day05 泛型,数据结构,List,Set
今日目标
1 泛型
1.1 泛型的介绍 ★
- 泛型是一种类型参数,专门用来保存类型用的
- 最早接触泛型是在ArrayList,这个E就是所谓的泛型了。使用ArrayList时,只要给E指定某一个类型,里面所有用到泛型的地方都会被指定对应的类型
1.2 使用泛型的好处 ★
- 不用泛型带来的问题
- 集合若不指定泛型,默认就是Object。存储的元素类型自动提升为Object类型。获取元素时得到的都是Object,若要调用特有方法需要转型,给我们编程带来麻烦.
- 使用泛型带来的好处
- 可以在编译时就对类型做判断,避免不必要的类型转换操作,精简代码,也避免了因为类型转换导致的代码异常
//泛型没有指定类型,默认就是Object
ArrayList list = new ArrayList();
list.add("Hello");
list.add("World");
list.add(100);
list.add(false);
//集合中的数据就比较混乱,会给获取数据带来麻烦
for (Object obj : list) {String str = (String) obj;//当遍历到非String类型数据,就会报异常出错System.out.println(str + "长度为:" + str.length());
}
1.3 泛型的注意事项
-
泛型在代码运行时,泛型会被擦除。后面学习反射的时候,可以实现在代码运行的过程中添加其他类型的数据到集合
- 泛型只在编译时期限定数据的类型 , 在运行时期会被擦除
1.4 自定义泛型类 ★
-
当一个类定义其属性的时候,不确定具体是什么类型时,就可以使用泛型表示该属性的类型
-
定义的格式
- 在类型名后面加上一对尖括号,里面定义泛型。一般使用一个英文大写字母表示,如果有多个泛型使用逗号分隔
- public class 类名<泛型名>{ … }
举例 : public class Student<X,Y>{ X xObj; } -
泛型的确定
- 当创建此泛型类是 , 确定泛型类中泛型的具体数据类型
-
练习
package com.itheima.genericity_demo.genericity_class;import java.time.Period;/*需求 : 定义一个人类,定义一个属性表示爱好,但是具体爱好是什么不清楚,可能是游泳,乒乓,篮球。*/
public class GenericityDemo {public static void main(String[] args) {Person<BasketBall> person = new Person<>();person.setHobby(new BasketBall());Person<Swim> person2 = new Person<>();person2.setHobby(new Swim());Person person3 = new Person<>();// 如果没有指定泛型 , 那么默认使用Object数据类型}
}class Person<H> {// 定义属性表达爱好private H hobby;public H getHobby() {return hobby;}public void setHobby(H hobby) {this.hobby = hobby;}
}class Swim {
}class PingPang {
}class BasketBall {
}
1.3 自定义泛型接口
-
当定义接口时,内部方法中其参数类型,返回值类型不确定时,就可以使用泛型替代了。
-
定义泛型接口
- 在接口后面加一对尖括号 , 尖括号中定义泛型 , 一般使用大写字母表示, 多个泛型用逗号分隔
- public interface<泛型名> { … }
- 举例 :
public interface Collection<E>{public boolean add(E e); } -
泛型的确定
- 实现类去指定泛型接口的泛型
- 实现了不去指定泛型接口的泛型 , 进行延续泛型 , 回到泛型类的使用
package com.itheima.genericity_demo.genericity_interface;
/*需求:模拟一个Collection接口,表示集合,集合操作的数据不确定。定义一个接口MyCollection具体表示。*/
// 泛型接口
public interface MyCollection<E> {// 添加功能public abstract void add(E e);// 删除功能public abstract void remove(E e);
}// 指定泛型的第一种方式 : 让实现类去指定接口的泛型
class MyCollectionImpl1 implements MyCollection<String>{@Overridepublic void add(String s) {}@Overridepublic void remove(String s) {}
}
// 指定泛型的第二种方式 : 实现类不确定泛型,延续泛型,回到泛型类的使用
class MyCollectionImpl2<E> implements MyCollection<E>{@Overridepublic void add(E a) {}@Overridepublic void remove(E a) {}
}
1.4 自定义泛型方法
-
当定义方法时,方法中参数类型,返回值类型不确定时,就可以使用泛型替代了
-
泛型方法的定义
- 可以在方法的返回值类型前定义泛型
- 格式 : public <泛型名> 返回值类型 方法名(参数列表){ … }
- 举例 : public void show(T t) { … }
-
泛型的确定
- 当调用一个泛型方法 , 传入的参数是什么类型, 那么泛型就会被确定
-
练习
package com.itheima.genericity_demo.genericity_method;import java.util.ArrayList; import java.util.Arrays;public class Test {public static void main(String[] args) {// Collection集合中 : public <T> T[] toArray(T[] a) : 把集合中的内容存储到一个数组中 , 进行返回ArrayList<String> list = new ArrayList<>();list.add("abc");list.add("ads");list.add("qwe");String[] array = list.toArray(new String[list.size()]);System.out.println(Arrays.toString(array));}// 接收一个集合 , 往集合中添加三个待指定类型的元素public static <X> void addElement(ArrayList<X> list, X x1, X x2, X x3) {list.add(x1);list.add(x2);list.add(x3);} }
1.5 通配符 ★
-
当我们对泛型的类型确定不了,而是表达的可以是任意类型,可以使用泛型通配符给定
符号就是一个问号:? 表示任意类型,用来给泛型指定的一种通配值。如下
public static void shuffle(List<?> list){//…
} 说明:该方法时来自工具类Collections中的一个方法,用来对存储任意类型数据的List集合进行乱序
-
泛型通配符结合集合使用
- 泛型通配符搭配集合使用一般在方法的参数中比较常见。在集合中泛型是不支持多态的,如果为了匹配任意类型,我们就会使用泛型通配符了。
- 方法中的参数是一个集合,集合如果携带了通配符,要特别注意如下
- 集合的类型会提升为Object类型
- 方法中的参数是一个集合,集合如果携带了通配符,那么此集合不能进行添加和修改操作 , 可以删除和获取
package com.itheima.genericity_demo;import java.util.ArrayList; import java.util.List;public class Demo {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("abc");list.add("asd");list.add("qwe");// 方法的参数是一个集合 , 集合的泛型是一个通配符 , 可以接受任意类型元素的集合show(list);}public static void show(List<?> list) {// 如果集合的泛型是一个通配符 , 那么集合中元素以Object类型存在Object o = list.get(0);// 如果集合的泛型是一个通配符 , 那么此集合不能进行添加和修改操作 , 可以删除和获取// list.add(??);// 删除可以list.remove(0);// 获取元素可以for (Object o1 : list) {System.out.println(o1);}} }package com.itheima.genericity_demo;import java.util.ArrayList;/*已知存在继承体系:Integer继承Number,Number继承Object。定义一个方法,方法的参数是一个ArrayList。要求可以接收ArrayList<Integer>,ArrayList<Number>,ArrayList<Object>,ArrayList<String>这些类型的数据。结论 : 具体类型的集合,不支持多态 , 要想接收任意类型集合 , 需要使通配符集合*/ public class Test1 {public static void main(String[] args) {ArrayList<Integer> list1 = new ArrayList<>();ArrayList<Number> list2 = new ArrayList<>();ArrayList<String> list3 = new ArrayList<>();ArrayList<Object> list4 = new ArrayList<>();useList5(list1);useList5(list2);useList5(list3);useList5(list4);}// 此方法只能接收存储Integer类型数据的集合public static void useList1(ArrayList<Integer> list) {}// 此方法只能接收存储Number类型数据的集合public static void useList2(ArrayList<Number> list) {}// 此方法只能接收存储String类型数据的集合public static void useList3(ArrayList<String> list) {}// 此方法只能接收存储Object类型数据的集合public static void useList4(ArrayList<Object> list) {}public static void useList5(ArrayList<?> list) {}}
1.6 受限泛型
-
受限泛型是指,在使用通配符的过程中 , 对泛型做了约束,给泛型指定类型时,只能是某个类型父类型或者子类型
-
分类 :
- 泛型的下限 :
- <? super 类型> //只能是某一类型,及其父类型,其他类型不支持
- 泛型的上限 :
- <? extends 类型> //只能是某一个类型,及其子类型,其他类型不支持
package com.itheima.genericity_demo.wildcard_demo;import java.util.ArrayList;/*wildcardCharacter基于上一个知识点,定义方法show1方法,参数只接收元素类型是Number或者其父类型的集合show2方法,参数只接收元素类型是Number或者其子类型的集合*/ public class Test2 {public static void main(String[] args) {ArrayList<Integer> list1 = new ArrayList<>();ArrayList<Number> list2 = new ArrayList<>();ArrayList<Object> list3 = new ArrayList<>();show1(list3);show1(list2);show2(list2);show2(list1);}// 此方法可以接受集合中存储的是Number或者Number的父类型 , 下限泛型public static void show1(ArrayList<? super Number> list) {}// 此方法可以接受集合中存储的是Number或者Number的子类型 , 上限泛型public static void show2(ArrayList<? extends Number> list) {} } - 泛型的下限 :
2 数据结构
-
栈结构 : 先进后出
-
队列结构 : 先进先出
-
数组结构 : 查询快 , 增删慢
-
链表结构 : 查询慢 , 增删快
-
二叉树
-
二叉树 : 每个节点最多有两个子节点
-
二茬查找树 : 每个节点的左子节点比当前节点小 , 右子节点比当前节点大
-
二茬平衡树 : 在查找树的基础上, 每个节点左右子树的高度不超过1
-
红黑树 :
-
每一个节点或是红色的,或者是黑色的
-
根节点必须是黑色
-
如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
-
不能出现两个红色节点相连的情况
-
对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
-
添加元素 :
-
-
-
哈希表结构 :
- 哈希值:是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
- Object类中有一个方法可以获取对象的哈希值
public int hashCode():返回对象的哈希码值 - 对象的哈希值特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
3 List集合(有序、有索引) ★
-
List集合是Collection集合子类型,继承了所有Collection中功能,同时List增加了带索引的功能
-
特点 :
- 元素的存取是有序的【有序】
- 元素具备索引 【有索引】
- 元素可以重复存储【可重复】
-
常见的子类
- ArrayList:底层结构就是数组【查询快,增删慢】
- Vector:底层结构也是数组(线程安全,同步安全的,低效,用的就少)
- LinkedList:底层是链表结构(双向链表)【查询慢,增删快】
-
List中常用的方法
- public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
- public E get(int index):返回集合中指定位置的元素
- public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。\
- public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素
-
LinkedList类
- LinkedList底层结构是双向链表。每个节点有三个部分的数据,一个是保存元素数据,一个是保存前一个节点的地址,一个是保存后一个节点的地址。可以双向查询,效率会比单向链表高。
- LinkedList特有方法
- public void addFirst(E e):将指定元素插入此列表的开头。
- public void addLast(E e):将指定元素添加到此列表的结尾。
- public E getFirst():返回此列表的第一个元素。
- public E getLast():返回此列表的最后一个元素。
- public E removeFirst():移除并返回此列表的第一个元素。
- public E removeLast():移除并返回此列表的最后一个元素。
4 Set集合(无序、无索引) ★
- Set集合也是Collection集合的子类型,没有特有方法。Set比Collection定义更严谨
- 特点 :
- 元素不能保证插入和取出顺序(无序)
- 元素是没有索引的(无索引)
- 元素唯一(元素唯一)
- Set常用子类
- HashSet:底层由HashMap,底层结构哈希表结构。
去重,无索引,无序。
哈希表结构的集合,操作效率会非常高。 - LinkedHashSet:底层结构链表加哈希表结构。
具有哈希表表结构的特点,也具有链表的特点。 - TreeSet:底层是有TreeMap,底层数据结构 红黑树。
去重,让存入的元素具有排序(升序排序)
- HashSet:底层由HashMap,底层结构哈希表结构。
day06-排序查找算法,Map集合,集合嵌套,斗地主案例
今日目标 :
1 TreeSet集合
1.1 集合体系
1.2 TreeSet特点 【去重、并排序】
- 不包含重复元素的集合[元素唯一]
- 没有带索引的方法[无索引]
- 可以按照指定的规则进行排序[可以排序]
1.3 TreeSet集合的练习
package com.itheima.treeset_demo;import java.util.Iterator;
import java.util.TreeSet;/*1 TreeSet集合练习存储Integer类型的整数,并遍历*/
public class TreeSetDemo {public static void main(String[] args) {TreeSet<Integer> ts = new TreeSet<>();ts.add(10);ts.add(10);ts.add(20);ts.add(10);ts.add(30);// 迭代器Iterator<Integer> it = ts.iterator();while(it.hasNext()){Integer s = it.next();System.out.println(s);}System.out.println("================");// 增强forfor (Integer t : ts) {System.out.println(t);}}
