YOLOv1
Yolo目标检测背景
目标检测的两个步骤可以概括为:
- 检测目标位置(生成检测框
(x, y, w, h, c(置信度), p(概率)) - 对目标物体进行分类
当前主流的算法主要分为两种
- 单阶段的(将目标位置的检测和分类单阶段完成)——Yolo算法
- 双阶段的(先检测位置,再进行分类,双阶段进行)——faster RCNN
Yolo的主要思想:将目标检测任务看作一个回归问题,在一个神经网络中同时预测目标的位置和类别
网络结构
总体结构
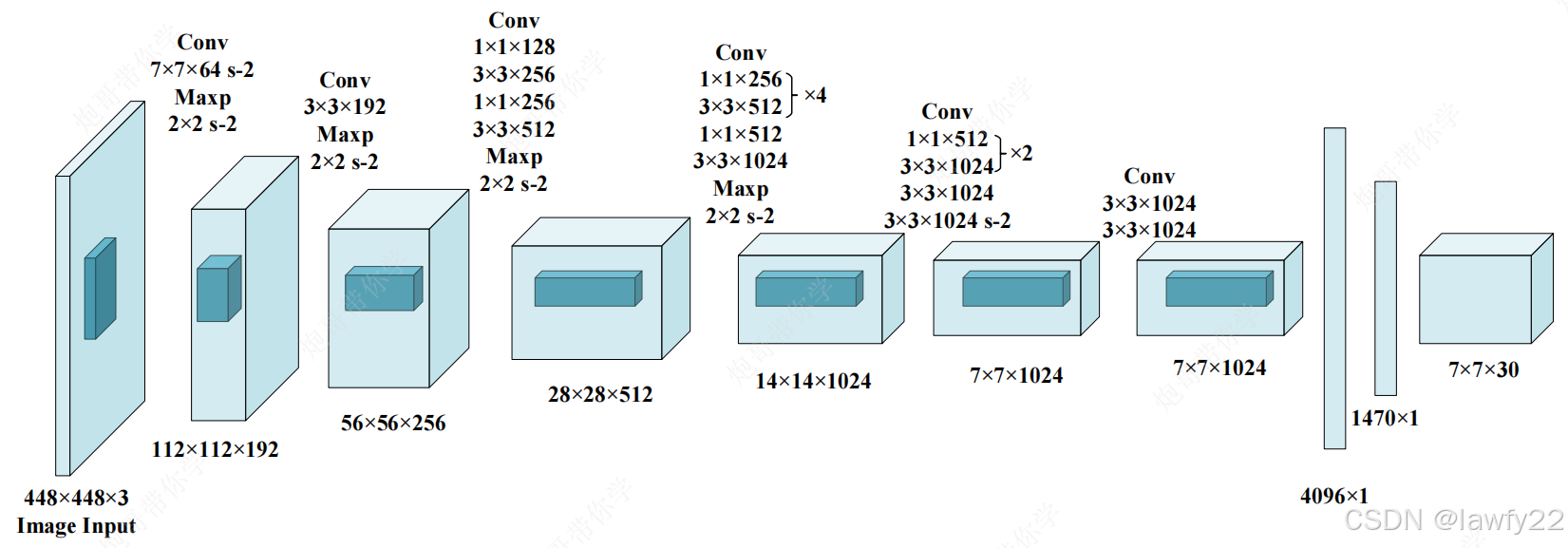
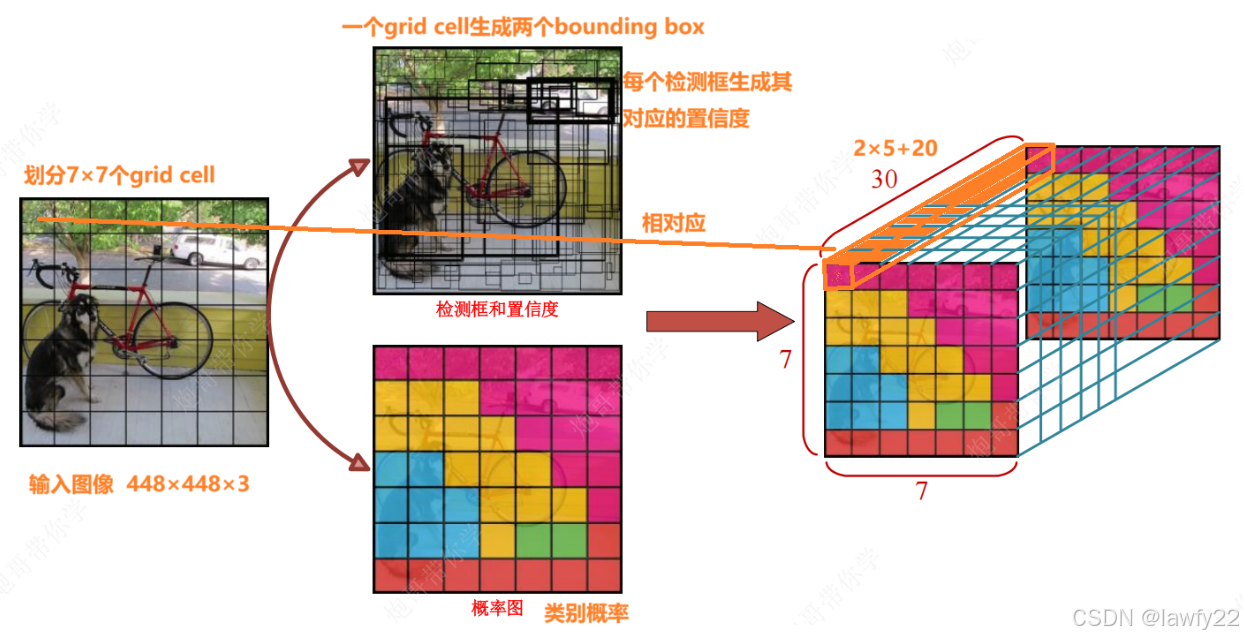
与传统的一些CNN网络相比,Yolov1进行目标检测的关键在最后一个7×7×30的张量(包含(x, y, w, h, p, c)的一些信息),进行目标检测
在图像特征提取时,我们通常希望图片的尺寸越来越小,而通道数越来越多
输入:448*448的图像
网络骨干与输出:
- 若干个卷积层和池化层,将图像变为7*7*1024的张量
- 最后经过两层全连接层,输出维度为7*7*30的张量
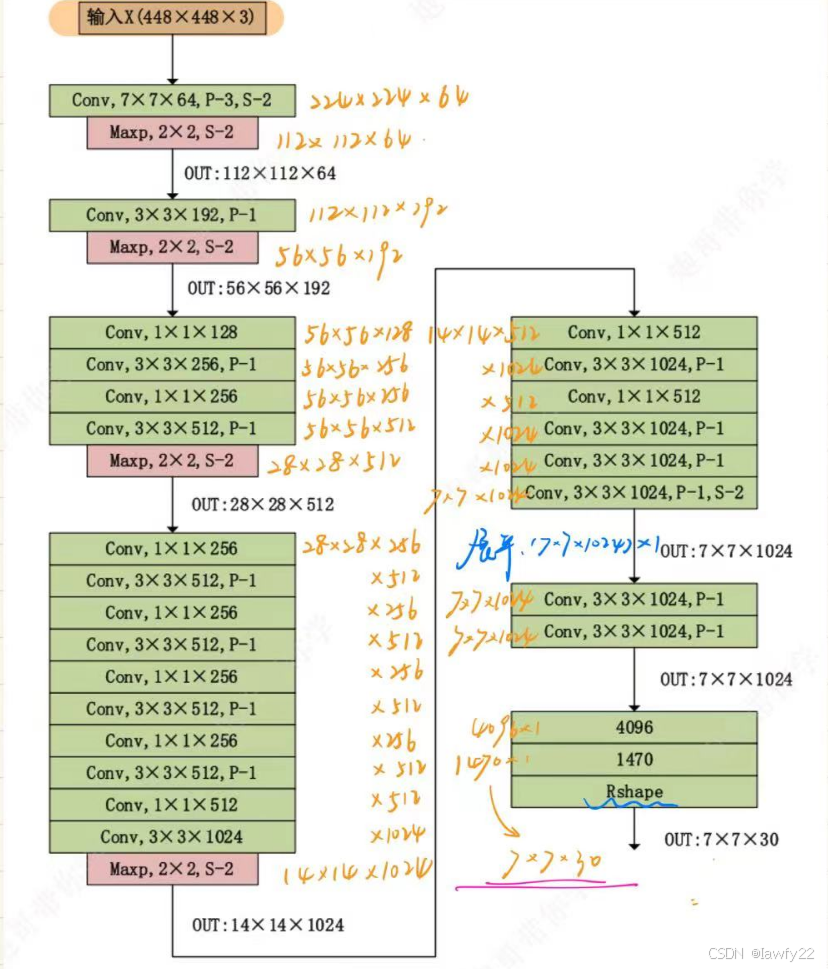
网络细节
- 除了最后一层使用线性激活函数外,其余层的激活函数函数使用**
Leaky ReLU** - 在训练中使用了Dropout与数据增强的方法防止过拟合(尤其是全连接层中,参数量很大,必须要防止过拟合)
- 对于最后一个卷积层,输出形状为
