我吐槽过,reuseport socket 没做一致性 hash,socket 新建或者退出时,会对所有 session 产生影响:
- 新建 socket 会追加到 group 最后,增加组员数量 num,进而影响 hvalue % num 结果;
- socket 退出时会用 group 最后一个 socket 替换退出者的 index,递减组员数量,影响 hash 结果。
要做一致性 hash,需要单独写 ebpf 程序 attach 到 reuseport lookup 的位置,但要想实现这个 ebpf 程序其实也麻烦,因为相当于你要手工跟踪和维护 socket 的 slot index,比方说 session k 会映射到 index = m 的一个socket m,但由于某个 socket 退出,socket m 的 index 发生了变化,要想捕捉到这个变化以重建映射,需要监控 socket 退出事件并持续跟踪 socket m 的原始 slot index,这件事可做,但非常繁琐。
还是老方法,麻烦的事情需要拿点东西来换。这次拿点 standby 或占位符来换。
如果我需要在 n 个 reuseport socket 之间做一致性 hash 映射,我会创建 n + d 个 reuseport socket,k 可以从 1 到 n 不等,然后我的 ebpf 始终只做 index = hvalue % n 即可,这种情况下,即使 n 个 socket 中有一个挂了,后面那 d 个 standby socket 的最后一个马上就填充了退出者的位置,接管服务,可谓透明无感。
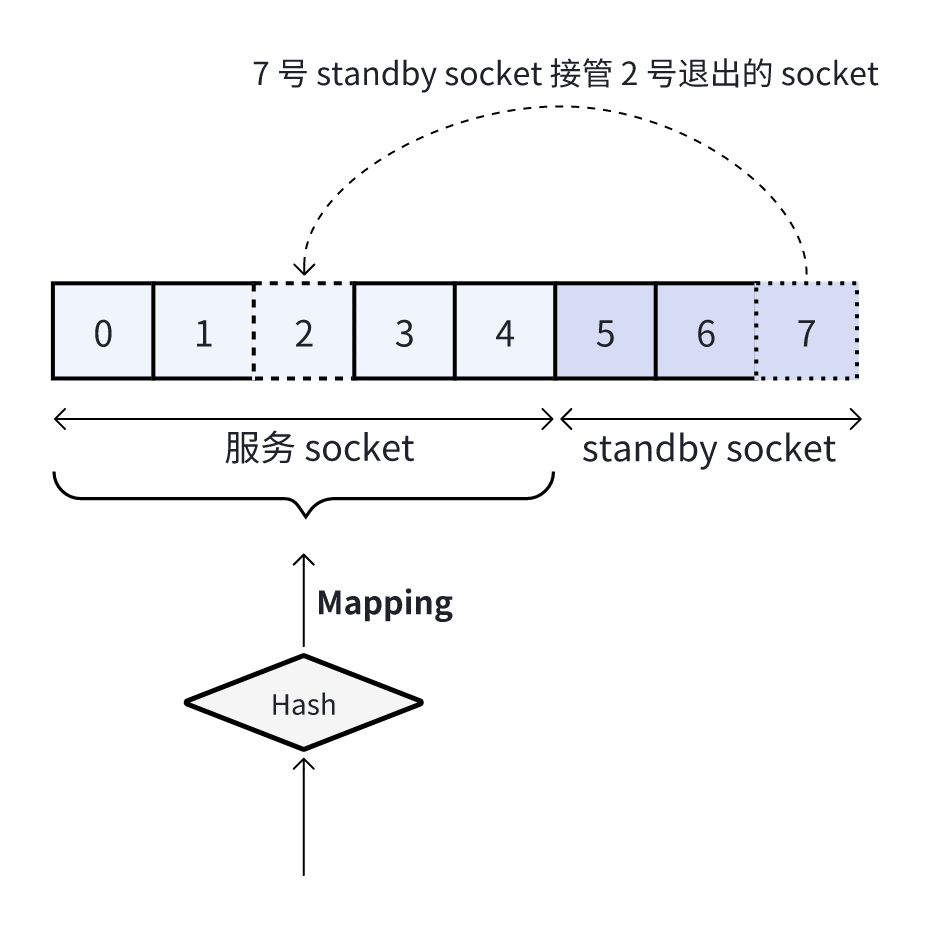
核心思想是,由 ebpf 程序自行控制从哪里到哪里进行 hash,而不是有多少算多少,全部参与运算。示例代码如下:
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <bpf/bpf_helpers.h>#define FIRST_N 4SEC("sk_reuseport")
int reuseport_prog(struct sk_reuseport_md *ctx)
{void *data = (void *)(long)ctx->data;void *data_end = (void *)(long)ctx->data_end;struct ethhdr *eth = data;if (data + sizeof(*eth) > data_end)return SK_DROP;data += sizeof(*eth);struct iphdr *ip = data;if (data + sizeof(*ip) > data_end)return SK_DROP;data += ip->ihl * 4;struct udphdr *udp = data;if (data + sizeof(*udp) > data_end)return SK_DROP;__u64 hash = ip->saddr;hash = hash * 31 + ip->daddr;hash = hash * 31 + udp->source;hash = hash * 31 + udp->dest;return hash % FIRST_N;
}
这个一致性 hash 策略也将大大降低昨天我那个热升级方案的复杂性。假设旧版本服务有 m 个 reuseport socket,新版本 socket 有 n 个,我在升级的时候,会创建 n + m 个 reuseport socket,其中后面 m 个并不提供任何服务,它们只是在前面旧版本服务退出后占位符,等到旧版本服务全部退出后,它们也将按顺序集体退出,这样真正的新版本服务 socket index 只需要一次新集体平移 m 个单位即可:

唯一的问题还是需要服务自行跟踪和维护自己的 index,所以 reuseport 至少还缺一个 getsockopt 调用:SO_REUSEPORT_GETINDEX:
void get_reuseport_index(int sockfd)
