目录
1.定制请求头
(1).查看请求头
(2).设置请求头
2.验证 Cookie
3.保持会话
4. SSL 证书验证
在互联网中,网页中的内容是千变万化的,如果只根据请求 URL 发送基本请求,则可能
无法获取网站的响应数据,此时需要根据网站接收请求的要求来完善请求。例如,在访问登
录后的页面时需要给请求头带上 Cookies ,在遇到 403 错误时需要给请求头添加 User-Agent 。
接下来,本节将针对处理复杂请求的内容进行详细讲解。
1.定制请求头
网络爬虫在发送请求抓取部分网页内容(如知乎网首页)时,可能会遇到服务器返回的
403 错误,即服务器有能力处理请求,但拒绝处理该客户端发送的请求。之所以出现服务
器拒绝访问的问题,是因为这些网页为防止网络爬虫恶意抓取网页信息加入了防爬虫措施。
它们通过检查该请求的请求头,判定发送本次请求的客户端不是浏览器,而可能是一个网
络爬虫。
为了解决这个问题,需要为网络爬虫发送的请求定制请求头,使该请求伪装成一个由浏
览器发起的请求,即在请求头中添加字段 User-Agent ,并将这个字段设为浏览器在发送相同
请求时使用的 User-Agent 。
定制请求头分为两步,即查看请求头和设置请求头。下面以知乎网登录页面为例,为大
家演示如何查看由浏览器发送请求的请求头信息,并根据该请求头中的 User-Agent 设置网络
爬虫的请求头,具体步骤如下。
(1).查看请求头
打开 Fiddler 工具,在 Chrome 浏览器中加载知乎网登录页面,完成加载后切换至 Fiddler
工具。在窗口左侧选中刚刚发送的 HTTP 请求,并且在窗口右侧查看该请求对应的请求头信
息,具体如图 3-3 所示。
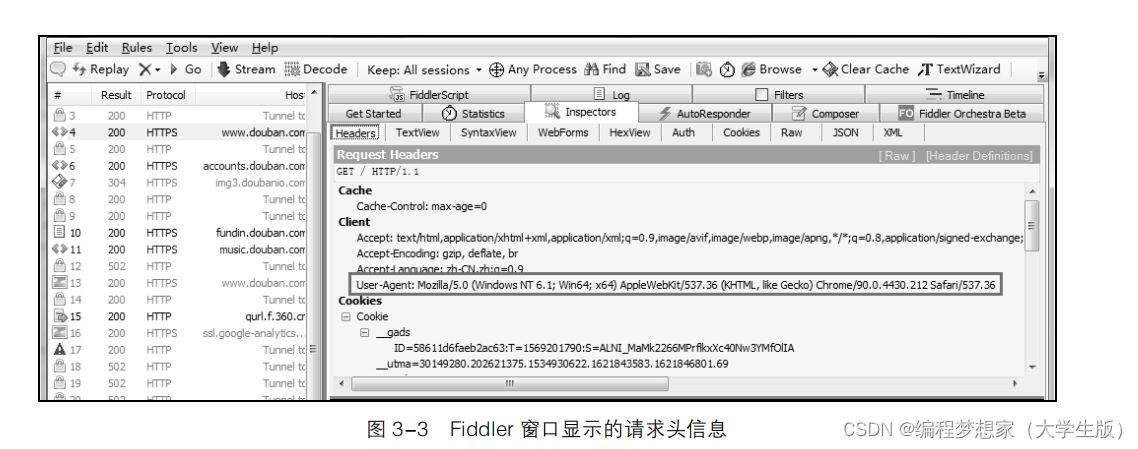
从图 3-3 中可以看出,字段 User-Agent 的值为 Mozilla/5.0 (Windows NT 6.1; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 。
(2).设置请求头
在 Requests 中,设置请求头的方式非常简单:只需要在调用请求函数时为 headers 参数传
入定制好的请求头即可。一般是将请求头中的字段与值分别作为字典的键与值,以字典的形
式传给 headers 参数。示例代码如下
import requests
# 定义 URL 和请求头
base_url = 'https://www.zhihu.com/signin'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64'
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
# 根据 URL 和请求头构造请求,发送 GET 请求,接收服务器返回的响应
response = requests.get(base_url, headers=header)
response.encoding = 'utf-8'
# 查看响应内容
print(response.text) 在上述代码中,首先定义了代表知乎网登录页面 URL 的变量 base_url 和代表请求头的变
量 header 。在请求头中以键值对的形式添加了 User-Agent 字段,并将该字段的值设为
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/90.0.4430.212 Safari/537.36 。然后调用了 get() 函数根据 base_url 发送 GET 请求到服务
器,指定请求头为 header ,并使用变量 response 接收服务器返回的响应。最后访问 response
的 text 属性获取了网页源代码。
运行代码,输出( HTML 格式化之后)如下结果。
<!DOCTYPE html>
