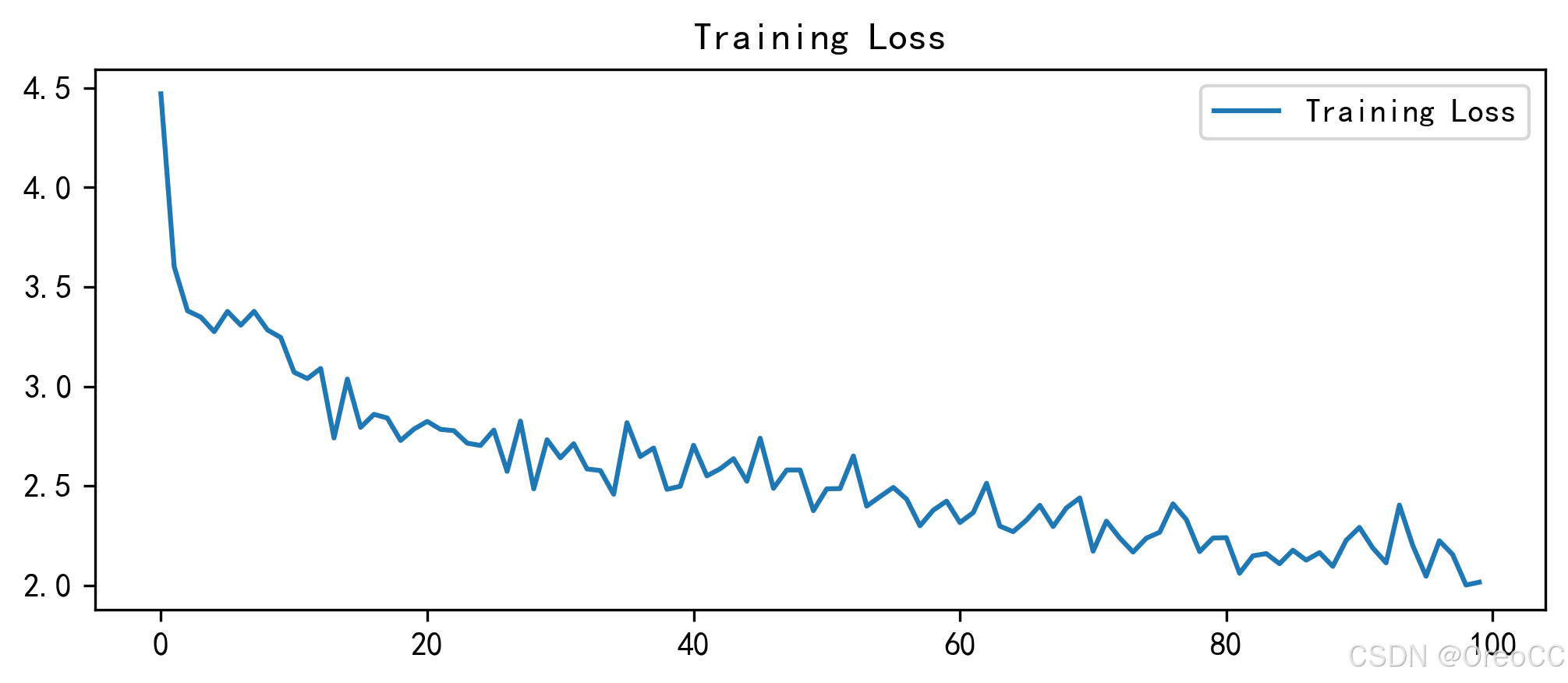
plt.rcParams['figure.dpi']=300 # 分辨率epochs_range=range(len(plot_losses))plt.figure(figsize=(8,3))plt.subplot(1,1,1)
plt.plot(epochs_range,plot_losses,label='Training Loss')
