目录
1.动态字符串SDS
1.1SDS底层源码
1.2 SDS动态扩容
1.3动态字符串SDS优点
2.IntSet
2.1底层结构
2.2有序性
2.3.IntSet结构扩容
2.4总结
3.Dict
3.1底层结构
3.2.Dict扩容
3.3Dict收缩
3.4.Dict的rehash
1.分配空间
2. 设置 rehashidx
3. 渐进式 rehash
Redis 采用渐进式 rehash 策略,避免一次性 rehash 大量键对服务器性能造成影响。具体步骤如下:
4. 迁移完成
4.ZipList
4.1底层结构
4.1.1 ZipList
4.1.2 Entry
4.2.Encoding编码
设计优势
4.3.ZipList的连锁更新问题
5.QuickList
5.1总结
6.SKipList
6.1底层结构源码
6.2总结
7.RedisObject
7.1.Redis的编码方式
1.动态字符串SDS
我们都知道Redis保存的key是字符串value往往是字符串或者字符串的集合。可见字符串是redis中最常见的一种数据结构。
redis底层是c语言编写的,不过redis并没有直接使用c语言中的字符串,因为c语言字符串存在许多问题:
//c语言 char* s = "hello" //本质是字符串数组:{'h','e','l','l','o','\0'}
- 获取字符串长度需要通过运算(获取字符串长度还需要 - 结束标识符)
- 非二进制安全(不能包含特殊字符)
- 不可修改
所以Redis构建了一种新的字符串,动态字符串简称SDS
1.1SDS底层源码

flags:redis为了解决数据结构体大小受限问题创建了不同的SDS数据结构类型(比如uint8_t只能存储大小为255个字节数组字符串),flags主要作用就是用来存储SDS的类型信息,在redis中,不同SDS在存储容量和内存使用效率上各有不同。借助flags字段,redis能够依据实际需求选用合适的SDS类型,从而实现内存的高效利用
flags默认值如下

例如,一个字符串包含name的sds结构如下:

flags:1表示使用type8来存储数据
1.2 SDS动态扩容
SDS之所以叫动态字符串,因为它具备动态扩容的能力
步骤如下:
1.redis首先会去申请新的内存空间:申请规则如下
如果我们新的字符串大小小于1M,则新空间为扩张后字符串长度两倍+1(减少内存分配的次数减少性能开销)
如果新字符串大小大于1M,则新空间为扩展后字符串长度+1M+1。称为内存分配。(大于1M字符串如果再扩张为2倍非常浪费内存空间)
2.再把原数组数据赋值过来
1.3动态字符串SDS优点
- 1.获取字符串长度的时间复杂度为0(1)
- 2.支持动态扩容
- 3.减少内存分配次数
- 4.二进制安全
2.IntSet
IntSet是Redis中Set集合的一种实现方式,基于整数数组来实现的,并且具备长度可变,有序等特征。
2.1底层结构

encoding其实和动态字符串SDS的flags作用一样记录使用哪种数据类型 ,其中encoding包含三种模式,表示存储的整数大小不同:

2.2有序性
为了方便查找,Redis会在intset中所有的整数按照升序依次保存在contens数组中,
现在每个数组中的每个数字都在int16_t范围内,因此采用的编码方式是INTSET_ENC_INT16

- 1.IntSet底层采用的是连续的数组来存储元素,并且每个元素的类型相同,那么每个元素内存中所占空间大小是固定的。
- 2.intset会有寻址公式startPtr + (sizeof(int16)*index)通过这种寻址公式,intset可以高效的访问数组中任意元素,通过将起始地址
startPtr加上偏移量(sizeof(int16)*index),就能得到指定索引位置元素的内存地址。3.startPtr:这是整数集合底层数组的起始地址。根据上面那幅图就是Header包含的部分sizeof(int16):sizeof是一个用于获取数据类型所占字节数的操作符,int16表示 16 位整数,index:这是数组中元素的索引
2.3.IntSet结构扩容
IntSet支持动态升级能力,如果当前数据结构存储不了要添加数据的大小就会升级编码
举个栗子:
现在假设有一个IntSet,元素为{5,10,20}采用的编码是INTSET_ENC_INT16则每个整数占2个字节

