图书分析大屏展示系统项目大纲与启动教程
一、项目概述
图书分析大屏展示系统是一个基于Django框架开发的Web应用,主要用于图书数据的可视化分析与展示。该系统采用MVT(Model-View-Template)架构模式,结合MySQL数据库,实现了图书数据的采集、清洗、存储、分析和可视化展示等功能。系统界面简洁大气,功能齐全,适合作为毕业设计或课程设计项目。
该系统主要特点包括:
- 基于Python Django框架开发,采用MVT架构
- 使用MySQL数据库进行数据存储
- 前端采用Bootstrap和jQuery等主流框架
- 集成爬虫功能,可自动采集图书数据
- 内置数据清洗模块,保证数据质量
- 可视化展示各类图书分析结果
- 支持用户注册登录和个性化推荐
二、项目截图
登录
注册
首页
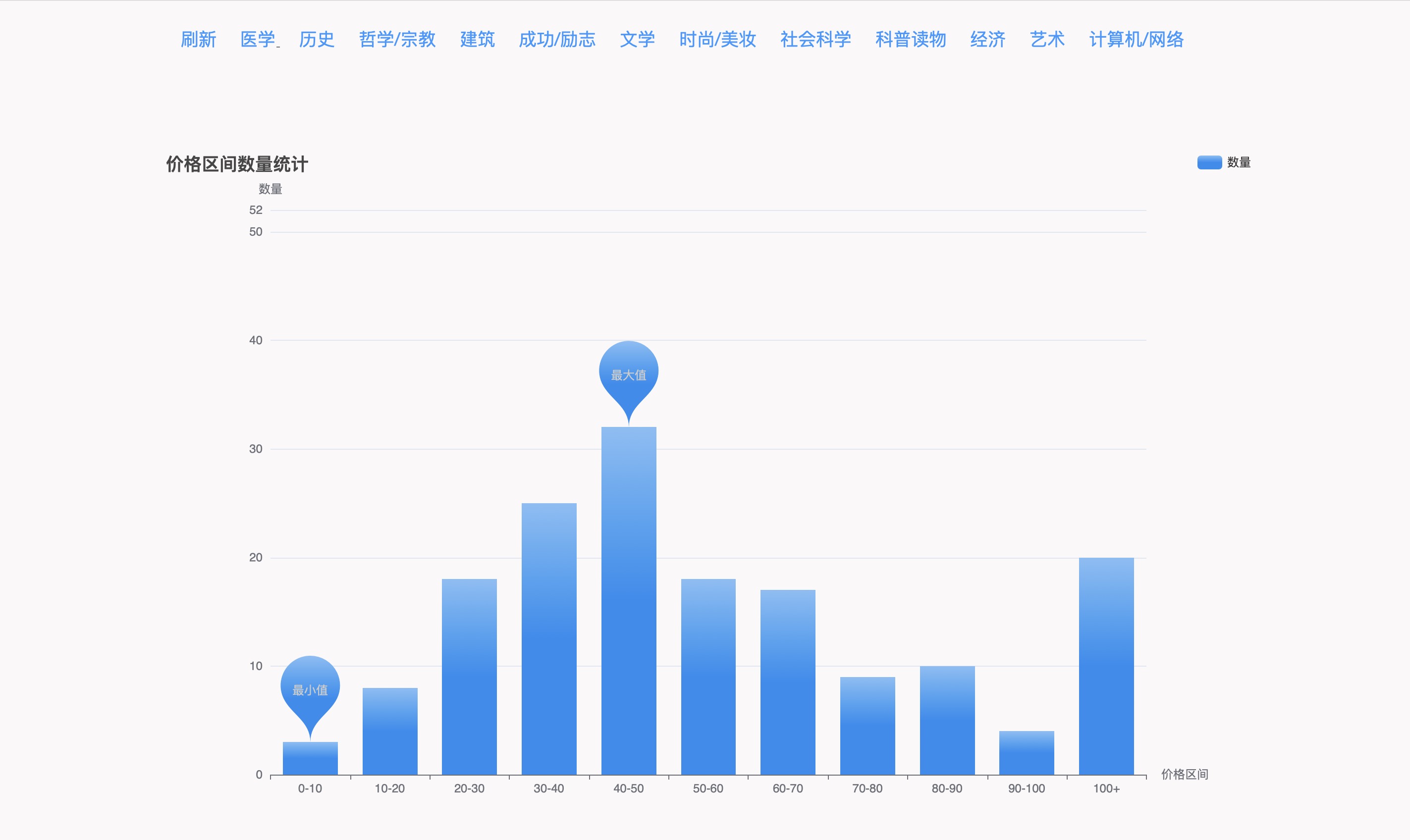
价格区间数量统计
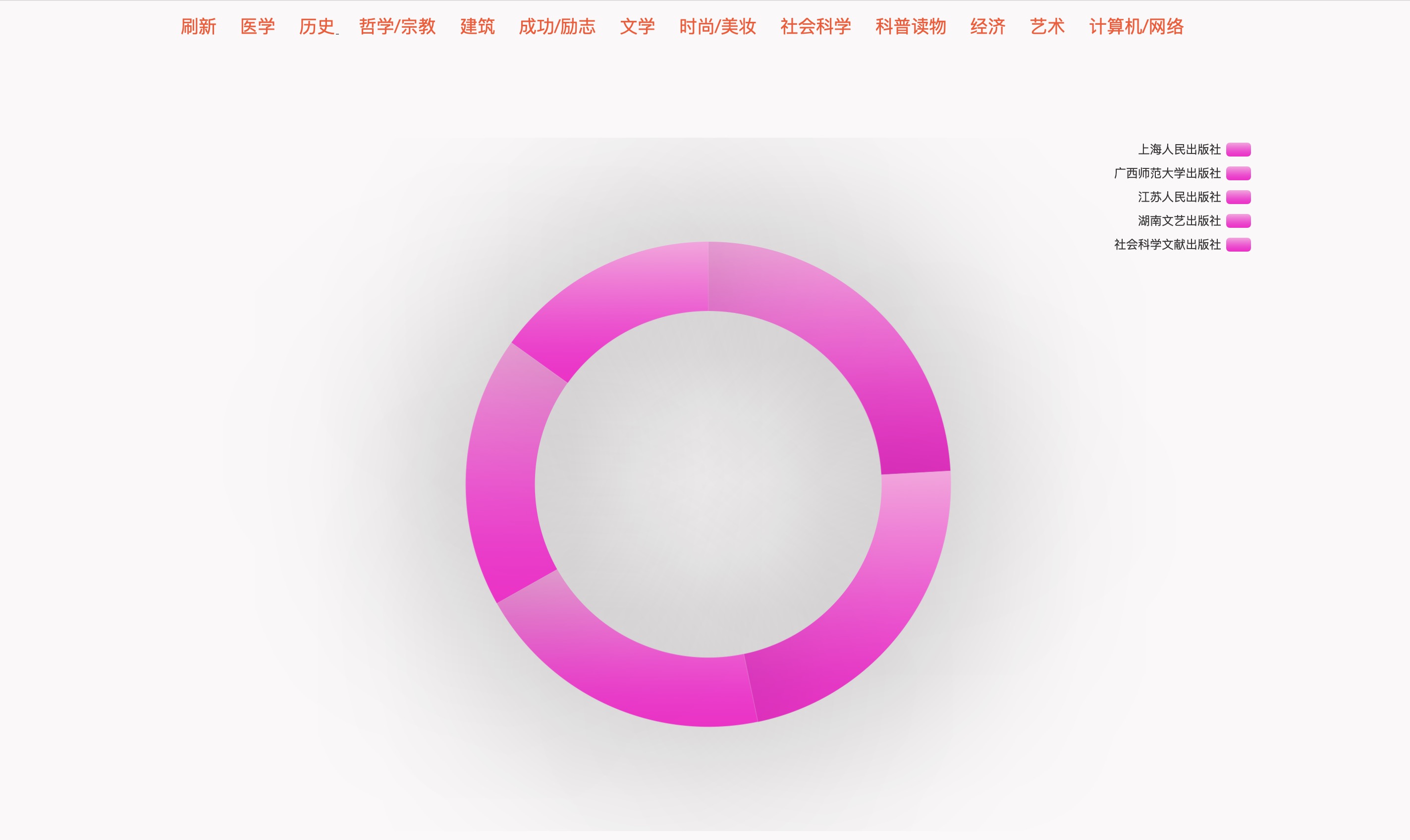
不同类别下出版社发行量Top5
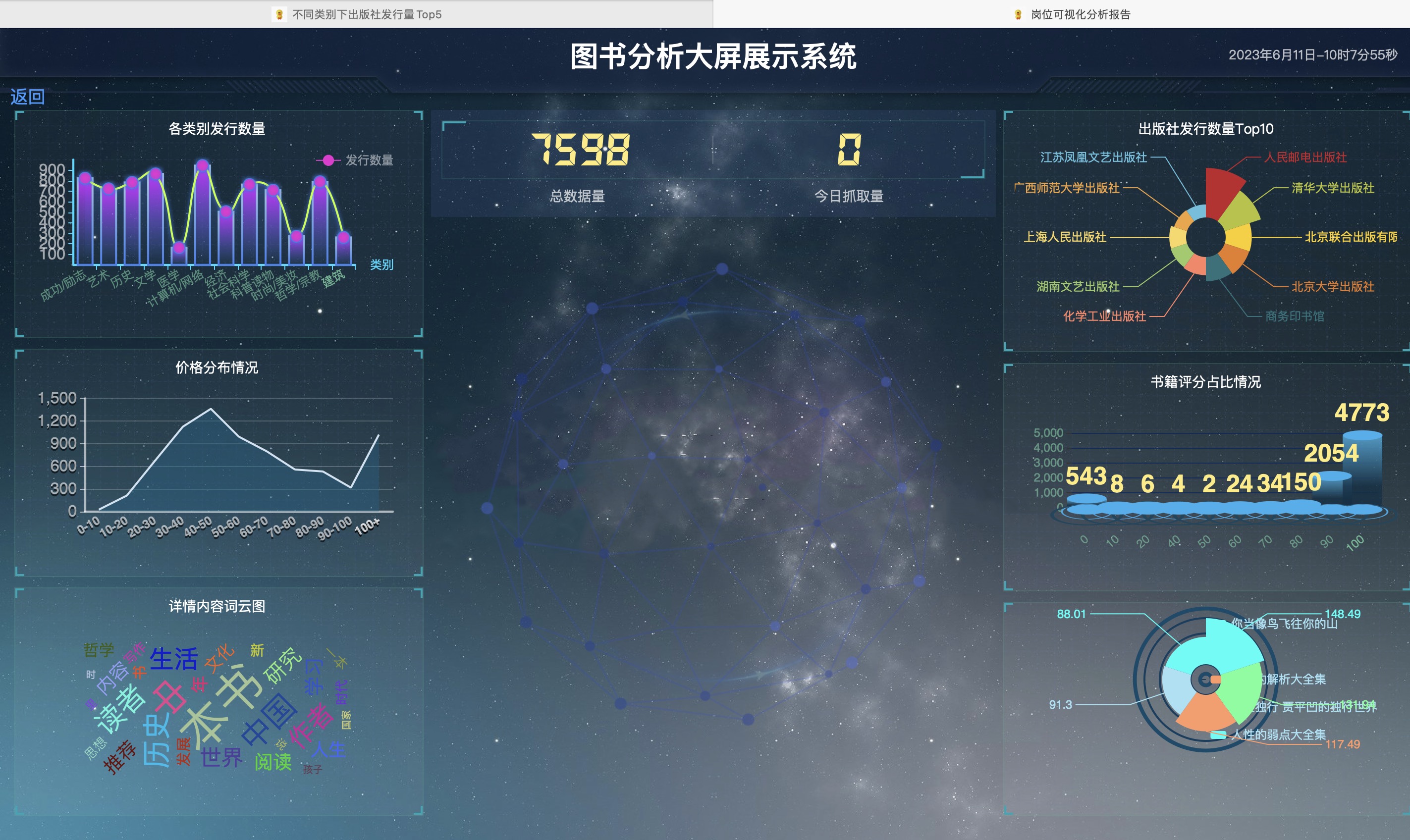
大屏展示
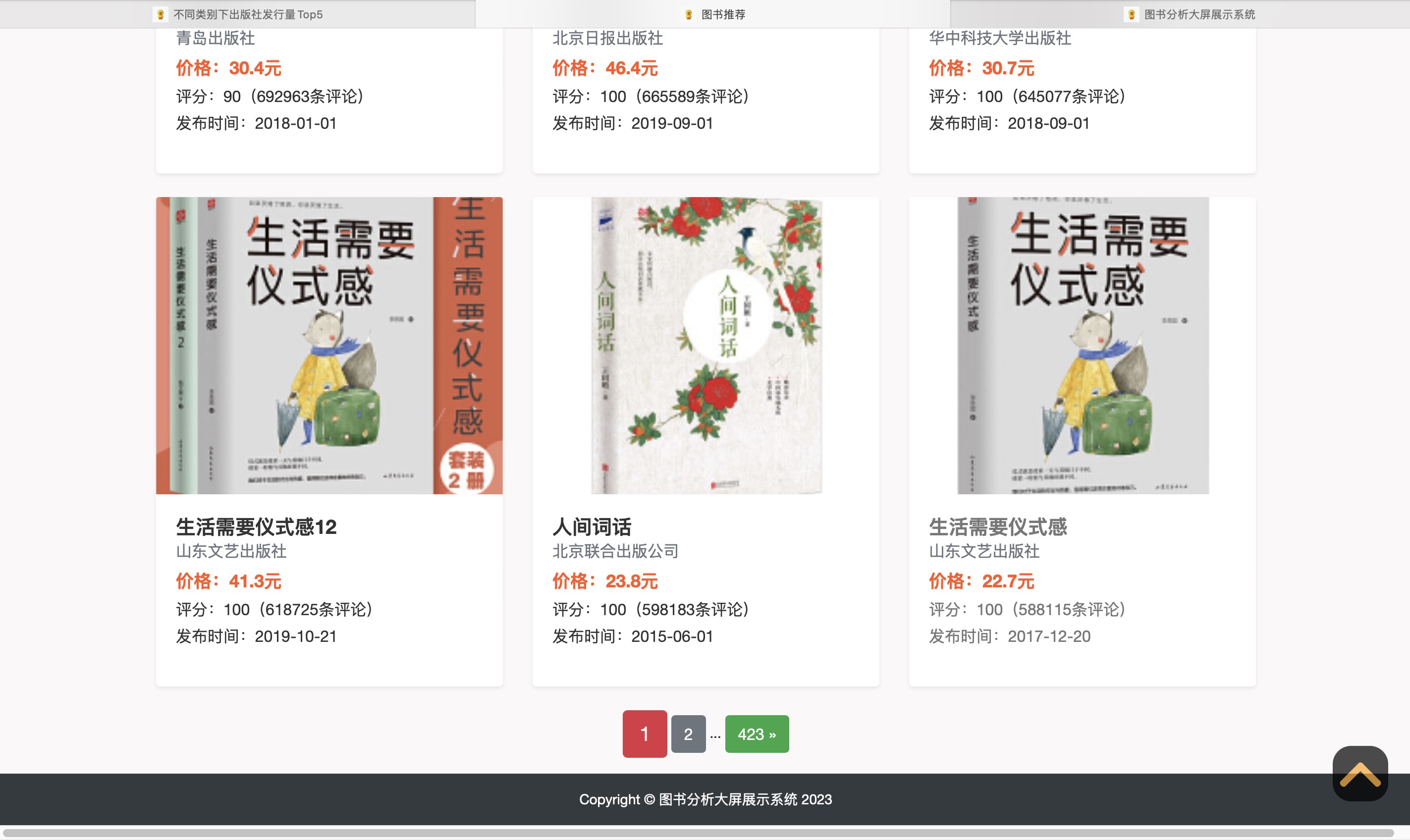
图书推荐
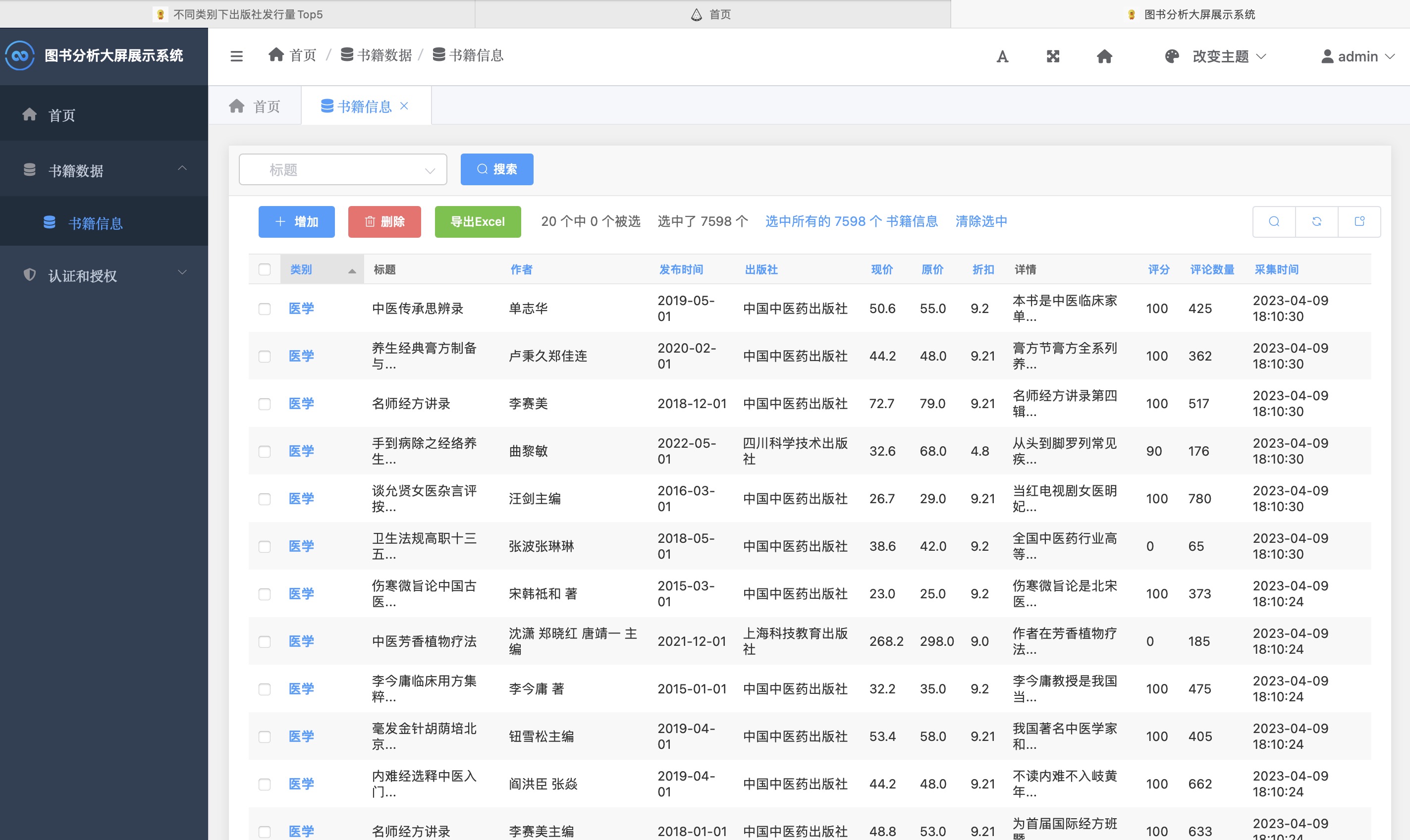
后台管理
三、技术栈
1. 开发环境
- 编辑器:PyCharm 2023.1 (旗舰版)
- 操作系统:Windows/Linux/MacOS
2. 前端技术
- 基础:HTML + CSS + JavaScript
- 框架:Bootstrap + jQuery
- 图表库:ECharts
3. 后端技术
