多层LSTM连接示意图:

单层LSTM的动态实现:
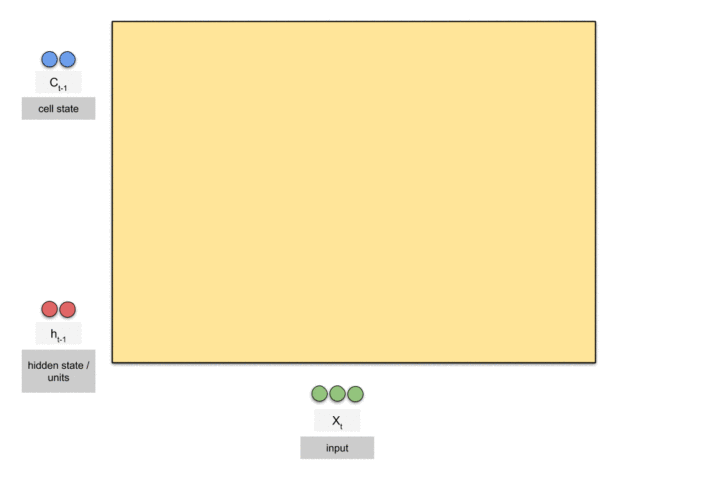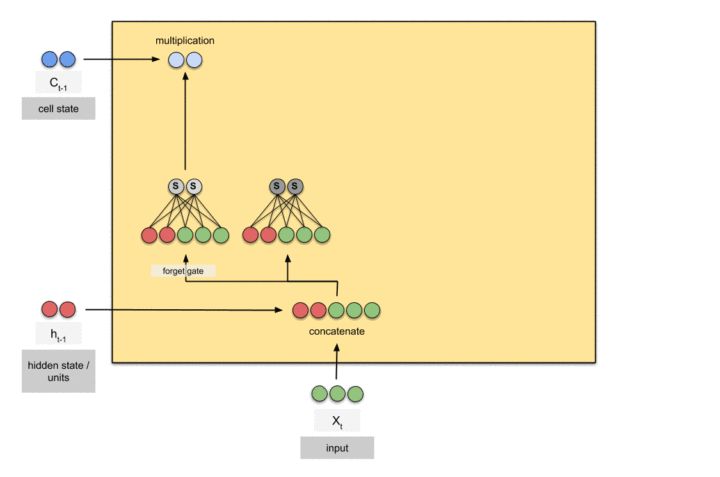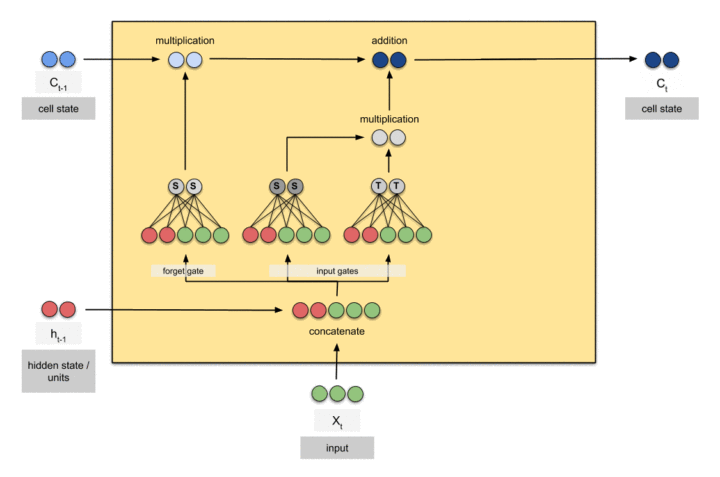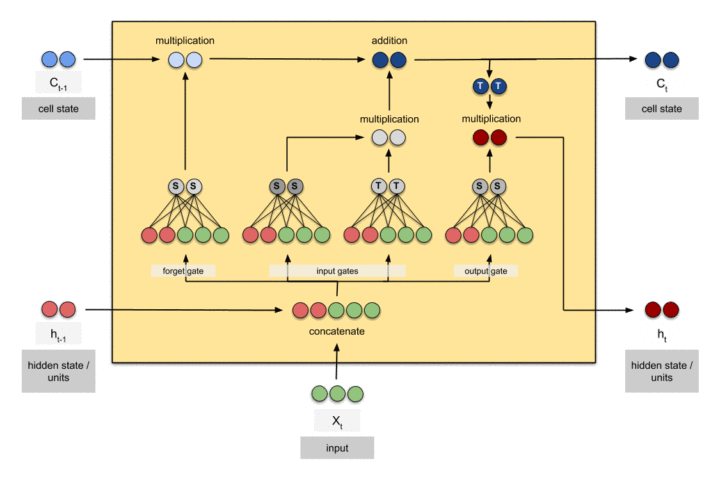
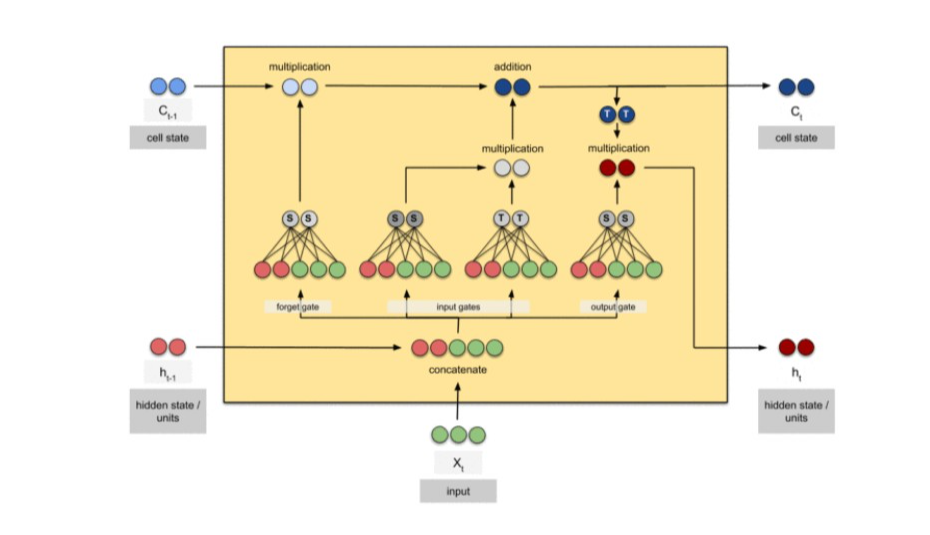
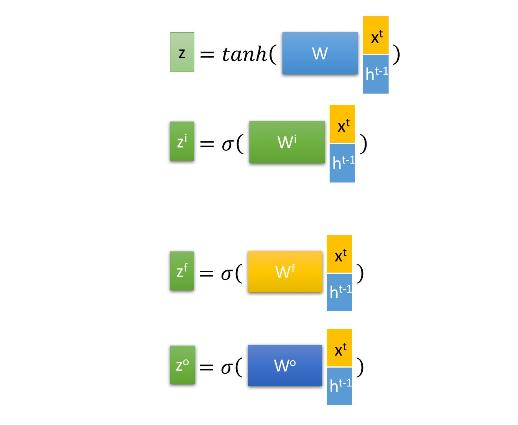
输入门、遗忘门、输出门:
import paddle
rnn = paddle.nn.LSTM(input_size=6, hidden_size=8, num_layers=2)
x = paddle.randn((4, 3, 6))
print('x',x)
y, (h, c) = rnn(x)
print(rnn)print('y',y)
print(y.shape) print('h',h)
print(h.shape)
print('c',c)
print(c.shape) paddle.summary(rnn,(4, 3, 6))
(6)之和
x Tensor(shape=[4, 3, 6], dtype=float32, place=CPUPlace, stop_gradient=True,[[[-0.39994577, -0.16884394, -1.09118211, 0.80282438, 0.77592939, 1.98887908],[-1.37776613, -0.50116003, -1.59069943, -0.92857558, -0.32358357, 0.40606323],[ 0.51607883, -0.90631920, -2.49934697, 0.52673978, 0.35466543, -1.23233390]],[[-0.35236493, -0.80131197, 0.41734406, 0.70300984, 2.56589055, -0.57770211],[ 0.52168477, -1.14594662, 0.89456636, 0.60237592, -0.64571965, -0.92338151],[-0.89197439, 2.07416654, 0.09576637, 0.51839197, -0.35192293, -0.34265402]],[[-1.20565021, -0.13362758, -1.21440089, 0.36546969, 0.29902026, 1.14574087],[ 0.16499370, -1.05054629, 0.60000432, -0.73830217, 1.45883906, 0.80631649],[ 0.90025264, -0.88333410, 1.86590922, 0.94177932, 0.25186336, 0.73045748]],[[ 0.59448457, 0.20400517, 0.10334436, 0.64043117, 1.15682471, 0.09200878],[-0.67695278, 0.52044302, -0.78882062, 1.27999902, 0.06613204, 1.43959534],[-0.00347163, 1.17208421, 0.45402086, -0.14898437, -0.22504820, 0.67211795]]])
LSTM(6, 8, num_layers=2(0): RNN((cell): LSTMCell(6, 8))(1): RNN((cell): LSTMCell(8, 8))
)