}-
如果TreeSet存储自定义对象 , 需要对自定义类进行指定排序规则
下列代码没有指定排序规则 , 所以运行会报出错误
package com.itheima.treeset_demo;public class Student {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}
}
=============================================================package com.itheima.treeset_demo;import java.util.Iterator;
import java.util.TreeSet;/*TreeSet集合练习存储学生对象,并遍历*/
public class TreeSetDemo2 {public static void main(String[] args) {TreeSet<Student> ts = new TreeSet<>();Student s1 = new Student("dilireba", 19);Student s2 = new Student("gulinazha", 20);Student s3 = new Student("maerzhaha", 18);ts.add(s1);ts.add(s2);ts.add(s3);System.out.println(ts);}
}1.4 排序规则
1.4.1 ★自然排序【对象实现Comparable、重写compareTo】
-
使用步骤
- 使用空参构造创建TreeSet集合对象
- 存储元素所在的类需要实现Comparable接口
- 重写Comparable接口中的抽象方法 compareTo方法,指定排序规则
-
compareTo方法如何指定排序规则 :
- 此方法如果返回的是小于0 , 代表的是当前元素较小 , 需要存放在左边
- 此方法如果返回的是大于0 , 代表的是当前元素较大, 需要存放在右边
- 此方法如果返回的是0 , 代表的是当前元素在集合中已经存在 , 不存储
-
练习 : 存储学生对象, 按照年龄的升序排序,并遍历
package com.itheima.treeset_demo;public class Student implements Comparable<Student>{private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}/**/@Overridepublic int compareTo(Student o) {/*this : 当前要添加的元素o : 集合中已经存在的元素如果方法返回值为负数 : 当前元素放左边如果方法的返回值为正数 : 当前元素放右边如果方法的返回值为0 : 说明当前元素在集合中存在,不存储*/int result = this.age - o.age;return result;} } =====================================================package com.itheima.treeset_demo; import java.util.Iterator; import java.util.TreeSet;/*TreeSet集合练习存储学生对象,并遍历*/ public class TreeSetDemo2 {public static void main(String[] args) {TreeSet<Student> ts = new TreeSet<>();Student s1 = new Student("dilireba", 19);Student s2 = new Student("gulinazha", 20);Student s3 = new Student("maerzhaha", 18);ts.add(s1);ts.add(s2);ts.add(s3);System.out.println(ts);} }package com.itheima.treeset_demo;public class Student implements Comparable<Student> {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}/**/@Overridepublic int compareTo(Student o) {/*this : 当前要添加的元素o : 集合中已经存在的元素如果方法返回值为负数 : 当前元素放左边如果方法的返回值为正数 : 当前元素放右边如果方法的返回值为0 : 说明当前元素在集合中存在,不存储*/int result = this.age - o.age;// 如果年龄相等 , 那么按照名字进行排序return result == 0 ? this.name.compareTo(o.name) : age;} }=============================================================package com.itheima.treeset_demo;import java.util.Iterator; import java.util.TreeSet;/*TreeSet集合练习存储学生对象, 按照年龄的升序排序,并遍历*/ public class TreeSetDemo2 {public static void main(String[] args) {TreeSet<Student> ts = new TreeSet<>();Student s1 = new Student("dilireba", 19);Student s2 = new Student("gulinazha", 20);Student s3 = new Student("maerzhaha", 18);Student s4 = new Student("ouyangnanan", 18);ts.add(s1);ts.add(s2);ts.add(s3);ts.add(s4);System.out.println(ts);} }
1.4.2 ★比较器排序【比较器类实现Comparator,并重写compare】
-
使用步骤
- TreeSet的带参构造方法使用的是 “比较器排序” 对元素进行排序的
- 比较器排序,就是让TreeSet集合构造方法接收Comparator接口的实现类对象
- 重写Comparator接口中的 compare(T o1,T o2)方法 , 指定排序规则
- 注意 : o1代表的是当前往集合中添加的元素 , o2代表的是集合中已经存在的元素,排序原理与自然排序相同!
-
排序规则
- 排序原理与自然排序相同!
-
练习
package com.itheima.treeset_demo.comparator_demo;public class Teacher {private String name;private int age;public Teacher() {}public Teacher(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}
}
======================================package com.itheima.treeset_demo.comparator_demo;import java.util.Comparator;
import java.util.TreeSet;/*TreeSet集合练习存储学生对象, 按照年龄的升序排序,并遍历*/
public class TreeSetDemo2 {public static void main(String[] args) {TreeSet<Teacher> ts = new TreeSet<>(new ComparatorImpl());Teacher s1 = new Teacher("dilireba", 19);Teacher s2 = new Teacher("gulinazha", 20);Teacher s3 = new Teacher("maerzhaha", 18);Teacher s4 = new Teacher("ouyangnanan", 18);ts.add(s1);ts.add(s2);ts.add(s3);ts.add(s4);System.out.println(ts);}
}// 比较器排序
class ComparatorImpl implements Comparator<Teacher> {@Overridepublic int compare(Teacher o1, Teacher o2) {int result = o1.getAge() - o2.getAge();return result == 0 ? o1.getName().compareTo(o2.getName()) : result;}
}
1.4.3 两种排序的区别
-
自然排序:自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序。
-
比较器排序:创建TreeSet对象的时候传递Comparator的实现类对象,重写compare方法,根据返回值进行排序。
-
如果Java提供好的类已经定义了自然排序排序规则 , 那么我们可以使用比较器排序进行替换
-
注意 : 如果自然排序和比较器排序都存在 , 那么会使用比较器排序
-
两种方式中,关于返回值的规则:
- 如果返回值为负数,表示当前存入的元素是较小值,存左边
- 如果返回值为0,表示当前存入的元素跟集合中元素重复了,不存
- 如果返回值为正数,表示当前存入的元素是较大值,存右边
2 Collections单列集合工具类 ★
- Collections工具类介绍
- java.util.Collections 是集合的工具类,里面提供了静态方法来操作集合,乱序,排序…
2.1 shuffle方法
-
public static void shuffle(List<?> list) 对集合中的元素进行打乱顺序。
-
集合中元素类型可以任意类型
package com.itheima.collections_demo;import java.util.ArrayList; import java.util.Collections;/*Collections类 : 操作单列集合的工具类public static void shuffle(List<?> list) 对集合中的元素进行打乱顺序1 乱序只能对List集合进行乱序2 集合中元素类型可以任意类型需求 : 定义一个List集合,里面存储若干整数。对集合进行乱序*/ public class ShuffleDemo {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>();list.add(10);list.add(30);list.add(50);list.add(40);list.add(20);Collections.shuffle(list);System.out.println(list);// 打印集合中的元素} }
2.2 sort方法(只对List结合排序)
-
public static void sort (List list): 对集合中的元素自然排序
- 该方法只能对List集合进行排序
- 从方法中泛型分析可知,集合中元素类型必须是Comparable的子类型
package com.itheima.collections_demo;import java.util.ArrayList; import java.util.Collections; import java.util.Comparator;/*Collections类 : 单列集合的工具类sort方法是一个重载的方法,可以实现自然排序及比较器排序。要特别注意的是sort方法只能对List集合进行排序,方法如下:public static <T extends Comparable> void sort (List<T> list)练习:定义List集合,存储若干整数,进行排序*/ public class SortDemo1 {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>();list.add(3);list.add(2);list.add(4);list.add(1);// 使用此方法 , 需要集合中存储的元素实现Comparable接口Collections.sort(list);System.out.println(list);} } -
public static void sort (List list, Comparator<? super T> c)
-
方法只能对List集合排序
-
对元素的类型没有要求
-
需要定义一个比较器Comparator (规则和之前TreeSet时一样)
-
使用场景:
- List集合中的元素类型不具备自然排序能力(元素类型没有实现结果 Comparable)
- List集合中的元素类型具备自然排序能力,但是排序规则不是当前所需要的。
package com.itheima.collections_demo;import java.util.ArrayList; import java.util.Collections; import java.util.Comparator;/*Collections类 : 单列集合的工具类sort方法是一个重载的方法,可以实现自然排序及比较器排序。要特别注意的是sort方法只能对List集合进行排序,方法如下:public static <T extends Comparable> void sort (List<T> list) : 只能对集合中的元素自然排序需求1:定义一个List集合,存储若干整数,要求对集合进行降序排序分析:整数类型Integer具备自然排序能力,但是题目要求降序排序需求2:定义一个学生类,属性有姓名,年龄。创建若干对象放到List集合中。要求对List集合中学生对象进行年龄的升序排序。分析:自定义类型默认是没有自然排序能力的,我们使用自定义比较器方式排序。*/ public class SortDemo2 {public static void main(String[] args) {/*需求2:定义一个学生类,属性有姓名,年龄。创建若干对象放到List集合中。要求对List集合中学生对象进行年龄的升序排序。分析:自定义类型默认是没有自然排序能力的,我们使用自定义比较器方式排序*/ArrayList<Student> list = new ArrayList<>();list.add(new Student("lisi", 24));list.add(new Student("zhangsan", 23));Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o1.getAge() - o2.getAge();}});System.out.println(list);}/*需求1:定义一个List集合,存储若干整数,要求对集合进行降序排序分析:整数类型Integer具备自然排序能力,但是题目要求降序排序*/private static void method1() {ArrayList<Integer> list = new ArrayList<>();list.add(3);list.add(2);list.add(4);list.add(1);// 使用此方法 , 需要集合中存储的元素实现Comparable接口Collections.sort(list, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}});System.out.println(list);} }
-
3 可变参数
3.1 可变参数介绍
- 在 JDK5 中提供了可变参数,允许在调用方法时传入任意个参数。可变参数原理就是一个数组形式存在
- 格式 : 修饰符 返回值类型 方法名(数据类型… 变量名) { }
- 举例 : public void show(int … num) : 表达式该方法可以接收任意个整数值 , 原理 : 其实就是一个int类型的数组
3.2 可变参数注意
- 可变参数只能作为方法的最后一个参数,但其前面可以有或没有任何其他参数。
- 可变参数本质上是数组,不能作为方法的重载。如果同时出现相同类型的数组和可变参数方法,是不能编译通过的。
3.3 可变参数的使用
- 调用可变参数方法,可以给出零到任意多个参数,编译器会将可变参数转化为一个数组,也可以直接传递一个数组。
方法内部使用时直接当做数组使用即可
package com.itheima.changevariable_demo;/*1 什么是可变参数JDK5中,允许在调用方法时传入任意个参数。可变参数原理就是一个数组形式存在格式 : 修饰符 返回值类型 方法名(数据类型… 变量名) { }举例 : public void show(int... num){}2 可变参数注意 :1) 可变参数只能作为方法的最后一个参数,但其前面可以有或没有任何其他参数。2) 可变参数本质上是数组,不能作为方法的重载。如果同时出现相同类型的数组和可变参数方法,是不能编译通过的。3 可变参数的使用 :调用可变参数的方法 , 可以传入0个到任意个数据 , 编译器会将可变参数转换成一个数组 , 也可以直接传递一个数组方法中把可变参数当做一个数组去使用即可练习:定义方法可以求任意个整数的和*/
public class VariableDemo1 {public static void main(String[] args) {sum();sum(1, 2);sum(1, 2, 3, 4);}public static void sum(int... num) {// 方法的参数是一个int类型的可变参数int sum = 0;// 定义求和变量for (int i : num) {sum += i;}System.out.println(sum);}
}3.4 addAll方法(就是一个含有可变参数的方法)
-
static boolean addAll(Collection<? super T> c , T… elements) : 添加任意多个数据到集合中
-
该方法就是一个含有可变参数的方法,使用时可以传入任意多个实参,实用方便!