我们向该其中添加一个数字:5000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
- 1.升级编码为INTSET_ENC_INT32每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- 2.倒序依次将数组中的元素拷贝到扩容后的正确位置
- 3.将待添加的元素放入数组末尾
- 4.最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
这里你可能会有疑问为什么不正序添加元素而是采用倒序添加元素
主要是避免数据覆盖问题:IntSet在内存中是连续存储的,当进行编码升级时,新元素类型的字节数会比原类型大。(要么添加到所有元素之后要么添加到所有元素之前,因为这个数要么就是负数很小,要么就是整数很大比如-5000or5000)如果正序添加元素,在将原
Intset中的元素复制到新数组时,由于新元素占用空间更大,可能会覆盖尚未处理的后续元素。

2.4总结
- 1.Redis会确保Inset中的元素唯一,有序
- 2.具备类型升级机制,可以节省内存空间
- 3.底层采用二分查找方式来查询
3.Dict
Dict是dictionary也就是字典的简称。redis是一个键值型(Key-Value pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系Dict来实现的。
Dict由三部分组成,分别是:哈希表(DictHashTable),哈希节点(DictEntry),字典(Dict)
3.1底层结构


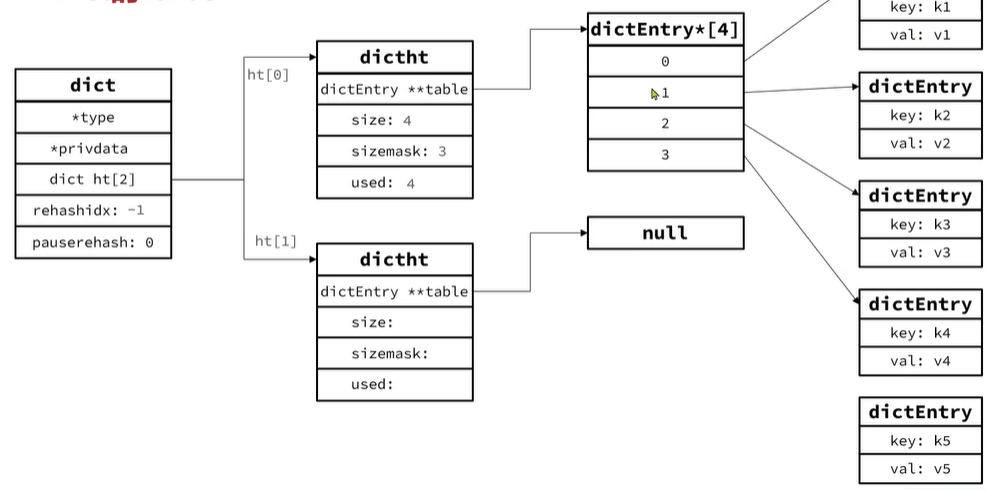
dict(字典)
- 1.type表示字典类型(不同场景下使用不同字典类型,扩展性很强)
- 2.ht[2]表是两个hash表,一个用于存储数据,一个用于重新构建hash表的时候使用
- 3.rehashidx表示是否进行rehash
对于dictht(哈希表)
- 1.第一个字段 table表示指针指向存储hash节点数组的指针
- 2.size代表hash表的大小也就是数组的大小
- 3.掩码sizemask,用于计算键值对存储的位置
- 4.used表示有多少个元素,因为会有hash冲突保存到数组同一个位置这样就形成链表
DictEntry(hash节点):就表示一个链表数据结构
当我们向dict添加键值对时,redis首先根据key计算出hash值(h),然后利用h&sizemask(按位与)来计算元素应该存储到数组中的哪个索引位置。我们存储k1=v1,假设k1的哈希值h =1,则1&3=1,因此k1=v1要存储到数组角标1位置。

3.2.Dict扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询,效率会大大降低。
Dict在每次新增链值对时都会检查负载因子 (LoadFactor=used/size),满足以下两种情况时会触发哈希表扩容:
- 哈希表的LoadFactor>=1,并且服务器没有执行bgsave 或者bgrewriteaof等后台进程;(因为这些后台进程对cpu使用非常高而且大量io读写,这时扩容影响性能)
- 哈希表的LoadFactor>5;
底层源码执行逻辑如下

