
医学生集合啦,继续挑战 7天一篇nhanes机器学习SCI!
Day 1
进展:确定选题、期刊、文献
前面挑战了一期NHANES机器学习,大家使用NHANES的发文章的热情,火爆程度远超想象!我在下面的评论区看到大家的学习欲爆,也有师妹在私信我,问我能不能继续挑战。我这次依然是继续挑战使用nhanse数据库的数据写SCI,师弟师妹们太刻苦了,搞得我的pressure倍增
实际上是NHANES的高阶内容,数据始终是那些数据,该怎么用起来呢?公开数据库最难的点是数据的清洗,必须要认识到数据的结构和类型,如果我要去使用的话,我应该怎么去提取
经过大家的监督,我也成功挑战了多期GBD、NHANES的论文,大家会发现:方法学一定是最简单的,只要足够的时间和精力就一定能掌握的,这点challenge对于医学生而言简直小菜一碟。融入了机器学习这一个热点,即使以前自己处理过的或者已经发表过文章的数据,还能再次用来尝试这个一新的方法,也是一个新的方向,特别是对于我们这些“资源”较少的朋友来说
机器学习、人工智能一定是未来的方向,从诺贝尔奖到Pubmed那么多的高分文章来看,一定要抓住这一波机会
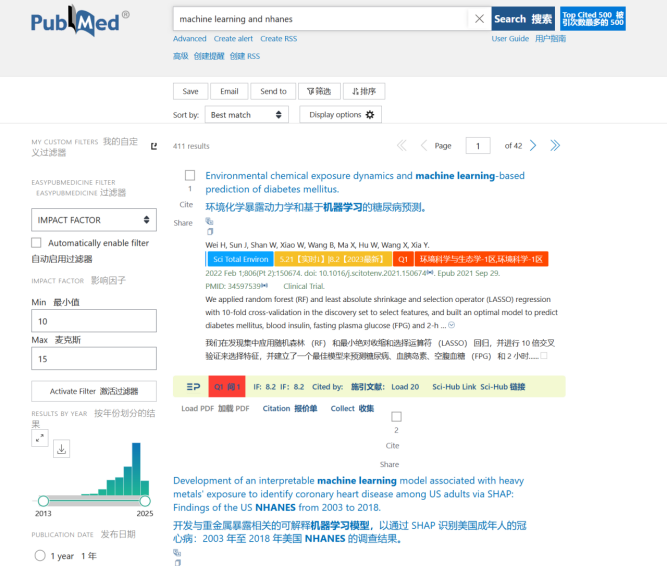
简单一搜,出来的文章可不简单,数量和质量都让人震惊。ML=machine learning,其中XGBOOST、随机森林等等单一模型的文章,还有多种、10种、100多种模型相互比较的文章。也会面临一个现实且严峻的问题,“我一个学医的,懂啥算法啊”但实际上这个担心我个人觉得有点儿多余,因为,他,新!整因为他新,所以所有人都在同一个起跑线!!或者说我只要能够使用数据跑的出来结果,能够解释结果,发几篇SCI文章,完全绰绰有余
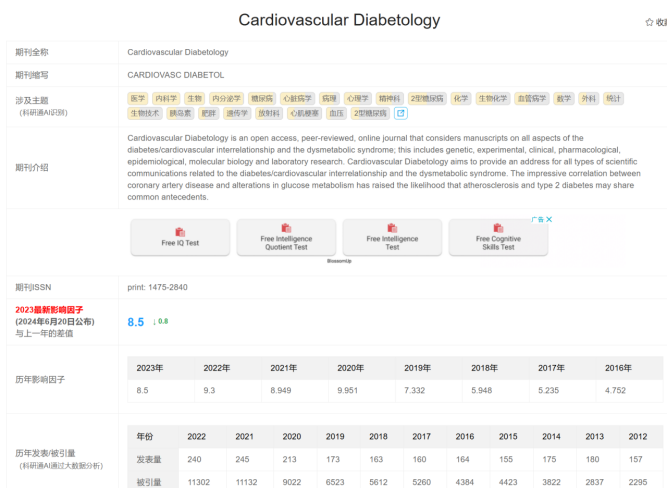
先定方向,写文章之前一定要有目标文章,因为做NHANES机器学习,结合自己也是搞心脏多一些,所以我选的期刊是Cardiovascular Diabetolog Q1区 8.5分的文章,发文量也比较的稳定,这个杂志熟悉的都知道,对于NHANES数据库还是非常有好的,上面也有很多机器学习的文章,这个文章是协和团队的成果
不管最后能不能发这个杂志,“不想当将军的士兵不是好士兵”,我先定位目标。期待NHANES+机器学习=1区CD 8.5,师弟师妹们一起在科研道路上发光发热!
Day 2
进展:选题检索
昨天大致检索了相关的文献,发现了类似的文章有但是不多,使用NHANES数据库的数据做机器学习的文章也不是很多,按照既往的挑战思路
暴露:和前面的目标文献基本一致,到时候筛
结局:心血管疾病CVD
人群:我选的是一个相对来讲比较大众的疾病人群
方法:机器学习
因为之前看到过类似的文献,所以我的心里有结果预期
基于类似于meta分析的PICOS原则的PECOS,我进行了充分的检索,不仅是Pubmed,还有我们比较容易忽视的WOS,发现确实别人没有做过,有也是类似的但是人群没做过。机器学习的代码在前面就跑过了,已经完全适配了我的电脑。只需要吧数据能够提取出来,然后依葫芦画瓢就可以来了
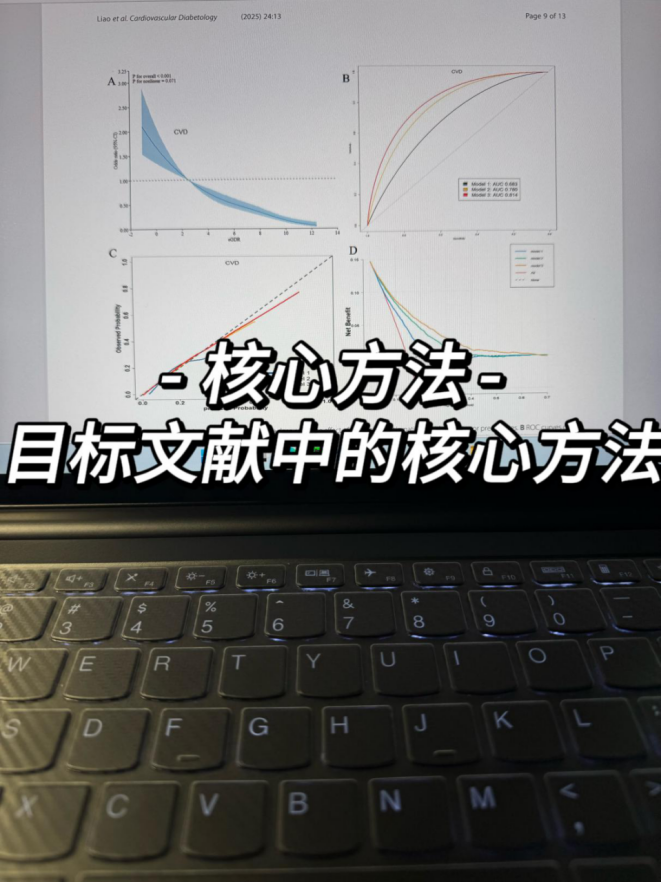
深入的学习目标文献的内容,不仅是选题的方式,逼近是核心方法--机器学习
还有一些数据细节的处理,比如他的所有的变量是如何定义的,比如他的缺失值是如何处理的,这些都是我们可以避坑的点,可以做到心中有数
一旦题目检索没有问题,就立马着手提取数据、分析数据
师弟师妹们,跟上我的节奏!明天继续汇报挑战进展,记得关注哟~


