Python数据分析 Pandas基本操作
一、Series基础操作
Series是pandas的基础数据结构,它可以用来创建一个带索引的一维数组,下面开始介绍它的基础操作

1、创建Series
1)使用数据创建Series:
import pandas as pd
pd.Series(10,20,30,40)
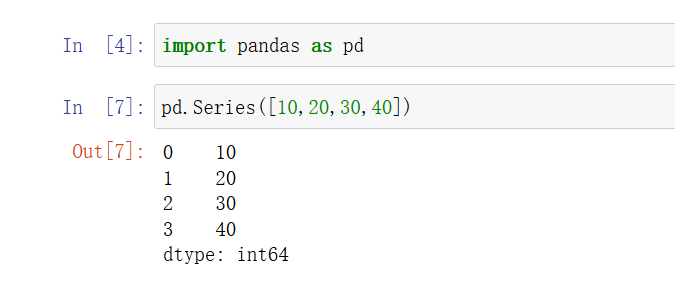
2)使用列表创建:默认索引,s列表中内容,拷贝到Series元数组中
s = [1, 2, 3, 4]
s1.Series(s)
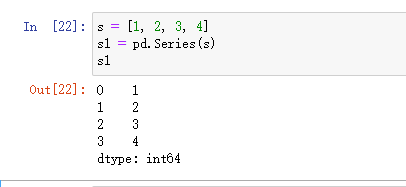
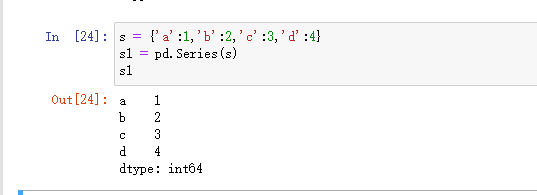
3)使用字典创建:默认索引为字典的key值,字典的value成为Series对象的元数组
s = {'a':1,'b':2,'c':3,'d':4}
s1 = pd.Series(s)
4)Series的索引操作,可以自定义索引的形式。
s = [1,2,3,4]
index = ['a','b','c','d']
s1 = pd.Series(s,index=index)

整数:适合顺序和离散的标签。
浮点数:适合需要精确值的情况,但注意精度问题。
字符串:适合文本标签。
日期时间:适合时间序列数据,精确到日期和时间。
时间戳:提供更精确的时间标记。
分类:适合有限的类别集合,节省内存和计算。
布尔值:不常见,但适用于需要布尔逻辑的场景。
元组:用于多级索引(MultiIndex)或复杂的索引结构。
自定义对象:适合特殊需求的索引,只要实现了必要的比较和哈希方法。
2、pd.Series 构造函数的参数
1)data:
-
描述: 用于构造
Series的数据。可以是列表、数组、字典、标量等。 -
类型:
list、array、dict、scalar等。 -
示例:
