前几天字节跳动刚宣布了发布 MOE 大模型 Seed-Thinking-v1.5(200B总参数、20B激活参数),全面超越 DeepSeek-R1(671B总参数、37B激活参数)。
字节发布 Seed-Thinking-v1.5:超越 DeepSeek-R1绝密伏击
今天,昆仑万维就宣布开源 Skywork-OR1 系列模型——通用32B(Skywork-OR1-32B)完全超越同规模阿里QwQ-32B;代码生成媲美 DeepSeek-R1,但性价比更高。
| Model | AIME24 (Avg@32) | AIME25 (Avg@32) | LiveCodeBench (Avg@4) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 39.2 | 37.6 |
| Light-R1-7B-DS | 59.1 | 44.3 | 39.5 |
| DeepSeek-R1-Distill-Qwen-32B | 72.9 | 59.0 | 57.2 |
| Light-R1-32B-DS | 78.1 | 65.9 | 61.6 |
| QwQ-32B | 79.5 | 65.3 | 61.6 |
| DeepSeek-R1 | 79.8 | 70.0 | 65.9 |
| Skywork-OR1-Math-7B | 69.8 | 52.3 | 43.6 |
| Skywork-OR1-7B-Preview | 63.6 | 45.8 | 43.9 |
| Skywork-OR1-32B-Preview | 79.7 | 69.0 | 63.9 |
项目地址:Skywork Open Reasoner Series
代码地址:https://github.com/SkyworkAI/Skywork-OR1
✅ Skywork OR1 核心方法总结表
| 模块类别 | 方法 / 策略名称 | 具体内容说明 |
|---|---|---|
| 数据构建与筛选 | 通过率筛选机制 | 使用未微调模型进行多轮采样,仅保留 通过率 > 0 且 < 1 的问题(模型“有希望学会”) |
| 数据混合策略 | 训练 32B 模型时引入更难问题(如 NuminaMath 高难子集),整体优于 DeepScaleR 训练数据 | |
| 题目可验证性过滤 | 去除无参考答案、无测试用例的问题;确保奖励函数评估稳定 | |
| 强化学习算法 | 多阶段 GRPO 训练 | 多阶段按上下文窗口划分:8K → 16K → 32K,逐步推进推理长度 |
| 截断响应策略 | 实验过 Advantage Mask,但最终 决定不使用任何 Advantage Mask,以保持 token 效率和可扩展性 | |
| KL 正则项设置 | 明确设置 KL 系数 |
| ,完全去除 KL Loss,避免限制策略演化 | ||
| 采样温度策略 | 强化学习中使用较高温度(T = 1.0),提升组内样本多样性与梯度信号 | |
| 自适应熵控制机制(AEC) | 设置目标熵 |
,每步更新系数
| 奖励函数机制 | 数学任务验证器 | 采用 Math-Verify,放弃 PRIME 和 Qwen2.5 verifier |
| 代码任务沙箱 | 自建 code sandbox,确保代码能正确运行并 全部通过测试用例 才判定为 reward = 1 |
下面我们介绍一下具体细节。
🌌 一、Skywork-OR1 Series
1.1 背景与定位
-
Skywork-OR1 系列是 Skywork 团队继中文推理模型 Skywork-o1 之后的新一代模型。
-
相比初代产品,OR1 更加聚焦于 逻辑理解与复杂推理能力的提升。
-
涵盖多种模型规模和专用模型,适配不同算力需求与使用场景。
1.2 模型构成
Skywork-OR1 系列包含三个主力模型:
| 模型名称 | 参数量 | 特点 |
|---|---|---|
| Skywork-OR1-7B | 7B | 通用推理模型,轻量高效 |
| Skywork-OR1-32B | 32B | 高性能推理模型,追求极致效果 |
| Skywork-OR1-Math-7B | 7B | 数学专用模型,精通 AIME 题目 |
-
Skywork-OR1-32B 在数学与代码任务上 全面超越同尺寸模型
-
Math-7B 在 AIME24 和 AIME25 上分别达到了 69.8 和 52.3 的准确率。
🌌 二、Dataset Preparation(数据处理)
🧩 2.1 Step 1: Data Source Selection and Preprocessing(数据选择与预处理)
这是 Skywork-OR1 系列模型构建过程中的第一步,目标是从众多数据中挑选出 高质量、有挑战性且可验证 的数学与代码题目,用于强化学习(RL)阶段的训练。
以下是论文中“Selection Criteria(选择标准)”这一小节的完整内容翻译,出自《Skywork Open Reasoner Series》技术报告:
2.2.1 Selection Criteria(数据选择标准)
为了构建高质量的强化学习训练数据,Skywork 团队针对数学与代码两个任务域,制定了统一的选择标准,具体如下:
1️⃣ 可验证性(Verifiable)
我们排除了所有无法验证正确性的题目,例如:
-
纯证明题(没有标准答案)
-
缺乏测试用例的编程题
2️⃣ 答案正确性(Correct)
我们过滤掉:
-
数学题中存在错误或不合法答案的问题
-
编程题中没有完备测试用例的样本
3️⃣ 挑战性(Challenging)
我们提前用基础模型(如未强化学习前的模型)对每个问题生成多轮答案(N 次),然后排除:
-
全部答案都对(N/N correct)的问题
-
全部答案都错(0/N correct)的问题
✅ 只保留那些“有一部分能做对”的题目,即模型“有希望学会”的内容
基于以上三条标准,Skywork 精选出了一批具有代表性和难度的训练题目,主要包括:
✅ 数学数据来源:
- NuminaMath-1.5 子集:
-
amc_aime、olympiads、olympiads_ref -
aops_forum、cn_contest、inequalities、number_theory
-
-
DeepScaleR
-
STILL-3 Preview RL 数据集
-
Omni-MATH
-
AIME(2024年以前的历年真题)
✅ 编程数据来源:
-
LeetCode(真实高质量代码题目)
-
TACO(带有完整结构与测试用例的代码任务)
🧩 2.2 Step 2: Model-Aware Difficulty Estimation(基于模型感知的难度评估)
这一步是为了确保用于强化学习(RL)训练的题目既具有挑战性,又能产生有意义的训练信号。关键思想是:先用模型自己“试做一遍题”,再根据结果来评估题目的难度。
数学题:
-
每道题进行 16 次生成(N=16)
编程题:
-
每道题进行 8 次生成(N=8)
每次生成使用:
-
温度 temperature = 1.0
-
最大上下文长度 = 32K tokens
难度判断方式
-
对于每个题目,记录模型答对的比例(比如 16 次中答对 5 次,即 5/16)。
- 按照这个比例,将题目分为:
-
0/N(全错)
-
N/N(全对)
-
中间区域(部分答对)
-
只保留第三类 —— 模型答对/答错情况有差异的题目,因为:
-
这类题最能提供“有用的训练信号”
-
全错/全对题目不利于优势估计(Advantage Estimation)