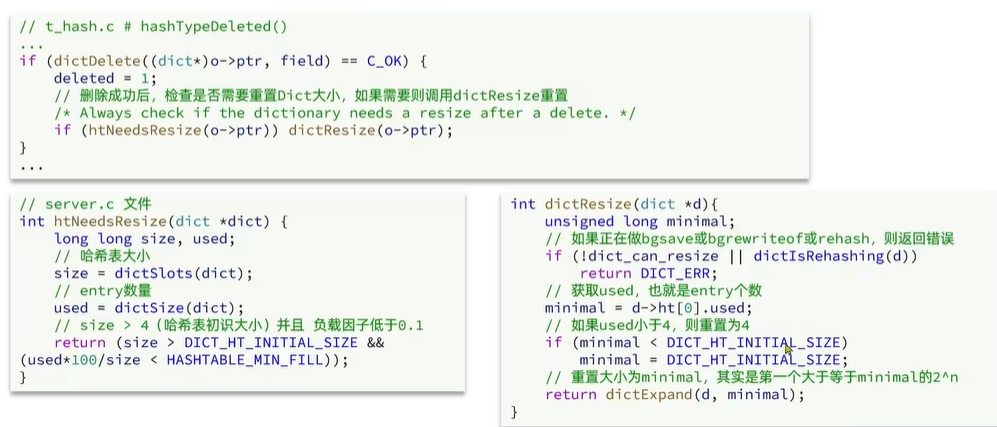
3.3Dict收缩
dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor<0.1时,会做哈希表收缩;
实现逻辑如下
3.4.Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。
实现步骤如下:
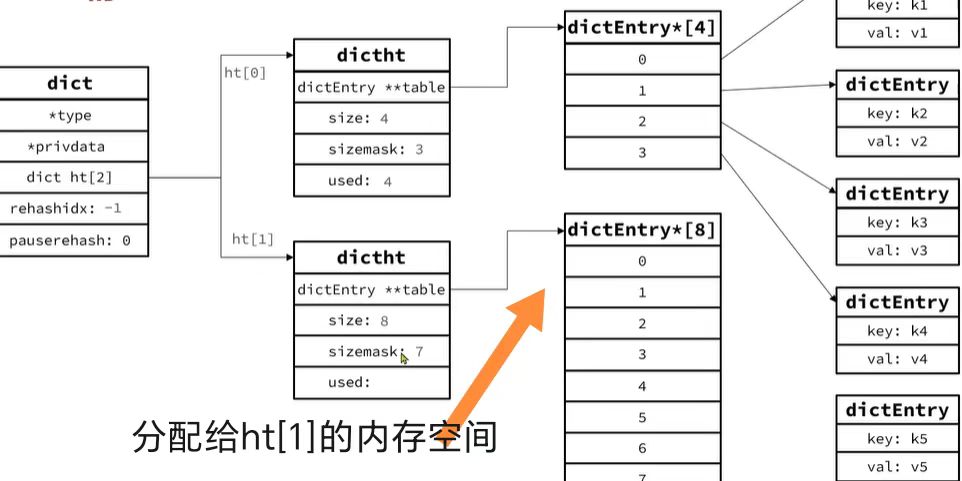
1.分配空间
- 扩展操作:为
ht[1]分配空间,其大小是第一个大于等于ht[0].used * 2的 2 的幂。- 收缩操作:为
ht[1]分配空间,其大小是第一个大于等于ht[0].used的 2 的幂。2. 设置
rehashidx把dict结构里的rehashidx设置为 0,这表明rehash操作正式开始。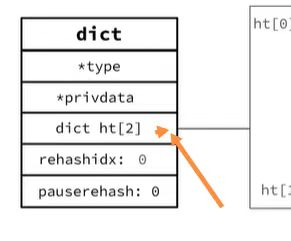
3. 渐进式
rehashRedis 采用渐进式
rehash策略,避免一次性rehash大量键对服务器性能造成影响。具体步骤如下:
