
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是手写数字识别
2、为什么选择 MNIST 数据集
二、环境准备与库依赖
1、Python 和 PyTorch 环境说明
2、安装所需库(torch, torchvision, matplotlib)
三、编写代码
1、加载 MNIST 数据集
2、定义 CNN 模型
3、训练模型
4、测试模型
6、效果展示(可选)
四、本地测试
1、图片准备
2、运行测试
一、引言
1、什么是手写数字识别
✨ 手写数字识别:让计算机读懂你的手写数字! ✨
你有没有想过,为什么手机上的相机能识别你拍的数字,或者为什么一些网站能够自动识别你手写的验证码?其实,这就是手写数字识别技术在背后默默工作的结果。📝🔍
📚 什么是手写数字识别?
手写数字识别就是通过计算机技术,让机器能够识别你手写的数字(0~9)。这不仅是让计算机看懂你的手写文字,更是深度学习在日常生活中的一种应用。想象一下,当你在填写表格、签名或者填写快递单时,计算机能够自动识别你写的数字而不需要人工干预,节省时间、提高效率!💼
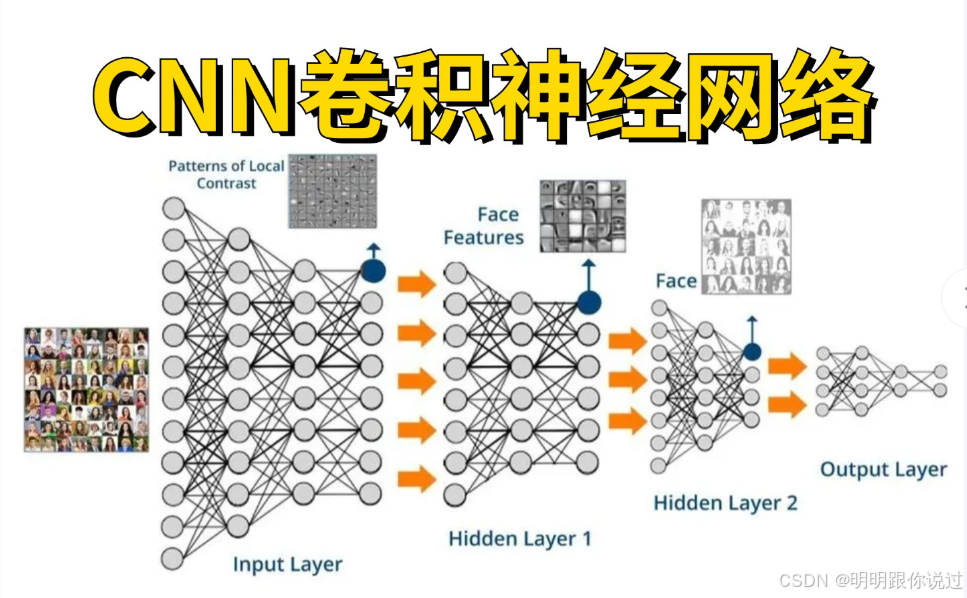
2、为什么选择 MNIST 数据集
MNIST(Modified National Institute of Standards and Technology)数据集是深度学习和计算机视觉领域中最经典、最常用的一个数据集。它由 70,000 张手写数字的图像组成,其中 60,000 张用于训练,10,000 张用于测试。每张图像是 28x28 像素的灰度图(黑白图),每个图像都对应一个数字标签(0 到 9)。
1. 简单易懂的入门数据集 📚
MNIST 是机器学习和深度学习领域中的经典入门数据集。对于初学者来说,它非常适合用来学习模型训练和测试。数据集的结构非常简单,数据量也适中,不会让你一开始就陷入复杂的细节和调参的困扰。👶💻
-
图像大小:每张图片只有 28x28 像素,计算量相对较小。
-
标签清晰:每个图像都有明确的数字标签,0 到 9 之间。
2. 数据集标注清晰 🏷️
MNIST 中的每张手写数字图片都有一个明确的标签,这意味着每张图像都知道它代表的是哪个数字(0 到 9)。这种清晰的标注使得我们可以轻松地进行监督学习(Supervised Learning)。监督学习的核心就是通过给定的输入和输出对来训练模型,让模型学会从输入图像中推测正确的输出标签。

二、环境准备与库依赖
1、Python 和 PyTorch 环境说明
🐍 安装 Python
Python 是当前最流行的编程语言之一,尤其在数据科学和机器学习领域中应用广泛。为了使用 PyTorch,我们首先需要安装 Python。下面是安装 Python 的步骤:
-
Windows 用户:
-
访问 Python 官网 下载最新版本的 Python 安装包。
-
在安装过程中,确保勾选 “Add Python to PATH” 选项,以便在命令行中直接使用 Python。
-
完成安装后,可以通过命令行输入
python --version来验证安装是否成功。
-
-
macOS/Linux 用户:
-
macOS 和大部分 Linux 发行版已经预装了 Python。你可以在终端中运行
python3 --version来检查是否已经安装了 Python。 -
如果没有安装,你可以使用 Homebrew(macOS)或包管理工具(如 apt、yum)进行安装。
-
下文示例代码的python版本为:3.12
🔥 安装 PyTorch
PyTorch 是一个深度学习框架,它提供了强大的神经网络构建和训练功能。安装 PyTorch 的步骤如下:
CPU 版本:
pip install torch torchvision torchaudioGPU 版本(支持 CUDA 11.3):
pip install torch torchvision torchaudio cudatoolkit=11.3
2、安装所需库(torch, torchvision, matplotlib)
执行以下命令安装本次实验所需的库
pip install torch torchvision matplotlib三、编写代码
1、加载 MNIST 数据集
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 图像预处理
transform = transforms.Compose([transforms.ToTensor(), # 转为张量transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])# 下载并加载训练集和测试集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)-
torch:PyTorch 的核心库,包含张量(Tensor)、神经网络等功能。 -
torchvision.datasets:包含一些常用的数据集(如 MNIST、CIFAR10),用于快速测试。 -
torchvision.transforms:用于对图像进行预处理(如转换为张量、标准化等)。 -
DataLoader:用于批量加载数据,并在训练中进行迭代。
transforms.Compose([...]) 是把一系列图像预处理操作组合起来的工具。
-
transforms.ToTensor():
将图像从 PIL 格式(或 NumPy 数组)转换成 PyTorch 张量,并把像素值从 [0, 255] 映射到 [0, 1]。 -
transforms.Normalize((0.1307,), (0.3081,)):
对图像进行标准化处理:-
均值(mean)为
0.1307,标准差(std)为0.3081,这是 MNIST 数据集的平均值和标准差。 -
公式为:
(x - mean) / std,有助于模型更快收敛。
-
datasets.MNIST(...) 用来加载 MNIST 数据集,这是一组 28x28 的手写数字图片(0-9)。
-
root='./data':数据将被下载或加载到./data文件夹中。 -
train=True:表示加载的是 训练集(共 60,000 张图片)。 -
train=False:表示加载的是 测试集(共 10,000 张图片)。 -
transform=transform:指定图像的预处理方式。 -
download=True:如果本地没有数据,就自动从互联网下载。
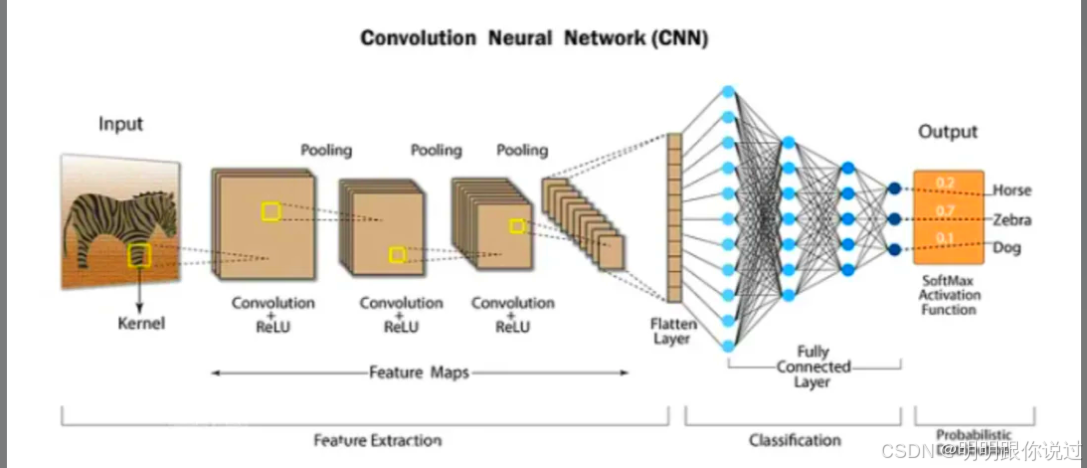
2、定义 CNN 模型
import torch.nn as nn
import torch.nn.functional as Fclass CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 输入1通道,输出32通道self.conv2 = nn.Conv2d(32, 64, kernel_size=3)self.dropout = nn.Dropout(0.25)self.fc1 = nn.Linear(9216, 128) # 计算公式: 64*(28-2*2)^2 = 9216self.fc2 = nn.Linear(128, 10) # 输出10类def forward(self, x):x = F.relu(self.conv1(x)) # [1,28,28] -> [32,26,26]x = F.relu(self.conv2(x)) # -> [64,24,24]x = F.max_pool2d(x, 2) # -> [64,12,12]x = self.dropout(x)x = x.view(-1, 64 * 12 * 12)x = F.relu(self.fc1(x))x = self.fc2(x)return F.log_softmax(x, dim=1)定义了一个新的神经网络类 CNN,它继承自 nn.Module,是 PyTorch 中所有神经网络的基础类。
这段代码定义了一个 典型的卷积神经网络结构,包含:
-
两层卷积层 + ReLU
-
一个最大池化层
-
Dropout 防过拟合
-
两层全连接层
-
输出通过 log_softmax 做分类
3、训练模型
import torch.optim as optimdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)def train(epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target) # 负对数似然损失loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}")for epoch in range(1, 6): # 训练5轮train(epoch)这段代码做的事情是:
使用 Adam 优化器,对 CNN 模型在 MNIST 手写数字数据集上进行多轮训练,每一轮遍历训练集,计算损失,反向传播并更新参数,打印每100个批次的训练进度。

4、测试模型
def test():model.eval()test_loss = 0correct = 0with torch.no_grad(): # 关闭梯度计算for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item()pred = output.argmax(dim=1)correct += pred.eq(target).sum().item()test_loss /= len(test_loader.dataset)acc = 100. * correct / len(test_loader.dataset)print(f"Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({acc:.2f}%)")test()✨ 这段代码的作用是:
✅ 在测试集上评估训练好的模型效果:
-
包括两个核心指标:
-
平均损失(Loss)
-
准确率(Accuracy)
-

6、效果展示(可选)
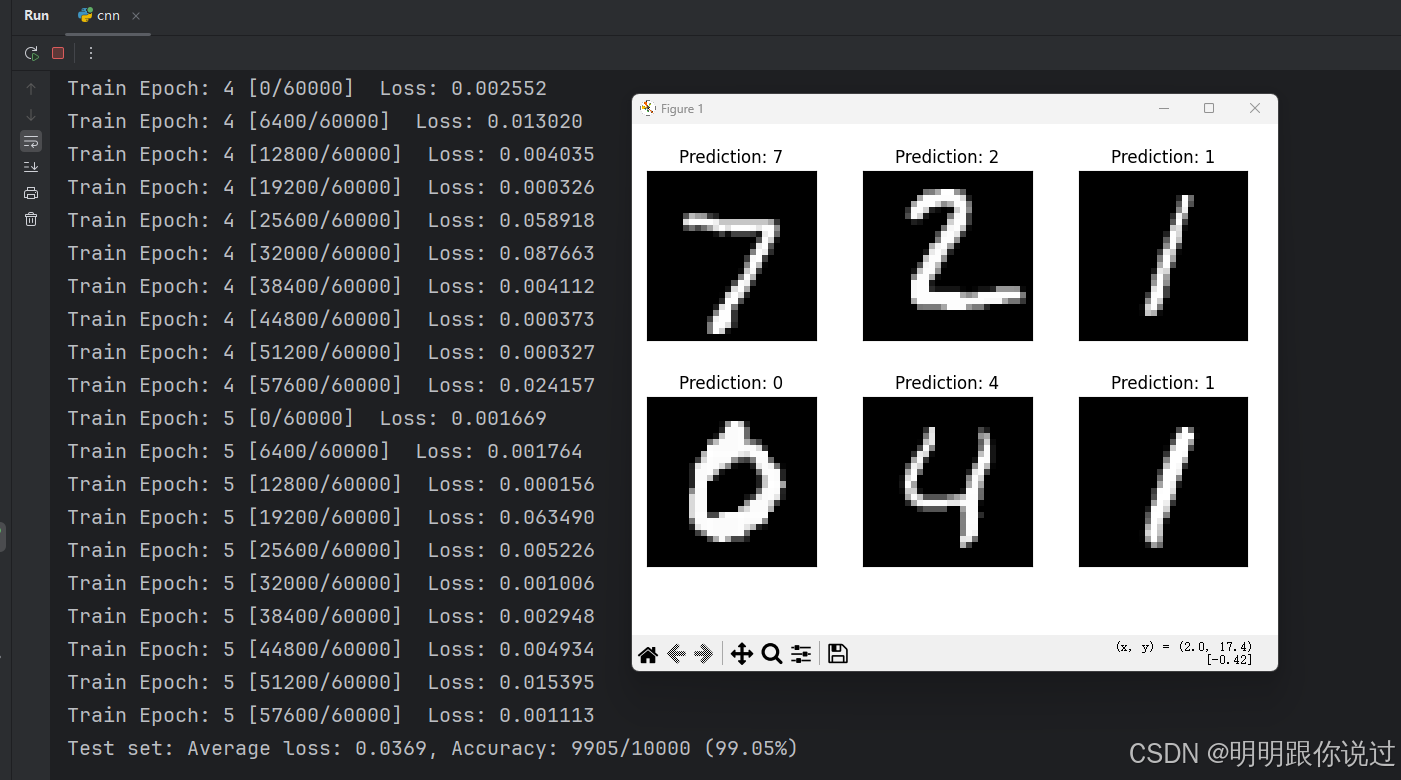
import matplotlib.pyplot as pltexamples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)with torch.no_grad():output = model(example_data.to(device))fig = plt.figure()
for i in range(6):plt.subplot(2,3,i+1)plt.tight_layout()plt.imshow(example_data[i][0], cmap='gray', interpolation='none')plt.title(f"Prediction: {output.argmax(dim=1)[i].item()}")plt.xticks([])plt.yticks([])
plt.show()🎯 这段代码的意义:
✅ 可视化模型在测试集上的预测效果:
它从测试集中拿出一小批图像,并显示前 6 张图像和对应的模型预测结果(即识别出来的数字)。
执行结果:
四、本地测试
1、图片准备
这里我们使用 Photoshop 准备一张测试图片保存到本地路径下,图片尺寸 28 X 28 像素,格式PNG

2、运行测试
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np# 图像预处理
transform = transforms.Compose([transforms.ToTensor(), # 转为张量transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])# 下载并加载训练集和测试集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 输入1通道,输出32通道self.conv2 = nn.Conv2d(32, 64, kernel_size=3)self.dropout = nn.Dropout(0.25)self.fc1 = nn.Linear(9216, 128) # 计算公式: 64*(28-2*2)^2 = 9216self.fc2 = nn.Linear(128, 10) # 输出10类def forward(self, x):x = F.relu(self.conv1(x)) # [1,28,28] -> [32,26,26]x = F.relu(self.conv2(x)) # -> [64,24,24]x = F.max_pool2d(x, 2) # -> [64,12,12]x = self.dropout(x)x = x.view(-1, 64 * 12 * 12)x = F.relu(self.fc1(x))x = self.fc2(x)return F.log_softmax(x, dim=1)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)def train(epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target) # 负对数似然损失loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}")for epoch in range(1, 6): # 训练5轮train(epoch)# 保存模型