(7, 7, 1024)的张量;然后将张量展开,使用两个全连接层作为一种线性回归,输出1470个参数,然后reshape为(7, 7, 30)
网络参数
卷积计算公式:
O H = H + 2 P − F H S + 1 O W = W + 2 P − F W S + 1 OH = \frac{H+2P-FH}{S} + 1 \\ OW = \frac{W + 2P - FW}{S} + 1 OH=SH+2P−FH+1OW=SW+2P−FW+1
结果分析
输出结果
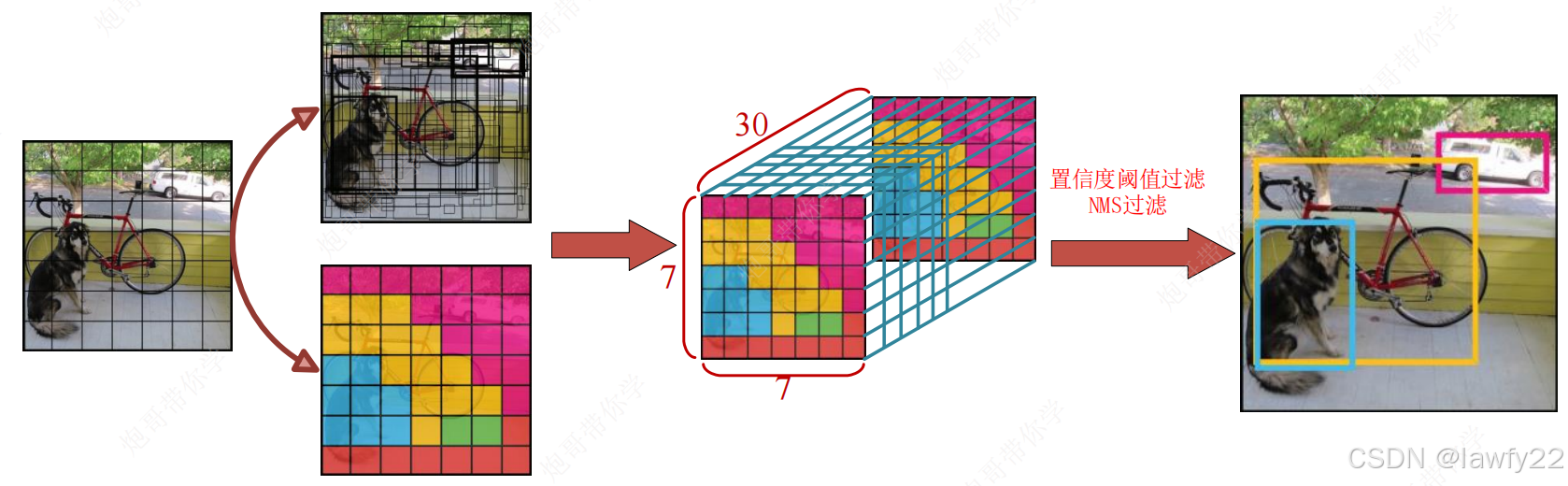
模型的最终输出的结果为**(7, 7, 30)的张量,对应的是原始图片对应区域的结果,即将原始图片划分为7×7个小方格大小的图片**

- 7×7对应原始图像划分的7×7个
grid cell - 30对应每个
grid cell中相关任务的结果信息
注意:
将原始图像划分为7×7个grid cell并不是真正地将图片划分,而是将图片输出的结果映射到7×7的小方格里,每个结果向量(30×1)对应图片的对应区域
对于每个grid cell:
- 预测
B个边界框(v1中选择两个边界框作为预测结果) - 每个边界框包含五个元素——
(x, y, w, h, c),即中心坐标 x 和 y ,检测框的宽和高 w 和 h,对应检测框的置信度c - 一共有二十个类别,因此每个
grid cell还有20个类别物体对应的概率值(各个边界框共用一组类别概率)
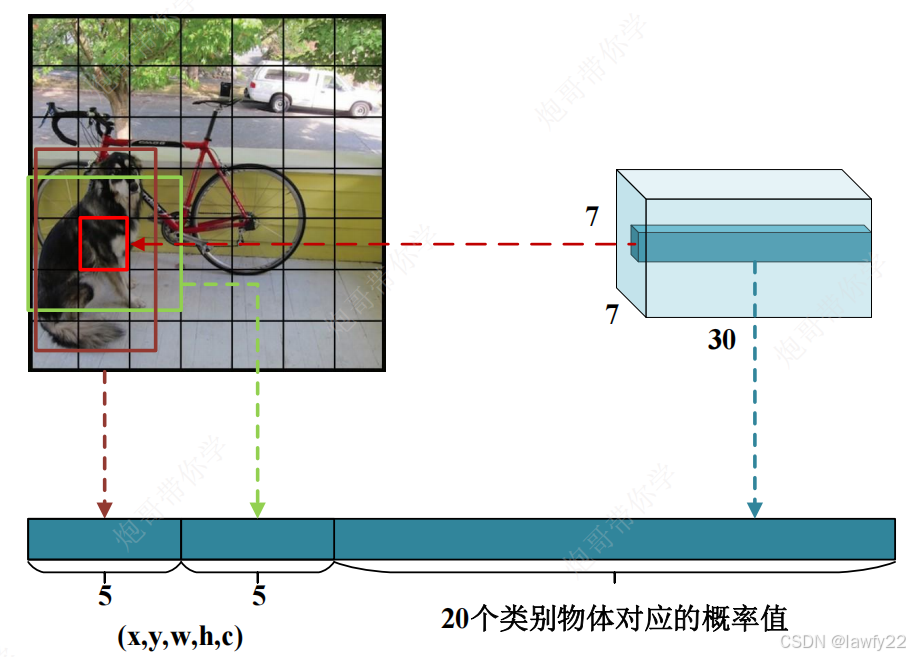
