本文翻译自:https://huggingface.co/agentica-org/DeepCoder-14B-Preview
文章目录
- 一、关于 DeepCoder-14B-Preview
- 概述
- 二、数据
- 三、训练方法
- GRPO+
- 迭代上下文长度增加
- 四、评估
- 五、DeepCoder 服务
- 使用建议
- 六、其它
- 许可证
- 致谢
一、关于 DeepCoder-14B-Preview
🚀 破解强化学习对大型语言模型(RLLM)的民主化 🌟
- rllm github : https://github.com/agentica-project/rllm
- Notion : https://pretty-radio-b75.notion.site/DeepCoder-A-Fully-Open-Source-14B-Coder-at-O3-mini-Level-1cf81902c14680b3bee5eb349a512a51
- Twitter: https://x.com/Agentica
- https://huggingface.co/agentica-org
- Together AI : https://www.together.ai
概述
DeepCoder-14B-Preview 是一个通过分布式强化学习 (RL) 从 DeepSeek-R1-Distilled-Qwen-14B 微调的代码推理 LLM,能够扩展到长上下文长度。
该模型在 LiveCodeBench v5(2024年8月1日至2025年2月1日)上实现了 60.6% 的 Pass@1 准确率,
相比基础模型(53%)提高了 8%,并且仅使用 14B 参数就达到了与 OpenAI 的 o3-mini 相似的性能。
二、数据
我们的训练数据集由大约 24K 个独特的测试问题对组成,这些数据是从以下来源编译的:
- Taco-Verified
- PrimeIntellect SYNTHETIC-1
- LiveCodeBench v5 (5/1/23-7/31/24)
三、训练方法
我们的训练秘籍依赖于DeepScaleR中引入的GRPO(GRPO+)改进版本和迭代上下文长度扩展。
GRPO+
我们通过从DAPO算法中获得洞察力来增强原始的GRPO算法,以实现更稳定的训练:
- 离线难度过滤: DAPO采用在线动态采样,实时丢弃完全正确和完全错误的样本。虽然这有助于保持更稳定的有效批量大小,但由于拒绝采样,它引入了显著的运行时开销。相反,我们对编码问题的一个子集进行离线难度过滤,以确保训练数据集保持在合适的难度范围内。
- 无熵损失: 我们观察到包含熵损失项通常会引发不稳定性,熵会呈指数增长并最终导致训练崩溃。为了缓解这种情况,我们完全消除了熵损失。
- 无KL损失: 消除KL损失可以防止LLM停留在原始SFT模型的信任区域内。这种移除还消除了计算参考策略的日志概率的需求,从而加速了训练过程。
- 过长过滤 (来自 DAPO): 为了保留长上下文推理,我们对截断的序列进行损失掩码。这项技术使 DeepCoder 尽管在 32K 上下文中进行训练,但仍然能够推广到 64K 上下文推理。
- Clip High (from DAPO): 通过增加 GRPO/PPO 的代理损失的上界,我们鼓励更多的探索和更稳定的熵。
迭代上下文长度增加
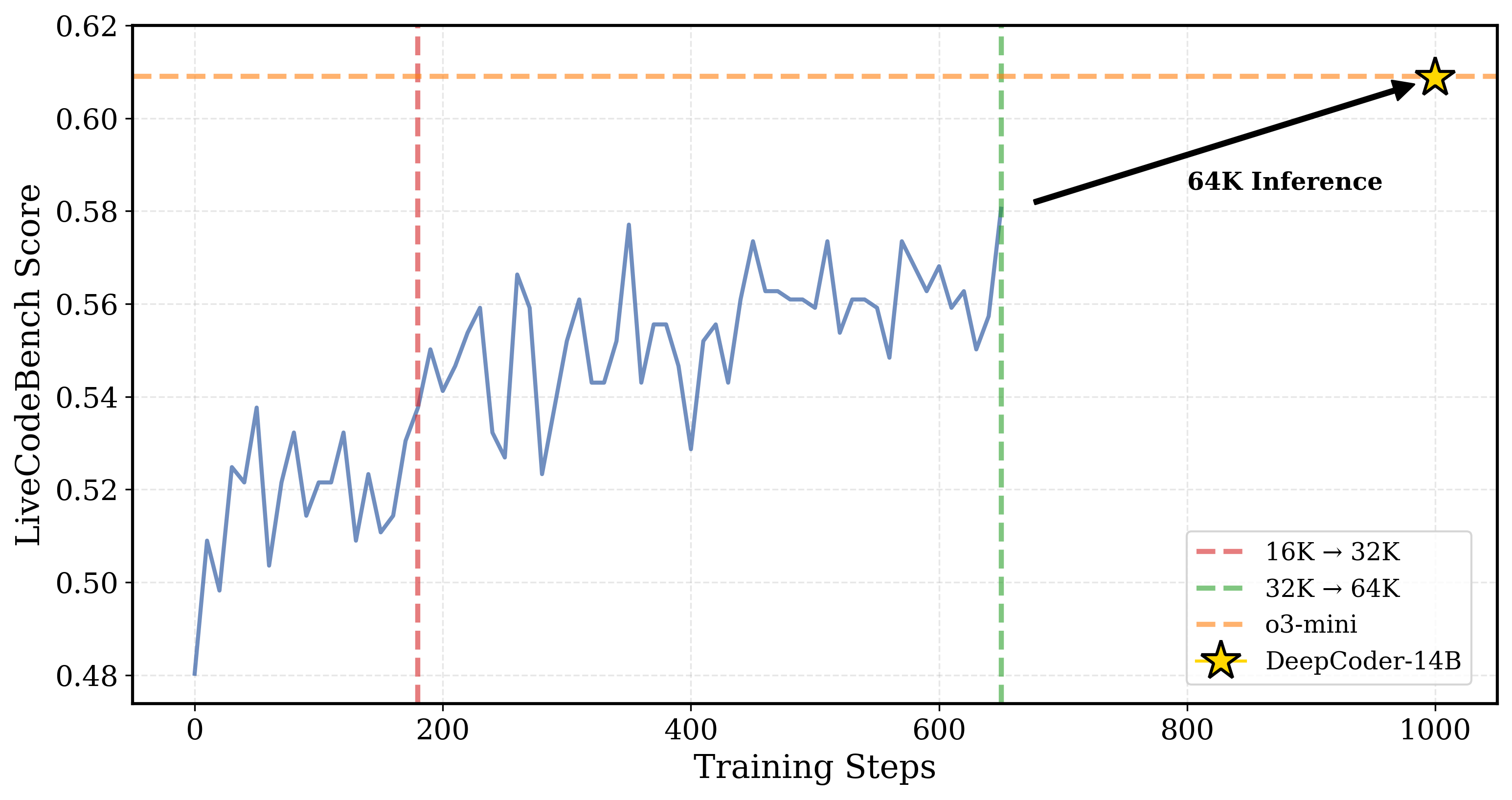
我们的原始 Deepscaler-1.5B-Preview 对长上下文进行了缩放训练,从 8K→16K→24K,分别在 AIME 上达到了 33→38→43%。