{int index;socklen_t len = sizeof(index);if (getsockopt(sockfd, SOL_SOCKET, SO_REUSEPORT_GETINDEX, &index, &len) == 0) {printf("This socket is at index %d in the reuseport group\n", index);} else {perror("getsockopt(SO_REUSEPORT_GETINDEX) failed");}
}
否则,就要通过下面的非常规手段获得进程 pid,socket index 的关系:
// 运行方法 bpftrace ./trace.btkprobe:reuseport_add_sock
{$pid = pid;$sk = (struct sock *)arg1;$port = (($sk->__sk_common.skc_num & 0xff) << 8) | (($sk->__sk_common.skc_num >> 8) & 0xff);$reuseport = (struct sock_reuseport *)($sk->sk_reuseport_cb);printf("add sock PID: %d, Port: %d, Sock:%p\n", $pid, $port, $sk);printf("curr num_socks and this index is %d \n", $reuseport->num_socks);
}kprobe:reuseport_detach_sock
{$pid = pid;$sk = (struct sock *)arg0;$port = (($sk->__sk_common.skc_num & 0xff) << 8) | (($sk->__sk_common.skc_num >> 8) & 0xff);$reuseport = (struct sock_reuseport *)($sk->sk_reuseport_cb);printf("remove sock PID: %d, Port: %d, Sock:%p\n", $pid, $port, $sk);printf("curr num_socks and this index is %d \n", $reuseport->num_socks);
}
这些关系被打印出来只是在这篇文章中被看清,实际上应该保存起来备用,在 SO_REUSEPORT_GETINDEX 被支持之前,这个信息非常重要。
注意,下面的方法不能保证导出的顺序就是 reuseport socket group 的 index 顺序,慎用!甚至 proc/$pid/fd 的链接时间戳都不好使:
root@vbox:/proc/net# cat udpsl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops384: 00000000:3039 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 16567 2 00000000c107c9c0 0384: 00000000:3039 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 15892 2 00000000023d3ee4 0
root@vbox:~# ls -l /proc/1000/fd
total 0
lrwx------ 1 root root 64 Mar 31 21:30 0 -> /dev/pts/0
lrwx------ 1 root root 64 Mar 31 21:30 1 -> /dev/pts/0
lrwx------ 1 root root 64 Mar 31 21:30 2 -> /dev/pts/0
lrwx------ 1 root root 64 Mar 31 21:30 3 -> 'socket:[15892]'
浙江温州皮鞋湿,下雨进水不会胖。