s1 = pd.Series([10, 20, 30]) s2 = pd.Series({'a': 1, 'b': 2}) s3 = pd.Series(5, index=['a', 'b', 'c'])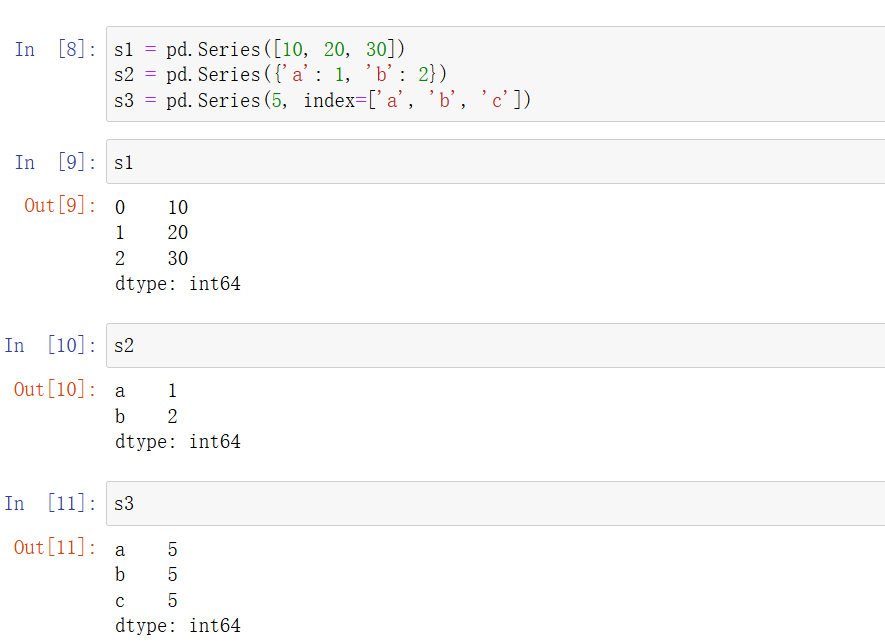
2)index:
-
描述: 自定义
Series的索引。如果不提供,默认使用整数索引(0, 1, 2, …)。 -
类型:
list、array或Index。 -
示例:
s = pd.Series([10, 20, 30], index=['a', 'b', 'c'])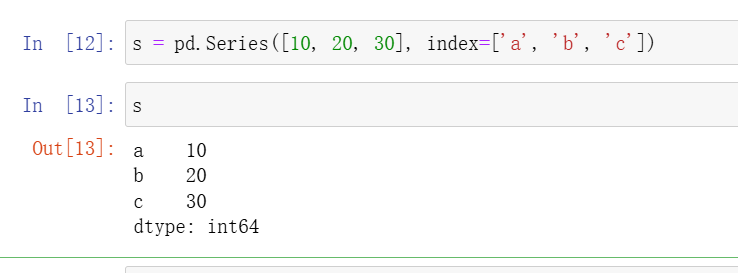
3)dtype:
-
描述: 指定
Series的数据类型。如果不提供,pandas会自动推断数据类型。 -
类型:
numpy.dtype或str。 -
示例:
s = pd.Series([10, 20, 30], dtype='float64')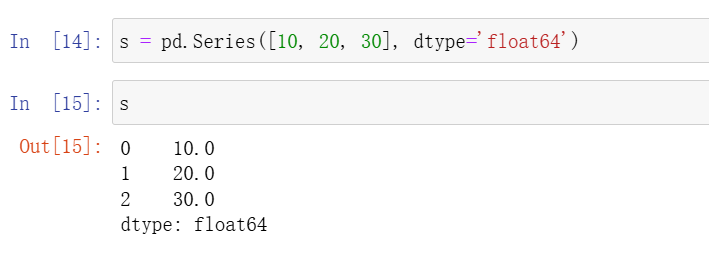
4)name:
-
描述: 给
Series一个名称,可以用于后续数据操作和可视化时的标签,在,name可以帮助识别 Series 的来源或意义,特别是在处理多个 Series 时,能够更容易地跟踪它们的含义 -
类型:
str。 -
示例:
s = pd.Series([10, 20, 30], name='s1')
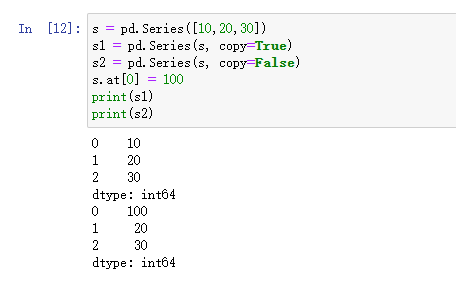
5)copy:
-
描述: 是否复制输入的数据。如果设置为
True为深拷贝,则会复制输入数据,默认为False浅拷贝。 -
类型:
bool。 -
示例
:
s = [10, 20, 30] s1 = pd.Series(s, copy=True) s2 = pd.Series(s, copy=False)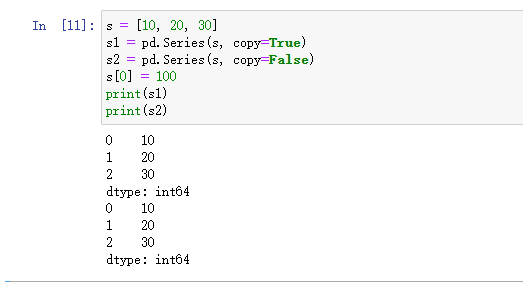
-
