2024 年 7 月 3 日,上海人工智能实验室与商汤科技联合香港中文大学和复旦大学正式发布新一代大语言模型书⽣·浦语2.5(InternLM2.5)。相比上一代模型,InternLM2.5 有三项突出亮点:
-
推理能力大幅提升,领先于国内外同量级开源模型,在部分维度上甚至超越十倍量级的 Llama3-70B;
-
支持 1M tokens 上下文,能够处理百万字长文;
-
具有强大的自主规划和工具调用能力,比如可以针对复杂问题,搜索上百个网页并进行整合分析。
InternLM2.5-7B 模型即日起开源可用,更大和更小的模型也将在近期发布开源。上海人工智能实验室秉持“以持续的高质量开源赋能创新”理念,在为社区始终如一地提供高质量开源模型的同时,也将继续坚持免费商用授权。
GitHub 链接:GitHub - InternLM/InternLM: Official release of InternLM2.5 7B base and chat models. 1M context support HuggingFace 模型:https://huggingface.co/internlm
书生·浦语主页:书生·浦语
性能加速器:合成数据+模型飞轮
随着大模型的快速发展,人类积累的数据也在快速消耗,如何高效地提升模型性能成为了当前面临的重大挑战。为此,我们研发了新的合成数据和模型飞轮,一方面通过合成数据弥补领域高质量数据的不足,另一方面通过模型的自我迭代不断完成数据提升和缺陷修复,从而大大加快了 InternLM2.5 的迭代。
针对不同的数据特点,我们制定了多种的数据合成技术方案,保障不同类型合成数据的质量,包括基于规则的数据构造,基于模型的数据扩充,和基于反馈的数据生成。
在研发过程中,模型本身也被持续不断地应用于模型的迭代。我们基于当前模型构建了多智能体用于数据的筛选、评估和标注,大幅提升了数据质量和多样性。同时也使用模型进行新语料的生产和精炼,让模型能够随着训练过程对发现的问题进行修复。
领先的推理能力
强大的推理能力是大模型通向通用人工智能的重要基础,InternLM2.5 将推理能力作为模型最核心的能力进行优化,为复杂场景的应用落地提供了良好的基础。
基于司南 OpenCompass 开源评测框架,研究团队使用统一可复现的评测方法在多个推理能力权威评测集上进行了评测。相比上一代模型,InternLM2.5 在多个推理能力权威评测集上实现了大幅性能提升,尤其在由竞赛问题构成的数学评测集 MATH 上更是提升100%,以 7B 参数达到了 60% 的准确率(达到 GPT-4 Turbo 1106 版本的水平),充分展示了模型在数学推理上的优异成绩。
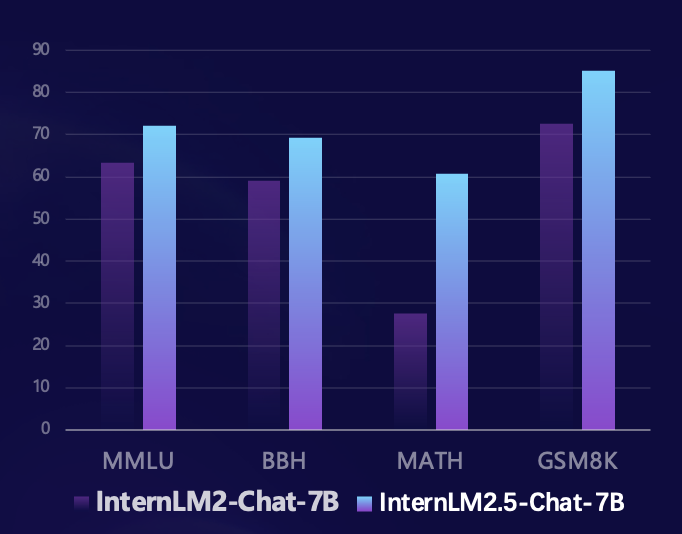
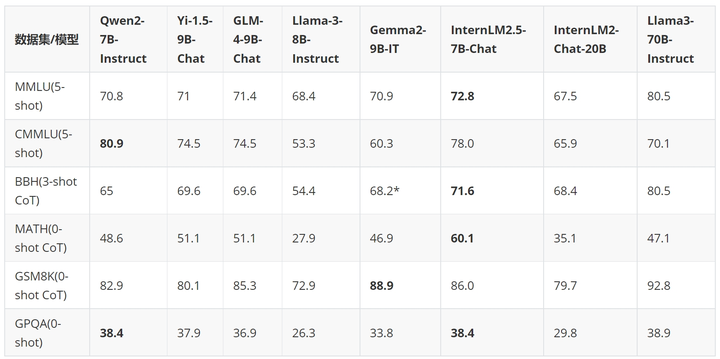
