概述
案例介绍
Apache Flink 是一个开源的流处理框架,具有高吞吐、低延迟、可容错等特点,可同时支持批处理和流处理,为数据处理提供了强大而灵活的解决方案,Flink 在 Docker 中的应用场景主要是为了简化集群的部署和管理,特别是在开发、测试以及小规模生产环境中。使用 Docker 可以快速启动、停止和重启集群,避免手动配置和依赖管理的复杂性。
Flink 实时统计功能可以应用在以下场景:
- 实时数据清洗和转换:在数据进入存储或分析系统之前,需要对原始数据进行清洗和转换,以确保数据的质量和一致性。
- 实时事件监测与告警:在实时监控系统中,当某些事件满足特定条件时触发告警。
- 实时推荐系统:根据用户的实时行为和偏好,为用户提供个性化推荐。
本案例通过云主机进行 Docker 部署和安装 Flink,在 CodeArts IDE 编辑器进行代码开发实现数据的实时统计。
通过实际操作,让大家深入了解如何方便快捷的使用 Flink。在这个过程中,大家将学习到 Docker 的安装、Flink 的安装部署以及简单的 Flink 代码开发,从而掌握 Flink 的基本使用方法,体验其在应用开发中的优势。
使用 Docker 可简化集群部署和管理,适合开发、测试及小规模生产环境。
华为云链接:华为云
适用对象
- 企业
- 个人开发者
- 高校学生
案例流程
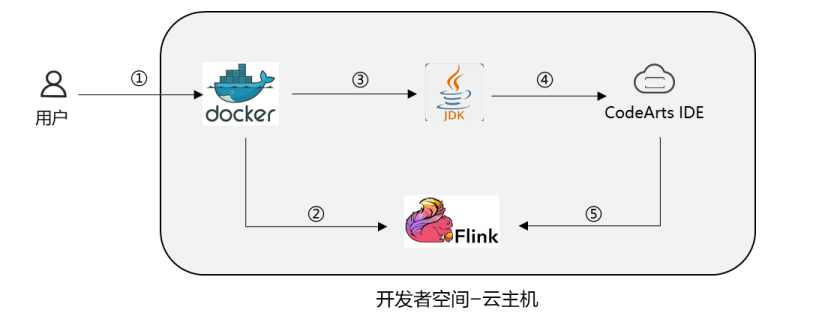
说明:
① 登录云主机,安装 Docker;
② 在 Docker 安装 Flink;
③ 安装 JDK1.8;
④ 打开 CodeArts IDE 编写wordCount 代码;
⑤ 代码打包到 Flink 运行。
资源总览
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
|---|---|---|---|
| 云主机 | 2 vCPUs |4GB X86 | 免费 | 60 |
Docker 安装 Flink 实现数据实时统计
1、安装 Docker
本案例中,使用 Docker 简化集群的部署和管理,提高开发效率、保证环境一致性、降低成本、提高安全性和可靠性,同时也支持复杂的架构和部署模式。
# 打开云主机命令行窗口输入以下命令,更新软件包
sudo apt update && sudo apt upgrade -y# 卸载旧版本 Docker(如果已安装)。
sudo apt-get remove docker docker-engine docker.io containerd runc# 安装必要的依赖
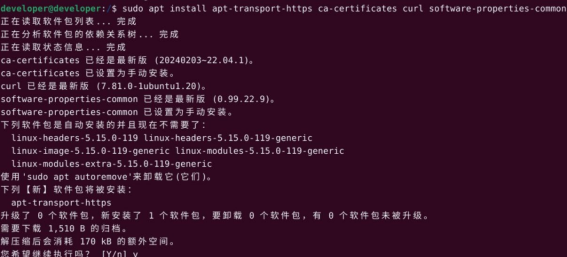
sudo apt install apt-transport-https ca-certificates curl software-properties-common
# 添加 Docker GPG 密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -

# 添加 Docker APT 源
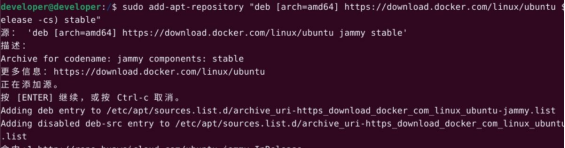
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu$(lsb_release -cs) stable"
执行命令后需要按”ENTER“键继续执行命令。
# 更新 APT 包索引
sudo apt update# 安装 Docker CE
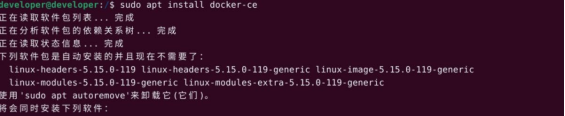
sudo apt update && sudo apt install docker-ce
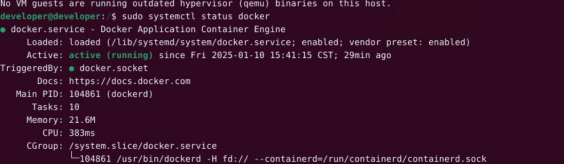
# 验证安装
sudo systemctl status docker
# 设置 Docker 开机自启
sudo systemctl enable docker# 安装 docker-compose
sudo apt-get install docker-compose

2、拉取 Flink 镜像
Apache Flink 是一个功能强大的流处理框架,适用于各种实时数据处理和分析场景,它提供了强大的功能和丰富的 API,支持分布式、高性能、低延迟和精确一次的处理,在现代数据处理领域发挥着重要的作用。
