你是否想过,AI是如何“理解”我们这个多彩世界的呢?
最近,一项由中国人民大学高瓴GeWu-Lab、北京邮电大学、上海AI Lab等机构联合研究的成果,为AI的“感官”升级提供了一种新思路。

这项研究被收录于即将召开的计算机视觉顶级会议ECCV2024。
AI的“视听盛宴”
想象一下,你正在观看一场音乐会,舞台上既有歌手深情演绎,又有乐手娴熟演奏,而AI需要从这复杂的视听场景中准确识别出正在演奏乐器的人。
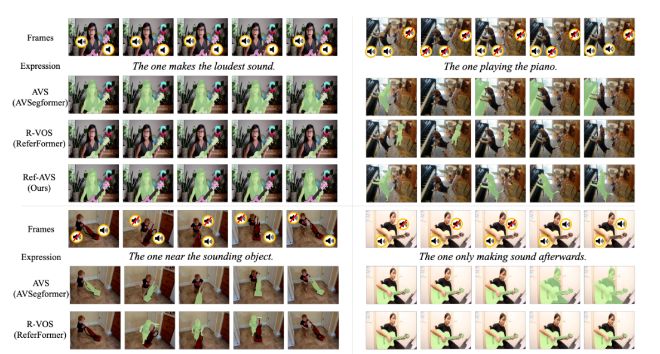
这听起来像是一项艰巨的任务,然而,新提出的方法Ref-AVS(Refer and Segment Objects in Audio-Visual Scenes)正是为此而生。
传统的视频对象分割(VOS)、视频对象参考分割(Ref-VOS)和视听分割(AVS)方法,虽然各有千秋,但都存在一定的局限性。
VOS依赖于第一帧的精确标注,Ref-VOS虽然更易访问但能力有限,而AVS仅能处理发声的物体。而Ref-AVS则通过整合文本、音频和视觉信息,让AI能够像人类一样,借助多模态线索定位感兴趣的物体,无论是正在唱歌还是弹吉他的人都能被轻松识别。
构建多模态理解的基石
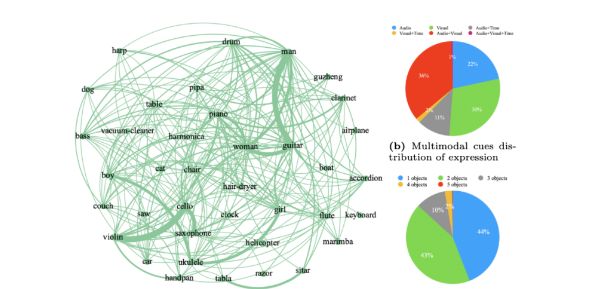
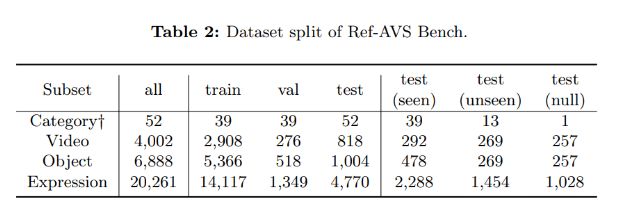
为了验证和优化Ref-AVS的性能,研究团队构建了一个名为Ref-AVS Bench的数据集,其中包含了丰富的视频帧、物体类别和指代表达式,以及对应的音频和像素级标注。
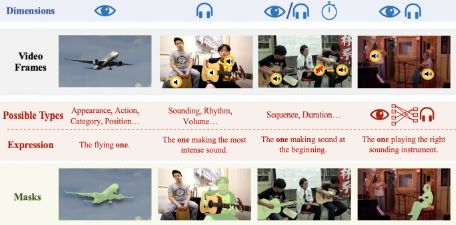
通过精心设计的数据收集和表达式生成过程,Ref-AVS Bench不仅确保了数据的多样性和真实性,还为模型的训练提供了坚实的基础。
实现多模态线索的融合
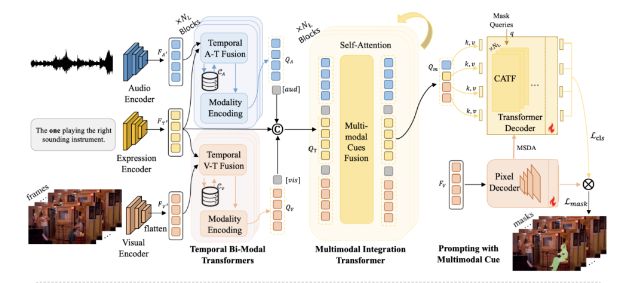
在技术实现上,Ref-AVS利用时序双模态融合和多模态整合Transformer模块,将文本、音频和视觉信息进行深度融合,以增强表达式指代能力。
这一过程中,Cached memory机制的引入,让模型能够更敏锐地感知时序变化中的多模态信息,从而在掩码解码器中生成更精确的分割结果。
实验结果
结果表明,Ref-AVS在处理多模态表达和场景理解方面展现了卓越的能力,不仅在定量评估中超越了其他方法,还在定性实验中展现了准确分割目标对象的强大实力。
未来,随着多模态融合技术的不断优化、模型应用的实时性提升以及数据集的扩展,多模态指代分割技术有望在视频分析、医疗图像处理、自动驾驶和机器人导航等领域发挥更大的作用,让AI更加贴近人类的感知方式,更深入地理解这个丰富多彩的世界。