- 框架:Django 4.2.2
- 爬虫:BeautifulSoup4 + Requests
- 数据处理:Pandas + NumPy
- 分析工具:SQLAlchemy + Jieba
4. 数据库
- MySQL 8.0.26
5. 开发语言
- Python 3.9.16
四、系统架构
1. 总体架构
系统采用经典的三层架构:
- 表示层(前端):负责用户界面与交互
- 业务逻辑层(后端):处理业务逻辑和数据分析
- 数据访问层:负责数据的存储和访问
2. MVT模式说明
- Model层:定义数据模型,处理数据访问
- View层:处理HTTP请求,实现业务逻辑
- Template层:负责页面渲染和用户界面
3. 功能模块划分
- 用户管理模块:负责用户注册、登录等功能
- 数据采集模块:实现网络爬虫功能,采集图书数据
- 数据清洗模块:处理和转换原始数据
- 数据分析模块:对图书数据进行统计和分析
- 可视化展示模块:以图表形式展示分析结果
- 图书推荐模块:基于用户喜好推荐图书
- 后台管理模块:系统配置和数据管理
五、目录结构
Book_Analysis/
├── README.md # 项目说明文档
├── .idea/ # PyCharm项目配置目录
├── test.py # 测试脚本
├── djangoPreject/ # Django项目目录
│ ├── djangoPreject/ # 项目配置目录
│ │ ├── __init__.py # 初始化文件
│ │ ├── settings.py # 项目设置
│ │ ├── urls.py # URL配置
│ │ ├── wsgi.py # WSGI应用配置
│ │ └── asgi.py # ASGI应用配置
