目录
1. 引言
2. 系统架构与技术栈
2.1 Kubernetes:弹性可伸缩的计算资源池
2.2 Kubeflow:端到端的MLOps工作流
2.3 PyTorch分布式训练:高效的模型训练引擎
3. 增强型数据处理技术
3.1 联邦学习聚合
3.2 在线学习更新
3.3 角落案例挖掘
4. 复杂模型训练技术
4.1 多模态模型训练
4.2 PyTorchJob生成与分布式训练
5. 严格安全验证框架
5.1 形式化验证
5.2 对抗样本测试
5.3 边缘案例仿真
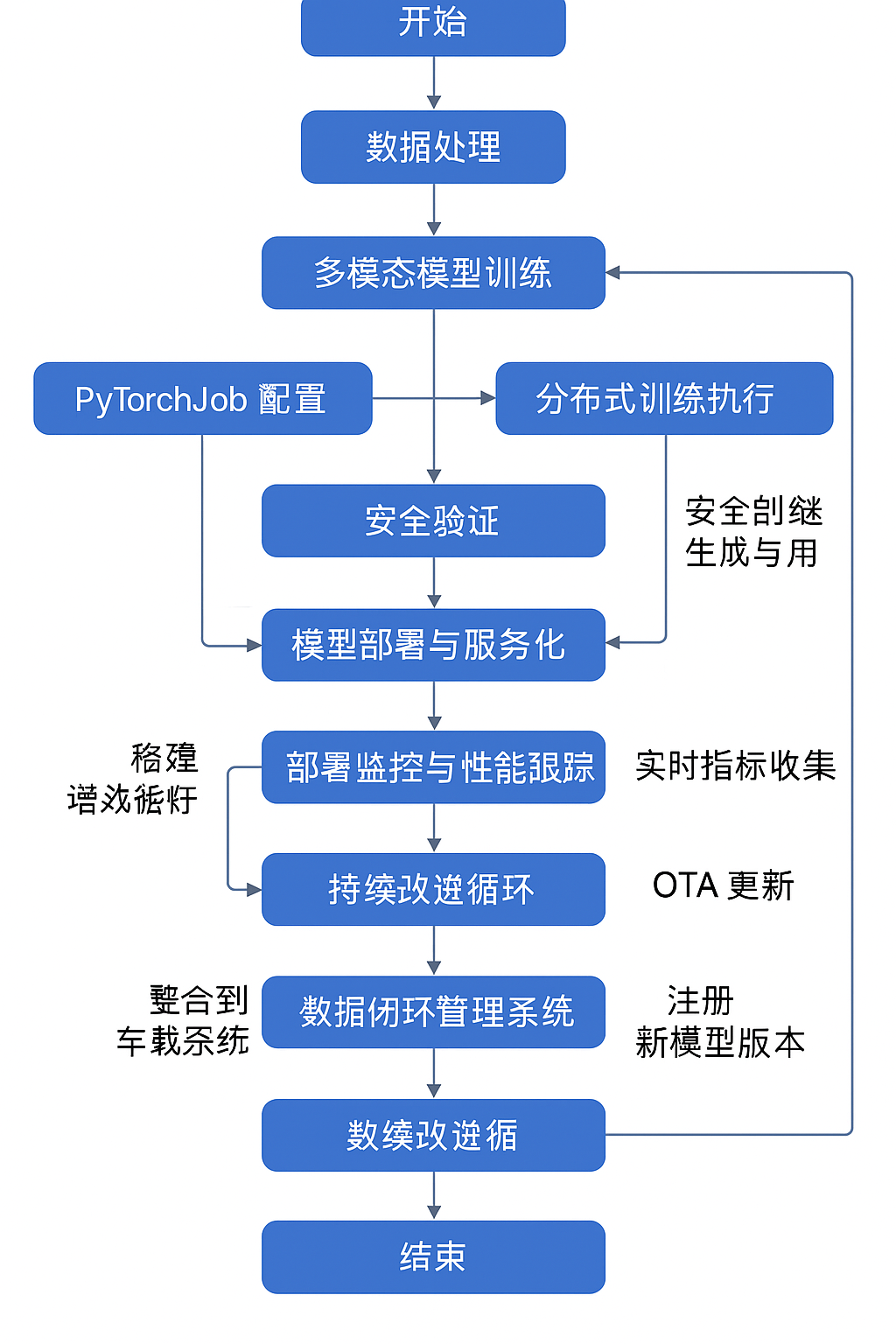
6. 整合数据闭环流水线
7. 模型部署与监控
7.1 模型部署与服务化
7.2 分布式训练执行
7.3 安全验证报告生成与使用
7.4 持续改进循环实现
8. 总结与展望
1. 引言
自动驾驶技术的快速发展面临海量多传感器数据、复杂模型训练和高安全性需求等挑战。构建高效、自动化、可扩展的MLOps平台成为实现算法持续优化和安全迭代的关键。本文深入探讨如何整合Kubernetes、Kubeflow和PyTorch分布式训练技术栈,打造支持自动驾驶数据闭环的强大基础设施。
2. 系统架构与技术栈
2.1 Kubernetes:弹性可伸缩的计算资源池
Kubernetes(K8s)作为容器编排平台,提供弹性的计算资源管理能力。它不仅调度CPU/GPU资源,还支持存储(如Ceph、PVC)和网络资源,能够运行分布式数据处理框架(如Apache Spark、Dask),实现大规模并行处理。
核心价值:
- 资源调度:通过resources.limits和requests精确分配GPU资源,支持NVIDIA MIG技术优化利用率
- 容错与扩展:自动重启失败Pod(restartPolicy: OnFailure),通过HPA动态伸缩
2.2 Kubeflow:端到端的MLOps工作流
Kubeflow基于Kubernetes,提供机器学习全生命周期管理,包括数据处理、训练、评估和部署。
核心组件:
- Kubeflow Pipelines:定义可重复、可版本化的工作流
- PyTorchJob:管理分布式训练任务
- KServe:实现模型部署与服务化
- MLMD:提供元数据管理,确保实验可追溯性
核心价值:
- 自动化:通过Pipeline编排复杂流程,减少人工干预
- 可扩展性:与K8s无缝集成,支持大规模任务
2.3 PyTorch分布式训练:高效的模型训练引擎
PyTorch通过其分布式数据并行(DDP)模块,支持多GPU、多节点训练,显著缩短训练时间。Kubeflow的PyTorchJob将其与K8s结合,通过声明式配置简化部署。
核心价值:
- 性能优化:利用torch.distributed实现高效的进程间通信
- 易用性:与Kubeflow集成后,开发者无需手动配置分布式环境
3. 增强型数据处理技术
3.1 联邦学习聚合
核心思想
中央服务器负责协调整个联邦学习过程。在每一轮(Round)训练中,服务器选取一部分符合条件的车辆(边缘设备),这些车辆利用本地数据进行模型训练,然后仅将模型的“更新量”(而非原始数据)安全地传回服务器。服务器收集到足够多的更新后,执行聚合逻辑来改进全局模型。这个改进后的模型将在下一轮分发给车辆。
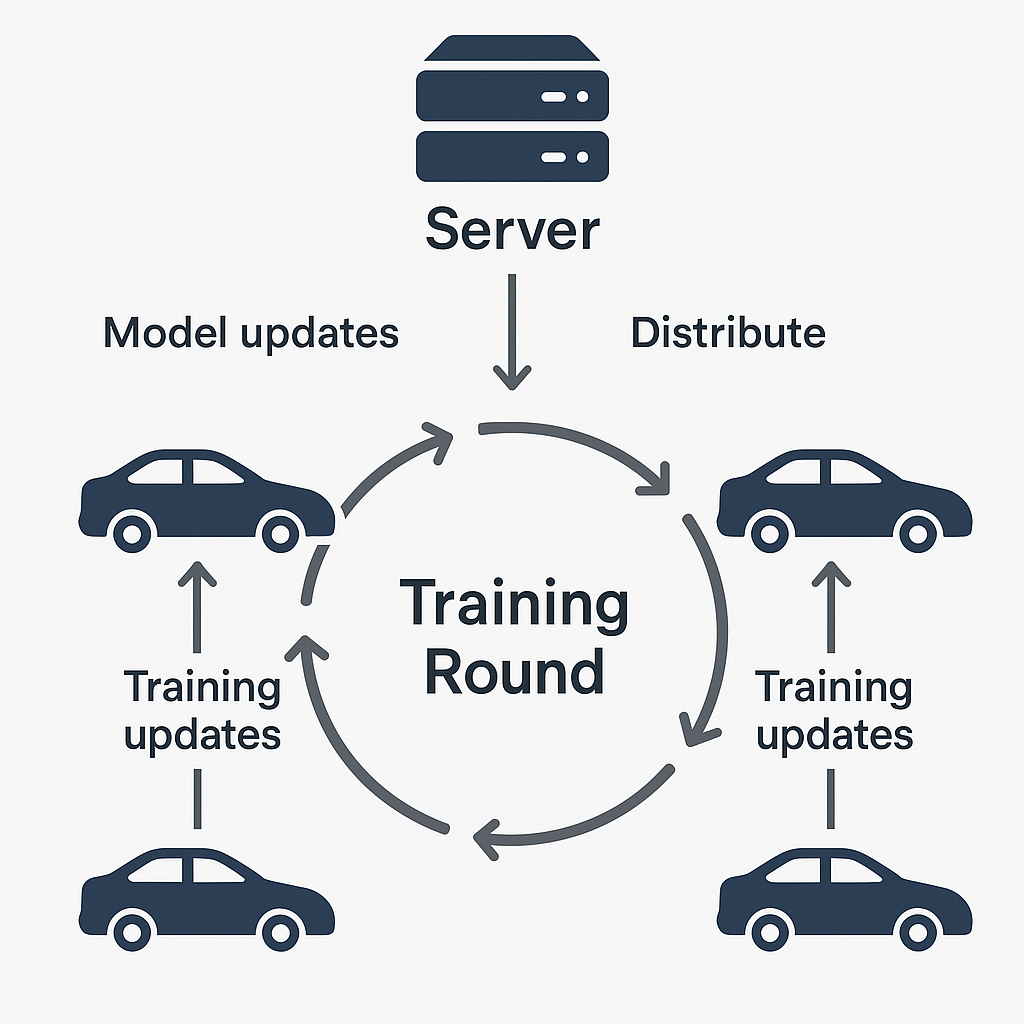
上传的“更新量”是什么?
本质上是模型参数本身或者模型参数的变化量。它是一堆数字(浮点数构成的向量、矩阵或张量),其结构与模型的参数(权重和偏置项)相对应。
它不是: 原始的传感器读数、驾驶行为日志、GPS 轨迹等用户数据。
它是: 经过本地训练后,能够体现模型学到了什么“知识”(即参数如何调整能更好地拟合本地数据)的数学表示。
为什么要这样做?
隐私保护: 用户的原始敏感数据保留在本地设备(车辆)上,不会传输到中央服务器,大大降低了数据泄露和滥用的风险。
通信效率: 模型更新量虽然可能也不小(取决于模型大小),但通常比传输可能非常庞大的原始数据集要高效得多,尤其是在无线网络环境下。
3.2 在线学习更新
@func_to_container_op
def online_learning_update(model_path: str, stream_data_path: str) -> str:"""在线学习更新:使用实时数据流增量更新模型Args:model_path: 当前模型路径stream_data_path: 实时数据流路径Returns:增量更新后的模型路径"""import os# 模拟在线学习更新逻辑print(f"使用实时数据流进行增量更新: {stream_data_path}")# 返回增量更新后的模型路径return os.path.join(os.path.dirname(model_path), "online_updated_model.pt")3.3 角落案例挖掘