-
分析 : Collection<? super T> , ? 可以是 T 的类型或者父类型 , 反过来 , T是?类型或者子类型
那么当你确定?的类型,也就是集合的类型 , 就可以往集合中添加此类型或者子类型
package com.itheima.changevariable_demo;import java.util.ArrayList; import java.util.Collections;/*Collections的addAll方法static <T> boolean addAll(Collection<? super T> c , T... elements) : 添加任意多个数据到集合中分析: 该方法就是一个含有可变参数的方法,使用时可以传入任意多个实参,实用方便!练习:创建一个List集合,使用addAll方法传入若干字符串*/ public class VariableDemo2 {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>();Collections.addAll(list, 10, 20, 30, 40);System.out.println(list);// [10, 20, 30, 40]} } -
4 排序,查找算法
4.1 冒泡排序
- 冒泡排序 : 将一组数据按照从小到大的顺序进行排序
- 冒泡排序原理 : 相邻元素两两作比较 , 大的元素往后放
package com.itheima.arraysort_demo.bubblesort_demo;import java.util.Arrays;/*冒泡排序 : 将一组数据按照从小到大的顺序进行排序冒泡排序的原理 : 相邻元素两两作比较 , 大的元素往后放需求 : 将数组中的元素 {3,5,2,1,4} 进行升序排序*/
public class SortDemo {public static void main(String[] args) {int[] arr = {3, 5, 2, 1, 4};// // 第一轮排序
// for (int i = 0; i < arr.length - 1; i++) {
// if (arr[i] > arr[i + 1]) {
// int temp = arr[i];
// arr[i] = arr[i + 1];
// arr[i + 1] = temp;
// }
// }
//
// System.out.println("第一轮排序:" + Arrays.toString(arr));
//
//
// // 第二轮排序
// for (int i = 0; i < arr.length - 2; i++) {
// if (arr[i] > arr[i + 1]) {
// int temp = arr[i];
// arr[i] = arr[i + 1];
// arr[i + 1] = temp;
// }
// }
//
// System.out.println("第二轮排序:" + Arrays.toString(arr));
//
//
// // 第三轮排序
// for (int i = 0; i < arr.length - 2; i++) {
// if (arr[i] > arr[i + 1]) {
// int temp = arr[i];
// arr[i] = arr[i + 1];
// arr[i + 1] = temp;
// }
// }
//
// System.out.println("第三轮排序:" + Arrays.toString(arr));
//
//
// // 第四轮排序
// for (int i = 0; i < arr.length - 2; i++) {
// if (arr[i] > arr[i + 1]) {
// int temp = arr[i];
// arr[i] = arr[i + 1];
// arr[i + 1] = temp;
// }
// }
//
// System.out.println("第四轮排序:" + Arrays.toString(arr));// 优化代码for (int j = 0; j < arr.length - 1; j++) {// 比较的轮次// 每轮相邻元素比较的次数for (int i = 0; i < arr.length - 1 - j; i++) {if (arr[i] > arr[i + 1]) {int temp = arr[i];arr[i] = arr[i + 1];arr[i + 1] = temp;}}System.out.println("第" + (j + 1) + "轮排序:" + Arrays.toString(arr));}}
}
4.2 选择排序
- 选择排序原理 : 它的工作原理是每一次从待排序的数据元素中选出最小的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。
- 注意事项 :
- 有n个元素,那么就要比较n-1轮次。
- 每一趟中都会选出一个最值元素,较前一趟少比较一次
package com.itheima.arraysort_demo.selectionsort_demo;
/*选择排序工作原理 :它的工作原理是每一次从待排序的数据元素中选出最小的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。注意 :1 有n个元素,那么就要比较n-1趟。2 每一趟中都会选出一个最值元素,较前一趟少比较一次*/import java.util.Arrays;public class SortDemo {public static void main(String[] args) {int[] arr = {4, 1, 5, 3, 2};// 遍历数组for (int i = 0; i < arr.length - 1; i++) {// 记录当前元素和其之后所有元素的最小值索引int minIndex = i;int min = arr[i];for (int j = i; j < arr.length; j++) {if (arr[j] < min) {minIndex = j; // 把当前最小值的索引赋值给minIndexmin = arr[j];// 替换最小值}}if (i != minIndex) {int temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}}System.out.println(Arrays.toString(arr));}
}4.3 二分查找
- 原理 : 每次去掉一般的查找范围
- 前提 : 数组必须有序
package com.itheima.arraysort_demo.binarysearch_demo;/*二分查找 :原理 : 每次去掉一般的查找范围前提 : 数组必须有序步骤 :1,定义两个变量,表示要查找的范围。默认min = 0 , max = 最大索引2,循环查找,但是min <= max3,计算出mid的值4,判断mid位置的元素是否为要查找的元素,如果是直接返回对应索引5,如果要查找的值在mid的左半边,那么min值不变,max = mid -1.继续下次循环查找6,如果要查找的值在mid的右半边,那么max值不变,min = mid + 1.继续下次循环查找7,当 min > max 时,表示要查找的元素在数组中不存在,返回-1.*/
public class BinarySearchDemo {public static void main(String[] args) {int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int i = binarySearch(arr, 8);System.out.println(i);}public static int binarySearch(int[] arr, int num) {// 定义两个变量,表示要查找的范围。默认min = 0 , max = 最大索引int max = arr.length - 1;int min = 0;// 2,循环查找,但是min <= maxwhile (min <= max) {// 3,计算出mid的值int mid = (min + max) / 2;if (arr[mid] == num) {// 4,判断mid位置的元素是否为要查找的元素,如果是直接返回对应索引return mid;} else if (arr[mid] > num) {// 5,如果要查找的值在mid的左半边,那么min值不变,max = mid -1.继续下次循环查找max = mid - 1;} else if (arr[mid] < num) {// 6,如果要查找的值在mid的右半边,那么max值不变,min = mid + 1.继续下次循环查找min = mid + 1;}}return -1;}
}5 Map集合
5.1 Map集合的介绍
- java.util.Map<K,V> 集合,里面保存的数据是成对存在的,称之为双列集合。存储的数据,我们称为键值对。 之前所学的Collection集合中元素单个单个存在的,称为单列集合
5.2 特点
-
Map<K,V> K:键的数据类型;V:值的数据类型
-
特点 :
- 键不能重复,值可以重复
- 键和值是 一 一 对应的,通过键可以找到对应的值
- (键 + 值) 一起是一个整体 我们称之为“键值对” 或者 “键值对对象”,在Java中叫做“Entry对象”
-
使用场景
- 凡是要表示一一对应的数据时就可以Map集合
- 举例 : 学生的学号和姓名 — (itheima001 小智)
- 举例 : 夫妻的关系 ---- (王宝强 马蓉 ) (谢霆锋 张柏芝)
- 凡是要表示一一对应的数据时就可以Map集合
5.3 常用实现类
- HashMap:
- 此前的HashSet底层实现就是HashMap完成的,HashSet保存的元素其实就是HashMap集合中保存的键,底层结构是哈希表结构,具有键唯一,无序,特点。
- LinkedHashMap:
- 底层结构是有链表和哈希表结构,去重,有序
- TreeMap:
- 底层是有红黑树,去重,通过键排序
5.4 常用的方法
- public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。
- public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。
- public V get(Object key) 根据指定的键,在Map集合中获取对应的值。
- public Set keySet(): 获取Map集合中所有的键,存储到Set集合中。
- public boolean containKey(Object key):判断该集合中是否有此键。
package com.itheima.map_demo.mapmethod_demo;import java.util.HashMap;
import java.util.Map;
import java.util.Set;/*Map中常用方法 :public V put(K key, V value): 把指定的键与指定的值添加到Map集合中public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值public V get(Object key) 根据指定的键,在Map集合中获取对应的值public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中public boolean containKey(Object key): 判断该集合中是否有此键。需求 : 将以下数据保存到Map集合中 , 进行测试以上方法“文章“ "马伊琍“谢霆锋” “王菲”“李亚鹏” “王菲”*/
public class MapDemo {public static void main(String[] args) {// 创建双列集合对象Map<String, String> hm = new HashMap<>();// 添加元素// public V put(K key, V value): 把指定的键与指定的值添加到Map集合中hm.put("文章", "马伊琍");hm.put("谢霆锋", "王菲");hm.put("李亚鹏", "王菲");// public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值// System.out.println(hm.remove("谢霆锋"));// public V get(Object key) 根据指定的键,在Map集合中获取对应的值// System.out.println(hm.get("李亚鹏"));// public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中
// Set<String> set = hm.keySet();
// for (String key : set) {
// System.out.println(key);
// }// public boolean containKey(Object key): 判断该集合中是否有此键。// System.out.println(hm.containsKey("李亚鹏"));System.out.println(hm);// 打印集合 , 打印的是集合中的元素}
}5.5 Map集合的遍历
package com.itheima.map_demo.map_test;import java.util.HashMap;
import java.util.Map;
import java.util.Set;/*创建Map集合对象 , 往集合中添加以下四对元素 , 使用键找值遍历集合周瑜 -- 小乔孙策 -- 大乔刘备 -- 孙尚香诸葛亮 -- 黄月英*/
public class MapTest1 {public static void main(String[] args) {// 创建集合对象Map<String, String> hm = new HashMap<>();// 添加元素hm.put("周瑜", "小乔");hm.put("孙策", "大乔");hm.put("刘备", "孙尚香");hm.put("诸葛亮", "黄月英");// 获取健集合Set<String> set = hm.keySet();// 遍历健集合 , 通过键找值for (String key : set) {String value = hm.get(key);System.out.println(key + "---" + value);}}
}-第二种方式 : 获取键值对对象 , 在找到键和值
package com.itheima.map_demo.map_test;import java.util.HashMap;
import java.util.Map;
import java.util.Set;/*需求 : 创建Map集合对象 , 往集合中添加以下三对元素使用获取Entry对象集合,在找到键和值 遍历集合张无忌 -- 赵敏张翠山 -- 殷素素张三丰 -- 郭芙*/
public class MapTest2 {public static void main(String[] args) {// 创建集合对象Map<String, String> hm = new HashMap<>();// 添加元素hm.put("张无忌", "赵敏");hm.put("张翠山", "殷素素");hm.put("张三丰", "郭芙");// 获取键值对对象集合Set<Map.Entry<String, String>> set = hm.entrySet();// 遍历键值对对象集合 , 获取每一个键值对对象for (Map.Entry<String, String> entry : set) {// 通过entry对象获取键String key = entry.getKey();// 通过entry对象获取值String value = entry.getValue();System.out.println(key + "--" + value);}}
}5.6 HashMap集合
- 注意 : HashMap集合 , 要想保证键唯一 , 那么键所在的类必须重写hashCode和equals方法