保留与淘汰比例
以两个不同大小模型(7B 和 32B)为例:
| 模型 | 全错比例 (数学/代码) | 全对比例 | 保留比例 |
|---|---|---|---|
| 7B | 21.4% / 28% | 32.4% / 24% | 46.2% / 48% |
| 32B | 20.7% / 17.1% | 42.0% / 45.4% | 37.3% / 37.6% |
📌 注意:大模型更容易产生“全对”样本,因此反而可用样本更少。
目的与优势
-
只留下 有分辨性的问题,提升训练数据的效能
-
确保 RL 的 advantage 计算成立,避免训练过程不稳定
-
为接下来的 Reward 函数设计和策略优化打下基础
🧩 Step 3: Quality Assessment via Human + LLM-as-a-Judge (人类 + 大模型双重评审的数据质量评估)
这一节的重点是:即使通过了前两步(筛选+难度评估),仍有不少题目存在质量问题,比如题干不完整、格式混乱、无关信息等。因此,Skywork 团队引入了人类评审 + 大模型辅助评审的机制,进一步剔除“低质量题目”。
Skywork 团队发现:
-
许多数学题目 格式混乱、不完整,甚至无实际意义
-
有些问题在模型评估中被标为“答对”,其实是模型凭经验猜对的
-
高质量训练必须确保数据的清晰性、准确性和完整性
人类评估标准(手动抽样检查)
从保留数据中抽取样本,由人工基于以下标准做检查:
| 检查维度 | 说明 |
|---|---|
| ✅ 语言清晰 | 题干表达是否通顺、易懂 |
| ✅ 信息完整 | 是否包含了所有必需的条件和背景 |
| ✅ 排版规范 | 数学符号是否正确、格式是否混乱 |
| ✅ 无干扰内容 | 是否包含无意义的注释、乱码、翻译残留 |
❌ 示例问题:
-
“Find σ₂(28) = ?”(信息不全)
-
“Which number is greater than 0.7” (缺选项)
-
翻译错误中夹杂原文、注释、图像提示(噪声)
LLM 评审机制
为了更高效筛查大量题目,Skywork 团队使用两个强力大模型:
-
Llama-3.3-70B-Instruct
-
Qwen2.5-72B-Instruct
自动流程:
-
提出统一的评审 prompt,请模型判断题目的质量(是否清晰、完整、规范等)
-
每个问题由两个模型分别生成 16 个回答,总共 32 个“投票”
-
统计判断结果:保留获得 9 票及以上肯定评价的题目
-
清理掉剩下的低质量问题,大约去掉 1000–2000 道数学题
🌌 三、Multi-stage GRPO with Adaptive Entropy Control(多阶段 GRPO 与自适应熵控制)
🧩 3.1 Overview
接下来介绍 Skywork-OR1 模型训练中使用的强化学习方案的整体设计思路,属于其 关键训练框架和创新亮点。
核心训练策略:GRPO + 多阶段训练 + 自适应熵
Skywork 团队在常规的 RLHF(强化学习微调)基础上做了三项主要增强:
-
GRPO(Grouped Rollout with Policy Optimization)
-
Multi-stage Training(多阶段训练)
-
Adaptive Entropy Control(自适应熵控制)
GRPO 简介
GRPO 是一种分组采样 + 分组奖励的策略优化方法:
-
对每个 prompt(问题),采样多个 response(回答)
-
每组 response 得到一个 相对优势估计(advantage estimate)
-
再用 PPO 或其变种进行训练更新
相比传统 RLHF,GRPO 的优势是:
-
更适合生成任务(如数学推理、代码生成)
-
更容易计算和稳定优化
多阶段训练(Multi-stage Training)
训练过程分为多个阶段,每个阶段使用不同的 context window(上下文长度):
-
Stage 1:较短上下文(例如 8K)
-
Stage 2:中等上下文(16K)
-
Stage 3:最终上下文(32K)
优势:
-
初期使用较短上下文,加快训练速度、减少资源消耗
-
后期再扩展上下文,提升复杂问题的建模能力
-
有效缓解了 RL 训练中“长序列学习慢”的问题
3. 自适应熵控制(Adaptive Entropy Control)
为避免模型在训练中变得过于保守(即 熵坍缩),Skywork 引入了一个自适应熵机制:
-
动态调整熵损失系数(αₖ),保持输出多样性
-
如果模型生成的回答熵太低,会自动增强探索(提高 αₖ)
-
若熵太高则减少惩罚,保持稳定
目标是:
保证模型始终保持“敢猜但不乱猜”的状态——探索性与确定性之间的平衡。
🧩 3.2 Multi-stage Training(多阶段训练)
这是 Skywork 在推理模型 RL 训练中最关键的一项设计,它解决了大模型训练时「推理链太长、训练太慢」的问题 —— 通过 “先短后长” 的方式,提升效率又保留性能。
| 阶段 | 上下文长度(seq_len) | 说明 |
|---|---|---|
| Stage 1 | 8K tokens | 快速训练,提升 token 效率 |
| Stage 2 | 16K tokens | 拓展推理长度,提升准确率 |
| Stage 3 | 32K tokens | 完整推理能力,适配评测环境 |
以下是对论文中 “Same Improvement, Higher Efficiency” 这一节的翻译与解读,出自《Skywork Open Reasoner Series》PDF 文件:
3.2.1 Same Improvement, Higher Efficiency(相同提升,更高效率)
为了验证多阶段训练(Multi-stage Training)的有效性,Skywork 团队在 DeepSeek-R1-Distill-Qwen-7B 上开展了对比实验。
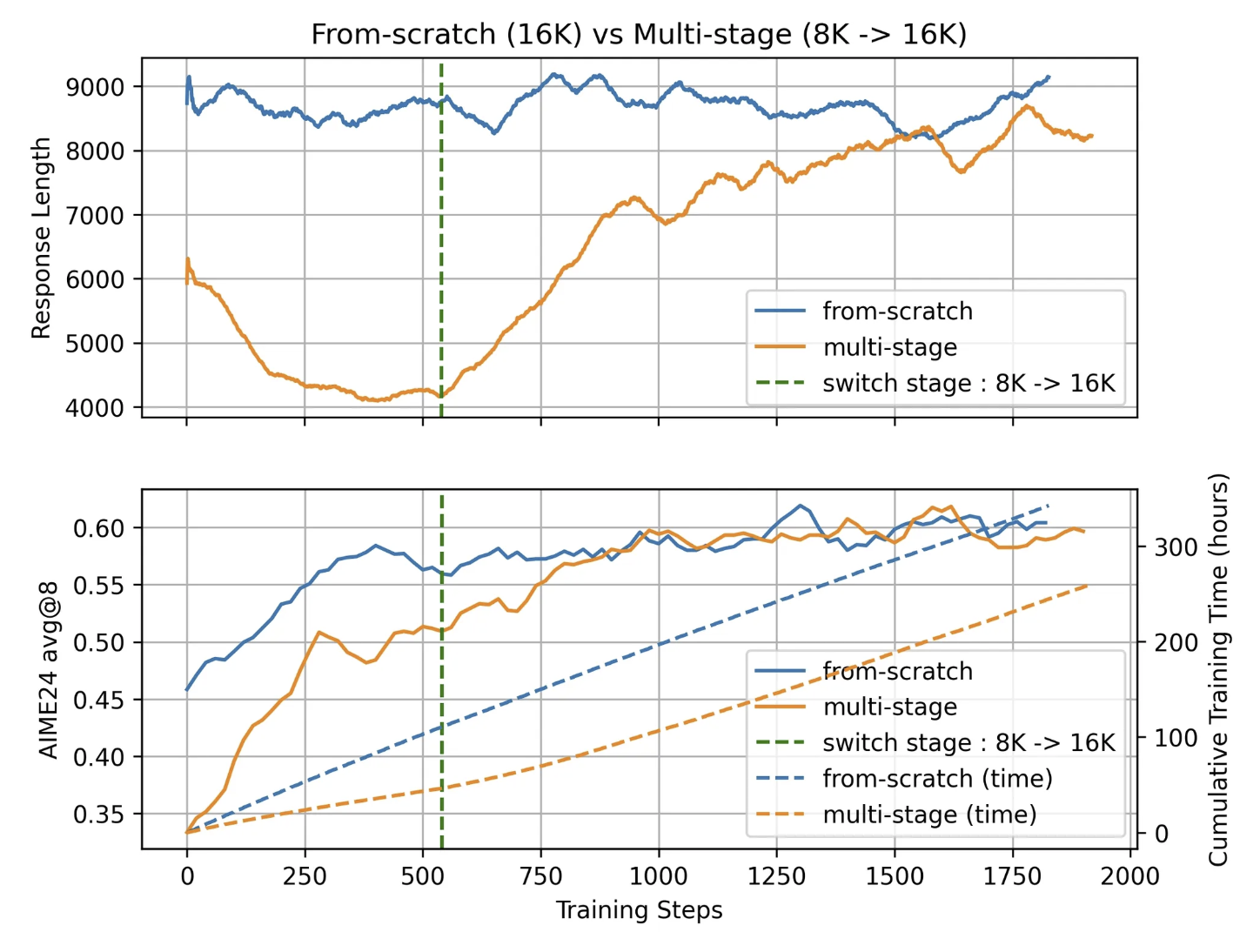
图1: 直接训16k和多阶段训练的对比
实验设计
进行了两组训练对比:
-
From-scratch 实验:
-
从训练一开始就设定 context window 长度为 16K,保持不变
-
-
Multi-stage 实验:
-
初始阶段使用 较小的上下文窗口(8K)
-
在第 540 步切换至 stage 2,扩展到 16K
-
结果观察
-
两组实验在足够训练步数后,AIME24 的准确率都能接近 60%
- 但:
-
Multi-stage 训练的 前期上下文更短,生成响应长度显著更短
-
因此,在前期训练中推理速度更快、计算成本更低
-
实验显示:1K 步内节省了大约 100 小时的训练时间
-
更进一步:
-
在进入 Stage 2(16K)后,模型的响应长度和准确率迅速上升
-
不到 500 步内,multi-stage 模型的 AIME24 准确率追上了 from-scratch 训练的水平
✅ 核心结论
-
性能提升相同:最终准确率相近
-
训练效率更高:初期上下文较短 → 响应更短 → 推理更快 → 更节省资源
3.2.2 Improving Token Efficiency While Preserving Scaling Potential(提高 Token 效率,同时保留模型扩展潜力)
这一节回应了一个潜在的担忧:
在多阶段训练中,早期使用较短上下文窗口(如 8K),是否会导致模型“习惯性”生成短答案,从而损害它在更长推理链上的能力?