plt.legend(loc='upper right')
plt.title('Training Loss')
plt.show()输出:
2. 可视化注意力
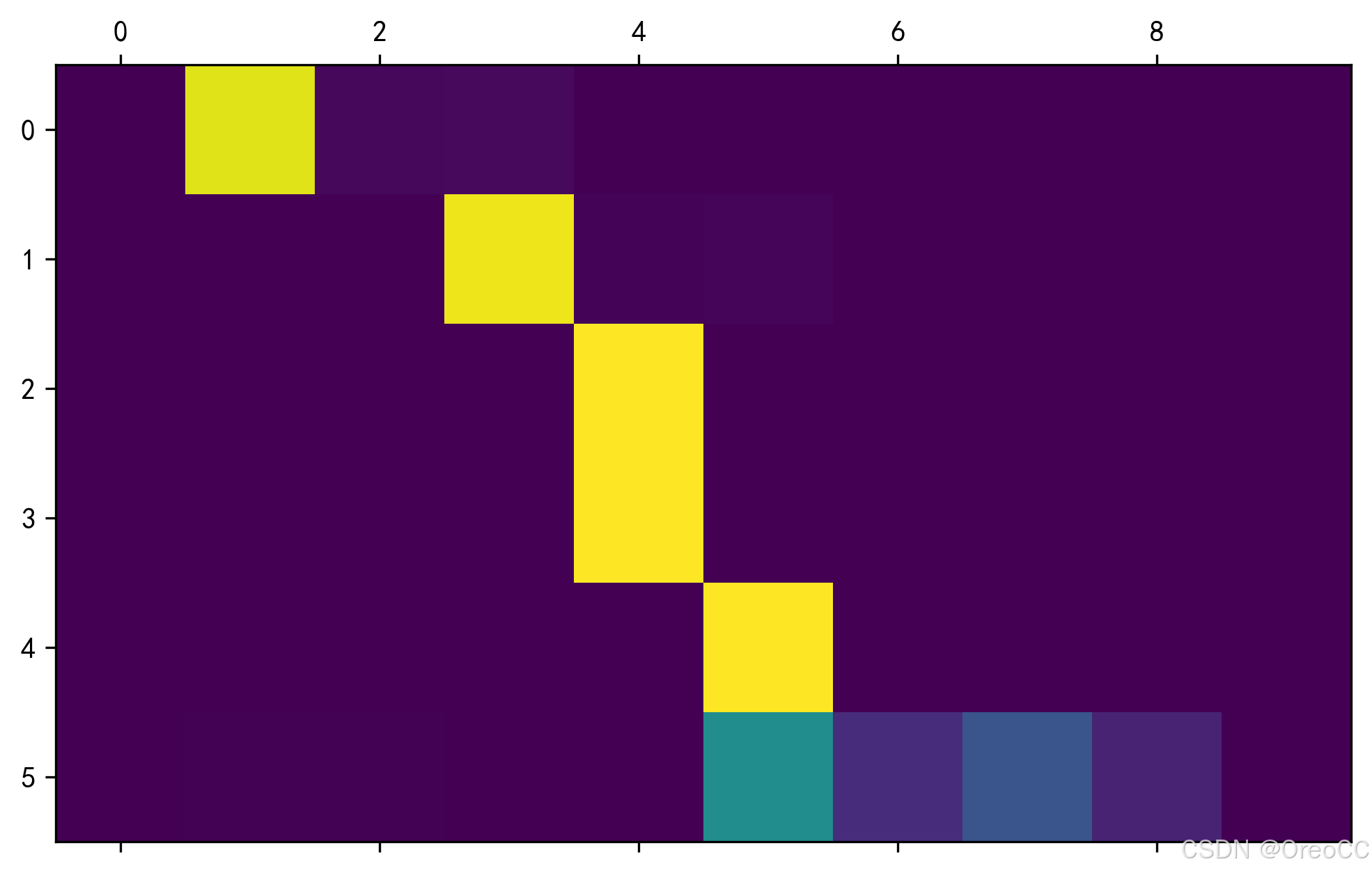
import matplotlib.pyplot as pltoutput_words,attentions=evaluate(encoder1,attn_decoder1,"je suis trop froid .")