- 在
rehash期间,每次对字典执行增、删、查、改操作时,程序除了完成指定操作之外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],然后将rehashidx的值加 1。- 此外,Redis 还会在定时任务里对字典进行
rehash操作,每次处理一定数量的键值对。4. 迁移完成
当ht[0]中的所有键值对都被rehash到ht[1]之后,释放ht[0],将ht[1]设置为ht[0],并创建一个新的空白哈希表作为ht[1],同时将rehashidx设置为 -1,表明rehash操作结束。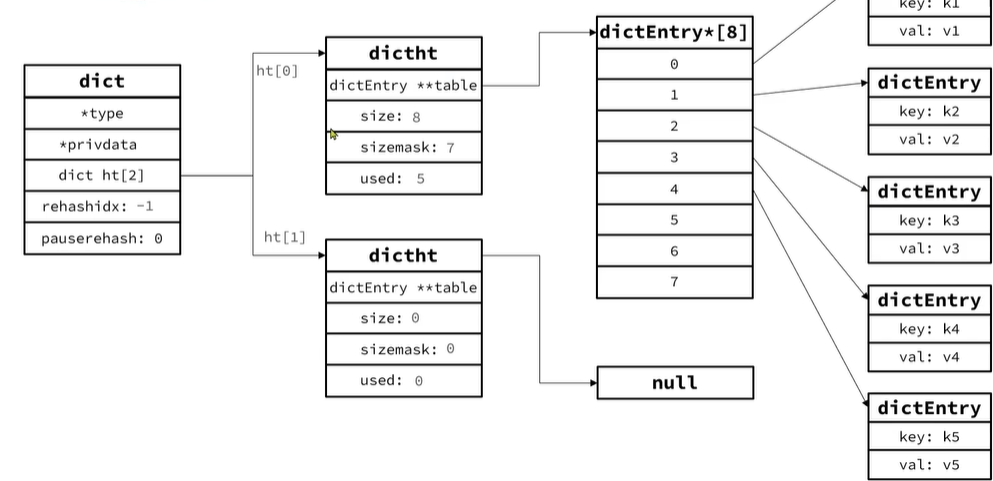
4.ZipList
ziplist是一种特殊的"双端链表",由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且"该操作的时间复杂度为0(1)。当列表或哈希元素数量较少且值较小时会采用这种结构。
4.1底层结构
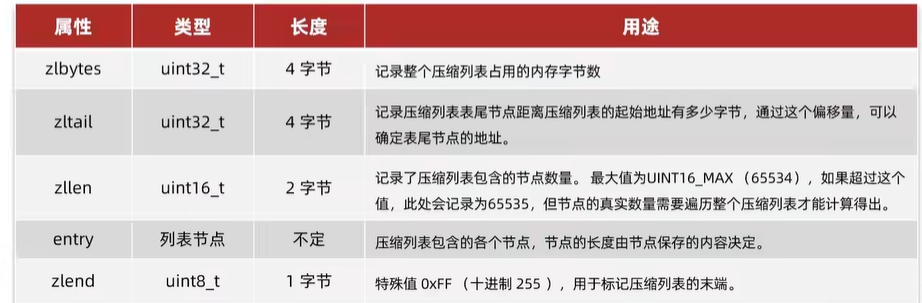
4.1.1 ZipList