注意:copy参数只能在源数据是
Numpy对象、Series对象中起到作用
二、DataFrame基本操作
DataFrame 是 pandas 库中的一个核心数据结构,用于处理和分析二维的表格数据。它类似于数据库中的表格或者 Excel 中的工作表。每一列可以是不同的数据类型(例如整数、浮点数、字符串等)它的每一列基本上都是一个Series,而每一行代表一个记录。
1、DataFrame 的基本结构
- 行(Rows):数据的每一行代表一个记录或实例。
- 列(Columns):数据的每一列代表一个变量或特征。
- 索引(Index):行的标签,用于识别每一行。
- 列标签(Column Labels):列的标签,用于识别每一列。
2、创建DataFrame对象
1)使用数据创建
s = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]])

2)使用列表创建
s = [[123,234,345],[456,567,667],[789,890,901]]
columns = ['身份id', '数字id', '人员id']
s1 = pd.DataFrame(s,columns=columns)
s1['身份id']
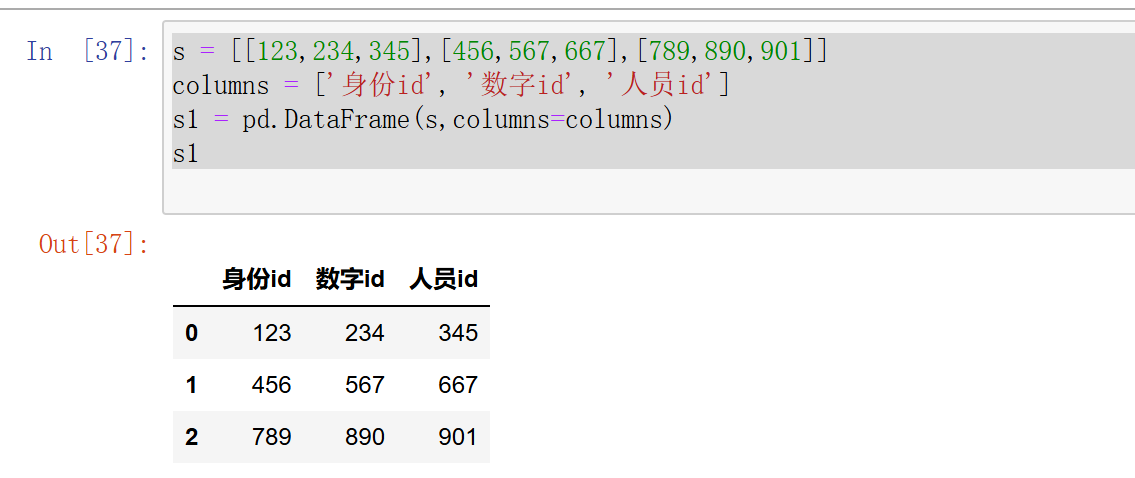
在这里,使用了columns参数指定了每个列名字,这些列名也就是Series的name属性,可以通过这个series的name属性 去取出该列的数据例如:
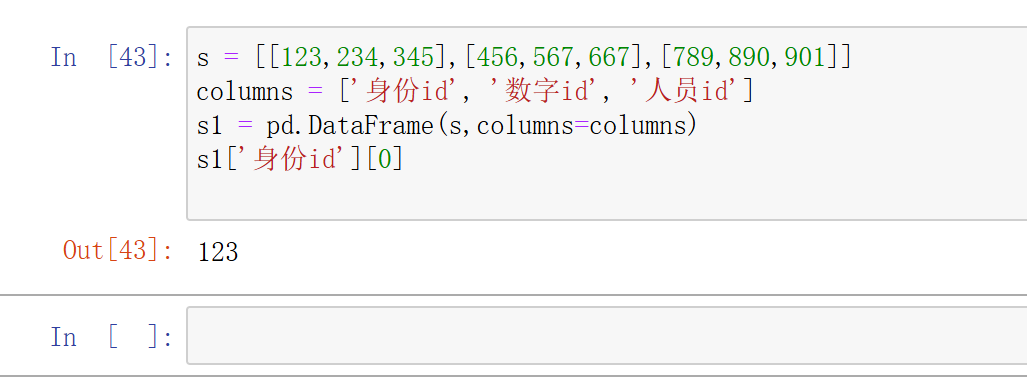
也可以去修改它的数据,例如:
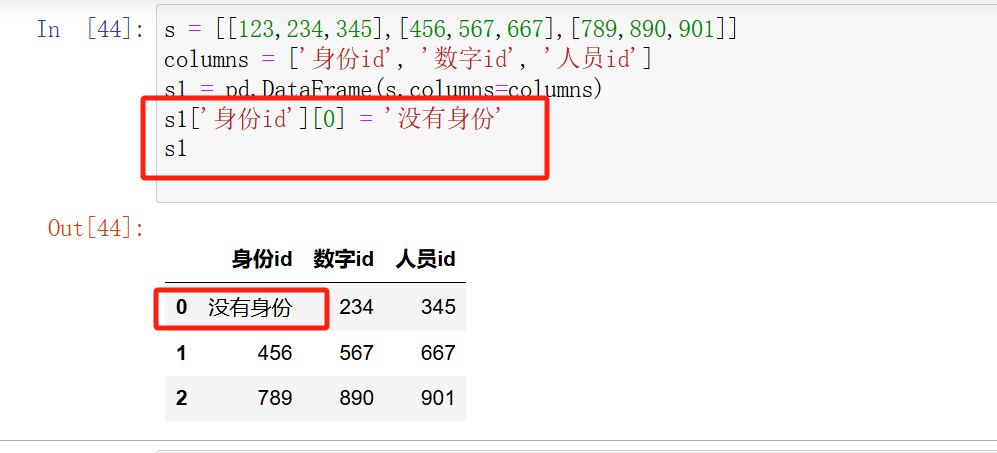
3)通过字典创建
s = {'身份id':[123,456,789],'数字id':[234,567,890],'人员id':[345,667,901]}
index=['张三','李四','王五']