实验观察与分析
在 Skywork 的训练实践中,发现如下结果:
- 在第 1 阶段使用 8K 上下文窗口训练时,虽然响应较短,但:
-
模型仍能在 32K 上下文窗口下取得与 DeepSeek-R1-Distill-Qwen-7B 相当的准确率(AIME24)
-
平均响应长度从 12.5K token 降低至 5.4K token,显著提升 token 使用效率
-
即:多阶段训练前期 token 更短,训练成本更低,但不会牺牲后续推理能力
后续阶段的表现
在第 2、3 阶段训练中:
-
响应长度逐步恢复并增长
-
模型准确率与响应质量同步提升
-
展现出出色的“可扩展性”与“可恢复性”
结论
Skywork 团队由此得出结论:
多阶段训练不仅在初期阶段显著提高了 token 使用效率,还保留了后续阶段的推理扩展能力,是兼顾“成本”与“效果”的最佳实践之一。
🧩 3.3 On the Issue of Truncated Samples(超长截断的影响)
3.3.1 Two Optimization Directions in Short Context Windows(短上下文窗口中的两种优化方向)
在我们对 Skywork-OR1-Math-7B 的第 1 阶段训练中,上下文窗口被设置为 8K,因此在训练初期,大约 40% 的响应被截断(truncated)。
观察到的现象
尽管在 RL 训练过程中,整体训练准确率在持续上升,但团队发现:
-
非截断样本的准确率(即答案能完整输出的那部分)却在训练前 100 步骤内出现了显著下降
-
直到约第 100 步之后,这部分样本的准确率才出现轻微回升
这说明:虽然整体 reward 看似变高了,但其中的优化信号其实主要来自 “减少截断比例” ,而不是提升解题能力本身
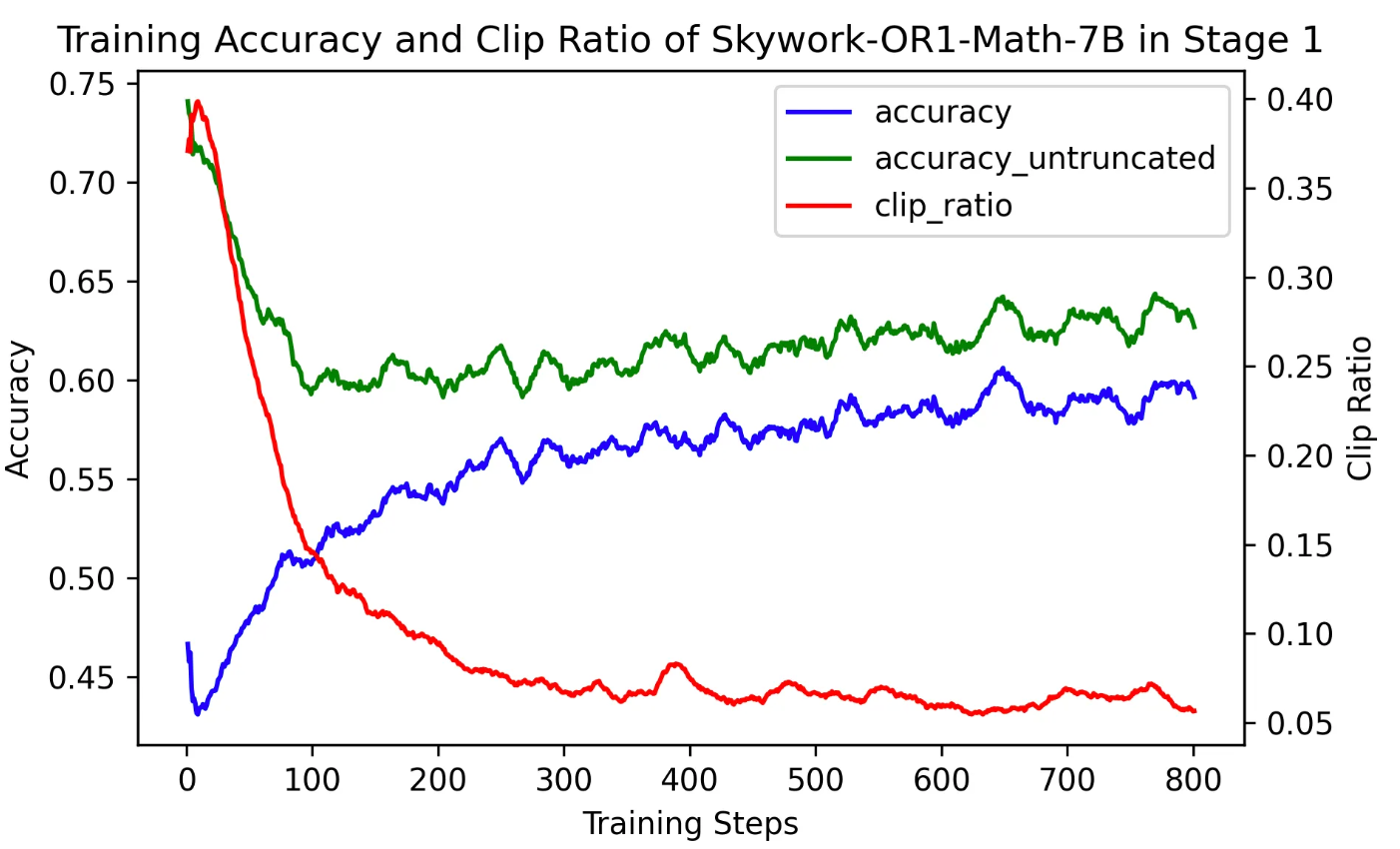
图2: 一阶段中能完整输出的样本准确率显著下降
-
蓝线(accuracy):整体训练批次的平均准确率
-
绿线(accuracy_non_truncated):非截断响应的准确率
-
橙线(clip_ratio):被截断的响应比例
观察发现:
-
在前 100 步中,clip_ratio 快速下降(截断情况变少)
-
这导致整体准确率看似在提升
-
但此时非截断样本的准确率反而下降了
原因解释
被截断的响应因为没有完整答案,因此在 RL 中被认为 reward=0(即使它实际上可能是对的)。
因此,训练初期模型的优化方向变成了:
-
让响应尽可能变短,从而避免被截断 → 获得正向奖励
这是一种“投机性行为”:模型学会如何规避截断惩罚,而非真正提升问题求解能力。
Skywork 在后续提出了若干策略(见下一小节)来纠正这一优化偏向,防止 RL 训练走向“只图不截断”的路径,而是回归到“提升非截断解答质量”的目标上。
3.3.2 Our Attempts: Advantage Mask For Truncated Responses(被截断响应 Advantage Mask 设计)
在短上下文窗口(如 8K)中训练 RL 模型时,很多响应容易被截断(truncated),而这些响应会被强制赋予 0 的 reward,即使它们的解答在逻辑上可能是正确的。
为解决这种误伤带来的训练噪声,Skywork 提出了一种策略:
对被截断响应的 advantage 值进行屏蔽(mask),防止它们影响梯度更新。
核心目标
希望训练重点优化以下两者之一:
-
提高非截断响应的准确率
-
而不是仅仅为了避免 reward=0 而盲目压缩响应长度
-
两种 Advantage Mask 策略
✅ Adv-Mask-Before
-
被截断响应的 advantage 被设为 0
-
但它们 不会参与 non-truncated 样本的 group advantage 计算
-
数学形式:
-
是 non-truncated 响应的 reward 集合。
✅ Adv-Mask-After
-
被截断响应依然 参与 group 平均 reward 的计算
-
但它们本身的 advantage 被设为 0
-
数学形式类似,但 reward 均值和方差来自全部响应(包括截断)
📊 实验结果比较
在 Skywork-OR1-Math-7B 上,分别使用上述两种策略训练,结果如下:
评估指标 无 mask Adv-Mask-Before Adv-Mask-After 响应长度是否明显缩短? ✅ 是 ❌ 否 中等 非截断准确率提升? ❌ 不明显 ✅ 明显提升 较高提升 大上下文窗口(如 32K)准确率 ✅ 高 ❌ 无提升 ❌ 无提升 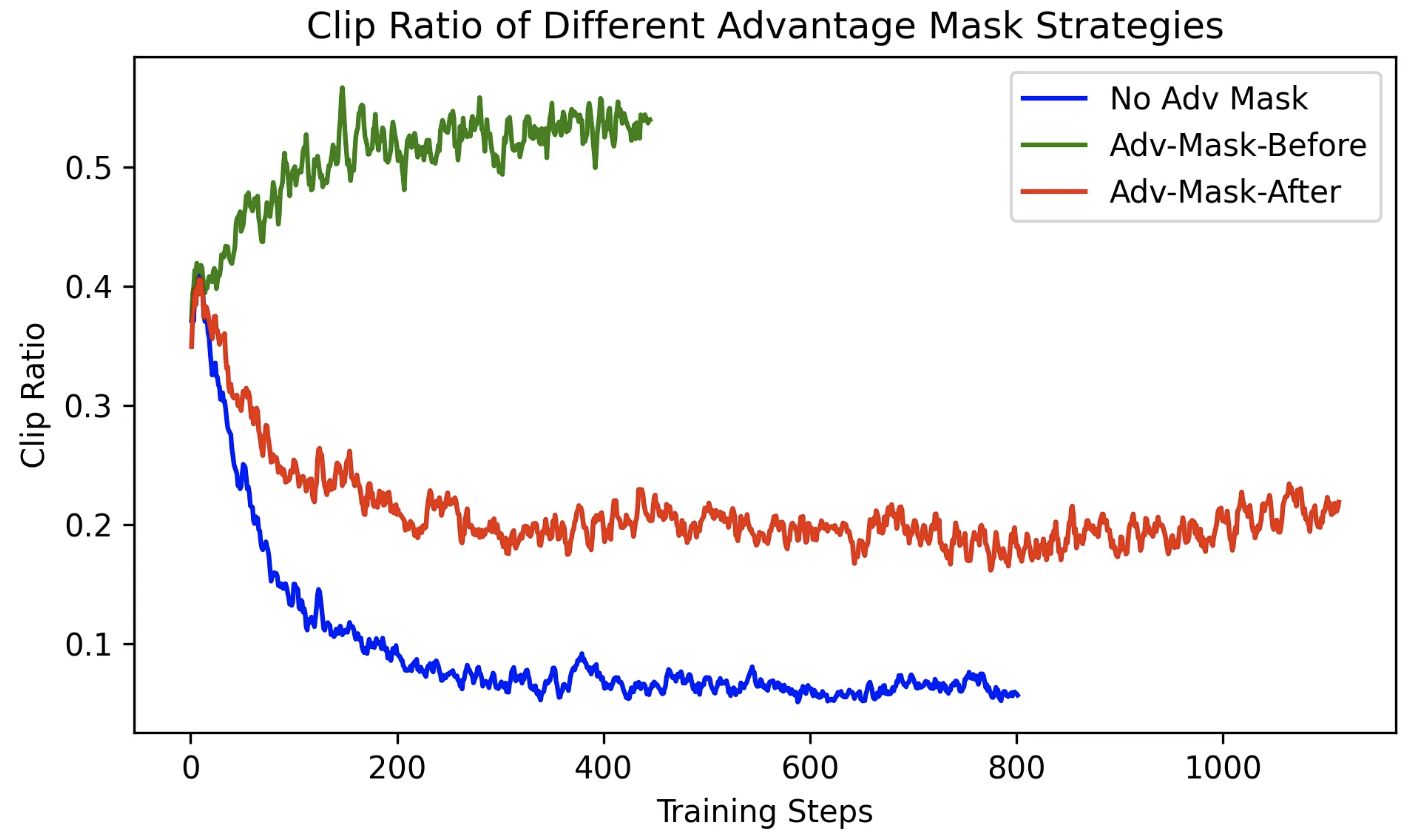
图3: 三种策略的截断概率
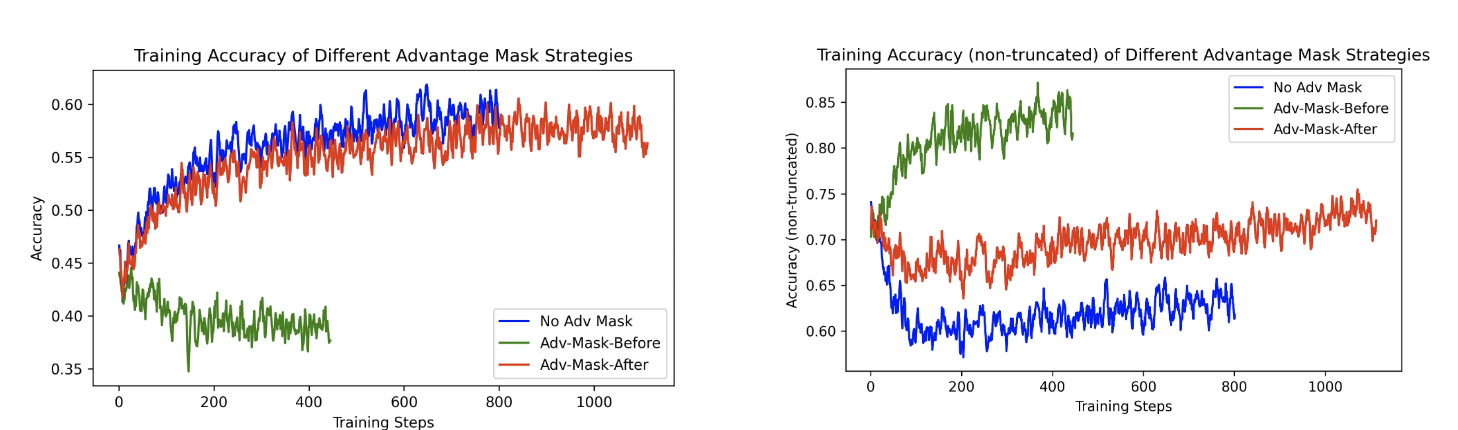
图4: 三种策略的整体准确率(左)以及非截断样本准确率(右)
最终结论:
尽管 Advantage Mask 能提升非截断样本的准确率,但它并不能显著提升最终大窗口下的泛化能力,甚至可能因为响应长度被反向拉长,导致训练组内样本数减少。
因此,Skywork 团队最终决定在正式训练流程中:
❌ 不使用任何 Advantage Mask,而是依赖更优的温度采样与熵控制策略来应对截断问题。
3.3.3 Advantage Mask Does not Exhibit Better Scaling Law(Advantage Mask 无法带来更好的 Scaling Law)
实验背景
虽然在短上下文窗口(如 8K)中使用 Advantage Mask 能够优化非截断响应的准确率,Skywork 团队进一步检验了:
这种优化方式是否在更大的上下文窗口下(如 32K)依然成立?是否能带来更好的泛化能力?