在过去的几个月里,大模型开源社区快速发展,涌现了一大批优秀的模型。和国内外最新的开源模型相比,InternLM2.5-7B-Chat 在绝大部分推理评测集上领先于同量级模型,相比前代模型更是实现了跨量级的性能超越,在部分维度上甚至赶超了十倍体量的 Llama3-70B-Instruct。
我们通过一个例子来展示 InternLM2.5 优秀的推理能力。
User:| 排名 | 国家 / 地区 | 金牌 | 银牌 | 铜牌 | 总计 |
|------|---------------------|------|------|------|------|
| 1 | 美国(USA) | 39 | 41 | 33 | 113 |
| 2 | 中国(CHN) | 38 | 32 | 19 | 89 |
| 3 | 日本(JPN) | 27 | 14 | 17 | 58 |
| 4 | 英国(GBR) | 22 | 20 | 22 | 64 |
| 5 | 俄罗斯奥林匹克委员会(ROC)| 20 | 28 | 23 | 71 |
| 6 | 澳大利亚(AUS) | 17 | 7 | 22 | 46 |
| 7 | 荷兰(NED) | 10 | 12 | 14 | 36 |
| 8 | 法国(FRA) | 10 | 12 | 11 | 33 |
| 9 | 德国(GER) | 10 | 11 | 16 | 37 |
| 10 | 意大利(ITA) | 10 | 10 | 20 | 40 |根据提供的2020年东京奥运会奖牌榜部分信息,请回答列表中属于北美洲国家和大洋洲国家的银牌奖牌和是多少?Assistant: 根据提供的信息,北美洲和大洋洲国家的银牌奖牌数如下:北美洲国家:
- 美国(USA):41枚银牌
- 加拿大(未在列表中,但作为北美洲国家,其银牌数未提供)大洋洲国家:
- 澳大利亚(AUS):7枚银牌因此,北美洲和大洋洲国家的银牌总数为:
41(美国)+ 7(澳大利亚)= 48枚银牌。User:根据我提供的信息,现在请你在排名前3的国家中,将金、银、铜牌每一项都至少有15枚的所有国家筛选出来,绘制成表格,请一步步思考来完成这个问题Assistant:好的,让我们一步步来解决这个问题。首先,我们需要确定排名前3的国家,根据您提供的信息,这些国家是美国、中国和日本。接下来,我们需要筛选出这些国家中,金、银、铜牌每一项都至少有15枚的国家。让我们逐一检查这些国家:1. 美国(USA):金牌39枚,银牌41枚,铜牌33枚。所有奖牌数都超过了15枚,因此美国符合条件。2. 中国(CHN):金牌38枚,银牌32枚,铜牌19枚。所有奖牌数都超过了15枚,因此中国符合条件。3. 日本(JPN):金牌27枚,银牌14枚,铜牌17枚。只有金牌数超过了15枚,因此日本不符合条件。因此,只有美国和中国符合条件。现在我们可以将这些信息绘制成表格:| 排名 | 国家 / 地区 | 金牌 | 银牌 | 铜牌 | 总计 |