│ ├── system/ # 系统应用
│ ├── user/ # 用户应用
│ ├── manage.py # Django管理脚本
│ ├── static/ # 静态文件目录
│ └── templates/ # 模板文件目录
├── booksdb.sql # 数据库SQL文件
├── clean.py # 数据清洗脚本
├── clean_data.csv # 清洗后的数据
├── data.csv # 原始爬取数据
├── reptile.py # 爬虫脚本
└── requirements.txt # 项目依赖配置
六、数据流程
- 数据获取:通过reptile.py爬虫脚本从网站爬取图书数据,保存到data.csv
- 数据清洗:使用clean.py脚本对原始数据进行清洗,生成clean_data.csv
- 数据入库:将清洗后的数据导入MySQL数据库
- 数据分析:在系统中对数据进行统计分析
- 数据可视化:通过ECharts等工具将分析结果可视化展示
七、功能模块详解
1. 用户管理模块
- 用户注册:新用户可以注册账号
- 用户登录:已注册用户可以登录系统
- 个人信息管理:用户可以更新个人信息
- 权限控制:区分普通用户和管理员权限
2. 数据采集模块
- 网络爬虫:自动从图书网站采集数据
- 定时任务:支持定时更新数据
- 采集配置:可配置采集规则和参数
3. 数据清洗模块
- 数据去重:删除重复记录
- 数据修复:修复错误和缺失值
- 数据转换:转换数据格式和单位
- 数据分类:对图书进行分类标记
4. 数据分析模块
- 基础统计:图书数量、价格统计等
- 分类分析:不同类别图书的分布和特点
- 出版社分析:出版社出版情况统计