s1 = pd.DataFrame(s,index=index)
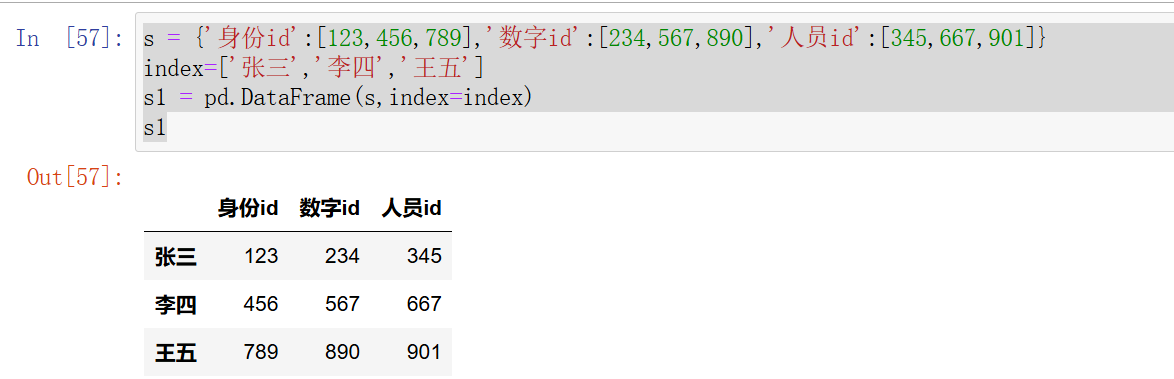
再次,使用了index参数,对DataFrame对象的索引进行了自定义,它的概念与Series的概念一样,也可以通过多维标签去访问或修改里面的元素,例如:
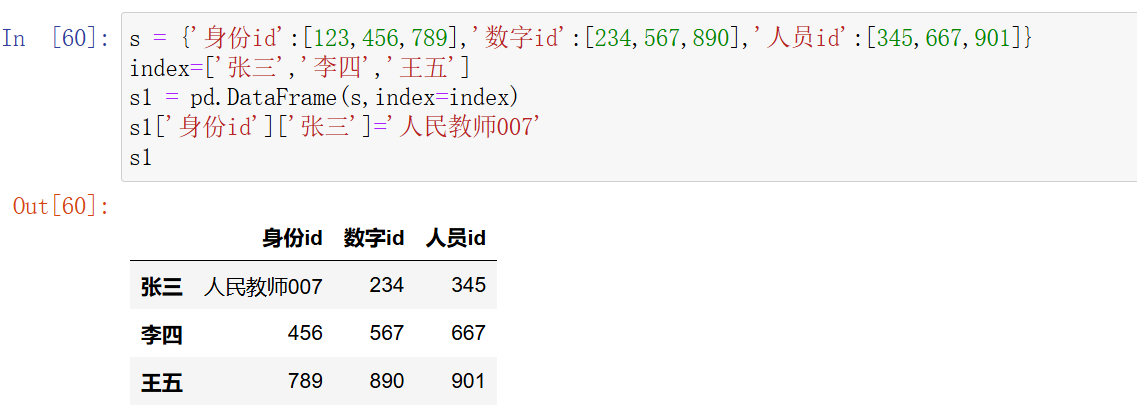
第一个元素是列名、第二个元素的索引,
4)通过Series对象去创建
s1 = pd.Series([123,456,789],name='身份id',index=['张三','李四','王五'])
s2 = pd.Series([234,567,667],name='数字id',index=['张三','李2四','王五'])
s3 = pd.Series([789,890,901],name='人员id',index=['张三','李四','王五'])s4 = pd.DataFrame([s1,s2,s3],axis=1)
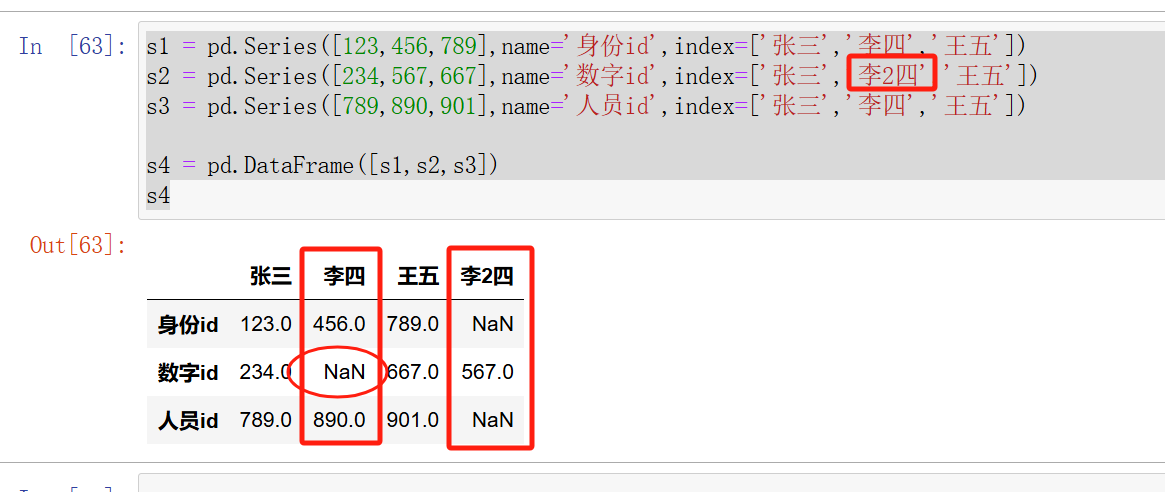
这里需要注意的是,如果Series对象中的index索引如果不一致,会导致多创建一个超出的列,因为Sreies和DataFrame的光系是并集关系,
但是这里还会出现另一个问题,之前我们已经说了,Series是DataFrame的列属性,但是在此处它却变成了DataFrame的行属性。
这是因为DataFrame 的构造方式和行为取决于你如何传递 Series 和使用的方法。实际上,Series 既可以被视为 DataFrame 的列,也可以被视为 DataFrame 的行,具体取决于构建 DataFrame 的方式。
Series作为列
通常情况下,将 Series 传递给 DataFrame 构造函数时,如果每个 Series 是作为字典的值传递给 DataFrame,这些 Series 会被视为列。