package com.itheima.map_demo.map_test;public class Student {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;if (age != student.age) return false;return name != null ? name.equals(student.name) : student.name == null;}@Overridepublic int hashCode() {int result = name != null ? name.hashCode() : 0;result = 31 * result + age;return result;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}
}package com.itheima.map_demo.map_test;
import java.util.HashMap;
import java.util.Set;/*HashMap类 :存储数据,每位学生(姓名,年龄)都有自己的家庭住址。学生和地址有对应关系,将学生对象和家庭住址存储到map集合中。学生作为键, 家庭住址作为值。要求:学生姓名相同并且年龄相同视为同一名学生,不能重复存储*/
public class HashMapTest {public static void main(String[] args) {// 学生作为键, 家庭住址作为值。HashMap<Student, String> hm = new HashMap<>();hm.put(new Student("迪丽热巴", 18) , "新疆");hm.put(new Student("迪丽热巴", 18) , "中国");Set<Student> set = hm.keySet();for (Student key : set) {String value = hm.get(key);System.out.println(key + "--" + value);}}
}5.7 LinkedHashMap集合(元素唯一、元素有序)
- LinkedHashMap类 , 在最底层采用的数据结构 : 是链表+哈希表。
- 特点 :
- 元素唯一
- 元素有序
package com.itheima.map_demo.map_test;import java.util.LinkedHashMap;
import java.util.Set;/*LinkedHashMap类 , 在最底层采用的数据结构 : 是链表+哈希表。特点 :1 元素唯一2 有序需求 : 创建LinkedHashMap对象 , 添加元素进行验证 元素唯一 , 有序的特点*/
public class LinkedHashMapTest {public static void main(String[] args) {// 创建集合对象LinkedHashMap<Integer, String> linkedHashMap = new LinkedHashMap<>();linkedHashMap.put(1, "张三");linkedHashMap.put(1, "李四");linkedHashMap.put(2, "王五");linkedHashMap.put(3, "赵六");System.out.println(linkedHashMap);}
}5.8 TreeMap集合
-
TreeMap的底层是红黑树实现的,有排序的能力,键去重。
-
可以自然排序(键所在的类要实现Comparable)
-
若自定义类没有自然排序功能,或自然排序功能不满足要求时。可以自定义比较器排序(Comparator)
package com.itheima.map_demo.map_test;
import java.util.TreeMap;/*需求 :定义TreeMap集合存储键值对,键使用Integer,值使用String,存储若干键值对,遍历集合观察结果是否有排序。*/
public class TreeMapTest1 {public static void main(String[] args) {// 定义TreeMap集合存储键值对,键使用Integer,值使用String// 创建集合对象TreeMap<Integer, String> treeMap = new TreeMap<>();treeMap.put(1, "张三");treeMap.put(3, "赵六");treeMap.put(2, "王五");System.out.println(treeMap);}
}package com.itheima.map_demo.map_test;import java.util.Comparator;
import java.util.TreeMap;/*需求:创建一个TreeMap集合,键是学生对象(Student),值是籍贯(String)。学生属性姓名和年龄, 要求按照年龄进行升序排序并遍历*/
public class TreeMapTest2 {public static void main(String[] args) {// 学生作为键, 家庭住址作为值。TreeMap<Student, String> tm = new TreeMap<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o1.getAge() - o2.getAge();}});tm.put(new Student("迪丽热巴", 18), "新疆");tm.put(new Student("迪丽热巴", 16), "中国");System.out.println(tm);}
}6 集合嵌套
6.1 List嵌套List
package com.itheima.Collection_nested_demo;import java.util.ArrayList;
import java.util.List;/*使用场景举例:一年级有多个班级,每个班级有多名学生。要求保存每个班级的学生姓名,保存一个年级所有的班级信息思路:可以使用List集合保存一个班级的学生可以使用List集合保存所有班级因此我们可以定义集合如下:班级:List<String>举例 :List<String> 三年一班 = {迪丽热巴 , 古力娜扎 ,马尔扎哈 ,欧阳娜娜}List<String> 三年二班 = {李小璐 , 白百何 , 马蓉}List<String> 三年三班 = {林丹 ,文章, 陈赫}年级:List<List<String>>举例 :List<List<String>> 年级 = {三年一班 , 三年二班 , 三年三班}*/
public class Test3 {public static void main(String[] args) {List<String> 三年一班 = new ArrayList<>();三年一班.add("迪丽热巴");三年一班.add("古力娜扎");三年一班.add("马尔扎哈");三年一班.add("欧阳娜娜");List<String> 三年二班 = new ArrayList<>();三年二班.add("李小璐");三年二班.add("白百何");三年二班.add("马蓉");List<String> 三年三班 = new ArrayList<>();三年三班.add("林丹");三年三班.add("文章");三年三班.add("陈赫");List<List<String>> 年级 = new ArrayList<>();年级.add(三年一班);年级.add(三年二班);年级.add(三年三班);for (List<String> 班级 : 年级) {for (String name : 班级) {System.out.println(name);}System.out.println("-----------------");}}
}6.2 List嵌套Map
package com.itheima.Collection_nested_demo;import java.util.*;/*List嵌套Map :使用场景举例:一年级有多个班级,每个班级有多名学生。要求保存每个班级的学生姓名,姓名有与之对应的学号,保存一年级所有的班级信息。思路:1 可以使用Map集合保存一个班级的学生(键是学号,值是名字)2 可以使用List集合保存所有班级因此我们可以定义集合如下:班级:Map<String,String> 键是学号,值是姓名举例 :Map<String,String> 三年一班 = {it001 = 迪丽热巴 , it002 = 古力娜扎 ,it003 = 马尔扎哈 ,it004 = 欧阳娜娜}Map<String,String> 三年二班 = {it001 = 李小璐 , it002 = 白百何 , it003 = 马蓉}Map<String,String> 三年三班 = {it001 = 林丹 ,it002 = 文章, it003 = 陈赫}年级:List<Map<String,String>>保存每个班级的信息举例 :List<Map<String,String>> 年级 = {三年一班 , 三年二班 , 三年三班}*/
public class Test2 {public static void main(String[] args) {Map<String, String> 三年一班 = new HashMap<>();三年一班.put("it001", "迪丽热巴");三年一班.put("it002", "古力娜扎");三年一班.put("it003", "马尔扎哈");三年一班.put("it004", "欧阳娜娜");Map<String, String> 三年二班 = new HashMap<>();三年二班.put("it001", "李小璐");三年二班.put("it002", "白百何");三年二班.put("it003", "马蓉");Map<String, String> 三年三班 = new HashMap<>();三年三班.put("it001", "林丹");三年三班.put("it002", "文章");三年三班.put("it003", "陈赫");List<Map<String, String>> 年级 = new ArrayList<>();年级.add(三年一班);年级.add(三年二班);年级.add(三年三班);for (Map<String, String> 班级 : 年级) {Set<String> studentId = 班级.keySet();for (String id : studentId) {String name = 班级.get(id);System.out.println(id + "---" + name);}System.out.println("=================");}}
}6.3 Map嵌套Map
package com.itheima.Collection_nested_demo;import java.util.*;/*Map嵌套Map使用场景举例:一个年级有多个班级,每个班级有多名学生。要求保存每个班级的学生姓名,姓名有与之对应的学号,保存一年级所有的班级信息,班级有与之对应的班级名称。思路:可以使用Map集合保存一个班级的学生(键是学号,值是名字)可以使用Map集合保存所有班级(键是班级名称,值是班级集合信息)因此我们可以定义集合如下:班级: Map<String,String> 键:学号,值:姓名举例 :Map<String,String> 三年一班 = {it001 = 迪丽热巴 , it002 = 古力娜扎 ,it003 = 马尔扎哈 ,it004 = 欧阳娜娜}Map<String,String> 三年二班 = {it001 = 李小璐 , it002 = 白百何 , it003 = 马蓉}Map<String,String> 三年三班 = {it001 = 林丹 ,it002 = 文章, it003 = 陈赫}年级: Map<String , Map<String,String>> 键:班级名称,值:具体班级信息举例:Map<String, Map<String,String>> 年级 = {"三年一班" = 三年一班 , "三年二班" = 三年二班 , "三年三班" = 三年三班 }*/
public class Test3 {public static void main(String[] args) {Map<String, String> 三年一班 = new HashMap<>();三年一班.put("it001", "迪丽热巴");三年一班.put("it002", "古力娜扎");三年一班.put("it003", "马尔扎哈");三年一班.put("it004", "欧阳娜娜");Map<String, String> 三年二班 = new HashMap<>();三年二班.put("it001", "李小璐");三年二班.put("it002", "白百何");三年二班.put("it003", "马蓉");Map<String, String> 三年三班 = new HashMap<>();三年三班.put("it001", "林丹");三年三班.put("it002", "文章");三年三班.put("it003", "陈赫");Map<String, Map<String, String>> 年级 = new HashMap<>();年级.put("三年一班", 三年一班);年级.put("三年二班", 三年二班);年级.put("三年三班", 三年三班);Set<String> 班级名字集合 = 年级.keySet();for (String 班级名字 : 班级名字集合) {Map<String, String> 班级信息 = 年级.get(班级名字);Set<String> 学生学号 = 班级信息.keySet();for (String 学号 : 学生学号) {String 姓名 = 班级信息.get(学号);System.out.println("班级名字:" + 班级名字 + " ,学号:" + 学号 + " , 名字:" + 姓名);}System.out.println("============");}}
}7 斗地主案例
package com.itheima.doudizhu;import java.util.*;/*按照斗地主的规则,完成洗牌发牌的动作。要求完成以下功能:准备牌:组装54张扑克牌洗牌:54张牌顺序打乱发牌:三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。看牌:查看三人各自手中的牌(按照牌的大小排序)、底牌规则:手中扑克牌从大到小的摆放顺序:大王,小王,2,A,K,Q,J,10,9,8,7,6,5,4,3*/