|------|---------------------|------|------|------|------|
| 1 | 美国(USA) | 39 | 41 | 33 | 113 |
| 2 | 中国(CHN) | 38 | 32 | 19 | 89 |请注意,日本(JPN)虽然金牌数超过了15枚,但银牌和铜牌数没有达到要求,因此没有包含在表格中。100万 Token 长文本支持,文档对话系统全开源
在长文档理解、复杂的智能体交互等应用场景中,模型的上下文长度支持有着更高的要求。InternLM2.5 提出了解决方案,将上下文长度从上一代模型 InternLM2 的 200K 提升到了 1M(约合 120 万汉字),进一步释放了模型在超长文本应用上的潜力。在模型的预训练中,我们从自然语料中筛选出了 256K Token 长度的文本,同时为了避免语料类型过于单一而导致的域偏移,我们通过合成数据进行了补充,使得模型在扩展上下文的同时可以尽量保留其能力。
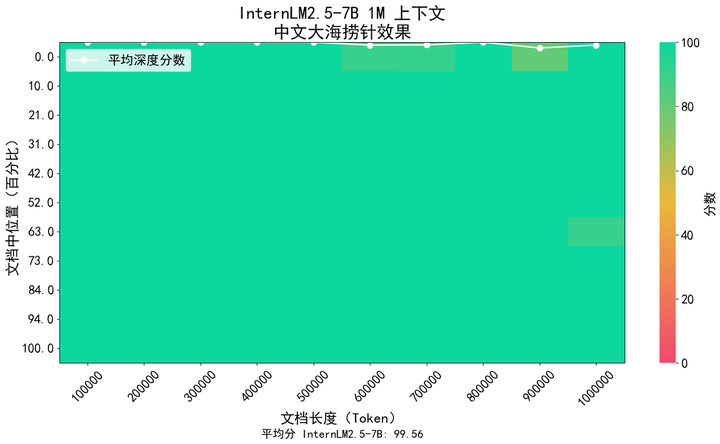
我们采用了业界流行的“大海捞针”来评估模型的长文信息召回内容,下图显示,InternLM 2.5 在 1M token 范围内实现了几乎完美的大海捞针召回,呈现了极强的长文处理能力。
除此之外,我们还使用了广泛使用的长文理解能力评测集 LongBench 来进行评估,结果显示 InternLM2.5 取得了最优的性能。
| GLM4-9B-Chat-1M | Qwen2-7B-Instruct | Yi1.5-9B-chat | InternLM2.5-7B-Chat-1M | |
| Longbench | 46.5 | 41.2 | 37.2 | 47.4 |
依托于 InternLM2.5 的长文本能力,我们开发了文档对话应用,支持用户私有化部署模型,自由上传文档进行对话。并且整个系统全链路开源,方便用户一键搭建,包括 LMDeploy 长文本推理后端支持,MinerU 多类型文档的解析转换能力,基于 Streamlit 的前端对话体验工具等。目前支持 TXT,Markdown 和 PDF 文档,后续会持续支持如 Word、PPT 等多种办公文档类型。

基于网络信息高效解决复杂问题
针对需要大规模复杂信息搜索和整合的复杂问题场景,InternLM2.5 创新性地提出了 MindSearch 多智能体框架,模拟人的思维过程,引入了任务规划、任务拆解、大规模网页搜索、多源信息归纳总结等步骤,有效地整合网络信息。其中,规划器专注于任务的规划、拆解和信息归纳,采用图结构编程的方式进行规划,并根据任务状态进行动态拓展,搜索器负责发散式搜索并总结网络搜索结果,使得整个框架能够基于上百个网页的信息进行筛选和浏览和整合。
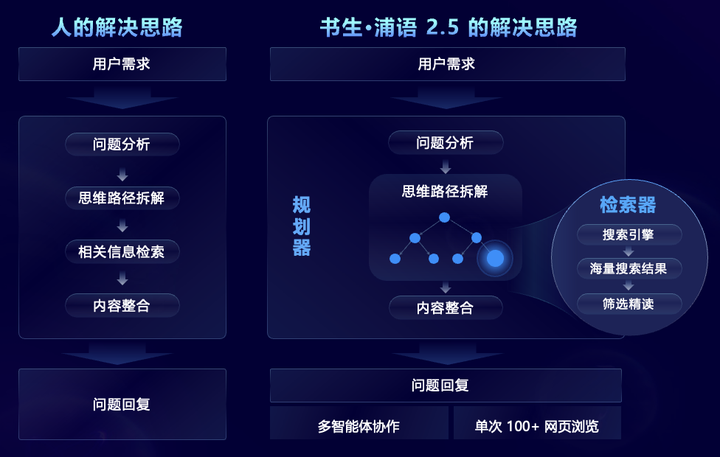