4.1.2 Entry
ZipList中的Entiy井不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用
了下面的结构:
previous_entry_length:前一节点的长度,占1个或5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字书,则采用5个字节来保存这个长废值,第一个字节为oxfe,后四个字节才是真实长度数据
encoding:编码属性,记录contentent的数据类型(字符串还是整数)以及长度,占用1个,2个或5个字节
content:负责保存节点的数据,可以是字符串或整数
ZipList的Entry这样设计不仅在节省内存空间的同时,保证数据的高效存储和访问,并且支持正向和反向遍历等操作。
1.记录前置节点长度(previous_entry_length)和当前节点长度(encoding)的字段,会根据实际长度动态调整。
2.反向遍历:借助记录前一个 Entry 的长度(previous_entry_length),能够从后往前反向遍历 ZipList。在某些场景下,反向遍历是必要的,比如实现栈的操作时,就需要从后往前访问元素。

4.2.Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种
整数编码:当
entry存储整数时,encoding用 1 字节表示 。通过encoding可确定整数类型及实际大小常见整数编码如下:
ZIP_INT_8B:对应二进制11111110,表示 8 位整数,content(数据部分)占 1 字节ZIP_INT_16B:对应二进制1100 0000,表示 16 位整数,content占 2 字节 。ZIP_INT_24B:对应二进制1111 0000,表示 24 位整数,content占 3 字节 。ZIP_INT_32B:对应二进制1110 0000,表示 32 位整数,content占 4 字节 。ZIP_INT_64B:对应二进制1101 0000,表示 64 位整数,content占 8 字节 。ZIP_INT_2C:对应二进制11111101,表示 2 位有符号整数,实际取值范围有限 。字节数组(字符串)编码:当
entry存储字符串时,根据字符串长度不同,encoding有 3 种编码方式,编码的第一个字节前 2 位表示数据类型,后续位标识字符串实际长度:
总结:
1.判断数据类型:
encoding第一个字节的前 2 位用于确定数据类型,二进制11开头表示整数 ;非11开头则是字节数组(字符串)。2.解析字节数组长度:对于字节数组编码,确定是字节数组类型后,根据前 2 位具体值判断是哪种字符串编码,再依据对应规则解析出字符串长度。
设计优势
- 节省内存:根据数据实际类型和长度选择合适编码,避免固定长度存储造成的内存浪费。如存储小整数或短字符串时,使用较少字节数编码。
- 快速解析:通过
encoding编码,可快速确定数据类型和长度,在读取entry数据时提高解析效率 。

4.3.ZipList的连锁更新问题
ZipList 的每个节点(Entry)包含一个记录前一个节点长度的属性previous_entry_length,该属性占用 1 个或 5 个字节:
- 若前一节点长度小于 254 字节,用 1 字节保存长度值。
- 若前一节点长度大于等于 254 字节,用 5 字节保存长度值,第一个字节固定为
0xfe,后 4 字节是真实长度数据。previous_entry_length都仅需 1 字节表示。若在队首插入一个 254 字节的数据:
- 第二个 Entry 的
previous_entry_length就得从 1 字节扩展为 5 字节 ,这使第二个 Entry 长度变为 254 字节。- 第二个 Entry 长度变化后,第三个 Entry 的
previous_entry_length也需从 1 字节变为 5 字节 ,依此类推,后续所有 Entry 都会因前一个长度的改变而改变 。这种特殊情况下产生的连续多次空间扩展操作,就是连锁更新(Cascade Update) 。不仅插入操作,删除操作也可能引发连锁更新。比如删除一个节点后,相邻节点记录的前置节点长度发生变化,若涉及长度从小于 254 字节变为大于等于 254 字节(或反之),就可能引发连锁更新。