30 = 2(两个框)×5(五个边界框信息)×20(类别概率值)
(x, y, w, h)表示
对于每个grid cell,其左上角坐标为(0,0),
- 每个
(x, y)是检测框(bounding box)的中心坐标,且一定在bounding box内部,该坐标值是归一化后的坐标值,在0–1之间,以左上角坐标(0,0)为参考 w, h是指检测框的宽和高,也是归一化到了0–1之间,表示相对于原始图像的宽和高
IOU
IOU的全称为交并比,该方法计算的是“预测的边框”和“真实的边框”的交集和并集的比值
I O U = 交集 并集 IOU = \frac{交集}{并集} IOU=并集交集
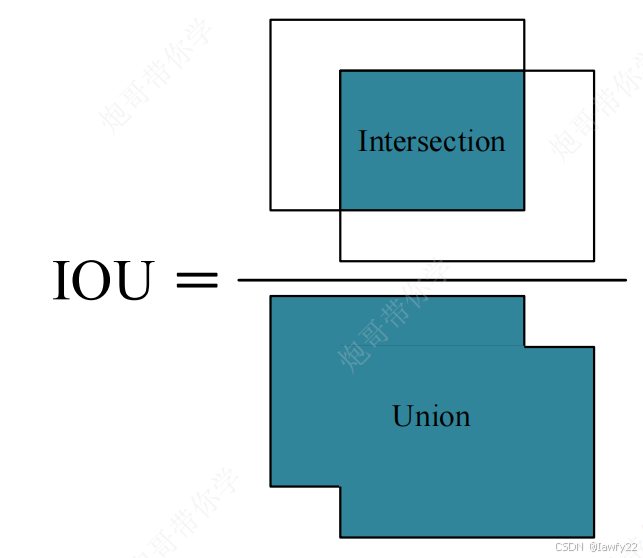
IOU的值在0–1之间——IOU越大,说明预测框和真实框的越接近
置信度
置信度有两重定义:
- 代表当前的
bounding box内有对象的概率值 P r ( O b j e c t ) Pr(Object) Pr(Object),其值为1或者0 - 表示当前的
bounding box有对象时,他自己预测的bounding box与物体真实的box之间的IOU(表示的是模型表达自己框出了物体的自信程度)
置信度的公式为:
C = P r ( O b j e c t ) ∗ I O U p r e d t r u e C = Pr(Object)*IOU^{true}_{pred} C=Pr(Object)∗IOUpredtrue
概率值