@func_to_container_op
def mine_corner_cases(data_path: str, model_path: str) -> str:"""使用模型推理或嵌入聚类方法挖掘角落案例"""# 原有实现内容return data_path + "/corner_cases"智能角落案例挖掘通过模型推理(低置信度场景)或异常检测算法(如基于Embedding的聚类),精准识别高价值数据,避免在无效数据上浪费资源。
4. 复杂模型训练技术
4.1 多模态模型训练
@func_to_container_op
def multimodal_training(processed_data_path: str, model_config: str, base_model_path: str = "") -> str:"""多模态模型训练:支持图像、点云、雷达等多种传感器数据的联合训练Args:processed_data_path: 处理后的数据路径model_config: 模型配置(包含模态类型、网络架构等)base_model_path: 基础模型路径,用于持续训练Returns:训练后的多模态模型路径"""import os# 模拟多模态训练逻辑print(f"使用多模态数据进行训练: {processed_data_path}")print(f"模型配置: {model_config}")# 返回训练后的模型路径return "/mnt/models/multimodal_model.pt"多模态融合模型类实现:
class MultiModalFusionModel(nn.Module):"""多模态融合模型 - 支持图像、点云、雷达等多种输入"""def __init__(self, config):super(MultiModalFusionModel, self).__init__()# 解析配置self.modalities = config.get("modalities", ["camera", "lidar"])self.fusion_type = config.get("fusion_type", "late_fusion")self.num_classes = config.get("num_classes", 10)# 创建各模态的特征提取器self.encoders = nn.ModuleDict()# 针对不同模态设置不同的编码器if "camera" in self.modalities:# 图像编码器 (例如使用ResNet50)self.encoders["camera"] = self._create_image_encoder()if "lidar" in self.modalities:# 点云编码器 (例如使用PointNet++)self.encoders["lidar"] = self._create_lidar_encoder()if "radar" in self.modalities:# 雷达编码器 self.encoders["radar"] = self._create_radar_encoder()# 特征维度 (仅示例)feature_dim = 256# 不同的融合策略if self.fusion_type == "late_fusion":# 后期融合: 每个模态有各自的预测头,然后融合self.heads = nn.ModuleDict({modality: nn.Linear(feature_dim, self.num_classes)for modality in self.modalities})# 融合层 (简单加权平均)self.fusion_weights = nn.Parameter(torch.ones(len(self.modalities)) / len(self.modalities))elif self.fusion_type == "early_fusion":# 早期融合: 将特征连接后再预测total_dim = feature_dim * len(self.modalities)self.fusion_layer = nn.Sequential(nn.Linear(total_dim, feature_dim),nn.ReLU(),nn.Linear(feature_dim, self.num_classes))elif self.fusion_type == "deep_fusion":# 深度融合: 使用Transformer架构进行跨模态注意力融合encoder_layers = nn.TransformerEncoderLayer(d_model=feature_dim, nhead=8, dim_feedforward=2048)self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=6)self.fusion_layer = nn.Linear(feature_dim, self.num_classes)多模态融合支持三种融合策略:早期融合、后期融合和深度融合(基于Transformer的注意力机制),能够全面整合摄像头、激光雷达、雷达等多种传感器数据。