- 价格分析:图书价格区间分布
5. 可视化展示模块
- 数据大屏:综合展示关键数据指标
- 柱状图表:展示分类和数量关系
- 饼图:展示占比分布情况
- 折线图:展示趋势变化
- 热力图:展示分布密度
6. 图书推荐模块
- 基于用户行为的推荐
- 基于内容的推荐
- 热门图书推荐
- 相似图书推荐
7. 后台管理模块
- 用户管理:管理用户信息和权限
- 数据管理:管理和维护图书数据
- 系统配置:设置系统参数
- 日志管理:查看系统运行日志
八、系统截图和界面说明
- 登录界面:用户登录入口,简洁美观
- 注册界面:新用户注册页面
- 首页:系统主页,展示系统概况
- 价格区间数量统计:以图表形式展示不同价格区间的图书数量
- 不同类别下出版社发行量Top5:展示各类别中出版社的发行量排名
- 大屏展示:数据可视化大屏,全面展示分析结果
- 图书推荐:基于用户行为的个性化推荐
- 后台管理:系统管理界面,提供数据管理功能
九、数据库设计
1. 主要数据表
用户表(user_user)
- id:用户ID,主键
- username:用户名
- password:密码
- email:邮箱
- is_active:是否激活
- create_time:创建时间
图书表(system_book)
- id:图书ID,主键
- book_name:图书名称
- author:作者
- publisher:出版社
- publish_date:出版日期
- price:价格
- category:类别
- description:描述
- cover_url:封面图片URL
- rating:评分
分类表(system_category)
- id:分类ID,主键