y Tensor(shape=[4, 3, 8], dtype=float32, place=CPUPlace, stop_gradient=False,[[[ 0.12606533, 0.03723524, -0.01543412, -0.05093168, -0.00058493, 0.02041843, -0.02015576, -0.03794828],[ 0.19590674, 0.09097288, -0.01683361, -0.09791360, 0.02531381, 0.04274859, -0.04400444, -0.05620224],[ 0.22171436, 0.14395498, -0.01471146, -0.12150520, 0.06584308, 0.05339855, -0.07185388, -0.05342202]],[[ 0.09426511, 0.04475664, -0.01056199, -0.07163173, 0.00677959, 0.02386722, -0.01371512, -0.04715024],[ 0.14545080, 0.07383338, -0.00895626, -0.13342401, 0.01213170, 0.04805123, -0.00590389, -0.06722270],[ 0.18524487, 0.11151871, 0.00289736, -0.19252071, 0.02871165, 0.06043112, -0.01222652, -0.06402460]],[[ 0.12229927, 0.05400331, -0.00953178, -0.06553464, 0.01734342, 0.02204929, -0.02571913, -0.04117016],[ 0.16857712, 0.07484694, -0.02250303, -0.09614565, -0.00239868, 0.04445631, -0.03118773, -0.05886544],[ 0.20006333, 0.06436764, -0.02840774, -0.11968626, -0.03018227, 0.06358111, -0.01926485, -0.06980018]],[[ 0.10642181, 0.05075689, -0.01515573, -0.05271235, 0.01304606, 0.02216698, -0.02666905, -0.04353783],[ 0.18087025, 0.06951316, -0.01432738, -0.10333572, -0.00218153, 0.04213399, -0.02817569, -0.05427728],[ 0.21686205, 0.08704377, -0.01545346, -0.12414743, -0.00640737, 0.05959129, -0.03789495, -0.05795782]]])
[4, 3, 8]
h Tensor(shape=[2, 4, 8], dtype=float32, place=CPUPlace, stop_gradient=False,[[[ 0.17736050, -0.08764581, 0.05920768, 0.03660521, 0.17524016, -0.19638550, 0.34747770, 0.21448627],[ 0.06513791, -0.11409879, -0.21574451, -0.14325079, 0.02657837, -0.27729952, -0.19942993, -0.03731265],[ 0.04778732, 0.21589978, -0.11827739, -0.12047609, 0.27885476, 0.02591145, -0.15165608, -0.39237073],[ 0.01800619, 0.05139154, -0.17368346, 0.08708881, 0.35007477, -0.10484657, -0.12915266, -0.13835609]],[[ 0.22171436, 0.14395498, -0.01471146, -0.12150520, 0.06584308, 0.05339855, -0.07185388, -0.05342202],[ 0.18524487, 0.11151871, 0.00289736, -0.19252071, 0.02871165, 0.06043112, -0.01222652, -0.06402460],[ 0.20006333, 0.06436764, -0.02840774, -0.11968626, -0.03018227, 0.06358111, -0.01926485, -0.06980018],[ 0.21686205, 0.08704377, -0.01545346, -0.12414743, -0.00640737, 0.05959129, -0.03789495, -0.05795782]]])