4.2 PyTorchJob生成与分布式训练
@func_to_container_op
def generate_pytorch_job_yaml(model_path: str, data_path: str, num_gpus: int = 8) -> str:"""生成大规模分布式训练的PyTorchJob YAML配置Args:model_path: 模型路径data_path: 数据路径num_gpus: GPU数量Returns:PyTorchJob YAML文件路径"""yaml_content = f"""
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:name: large-scale-trainingnamespace: kubeflow
spec:pytorchReplicaSpecs:Master:replicas: 1restartPolicy: OnFailuretemplate:spec:containers:- name: pytorchimage: your-registry/advanced-pytorch:v2.0command: ["python", "/opt/train.py"]env:- name: MODEL_PATHvalue: "{model_path}"- name: DATA_PATHvalue: "{data_path}"resources:limits:nvidia.com/gpu: 1Worker:replicas: {num_gpus - 1}restartPolicy: OnFailuretemplate:spec:containers:- name: pytorchimage: your-registry/advanced-pytorch:v2.0command: ["python", "/opt/train.py"]env:- name: MODEL_PATHvalue: "{model_path}"- name: DATA_PATHvalue: "{data_path}"resources:limits:nvidia.com/gpu: 1"""# 将YAML写入文件yaml_path = "/tmp/large_scale_training.yaml"with open(yaml_path, "w") as f:f.write(yaml_content)return yaml_path自动生成PyTorchJob YAML配置,简化了分布式训练部署流程,实现了KFP 流水线 (Kubeflow Pipelines)与Kubeflow训练任务的无缝连接。PyTorchJob自动设置RANK、WORLD_SIZE等环境变量,屏蔽分布式配置复杂性,提升开发效率。
5. 严格安全验证框架
5.1 形式化验证
@func_to_container_op
def formal_verification(model_path: str) -> dict:"""形式化验证:使用形式化方法验证模型的关键安全属性Args:model_path: 模型路径Returns:验证结果,包含通过/失败状态和详细报告"""# 模拟形式化验证结果verification_results = {"status": "PASS","verified_properties": ["不会错误识别行人", "不会错误识别红灯", "保持安全距离"],"report_path": "/mnt/reports/formal_verification_report.pdf"}return verification_results形式化验证通过数学方法验证模型关键安全属性,如交通信号灯识别、行人检测和车道线检测等,确保模型在各种条件下都能正确运行。
5.2 对抗样本测试
对抗性测试是针对机器学习模型(特别是深度神经网络)的一种“压力测试”。它不同于只用干净、标准的测试数据来评估模型,而是故意制造一些经过微小修改的输入数据(称为对抗样本),这些修改对人眼来说可能难以察觉,但却能有效地“欺骗”模型,使其做出错误的预测。
@func_to_container_op