数据集中共有20个类别,对应20个类别的概率值
如下图,每个小方格都会输出20个类别概率,且两个预测框(bounding box)共用一组概率值,且最终会保留概率值最高的类别
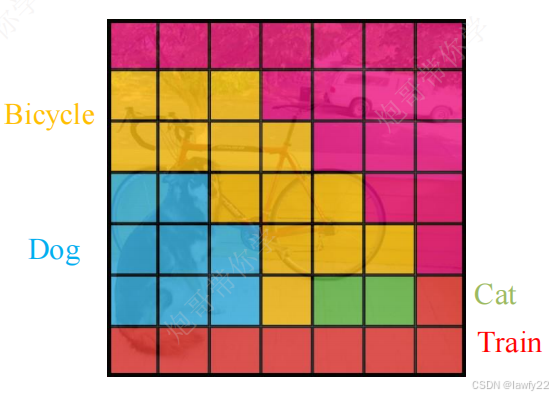
输出的概率使用Softmax函数进行映射,维度为20×1
概率值输出
类别置信度
类别置信度是指在有物体的情况下,对应类别的物体的置信度
c = P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u e = P r ( C l a s s i ) ∗ I O U p r e d t r u e c = Pr(Class_i|Object)*Pr(Object)*IOU^{true}_{pred}=Pr(Class_i)*IOU^{true}_{pred} c=Pr(Classi∣Object)∗Pr(Object)∗IOUpredtrue=Pr(Classi)∗IOUpredtrue
表示:框出box内确实有物体和物体类型的自信程度
类别置信度过滤:计算每个框的类别置信度,然后把值较小的筛去,为类别置信度
非极大值抑制NMS
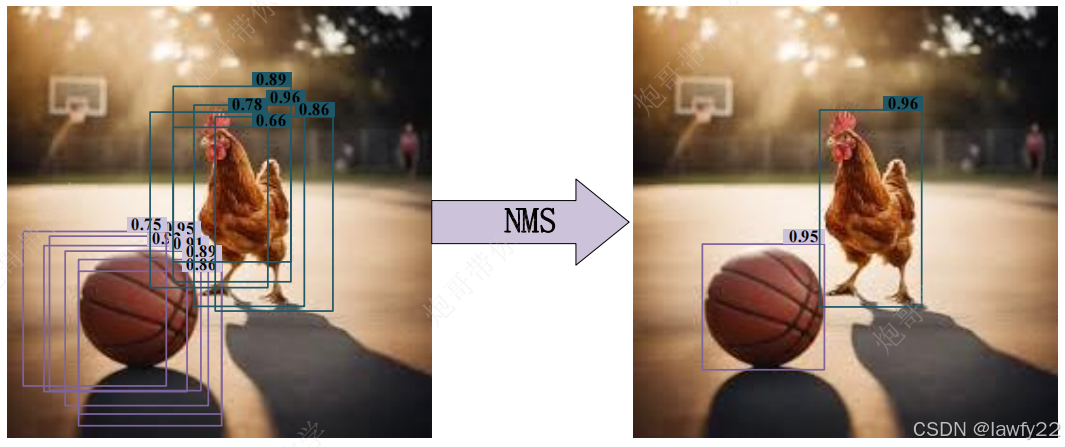
NMS算法主要作用:针对不同类别检测框独立且并行处理,对图像中的检测框进行去重
如果不使用该算法进行去重,则一个目标会有多个检测框
算法流程
- 选取篮球检测框中置信度最大的那一个
box,记作box_best,并且保留 - 计算