同样,Deepcoder-14B-Preview 在 16K→32K 上进行了训练,在 LiveCodeBench (v5) 上达到了 54→58%。
DeepCoder-14B-Preview 在 64K 上下文评估时成功推广到更长的上下文,达到了 60.6%。
DeepCoder由于DAPO的过长过滤,比基础蒸馏模型更能泛化到长上下文中。
然而,当最大长度限制在16K时,它的较长的响应通常会截断,这可能会降低其得分。
| 模型 | 16K | 32K | 64K |
|---|---|---|---|
| DeepCoder-14B-Preview | 45.6 | 57.9 | 60.6 |
| DeepSeek-R1-Distill-Qwen-14B | 50.2 | 53.0 | 53.0 |
一份更详细的训练方法描述可以在我们的 博客文章 中找到。
四、评估
我们在各种编码基准测试中评估 Deepcoder-14B-Preview,包括 LiveCodeBench (LCBv5)、Codeforces 和 HumanEval+。
| 模型 | LCB (v5)(8/1/24-2/1/25) | Codeforces Rating | Codeforces Percentile | HumanEval+ |
|---|---|---|---|---|
| DeepCoder-14B-Preview (ours) | 60.6 | 1936 | 95.3 | 92.6 |
| DeepSeek-R1-Distill-Qwen-14B | 53.0 | 1791 | 92.7 | 92.0 |
| O1-2024-12-17 (Low) | 59.5 | 1991 | 96.1 | 90.8 |
| O3-Mini-2025-1-31 (低) | 60.9 | 1918 | 94.9 | 92.6 |
| O1-预览 | 42.7 | 1658 | 88.5 | 89 |
| Deepseek-R1 | 62.8 | 1948 | 95.4 | 92.6 |
| Llama-4-Behemoth | 49.4 | - | - | - |
五、DeepCoder 服务
我们的模型可以使用流行的性能高效的推理系统进行部署:
- vLLM
- Hugging Face 文本生成推理 (TGI)
- SGLang
- TensorRT-LLM
所有这些系统都支持 OpenAI Chat Completions API 格式。
使用建议
我们的使用建议与R1和R1 Distill系列相似:
- 避免添加系统提示;所有指令应包含在用户提示中。
温度 = 0.6top_p = 0.95- 此模型在将
max_tokens设置为至少64000时表现最佳
六、其它
许可证
本项目采用MIT许可证发布,体现了我们对开放和易于访问的AI开发的承诺。我们相信通过使我们的工作免费提供给任何人使用、修改和在此基础上构建,可以民主化AI技术。这种宽松的许可证确保了全球的研究人员、开发人员和爱好者可以无限制地利用和扩展我们的工作,从而在AI社区中促进创新和协作。
致谢
- 我们的训练实验由我们对Verl的深度修改版分支提供支持,Verl是一个开源的培训后库。
- 我们的模式是在
DeepSeek-R1-Distill-Qwen-14B之上训练的。 - 我们的工作是作为伯克利天空计算实验室和伯克利人工智能研究的一部分完成的。
2025-04-16(三)




)
---(jdk安装和环境变量配置))