def adversarial_testing(model_path: str, num_attacks: int = 1000) -> dict:"""对抗样本测试:生成对抗样本并评估模型鲁棒性Args:model_path: 模型路径num_attacks: 对抗攻击数量Returns:测试结果,包含鲁棒性指标和失败案例"""# 模拟对抗测试结果adversarial_results = {"robustness_score": 0.92,"successful_attacks": 80,"total_attacks": num_attacks,"failure_cases_path": "/mnt/reports/adversarial_failures.json"}return adversarial_results对抗样本测试通过FGSM、PGD和Carlini-Wagner等方法生成特殊输入,评估模型对扰动的鲁棒性,识别和修复模型潜在的漏洞。
FGSM 是最简单、最快速的攻击方法之一,属于“一击致命”型。
它首先计算模型对于输入数据的“错误倾向方向”。具体来说,就是计算损失函数(模型犯错程度的度量)关于输入像素的梯度(gradient)。梯度指向的是损失增加最快的方向。
然后,FGSM 只关心这个方向(是正是负),不关心坡度有多陡(梯度值的大小)。
最后,沿着这个“最容易犯错”的方向,给原始图片加上一个固定强度(ε,epsilon)的、非常小的扰动。就像轻轻推一下,让它往错误的方向偏一点。
5.3 边缘案例仿真
@func_to_container_op
def edge_case_simulation(model_path: str, corner_cases_path: str) -> dict:"""边缘案例仿真:在挖掘的角落案例场景中进行更严格的仿真测试Args:model_path: 模型路径corner_cases_path: 角落案例数据路径Returns:仿真结果,包含性能指标和失败场景"""# 模拟边缘案例仿真结果edge_results = {"success_rate": 0.88,"failure_rate": 0.12,"critical_failures": 5,"detailed_report": "/mnt/reports/edge_case_simulation.json"}return edge_results仿真测试能够发现离线指标无法完全反映的潜在失效模式,尤其是在城市、高速公路、乡村道路和恶劣天气等多种环境下的极端场景表现。
6. 整合数据闭环流水线
@dsl.pipeline(name="Enhanced Autonomous Driving Pipeline",description="增强型自动驾驶数据闭环流水线:包含高效数据处理、复杂模型训练和严格安全验证"
)
def enhanced_pipeline(date_range: str = "2025-03-01/2025-03-31",data_path: str = "/mnt/data",model_path: str = "/mnt/models/perception_v2.3.pt",edge_updates_path: str = "/mnt/edge_updates",stream_data_path: str = "/mnt/stream_data",num_gpus: int = 8,num_adversarial_attacks: int = 1000,num_simulation_scenarios: int = 1000
):# 1. 高效数据处理阶段download_task = download_raw_data(date_range, data_path).set_cpu_request('1').set_memory_request('2G')preprocess_task = preprocess_data(download_task.output).set_cpu_request('2').set_memory_request('4G')# 联邦学习聚合federated_task = federated_learning_aggregation(model_path, edge_updates_path).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')# 在线学习更新online_learning_task = online_learning_update(federated_task.output,stream_data_path).set_cpu_request('2').set_memory_request('4G').set_gpu_limit('1')# 角落案例挖掘mine_task = mine_corner_cases(preprocess_task.output, online_learning_task.output).