实验结果与观察
研究者在训练过程第 1 阶段对不同策略进行了对比:
-
不使用 advantage mask
-
使用 Adv-Mask-Before
-
使用 Adv-Mask-After
它们在 AIME24 上的表现如下图所示:
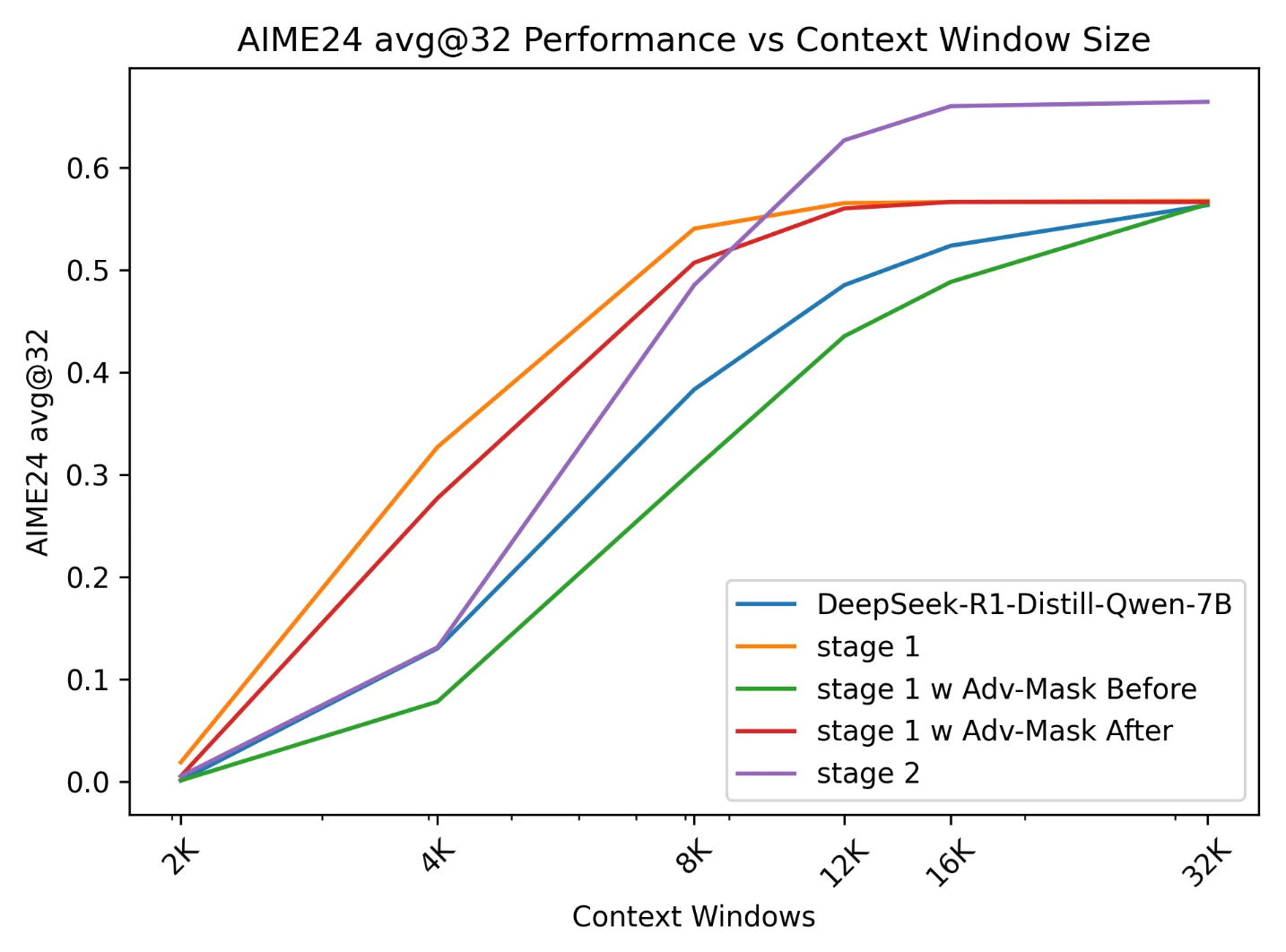
图5: 三种策略在32k长度下的准确率对比
策略类型 训练阶段(8K)准确率 大窗口(32K)准确率 No Advantage Mask 中等,持续提升 最高(最佳泛化) Adv-Mask-Before 初期准确率提升快,但后期下降 无改善 Adv-Mask-After 折中表现 无明显提升 尽管 Advantage Mask 能提升短窗口中的准确率,但:
-
当进入大窗口阶段(如 32K)后,各策略表现趋同
-
使用 Advantage Mask 的策略甚至会因 clip ratio 增高而造成训练 group size 缩小
-
token efficiency 反而下降,模型扩展能力变差
最终结论:
使用 Advantage Mask 无法带来更好的 scaling law,不如直接接受截断样本带来的训练信号噪声。
因此,Skywork 最终训练流程中 完全移除了 Advantage Mask 策略,转而采用更高效的熵控制与高温采样策略来应对截断问题。
🧩 3.4 Adaptive Entropy Control(自适应熵控制)
3.4.1 Suitable Entropy Control yields Better Performance(合理的熵控制带来更好的性能)
实验背景与问题发现:
在初步研究中,Skywork 团队发现:
强化学习训练过程中,Actor 模型的策略熵(entropy)往往迅速坍缩,也就是说模型输出变得越来越确定,缺乏多样性。
如果没有额外控制,这种“熵坍缩”会:
-
减少探索性
-
提前收敛到次优策略
-
降低泛化能力
为此,研究者尝试在策略损失中添加一个 熵损失项(entropy loss),其形式如下:
其中
是熵损失系数。
实验设定与观察
团队分别设定了两个不同的熵损失系数:
-
-
并对模型在 RL 训练期间的表现进行了监控,包括:
-
AIME 测试集上的准确率变化
-
模型生成响应的熵变化趋势
📊 实验结果分析:
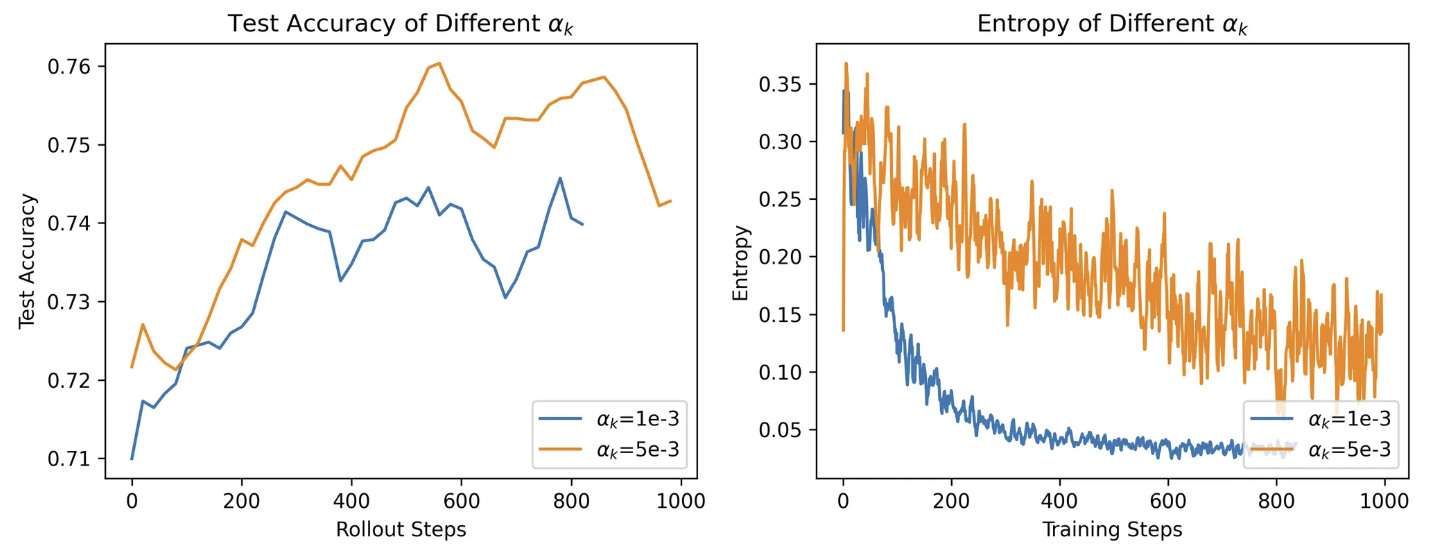
图6: 熵系数对模型效果的影响。(左)准确率(右)熵
-
较高熵系数(5e-3)对应的模型:
-
熵下降更缓慢(entropy decay slower)
-
最终准确率更高,泛化能力更强
-
-
较低熵系数或未添加熵项的模型:
-
更容易出现熵迅速下降,甚至收敛至 0
-
表现出“熵坍缩”或“熵爆炸”的不稳定行为
-
结论:合理调控熵,有助于模型提升探索性与泛化性能。
挑战:熵损失对超参与数据极为敏感
虽然熵项对训练有益,但实验也揭示出:
-
模型对
-
的设置 高度敏感
-
数据集本身的差异也会极大影响熵的变化曲线
例如:
- 同样是数学任务,使用不同子集训练,仅更换数据,模型的熵走势会完全相反:
-
一个数据集导致持续熵下降(熵坍缩)
-
另一个导致熵持续上升(熵爆炸)
-
3.4.2 Entropy Loss is Sensitive to the Coefficient(熵损失对系数高度敏感)
在上一节我们看到了加入熵正则项
