本文介绍了酶作用优化(EAO)算法,这是一种新颖的仿生优化算法,旨在模拟生物系统中的自适应酶机制。EAO采用了一种动态平衡探索和开发的新颖策略,以有效地导航和优化复杂的多维搜索空间。于2025发表在JCR 2区,中科院4区 SCI计算机类期刊 The Journal of Supercomputing。
1、灵感来源
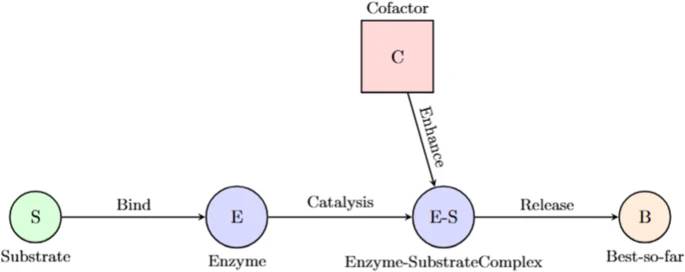
EAO从生物系统中酶的催化行为中汲取灵感。酶是通过与目标分子结合来加速化学反应的特殊蛋白质,称为底物。结合后,酶-底物复合物经历了微妙的结构变化,降低了活化能,增加了反应速率,而不消耗酶[15]。这种适应性机制,其中酶(催化剂)在辅因子和环境信号的影响下促进底物转化,形成了EAO优化算法的基础。在酶动力学中,辅因子、pH水平、温度和浓度梯度都可以影响底物转化。酶采用多种配置并使用灵活的活性位点,平衡代谢途径的探索和开发。类似地,EAO通过采用酶-底物类比与这些自适应步骤平行,其中候选溶液(底物)与迄今为止最佳溶液(酶)相互作用。随机扰动反映了生物过程的随机动力学,如图1所示。
2 EAO的数学模型
本节解释了EAO的数学模型,其中第一步是子策略初始化。搜索代理(子策略)的数量用 N N N表示,最大迭代次数用 T T T表示,搜索空间的维度用 dim_search \text{dim\_\text{search}} dim_search表示。每个决策变量被限制在下界(LB)和上界(UB)之间,表示为在每个维度中定义可行区域的向量。令 f ( x ) f(\mathbf{x}) f(x)表示要最小化的目标函数。公式(1)提供了子策略池的随机初始化方案:
X i ( 0 ) = LB + ( UB − LB ) ⊙ r i , (1) \mathbf{X}_i^{(0)} = \text{LB} + (\text{UB} - \text{LB}) \odot \mathbf{r}_i, \tag{1} Xi(0)=LB+(UB−LB)⊙ri,(1)
其中 X i ( 0 ) \mathbf{X}_i^{(0)} Xi(0)是第 i i i个搜索代理(子策略)的初始位置, r i \mathbf{r}_i ri是[0, 1]中均匀分布的随机值向量, ⊙ \odot ⊙表示元素乘法。索引 i i i从1到 N N N。
一旦生成了初始子策略位置,使用公式(2)评估每个子策略的适应度,从而衡量其质量:
F i ( 0 ) = f ( X i ( 0 ) ) , (2) F_i^{(0)} = f(\mathbf{X}_i^{(0)}), \tag{2} Fi(0)=f(Xi(0)),(2)
其中 F i ( 0 ) F_i^{(0)} Fi(0)是第 i i i个子策略的初始适应度。
在迭代0时,通过识别 F i ( 0 ) F_i^{(0)} Fi(0)的最小值来确定最佳子策略,相应的位置定义为 X best ( 0 ) \mathbf{X}_{\text{best}}^{(0)} Xbest(0)。量 F best ( 0 ) = f ( X best ( 0 ) ) F_{\text{best}}^{(0)} = f(\mathbf{X}_{\text{best}}^{(0)}) Fbest(0)=f(Xbest(0))表示迭代0时的最佳适应度值。从 t = 1 t = 1 t=1到 t = T t = T t=T的主要迭代循环中,采用几种自适应策略。公式(3)定义了每次迭代 t t t的自适应因子(AF):
AF t = t MaxIter (3) \text{AF}_t = \sqrt{\frac{t}{\text{MaxIter}}} \tag{3} AFt=MaxItert(3)
此平方根关系确保随着迭代的进行,自适应因子逐渐增加。
在每次迭代 t t t时,每个子策略 X i ( t − 1 ) \mathbf{X}_i^{(t-1)} Xi(t−1)生成两个候选位置。公式(4)描述了第一个子策略候选位置:
X i , 1 ( t ) = ( X best ( t − 1 ) − X i ( t − 1 ) ) + ρ i ⊙ sin ( AF t ⋅ ( X best ( t − 1 ) − X i ( t − 1 ) ) ) \mathbf{X}_{i,1}^{(t)} = (\mathbf{X}_{\text{best}}^{(t-1)} - \mathbf{X}_i^{(t-1)}) + \rho_i \odot \sin(\text{AF}_t \cdot (\mathbf{X}_{\text{best}}^{(t-1)} - \mathbf{X}_i^{(t-1)})) Xi,1(t)=(Xbest(t−1)−Xi(t−1))+ρi⊙sin(AFt⋅(Xbest(t−1)−Xi(t−1)))
其中 ρ i \rho_i ρi是[0, 1] dim ^{\text{dim}} dim中的随机向量,正弦函数逐元素应用。结果位置 X i , 1 ( t ) \mathbf{X}_{i,1}^{(t)} Xi,1(t)被限制在区间[LB, UB]内,以确保其在可行区域内。
为了生成第二个子策略候选位置,从集合{1, 2, …, N}中选择两个不同的子策略索引 p , q p, q p,q。这些索引定义向量 d \mathbf{d} d,如公式(5)所示:
d = X p ( t − 1 ) − X q ( t − 1 ) (5) \mathbf{d} = \mathbf{X}_p^{(t-1)} - \mathbf{X}_q^{(t-1)} \tag{5} d=Xp(t−1)−Xq(t−1)(5)
其中此差异用于将额外多样性注入搜索过程中。
公式(6)定义了第二个子策略候选位置。它通过结合上述元素构建:
X i , 2 ( t ) = X i ( t − 1 ) + s c 1 d i + AF t s c 2 ( X best ( t − 1 ) − X i ( t − 1 ) ) \mathbf{X}_{i,2}^{(t)} = \mathbf{X}_i^{(t-1)} + s c_1 \mathbf{d}_i + \text{AF}_t s c_2 (\mathbf{X}_{\text{best}}^{(t-1)} - \mathbf{X}_i^{(t-1)}) Xi,2(t)=Xi(t−1)+sc1di+AFtsc2(Xbest(t−1)−Xi(t−1))
系数 s c 1 s c_1 sc1和 s c 2 s c_2 sc2是[EC, 1]区间内的随机缩放因子,其中EC是酶浓度(通常为小常数,例如0.1)。此位置也被限制在[LB, UB]内以保持可行性。
在每次迭代 t t t时,评估 X i , 1 ( t ) \mathbf{X}_{i,1}^{(t)} Xi,1(t)和 X i , 2 ( t ) \mathbf{X}_{i,2}^{(t)} Xi,2(t),这两个候选位置如公式(7)所示:
X i ( t ) = { X i , 1 ( t ) , if F ( X i , 1 ( t ) ) < F ( X i ( t − 1 ) ) , X i ( t − 1 ) , otherwise . (7) \mathbf{X}_i^{(t)} = \begin{cases} \mathbf{X}_{i,1}^{(t)}, & \text{if } F(\mathbf{X}_{i,1}^{(t)}) < F(\mathbf{X}_i^{(t-1)}), \\ \mathbf{X}_i^{(t-1)}, & \text{otherwise}. \end{cases} \tag{7} Xi(t)={Xi,1(t),Xi(t−1),if F(Xi,1(t))<F(Xi(t−1)),otherwise.(7)
当达到更好的适应度时,此更新位置替换 X i ( t − 1 ) \mathbf{X}_i^{(t-1)} Xi(t−1),如公式(8)所示:
X i ( t ) = { X i , upd ( t ) , if F ( X i , upd ( t ) ) < F ( X i ( t − 1 ) ) , X i ( t − 1 ) , otherwise . (8) \mathbf{X}_i^{(t)} = \begin{cases} \mathbf{X}_{i,\text{upd}}^{(t)}, & \text{if } F(\mathbf{X}_{i,\text{upd}}^{(t)}) < F(\mathbf{X}_i^{(t-1)}), \\ \mathbf{X}_i^{(t-1)}, & \text{otherwise}. \end{cases} \tag{8} Xi(t)={Xi,upd(t),Xi(t−1),if F(Xi,upd(t))<F(Xi(t−1)),otherwise.(8)
然后如公式(9)所示更新全局最佳:
if F ( X i ( t ) ) < F best ( t − 1 ) ⟹ X best ( t ) = X i ( t ) , F best ( t ) = F ( X i ( t ) ) . (9) \text{if } F(\mathbf{X}_i^{(t)}) < F_{\text{best}}^{(t-1)} \implies \mathbf{X}_{\text{best}}^{(t)} = \mathbf{X}_i^{(t)}, F_{\text{best}}^{(t)} = F(\mathbf{X}_i^{(t)}). \tag{9} if F(Xi(t))<Fbest(t−1)⟹Xbest(t)=Xi(t),Fbest(t)=F(Xi(t)).(9)
在EAO中,每个子策略位置都保持在其允许区间内,通过更新子策略位置到下界和上界向量LB和UB进行约束。在每次更新步骤(公式(4)-(6))之后,任何超过上界 UB d \text{UB}_d UBd的子策略 X i \mathbf{X}_i Xi的维度 d d d被设置为 UB d \text{UB}_d UBd,任何低于下界 LB d \text{LB}_d LBd的维度被设置为 LB d \text{LB}_d LBd,如公式(10)所述:
X i ( d ) = max ( min ( X i ( d ) , UB d ) , LB d ) , ∀ d ∈ { 1 , … , dim } . (10) \mathbf{X}_i(d) = \max(\min(\mathbf{X}_i(d), \text{UB}_d), \text{LB}_d), \quad \forall d \in \{1, \ldots, \text{dim}\}. \tag{10} Xi(d)=max(min(Xi(d),UBd),LBd),∀d∈{1,…,dim}.(10)
这种机制确保了每次迭代时所有解都保持在搜索空间边界内。
为了更好地说明EAO中的更新机制,图4提供了搜索空间的概念布局,展示了这些候选更新如何围绕当前子策略 X i \mathbf{X}_i Xi、差异向量 d \mathbf{d} d和最佳子策略旋转。
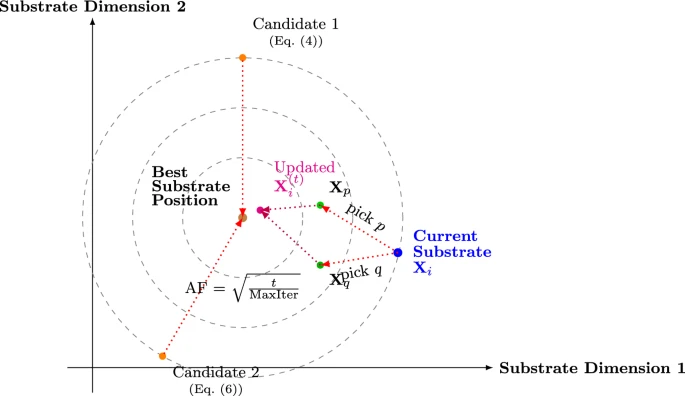
图4. 最佳子策略更新的概念模型
3、 EAO算法分析
算法1概述了EAO的伪代码。该过程从初始化子策略池(步骤1)和识别最佳解开始。然后,对于每次迭代(步骤2),计算控制因子(AF)。每个子策略产生两个候选位置:
- 一个位置部分由当前最佳子策略的差异信息形成,向搜索过程中注入种群多样性。
- 一个位置受两个随机选择的子策略之间差异的影响。
评估后,如果候选位置产生更好的适应度,则替换原始子策略。相应地更新全局最佳解。达到最大迭代次数后,返回最终最佳子策略作为近似全局最优解(步骤3)。
算法1

Rodan, A., Al-Tamimi, AK., Al-Alnemer, L. et al. Enzyme action optimizer: a novel bio-inspired optimization algorithm. J Supercomput 81, 686 (2025). https://doi.org/10.1007/s11227-025-07052-w.