- name:分类名称
- description:分类描述
用户收藏表(system_userfavorite)
- id:收藏ID,主键
- user_id:用户ID,外键
- book_id:图书ID,外键
- create_time:收藏时间
2. 表关系
- 用户与收藏:一对多关系
- 图书与收藏:一对多关系
- 分类与图书:一对多关系
十、详细启动教程
1. 环境准备
1.1 安装Python
确保您已安装Python 3.9或更高版本,可以通过以下命令检查Python版本:
python --version
1.2 安装MySQL
安装MySQL 8.0或更高版本,并确保服务正常运行。记住您设置的用户名和密码。
1.3 创建虚拟环境(可选但推荐)
# 创建虚拟环境
python -m venv venv# Windows激活虚拟环境
venv\Scripts\activate# Linux/Mac激活虚拟环境
source venv/bin/activate
1.5 安装依赖
进入项目目录,安装所需的Python包:
pip install -r requirements.txt
这将安装包括Django、PyMySQL、BeautifulSoup4、Pandas等必要的库。
2. 数据库配置
2.1 创建数据库
登录MySQL,创建名为booksdb的数据库:
CREATE DATABASE booksdb CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
2.2 修改数据库配置
编辑djangoPreject/djangoPreject/settings.py文件,找到DATABASES配置部分,根据您的MySQL设置修改以下内容:
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'booksDB','USER': '您的MySQL用户名','PASSWORD': '您的MySQL密码','HOST': 'localhost','POST': 3306,'OPTIONS': {'init_command': "SET sql_mode='STRICT_TRANS_TABLES'",},}
}
3. 数据导入
有两种方式可以导入数据:
3.1 使用预先准备的SQL文件(推荐)
使用MySQL客户端或命令行工具导入booksdb.sql文件:
mysql -u 用户名 -p booksdb < booksdb.sql
或者使用MySQL管理工具(如Navicat、MySQL Workbench等)导入SQL文件。
3.2 自定义数据(可选)
如果想使用自己的数据,可以按照以下步骤操作:
3.2.1 数据库同步
cd djangoPreject
python manage.py makemigrations
python manage.py migrate
如果需要自定义数据,请调用 reptile.py 爬虫文件,其中 max_page 是每个分类最大采集页数。爬虫结果会写入 data.csv 文件(如果采集多次记得备份,因为每次调用爬虫会覆盖)
爬取数据以后,需要调用 clean.py 数据清洗文件,会生成一个 clean_data.csv 文件,代码中调用清洗后的文件存入数据库(需要修改数据库相关的内容)
复制 booksdb.sql 中的文件内容运行。(不需要爬虫和数据清洗可以直接执行)
3.2.2 运行爬虫收集数据