对模型性能有提升作用。
但在这部分,Skywork 团队揭示出一个重要问题:熵损失项对系数的选择非常敏感,错误的设置可能导致模型训练彻底崩溃。
消融实验:不同 αₖ 的表现对比
研究者在 Skywork-OR1-Math-7B-stage1 上设置了以下五种熵系数(αₖ):
-
1e-4、5e-4、1e-3、5e-3、1e-2
并观察每种设置下模型的:
-
策略熵(entropy)变化曲线
-
AIME24 准确率
📊 实验结果
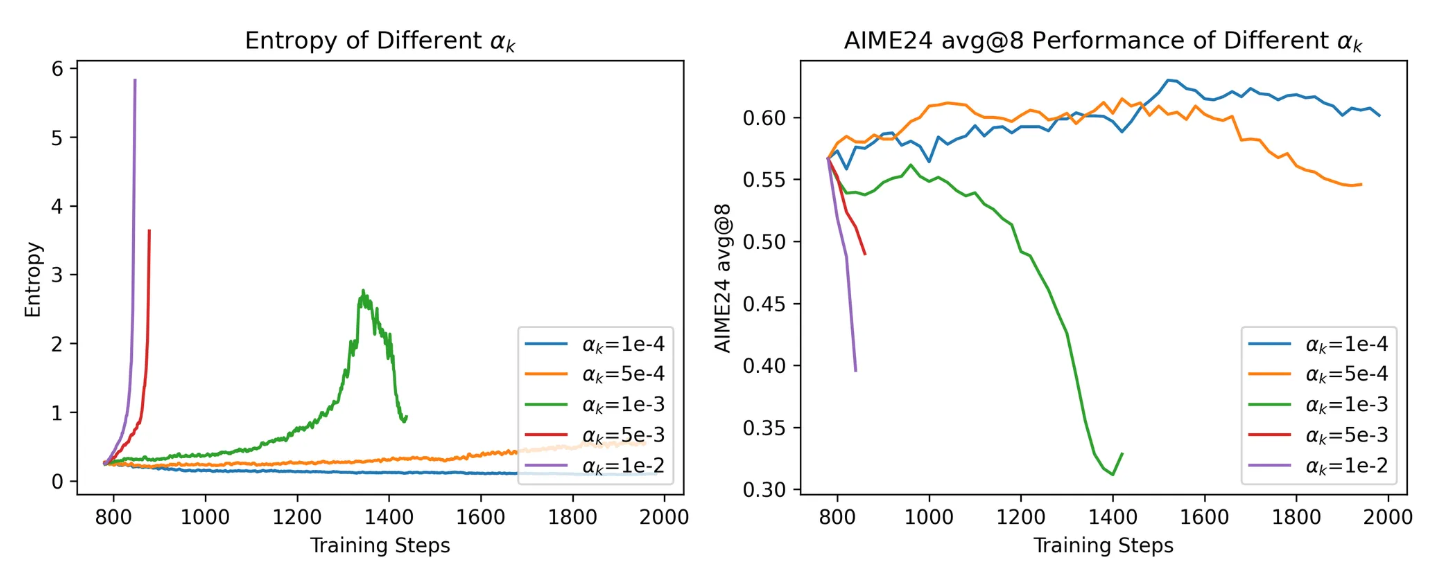
图7: 熵损失系消融实验(左)熵损失(右)AIME24准确率
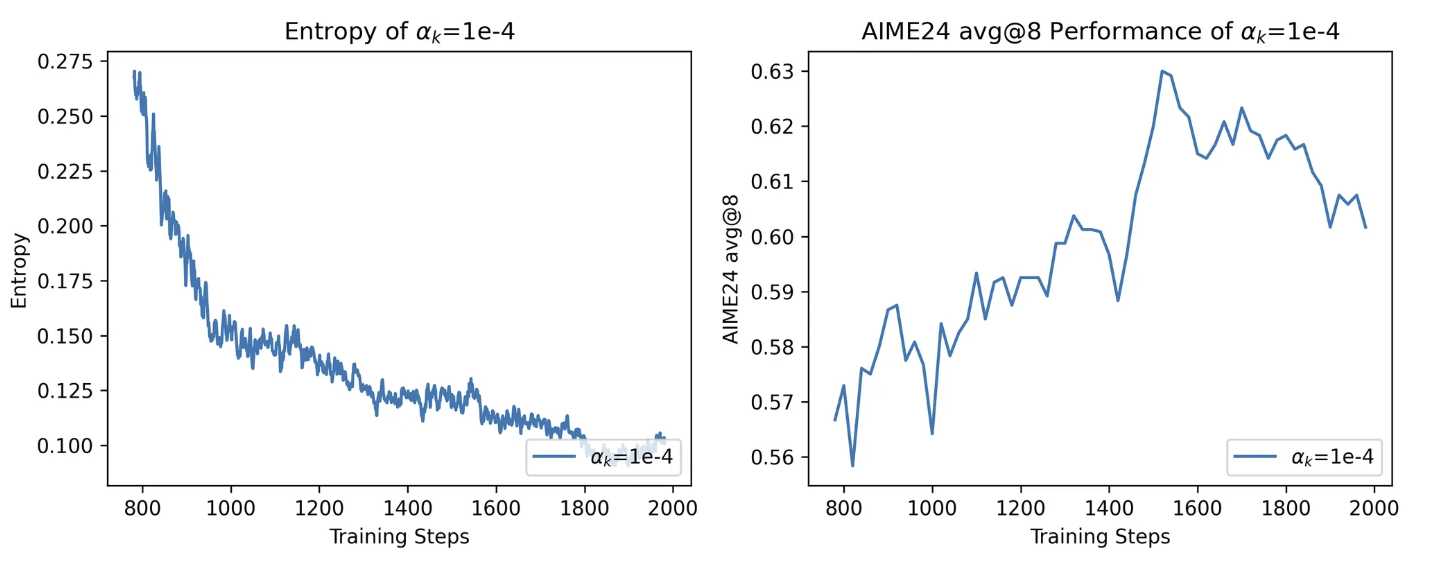
图8: 熵系数为1e-4(左)熵逐渐降低(右)AIME24准确率后期降低
✅ αₖ = 1e-4:
-
熵变化平稳,避免了“熵爆炸”
-
但熵仍然会缓慢下滑到接近 0,无法阻止“熵崩溃”
✅ αₖ ≥ 5e-4:
-
初期可能正常
-
但 熵会迅速飙升,最终模型陷入不稳定状态或崩溃(entropy explosion)
αₖ 越大,熵增长越快,训练越容易失控
Skywork 明确指出:
在训练前手动选一个“合适”的 αₖ 几乎不可能。
因为:
-
模型对不同任务(如数学/编程)熵反应不同
-
数据分布微小变化也会导致熵曲线截然不同
因此,这成为 Skywork 提出 Adaptive Entropy Control 的根本动机:
用动态调节的 αₖ 替代静态超参,以保证模型在训练中维持合理的策略熵水平,避免熵崩溃或爆炸。
3.4.3 Entropy Loss is Sensitive to Training Data(熵损失对训练数据也高度敏感)
在上一节中,Skywork 团队展示了熵损失对超参数 αₖ 的敏感性。接下来,他们进一步发现:
即使 熵系数 αₖ 固定不变,仅仅更换训练数据集,也会导致熵演化曲线出现完全不同的趋势。
实验设计
研究者设计了两个训练实验:
-
模型配置完全相同(包括 αₖ = 1e-3)
- 只改变训练数据集:
-
两个数据集都属于数学领域
-
实验结果对比
- 实验一(原始数据集):
-
模型在训练过程中,策略熵逐步下降
-
- 实验二(新数据集):
-
模型的熵不断上升,甚至出现熵爆炸趋势
-
熵控制策略不仅依赖于超参数设定(如 αₖ),也强烈依赖于训练数据本身的结构和分布。
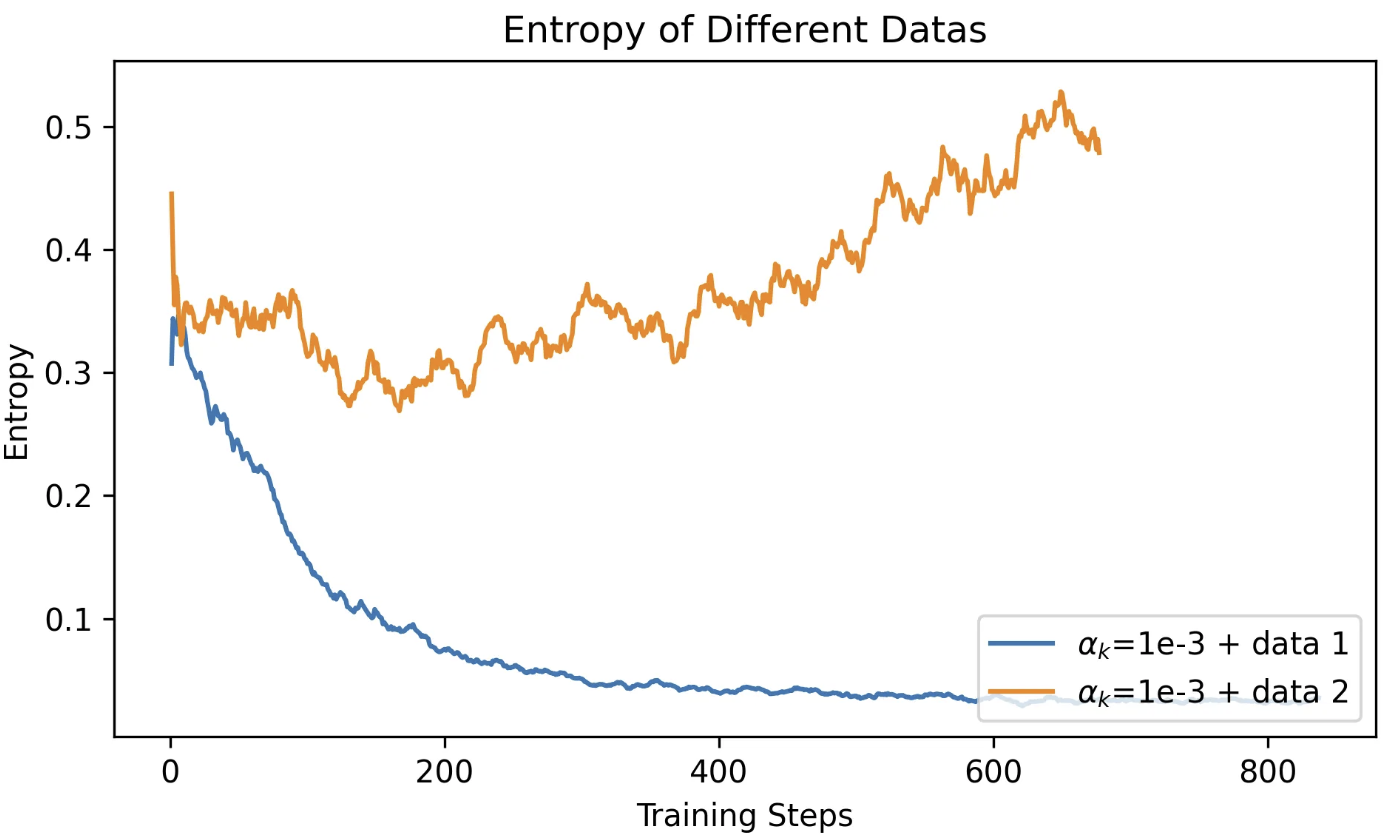
图9: 不同训练数据对熵的影响
因此,Skywork 得出如下结论:
❌ 单一静态 αₖ 无法泛化
✅ 熵控制必须具备数据自适应能力这直接催生了后续的 “Adaptive Entropy Control(自适应熵调节机制)”,也就是下一节内容的核心。
3.4.4 Our Method: Adaptive Entropy Control(自适应熵控制)
前几节表明,无论是固定的熵损失系数
,还是训练数据本身,都会对模型训练的熵轨迹造成极高敏感性。这使得“手动预设一个合适的熵系数”几乎不可能。
为此,Skywork 团队提出了一种自适应的解决方案:
自适应熵调节(核心思想)
目标:动态调节熵损失系数 αₖ,使当前模型的熵不低于目标熵(tgt-ent)
-
两个新超参数:
-
-
:期望维持的目标熵
-
-
:每步允许调整的熵系数变化幅度
-
-
初始设置:
-
