2025.4.20周报
- 题目信息
- 摘要
- 创新点
- 网络架构
- 实验
- 生成性能对比
- 预测性能对比
- 结论
- 不足以及展望
题目信息
- 题目: A novel flood forecasting model based on TimeGAN for data-sparse basins
- 期刊: Stochastic Environmental Research and Risk Assessment
- 作者: Chang Chen, Fan Wang, Zhongxiang Wang, Dawei Zhang, Liyun Xiang
- 发表时间: 2025
- 文章链接:https://link.springer.com/article/10.1007/s00477-025-02968-4
摘要
随着城市化加速,城市洪涝防治对高精度洪水预报需求迫切。当前模型分为物理机制驱动与数据驱动两类:传统水文模型依赖精确地理数据且计算复杂;数据驱动模型虽效率高,但神经网络需要大量洪水时序数据,而实际洪灾事件稀少导致样本不足,易引发过拟合问题。针对TimeGAN在洪水场景的应用局限,本文提出新型双注意力数据增强网络TW-TimeGAN。该模型创新融合Transformer架构与Wasserstein距离损失函数,有效解决梯度异常问题,提升长期序列预测稳定性;通过特征-时间双注意力机制与RNN结合,增强了对降雨径流时空特征的提取能力。采用济南黄台桥流域1998-2021年实测数据进行验证,结果表明TW-TimeGAN-BiLSTM模型在纳什效率系数等关键指标上表现最优,预测精度较传统LSTM提升12.3%,有效解决了小样本条件下的模型泛化难题。研究为水文建模提供了兼顾物理机制与数据驱动优势的新方法,显著提高了城市洪水预警的可靠性和时效性。
创新点
作者提出基于双注意力机制的TW - TimeGAN,其嵌入Transformer和Wasserstein距离损失函数,提升长期预测准确性与鲁棒性;且首次将Wasserstein距离与洪水预测结合和在恢复函数中引入特征 - 时间双注意力机制,增强特征提取能力。
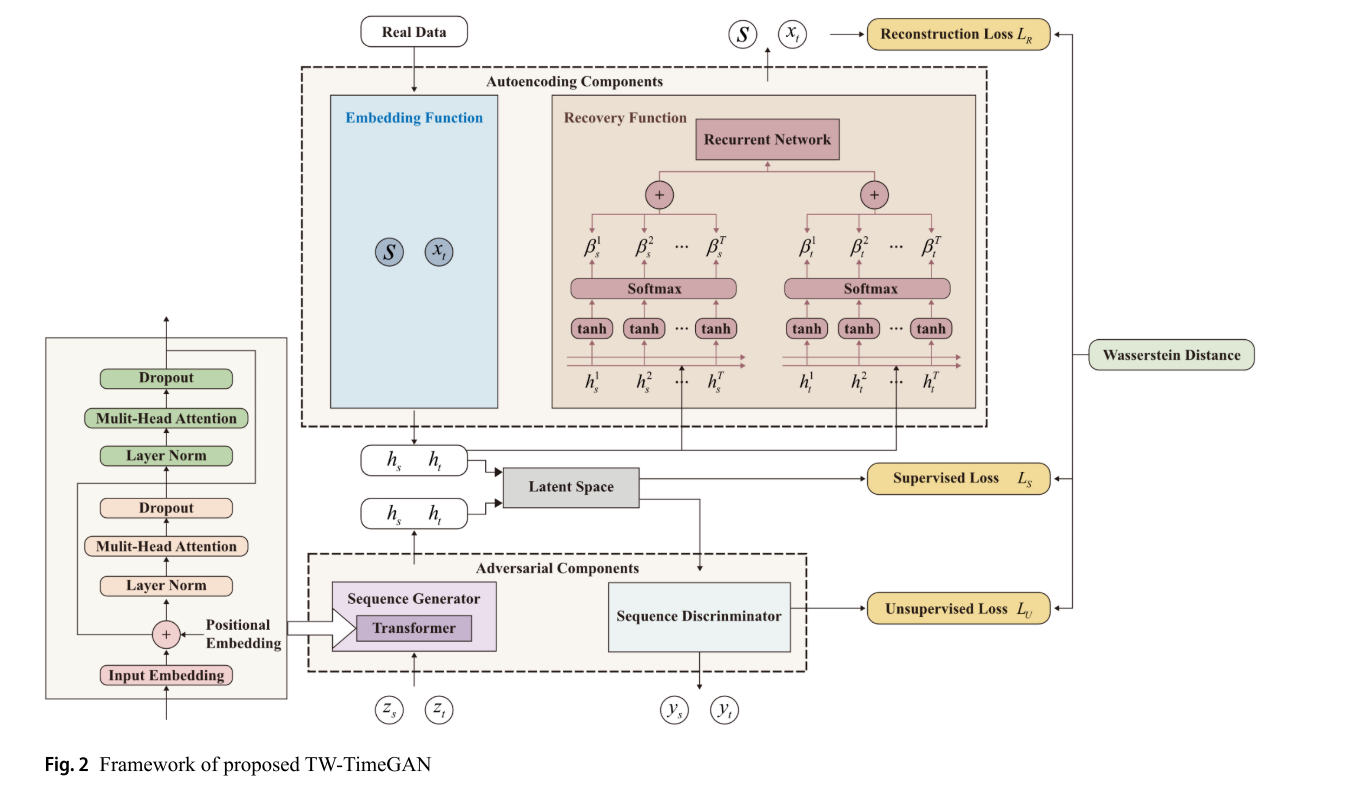
网络架构
有关于GAN和TimeGAN的一些概念和前置知识我之前有介绍过,这里就不再赘述了。链接如下:https://blog.csdn.net/Zcymatics/article/details/145981612?spm=1001.2014.3001.5501
接下来就来详细解释一下本论文构建TW - TimeGAN模型,嵌入Transformer编码器结构,采用Wasserstein距离损失函数,引入特征 - 时间双注意力机制。其网络架构包含的内容如下:
双注意力机制增强了模型对这些特征和关系的提取能力,提高了合成数据的质量。其中包括:
特征注意力:用于关注不同特征(如降雨和径流)之间的关系。
时间注意力:用于关注时间序列中的时间依赖性。
下图中的模型框架的解释:
嵌入函数:
将原始序列映射到潜在空间。输入 为 x(真实洪水序列) 到嵌入函数,通过嵌入函数映射为潜在代码 h t h_t ht
序列生成器
关于Transformer可以看我之前的博客:https://blog.csdn.net/Zcymatics/article/details/142283856?spm=1001.2014.3001.5501与https://blog.csdn.net/Zcymatics/article/details/142406494?spm=1001.2014.3001.5501
通过嵌入Transformer编码器,从随机噪声生成合成序列,过程如下:
- 噪声通过transformer的嵌入层添加位置编码,位置编码确保Transformer能捕捉时间依赖性,公式如下: P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos); P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)。其中pos 是序列中的位置;i 是维度索引;dmodel是模型的嵌入维度;PE 是位置编码向量。
- Transformer编码器通过多头注意力处理,多头注意力允许模型同时关注序列中的多个时间点,捕捉降雨和径流之间的复杂关系。 Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V,其中Q(查询)、K(键)、V(值)是输入序列的线性变换表示;d表示维度。
序列判别器
用于判断序列真假,使用Wasserstein距离优化。接收真实序列x 和合成序列 x ^ \hat{x} x^,计算Wasserstein距离: L W = E x ∼ p x [ D ( x ) ] − E z ∼ p z [ D ( G ( z ) ) ] L_W = \mathbb{E}_{x \sim p_x}[D(x)] - \mathbb{E}_{z \sim p_z}[D(G(z))] LW=Ex∼px[D(x)]−Ez∼pz[D(G(z))]。其中,Wasserstein距离衡量真实分布 𝑝𝑥和生成分布pG(z)之间的差异,判别器 D 估计分布间的距离,生成器 G 最小化此距离。
恢复函数
其用于从潜在空间重建序列,嵌入特征-时间双注意力机制。
时间注意力机制用于提取关键时刻,计算潜在代码的时间特征权重,其中:
- e t = v a T ⋅ tanh ( W a h t + b a ) e_t = v_a^T \cdot \tanh(W_a h_t + b_a) et=vaT⋅tanh(Waht+ba)。通过非线性变换计算每个时间步的注意力得分。
- α t = softmax ( e t ) = exp ( e t ) ∑ t ′ = 1 T exp ( e t ′ ) \alpha_t = \text{softmax}(e_t) = \frac{\exp(e_t)}{\sum_{t'=1}^T \exp(e_{t'})} αt=softmax(et)=∑t′=1Texp(et′)exp(et)。将得分归一化为权重,表示各时间步的相对重要性。
- c = ∑ t = 1 T α t h t c = \sum_{t=1}^T \alpha_t h_t c=∑t=1Tαtht。根据权重加权隐藏状态,生成时间注意力输出。
其中 ht是时间步的隐藏状态;et是注意力得分;α t是归一化权重;c 是加权后的上下文向量。
损失函数:
三个损失函数协同优化,分别如下:
- 重构损失: L R = E x ∼ p x [ ∥ x − x ^ ∥ 2 2 ] L_R = \mathbb{E}_{x \sim p_x} \left[ \| x - \hat{x} \|_2^2 \right] LR=Ex∼px[∥x−x^∥22]
衡量原始时间序列x与生成的序列 x ^ \hat{x} x^ 之间的均方误差。确保嵌入和恢复函数能保留原始数据的特征。 - 监督损失 : L S = E x ∼ p x [ ∑ t = 1 T ∥ h t − h ^ t ∥ 2 2 ] L_S = \mathbb{E}_{x \sim p_x} \left[ \sum_{t=1}^T \| h_t - \hat{h}_t \|_2^2 \right] LS=Ex∼px[∑t=1T∥ht−h^t∥22]