public class DouDiZhu {public static void main(String[] args) {// 准备牌// 键我牌的序号 , 值为牌面HashMap<Integer, String> pokers = new HashMap<>();// 牌的颜色String[] colors = {"♠", "♥", "♣", "♦"};String[] numbers = {"2", "A", "K", "Q", "J", "10", "9", "8", "7", "6", "5", "4", "3"};int count = 2;for (String number : numbers) {// 3for (String color : colors) {// System.out.println(count + " = " + color + number);pokers.put(count, color + number);count++;}}pokers.put(0, "大王");pokers.put(1, "小王");System.out.println(pokers);// 洗牌Set<Integer> set = pokers.keySet();// 创建存储编号的list集合List<Integer> list = new ArrayList<>();// {10 , 6 , 8 , 20 , 22 , 11 ... }// 把set集合中的元素存储到list集合中list.addAll(set);// 打乱集合中编号Collections.shuffle(list);System.out.println(list);// 发牌TreeSet<Integer> 赌神 = new TreeSet<>();TreeSet<Integer> 赌圣 = new TreeSet<>();TreeSet<Integer> 赌侠 = new TreeSet<>();TreeSet<Integer> 底牌 = new TreeSet<>();// 遍历牌的编号for (int i = 0; i < list.size() - 3; i++) {if (i % 3 == 0) {赌神.add(list.get(i));} else if (i % 3 == 1) {赌圣.add(list.get(i));} else {赌侠.add(list.get(i));}}底牌.add(list.get(51));底牌.add(list.get(52));底牌.add(list.get(53));System.out.println("赌神:" + 赌神);System.out.println("赌圣:" + 赌圣);System.out.println("赌侠:" + 赌侠);System.out.println("底牌:" + 底牌);// 看牌// 赌神lookPoker(pokers, 赌神, "赌神: ");// 赌圣lookPoker(pokers, 赌圣, "赌圣: ");// 赌侠lookPoker(pokers, 赌侠, "赌侠: ");// 底牌System.out.print("底牌: ");for (Integer integer : 底牌) {String poker = pokers.get(integer);System.out.print(poker + "\t");}}private static void lookPoker(HashMap<Integer, String> pokers, TreeSet<Integer> 赌神, String s) {System.out.print(s);for (Integer integer : 赌神) {String poker = pokers.get(integer);System.out.print(poker + "\t");}System.out.println();}
}模块18.集合
模块17重点回顾:1.wait和notifya.wait:线程等待,在等待过程中释放锁,需要其他线程调用notify唤醒b.notify:唤醒一条等待的线程,如果多条线程等待,随机一条唤醒c.notifyAll:唤醒所有等待线程2.Lock:锁方法:lock()获取锁 unlock()释放锁3.线程池:Executorsa.获取:static ExecutorService newFixedThreadPool(int nThread)b.提交线程任务:submit(Runnable r) submit(Callable c)c.Future:接收run或者call方法的返回值d.shutDown()关闭线程池4.Callable:类似于Runnablea.方法:call()设置线程任务,类似于run方法,但是call可以throws异常,以及有返回值b.接收返回值:FutureTask 实现了Future接口get()获取call方法的返回值模块18重点:1.知道集合的特点以及作用2.会使用Collection接口中的方法3.会使用迭代器迭代集合4.会ArrayList以及LinkedList的使用5.会使用增强for遍历集合
第一章.集合框架(单列集合)
1.之前我们学了保存数据的有:变量,数组,但是数组定长,所以如果添加一个数据或者删除一个数据,数组并不好使,需要创建新数组,所以接下来我们学一个长度可变的容器,集合2.集合的特点a.只能存储引用数据类型的数据b.长度可变c.集合中有大量的方法,方便我们操作3.分类:a.单列集合:一个元素就一个组成部分:list.add("张三")b.双列集合:一个元素有两部分构成: key 和 valuemap.put("涛哥","金莲") -> key,value叫做键值对 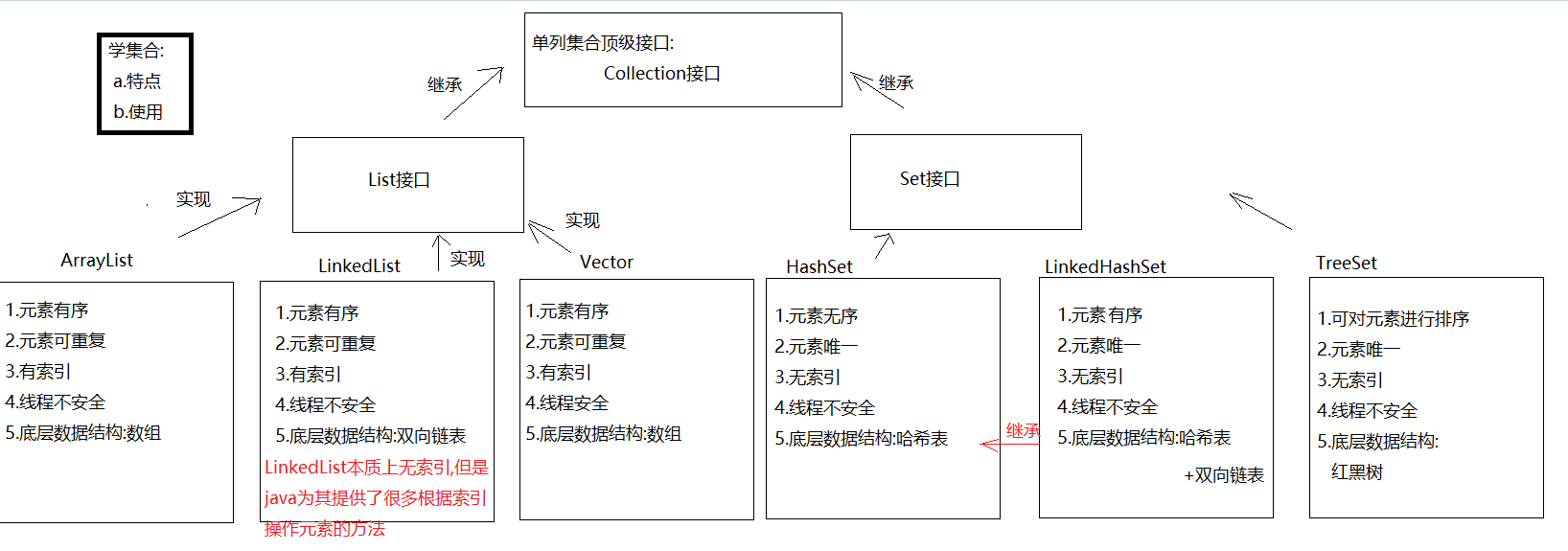
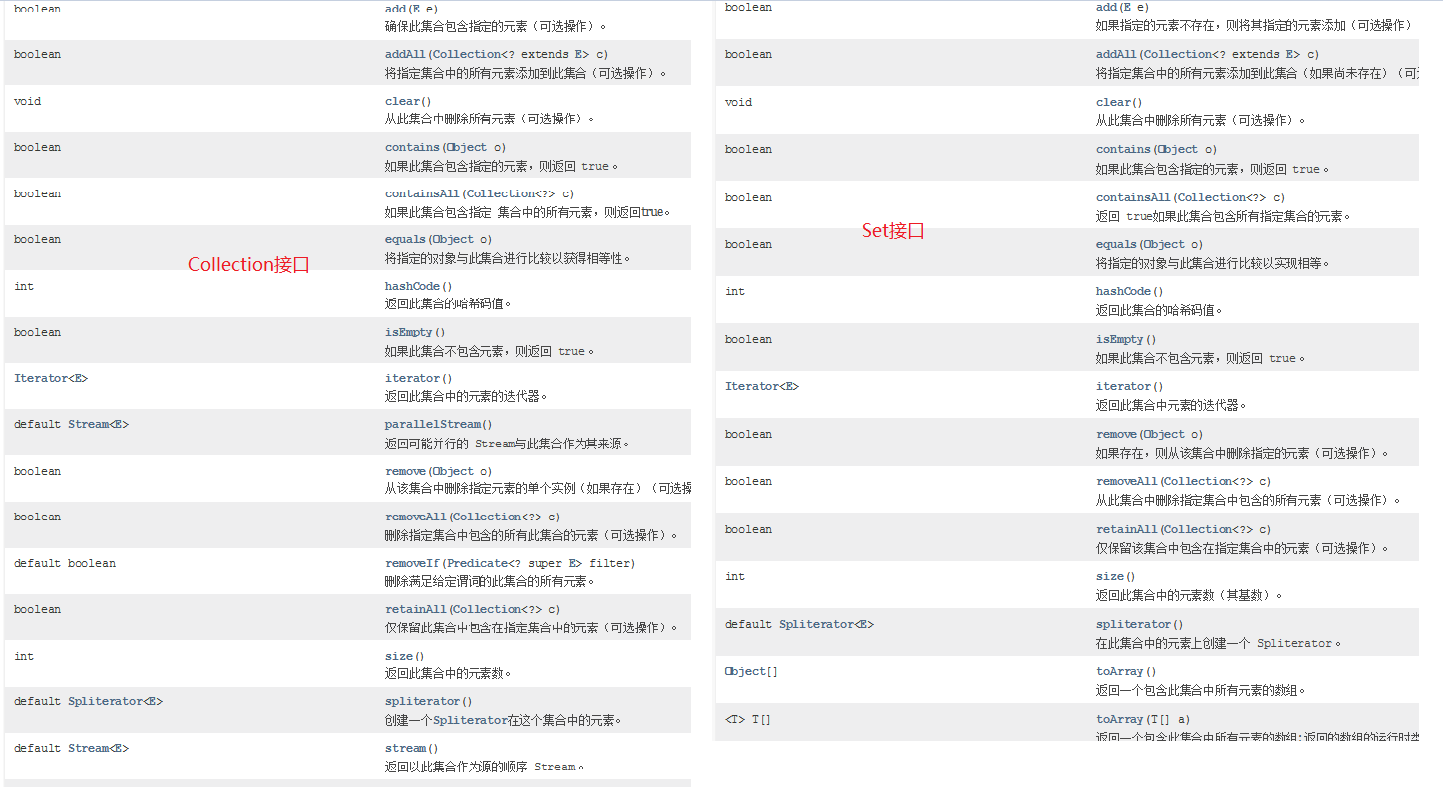
第二章.Collection接口
1.概述:单列集合的顶级接口
2.使用:a.创建:Collection<E> 对象名 = new 实现类对象<E>()b.<E>:泛型,决定了集合中能存储什么类型的数据,可以统一元素类型泛型中只能写引用数据类型,如果不写,默认Object类型,此时什么类型的数据都可以存储了<int> 不行<Integer> 行<Person> 行c.泛型细节:我们等号前面的泛型必须写,等号后面的泛型可以不写,jvm会根据前面的泛型推导出后面的泛型是啥3.常用方法:boolean add(E e) : 将给定的元素添加到当前集合中(我们一般调add时,不用boolean接收,因为add一定会成功)boolean addAll(Collection<? extends E> c) :将另一个集合元素添加到当前集合中 (集合合并)void clear():清除集合中所有的元素boolean contains(Object o) :判断当前集合中是否包含指定的元素boolean isEmpty() : 判断当前集合中是否有元素->判断集合是否为空boolean remove(Object o):将指定的元素从集合中删除int size() :返回集合中的元素个数。Object[] toArray(): 把集合中的元素,存储到数组中
public class Demo01Collection {public static void main(String[] args) {Collection<String> collection = new ArrayList<>();//boolean add(E e) : 将给定的元素添加到当前集合中(我们一般调add时,不用boolean接收,因为add一定会成功)collection.add("萧炎");collection.add("萧薰儿");collection.add("彩鳞");collection.add("小医仙");collection.add("云韵");collection.add("涛哥");System.out.println(collection);//boolean addAll(Collection<? extends E> c) :将另一个集合元素添加到当前集合中 (集合合并)Collection<String> collection1 = new ArrayList<>();collection1.add("张无忌");collection1.add("小昭");collection1.add("赵敏");collection1.add("周芷若");collection1.addAll(collection);System.out.println(collection1);//void clear():清除集合中所有的元素collection1.clear();System.out.println(collection1);//boolean contains(Object o) :判断当前集合中是否包含指定的元素boolean result01 = collection.contains("涛哥");System.out.println("result01 = " + result01);//boolean isEmpty() : 判断当前集合中是否有元素->判断集合是否为空System.out.println(collection1.isEmpty());//boolean remove(Object o):将指定的元素从集合中删除collection.remove("涛哥");System.out.println(collection);//int size() :返回集合中的元素个数。System.out.println(collection.size());//Object[] toArray(): 把集合中的元素,存储到数组中Object[] arr = collection.toArray();System.out.println(Arrays.toString(arr));}
}
第三章.迭代器
1.迭代器基本使用
1.概述:Iterator接口
2.主要作用:遍历集合
3.获取:Collection中的方法:Iterator<E> iterator()
4.方法:boolean hasNext() -> 判断集合中有没有下一个元素E next() ->获取下一个元素
public class Demo01Iterator {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("楚雨荨");list.add("慕容云海");list.add("端木磊");list.add("上官瑞谦");list.add("叶烁");//获取迭代器对象Iterator<String> iterator = list.iterator();while(iterator.hasNext()){String element = iterator.next();System.out.println(element);}}
}注意:next方法在获取的时候不要连续使用多次
public class Demo02Iterator {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("楚雨荨");list.add("慕容云海");list.add("端木磊");list.add("上官瑞谦");list.add("叶烁");//获取迭代器对象Iterator<String> iterator = list.iterator();while(iterator.hasNext()){String element = iterator.next();System.out.println(element);//String element2 = iterator.next();//System.out.println(element2);}} }NoSuchElementException:没有可操作的元素异常
2.迭代器迭代过程
int cursor; //下一个元素索引位置
int lastRet = -1;//上一个元素索引位置
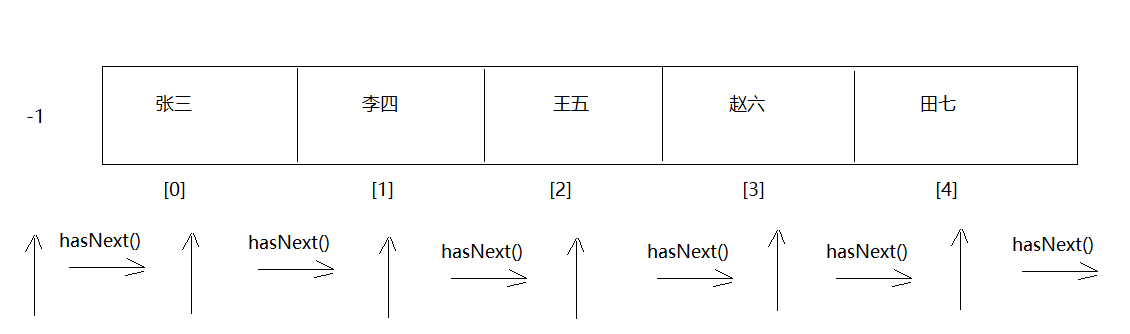
3.迭代器底层原理
1.获取Iterator的时候怎么获取的:Iterator iterator = list.iterator()我们知道Iterator是一个接口,等号右边一定是它的实现类对象问题:Iterator接收的到底是哪个实现类对象呢? -> ArrayList中的内部类Itr对象

注意:只有ArrayList使用迭代器的时候Iterator接口才会指向Itr,其他的集合使用迭代器Iterator就指向的不是Itr了
HashSet<String> set = new HashSet<>(); Iterator<String> iterator1 = set.iterator();
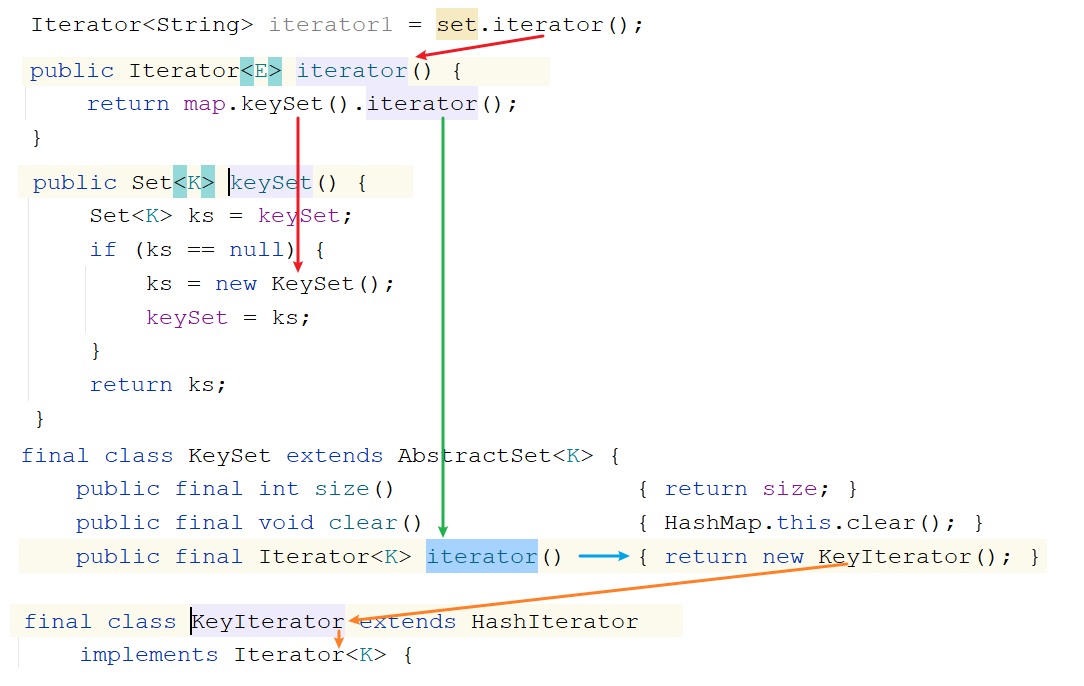
4.并发修改异常
需求:定义一个集合,存储 唐僧,孙悟空,猪八戒,沙僧,遍历集合,如果遍历到猪八戒,往集合中添加一个白龙马
public class Demo03Iterator {public static void main(String[] args) {//需求:定义一个集合,存储 唐僧,孙悟空,猪八戒,沙僧,遍历集合,如果遍历到猪八戒,往集合中添加一个白龙马ArrayList<String> list = new ArrayList<>();list.add("唐僧");list.add("孙悟空");list.add("猪八戒");list.add("沙僧");Iterator<String> iterator = list.iterator();while(iterator.hasNext()){String element = iterator.next();if ("猪八戒".equals(element)){list.add("白龙马");}}System.out.println(list);}
}
String element = iterator.next();
=========================================
private class Itr implements Iterator<E> {int cursor; // index of next element to returnint lastRet = -1; // index of last element returned; -1 if no such/*modCount: 实际操作次数expectedModCount:预期操作次数*/int expectedModCount = modCount;@SuppressWarnings("unchecked")public E next() {checkForComodification();} final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}
}
结论:当预期操作次数和实际操作次数不相等了,会出现"并发修改异常"
我们干了什么事儿,让实际操作次数和预期操作次数不相等了
list.add("白龙马")
====================================
public boolean add(E e) {modCount++;//实际操作次数+1
}
====================================
最终结论:我们调用了add方法,而add方法底层只给modCount++,但是再次调用next方法的时候,并没有给修改后的modCount重新赋值给expectedModCount,导致next方法底层的判断判断出实际操作次数和预期操作次数不相等了,所以抛出了"并发修改异常"
ArrayList中的方法:ListIterator listIterator()
public class Demo03Iterator {public static void main(String[] args) {//需求:定义一个集合,存储 唐僧,孙悟空,猪八戒,沙僧,遍历集合,如果遍历到猪八戒,往集合中添加一个白龙马ArrayList<String> list = new ArrayList<>();list.add("唐僧");list.add("孙悟空");list.add("猪八戒");list.add("沙僧");//Iterator<String> iterator = list.iterator();ListIterator<String> listIterator = list.listIterator();while(listIterator.hasNext()){String element = listIterator.next();if ("猪八戒".equals(element)){listIterator.add("白龙马");}}System.out.println(list);} }使用迭代器迭代集合的过程中,不要随意修改集合长度,容易出现并发修改异常
第四章.数据结构
数据结构是一种具有一定逻辑关系,在计算机中应用某种存储结构,并且封装了相应操作的数据元素集合。它包含三方面的内容,逻辑关系、存储关系及操作。
为什么需要数据结构
随着应用程序变得越来越复杂和数据越来越丰富,几百万、几十亿甚至几百亿的数据就会出现,而对这么大对数据进行搜索、插入或者排序等的操作就越来越慢,数据结构就是用来解 决这些问题的。
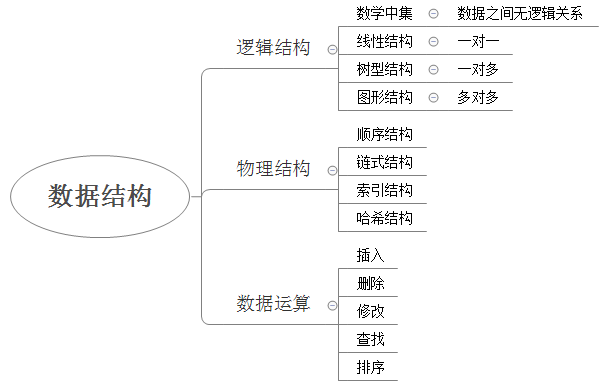
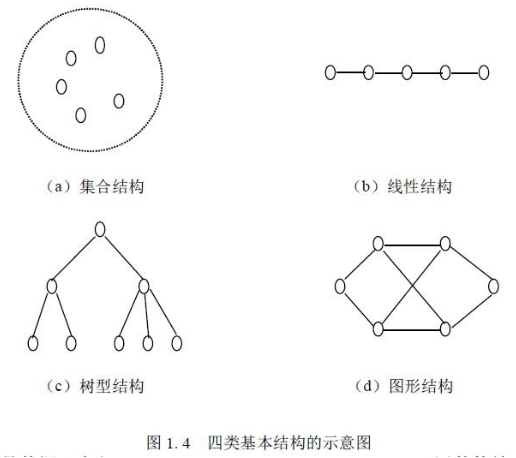
数据的逻辑结构指反映数据元素之间的逻辑关系,而与他们在计算机中的存储位置无关:
- 集合(数学中集合的概念):数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;
- 线性结构:数据结构中的元素存在一对一的相互关系;
- 树形结构:数据结构中的元素存在一对多的相互关系;
- 图形结构:数据结构中的元素存在多对多的相互关系。
