🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
前言
在 AI 的热潮中,很容易忽视那些让它得以实现的基础数学和技术。作为一名专业人士,通过不使用机器学习库(比如 sklearn、TensorFlow、PyTorch 等)来编写模型,可以显著提升你对这些基础技术的理解。因为有时候,用现成的工具就像吃别人嚼过的糖,没劲!自己动手,那才叫真本事,不仅能搞懂背后的原理,还能在朋友面前炫耀一番:“看我这代码,多牛!”所以,咱们这就开始,一起踏上这个充满挑战和乐趣的旅程吧!🚀
本系列我们会深入探讨各种机器学习模型,并从零搭建它们。在每篇文章结束时,我希望读者能够对这些我们每天作为数据专业人士使用的模型有极其深入和基础的理解。咱们就从多元线性回归开始吧!
多元线性回归
多元线性回归可以用来模拟两个或多个自变量与一个数值型因变量之间的关系。日常用例包括根据房屋的卧室数量、浴室数量、面积等信息预测房价。咱们先来聊聊多元线性回归的一些关键假设。
- 自变量与因变量的线性关系:具体来说,任何一个自变量(或特征)变化 1 个单位时,因变量应该以恒定的速率变化。
- 没有多重共线性:这意味着特征之间需要相互独立。以房价为例,如果卧室数量和浴室数量之间存在某种相关性,这可能会影响模型的性能。确保没有或最小化多重共线性,也能让你更高效地利用给定的数据。
- 同方差性:这意味着在任何自变量水平下,误差都是恒定的。如果咱们的房价预测模型显示,随着预测价格的上升,误差也在增加,那咱们就不能说这个模型满足同方差性了。可能需要对特征数据进行一些变换,以满足这个假设。
数学原理
还记得 (y = mx + b) 吗?大多数人在公立学校的时候都学过这个公式。而多元线性回归则可以用下面的公式表示:
y = B 0 + B 1 x 1 + B 2 x 2 + ⋯ + B n x n + E y = B_0 + B_1x_1 + B_2x_2 + \dots + B_nx_n + E y=B0+B1x1+B2x2+⋯+Bnxn+E
- y y y:因变量或目标变量,也就是咱们要预测的东西。
- B 0 , B 1 , … , B n B_0, B_1, \dots, B_n B0,B1,…,Bn:“Beta” 或自变量的系数。 B 0 B_0 B0 是截距,类似于 y = m x + b y = mx + b y=mx+b 中的 b b b。剩下的系数分别代表剩下的自变量或特征的系数。
- x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x1,x2,…,xn:自变量或特征。
- E E E:“Epsilon”,更实际地说是误差项,也就是咱们的预测值与实际 y y y 之间的差距。
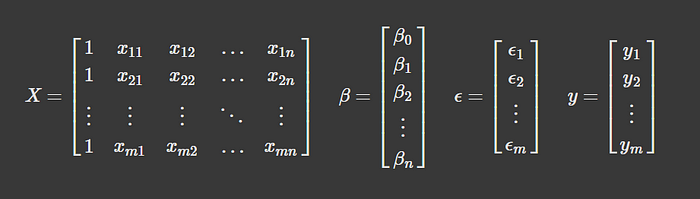
你也可以用矩阵表示法来表示多元线性回归方程。我个人更喜欢这种方法,因为它让我不得不从向量和矩阵的角度去思考,而这些正是几乎所有机器学习模型背后的数学核心。
Y = X B + E \mathbf{Y} = \mathbf{X} \mathbf{B} + \mathbf{E} Y=XB+E
咱们来更直观地看看这些变量里都有啥。先从 X \mathbf{X} X 开始,它代表了咱们所有的特征数据,是一个矩阵。注意,这个矩阵的第一列全是 1。为啥呢?这代表了截距项 B 0 B_0 B0 的占位符。
从数据角度来看,咱们有啥呢?咱们有所有的特征数据、目标变量 Y Y Y,误差项理论上是未知的,但它只是预测值 y y y 与实际值 y y y 之间的差距。换句话说,它只是用来补全方程的。所以,咱们需要求解的是 B \mathbf{B} B,也就是权重。
 ### 最小化代价函数
### 最小化代价函数
要找到 B \mathbf{B} B,请注意,咱们并不是直接求解它。相反,咱们想找到向量 B \mathbf{B} B 中的值,使得预测值与实际值之间的误差最小化。这是通过最小化关于 B \mathbf{B} B 的代价函数来实现的,这个代价函数也被称为均方误差。
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1