<html lang="zh" data-hairline="true" data-theme="light"> <head> <meta charset="utf-8" /> <title data-react-helmet="true">知乎 - 有问题,就会有答案</title> <meta name="viewport" content="width=device-width,initial-scale=1,maximum-scale=1" /> <meta name="renderer" content="webkit" /> <meta name="force-rendering" content="webkit" /> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /> <meta name="google-site-verification" content="FTeR0c8arOPKh8c5DYh_9uu98_zJbaWw53J-Sch9MTg" /> ……</body>
</html> 对比从浏览器中查看的源代码可知,程序成功抓取了知乎网登录页面的源代码。
需要注意的是,如果程序使用同一个 User-Agent 字段访问网站的频率过高,那么程序也
有可能会被网站识别成网络爬虫,并被查封。为解决这个问题,可以收集所有可用的
User-Agent ,在向服务器发送请求时每隔一段时间便随机选择一个 User-Agent ,设置动态的请
求头。除此之外,还可以使用能够自动生成 User-Agent 的 fake-useragent 模块。
2.验证 Cookie
当用户首次登录一个网站时,网站往往会要求用户输入用户名和密码,并且给出自动登
录选项供用户勾选。用户如果勾选了自动登录选项,那么在下一次访问该网站时,不用输入
用户名和密码便可以登录,这是因为第一次登录时服务器发送了包含登录凭证的 Cookie 到用
户硬盘上,第二次登录时浏览器发送了 Cookie ,服务器验证 Cookie 后就识别了用户的身份,
用户便无须输入用户名和密码。
Cookie(有时也用其复数形式 Cookies )是指某些网站为了辨别用户身份、进行会话跟踪,
而暂时存储在客户端的一段文本数据(通常经过加密)。
在 Requests 库中,发送请求时可以通过两种方式携带 Cookie ,一种方式是直接将包含
Cookie 信息的请求头传入请求函数的 headers 参数;另一种方式是将 Cookie 信息传入请求函
数的 cookies 参数。不过, cookies 参数需要接收一个 RequestsCookieJar 类的对象,该对象类
似于一个字典,会以名称(Name )与值( Value )的形式存储 Cookie 。
下面以登录后的百度首页为例,分别通过上述两种方式演示如何使用Requests 实现 Cookie
登录。
第 1 种方式的实现代码如下。
import requests
headers = { 'Cookie': '此处填写登录百度网站后查看的 Cookie 信息', # 设置字段 Cookie 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4)' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/53.0.2785.116 Safari/537.36',} # 设置字段 User-Agent
response = requests.get('https://www.baidu.com/', headers=headers)
print(response.text)第 2 种方式的实现代码如下。
import requests
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) ' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/53.0.2785.116 Safari/537.36'}
# 准备 Cookie
cookie = '此处填写登录百度网站后查看的 Cookie 信息'
# 创建 RequestsCookieJar 类的对象
jar_obj = requests.cookies.RequestsCookieJar()
# 以逗号为分隔符分隔 Cookie,并将获得的键和值保存至 jar_obj 中
for temp in cookie.split(';'): key, value = temp.split('=', 1) jar_obj.set(key, value)
response = requests.get('https://www.baidu.com/', headers=header, cookies=jar_obj)
print(response.text)上述两段代码的运行结果如下。
......