数据的物理结构/存储结构:是描述数据具体在内存中的存储(如:顺序结构、链式结构、索引结构、哈希结构)等,一种数据逻辑结构可表示成一种或多种物理存储结构。
数据结构是一门完整并且复杂的课程,那么我们今天只是简单的讨论常见的几种数据结构,让我们对数据结构与算法有一个初步的了解。
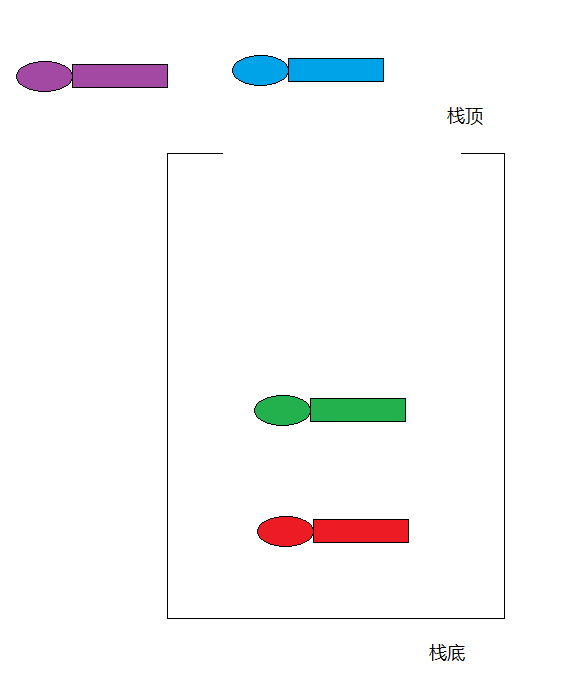
1.栈
1.特点:先进后出
2.好比:手枪压子弹
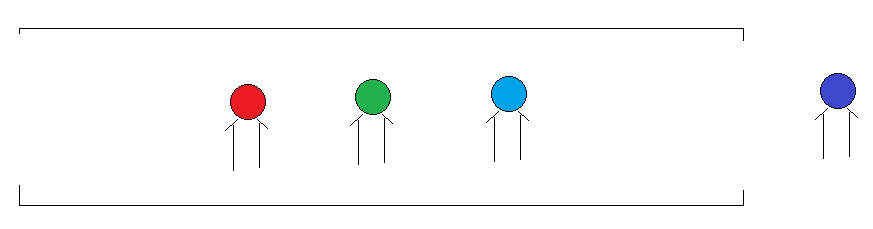
2.队列
1.特点:先进先出
2.好比:过安检
3.数组
1.特点:查询快,增删慢
2.查询快:因为有索引,我们可以直接通过索引操作元素增删慢:因为数组定长a.添加元素:创建新数组,将老数组中的元素复制到新数组中去,在最后添加新元素;要是从中间插入就更麻烦了插入完新元素,后面的元素都要往后移动b.删除元素:创建新数组,将老数组中的元素复制到新数组中去,被删除的元素就不复制了;如果要是从之间删除被删除的元素后面的元素都要往前移动
4.链表
1.在集合中涉及到了两种链表
2.单向链表a.节点:一个节点分为两部分第一部分:数据域(存数据)第二部分:指针域(保存下一个节点地址)b.特点:前面节点记录后面节点的地址,但是后面节点地址不记录前面节点地址3.双向链表:a.节点:一个节点分为三部分第一部分:指针域(保存上一个节点地址)第二部分:数据域(保存的数据)第三部分:指针域(保存下一个节点地址)b.特点:前面节点记录后面节点地址,后面节点也记录前面节点地址4.链表结构特点:查询慢,增删快
4.1单向链表
a.节点:一个节点分为两部分第一部分:数据域(存数据)第二部分:指针域(保存下一个节点地址)
b.特点:前面节点记录后面节点的地址,但是后面节点地址不记录前面节点地址
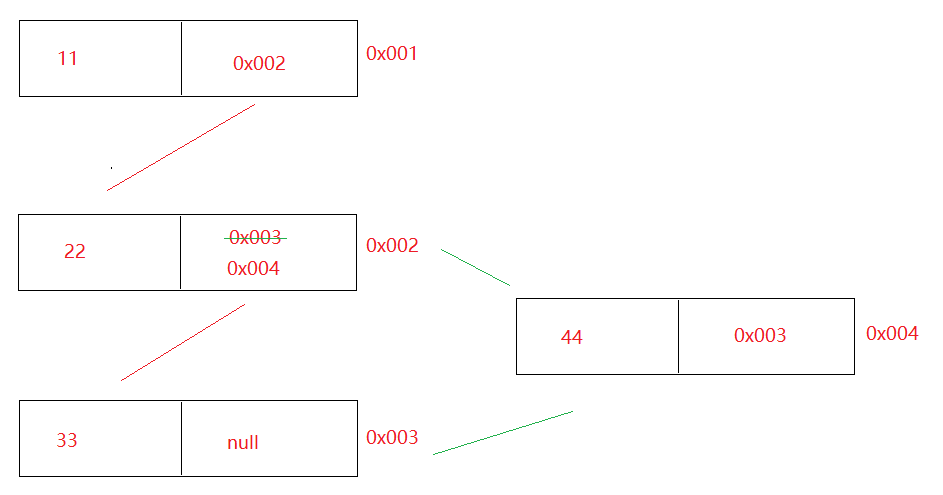
4.2双向链表
a.节点:一个节点分为三部分第一部分:指针域(保存上一个节点地址)第二部分:数据域(保存的数据)第三部分:指针域(保存下一个节点地址)b.特点:前面节点记录后面节点地址,后面节点也记录前面节点地址

第五章.List接口
1.概述:是Collection接口的子接口
2.常见的实现类:ArrayList LinkedList Vector
第六章.List集合下的实现类
1.ArrayList集合
1.概述:ArrayList是List接口的实现类
2.特点:a.元素有序-> 按照什么顺序存的,就按照什么顺序取b.元素可重复c.有索引-> 可以利用索引去操作元素d.线程不安全3.数据结构:数组
4.常用方法:boolean add(E e) -> 将元素添加到集合中->尾部(add方法一定能添加成功的,所以我们不用boolean接收返回值)void add(int index, E element) ->在指定索引位置上添加元素boolean remove(Object o) ->删除指定的元素,删除成功为true,失败为falseE remove(int index) -> 删除指定索引位置上的元素,返回的是被删除的那个元素E set(int index, E element) -> 将指定索引位置上的元素,修改成后面的element元素E get(int index) -> 根据索引获取元素int size() -> 获取集合元素个数
1.1.ArrayList集合使用
public class Demo01ArrayList {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();//boolean add(E e) -> 将元素添加到集合中->尾部(add方法一定能添加成功的,所以我们不用boolean接收返回值)list.add("铁胆火车侠");list.add("喜洋洋");list.add("火影忍者");list.add("灌篮高手");list.add("网球王子");System.out.println(list);//void add(int index, E element) ->在指定索引位置上添加元素list.add(2,"涛哥");System.out.println(list);//boolean remove(Object o) ->删除指定的元素,删除成功为true,失败为falselist.remove("涛哥");System.out.println(list);//E remove(int index) -> 删除指定索引位置上的元素,返回的是被删除的那个元素String element = list.remove(0);System.out.println(element);System.out.println(list);//E set(int index, E element) -> 将指定索引位置上的元素,修改成后面的element元素String element2 = list.set(0, "金莲");System.out.println(element2);System.out.println(list);//E get(int index) -> 根据索引获取元素System.out.println(list.get(0));//int size() -> 获取集合元素个数System.out.println(list.size());}
}public class Demo02ArrayList {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("铁胆火车侠");list.add("喜洋洋");list.add("火影忍者");list.add("灌篮高手");list.add("网球王子");Iterator<String> iterator = list.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println("=====================");for (int i = 0;i<list.size();i++){System.out.println(list.get(i));}System.out.println("=====================");/*遍历带有索引集合的快捷键集合名.fori*/for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}}
}public class Demo03ArrayList {public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>();list.add(2);System.out.println(list);/*需求:删除2remove(Object o) -> 直接删除指定元素remove(int index) -> 删除指定索引位置上的元素如果remove中直接传递整数,默认调用按照指定索引删除元素的remove但是此时list中没有2索引,所以越界解决:我们可以将2包装成包装类,变成包装类之后,其父类就是Object了,*///list.remove(2);list.remove(Integer.valueOf(2));System.out.println(list);} }
1.2.底层源码分析
1.ArrayList构造方法:a.ArrayList() 构造一个初始容量为十的空列表b.ArrayList(int initialCapacity) 构造具有指定初始容量的空列表 2.ArrayList源码总结:a.不是一new底层就会创建初始容量为10的空列表,而是第一次add的时候才会创建初始化容量为10的空列表b.ArrayList底层是数组,那么为啥还说集合长度可变呢?ArrayList底层会自动扩容-> Arrays.copyOf c.扩容多少倍?1.5倍
ArrayList() 构造一个初始容量为十的空列表
=========================================
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
Object[] elementData; ->ArrayList底层的那个数组public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
} =========================================
list.add("a");public boolean add(E e) {modCount++;add(e, elementData, size);// e->要存的元素 elementData->集合数组,长度开始为0,size->0return true;
}private void add(E e->元素, Object[] elementData->集合数组, int s->0) {if (s == elementData.length)elementData = grow();elementData[s] = e;size = s + 1;
}private Object[] grow() {return grow(size + 1);
}private Object[] grow(int minCapacity->1) {int oldCapacity = elementData.length;//0if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {return elementData = new Object[Math.max(DEFAULT_CAPACITY->10, minCapacity->1)];}
}
==========================================
假设ArrayList中存了第11个元素,会自动扩容-> Arrays.copyOfprivate Object[] grow(int minCapacity) {//11int oldCapacity = elementData.length;//10if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {int newCapacity(15) = ArraysSupport.newLength(oldCapacity->10,minCapacity - oldCapacity->1, /* minimum growth */oldCapacity >> 1 ->5 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}
} public static int newLength(int oldLength->10, int minGrowth->1, int prefGrowth->5) {// preconditions not checked because of inlining// assert oldLength >= 0// assert minGrowth > 0int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // 15if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {return prefLength;} else {// put code cold in a separate methodreturn hugeLength(oldLength, minGrowth);}
}
ArrayList(int initialCapacity) 构造具有指定初始容量的空列表
ArrayList<String> list = new ArrayList<>(5);
==============================================
public ArrayList(int initialCapacity->5) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];//直接创建长度为5的数组} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}
}
ArrayList list = new ArrayList() -> 现在我们想用都是new
但是将来开发不会想使用就new集合,都是调用一个方法,查询出很多数据来,此方法返回一个集合,自动将查询出来的数据放到集合中,我们想在页面上展示数据,遍历集合
而且将来调用方法,返回的集合类型,一般都是接口类型
List<泛型> list = 对象.查询方法()
第七章.LinkedList集合
1.概述:LinkedList是List接口的实现类
2.特点:a.元素有序b.元素可重复c.有索引 -> 这里说的有索引仅仅指的是有操作索引的方法,不代表本质上具有索引d.线程不安全3.数据结构:双向链表 4.方法:有大量直接操作首尾元素的方法- public void addFirst(E e):将指定元素插入此列表的开头。- public void addLast(E e):将指定元素添加到此列表的结尾。- public E getFirst():返回此列表的第一个元素。- public E getLast():返回此列表的最后一个元素。- public E removeFirst():移除并返回此列表的第一个元素。- public E removeLast():移除并返回此列表的最后一个元素。- public E pop():从此列表所表示的堆栈处弹出一个元素。- public void push(E e):将元素推入此列表所表示的堆栈。- public boolean isEmpty():如果列表没有元素,则返回true。
public class Demo05LinkedList {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("吕布");linkedList.add("刘备");linkedList.add("关羽");linkedList.add("张飞");linkedList.add("貂蝉");System.out.println(linkedList);linkedList.addFirst("孙尚香");System.out.println(linkedList);linkedList.addLast("董卓");System.out.println(linkedList);System.out.println(linkedList.getFirst());System.out.println(linkedList.getLast());linkedList.removeFirst();System.out.println(linkedList);linkedList.removeLast();System.out.println(linkedList);System.out.println("======================");Iterator<String> iterator = linkedList.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println("=======================");for (int i = 0; i < linkedList.size(); i++) {System.out.println(linkedList.get(i));}}
}public E pop():从此列表所表示的堆栈处弹出一个元素。
public void push(E e):将元素推入此列表所表示的堆栈。
public class Demo06LinkedList {public static void main(String[] args) {LinkedList<String> linkedList = new LinkedList<>();linkedList.add("吕布");linkedList.add("刘备");linkedList.add("关羽");linkedList.add("张飞");linkedList.add("貂蝉");//public E pop():从此列表所表示的堆栈处弹出一个元素。linkedList.pop();System.out.println(linkedList);//public void push(E e):将元素推入此列表所表示的堆栈。linkedList.push("涛哥");System.out.println(linkedList);}