[2, 4, 8]
c Tensor(shape=[2, 4, 8], dtype=float32, place=CPUPlace, stop_gradient=False,[[[ 0.37910637, -0.42640921, 0.12153221, 0.06514800, 0.49467742, -0.33455023, 0.49630848, 0.28509313],[ 0.10826016, -0.28854835, -0.58194470, -0.24991161, 0.03781226, -0.45884287, -0.37416759, -0.11784617],[ 0.16163930, 0.67656636, -0.33257541, -0.33084434, 0.36936939, 0.13234609, -0.24183141, -0.92222750],[ 0.04265260, 0.11543229, -0.35903591, 0.16842273, 0.48566097, -0.27855623, -0.24916294, -0.36821401]],[[ 0.46252376, 0.27226013, -0.02847151, -0.19650725, 0.13580972, 0.11520113, -0.17235029, -0.10225918],[ 0.38834193, 0.20850745, 0.00485603, -0.34224576, 0.06490447, 0.13443303, -0.02630240, -0.11699687],[ 0.44824469, 0.13285753, -0.05207641, -0.23715332, -0.06911413, 0.14895318, -0.04506143, -0.13610318],[ 0.47666115, 0.16542867, -0.02775677, -0.23145792, -0.01375821, 0.13625184, -0.08468147, -0.10931204]]])
[2, 4, 8]
------------------------------------------------------------------------------------------Layer (type) Input Shape Output Shape Param #
==========================================================================================LSTM-2 [[4, 3, 6]] [[4, 3, 8], [[2, 4, 8], [2, 4, 8]]] 1,088
==========================================================================================
Total params: 1,088
Trainable params: 1,088
Non-trainable params: 0
------------------------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.01
------------------------------------------------------------------------------------------{'total_params': 1088, 'trainable_params': 1088}