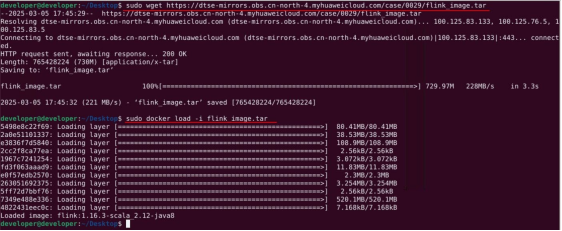
# 使用以下命令从 OBS 下载指定版本的 Flink 镜像,并将镜像加载到本地的 Docker 镜像库中。
# 下载并加载 Flink 镜像
sudo wget https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0029/flink_image.tar
sudo docker load -i flink_image.tar
# 创建一个目录用于存放 Flink 集群的相关文件。
mkdir ~/flink && cd ~/flink# 创建 docker-compose.yml 文件
vim docker-compose.yml
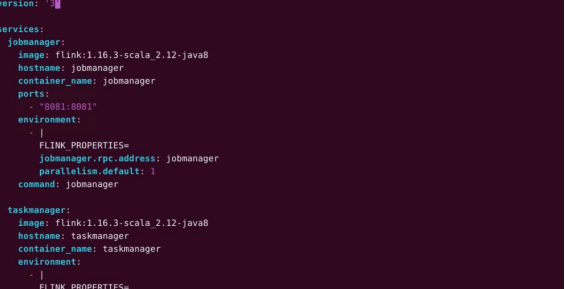
文件内容如下:
version: '3'services:jobmanager:image: flink:1.16.3-scala_2.12-java8hostname: jobmanagercontainer_name: jobmanagerports:- "8081:8081"environment:- |FLINK_PROPERTIES=jobmanager.rpc.address: jobmanagerparallelism.default: 1command: jobmanagertaskmanager:image: flink:1.16.3-scala_2.12-java8hostname: taskmanagercontainer_name: taskmanagerenvironment:- |FLINK_PROPERTIES=jobmanager.rpc.address: jobmanagertaskmanager.numberOfTaskSlots: 2parallelism.default: 1depends_on:- jobmanagercommand: taskmanager
# 配置代理
# 在 Docker 的配置文件中添加华为镜像加速器。sudo vim /etc/docker/daemon.json# 配置信息如下
{"registry-mirrors": [ "https://7046a839d8b94ca190169bc6f8b55644.mirror.swr.myhuaweicloud.com" ]
}# 重启 docker。
sudo systemctl restart docker# 启动 Flink 集群
# 通过以下命令启动 Flink 集群:
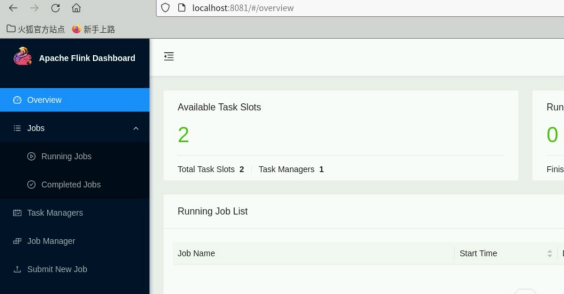
sudo docker-compose up -d

等待容器启动后,你可以通过访问 http://localhost:8081 来打开 Flink 的 Web 界面,以检查集群是否成功启动。
# 修改配置文件,保证日志正常打印
# 执行如下命令复制 taskmanager 下的 docker-entrypoint.sh 脚本。
sudo docker cp taskmanager:/docker-entrypoint.sh ./docker-entrypoint.sh# 替换配置文件。
vim docker-entrypoint.sh# 配置文件增加如下内容:$FLINK_HOME/bin/taskmanager.sh start "$@"
fi
sleep 1
exec /bin/bash -c "tail -f $FLINK_HOME/log/*.log" args=("${args[@]}")
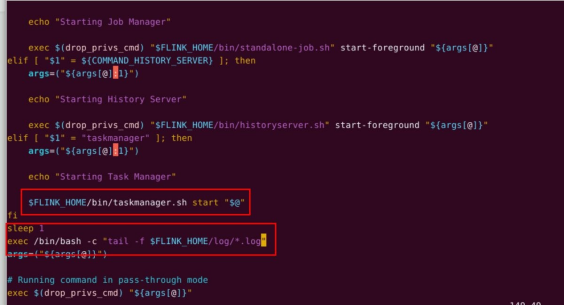
# 将修改后的配置文件再上传到 taskmanager。
sudo docker cp ./docker-entrypoint.sh taskmanager:/docker-entrypoint.sh# 重启服务。
sudo docker-compose restart# 查看服务状态。
sudo docker ps -a
3、安装 Java 环境
jdk1.8 的安装包如下,请把压缩格式的文件 jdk-8u431-linux-x64.tar.gz 下载到云主机复制下面链接到浏览器下载。
https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0001/jdk-8u431-linux-x64.tar.gz

# 把安装包上传到/home/developer/Downloads 的目录下执行如下命令:
# 创建/usr/lib/jvm 目录用来存放 JDK 文件
sudo mkdir -p /usr/lib/jvm# 把 JDK 文件解压到/usr/lib/jvm 目录下
sudo tar -zxvf /home/developer/Downloads/jdk-8u431-linux-x64.tar.gz -C /usr/lib/jvm # JDK 文件解压缩以后,可以执行如下命令到/usr/lib/jvm 目录查看一下:
cd /usr/lib/jvm
ls# 可以看到,在/usr/lib/jvm 目录下有个 jdk1.8.0_371 目录。下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc# 使用 vim 编辑器,打开了 developer 这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_431
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH# 保存.bashrc 文件并退出 vim 编辑器。然后,继续执行如下命令让.bashrc 文件的配置立即生效:
source ~/.bashrc# 这时,可以使用如下命令查看是否安装成功:
java -version
如果能够在屏幕上返回如下信息,则说明安装成功:

至此,就成功安装了 Java 环境。
4、代码开发
双击打开桌面上的 CodeArts IDE for JAVA。

点击新建工程。
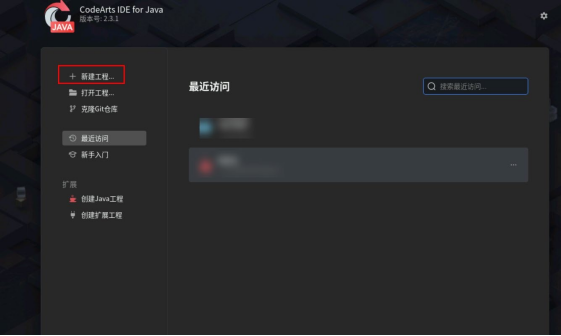
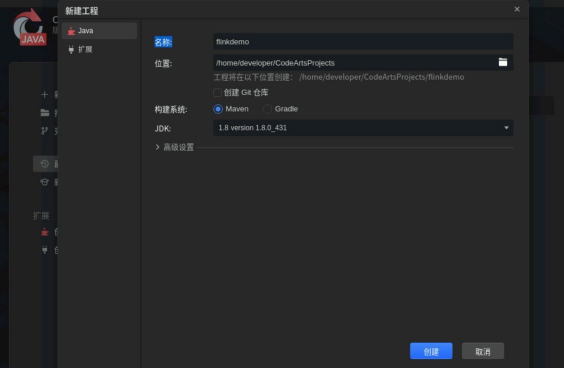
工程信息如下:
名称:自定义
位置:默认
构建系统:Maven
JDK:1.8
# 配置 settings.xml 文件,在命令行执行:
vim /home/developer/.m2/settings.xml
# 将内容替换如下:
<?xml version="1.0" encoding="UTF-8"?>
<settingsxmlns="http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"><!-- 默认的值是${user.home}/.m2/repository --><!--<localRepository></localRepository>--><!-- 如果 Maven 要试图与用户交互来得到输入就设置为 true,否则就设置为 false,默认为 true。 --><!--<interactiveMode>true</interactiveMode>--><!-- 如果 Maven 使用${user.home}/.m2/plugin-registry.xml 来管理 plugin 的版本,就设置为 true,默认为 false。 --><!--<usePluginRegistry>false</usePluginRegistry>--><!-- 如果构建系统要在离线模式下工作,设置为 true,默认为 false。 如果构建服务器因为网络故障或者安全问题不能与远程仓库相连,那么这个设置是非常有用的。 --><!--<offline>false</offline>--><servers><!-- server | Specifies the authentication information to use when connecting to a particu
lar server,identified by| a unique name within the system (referred to by the 'id' attribute below).| | NOTE: You should either specify username/password OR privateKey/passphras
e, since these pairingsare| used together.| --><!-- server 标签的作用 ,如下 --><!-- 使用 mvn install 时,会把项目打的包安装到本地 maven 仓库 --><!-- 使用 mvn deploye 时,会把项目打的包部署到远程 maven 仓库,这样有权限访问远程仓库的人都可以访问你的 jar 包 --><!-- 通过在 pom.xml 中使用 distributionManagement 标签,来告知 maven 部署的远程仓库地址--></servers><mirrors><mirror><id>huaweiyun</id><mirrorOf>*</mirrorOf><!--*代表所有的 jar 包都到华为云下载--><!--<mirrorOf>central</mirrorOf>--><!--central 代表只有中央仓库的 jar 包才到华为云下载--><!-- maven 会有默认的 id 为 “central” 的中央仓库--><name>huaweiyun-maven</name><url>https://mirrors.huaweicloud.com/repository/maven/</url></mirror></mirrors><!-- settings.xml 中的 profile 是 pom.xml 中的 profile 的简洁形式。它包含了激活(activation),仓库(repositories),插件仓库(pluginRepositories)和属性(properties)元素。profile 元素仅包含这四个元素是因为他们涉及到整个的构建系统,而不是个别的 POM 配置。如果 settings 中的 profile 被激活,那么它的值将重载 POM 或者 profiles.xml 中的任何相等 ID 的 profiles。 --><!-- 如果 setting 中配置了 repository,则等于项目的 pom 中配置了 --><profiles><profile><!-- 指定该 profile 的 id --><id>dev</id><!-- 远程仓库--><repositories><!-- 华为云远程仓库--><repository><id>huaweicloud</id><name>huaweicloud maven Repository</name><url>https://mirrors.huaweicloud.com/repository/maven/</url><!-- 只从该仓库下载 release 版本 --><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-milestone</id><name>Spring Milestone Repository</name><url>https://repo.spring.io/milestone</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots><layout>default</layout></repository><repository><id>spring-snapshot</id><name>Spring Snapshot Repository</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots><layout>default</layout></repository></repositories><pluginRepositories><!-- 插件仓库。插件从这些仓库下载 --><pluginRepository><id>huaweicloud</id><url>https://mirrors.huaweicloud.com/repository/maven/</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots></pluginRepository></pluginRepositories></profile></profiles><!-- activations 是 profile 的关键,就像 POM 中的 profiles,profile 的能力在于它在特定情况下可以修改一些值。而这些情况是通过 activation 来指定的。 --><!-- <activeProfiles/> --><activeProfiles><activeProfile>dev</activeProfile></activeProfiles>
</settings>
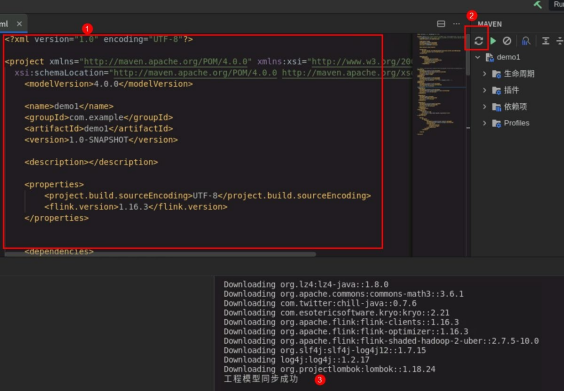
配置 pom 文件:
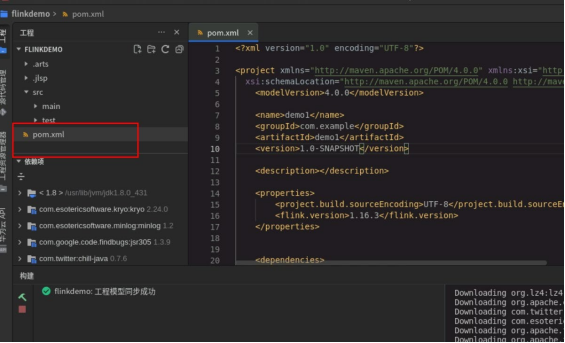
# 文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><name>demo1</name><groupId>com.example</groupId><artifactId>flinkdemo</artifactId><version>1.0-SNAPSHOT</version><description></description><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.16.3</flink.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>1.16.3</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.16.3</version><!-- 根据实际需求选择版本 --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.16.3</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies><repositories><repository><id>central</id><url>https://repo.maven.apache.org/maven2/</url></repository></repositories><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>8</source><target>8</target></configuration></plugin></plugins></build>
</project>
配置完之后,点击右边 MAVEN 刷新按钮,下载依赖。
打开项目工程,删除 App.java。
新建 WordCount.java 类。
代码如下:
package com.example;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
//import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Random;
public class WordCount
{/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception{// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 后续的数据源、转换、操作等代码// env.execute("WordCount01");// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 定义一个用于生成随机单词的数组/* String[] words = {"apple", "banana", "cherry", "date", "elderberry"};Random random = new Random();// 这里使用一个无限循环来模拟持续生成数据while (true) {// 随机选择一个单词String word = words[random.nextInt(words.length)]; */// DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream < String > dataStream01 = env.socketTextStream("10.12.164.220", 9999);DataStream < String > flatMapStream = dataStream01.flatMap(new FlatMapFunction < String, String > (){@Overridepublic void flatMap(String line, Collector < String > collector) throws Exception{String[] arr = line.split(" ");for(String word: arr){// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的 DataStreamcollector.collect(word);}}});//flatMapStream.print();// Tuple2 指的是 2 元组DataStream < Tuple2 < String, Integer >> mapStream = flatMapStream.map(new MapFunction < String, Tuple2 < String, Integer >> (){@Overridepublic Tuple2 < String, Integer > map(String word) throws Exception{return Tuple2.of(word, 1); // ("hello",1)}});DataStream < Tuple2 < String, Integer >> sumResult = mapStream.keyBy(new KeySelector < Tuple2 < String, Integer > , String > (){@Overridepublic String getKey(Tuple2 < String, Integer > tuple2) throws Exception{return tuple2.f0;}// 此处的 1 指的是元组的第二个元素,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute("WordCount01");/*env.setParallelism(2); // 设置全局并行度dataStream.keyBy(0).sum(1).setParallelism(2); // 设置单个操作的并行度*/}
}
打开命令行输入命令查看云主机本地 ip。
ifconfig
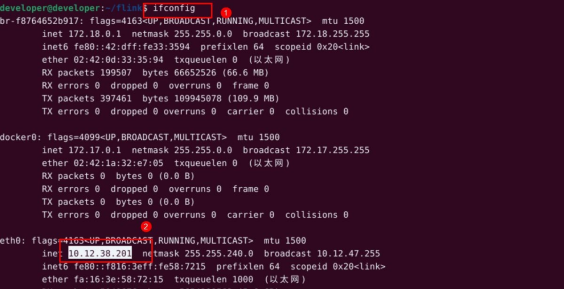
将得到的 ip 填入代码中。
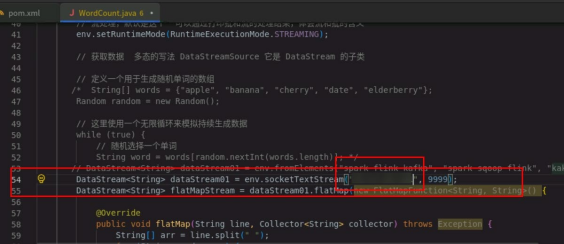
打包代码。
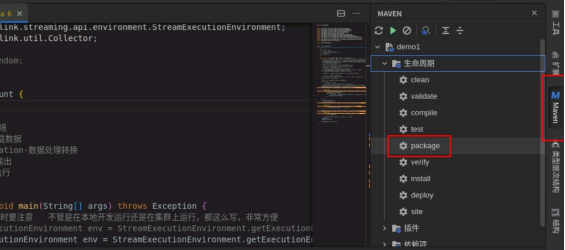
右侧项目 target 目录下生成 jar 包。
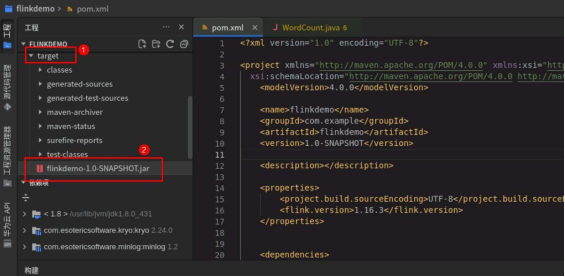
5、运行代码
在命令行窗口输入命令打开监听:
nc -l 9999

打开 flink web 上传 jar 包运行代码。点击左边栏 Submit New Job。
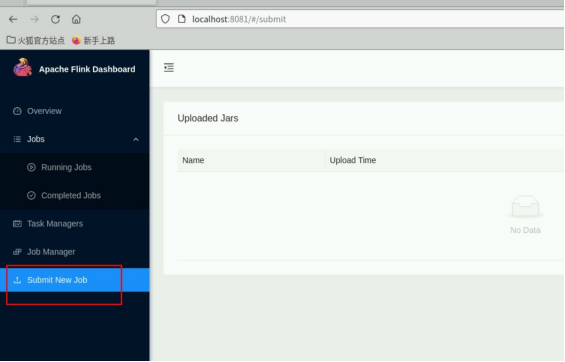
点击右边 Add New 。
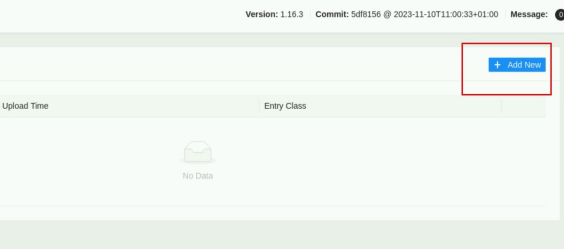
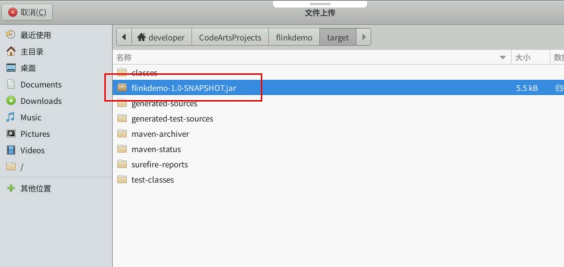
上传 jar 包。
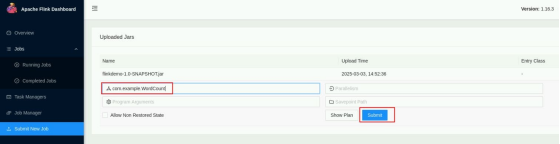
填写任务运行参数。填写主类:com.example.WordCount,点击 Submit 运行。
在命令行监听输入单词。

打开 flink web Task Managers。
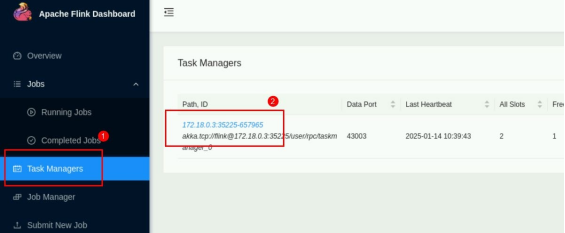
点击 Stdout 可以看到打印出刚刚输出的单词数量,根据相同单词数据进行累加统计。

不再进行监听的时候,进入命令行,按下 Ctrl+C 停止命令行监听窗口。
如果想了解更多 docker 内容可以访问:https://www.docker.com/
想了解更多关于 flink 内容的可以访问:https://flink.apache.org/


)