# 创建 Series 对象
s1 = pd.Series([123, 456, 789], name='编号', index=['张三', '李四', '王五'])
s2 = pd.Series([234, 567, 667], name='数字id', index=['张三', '李四', '王五'])
s3 = pd.Series([789, 890, 901], name='人员id', index=['张三', '李四', '王五'])# 使用 pd.DataFrame() 构造函数,Series 作为列
df = pd.DataFrame({'编号': s1,'数字id': s2,'人员id': s3
})
print(df)
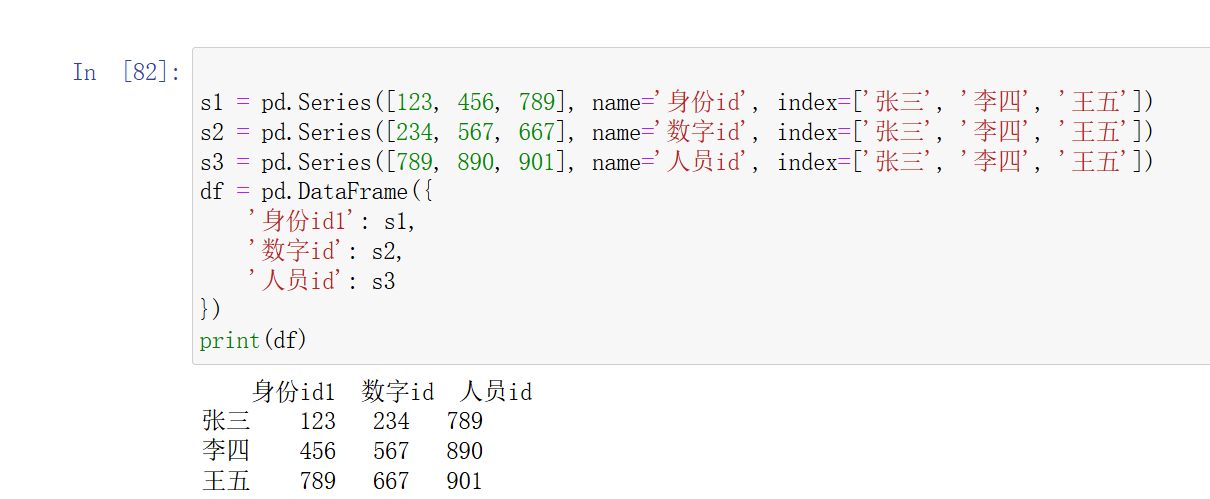
注意:在构造DataFrame对象时,它的列名以最后赋值的
Series属性的name为最终结果,在上面例子的字典中,字典的key就可以看作是Series的name属性,它的赋值在Series构造函数之后,所以最终的结果就是身份id1,
Series作为行
当 Series 被作为列表传递给 DataFrame 的构造函数时,它们会被默认视为 DataFrame 的行。每个 Series 的 name 属性将成为 DataFrame 的行索引。
# 创建 Series 对象
s1 = pd.Series([123, 456, 789], name='编号', index=['张三', '李四', '王五'])
s2 = pd.Series([234, 567, 667], name='数字id', index=['张三', '李四', '王五'])
s3 = pd.Series([789, 890, 901], name='人员id', index=['张三', '李四', '王五'])# 使用 pd.DataFrame() 构造函数,Series 作为行
df = pd.DataFrame([s1, s2, s3])print(df)