熵损失系数初始化为
-
-
-
每个 rollout step 的动态调节规则:
-
若当前熵
-
- ,则提升熵系数:
-
若当前熵
- ,则降低熵系数:
-
-
最终熵损失系数表达式:
即:只有当当前熵低于目标熵时,才启用熵项进行正则化。
实验设置与效果
-
在 Skywork-OR1-Math-7B 上进行实测
- 设置:
-
-
实验中模型生成响应的熵始终稳定维持在目标值 0.2 左右,避免了熵爆炸或坍缩问题。
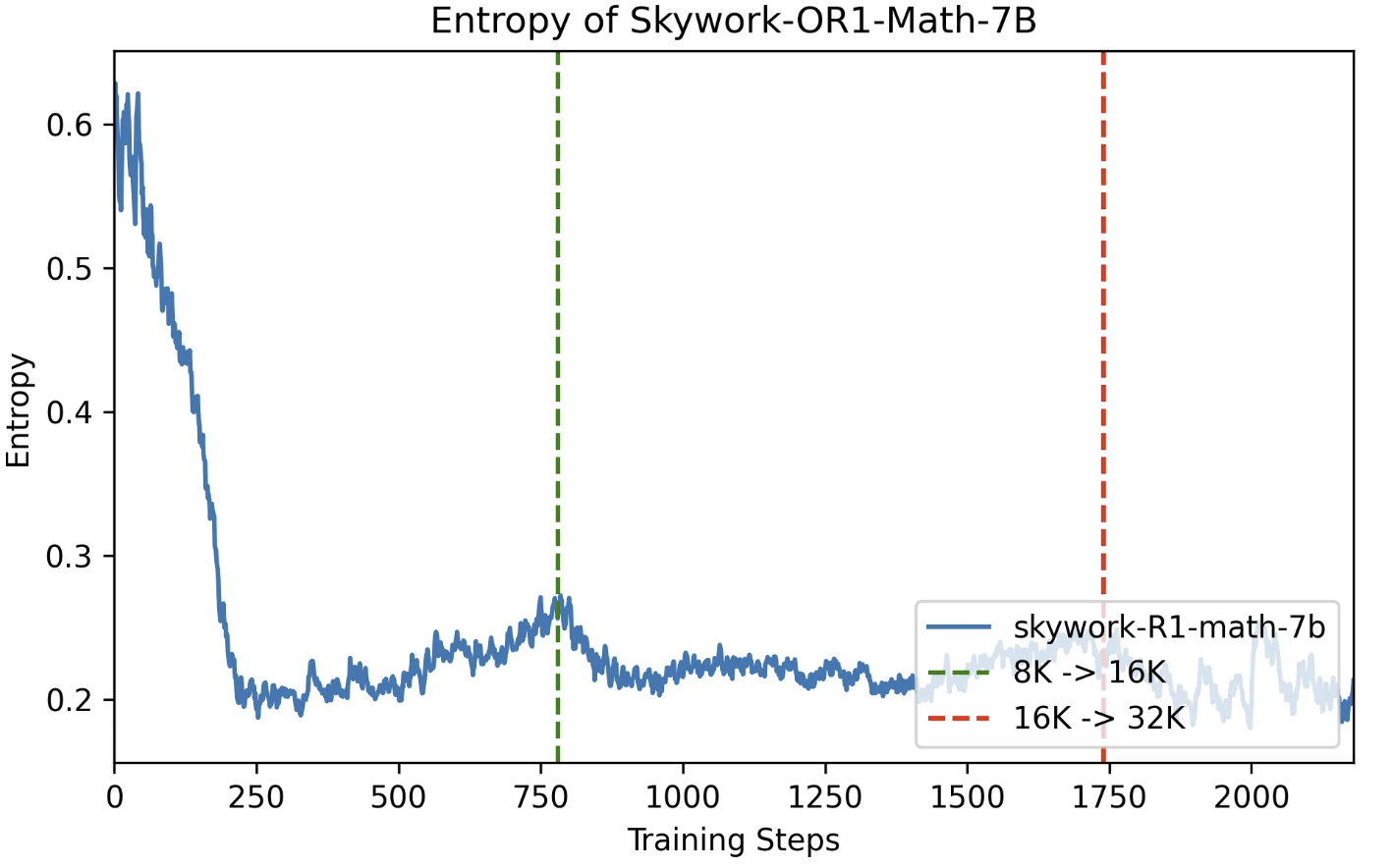
图10: 自适应熵控制
🧩 3.5 On the Effect of Temperature on Model Entropy(采样温度对模型熵的影响)
由于 Skywork 使用的 GRPO 是 group-wise 策略优化机制,模型的每一步训练都会采样一组(group)响应用于优化。如果组内响应高度相似或质量较差,则会极大降低训练效率。
而采样温度(temperature τ)的设置会直接影响:
-
生成样本的多样性(diversity)
-
group 的正确/错误比例
-
进而影响 RL 的优化信号与梯度方向
通过实验,Skywork 发现如下关键现象:
🔹 高温(如 τ = 1.0):
-
增强采样的多样性
-
但也可能导致 group 全错(无正向 advantage),影响效率
🔹 低温(如 τ = 0.6):
-
模型生成响应趋于集中和确定
-
group 中答案过于相似或全部正确 → advantage ≈ 0
-
学习信号迅速枯竭,导致训练停滞
❗ 最终导致:模型在前 100 步内熵快速下降或直接坍缩至 0,训练“卡死”
📊 实验对比结果(AIME25)
- 使用 τ = 0.6:
-
初始熵最低
-
准确率提升缓慢
-
- 使用 τ = 1.0:
-
初始熵较高,学习速度明显加快
-
后期准确率表现更好
-
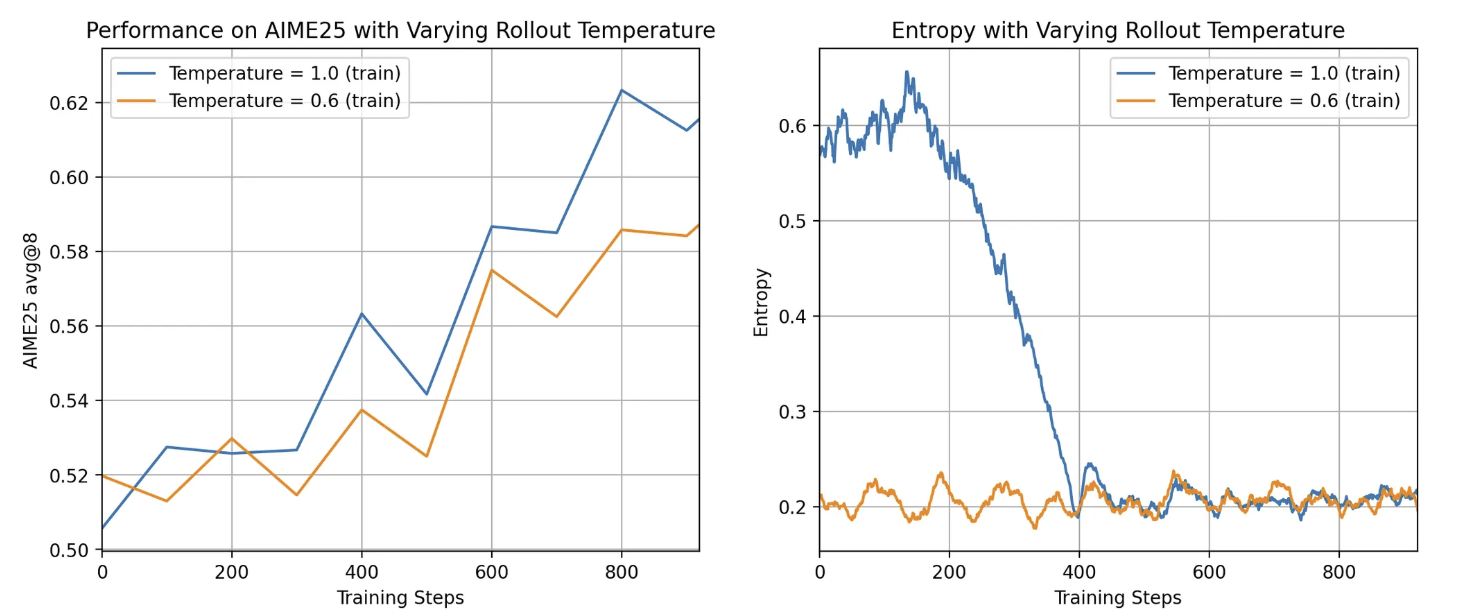
图11: 温度对模型效果影响
实验还发现:即便使用 adaptive entropy control 来维持熵在目标值(如 0.2)上下波动,不同温度起始熵的差异也显著影响早期学习信号。
“温度太低导致 group 中 token 分布高度重合,策略更新集中在少量 token 上,泛化能力变弱。”
使用更高温度:
-
有助于保持策略熵在合理区间
-
避免模型陷入“回答一模一样”的局部最优
✅ 总结一句话:
高温度采样 + 自适应熵调节 是 Skywork 保证 RL 有效性与稳定性的关键配置。
🧩 3.6 On the Issue of KL Loss(KL Loss 问题探讨)
在 GRPO 强化学习中,为了约束训练策略不要偏离参考模型(reference policy),常会引入 KL 正则项:
其中:
-
-
:原始策略损失
-
:KL 系数,用于控制正则强度
-
-
:参考策略(此处为 DeepSeek-R1-Distill-Qwen-7B)
Skywork 团队做了如下对比实验:
-
阶段 1:设定 KL 系数
-
- 阶段 2:分别运行两组模型
-
一组继续使用
-
-
一组设定
-
-
-
(完全去除 KL 项)
-
📊 实验结果
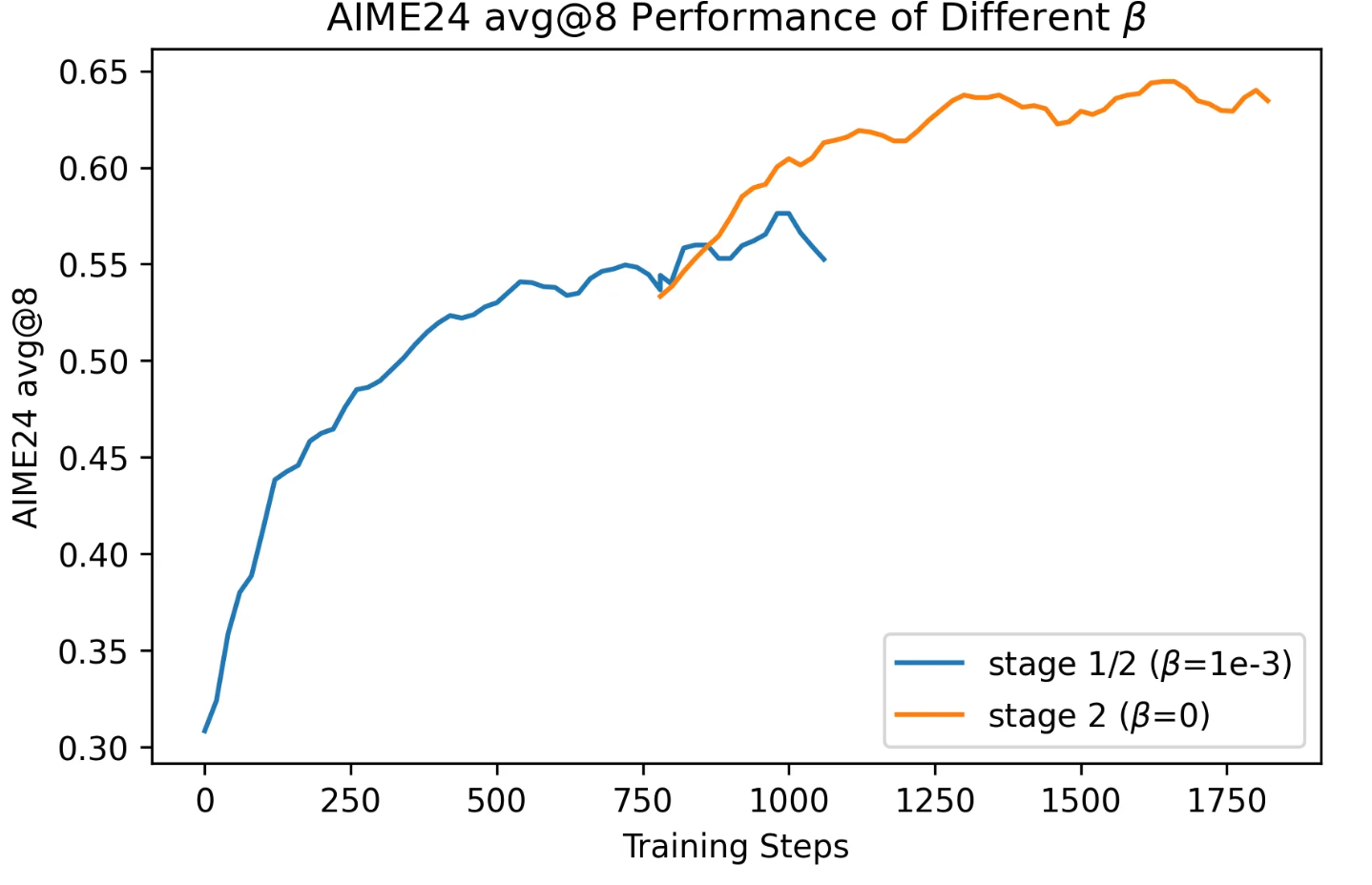
图12: 使用KL散度最终导致模型效果下降
-
**使用
-
-