plt.matshow(attentions.numpy())输出:
<matplotlib.image.AxesImage at 0x1d2d82c66d0>
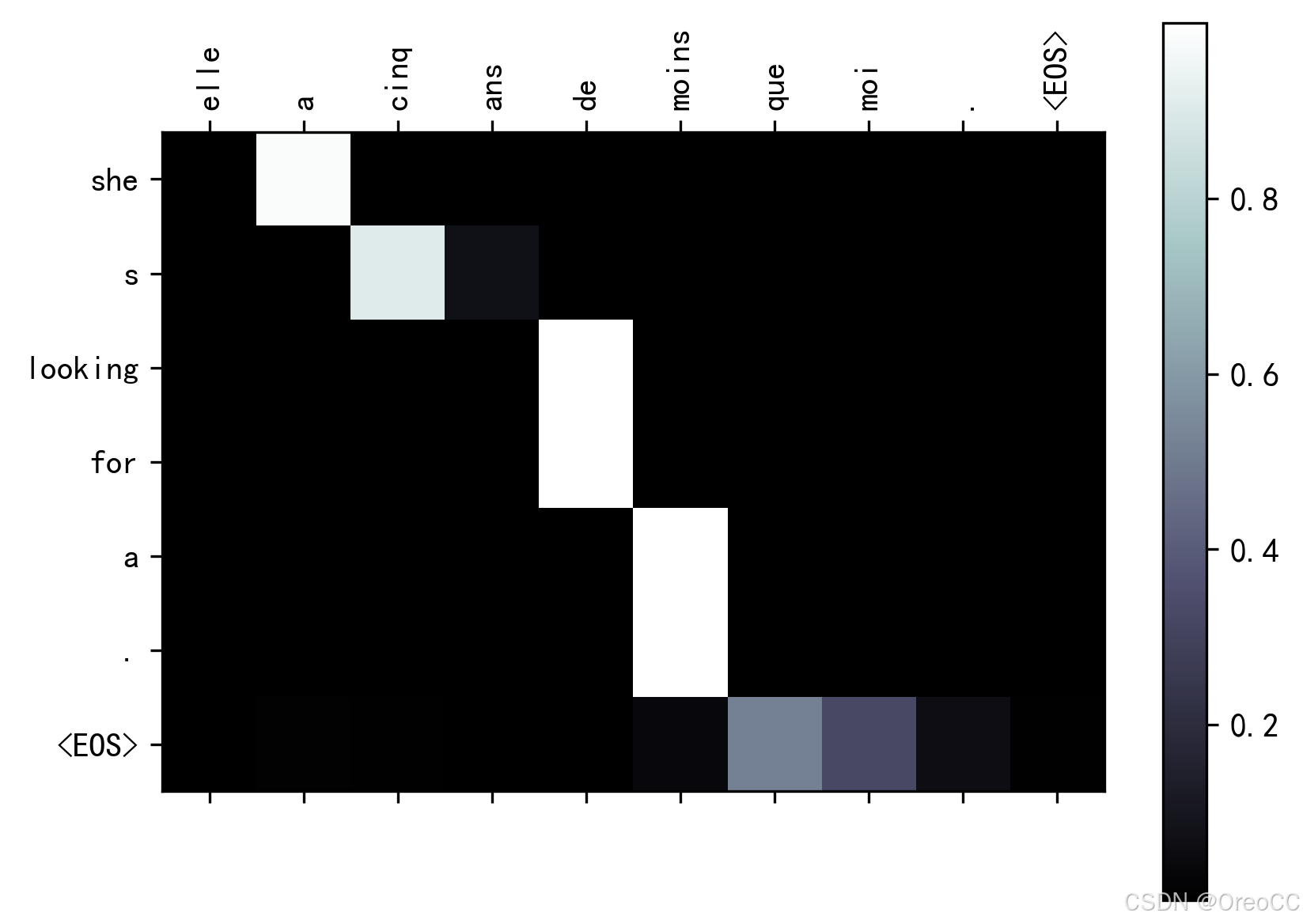
import matplotlib.ticker as tickerdef showAttention(input_sentence,output_words,attentions):# Set up figure with colorbarfig=plt.figure()ax=fig.add_subplot(111)cax=ax.matshow(attentions.numpy(),cmap='bone')fig.colorbar(cax)# Set up axesax.set_xticklabels(['']+input_sentence.split(' ')+['<EOS>'],rotation=90)ax.set_yticklabels(['']+output_words)# Show label at every tickax.xaxis.set_major_locator(ticker.MultipleLocator(1))ax.yaxis.set_major_locator(ticker.MultipleLocator(1))plt.show()def evaluateAndShowAttention(input_sentence):output_words,attentions=evaluate(encoder1,attn_decoder1,input_sentence)print('input =',input_sentence)print('output =',' '.join(output_words))showAttention(input_sentence,output_words,attentions)evaluateAndShowAttention("elle a cinq ans de moins que moi .")
