本文为个人学习笔记,如有错误欢迎批评指正,如有侵权,请联系删除。
今日名言:
好运只是个副产品,只有当你不带任何私心杂念,单纯的去做事情时,他才会降临。

上一篇文章我们讲了C++入门的一部分内容,接下来我们继续了解,也希望你的生活有好运降临,永远向阳生长!
函数重载
函数重载的概念
在文言文中,我们经常会遇到这样一个概念:一词多义。是的,在这个让人头疼的一词多义的压迫下,我们在做题时必须通过上下文来判断一个词的真实含义。而在C++中,我们把这种现象叫作重载。
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些函数的形参列表不同,常用来处理不同的问题。其中形参列表不同指的是形参的类型不同,形参的个数不同,形参的顺序不同。
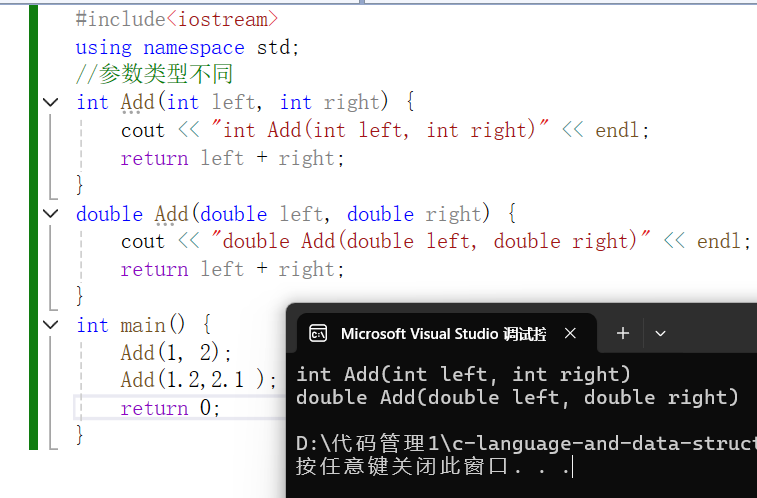
#include<iostream>
using namespace std;
//参数类型不同
int Add(int left, int right) {cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right) {cout << "double Add(double left, double right)" << endl;return left + right;
}
int main() {Add(1, 2);Add(1.2,2.1 );return 0;
} 
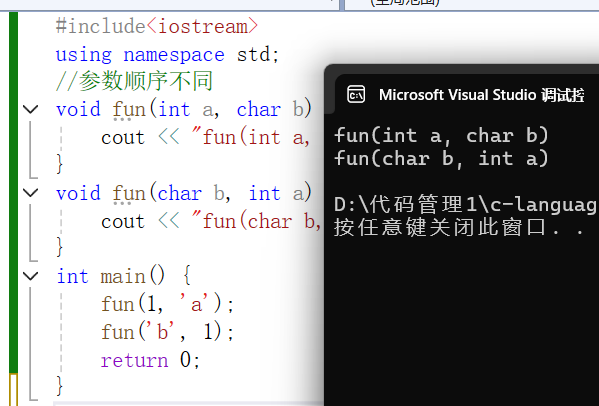
#include<iostream>
using namespace std;
//参数个数不同
void fun() {cout << "fun()" << endl;}
void fun(int a) {cout << "fun(int a)" << endl;
}
int main() {fun();fun(1);return 0;
}

还需要注意的是,返回类型不同的函数不构成重载。
很多人就会有问题啦,为什么C++中支持函数重载,而C语言不支持呢?(这里讲的不是很深,如果有兴趣的话,大家可以自行了解)
重载的原因
这是因为C++中有函数名修饰规则,只要参数不同修饰出来的名字就不一样,就可以支持重载。但是C语言就不同,在C语言中同名函数无法区分,就没办法支持重载了。
引用
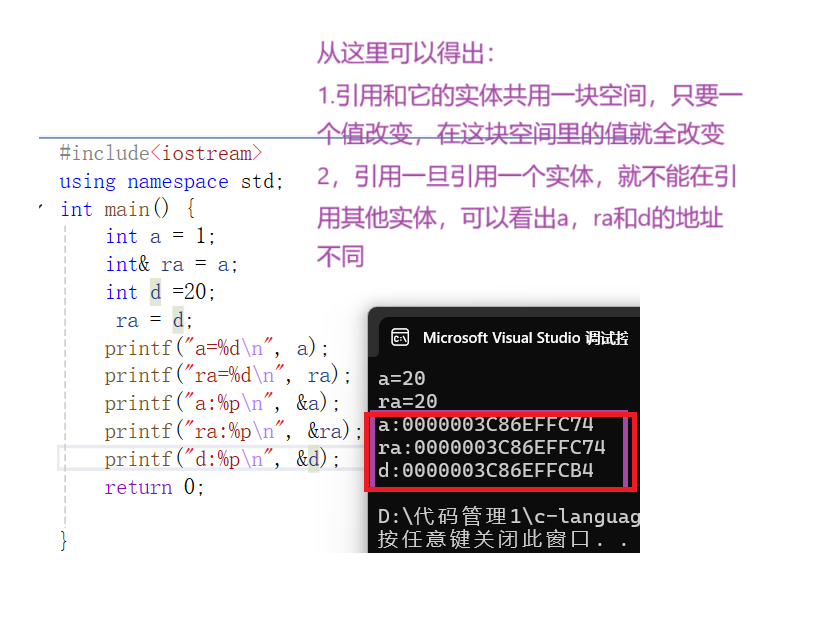
引用不是定义了一个变量,而是给一个已经存在的变量取了一个别名,也不会为引用变量开辟新的内存空间,它和所引用的变量共用一块空间。通俗点讲,引用就像一个外号,你在家里的外号和在学校里的外号可能不一样,但你还是你,不会因为外号不同又多出了一个你,你就是独一无二的!
需要注意的是引用的类型必须和引用实体是同一种类型的。
引用特性
1.引用在定义时必须初始化,必须指出所引用的变量是谁。
2.一个变量可以有多个引用,就像我们上面列举的情况,你可以有很多个别名
3.引用一旦引用一个实体,再不能再引用其它实体
常引用
首先看一下下面这段代码,你能判断出哪些是正确的吗?
void fun() {const int a = 10;int& ra = a;const int& ra = a;int b = 0;const int& rb = b;double c = 1.0;int& rc = c;const int& rc = c;
}看过之后,我们来逐个拆解吧!



所以我们可以得出结论,取别名时,权限可以缩小但是不可以放大,而权限的缩小的放大只存在于引用和指针中。
下面和我们非常熟悉的一个函数见面吧
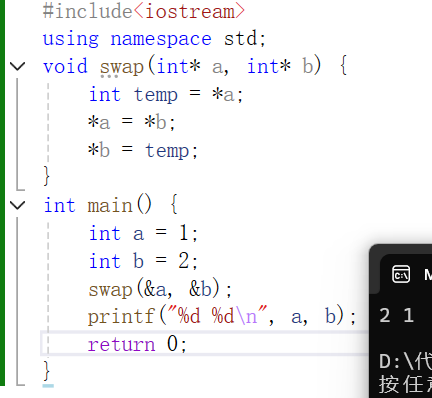
下面这段代码也可以实现相同的效果,我们来了解了解
#include<iostream>
using namespace std;
void swap(int&a, int& b) {int temp = a;a = b;b = temp;
}
int main() {int a = 1;int b = 2;swap(a, b);printf("%d %d\n", a, b);return 0;
}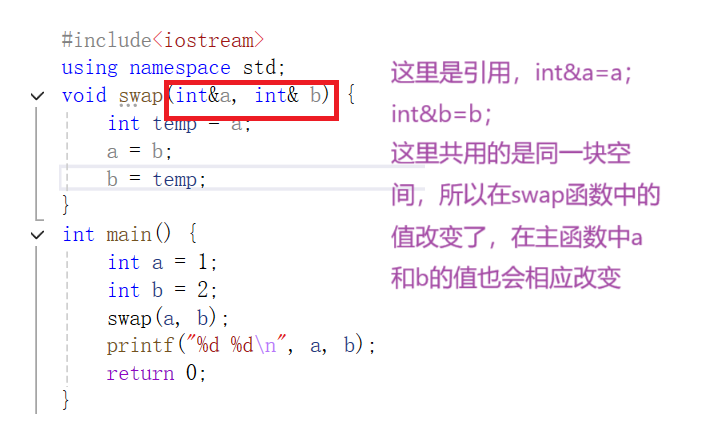
需要注意的是,这里引用和取地址完全不是一回事,引用是同一块空间。
做返回值

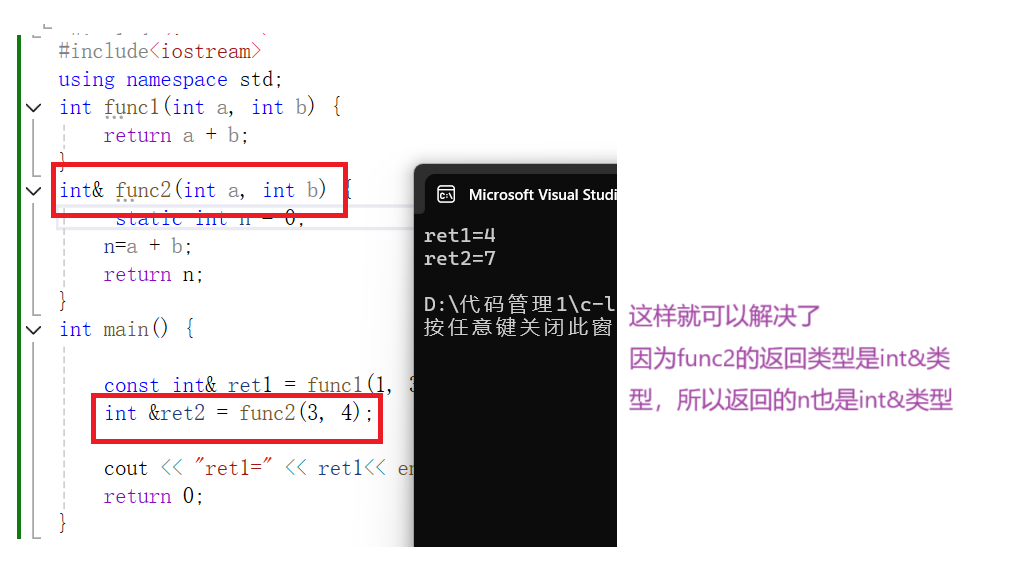
#include<iostream>
using namespace std;
int func1(int a, int b) {return a + b;
}
int& func2(int a, int b) {static int n = 0;n=a + b;return n;
}
int main() {const int& ret1 = func1(1, 3);int &ret2 = func2(3, 4);cout << "ret1=" << ret1<< endl<<"ret2="<<ret2<<endl;return 0;
}
是不是觉得引用超级方便,那么,现在我要来和你说说他的缺点啦
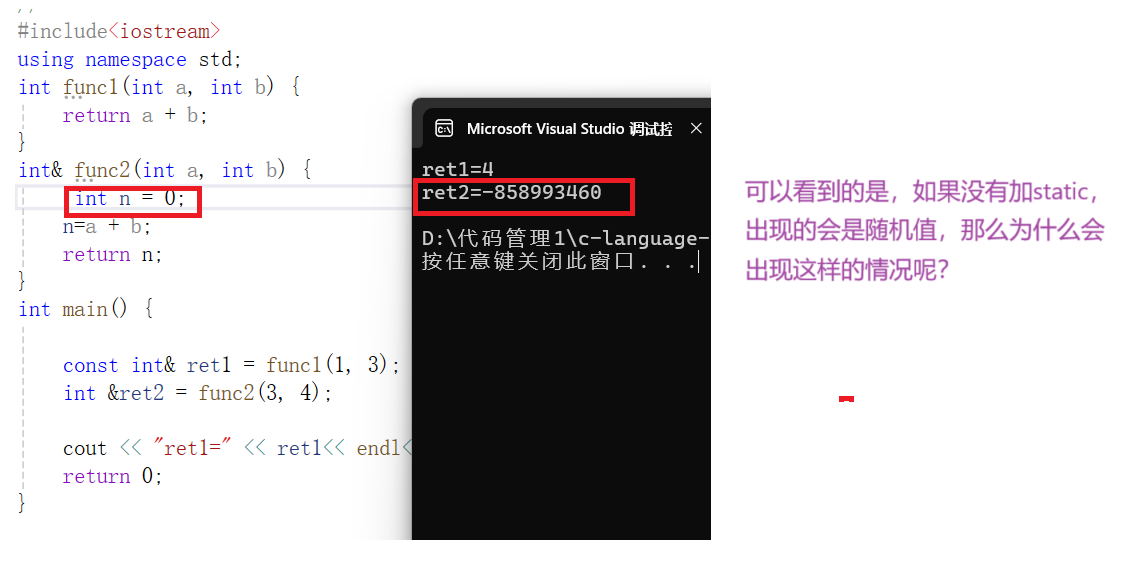
上面的函数我们是不是加了 static,那么不加static会怎么样呢?
这里需要注意的几点是
1.函数运行时,系统需要给该函数开辟独立的栈空间用来保存该函数的形参
局部变量以及一些寄存器信息
2.函数运行结束后,该函数对应的栈空间就被系统回收了
3.空间被回收指该块栈空间暂时不能被使用,但是内存还是在的,就比如说,上课要和学校申请教室,用完后教室要归还,但是并不代表归还了教室就不存在了。
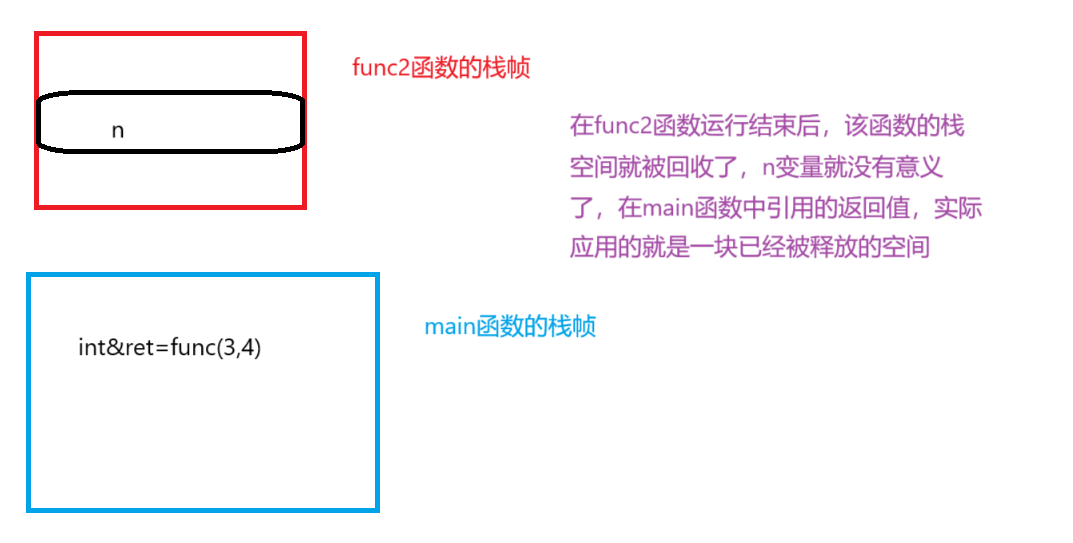
所以从这里可以得出,如果返回变量n是一个局部变量,引用返回是不安全的。也就是说 如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
为什么加了static就不会出现随机值呢
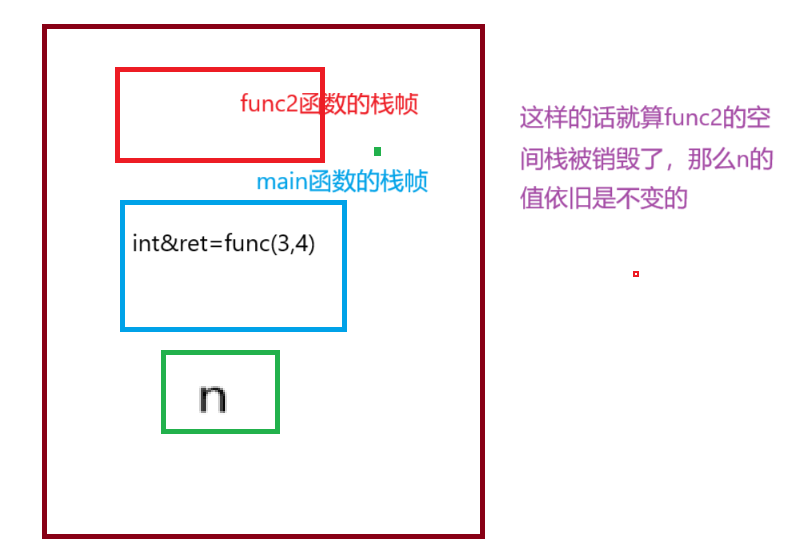
总结一下:
什么时候可以用引用返回呢?
1.当返回变量是静态变量时
2.当返回变量是全局变量时
传值、传引用的效率比较
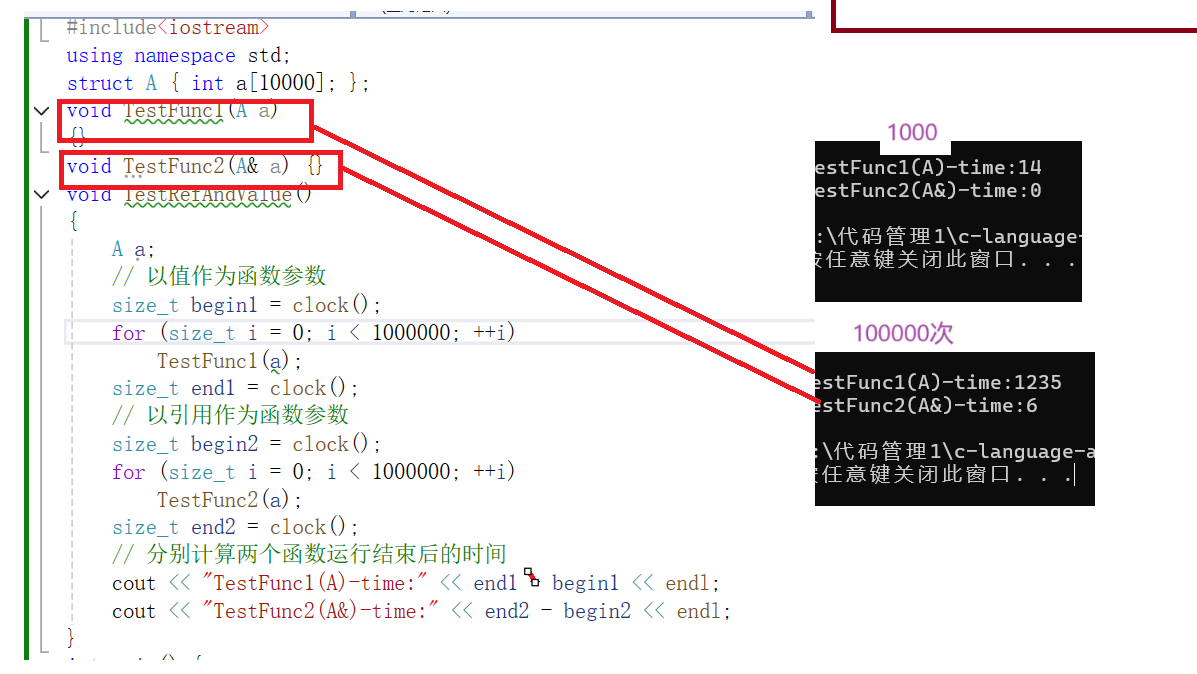
以值作为参数或返回值类型时,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时拷贝,因此用值作为参数或者返回值类型 ,效率是十分低下的,尤其是当参数或者返回值类型非常大时,效率就更加低下了。
#include <time.h>
#include<iostream>
using namespace std;
struct A { int a[10000]; };
void TestFunc1(A a)
{}
void TestFunc2(A& a) {}
void TestRefAndValue()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main() {TestRefAndValue();return 0;
}
 值和引用的作为返回值类型的性能比较
值和引用的作为返回值类型的性能比较
#include <time.h>
#include<iostream>
using namespace std;
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main() {TestReturnByRefOrValue();return 0;
}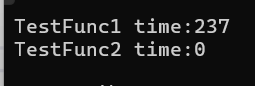
从上述代码我们可以看出传值和引用在作为传参以及返回值类型上效率相差很大
指针和引用的区别
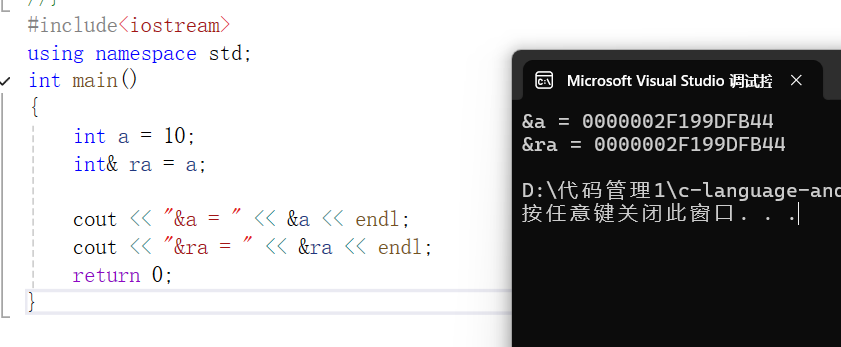
在语法概念上,引用就是一个别名,没有独立空间,和其实体共用一块空间
#include<iostream>
using namespace std;
int main()
{int a = 10;int& ra = a;cout << "&a = " << &a << endl;cout << "&ra = " << &ra << endl;return 0;
}
在底层实现上实际是有空间的,因为引用是按照指针的方式实现的
#include<iostream>
using namespace std;
int main()
{int a = 10;int& ra = a;ra = 20;int* pa = &a;*pa = 20;return 0;
}指针和引用的不同点
1.引用在概念上定义一个变量的别名,指针储存一个变量的地址
2.引用在定义上不许初始化,指针没有要求
3.引用在初始化时引用一个实体后,就不能在引用其他实体,而指针可以在任何时候 指向一个同一类型的实体
4.没有NULL引用但是有NULL指针
5.在sizeof中的含义不同,引用的的结果是引用类型的大小,但是指针始终是地址空间所占字节个数
6.引用自加即引用的实体增加1,指针自加即指针即指针向后偏移一个类型的大小
7.有多级指针,没有多级引用
8.访问实体的方式不同,指针需要显示解引用,引用编译器自己处理
9.引用比指针使用起来相对安全
auto关键字
在早期的C++中,auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量
C++11中,auto被赋予了新的含义:auto不在是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得
#include<iostream>
using namespace std;
int TestAuto()
{return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化return 0;
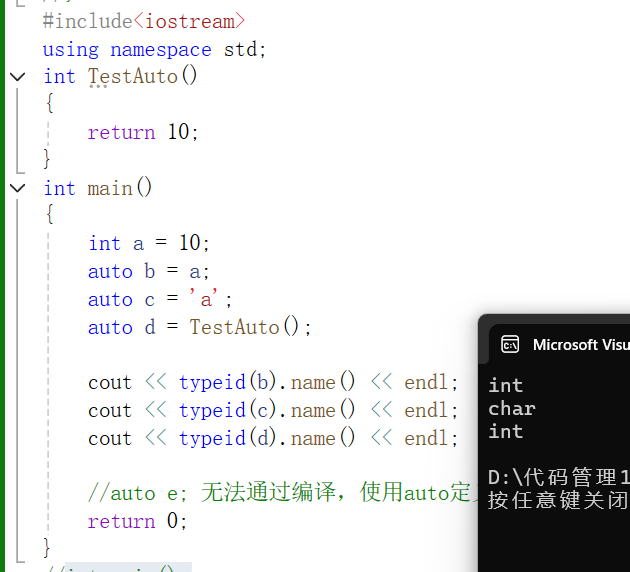
需要注意的是:
使用auto定义变量时必须对其进行初始化,在编译阶段需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的占位符,编译器在编译期会将auto替换为实际变量类型。
auto使用细则
1.auto与指针和引用结合起来使用
使用auto声明指针类型时,auto和auto * 没有区别,但是使用auto声明引用类型时则必须加&
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;return 0;
}
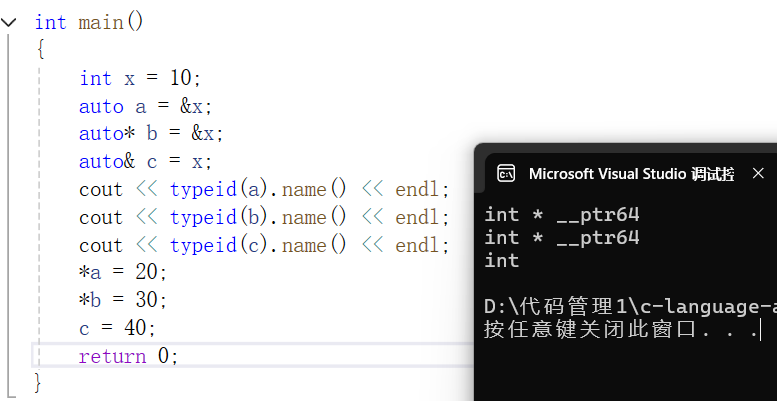
2.在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是同一个类型,否则编译器会报错,因为编译器只对第一个类型进行推导,然后用推导出来的类型定义其他变量
void TestAuto()
{auto a = 1, b = 2; auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}
auto不能推导的场景
1,auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
2.auto不能直接用来声明数组
void TestAuto()
{int a[] = {1,2,3};auto b[] = {4,5,6};
}基于范围的for循环
与C语言中不同的是,C++中的for循环更加方便
for循环后的括号由冒号(:)分为两部分,第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,与普通循环类似,可以用continue结束本次循环,也可以用break来跳出这个循环。
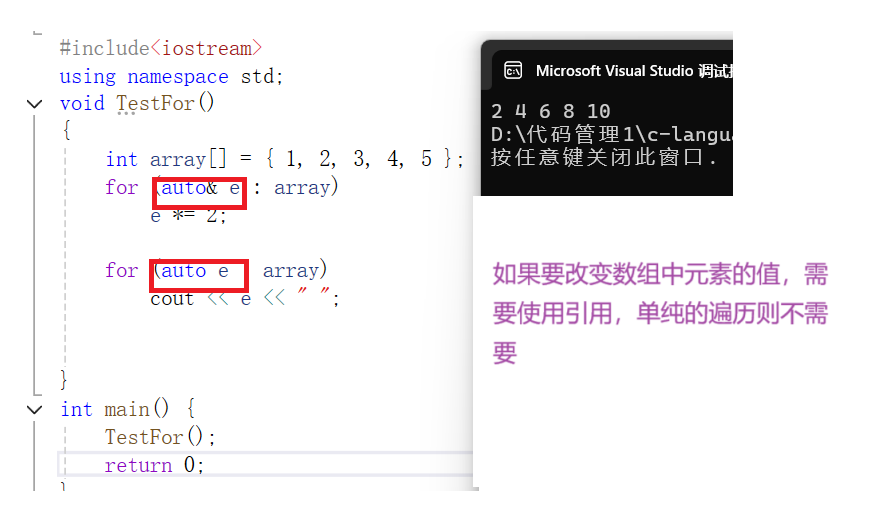
#include<iostream>
using namespace std;
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (auto& e : array)e *= 2;for (auto e : array)cout << e << " ";}
int main() {TestFor();return 0;
}
范围for使用的条件
1.for循环迭代的范围必须是确定的
对于数组而言,就是数组中的第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法
2.迭代的对象要进行++和==的操作。
)




![[吾爱出品] 【键鼠自动化工具】支持识别窗口、识图、发送文本、按键组合等](http://pic.xiahunao.cn/nshx/[吾爱出品] 【键鼠自动化工具】支持识别窗口、识图、发送文本、按键组合等)