衡量真实潜在表示 h t h_t ht和生成潜在表示 h ^ t \hat{h}_t h^t的差值,确保生成器捕捉时间动态 - 无监督损失: L U = E x ∼ p x [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] L_U = \mathbb{E}_{x \sim p_x} \left[ \log D(x) \right] + \mathbb{E}_{z \sim p_z} \left[ \log (1 - D(G(z))) \right] LU=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]
传统GAN对抗损失,优化判别器区分真假序列,生成器生成逼真序列G是生成器,D是判别器。
实验
这篇论文围绕基于TimeGAN改进的TW - TimeGAN模型在洪水预测中的应用展开实验,从生成性能和预测性能两方面进行评估,采用t - SNE评估生成性能,DTW定量比较实际和合成时间序列数据的相似度,用RMSE、MAE、NSE等评估预测性能。
其中:
- DTW(动态时间规整),用于衡量时间序列相似性,通过动态规划找到两个序列的最佳对齐路径,计算累积距离。值越小,序列越相似。
DTW ( X , Y ) = min π ∑ ( i , j ) ∈ π d ( x i , y j ) \text{DTW}(X, Y) = \min_{\pi} \sum_{(i,j) \in \pi} d(x_i, y_j) DTW(X,Y)=minπ∑(i,j)∈πd(xi,yj)
X,Y 是两个时间序列;π 是对齐路径;d(xi,yj)是欧氏距离 - NSE衡量预测值与真实值的拟合度,是真实值均值。值接近1表示预测准确,公式如下:
NSE = 1 − ∑ i = 1 N ( y i − y ^ i ) 2 ∑ i = 1 N ( y i − y ˉ ) 2 \text{NSE} = 1 - \frac{\sum_{i=1}^N (y_i - \hat{y}_i)^2}{\sum_{i=1}^N (y_i - \bar{y})^2} NSE=1−∑i=1N(yi−yˉ)2∑i=1N(yi−y^i)2
y ˉ \bar{y} yˉ是真实值的均值;y_i真实值; y ^ i \hat{y}_i y^i预测值
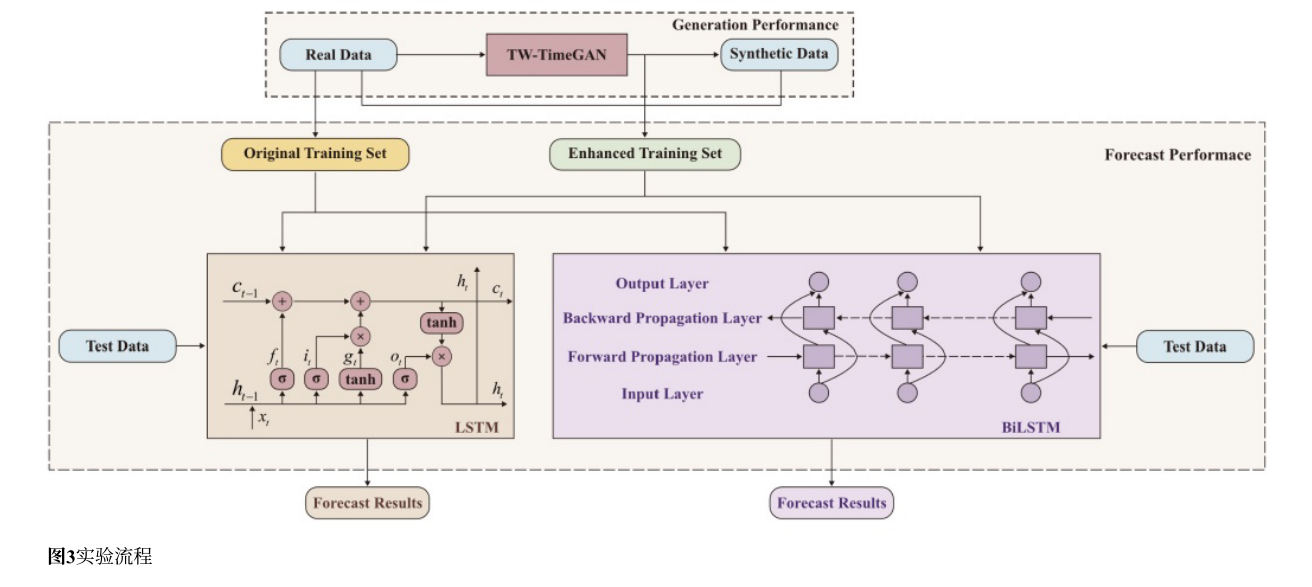
实验流程如下图所示:
作者使用原始TimeGAN和其他改进的生成模型生成真实和合成的洪水序列。这些模型包括不同的改进版本,用于比较生成性能。
将不同方法生成的合成洪水序列的分布与真实序列的分布进行比较,以评估合成样本的真实性;随后,使用上述数据增强方法扩充训练数据,并比较扩充前后洪水预报结果,评估生成数据的有效性;扩充数据包括真实数据和合成数据,比较旨在验证合成数据是否提升了预报性能;通过比较五种模型,证明TW-TimeGAN的综合优势。
实验结果如下:
生成性能对比
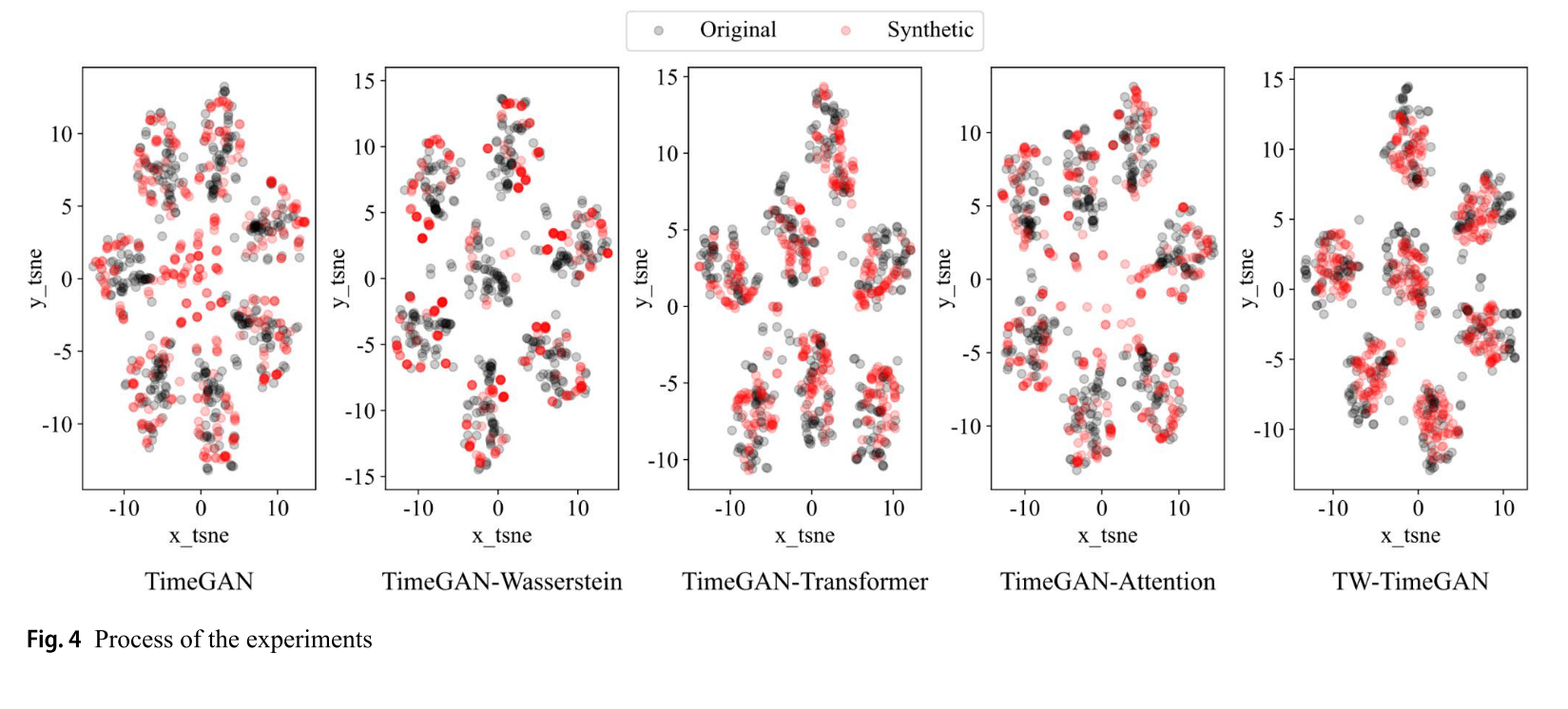
不同模型生成序列的相似度对比:研究使用原始TimeGAN、TimeGAN - Wasserstein、TimeGAN - Transformer、TimeGAN - Attention和TW - TimeGAN五种模型生成合成洪水序列。通过DTW评估,TW - TimeGAN的DTW值最低,表明其生成的合成洪水序列与实际洪水序列相似度最高,数据质量最佳。

t - SNE可视化对比:原始TimeGAN生成的合成洪水序列有较多离群值,分布与实际序列差异大;TimeGAN - Wasserstein生成的序列分布接近实际序列,但数据点多集中在周边,未能充分捕捉实际洪水序列特征;TimeGAN - Transformer和TimeGAN - Attention覆盖了更多实际洪水序列特征;TW - TimeGAN生成的合成数据与实际数据分布重叠度最高,能有效学习降水和流量特征,生成的合成洪水序列更具多样性。