python reptile.py
爬虫会将数据保存到data.csv文件。注意,每次运行爬虫会覆盖之前的data.csv文件,如需保留请提前备份。
3.2.3 清洗数据
python clean.py
此脚本会读取data.csv,处理后生成clean_data.csv文件。
3.2.4 修改数据库连接信息
编辑clean.py文件,找到create_engine配置部分,修改为您的数据库信息:
engine = create_engine('mysql+pymysql://用户名:密码@localhost:3306/booksdb?charset=utf8')
4. 创建管理员账户
cd djangoPreject
python manage.py createsuperuser
按照提示输入用户名、邮箱和密码,创建管理员账户。
5. 启动项目
cd djangoPreject
python manage.py runserver
此时,Django开发服务器会在本地8000端口启动。
6. 访问系统
- 前台首页:http://127.0.0.1:8000/
- 后台管理:http://127.0.0.1:8000/admin
在后台管理界面使用刚才创建的管理员账户登录。
总结
图书分析大屏展示系统是一个功能完善、界面美观的Web应用,集成了数据采集、清洗、分析和可视化等多种功能。该系统采用Django+MySQL技术栈,具有良好的扩展性和维护性。通过本教程,您可以轻松部署和运行该系统,并根据需求进行二次开发和功能扩展。
无论是作为毕业设计、课程设计还是练习项目,本系统都能帮助您理解并实践Web开发、数据处理和可视化的相关知识,提升您的技术能力和项目经验。