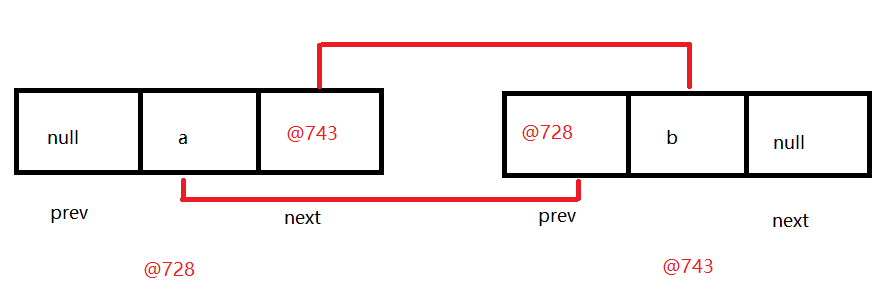
}1.1 LinkedList底层成员解释说明
1.LinkedList底层成员transient int size = 0; 元素个数transient Node<E> first; 第一个节点对象transient Node<E> last; 最后一个节点对象2.Node代表的是节点对象private static class Node<E> {E item;//节点上的元素Node<E> next;//记录着下一个节点地址Node<E> prev;//记录着上一个节点地址Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
1.2 LinkedList中add方法源码分析
LinkedList<String> list = new LinkedList<>();
list.add("a");
list.add("b"); void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;
}
1.3.LinkedList中get方法源码分析
public E get(int index) {checkElementIndex(index);return node(index).item;
} Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}
index < (size >> 1)采用二分思想,先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历
第八章.增强for
1.基本使用
1.作用:遍历集合或者数组
2.格式:for(元素类型 变量名:要遍历的集合名或者数组名){变量名就是代表的每一个元素}3.快捷键:集合名或者数组名.for
public class Demo01ForEach {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("张三");list.add("李四");list.add("王五");list.add("赵六");for (String s : list) {System.out.println(s);}System.out.println("=====================");int[] arr = {1,2,3,4,5};for (int i : arr) {System.out.println(i);}}
}2.注意
1.增强for遍历集合时,底层实现原理为迭代器
2.增强for遍历数组时,底层实现原理为普通for

所以不管是用迭代器还是使用增强for,在遍历集合的过程中都不要随意修改集合长度,否则会出现并发修改异常
模块19.集合
模块18回顾:1.Collection集合:单列集合的顶级接口a.add addAll clear size isEmpty remove toArray contains2.迭代器:Iteratora.获取:iterator方法b.方法:hasNext()next()c.并发修改异常:在迭代集合的时候,不能随意修改集合长度原因:调用add,只给实际操作次数+1.后面调用next的时候,没有给预期操作次数重新赋值,导致预期操作次数和实际操作次数不相等了3.数据结构:栈:先进后出队列:先进先出数组:查询快,增删慢链表:查询慢,增删快4.ArrayLista.特点:元素有序,有索引,元素可重复,线程不安全b.数据结构:数组c.方法:add(元素)直接在最后添加元素add(索引,元素)在指定索引位置上添加元素remove(元素)删除指定元素remove(索引)按照指定索引删除元素size()获取元素个数get(索引)根据索引获取元素set(索引,元素)将指定索引位置上的元素修改成我们指定的元素d.利用无参构造创建集合对象,第一次add时,会创建一个长度为10的空数组超出范围,自动扩容->Arrays.copyOf扩容1.5倍5.LinkedLista.特点: 元素有序 有索引(java提供了按照索引操作元素的方法,并不代表本质上拥有索引),元素可重复,线程不安全b.数据结构:双向链表c.方法:有大量直接操作收尾元素的方法6.增强for:a.格式:for(元素类型 变量名:集合名或者数组名){变量就代表每一个元素}b.原理:遍历集合时,原理为迭代器遍历数组时,原理为普通for模块19重点:1.会Collections集合工具类的常用方法2.会使用泛型3.知道HashSet和LinkedHashSet的特点以及使用4.知道HashSet将元素去重复的过程
第一章.Collections集合工具类
1.概述:集合工具类
2.特点:a.构造私有b.方法都是静态的3.使用:类名直接调用4.方法:static <T> boolean addAll(Collection<? super T> c, T... elements)->批量添加元素 static void shuffle(List<?> list) ->将集合中的元素顺序打乱static <T> void sort(List<T> list) ->将集合中的元素按照默认规则排序static <T> void sort(List<T> list, Comparator<? super T> c)->将集合中的元素按照指定规则排序
public class Demo01Collections {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();//static <T> boolean addAll(Collection<? super T> c, T... elements)->批量添加元素Collections.addAll(list,"张三","李四","王五","赵六","田七","朱八");System.out.println(list);//static void shuffle(List<?> list) ->将集合中的元素顺序打乱Collections.shuffle(list);System.out.println(list);//static <T> void sort(List<T> list) ->将集合中的元素按照默认规则排序-> ASCII码表ArrayList<String> list1 = new ArrayList<>();list1.add("c.举头望明月");list1.add("a.床前明月光");list1.add("d.低头思故乡");list1.add("b.疑是地上霜");Collections.sort(list1);System.out.println(list1);}
}1.方法:static <T> void sort(List<T> list, Comparator<? super T> c)->将集合中的元素按照指定规则排序2.Comparator比较器a.方法:int compare(T o1,T o2)o1-o2 -> 升序o2-o1 -> 降序
public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class Demo02Collections {public static void main(String[] args) {ArrayList<Person> list = new ArrayList<>();list.add(new Person("柳岩",18));list.add(new Person("涛哥",16));list.add(new Person("金莲",20));Collections.sort(list, new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge()-o2.getAge();}});System.out.println(list);}
}1.接口:Comparable接口
2.方法: int compareTo(T o) -> this-o (升序) o-this(降序)
public class Student implements Comparable<Student>{private String name;private Integer score;public Student() {}public Student(String name, Integer score) {this.name = name;this.score = score;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getScore() {return score;}public void setScore(Integer score) {this.score = score;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", score=" + score +'}';}@Overridepublic int compareTo(Student o) {return this.getScore()-o.getScore();}
}public class Demo03Collections {public static void main(String[] args) {ArrayList<Student> list = new ArrayList<>();list.add(new Student("涛哥",100));list.add(new Student("柳岩",150));list.add(new Student("三上",80));Collections.sort(list);System.out.println(list);}
}Arrays中的静态方法:static <T> List<T> asList(T...a) -> 直接指定元素,转存到list集合中public class Demo04Collections {public static void main(String[] args) {List<String> list = Arrays.asList("张三", "李四", "王五");System.out.println(list);} }
第二章.泛型
1.泛型:<>
2.作用:统一数据类型,防止将来的数据转换异常
3.注意:a.泛型中的类型必须是引用类型b.如果泛型不写,默认类型为Object
1.为什么要使用泛型
1.从使用层面上来说:统一数据类型,防止将来的数据类型转换异常
2.从定义层面上来看:定义带泛型的类,方法等,将来使用的时候给泛型确定什么类型,泛型就会变成什么类型,凡是涉及到泛型的都会变成确定的类型,代码更灵活
public class Demo01Genericity {public static void main(String[] args) {ArrayList list = new ArrayList();list.add("1");list.add(1);list.add("abc");list.add(2.5);list.add(true);//获取元素中为String类型的字符串长度for (Object o : list) {String s = (String) o;System.out.println(s.length());//ClassCastException}}
}
{obj[size] = e;size++;return true;}/*** 定义一个get方法,根据索引获取元素*/public E get(int index){return (E) obj[index];}@Overridepublic String toString() {return Arrays.toString(obj);}
}
public class Demo02Genericity {public static void main(String[] args) {MyArrayList<String> list1 = new MyArrayList<>();list1.add("aaa");list1.add("bbb");System.out.println(list1);//直接输出对象名,默认调用toStringSystem.out.println("===========");MyArrayList<Integer> list2 = new MyArrayList<>();list2.add(1);list2.add(2);Integer element = list2.get(0);System.out.println(element);System.out.println(list2);}
}2.2含有泛型的方法
1.格式:修饰符 <E> 返回值类型 方法名(E e)2.什么时候确定类型调用的时候确定类型
public class ListUtils {//定义一个静态方法addAll,添加多个集合的元素public static <E> void addAll(ArrayList<E> list,E...e){for (E element : e) {list.add(element);}}}
public class Demo03Genericity {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();ListUtils.addAll(list1,"a","b","c");System.out.println(list1);System.out.println("================");ArrayList<Integer> list2 = new ArrayList<>();ListUtils.addAll(list2,1,2,3,4,5);System.out.println(list2);}
}2.3含有泛型的接口
1.格式:public interface 接口名<E>{}
2.什么时候确定类型:a.在实现类的时候还没有确定类型,只能在new实现类的时候确定类型了 ->比如 ArrayListb.在实现类的时候直接确定类型了 -> 比如Scanner
public interface MyList <E>{public boolean add(E e);
}
public class MyArrayList1<E> implements MyList<E>{//定义一个数组,充当ArrayList底层的数组,长度直接规定为10Object[] obj = new Object[10];//定义size,代表集合元素个数int size;/*** 定义一个add方法,参数类型需要和泛型类型保持一致** 数据类型为E 变量名随便取*/public boolean add(E e){obj[size] = e;size++;return true;}/*** 定义一个get方法,根据索引获取元素*/public E get(int index){return (E) obj[index];}@Overridepublic String toString() {return Arrays.toString(obj);}
}public class Demo04Genericity {public static void main(String[] args) {MyArrayList1<String> list1 = new MyArrayList1<>();list1.add("张三");list1.add("李四");System.out.println(list1.get(0));}
}
public interface MyIterator <E>{E next();
}public class MyScanner implements MyIterator<String>{@Overridepublic String next() {return "涛哥和金莲的故事";}
}public class Demo05Genericity {public static void main(String[] args) {MyScanner myScanner = new MyScanner();String result = myScanner.next();System.out.println("result = " + result);}
}3.泛型的高级使用
3.1 泛型通配符 ?