box_best与其他的篮球检测框的IOU,同时指定一个阈值(通常设置为0.5 - 如果
IOU > 0.5,那么就舍弃这个box(交并比比较大,说明两个box可能表示同一个目标,所以保留置信度最高的那个) - 从最后剩余的所有
box里,再找到最大置信度的那一个,如此重复计算
最终输出
损失函数
由于最终的输出形式为 (x, y, w, h, c) + p,其中(x, y, w, h)代表坐标(位置),c为置信度,p为类别,因此可以将损失函数划分为三个方面:
- 坐标损失
- 置信度损失
- 类别损失

坐标损失
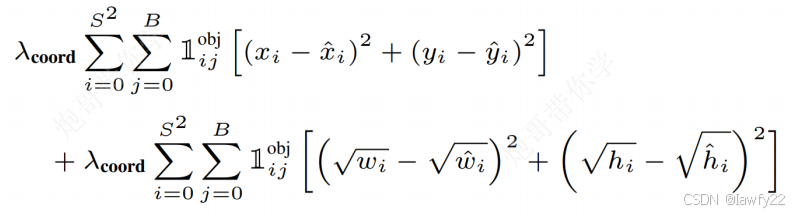
包含两个损失:
- 中心点坐标损失,使用平方差损失
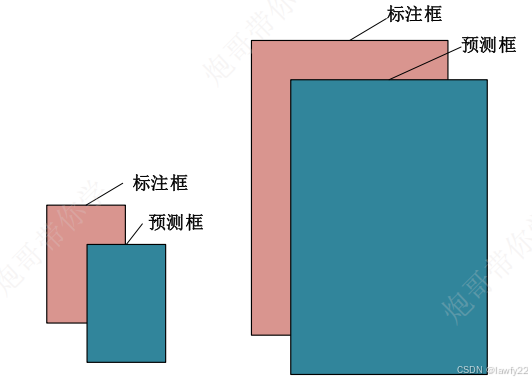
bounding box损失,先对h, w进行开根号后计算平方差
bounding box损失计算原理:对于两个大小差别很大的物体(假设大物体的宽度误差为 ( w 1 − w 1 ′ ) 2 (w_1 - w_1')^2 (w1−w1′)2,小物体的宽度误差为 ( w 2 − w 2 ′ ) 2 (w_2 - w_2')^2 (w2−w2′)2),当大物体的检测效果较好时,而由于其尺寸比较大( w 1 > > w 2 w_1 >> w_2 w1>>w2),导致 ( w 1 − w 1 ′ ) 2 > ( w 2 − w 2 ′ ) 2 (w_1 - w_1')^2 > (w_2 - w_2')^2 (w1−w1′)2>(w2−w2′)2,致使最后的训练失效