**:
-
KL loss 强力将 actor 模型“拉回”参考模型
-
KL 散度迅速下降接近 0
-
导致策略几乎不再有新变化 ⇒ 性能提升停滞
-
-
**使用
-
-
**:
-
模型保持足够探索性
-
AIME24 上性能持续上升
-
结论:KL loss 阻碍了阶段 2 中策略的自由优化,反而影响性能提升
根据以上实验观察,Skywork 在最终所有模型训练流程中:
彻底移除 KL loss(即
),以保持策略探索与性能上升空间。
🧩 3.6 On the Effectiveness of Data Mixture(数据混合策略的有效性研究 )
Skywork 团队在训练 32B 模型的早期实验中,曾采用 DeepScaleR 数据集,其经过了类似的预处理与过滤流程。但实验发现:
✅ 在训练初期,模型准确率略有提升
❌ 训练到第 300 步后,性能大幅下滑,准确率回落到训练前水平这说明 DeepScaleR 数据对小模型可能有效,但对大模型并不稳健。
✅ Skywork 数据混合策略的改进点
为了获得更稳定、挑战性更高的数学任务数据,Skywork 做了如下设计:
-
在原始数据中加入了更多困难题目(hard problems)
-
这些题目主要筛选自 NuminaMath-1.5
-
并进行过 严格去重、结构校验、难度过滤
对比实验设置
-
比较对象:Skywork 的数学数据混合策略 vs DeepScaleR 的数据组合
-
模型:早期版本的 Skywork-OR1-32B(仅使用数学数据训练)
-
评估指标:AIME24 准确率、训练曲线变化趋势
📊 实验结果
数据混合策略 初期表现 长期稳定性 高难任务表现 DeepScaleR 中等 ❌ 容易退化 一般 Skywork 数据混合 ✅ 快速提升 ✅ 长期稳定 ✅ 突出提升 实验中 Skywork 数据混合策略不仅训练曲线更平稳,而且能显著提升模型在困难问题上的泛化能力。
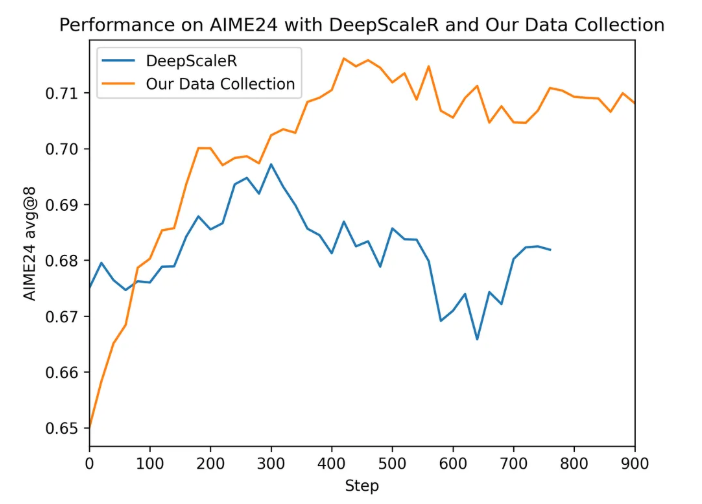
图13: Skywork数据混合 VS DeepScaleR数据
🌌 四、Math and Code Reward Function Design and Implementations(数学与代码任务的奖励函数设计与实现)
为了准确评估模型生成内容的正确性,Skywork 在数学与代码任务上分别设计了可复用、可扩展的奖励判别机制。
🧩 4.1 Math Verifiers(数学验证器)
为了构建可靠的数学奖励函数,Skywork 团队在所有实验初期,对当时主流的数学 rule-based verifier 做了系统性评估与对比。
评估对象包括:
-
原始 MATH 项目的 verl 版 verifier
-
PRIME verifier
-
Qwen2.5 verifier
-
DeepScaleR 的 verifier
-
Math-Verify
研究团队抽样一小批数学问题及其解答人工验证每个 verifier 的解析与判断质量。发现如下问题:
- Qwen2.5 verifier:
-
在解析带有 LaTeX 公式(如
\boxed{a^2})时,信息会丢失,可能解析成错误结果(如仅保留^2)
-
- PRIME verifier:
-
在运行过程中 容易卡死或超时
-
因此,Qwen2.5 与 PRIME 两个 verifier 被剔除,不再参与后续分析。
实验数据与分布分析