预测性能对比
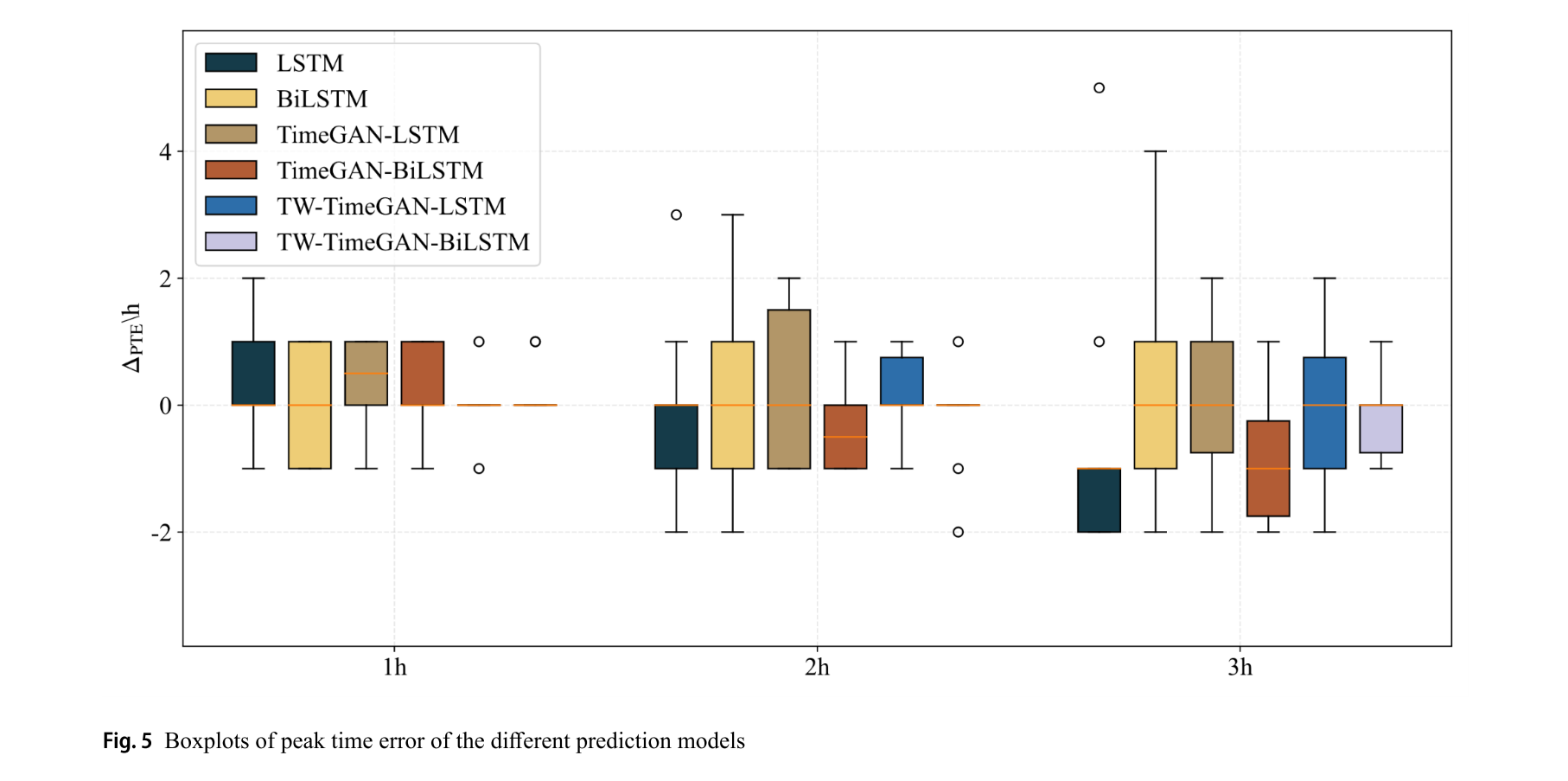
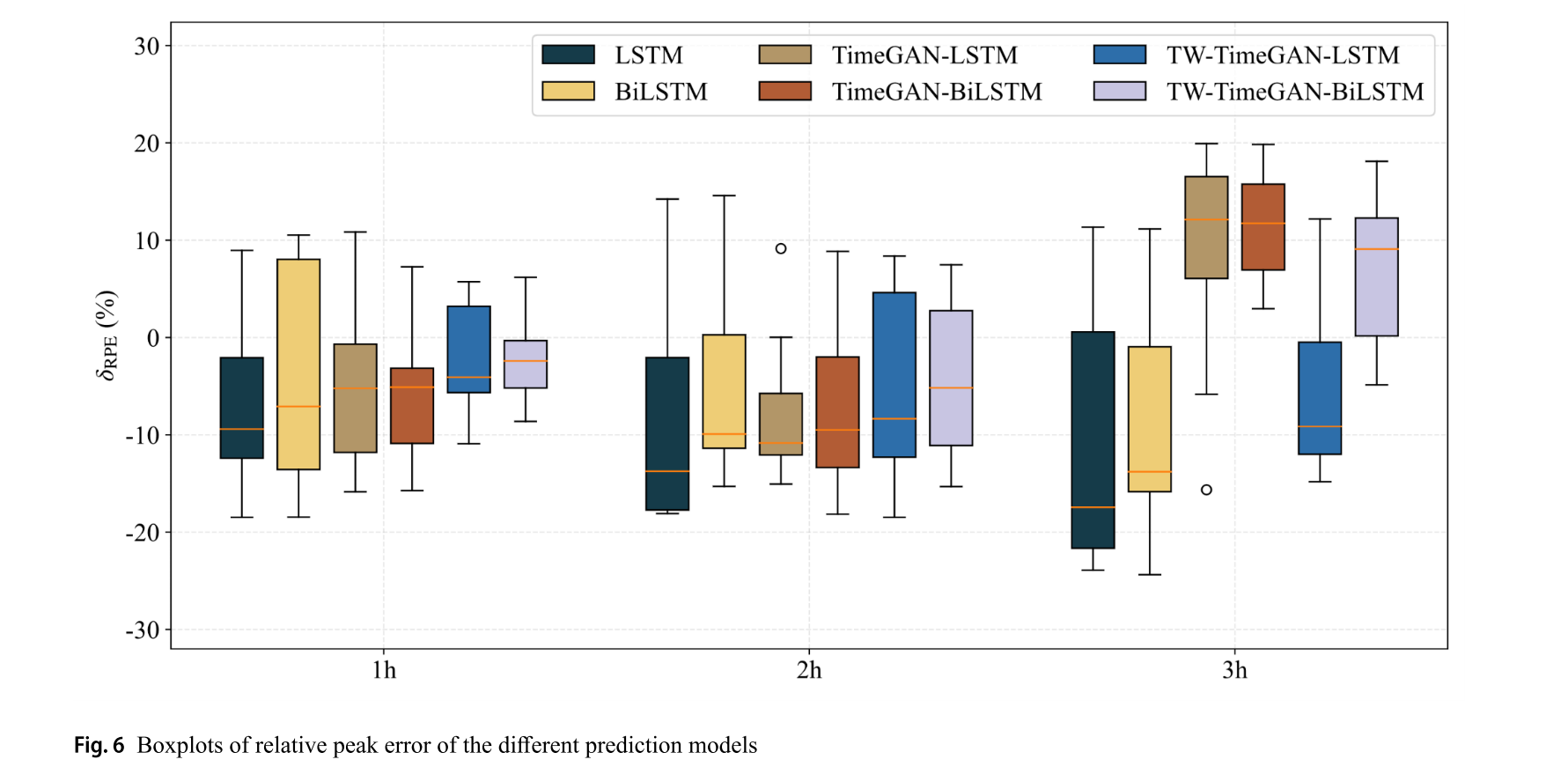
峰值时间误差:原始小样本洪水预测中,LSTM和BiLSTM模型的峰值时间误差随提前时间增加而增大,在T + 3时出现偏差为4H和5H的离群值;引入TimeGAN在T + 1和T + 2时对峰值时间误差影响小;TW - TimeGAN显著降低了峰值时间误差,分布更集中,预测准确性提高。
峰值流量预测:LSTM和BiLSTM模型严重低估峰值流量,且预测准确性随提前时间增加而下降;TimeGAN - LSTM和TimeGAN - BiLSTM模型相对峰值误差较小,但预测结果波动大;TW - TimeGAN使预测结果分布更集中,相对峰值误差最小,虽随预测步长增加误差分布逐渐分散,但仍优于其他模型。
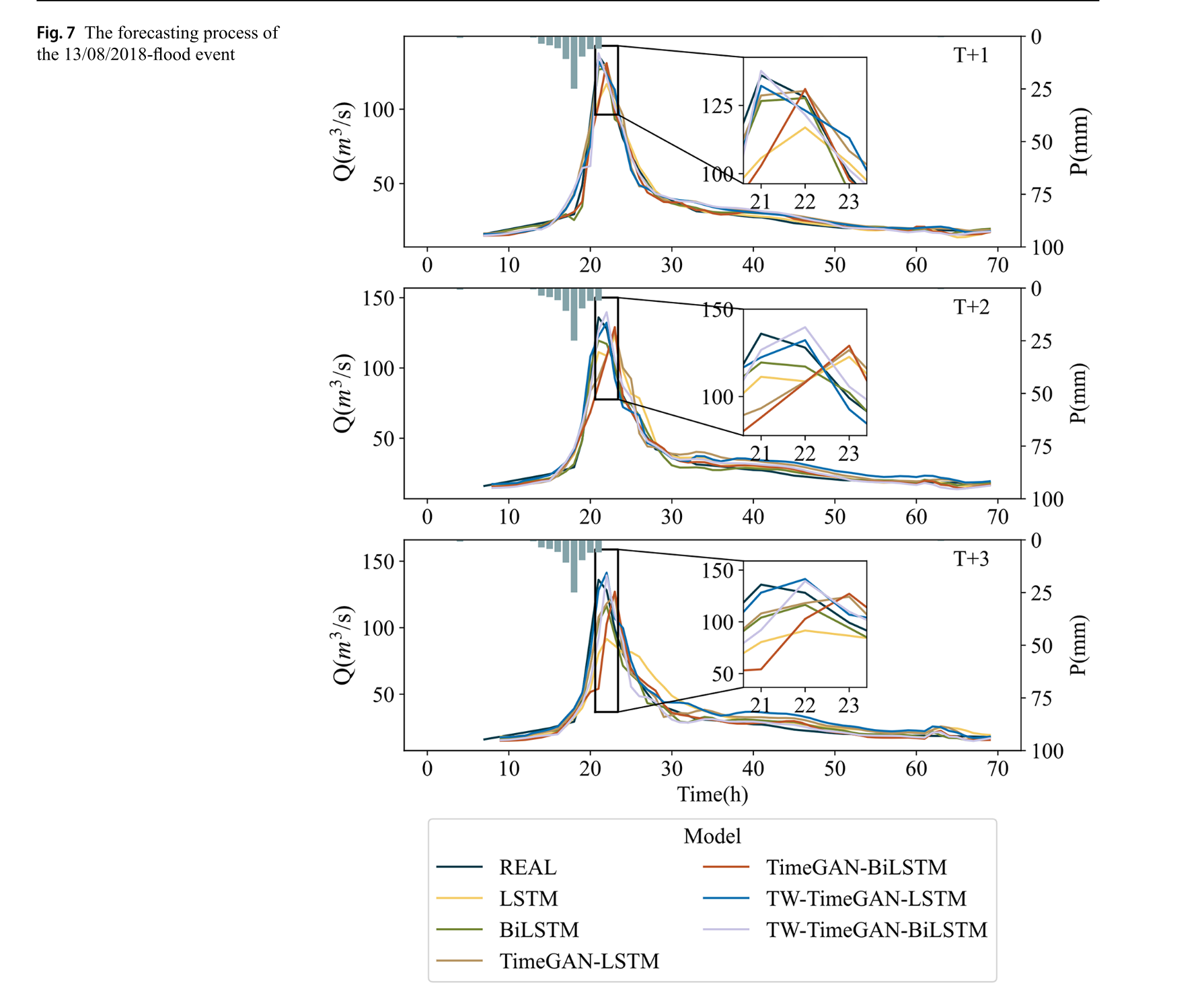
具体洪水事件预测过程分析
2018年8月13日洪水事件:LSTM模型严重低估峰值流量,预测准确性低;BiLSTM模型在T + 1时能估计峰值流量,但随提前时间增加预测能力下降;TimeGAN - LSTM和TimeGAN - BiLSTM模型在峰值流量预测上优于前两者,但在峰值时间误差预测上表现弱;TW - TimeGAN - LSTM和TW - TimeGAN - BiLSTM模型在峰值流量预测上表现出色,能模拟洪水涨落过程,其中TW - TimeGAN - BiLSTM预测结果更准确。
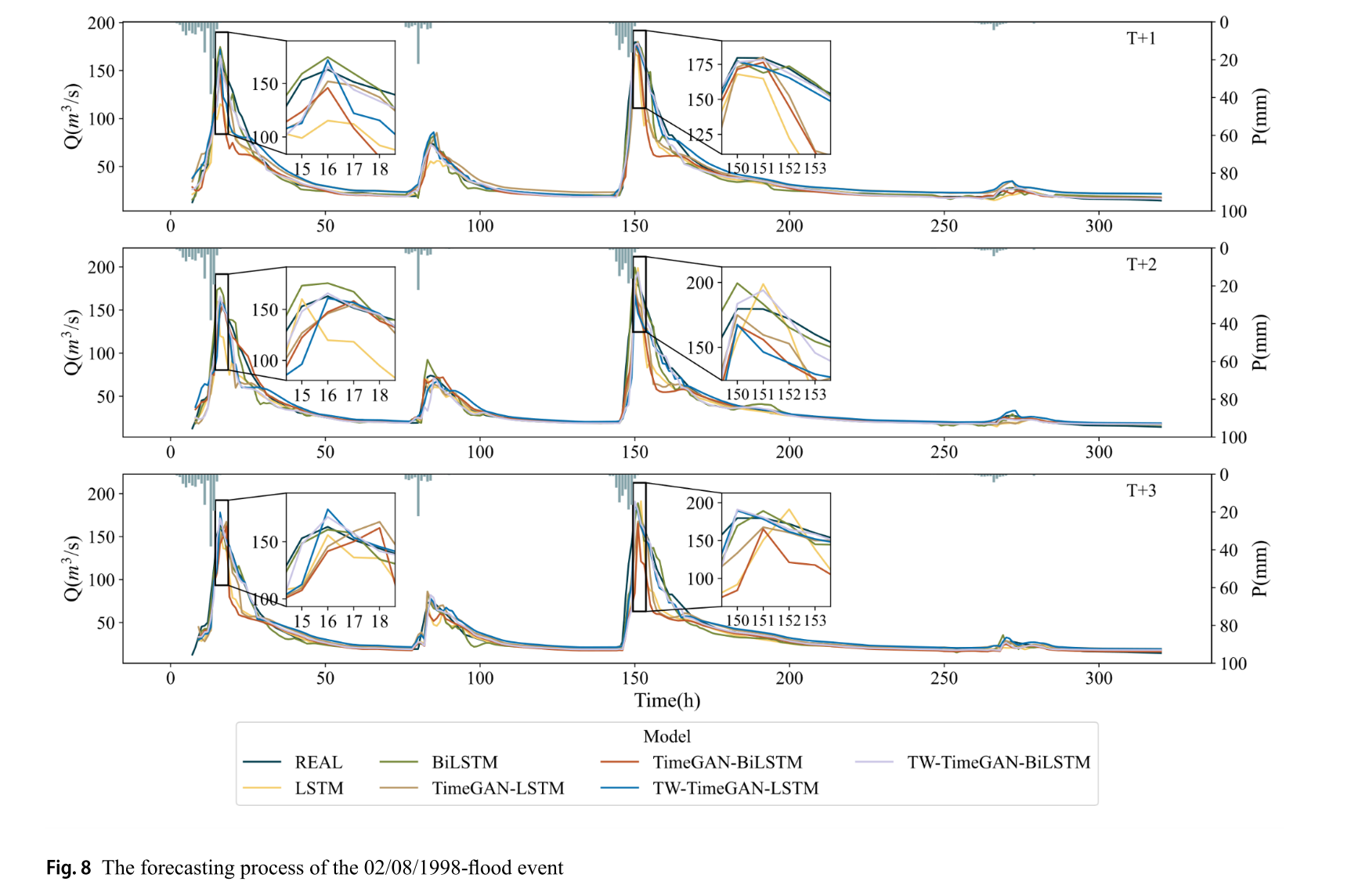
1998年8月2日洪水事件:LSTM模型波动大,预测性能最差;BiLSTM模型高估峰值流量,不利于防洪决策;TimeGAN - LSTM和TimeGAN - BiLSTM模型能较好模拟峰值流量,但严重高估退水过程;TW - TimeGAN - LSTM模型低估洪水上涨过程;TW - TimeGAN - BiLSTM模型在T + 1和T + 2时准确捕捉峰值流量和退水过程,T + 3时虽略微高估峰值流量,但相对误差小,预测结果更准确。
论文代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 超参数设置
batch_size = 64
seq_len = 24 # 时间序列长度(如24小时)
feature_dim = 2 # 特征维度(如降雨和径流)
hidden_dim = 64 # 隐藏层维度
num_heads = 4 # Transformer多头注意力头数
num_layers = 2 # Transformer层数
latent_dim = 32 # 潜在空间维度
lambda_gp = 10 # 梯度惩罚权重
lr = 0.0002 # 学习率
num_epochs = 100 # 训练轮数# 设置随机种子以确保可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 模拟洪水时间序列数据
def generate_synthetic_data(batch_size, seq_len, feature_dim):# 使用正弦波叠加噪声模拟降雨和径流t = np.linspace(0, 2 * np.pi, seq_len)data = np.zeros((batch_size, seq_len, feature_dim))for i in range(batch_size):for j in range(feature_dim):data[i, :, j] = np.sin(t + np.random.randn() * 0.1) + np.random.randn(seq_len) * 0.05return torch.FloatTensor(data).to(device)# Transformer编码器模块