系数 λ c o o r d \lambda _{coord} λcoord 为 5,主要作用是缩放,强调检测目标的重要程度
置信度损失
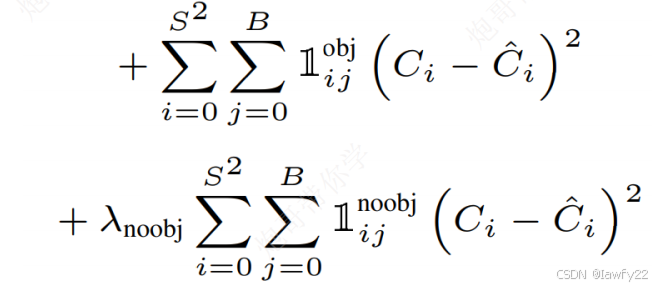
置信度针对于所有的bounding box(有对象和没有对象的都参与计算
- 当有对象的时候, C ^ i \hat C_i C^i 的标签值为预测框和标注框之间的
IOU交并比 - 当没有对象的时候, C ^ i \hat C_i C^i 的标签值为 0
系数 λ n o o b j \lambda _{noobj} λnoobj 为 0.5,主要作用是缩放,强调检测目标的重要程度
λ n o o b j \lambda _{noobj} λnoobj 和 λ c o o r d \lambda _{coord} λcoord 相差较大的原因:
一张图片中只有少数几个目标,而绝大部分区域是没有目标的,因此加这样的系数避免loss值过渡学习到没有目标的区域
概率损失
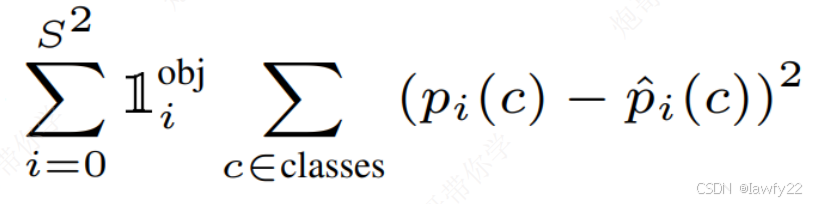
概率损失针对所有grid cell只有有对象的grid cell参与计算
模型总结
优点:
- 将物体检测定义为回归问题,不需要复杂的组件,比较简单,速度很快
- 基于全图进行检测,不用滑动窗口和预选区技术
缺点:
- v1准确率不高
- 在小物体上的定位效果较差
- 可以检测的目标物体比较少(最多只能检测49个结果)



)

)