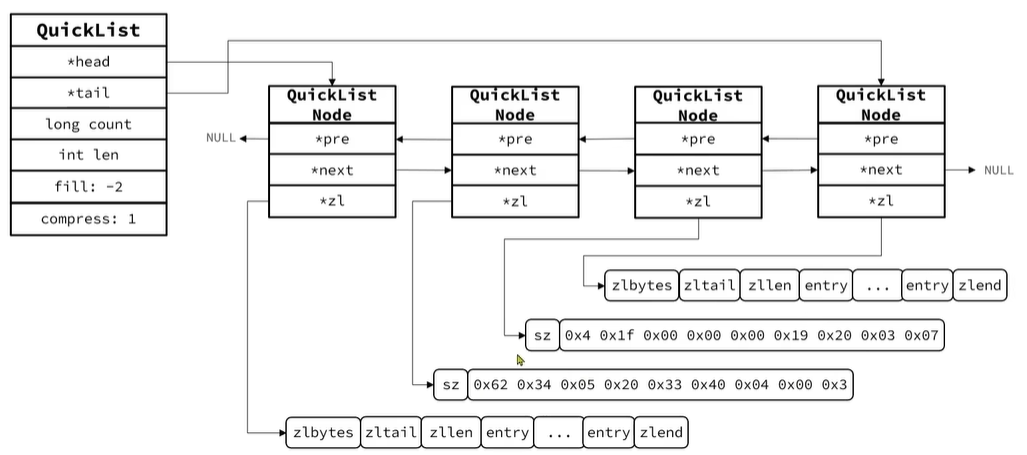
5.QuickList
ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用过多,申请内存效率很低。所以当我们要存储大量数据,超出ZipList最佳上限那么可以创建多个ZipList来分片存储数据。
Redis3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是ZipList
1.为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
- 如果值为正,则代表ziplist的允许的entry个数的最大值
- 如果值为负,则代表ziplist的最大内存大小,分5种情况:
1:每个ziplist的内存占用不能超过4kb
-2:每个ziplist的内存占用不能超过8kb
-3:每个ziplist的内存占用不能超过16kb
-4:每个ziplist的内存占用不能超过32kb
-5:每个ziplist的内存占用不能超过64kb
其默认值为-2:
2.除了控制ziplist的大小,quicklist-comprest还可以对节点的ZipList做压缩。通过配置项ist-compress-depth来控制。因为链表一般都是从首尾访问较多,所以首尾是不压缩的。这个参数是控制首尾不压缩的节点个数:
- 0:特殊值,代表不压缩
- 1:标示quicklist的首尾各有1个节点不压缩,中间节点压缩
- 2:标示quicklist的首尾各有2个节点不压缩,中间节点压缩
以此类推
默认值:
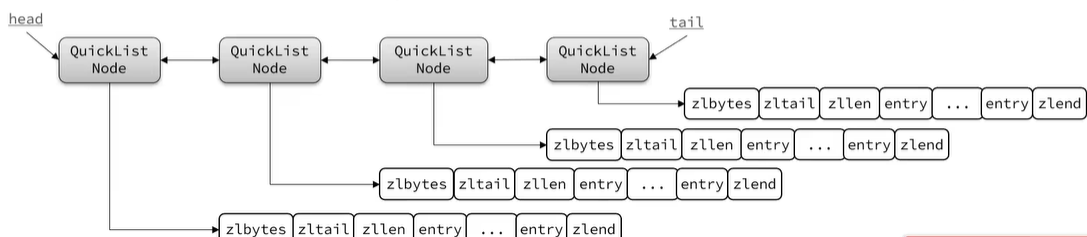


QuickList整体结构图如下
5.1总结
- quickList是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
6.SKipList
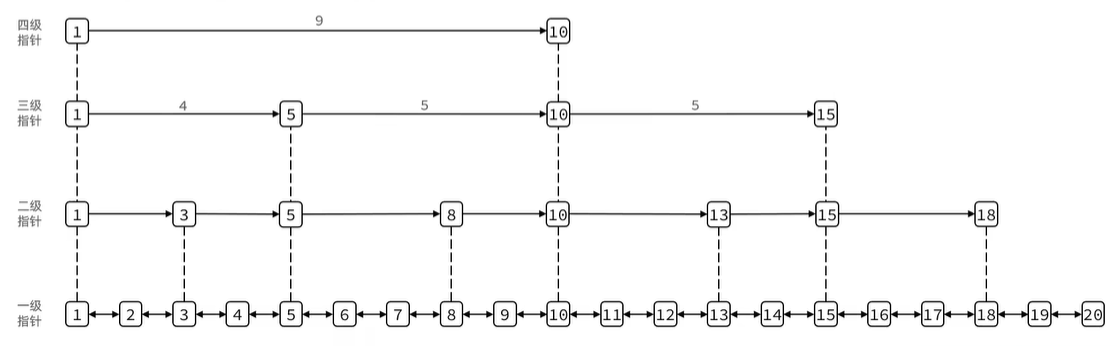
SkipList(跳表)是一种用于实现有序集合的数据结构。首先是链表,但与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
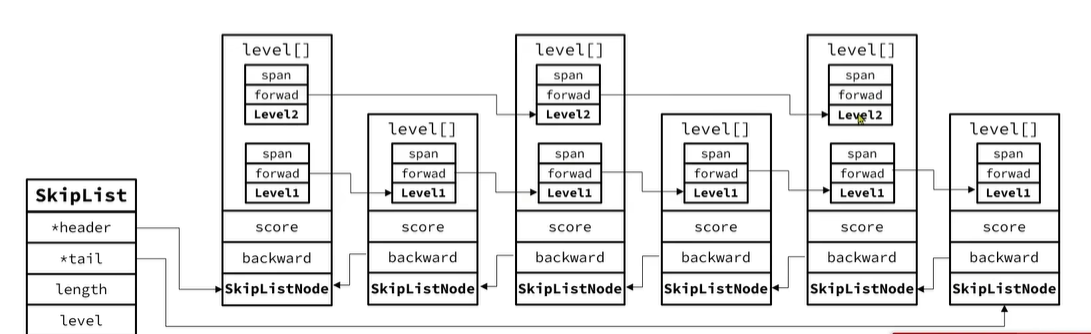
6.1底层结构源码