接下来,研究者使用 Skywork 的难度评估流程(difficulty estimation procedure)生成样本,并利用剩下的 verifier 来验证生成解的正确性。
-
验证器评估结果用于统计不同难度等级(0–8)下正确 rollouts 的数量分布
-
不同 verifier 的验证能力对最终数据筛选与评估精度影响显著
下图展示了验证器在 NuminaMath-1.5 子集上的覆盖情况:
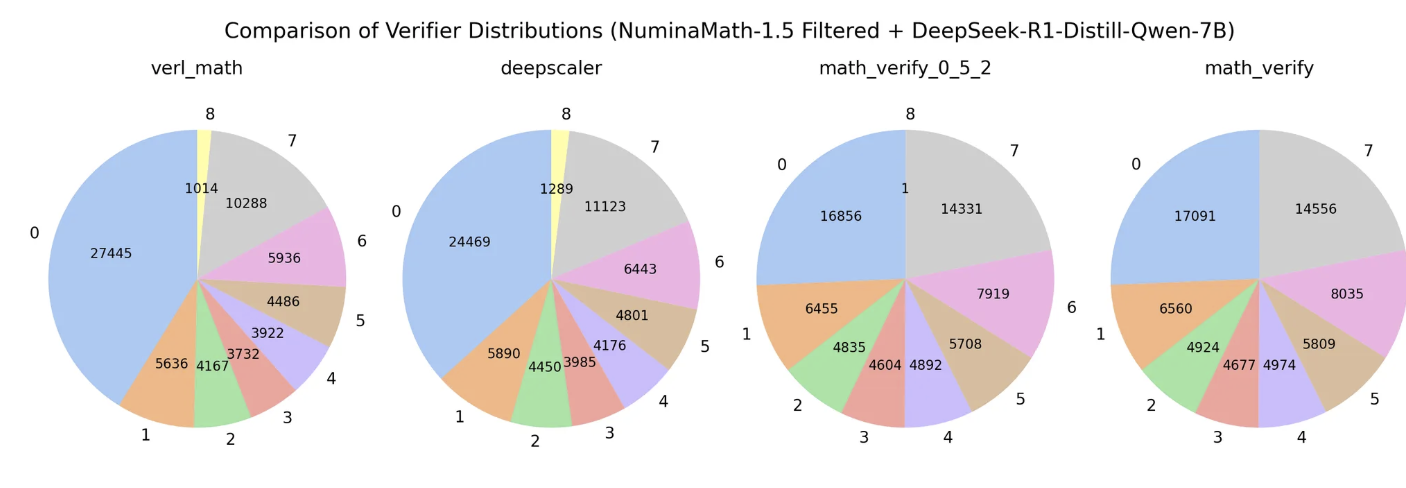
图14: 验证器给出的难度分布
与人工判定结果对比
Skywork 将 verifier 判定结果与人工评审结论对比,验证其可靠性,并将表现良好的 verifier 融入 RL 奖励函数体系。
最终决定使用:
-
DeepScaleR 的 verifier
-
Math-Verify(HuggingFace 实现)
这些 verifier 在准确性与执行稳定性之间达成了良好平衡。
🧩 4.2 Code Sandboxes(代码沙箱环境)
在处理 代码生成任务的奖励函数时,Skywork 团队非常重视评估的可靠性和安全性。
为此,团队开发并使用了 代码沙箱(code sandbox),用于执行模型生成的代码,并进行自动化测试与评估。沙箱机制的作用
-
执行测试用例(test cases):确保模型生成的代码能够被成功执行
-
对比输出与预期结果:判断代码是否正确解决了问题
-
隔离执行环境:保障测试安全,避免运行任意代码造成系统风险
实现细节与规则
Skywork 在沙箱环境中定义了如下执行流程:
- 对于每一道代码题(如 LeetCode/TACO 题目):
-
解析题目和模型输出的代码
-
在沙箱中 加载题目的原始测试用例
-
运行代码,并对比所有测试用例的输出
-
-
只有当所有测试用例都通过,才判定该解为 reward = 1,否则为 0
🌌 五、Training of Open-Source Models(开源模型训练流程)
Skywork 团队致力于推动推理领域的开源研究,公开了用于训练 Skywork-OR1 系列模型的完整流程,包括:
-
数据准备策略
-
多阶段训练机制
-
RL 优化细节(如熵控制、奖励函数)
-
超参数设置
-
训练代码和模型权重
多阶段训练结构(Multi-Stage Training Setup)
Skywork 所有开源模型均采用多阶段训练框架:
模型 Stage 1 Stage 2 Stage 3 Skywork-OR1-Math-7B 8K 16K 32K Skywork-OR1-7B-Preview 8K 16K 32K Skywork-OR1-32B-Preview 8K 16K 32K 这个设计显著提高了训练效率,并保留模型的扩展能力。
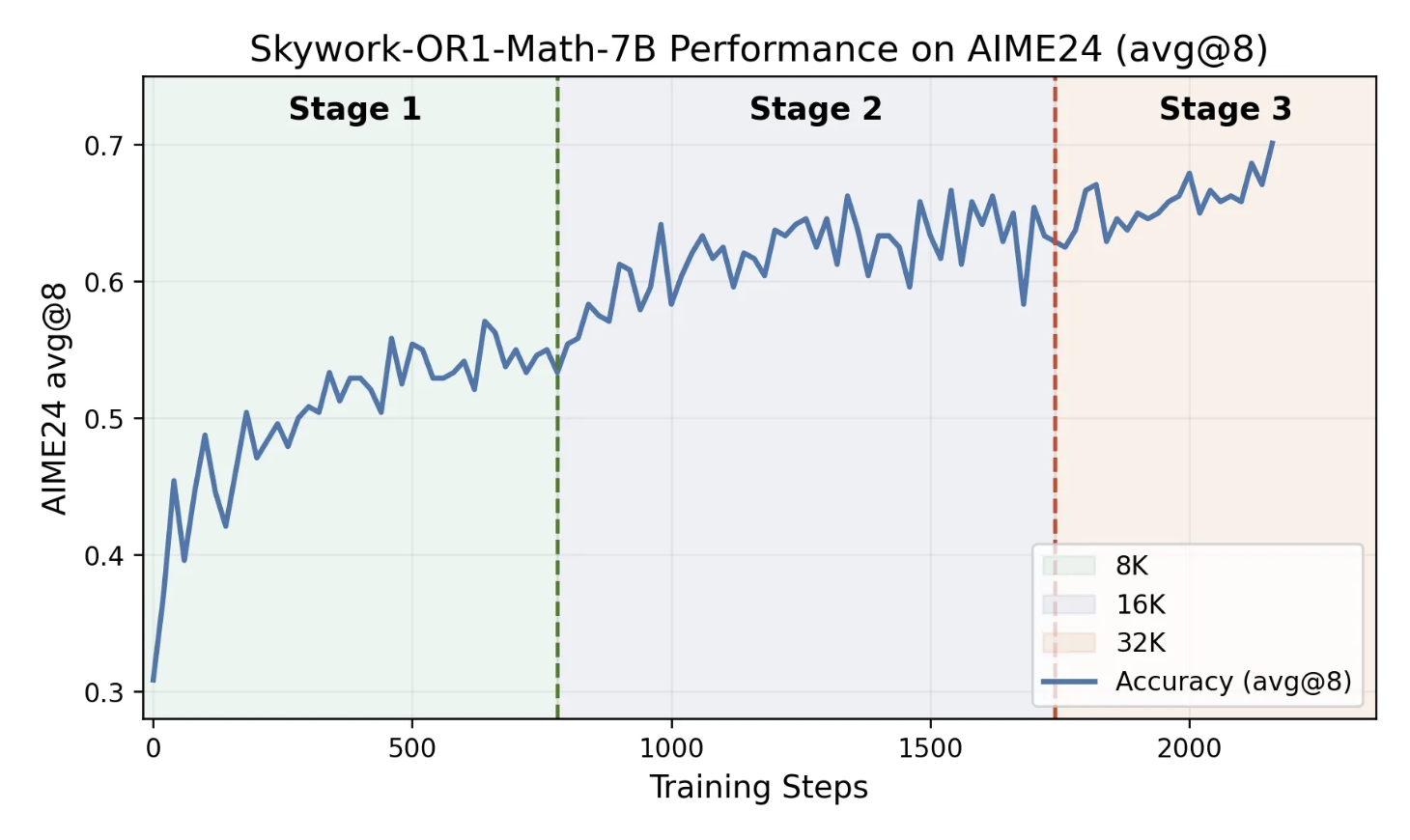
图15: 多阶段训练
模型与资源开放
以下所有内容已完全开源并可复现:
内容类别 链接或位置 🤗 HuggingFace 模型仓库 Skywork OR1 模型 🤗 HuggingFace 数据集 Skywork OR1 RL 数据 🧑💻 训练代码 GitHub Repo 📚 技术博客 Notion 博客 这些资源包含训练日志、数据处理脚本、reward 逻辑实现等,支持社区开发者完整复现 Skywork 的训练成果。
-


)