class TransformerEncoder(nn.Module):def __init__(self, input_dim, hidden_dim, num_heads, num_layers):super(TransformerEncoder, self).__init__()# 输入线性层self.input_linear = nn.Linear(input_dim, hidden_dim)# Transformer编码器层encoder_layer = nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=num_heads, dim_feedforward=hidden_dim * 4, dropout=0.1)self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 位置编码self.positional_encoding = self.create_positional_encoding(seq_len, hidden_dim)def create_positional_encoding(self, seq_len, d_model):# 实现位置编码position = torch.arange(0, seq_len).unsqueeze(1).float()div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))pe = torch.zeros(seq_len, d_model)pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pe.unsqueeze(0).to(device)def forward(self, x):# x: [batch_size, seq_len, input_dim]x = self.input_linear(x) # 映射到隐藏维度x = x + self.positional_encoding[:, :x.size(1), :] # 添加位置编码x = x.permute(1, 0, 2) # [seq_len, batch_size, hidden_dim]output = self.transformer_encoder(x) # Transformer编码return output.permute(1, 0, 2) # [batch_size, seq_len, hidden_dim]# 特征-时间双注意力机制(用于恢复函数)
class DualAttention(nn.Module):def __init__(self, hidden_dim):super(DualAttention, self).__init__()# 特征注意力self.feature_attn = nn.Sequential(nn.Linear(hidden_dim, hidden_dim // 2),nn.Tanh(),nn.Linear(hidden_dim // 2, 1))# 时间注意力self.time_attn = nn.Sequential(nn.Linear(hidden_dim, hidden_dim // 2),nn.Tanh(),nn.Linear(hidden_dim // 2, 1))def forward(self, h):# h: [batch_size, seq_len, hidden_dim]# 特征注意力feature_scores = self.feature_attn(h) # [batch_size, seq_len, 1]feature_weights = torch.softmax(feature_scores, dim=-1)feature_context = h * feature_weights # 加权特征# 时间注意力time_scores = self.time_attn(feature_context) # [batch_size, seq_len, 1]time_weights = torch.softmax(time_scores, dim=1) # [batch_size, seq_len, 1]context = torch.sum(feature_context * time_weights, dim=1) # [batch_size, hidden_dim]return context# 序列生成器
class Generator(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_heads, num_layers):super(Generator, self).__init__()self.transformer = TransformerEncoder(input_dim, hidden_dim, num_heads, num_layers)self.output_linear = nn.Linear(hidden_dim, output_dim)def forward(self, z):# z: [batch_size, seq_len, input_dim]h = self.transformer(z) # Transformer编码output = self.output_linear(h) # 映射到输出维度return output # [batch_size, seq_len, output_dim]# 序列判别器
class Discriminator(nn.Module):def __init__(self, input_dim, hidden_dim):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.LeakyReLU(0.2),nn.Linear(hidden_dim, hidden_dim // 2),nn.LeakyReLU(0.2),nn.Linear(hidden_dim // 2, 1))def forward(self, x):# x: [batch_size, seq_len, input_dim]x = x.view(x.size(0), -1) return self.model(x) # [batch_size, 1]# 嵌入函数
class Embedder(nn.Module):def __init__(self, input_dim, latent_dim):super(Embedder, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, latent_dim),nn.ReLU(),nn.Linear(latent_dim, latent_dim))def forward(self, x):return self.model(x) # [batch_size, seq_len, latent_dim]# 恢复函数(包含双注意力)