经过针对性能力增强,InternLM2.5 能够有效从上百个网页中进行信息筛选、浏览和整合,解决专业的复杂问题,将人类需要 3 小时才能完成的调研总结工作缩短到了 3 分钟。如下面的视频所示,对于多步骤的复杂问题,模型能够分析用户需求,先搜索嫦娥 6 号的技术难点、再针对每一个技术难点搜索对应的解决方案,再从任务目标、技术手段、科学成果、国际合作 4 个方面对比阿波罗 11号 登月计划,最后总结我国探月成功的贡献。
书生·浦语2.5开源,推理能力再创新标杆
拥抱更广泛的开源生态
除了开源模型,书生·浦语从去年 7 月份开始推出了面向大模型研发与应用的全链条开源工具体系,贯穿数据、预训练、微调、部署、评测、应用六大环节。这些工具让用户能够更轻松地进行大模型的创新和应用,推动大模型开源生态的繁荣发展。随着 InternLM2.5 的发布,全链条工具体系也迎来了升级,对于应用环节进行了拓展,面向不同需求提供了新的工具,包括:
-
HuixiangDou 领域知识助手(GitHub - InternLM/HuixiangDou: HuixiangDou: Overcoming Group Chat Scenarios with LLM-based Technical Assistance),专为处理群聊中的复杂技术问题而设计,适用于微信、飞书、钉钉等平台,提供完整的前后端 web、Android 及算法源码,支持工业级应用。
-
MinerU 智能数据提取工具(GitHub - opendatalab/MinerU: MinerU is a one-stop, open-source, high-quality data extraction tool,supports PDF/webpage/e-book extraction.),为多模态文档解析打造,不仅能将混合了图片、表格、公式等在内的多模态 PDF 文档精准转化为清晰、易于分析的 Markdown 格式,还能从包含广告等各种干扰信息的网页中快速解析、抽取正式内容
除了自研的全链条开源工具体系之外,InternLM2.5 积极拥抱社区,兼容广泛的社区生态项目,主流开源项目“一网打尽”。

书生大模型实战营
上海人工智能实验室去年 12 月份推出了书生·浦语大模型实战营,收到社区的一致好评,半年来累计已有 15 万人次参与学习,并孵化出超 600 个生态项目。在 InternLM2.5 发布之际,我们也正式宣布书生·浦语大模型实战营正式升级为书生大模型实战营,逐步加入更多书生大模型体系课程与实战, 带你从入门到进阶,大模型时代不迷航。
7 月 10 日至 8 月 10 日将正式开启第三期书生大模型实战营,在实战营中手把手带大家微调、部署 InternLM2.5 模型,免费算力及助教老师全程陪伴,还有权威的官方证书,快来报名学习吧!
报名链接:https://www.wjx.cn/vm/PvefmG2.aspx?udsid=831608

总结
书生·浦语以持续的高质量开源赋能创新,坚持开源和免费商用,面向实际应用场景提供更好的模型和工具链。