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')# 2. 复杂模型训练阶段# 多模态模型训练multimodal_config = """{"modalities": ["camera", "lidar", "radar"],"fusion_type": "deep_fusion","architecture": "transformer"}"""multimodal_task = multimodal_training(preprocess_task.output,multimodal_config,online_learning_task.output).set_cpu_request('4').set_memory_request('16G').set_gpu_limit('2')# 生成大规模分布式训练配置pytorch_job_task = generate_pytorch_job_yaml(multimodal_task.output,preprocess_task.output,num_gpus).set_cpu_request('1').set_memory_request('2G')# 3. 严格安全验证阶段# 形式化验证formal_verification_task = formal_verification(multimodal_task.output).set_cpu_request('4').set_memory_request('8G')# 对抗样本测试adversarial_task = adversarial_testing(multimodal_task.output,num_adversarial_attacks).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')# 常规离线评估offline_eval_task = offline_evaluation(multimodal_task.output, preprocess_task.output).set_cpu_request('2').set_memory_request('4G')# 常规仿真评估simulation_task = simulation_evaluation(multimodal_task.output, num_simulation_scenarios).set_cpu_request('4').set_memory_request('8G')# 边缘案例仿真edge_simulation_task = edge_case_simulation(multimodal_task.output,mine_task.output).set_cpu_request('4').set_memory_request('8G').set_gpu_limit('1')整合流水线将高效数据处理、复杂模型训练和严格安全验证整合为一体,形成完整闭环。每个组件根据计算需求自适应分配资源,实现全流程自动化执行。
7. 模型部署与监控
7.1 模型部署与服务化
# 将训练好的模型部署为推理服务
from kfp import dsl
from kfp.components import func_to_container_op@func_to_container_op
def deploy_model(model_path: str, service_name: str) -> str:"""将模型部署为KServe推理服务"""import yamlimport os# 生成KServe InferenceService YAMLservice_yaml = f"""apiVersion: "serving.kserve.io/v1beta1"kind: "InferenceService"metadata:name: "{service_name}"namespace: kubeflowspec:predictor:pytorch:storageUri: "pvc://model-pvc{model_path}"resources:limits:nvidia.com/gpu: 1"""# 将YAML写入文件并应用到集群yaml_path = f"/tmp/{service_name}.yaml"with open(yaml_path, "w") as f:f.write(service_yaml)# 模拟kubectl应用YAMLprint(f"应用KServe配置: {yaml_path}")# 返回服务访问点return f"https://{service_name}.kubeflow.example.com/v1/models/{service_name}"# 在流水线中调用
deploy_task = deploy_model(multimodal_task.output,f"perception-model-{workflow_id}"
).set_cpu_request('1').set_memory_request('2G')
- PyTorchJob YAML:用于大规模分布式训练,配置如何在多GPU环境中训练模型
- KServe InferenceService YAML:用于模型部署与服务化,配置如何提供模型推理服务
KServe支持Canary部署策略,实现模型的逐步放量和风险控制。监控系统收集模型在生产环境中的表现,并将低置信度预测等异常情况反馈到角落案例挖掘环节,形成完整数据闭环
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:name: "autonomous-driving-perception"namespace: kubeflow
spec:predictor:pytorch:storageUri: "pvc://model-pvc/models/perception_v2.4"resources:limits:nvidia.com/gpu: 17.2 分布式训练执行
生成的PyTorchJob配置会被提交到Kubernetes集群执行:
@func_to_container_op
def submit_pytorch_job(pytorch_job_yaml: str) -> str:"""提交PyTorchJob到Kubernetes集群执行分布式训练"""import subprocessimport timeimport json# 模拟kubectl应用PyTorchJobprint(f"应用PyTorchJob: {pytorch_job_yaml}")job_name = "large-scale-training"# 等待训练完成print(f"等待PyTorchJob {job_name} 完成...")# 实际实现应轮询检查作业状态# 返回训练结果return json.dumps({"job_name": job_name,"status": "Succeeded","training_time": "12h 34m","final_metrics": {"accuracy": 0.92,"loss": 0.08}})# 在流水线中调用
training_result = submit_pytorch_job(pytorch_job_task.output
).set_cpu_request('1').set_memory_request('2G')7.3 安全验证报告生成与使用
@func_to_container_op
def generate_safety_report(formal_results: dict, adversarial_results: dict,simulation_results: dict,edge_case_results: dict,model_info: str
) -> str:"""综合各项验证结果生成安全报告"""import jsonimport os# 解析模型信息model_info_dict = json.loads(model_info)# 计算整体安全分数formal_score = formal_results.get("verification_rate", 0) * 100adv_score = adversarial_results.get("robustness_score", 0) * 100sim_score = simulation_results.get("success_rate", 0) * 100edge_score = edge_case_results.get("success_rate", 0) * 100# 权重计算weights = [0.4, 0.2, 0.2, 0.2]total_score = sum([formal_score * weights[0], adv_score * weights[1],sim_score * weights[2],edge_score * weights[3]])# 生成报告report = {"model_version": model_info_dict.get("version", "unknown"),"safety_score": total_score,"status": "PASS" if total_score > 85 else "FAIL","verification_summary": {"formal_verification": formal_results,"adversarial_testing": adversarial_results,"simulation": simulation_results,"edge_cases": edge_case_results},"recommendations": _generate_recommendations(formal_results, adversarial_results, simulation_results, edge_case_results)}# 保存报告report_path = "/mnt/reports/safety_report.json"with open(report_path, "w") as f:json.dump(report, f, indent=2)return report_path# 在流水线中调用
safety_report = generate_safety_report(formal_verification_task.output,adversarial_task.output,simulation_task.output,edge_simulation_task.output,json.dumps({"version": "v2.4.0"})
).set_cpu_request('2').set_memory_request('4G')7.4 持续改进循环实现
建立反馈循环,自动更新训练数据:
@func_to_container_op
def update_training_dataset(corner_cases_path: str,failed_scenarios: dict,current_dataset_path: str
) -> str:"""将发现的问题案例整合到训练数据集中"""import osimport shutilimport json# 新数据集路径updated_dataset = f"{current_dataset_path}_enhanced"os.makedirs(updated_dataset, exist_ok=True)# 复制原始数据集print(f"复制基础数据集: {current_dataset_path} -> {updated_dataset}")# 添加角落案例print(f"整合角落案例: {corner_cases_path} -> {updated_dataset}/corner_cases")# 添加失败场景if isinstance(failed_scenarios, str):failed_scenarios = json.loads(failed_scenarios)critical_failures = failed_scenarios.get("critical_failures", [])print(f"整合{len(critical_failures)}个关键失败场景到数据集")# 记录数据集更新元数据metadata = {"base_dataset": current_dataset_path,"corner_cases_added": corner_cases_path,"critical_failures_added": len(critical_failures),"timestamp": time.strftime("%Y-%m-%d %H:%M:%S")}with open(f"{updated_dataset}/metadata.json", "w") as f:json.dump(metadata, f, indent=2)return updated_dataset# 在流水线中调用
updated_dataset = update_training_dataset(mine_task.output,edge_simulation_task.output,preprocess_task.output
).set_cpu_request('2').set_memory_request('4G')8. 总结与展望
通过整合Kubernetes、Kubeflow和PyTorch分布式训练技术栈,我们构建了一个高度自动化、可扩展、高效的自动驾驶数据闭环MLOps平台。系统引入了联邦学习和在线学习等高效数据处理技术,支持多模态模型和大规模分布式训练,并通过形式化验证和对抗样本测试等严格安全验证框架保障模型质量。
这一技术栈不仅缩短了模型迭代周期,还通过严格的评估和监控确保了安全性与可靠性,成为自动驾驶领域MLOps实践的典范,未来持续优化将推动技术迈向更高水平。


)