class Recovery(nn.Module):def __init__(self, latent_dim, hidden_dim, output_dim):super(Recovery, self).__init__()self.attention = DualAttention(hidden_dim)self.model = nn.Sequential(nn.Linear(latent_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim))def forward(self, h):# h: [batch_size, seq_len, latent_dim]h = self.model(h) # 映射context = self.attention(h) # 双注意力output = self.model(h) # 最终输出return output # [batch_size, seq_len, output_dim]# TW-TimeGAN模型
class TWTimeGAN(nn.Module):def __init__(self):super(TWTimeGAN, self).__init__()self.generator = Generator(latent_dim, hidden_dim, latent_dim, num_heads, num_layers)self.discriminator = Discriminator(feature_dim * seq_len, hidden_dim)self.embedder = Embedder(feature_dim, latent_dim)self.recovery = Recovery(latent_dim, hidden_dim, feature_dim)def forward(self, x, z):# 嵌入和恢复h = self.embedder(x) # 真实序列嵌入x_hat = self.recovery(h) # 重构序列# 生成h_hat = self.generator(z) # 生成潜在代码x_tilde = self.recovery(h_hat) # 生成序列# 判别y_real = self.discriminator(x) # 真实序列得分y_fake = self.discriminator(x_tilde) # 生成序列得分return h, x_hat, h_hat, x_tilde, y_real, y_fake# 梯度惩罚计算
def compute_gradient_penalty(D, real_samples, fake_samples):alpha = torch.rand(real_samples.size(0), 1, 1).to(device)alpha = alpha.expand_as(real_samples)interpolates = (alpha * real_samples + (1 - alpha) * fake_samples).requires_grad_(True)d_interpolates = D(interpolates)gradients = torch.autograd.grad(outputs=d_interpolates,inputs=interpolates,grad_outputs=torch.ones_like(d_interpolates),create_graph=True,retain_graph=True)[0]gradients = gradients.view(gradients.size(0), -1)gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()return gradient_penalty# 训练函数
