在深度学习中,优化器和优化方法是训练模型时至关重要的组成部分。它们负责调整模型的参数,以最小化损失函数,提高模型的性能。
一、SGD
梯度下降法:
批量梯度下降(Batch Gradient Descent) BGD
随机梯度下降 (Stochastic Gradient Descent) SGD
小批量梯度下降(Mini-batch Gradient Descent) MGD
1.1、 批量梯度下降
批量梯度下降指的是它在每一次迭代中都使用全部的训练数据来更新模型参数。 由于它的全部数据都一起进行梯度下降,所以相对更加高效和可以朝着全局最优解进 行。 但是由于是全部数据一起进行梯度下降,在大规模数据集上内存或者显存会不够,造成极大的计算开销。
1.2、随机梯度下降
它是另一个极端,批量梯度下降是将全部数据集一起进行梯度下降,它是只拿出一个 样本进行梯度下降,由于数据少,所以计算开销很小,但是效率不是很高。
1.3、小批量梯度下降
它是批量梯度下降和随机梯度下降的一个各取所长的方案,将训练数据集成若干个小批量,进行梯度下降, 并根据该样本的梯度来更新参数的值。这种方案取得了相对平衡,由于每次取多少是 可以被提前确定的,所以可以根据计算机性能进行选择。
在实际的深度学习中,虽然叫SGD,看似是随机梯度下降,但是却使用的是小批量梯 度下降。可以把他们统称为SGD。
然而,由于使用的是样本梯度来更新参数,随机梯度下降的更新方向较为不稳定,可 能会出现震荡现象,导致无法收敛到全局最优解,尤其是在非凸函数中。

def SGD(points, w, b, lr, batch_size):# 将数据的顺序打乱np.random.shuffle(points)for num_batch in range(0, len(points), batch_size):batch_points = points[num_batch:num_batch+batch_size, :]batch_x = batch_points[:, 0]batch_y = batch_points[:, 1]# 计算梯度batch_pre_y = w * batch_x + bdw = np.mean(2 * (batch_pre_y - batch_y) * batch_x)db = np.mean(2 * (batch_pre_y - batch_y))w -= lr * dwb -= lr * dbreturn w, b二、SGD_Momentum
SGD+Momentum是随机梯度下降(Stochastic Gradient Descent,SGD)的一种 变体,它引入了动量(Momentum)的概念来改进传统的随机梯度下降算法。动量 的引入有助于解决SGD中的震荡和收敛速度较慢的问题。可以更好地应对梯度变化和 梯度消失问题,从而提高训练模型的效率和稳定性。
2.1、TensorFlow框架

它的工作方式是在每次迭代时都会计算模型参数的梯度,然后将梯度值乘以一个因子 (称为动量或动量系数),再将乘积累加到模型参数中。
这样,模型参数的更新不再仅仅依赖于当前梯度值,还依赖于过去的梯度值,有助于 加速收敛。同时,动量有助于减小更新的方差,从而减小震荡,使得参数更新更加平 滑。
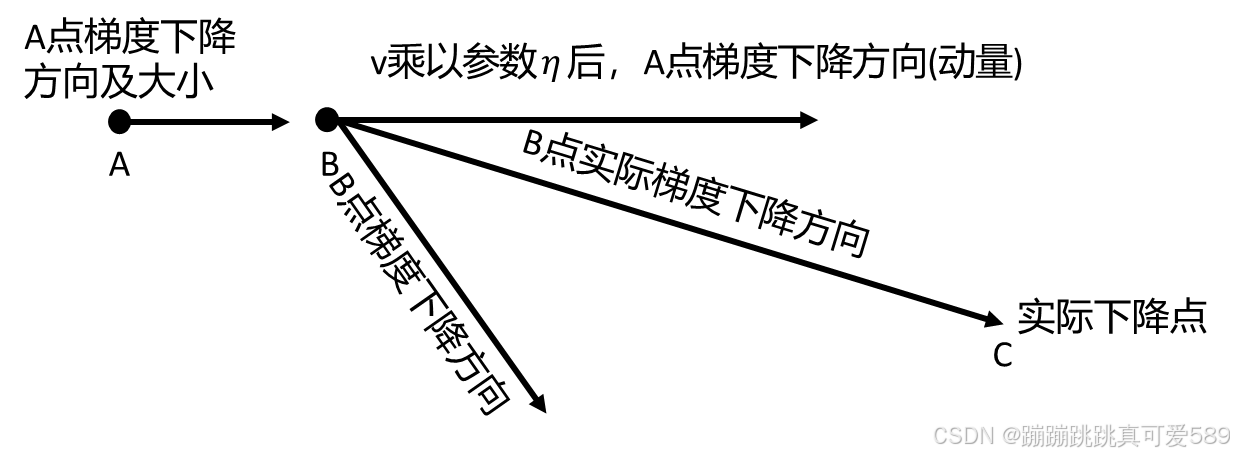

2.2、PyTorch框架

momentum = 0.9
v_w = 0
v_b = 0
def SGD_Momentum(points, w, b, lr, batch_size):global momentum, v_w, v_b# 将数据的顺序打乱np.random.shuffle(points)for num_batch in range(0, len(points), batch_size):batch_points = points[num_batch: num_batch+batch_size, :]batch_x = batch_points[:, 0]batch_y = batch_points[:, 1]# 计算梯度batch_pre_y = w * batch_x + bdw = np.mean(2 * (batch_pre_y - batch_y) * batch_x)db = np.mean(2 * (batch_pre_y - batch_y))# 更新参数v_w = momentum * v_w + lr * dwv_b = momentum * v_b + lr * dbw -= v_wb -= v_breturn w, b三、AdaGrad
Adagrad引入了二阶动量,它可以是一种自适 应学习率优化器,通过对每个参数使用不同的学习率来解决学习率固定的问题。 SGD以及动量以同样的学习率更新每个参数。神经网络模型往往包含大量的参数,但 是这些参数并不会总是用得到,更新频率也不一样。对于经常更新的参数,不希望其 被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,了解的信息太 少,希望能够从每个偶然出现的样本身上多学一些,即学习速率大一些。
在训练过程中,Adagrad会根据每个参数的梯度值来自动调整它们的学习率,使得每 个参数都能够适当地更新。

优点:它可以让参数在训练的前期更新得快一些,在后期更新得慢一些,有助于稳定 训练,从而更快地收敛到最优值,不同更新频率的参数具有不同的学习率,减少摆 动,在稀疏数据场景下表现会非常好。
缺点:但是由于分母中是历史梯度平方的累积和,随着训练的进行,分母会逐渐增 大,导致学习率递减得很快,可能造成训练提前停止。

epsilon = 1e-7
G_w = 0
G_b = 0
def AdaGrad(points, w, b, lr, batch_size):global epsilon, G_w, G_b# 将数据的顺序打乱np.random.shuffle(points)for num_batch in range(0, len(points), batch_size):batch_points = points[num_batch: num_batch+batch_size, :]batch_x = batch_points[:, 0]batch_y = batch_points[:, 1]# 计算梯度batch_pre_y = w * batch_x + bdw = np.mean(2 * (batch_pre_y - batch_y) * batch_x)db = np.mean(2 * (batch_pre_y - batch_y))# 梯度的平方和G_w = G_w + dw ** 2G_b = G_b + db ** 2# 更新参数w = w - (lr / np.sqrt(G_w + epsilon)) * dwb = b - (lr / np.sqrt(G_b + epsilon)) * dbreturn w, b四、RMSProp
为了解决Adagrad优化器的缺点,Geoff Hinton提出了RMSProp优化器,其实相比 于Adagrad优化器,RMSProp优化器只是添加了一个系数用来控制衰减速度,它的 更新方案为:
 优点:RMSProp的思想是在更新参数的同时,使用梯度的指数加权平方的移动平均 来调整学习率,克服了AdaGrad中学习率递减过快的问题。这个算法通过不断调整学 习率来帮助模型更快地收敛。RMSProp与Adagrad算法类似,但它更加稳定,并且 更容易调参。
优点:RMSProp的思想是在更新参数的同时,使用梯度的指数加权平方的移动平均 来调整学习率,克服了AdaGrad中学习率递减过快的问题。这个算法通过不断调整学 习率来帮助模型更快地收敛。RMSProp与Adagrad算法类似,但它更加稳定,并且 更容易调参。
但是,类似于AdaGrad,RMSProp仍然未考虑梯度的方向,这导致在某些情况下学 习率的适应性可能不足。
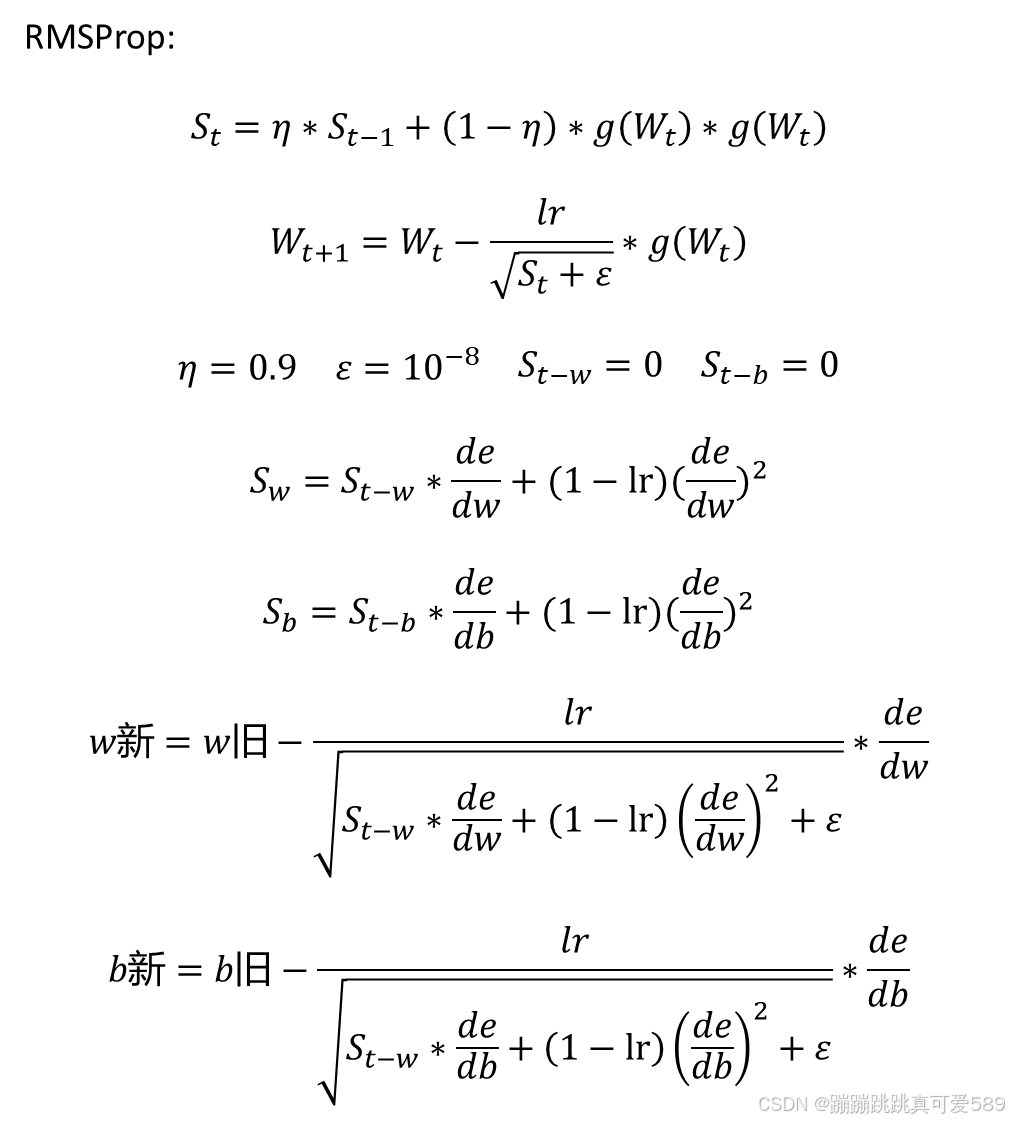
epsilon = 1e-7
G_w = 0
G_b = 0
decay_rate = 0.9def RMSProp(points, w, b, lr, batch_size):global epsilon, G_w, G_b, decay_rate# 将数据的顺序打乱np.random.shuffle(points)for num_batch in range(0, len(points), batch_size):batch_points = points[num_batch: num_batch+batch_size, :]batch_x = batch_points[:, 0]batch_y = batch_points[:, 1]# 计算梯度batch_pre_y = w * batch_x + bdw = np.mean(2 * (batch_pre_y - batch_y) * batch_x)db = np.mean(2 * (batch_pre_y - batch_y))# 更新梯度G_w = decay_rate * G_w + (1 - decay_rate) * (dw ** 2)G_b = decay_rate * G_b + (1 - decay_rate) * (db ** 2)# 更新参数w = w - (lr / np.sqrt(G_w + epsilon)) * dwb = b - (lr / np.sqrt(G_b + epsilon)) * dbreturn w, b五、Adam
5.1、矩估计引入
Adam(Adaptive Moment Estimation)自适应矩估计,也是一种自适应学习率的优化 器,它结合了Momentum和RMSProp两种优化方法的算法,引入了两个新参数。

5.2、估计的是否准确

5.3、偏差校正引入




5.4、Adam

#一阶矩估计和二阶矩估计的变量
m_w = 0
m_b = 0
v_w = 0
v_b = 0
# 设置参数
beta1 = 0.9
beta2 = 0.999
epsilon = 1e-7
def Adam(points, w, b, lr, t, batch_size):global m_w, m_b, v_w, v_b, beta1, beta2, epsilon# 将数据的顺序打乱np.random.shuffle(points)for num_batch in range(0, len(points), batch_size):batch_points = points[num_batch: num_batch+batch_size, :]batch_x = batch_points[:, 0]batch_y = batch_points[:, 1]# 计算梯度batch_pre_y = w * batch_x + bdw = np.mean(2 * (batch_pre_y - batch_y) * batch_x)db = np.mean(2 * (batch_pre_y - batch_y))# 一阶矩估计的公式m_w = beta1 * m_w + (1 - beta1) * dwm_b = beta1 * m_b + (1 - beta1) * db# 二阶矩估计的公式v_w = beta2 * v_w + (1 - beta2) * (dw ** 2)v_b = beta2 * v_b + (1 - beta2) * (db ** 2)# 矫正一阶矩估计m_w_hat = m_w / (1 - beta1 ** t)m_b_hat = m_b / (1 - beta1 ** t)# 矫正二阶矩估计v_w_hat = v_w / (1 - beta2 ** t)v_b_hat = v_b / (1 - beta2 ** t)# 更新参数w = w - (lr / np.sqrt(v_w_hat) + epsilon) * m_w_hatb = b - (lr / np.sqrt(v_b_hat) + epsilon) * m_b_hatreturn w, b六、 batch_size
batch_size是指每次训练时使用的样本数量,是一个非常重要的超参数,它会影响模型的训练速度和准确性。当batch_size = 1时,如果输入的样本数量是10个,那么就 会在一个迭代次数里更新10除以1次w和b,这个的迭代次数就是epoch,
使用小的 batch_size有几个潜在的好处:
内存效率:使用小的batch_size意味着每次只需加载少量的训练数据到内存中。这在 处理大型数据集时特别重要,因为它可以减少内存的需求,使得模型能够适应有限的 系统资源。
参数更新频率:使用小的batch_size可以增加参数的更新频率。由于每个小批量的数 据都会产生一次参数更新,使用小的batch_size可以使得参数更频繁地更新,从而加 快模型的收敛速度。
噪声鲁棒性:小的batch_size可以引入一定程度的随机性和噪声,从而提高模型的鲁 棒性。每个小批量的数据可能具有不同的特征和噪声,这可以帮助模型更好地适应不 同类型的样本。
训练稳定性:对于某些复杂的模型或具有较大参数空间的模型,使用小的batch_size 可以提高训练的稳定性。小批量数据的使用可以减少参数更新的方差,并且可能有助 于避免过拟合。
然而,小的batch_size也可能存在一些挑战和限制:
训练速度:使用小的batch_size可能导致训练过程变慢。由于参数更新频率增加,每 个小批量的计算成本也增加,可能导致训练时间延长。
精确度:较小的batch_size可能导致训练过程中的梯度估计不准确。较小的样本集可 能不足以代表整个数据分布,从而影响梯度的估计和参数的更新方向。
学习率调整:使用小的batch_size通常需要更小的学习率来保持稳定性。由于参数更 新更频繁,较大的学习率可能导致训练过程不稳定。
总之,选择合适的batch_size需要考虑到数据集的大小、系统资源、模型复杂度 和训练速度等因素。通常,选择一个适度的batch_size可以在训练效率和模型性能之 间取得平衡。最佳的batch_size可能需要通过实验和调整来确定,以满足特定问题和任务的需求



——4.1基本算术运算的实现)