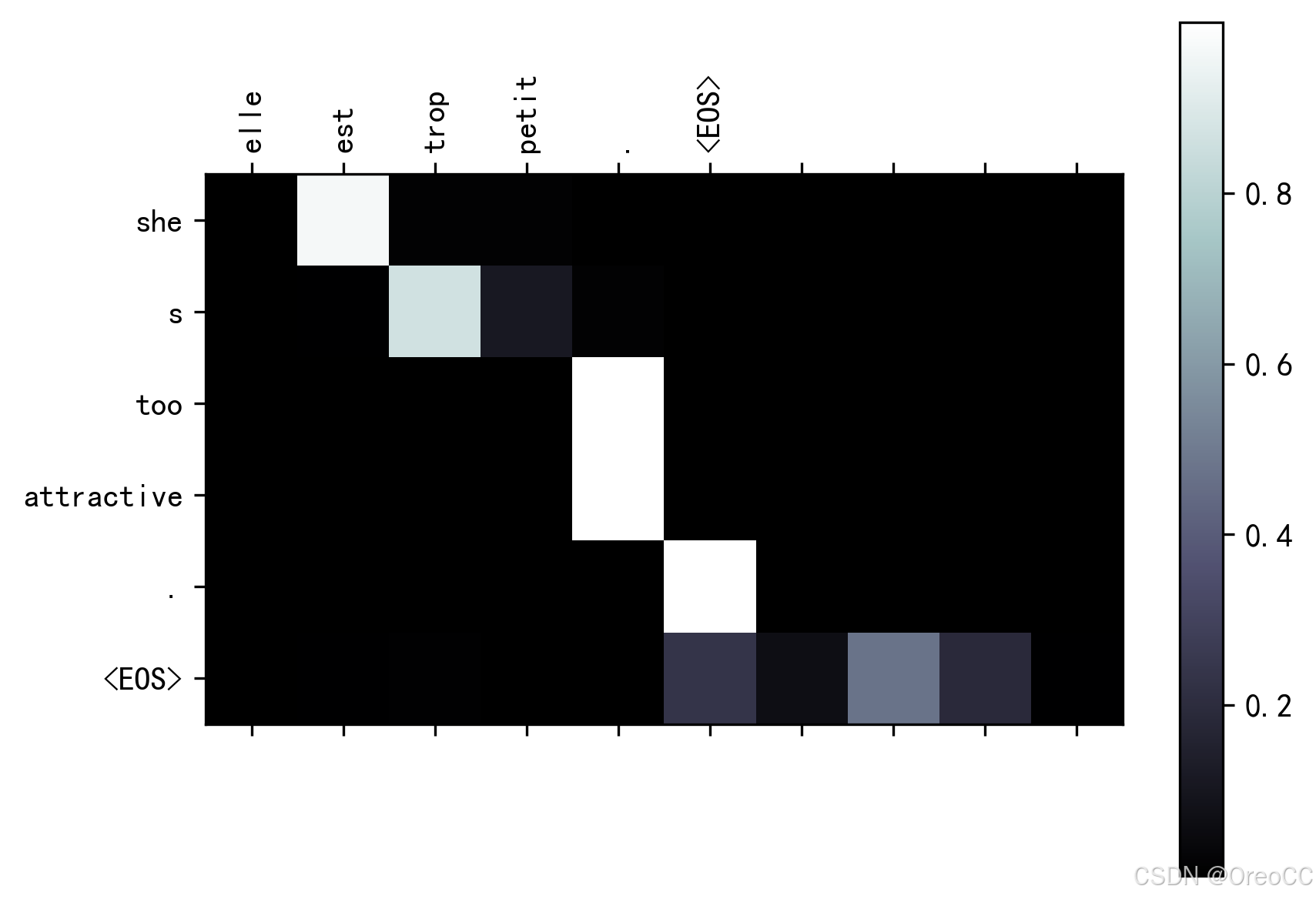
evaluateAndShowAttention("elle est trop petit .")