def train_tw_timegan():# 初始化模型model = TWTimeGAN().to(device)optimizer_g = optim.Adam(list(model.generator.parameters()) + list(model.embedder.parameters()) + list(model.recovery.parameters()),lr=lr, betas=(0.5, 0.9))optimizer_d = optim.Adam(model.discriminator.parameters(), lr=lr, betas=(0.5, 0.9))# 训练循环for epoch in range(num_epochs):# 生成批次数据real_data = generate_synthetic_data(batch_size, seq_len, feature_dim)z = torch.randn(batch_size, seq_len, latent_dim).to(device)# 前向传播h, x_hat, h_hat, x_tilde, y_real, y_fake = model(real_data, z)# 计算损失# 重构损失loss_reconstruction = torch.mean((real_data - x_hat) ** 2)# 监督损失loss_supervised = torch.mean((h - h_hat) ** 2)# Wasserstein判别器损失gradient_penalty = compute_gradient_penalty(model.discriminator, real_data, x_tilde)loss_discriminator = -torch.mean(y_real) + torch.mean(y_fake) + lambda_gp * gradient_penalty# Wasserstein生成器损失loss_generator = -torch.mean(y_fake)# 联合生成器损失loss_g_total = loss_generator + 10 * loss_reconstruction + 5 * loss_supervised# 优化optimizer_d.zero_grad()loss_discriminator.backward(retain_graph=True)optimizer_d.step()optimizer_g.zero_grad()loss_g_total.backward()optimizer_g.step()# 打印损失if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch+1}/{num_epochs}] | D Loss: {loss_discriminator.item():.4f} | G Loss: {loss_g_total.item():.4f}")# 运行训练
if __name__ == "__main__":train_tw_timegan()
结论
本文提出增强型数据增强网络TW - TimeGAN用于小样本洪水序列预测。实验表明,该模型能有效学习降水和流量特征,生成高质量合成洪水序列。结合BiLSTM预测模型,其预测结果的平均RMSE和MAE最小,NSE最大,TW - TimeGAN - BiLSTM预测性能最佳,在洪水预测中适用性更强,还能优化水资源管理。
不足以及展望
文章未提及模型在不同气候、地理条件下的泛化能力,也未对模型训练的计算成本和时间进行分析。此外,仅使用了有限的评价指标评估模型性能,可能无法全面反映模型优劣。后续研究可整合卫星观测气象数据、蒸发数据及地面观测站数据,纳入土壤湿度、温度和融雪等特征,增强合成洪水序列的真实性与多样性。还可进一步探索模型在不同流域、气候条件下的适用性,优化模型结构和参数,提高预测精度。同时,分析模型训练的计算成本和时间,提升模型的实用性。