score:分值是用于排序的依据
ele:实际存储的数据
backward:后退指针用于从尾向头遍历跳跃表
zskiplistLevel:层数组则用于实现多层索引结构,每个元素包含一个前进指针(forward)和跨度(span)。跨度表示从当前节点到下一个节点之间的元素数量
调表结构图:
6.2总结
- 调表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
7.RedisObject
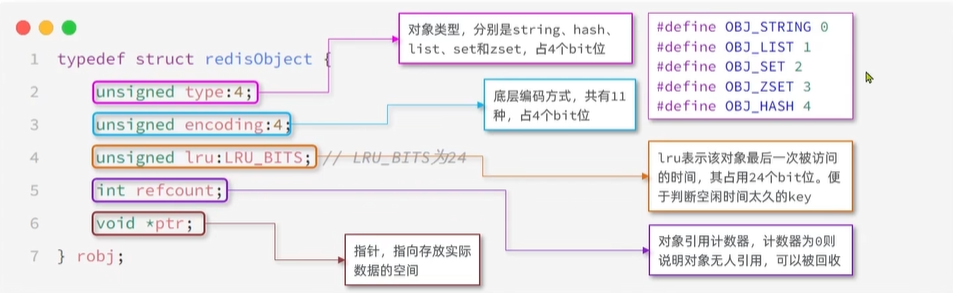
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象,源码如下:
RedisObject是 Redis 实现多数据类型支持的关键结构。借助
type和encoding字段,Redis 能够灵活存储和处理不同类型的数据,同时利用引用计数和 LRU/LFU 机制管理内存。
7.1.Redis的编码方式
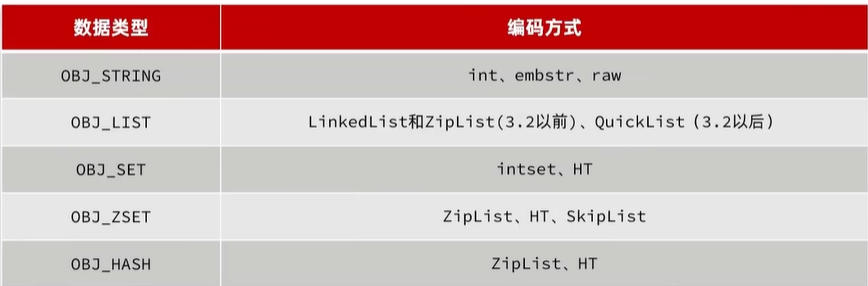
Redis会根据存储数据类型的不同,选择不同的编码方式,共包含11种不同类型:
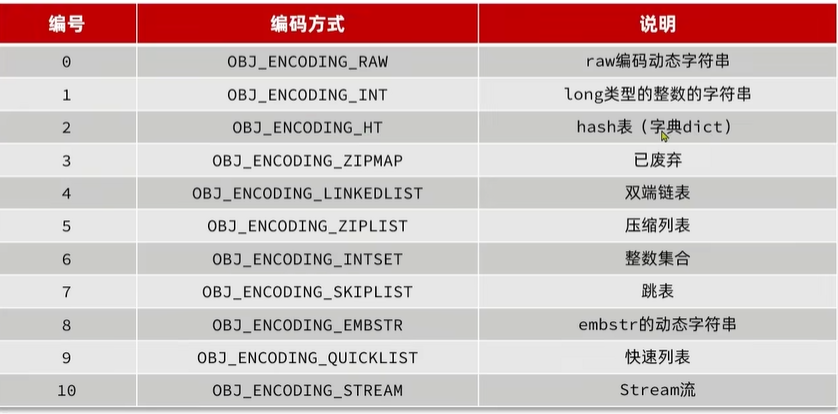
String,List,Set,Zset,Hash每一种数据类型对应几种不同编码: