目录
一、简介
(一)LLama-factory
(二)命令和webui
(三)使用WandB面板
(四)使用SwanLab面板
二、微调
三、推理
四、运行模型
(一)llama-factory的webui网页
(二)部署到ollama
五、遇到的问题
(一)question-complex_cot-response格式的数据集,在使用llama-factory微调的时候,参数template应该设为什么?
(二) 用8张V100进行微调的时候,per_device_train_batch_size设为2会导致显存不够用情况
(三)llama-factory中的val_size设置后,是随机抽取的验证集吗?
六、参考
一、简介
(一)LLama-factory
LLama-factory是一个开源的微调框架,旨在简化大型语言模型(LLM)的微调、评估和部署过程。它支持多种预训练模型和微调算法,提供了一套完整的工具和接口,使得用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景,如智能客服、语音识别、机器翻译等。
主要功能和特性
- 支持的模型:LLaMA-Factory支持多种大型语言模型,包括LLaMA、BLOOM、Mistral、Baichuan、Qwen、ChatGLM等。
- 微调算法:提供了多种微调算法,如增量预训练、指令监督微调、奖励模型训练、PPO训练、DPO训练和ORPO训练等。
- 运算精度与优化算法:支持32比特全参数微调、16比特冻结微调、16比特LoRA微调和基于AQLM/AWQ/GPTQ/LLM.int8的2/4/8比特QLoRA微调等多种精度选择,以及GaLore、DoRA、LongLoRA、LLaMA Pro等先进算法。
- 用户界面:LLaMA-Factory提供了简洁明了的操作界面和丰富的文档支持,使得用户能够轻松上手并快速实现模型的微调与优化。
使用场景和优势
LLaMA-Factory特别适用于研究人员和开发者,因为它简化了大型语言模型的微调、评估和部署过程。通过其用户友好的界面和丰富的功能特性,开发者可以快速适应特定任务需求,提升模型表现。
(二)命令和webui
1. 个人觉得使用命令方式更方便,配置好参数后执行命令就好。不好的地方是需要找到对应的命令修改参数。
2. webui,好处是看起来直观,不好的地方是刷新网页后,上次填写过的参数内容还得重新填写一遍,虽然有少部分记录下来,但是大部分还是得重新填写。可以设置好参数后拿到设置的参数命令,用bash进行执行。
(三)使用WandB面板
1. 在当前环境下安装:
pip install wandb
2.查看WandB的key方法:
复制网址: https://wandb.ai/authorize,打开wandb登录自己的账号,key直接弹出
3.使用方法:可以直接登录上
wandb login 输入对应的秘钥

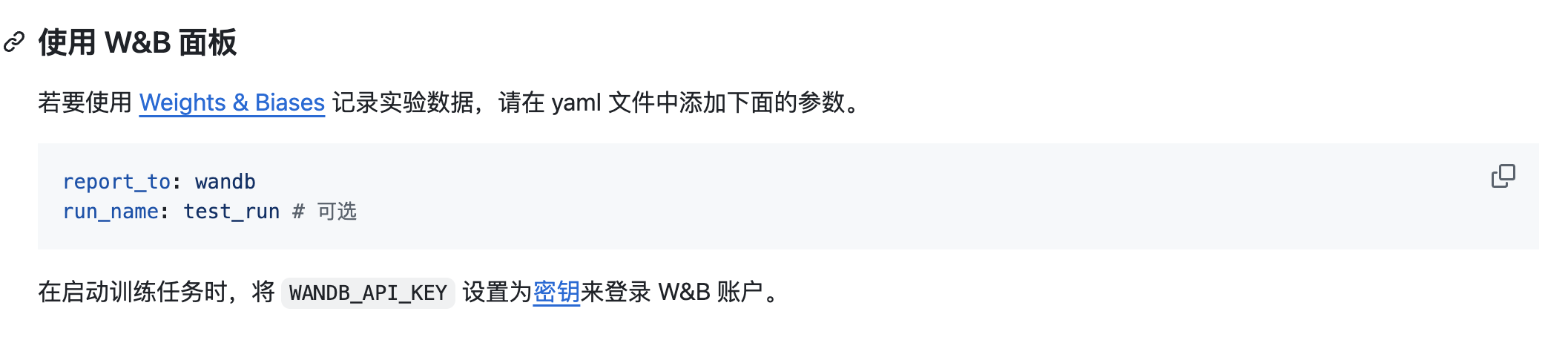
4.使用方法:也可以在yaml中配置上
 5.参考:LLama factory接入wandb面板_wandb: (1) create a w&b account wandb: (2) use an -CSDN博客
5.参考:LLama factory接入wandb面板_wandb: (1) create a w&b account wandb: (2) use an -CSDN博客
(四)使用SwanLab面板
1.在当前环境安装
pip install swanlab2.使用方法:可以直接登录上
swanlab login 输入对应的秘钥

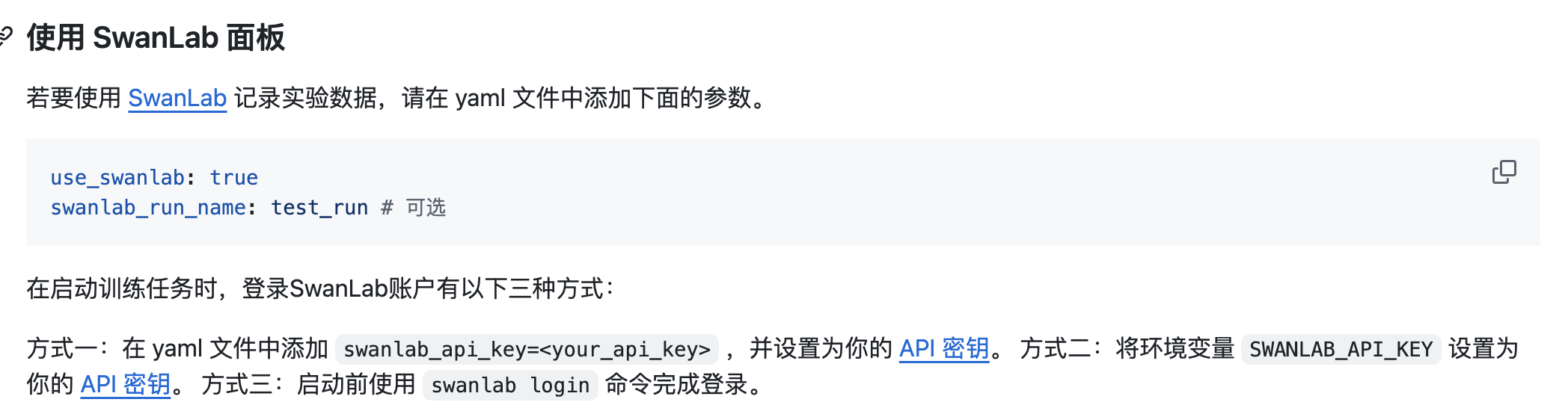
3.使用方法:也可以在yaml中配置上
二、微调
微调命令
FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 llamafactory-cli train /data/3-project/1-sxw/12-LLaMA-Factory/1-patent/train_lora/qwen2.5_32B_lora_sft_ds3.yaml三、推理
在路径LLaMA-Factory/examples/inference找到llama3_lora_sft.yaml文件,进行修改。设置模型路径和微调后保存的路径。

model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: true
finetuning_type: lora推理命令
FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 llamafactory-cli chat inference/qwen2.5_32B_lora_sft.yaml四、合并模型,并导出
(一)命令行操作
1.找到LLaMA-Factory/examples/merge_lora文件下的llama3_lora_sft.yaml进行修改。
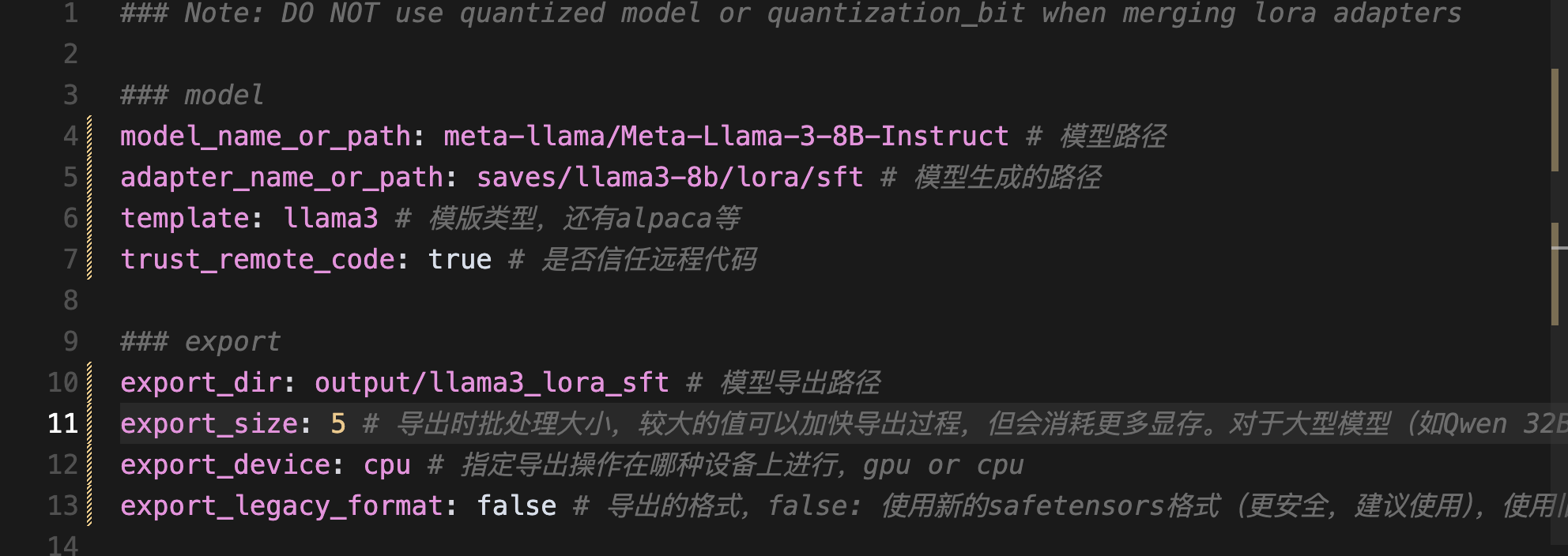
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct # 模型路径
adapter_name_or_path: saves/llama3-8b/lora/sft # 模型生成的路径
template: llama3 # 模版类型,还有alpaca等
trust_remote_code: true # 是否信任远程代码### export
export_dir: output/llama3_lora_sft # 模型导出路径
export_size: 5 # 导出时批处理大小,较大的值可以加快导出过程,但会消耗更多显存。对于大型模型(如Qwen 32B),建议使用较小的值(比如5)以避免显存不足。
export_device: cpu # 指定导出操作在哪种设备上进行,gpu or cpu
export_legacy_format: false # 导出的格式,false: 使用新的safetensors格式(更安全,建议使用),使用旧的PyTorch格式(.bin文件,兼容性更好)
2.导出命令
llamafactory-cli export merge_lora/llama3_lora_sft.yaml 3.导出到指定的路径下,显示如下
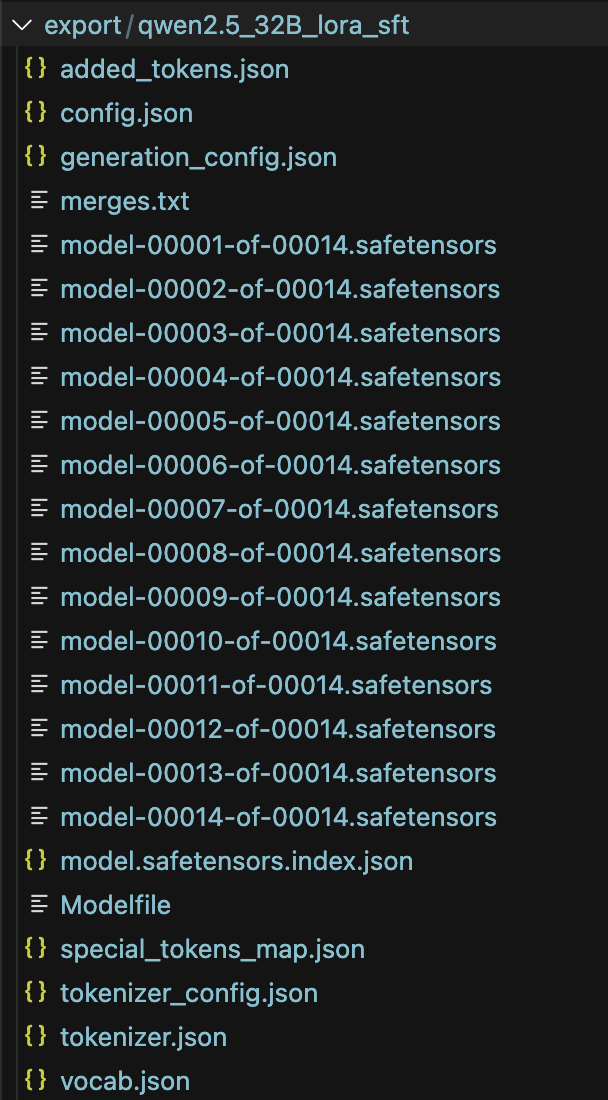
四、运行模型
(一)llama-factory的webui网页
可以使用webui网页上,加载导出的模型进行测试
(二)部署到ollama
0.ollama的安装部署参考链接:在Linux系统安装Ollama两种方法:自动安装和手动安装,并配置自启动服务 _linux 安装ollama-CSDN博客
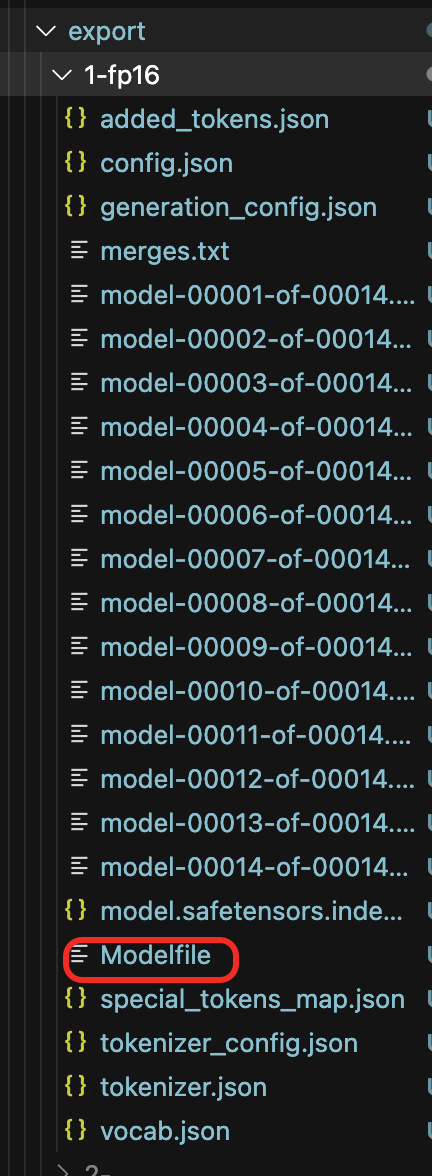
1.使用llama-factory导出时提供的Modelfile,在导出的目录下
2.执行命令
cd 生成的路径
ollama create 新模型名 -f Modelfile3.遇到问题
(1) 提示:写入ollama模型文件blobs的时候被拒绝
open /data/4-ollama-models/blobs/sha256-2145686602: permission denied 应该是权限不足,修改权限:
sudo chmod 750 /data/4-ollama-models/ •解释:-R 表示递归修改目录下所有子文件和目录的权限;750 表示所有者有读、写、执行权限,所属组有
读和执行权限,其他用户无权限。
注意:如果仍报错,可临时放宽权限为 777(需谨慎,仅用于测试)
我的权限不行,主要是因为分组权限的问题,所以切换到分组设定的用户下执行就可以了。
(2) 提示:写入ollama模型文件manifests/registry.ollama.ai/library被拒绝
Error: open /data/4-ollama-models/manifests/registry.ollama.ai/library/qwen2.5/32b_instruct_F01C_QwQ_lora8_bp16: permission denied4.成功在ollama构建模型
五、遇到的问题
(一)question-complex_cot-response格式的数据集,在使用llama-factory微调的时候,参数template应该设为什么?
对于 question-complex_cot-response 格式的数据集,LLaMA-Factory 中没有直接对应的内置模板。您有以下几种选择:
1. 创建自定义模板(推荐)
这是最准确的方法,允许您精确控制输入输出格式:
(1)在 LLaMA-Factory 的 templates 目录中创建新文件:
mkdir -p /LLaMA-Factory/src/llamafactory/templates/custom(2)创建自定义模板文件 cot.json:
nano /LLaMA-Factory/src/llamafactory/templates/custom/cot.json(3)添加以下内容:
Apply to qwq_32B_lora...{"prompt": "以下是一个问题:\n\n{question}\n\n请通过一步步思考来解决这个问题。","completion": "思考过程:\n{complex_cot}\n\n最终答案:\n{response}","chat_template": [{"role": "user","content": "以下是一个问题:\n\n{question}\n\n请通过一步步思考来解决这个问题。"},{"role": "assistant", "content": "思考过程:\n{complex_cot}\n\n最终答案:\n{response}"}],"system_message": "你是一个擅长通过一步一步分析解决复杂问题的助手。"}(4)在训练yaml配置中使用:
template: custom/cot2. 使用数据集预处理脚本
如果不想创建自定义模板,可以预处理数据集以适应现有模板:
import json# 读取原始数据
with open('/path/to/your/cot/dataset.json', 'r') as f:data = json.load(f)# 转换为alpaca格式
alpaca_data = []
for item in data:alpaca_item = {"instruction": item["question"],"input": "","output": f"思考过程:\n{item['complex_cot']}\n\n最终答案:\n{item['response']}"}alpaca_data.append(alpaca_item)# 保存为新文件
with open('/path/to/your/alpaca_format_dataset.json', 'w') as f:json.dump(alpaca_data, f, indent=2, ensure_ascii=False)然后在配置中使用:
template: alpaca3. 使用sharegpt模板(如果您的模型支持聊天格式)
# 将数据转换为sharegpt格式
sharegpt_data = []
for item in data:sharegpt_item = {"conversations": [{"role": "user", "content": item["question"]},{"role": "assistant", "content": f"思考过程:\n{item['complex_cot']}\n\n最终答案:\n{item['response']}"}]}sharegpt_data.append(sharegpt_item)# 保存为新文件
with open('/path/to/your/sharegpt_format_dataset.json', 'w') as f:json.dump(sharegpt_data, f, indent=2, ensure_ascii=False)然后在配置中使用:
template: sharegpt哪种方法最好?
推荐方法1(创建自定义模板),因为:
- 保持原始数据格式,无需转换
- 更精确地控制模板格式
- 更好地适应CoT训练的特定需求
如果您使用Qwen、Llama或Mistral等聊天模型,方法3(sharegpt)也是一个好选择,特别是当您想让模型学习作为对话助手的行为时。
(二) 用8张V100进行微调的时候,per_device_train_batch_size设为2会导致显存不够用情况
1. 提示:
[WARNING] [stage3.py:2139:step] 3 pytorch allocator cache flushes since last step. this happens when there is high memory pressure and is detrimental to performance. if this is happening frequently consider adjusting settings to reduce memory consumption. If you are unable to make the cache flushes go away consider adding get_accelerator().empty_cache() calls in your training loop to ensure that all ranks flush their caches at the same time2. 解决方案:
这个警告表明在训练过程中出现了频繁的PyTorch分配器缓存刷新,这是由于高内存压力导致的。虽然训练可以继续,但会对性能产生负面影响。
3. 问题解释
当GPU内存压力大时,PyTorch会自动刷新其分配器缓存以释放内存空间。这个操作会导致显著的性能下降,因为:
- 缓存刷新会中断训练流程
- 重新分配内存比重用缓存中的内存慢得多
- 不同GPU上的缓存刷新可能不同步,导致分布式训练效率下降
4. 是否可以不处理?
可以不处理,但不推荐:
- 训练不会停止,模型最终仍会训练完成
- 但训练速度会显著降低(可能慢20-40%)
- 分布式训练可能变得不稳定
5.解决方案
- 减少内存压力 (最佳选择):
# 修改配置文件per_device_train_batch_size: 1 # 降低单卡批次大小gradient_accumulation_steps: 16 # 增加梯度累积步数2. 添加显式缓存清理:
如果无法减少批量大小,可以在训练循环中添加定期的缓存清理。创建一个自定义训练脚本:
# custom_trainer.pyfrom llamafactory.train import trainfrom torch.cuda import empty_cacheimport torch.distributed as distimport time# 在每个epoch结束后清空缓存的钩子函数def cache_cleanup_hook(trainer, *args, **kwargs):if dist.is_initialized():dist.barrier() # 确保所有GPU同步empty_cache()time.sleep(1) # 给系统一点时间# 修改训练函数def custom_train():train(post_step_callback=cache_cleanup_hook)if __name__ == "__main__":custom_train()使用此脚本:
FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python custom_trainer.py /LLaMA-Factory/1-patent/3-qwq_32B_lora_sft_cot_QwQ/1-lora8_fp16/train_lora/qwq_32B_lora_sft_ds3.yaml3. 更简单的解决方案 - 修改环境变量:
qwq_32B_lora_sft_ds3.yaml
# 添加到训练命令前export PYTORCH_CUDA_ALLOC_CONF="max_split_size_mb:128"# 然后运行训练FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 llamafactory-cli train /data/3-project/1-sxw/12-LLaMA-Factory/1-patent/3-qwq_32B_lora_sft_cot_F01C_QwQ_959/1-lora8_fp16/train_lora/qwq_32B_lora_sft_ds3.yaml4. 推荐操作
最简单的解决方案是方案1,直接在配置文件中降低每个设备的批次大小:
per_device_train_batch_size: 1gradient_accumulation_steps: 16 # 或者更高这样既能维持有效批量大小,又能减轻内存压力,无需修改代码或添加自定义脚本。
如果训练已经进行了很久,不想中断,则可以保持不变,接受性能损失。但对于新的训练任务,建议采用上述优化措施。
5.结论:
(1)batchsize=per_device_train_batch_size*radient_accumulation_steps*GPU卡数
8张V100,bachsize最多设为128,并且设为16后会报错pytorch会一直清理缓存,每张gpu利用率达到95%。batchsize设为64后,就还好,每张gpu利用率达到56%。
(三)llama-factory中的val_size设置后,是随机抽取的验证集吗?
在LLaMA-Factory中,val_size设置后,验证集是通过随机抽取生成的。具体来说,当你在数据集准备阶段设置val_size参数时,LLaMA-Factory会从数据集中随机抽取一定比例的数据作为验证集,用于模型训练过程中的评估。
验证集的作用
验证集的主要作用是在模型训练过程中评估模型的性能,帮助调整超参数和防止过拟合。通过在验证集上的表现,开发者可以了解模型的泛化能力,并在必要时进行模型调整。
验证集的生成方式
LLaMA-Factory通过随机抽取的方式生成验证集。具体步骤如下:
- 在数据集准备阶段,设置
val_size参数,指定验证集的比例。 - LLaMA-Factory从数据集中随机抽取指定比例的数据作为验证集。
- 验证集中的数据用于模型训练过程中的评估和调参。
六、参考
1.使用LLaMA-Factory微调Llama3大模型_llamafactory官网-CSDN博客
2. lora微调大模型Qwen2.5_32B_qwen2.5 lora-CSDN博客
3.使用LLaMA Factory微调导出模型,并用ollama运行,用open webui使用该模型_llama factory 微调后的模型 ollama-CSDN博客


--okhttp的网络通信的使用)


凹凸缺陷检测)