function [OptimalCatalysis, BestSubstrate, conv_curve] = EAO(EnzymeCount, MaxIter, LB, UB, ...ActiveSiteDimension, EvaluateCatalysis)
% --- 1) Initialization ---
SubstratePool = LB + (UB - LB) .* rand(EnzymeCount, ActiveSiteDimension);
ReactionRate = arrayfun(@(i) EvaluateCatalysis(SubstratePool(i,:)),1:EnzymeCount)';
[OptimalCatalysis, idx] = min(ReactionRate);
BestSubstrate = SubstratePool(idx,:);
conv_curve = zeros(1, MaxIter);
%EAO parameter (Enzyme Concentration EC)
EC = 0.1;
for t = 1:MaxIterAF = sqrt(t / MaxIter);for i = 1:EnzymeCount% 1) Update FirstSubstratePositionFirstSubstratePosition = (BestSubstrate - SubstratePool(i,:)) + rand(1, ActiveSiteDimension) ....* sin(AF * SubstratePool(i,:));FirstSubstratePosition = max(min(FirstSubstratePosition, UB),LB);FirstEvaluation = EvaluateCatalysis(FirstSubstratePosition);% 2) Pick two random distinct SubstratesSubstrates = randperm(EnzymeCount, 2);while any(Substrates == i)Substrates = randperm(EnzymeCount, 2);endS1 = SubstratePool(Substrates(1), :);S2 = SubstratePool(Substrates(2), :);% 2.1) vector-valued random factors for each dimensionscA1 = EC + (1-EC)*rand(1, ActiveSiteDimension);exA = (EC + (1-EC)*rand(1, ActiveSiteDimension)) .* AF;CandidateA = SubstratePool(i,:) + scA1 .* (S1 - S2) + exA .* (BestSubstrate - SubstratePool(i,:));CandidateA = max(min(CandidateA, UB), LB);CandidateAFitness = EvaluateCatalysis(CandidateA);% 2.2) scalar random factors for all dimensionsscB1 = EC + (1-EC)*rand();exB = (EC + (1-EC)*rand()) * AF;CandidateB = SubstratePool(i,:) + scB1 .* (S1 - S2) + exB .* (BestSubstrate - SubstratePool(i,:));CandidateB = max(min(CandidateB, UB), LB);CandidateBFitness = EvaluateCatalysis(CandidateB);% 2.3) Pick better candidate (Update SecondSubstratePosition)if CandidateAFitness < CandidateBFitnessSecondSubstratePosition = CandidateA;SecondEvaluation = CandidateAFitness;elseSecondSubstratePosition = CandidateB;SecondEvaluation = CandidateBFitness;end% 3) Compare FirstSubstratePosition vs. SecondSubstratePositionif FirstEvaluation < SecondEvaluationUpdatedPosition = FirstSubstratePosition;UpdatedFitness = FirstEvaluation;elseUpdatedPosition = SecondSubstratePosition;UpdatedFitness = SecondEvaluation;end% 4) Update SubstratePool & Global Bestif UpdatedFitness < ReactionRate(i)SubstratePool(i, :) = UpdatedPosition;ReactionRate(i) = UpdatedFitness;if UpdatedFitness < OptimalCatalysisOptimalCatalysis = UpdatedFitness;BestSubstrate = UpdatedPosition;endendendconv_curve(t) = OptimalCatalysis;
end
end


)