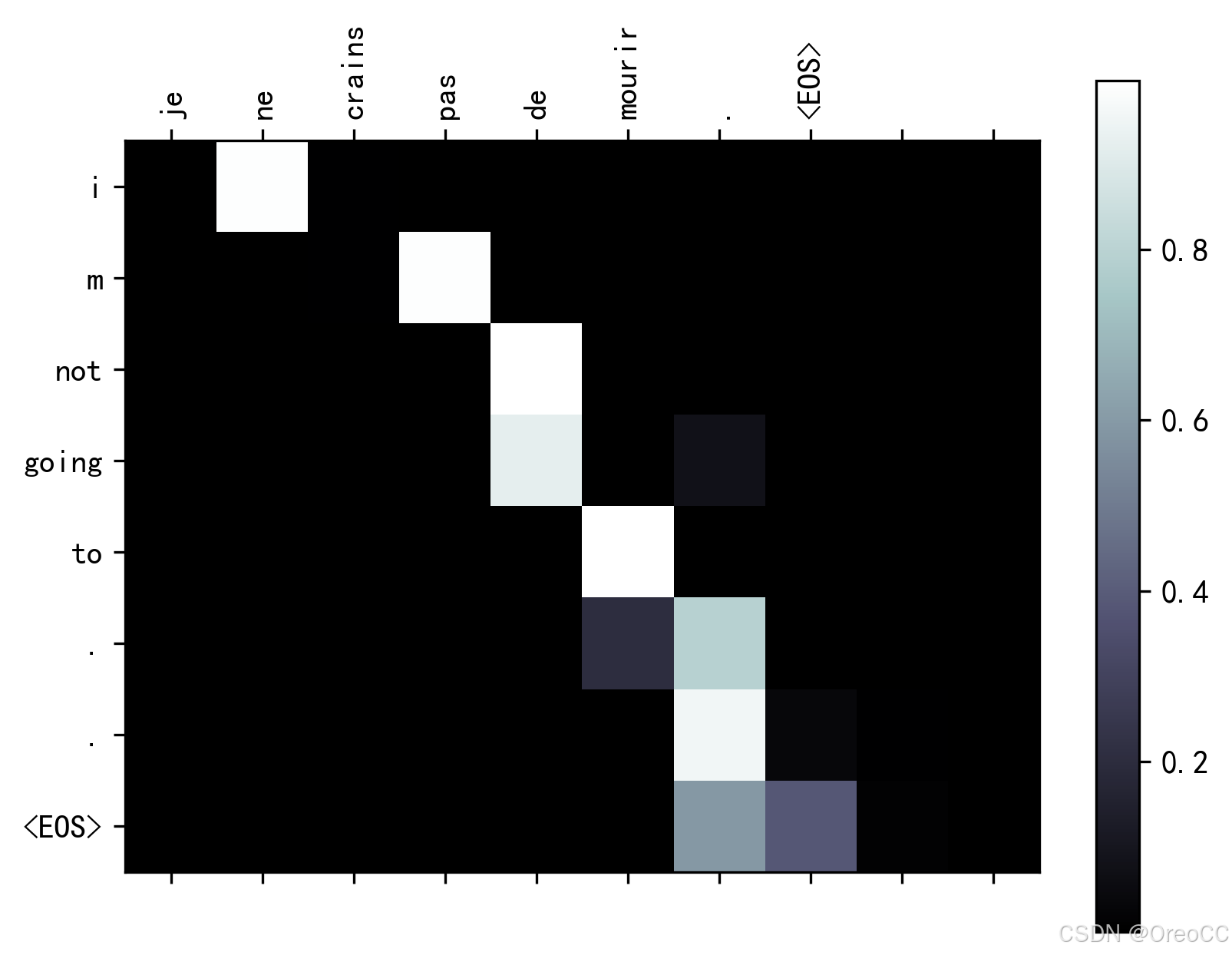
evaluateAndShowAttention("je ne crains pas de mourir .")