torch.save(model.state_dict(), 'mnist_cnn.pth')def test():model.eval()test_loss = 0correct = 0with torch.no_grad(): # 关闭梯度计算for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item()pred = output.argmax(dim=1)correct += pred.eq(target).sum().item()test_loss /= len(test_loader.dataset)acc = 100. * correct / len(test_loader.dataset)print(f"Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({acc:.2f}%)")test()# 加载已经训练好的模型
model = CNN().to(device)
model.load_state_dict(torch.load('mnist_cnn.pth')) # 加载训练好的模型权重
model.eval() # 设置模型为评估模式# 图像预处理:将图片调整为28x28,转为灰度图,并进行标准化
def process_image(image_path):image = Image.open(image_path).convert('L') # 转为灰度图image = image.resize((28, 28)) # 调整大小为28x28transform = transforms.Compose([transforms.ToTensor(), # 转为张量transforms.Normalize((0.1307,), (0.3081,)) # 标准化])image = transform(image).unsqueeze(0) # 增加一个 batch 维度return image# 预测函数
def predict(image_path):image = process_image(image_path)image = image.to(device) # 移动到设备上(GPU 或 CPU)output = model(image) # 模型预测pred = output.argmax(dim=1, keepdim=True) # 获取最大概率的类别return pred.item() # 返回预测的数字# 测试手写图片
image_path = 'C:/Users/LMT/Desktop/cnn.png' # 你保存的手写数字图片路径
predicted_digit = predict(image_path)
print(f"Predicted Digit: {predicted_digit}")将 image_path 修改为测试图片所在的路径
执行后结果如下:
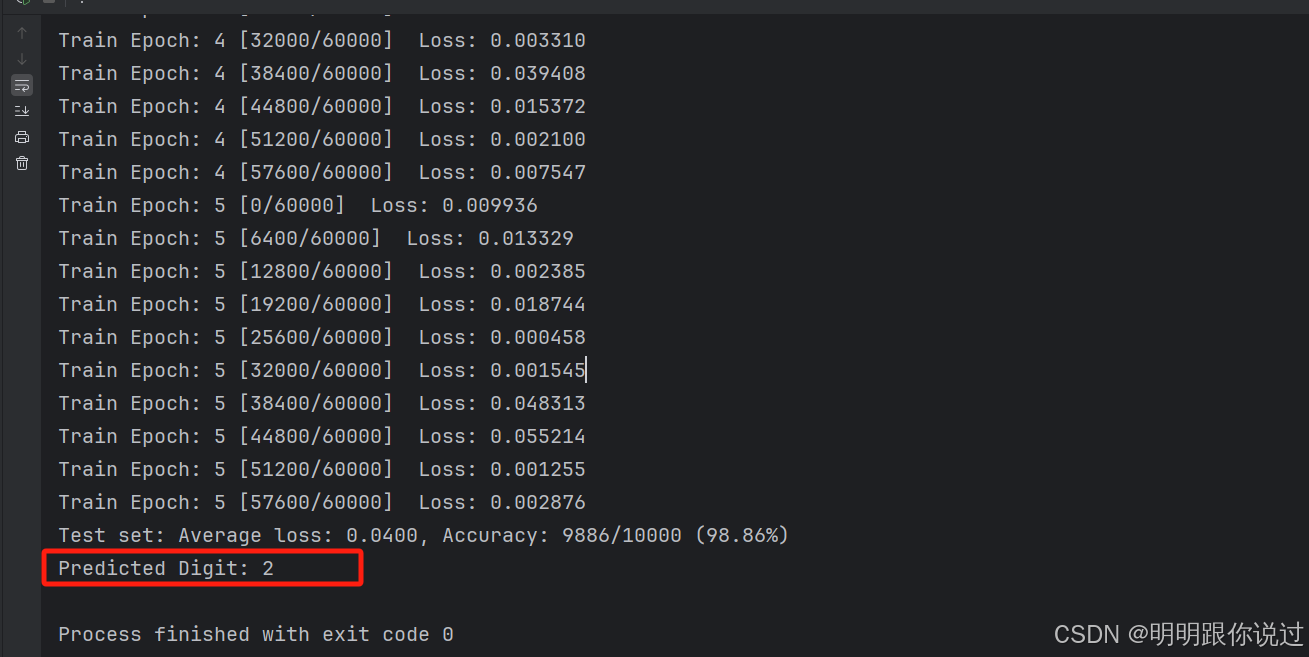
成功识别
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!