Day 3
进展:文献阅读+数据提取+代码测试
文献阅读:
我们要去根据目标文献确定我们的变量,结局变量、协变量分别是什么。因为是基于写变量去筛选变量,所以是没有暴露的,相当于所有的协变量都是暴露,我变量确定了过后要根据目标文献的描述确定需要提取的变量
数据提取:
这一步实际上要用用到之前我们在NHANES挑战的时候使用到的表哥,就是一定更要提前把需要提取的变量整理好,在那几个周期存在,应该在Demo、还是Exam里面,这需要在NHANES的官网进行检索确定,然后就是确定需要提取那一列,以及一些复合变量需要提取多列进行计算。最简单的例子就是,大家比较熟悉的明星指标:TyG甘油三酯葡萄糖指数,Ln[空腹甘油三酯mg/dL *空腹血糖mg/dL /2]那就需要提取两列数据进行计算
代码测试:
代码前面已经挑战成功过一次了,代码肯定没问题
做任何一个公开数据库,我们一定要学会方法学平移!我们一定要学会数据的提取!数据、代码都已经ready!准备跑出Figure and Table了
挑战继续~
感谢师弟师妹们的监督,一起加油呀!




Day 5-6
这两天的任务:核心Table and Figure
说白了就是跑代码,跑代码真的不难,只要电脑不是特别的拉,只要把数据换成自己的就行跑的出来。但现实很骨感,跑的过程中总会遇到各种小问题,不过别慌,前期的代码测试通过了之后,至少知道一定是能够跑的出来结果的,只是需要时间
我上期成功挑战过,这次就不用重新安装各种包啦,只需要加载library就可以啦,轻松不少。但师弟师妹们要是第一次安装,可得做好心理准备,安装包多到让人眼花缭乱,多种不同的算法的包也不一样,2 - 3 个小时都不一定能搞定。不要慌张、慢慢来,而且对电脑配置也有一定的要求,这也是做机器学习这类项目时最常遇到的难题
其实也还好,我这个电脑是联想到的ThinkPad,I5+3050的基础款配置在科室也能跑成功,只是发烫得厉害,没办法放到窗外物理降温就好了。好在 NHANES 的数据集不算大,甚至来说十分的小跑机器学习用不了多少时间,我就花了大概半个小时,跑出来 Figure 和 Table 后,分门别类的做好整理,然后整理好legends放在文件夹中备用,收拾收拾就可以准备写作啦
挑战继续
加油加油~



Day 6-7
写作!
前面有关注我们的师弟师妹们私底下和我说,“我也去使用了框架写作法写作了,确实非常高校”
就是呀。既然文章的核心结果都出来了,还担心写不出来吗?虽然真的很简单,但是有的师弟师妹会比较犯难的是
那我们再给大家展示一下框架写作法,“高效、专业”的完成内容写作,这也是发挥目标文献作用的时候了。模仿目标文献,当我的文章结果、写作、逻辑基本都和已经成功发表的文章不想上下的时候,那我们的文章接受的概率就会大大增加,当然不考虑你的通讯作者等一系列潜在不可控因素
所以我们文章的重心应该在选题!!!我的这个研究究竟有没有“创新”有多大的创新,写作写的多了就知道编辑和审稿人想要什么了,写多了就祛魅了
感谢师妹们的监督,我想给师弟师妹没汇报:Nhanes机器学习挑战成功!一起冲鸭!前面有师弟师妹们在咨询具体怎么操作,我们整理了相关的内容供师弟师妹们si戳了解学习,中介MR、肠道菌群、GBD、NHANES、Case Report等等不同类型的paper方法我们都有
 browserscan检测原理逆向分析)