作为列:当 Series 作为字典的值传递给 DataFrame 构造函数时,Series 被视为 DataFrame 的列。
作为行:当 Series 被作为列表传递给 DataFrame 构造函数时,Series 被视为 DataFrame 的行。
除了以上办法可以使用
Series对象构造一个DataFrame对象,其实还有一个更好用的方法,就是使用pandas.concat()函数方法,它可以用于在指定轴上对多个DataFrame或Series进行拼接的函数。它可以将多个对象沿着一个轴(行轴或列轴)合并成一个单一的对象。这个函数非常灵活,支持多种拼接方式,可以处理不同形状和索引的数据结构,后续在谈它。
3、DataFrame的构造函数
DataFrame的构造函数和Series的构造函数,其实都差不多,他们都是由这几个参数组成data、index、dtype、name、copy
参数说明:
data:- 类型:各种类型(
dict,list,Series,DataFrame,ndarray,DataFrame等) - 说明:用于指定
DataFrame的数据。可以是字典、列表、Series列表、二维数组等。
- 类型:各种类型(
index:- 类型:
Index或array-like - 说明:用于指定
DataFrame的行索引。如果未提供,将使用默认的整数索引。
- 类型:
columns:- 类型:
Index或array-like - 说明:用于指定
DataFrame的列名。如果未提供,将根据data自动生成。
- 类型:
dtype:- 类型:
str或np.dtype - 说明:用于指定
DataFrame的数据类型。如果未指定,DataFrame将根据data自动推断数据类型。
- 类型:
copy:- 类型:
bool - 说明:是否复制数据。默认为
False,即尽可能避免复制数据;设置为True时,则会复制数据。
- 类型:



)