"userAttr":Number("")|| 0,
"username":"Itcast_001122",
"unametype":"2",
"userIsSkined":"off",
"userIsNewSkined":"off",
"userSkinName":"",
"userSkinOpacity":"70",
…… 由加粗部分的代码可以看出,程序输出的网页源代码包含了用户名 Itcast_001122 。这说明
我们成功地访问了登录后的百度首页。
3.保持会话
我们在浏览拼多多网站时,只要在拼多多网站中登录成功一次,就可以连续打开多个商
品的标签页,中途浏览其他网页再快速回到拼多多网站也不需要重复登录,除非离开网站的
时间过长。这些情况便是保持会话的体现。
在 Requests 中, Session 类负责管理会话。通过 Session 类的对象不仅可以实现在同一会
话内发送多次请求的功能,还可以在跨请求时保持 Cookie 信息。
例如,使用 Session 类的对象请求一个测试网站时设置 Cookie 信息,然后在请求另一个
网站时获取 Cookie 信息,具体代码如下。
import requests
# 创建会话
sess_obj = requests.Session()
sess_obj.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
response = sess_obj.get("http://httpbin.org/cookies")
print(response.text) 在上述代码中,首先创建了一个 Session 类的对象 sess_obj 。然后基于 sess_obj 对象发送
了一个 GET 请求到测试网站,并且在请求该测试网站时设置了 Cookie 信息。其中 Cookie 的
名称设置为 sessioncookie ,内容为 123456789 。最后基于 sess_obj 对象请求另一个网站,获取
上次请求时设置的 Cookie 信息。
运行代码,输出如下结果。
{ "cookies": { "sessioncookie": "123456789" }
} 从输出结果可以看出,程序成功地获取了 Cookie 信息。这说明使用 Session 类的对象在
跨请求时可以成功保持 Cookie 信息。
如果不使用 Session 类的对象请求测试网站,而直接使用 Requests 库请求测试网站时,示
例代码如下所示。
import requests
requests.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
response = requests.get("http://httpbin.org/cookies")
print(response.text)运行程序,输出如下结果。
{"cookies": {}} 从输出的结果可以看出,程序并没有获取 Cookie 信息。这说明两次发送的请求属于完全
独立的请求,它们之间无法保持 Cookie 信息。
4. SSL 证书验证
大多数网站中都加入了 SSL 证书,以实现数据信息在浏览器和服务器之间的加密传输,
保证双方传递信息的安全性。 SSL 证书是一种数字证书,类似于驾驶证、护照和营业执照的
电子副本,由受信任的数字证书颁发机构 CA 在验证服务器身份后颁发,具有服务器身份验证
和数据传输加密功能。
当使用 Requests 调用请求函数发送请求时,由于请求函数的 verify 参数的默认值为 True ,
所以每次请求网站默认都会进行 SSL 证书的验证。不过,有些网站可能没有购买 SSL 证书,
或者 SSL 证书失效。程序访问这类网站时会因为找不到 SSL 证书而抛出 SSLError 异常。例如,
使用 Requests 请求国家数据网站,具体代码如下。
import requests
base_url = 'https://data.stats.gov.cn/'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/90.0.4430.212 Safari/537.36'}
# 发送 GET 请求
response = requests.get(base_url, headers=header)
print(response.status_code)运行代码,程序抛出 SSLError 异常,具体内容如下。
......
requests.exceptions.SSLError: HTTPSConnectionPool(host='data.stats.gov.cn', port=
443): Max retries exceeded with url: / (Caused by SSLError(SSLCert Verification Error(1,
'[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in
certificate chain (_ssl.c:1108)')))这时需要主动关闭 SSL 验证,即在调用 get()函数时将 verify 参数设置为 False,代码如下。
response = requests.get(base_url, headers=header, verify=False)再次运行代码,发现控制台没有输出 SSLError 异常,而是输出了如下警告信息。
C:\Users\admin\AppData\Roaming\Python\Python38\site-packages\urllib3\
connectionpool.py:981: InsecureRequestWarning: Unverified HTTPS request
is being made to host 'data.stats.gov.cn'. Adding certificate verification is
strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.
html#ssl-warnings这时,如果不希望收到警告信息,则可以采用如下方式消除警告信息。
import urllib3
urllib3.disable_warnings()再次运行程序,发现控制台中不再输出上面的警告信息。

)
感知机)