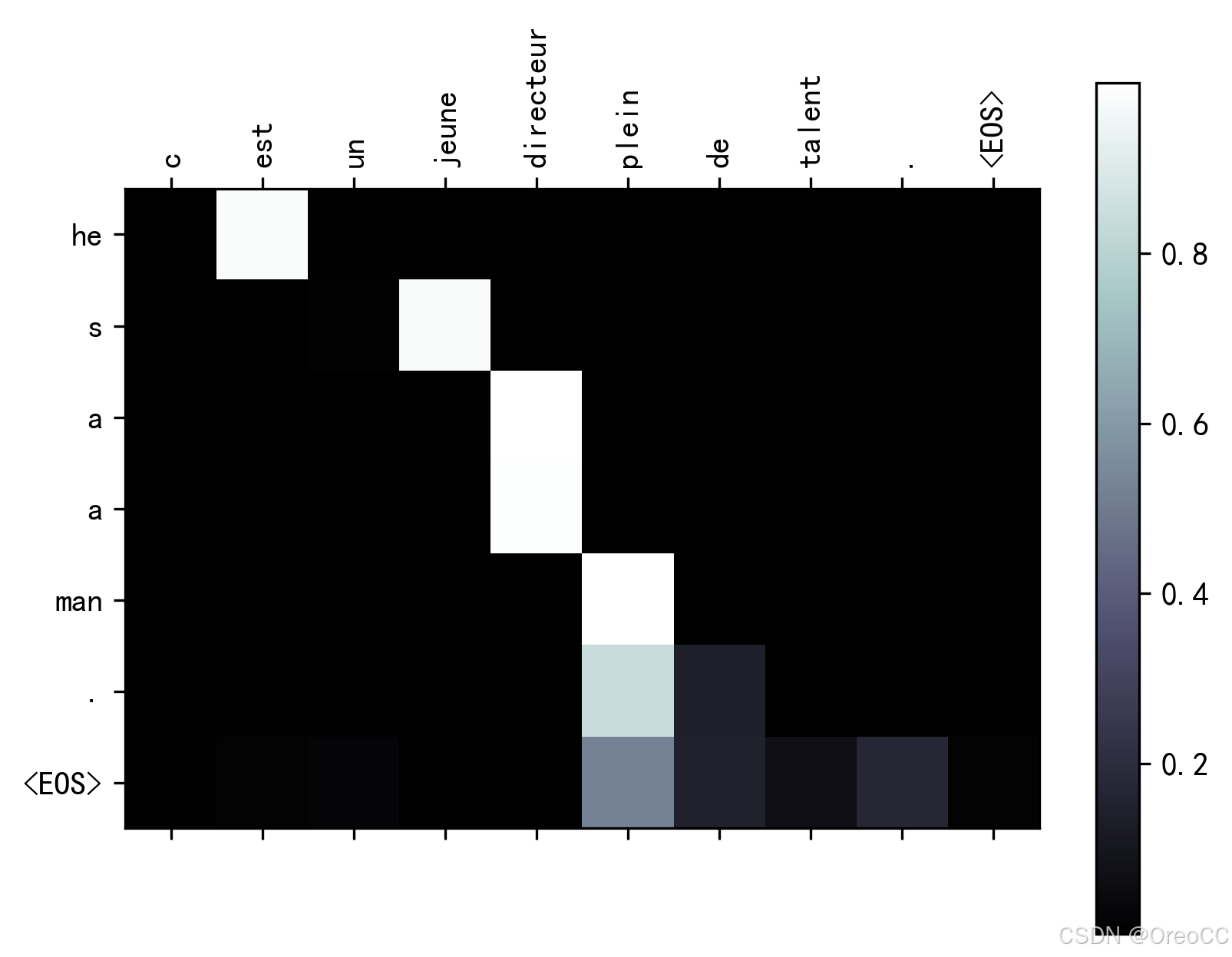
evaluateAndShowAttention("c est un jeune directeur plein de talent .")输出:
input = elle a cinq ans de moins que moi . output = she s looking for a . <EOS>
input = elle est trop petit . output = she s too attractive . <EOS>
input = je ne crains pas de mourir . output = i m not going to . . <EOS>
input = c est un jeune directeur plein de talent . output = he s a a man . <EOS>
五、心得体会
理解了注意力机制的添加过程。


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