public class Demo01Genericity {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();list1.add("张三");list1.add("李四");ArrayList<Integer> list2 = new ArrayList<>();list2.add(1);list2.add(2);method(list1);method(list2);}public static void method(ArrayList<?> list){for (Object o : list) {System.out.println(o);}}}
3.2 泛型的上限下限
1.作用:可以规定泛型的范围
2.上限:a.格式:<? extends 类型>b.含义:?只能接收extends后面的本类类型以及子类类型
3.下限:a.格式:<? super 类型>b.含义:?只能接收super后面的本类类型以及父类类型
/*** Integer -> Number -> Object* String -> Object*/
public class Demo02Genericity {public static void main(String[] args) {ArrayList<Integer> list1 = new ArrayList<>();ArrayList<String> list2 = new ArrayList<>();ArrayList<Number> list3 = new ArrayList<>();ArrayList<Object> list4 = new ArrayList<>();get1(list1);//get1(list2);错误get1(list3);//get1(list4);错误System.out.println("=================");//get2(list1);错误//get2(list2);错误get2(list3);get2(list4);}//上限 ?只能接收extends后面的本类类型以及子类类型public static void get1(Collection<? extends Number> collection){}//下限 ?只能接收super后面的本类类型以及父类类型public static void get2(Collection<? super Number> collection){}
}应用场景:
1.如果我们在定义类,方法,接口的时候,如果类型不确定,我们可以考虑定义含有泛型的类,方法,接口
2.如果类型不确定,但是能知道以后只能传递某个类的继承体系中的子类或者父类,就可以使用泛型的通配符
第三章.斗地主案例(扩展案例)
3.1 案例介绍
按照斗地主的规则,完成洗牌发牌的动作。
具体规则:
使用54张牌打乱顺序,三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
3.2 案例分析
-
准备牌:
牌可以设计为一个ArrayList,每个字符串为一张牌。
每张牌由花色数字两部分组成,我们可以使用花色集合与数字集合嵌套迭代完成每张牌的组装。
牌由Collections类的shuffle方法进行随机排序。 -
发牌
将每个人以及底牌设计为ArrayList,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
-
看牌
直接打印每个集合。

3.3 代码实现
1.创建ArrayList集合-> color -> 专门存花色
2.创建一个ArrayList集合 -> number -> 专门存牌号
3.创建一个ArrayList集合 -> poker -> 专门存花色和牌号组合好的牌面
4.打乱poker
5.创建4个ArrayList集合,分别代表三个玩家,以及存储一个底牌
6.如果index为最后三张,往dipai集合中存
7.如果index%3==0 给p1
8.如果index%3==1 给p2
9.如果index%3==2 给p3
10.遍历看牌
public class Poker {public static void main(String[] args) {//1.创建ArrayList集合-> color -> 专门存花色ArrayList<String> color = new ArrayList<>();//2.创建一个ArrayList集合 -> number -> 专门存牌号ArrayList<String> number = new ArrayList<>();//3.创建一个ArrayList集合 -> poker -> 专门存花色和牌号组合好的牌面ArrayList<String> poker = new ArrayList<>();color.add("♠");color.add("♥");color.add("♣");color.add("♦");for (int i = 2; i <= 10; i++) {number.add(i + "");}number.add("J");number.add("Q");number.add("K");number.add("A");//System.out.println(color);//System.out.println(number);for (String num : number) {for (String huaSe : color) {String pokerNumber = huaSe + num;poker.add(pokerNumber);}}poker.add("😊");poker.add("☺");//System.out.println(poker);//4.打乱pokerCollections.shuffle(poker);//System.out.println(poker);//5.创建4个ArrayList集合,分别代表三个玩家,以及存储一个底牌ArrayList<String> p1 = new ArrayList<>();ArrayList<String> p2 = new ArrayList<>();ArrayList<String> p3 = new ArrayList<>();ArrayList<String> dipai = new ArrayList<>();for (int i = 0; i < poker.size(); i++) {String s = poker.get(i);//6.如果index为最后三张,往dipai集合中存if (i >= 51) {dipai.add(s);//7.如果index%3==0 给p1} else if (i % 3 == 0) {p1.add(s);//8.如果index%3==1 给p2} else if (i % 3 == 1) {p2.add(s);//9.如果index%3==2 给p3}else if (i%3==2){p3.add(s);}}//10.遍历看牌System.out.println("涛哥:"+p1);System.out.println("三上:"+p2);System.out.println("金莲:"+p3);System.out.println("底牌:"+dipai);}
}
public class Poker1 {public static void main(String[] args) {//1.创建数组-> color -> 专门存花色String[] color = "♠-♥-♣-♦".split("-");//2.创建数组 -> number -> 专门存牌号String[] number = "2-3-4-5-6-7-8-9-10-J-Q-K-A".split("-");//3.创建一个ArrayList集合 -> poker -> 专门存花色和牌号组合好的牌面ArrayList<String> poker = new ArrayList<>();//System.out.println(color);//System.out.println(number);for (String num : number) {for (String huaSe : color) {String pokerNumber = huaSe + num;poker.add(pokerNumber);}}poker.add("😊");poker.add("☺");//System.out.println(poker);//4.打乱pokerCollections.shuffle(poker);//System.out.println(poker);//5.创建4个ArrayList集合,分别代表三个玩家,以及存储一个底牌ArrayList<String> p1 = new ArrayList<>();ArrayList<String> p2 = new ArrayList<>();ArrayList<String> p3 = new ArrayList<>();ArrayList<String> dipai = new ArrayList<>();for (int i = 0; i < poker.size(); i++) {String s = poker.get(i);//6.如果index为最后三张,往dipai集合中存if (i >= 51) {dipai.add(s);//7.如果index%3==0 给p1} else if (i % 3 == 0) {p1.add(s);//8.如果index%3==1 给p2} else if (i % 3 == 1) {p2.add(s);//9.如果index%3==2 给p3}else if (i%3==2){p3.add(s);}}//10.遍历看牌System.out.println("涛哥:"+p1);System.out.println("三上:"+p2);System.out.println("金莲:"+p3);System.out.println("底牌:"+dipai);}
}第四章.红黑树(了解)
集合加入红黑树的目的:提高查询效率
HashSet集合:数据结构:哈希表jdk8之前:哈希表 = 数组+链表jdk8之后:哈希表 = 数组+链表+红黑树 ->为的是查询效率
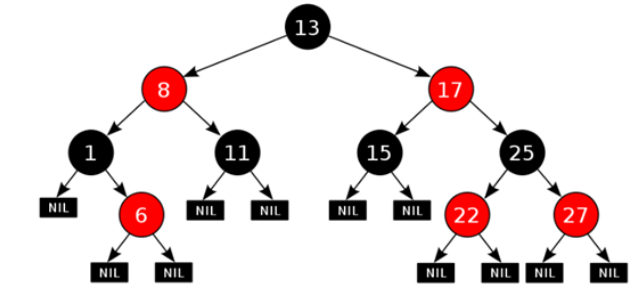
1. 每一个节点或是红色的,或者是黑色的2. 根节点必须是黑色3. 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的4. 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连 的情况)5. 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
https://www.cs.usfca.edu/~galles/visualization/RedBlack
第五章.Set集合
1.涛哥总说:Set接口并没有对Collection接口进行功能上的扩充,而且所有的Set集合底层都是依靠Map实现
1.Set集合介绍
Set和Map密切相关的
Map的遍历需要先变成单列集合,只能变成set集合
2.HashSet集合的介绍和使用
1.概述:HashSet是Set接口的实现类
2.特点:a.元素唯一b.元素无序c.无索引d.线程不安全
3.数据结构:哈希表a.jdk8之前:哈希表 = 数组+链表b.jdk8之后:哈希表 = 数组+链表+红黑树加入红黑树目的:查询快
4.方法:和Collection一样
5.遍历:a.增强forb.迭代器
public class Demo01HashSet {public static void main(String[] args) {HashSet<String> set = new HashSet<>();set.add("张三");set.add("李四");set.add("王五");set.add("赵六");set.add("田七");set.add("张三");System.out.println(set);//迭代器Iterator<String> iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println("============");//增强forfor (String s : set) {System.out.println(s);}}
}3.LinkedHashSet的介绍以及使用
1.概述:LinkedHashSet extends HashSet
2.特点:a.元素唯一b.元素有序c.无索引d.线程不安全
3.数据结构:哈希表+双向链表
4.使用:和HashSet一样
public class Demo02LinkedHashSet {public static void main(String[] args) {LinkedHashSet<String> set = new LinkedHashSet<>();set.add("张三");set.add("李四");set.add("王五");set.add("赵六");set.add("田七");set.add("张三");System.out.println(set);//迭代器Iterator<String> iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println("============");//增强forfor (String s : set) {System.out.println(s);}}
}4.哈希值
1.概述:是由计算机算出来的一个十进制数,可以看做是对象的地址值
2.获取对象的哈希值,使用的是Object中的方法public native int hashCode()3.注意:如果重写了hashCode方法,那计算的就是对象内容的哈希值了4.总结:a.哈希值不一样,内容肯定不一样b.哈希值一样,内容也有可能不一样
public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo01Hash {public static void main(String[] args) {Person p1 = new Person("涛哥", 18);Person p2 = new Person("涛哥", 18);System.out.println(p1);//com.atguigu.f_hash.Person@4eec7777System.out.println(p2);//com.atguigu.f_hash.Person@3b07d329System.out.println(p1.hashCode());System.out.println(p2.hashCode());//System.out.println(Integer.toHexString(1324119927));//4eec7777//System.out.println(Integer.toHexString(990368553));//3b07d329System.out.println("======================");String s1 = "abc";String s2 = new String("abc");System.out.println(s1.hashCode());//96354System.out.println(s2.hashCode());//96354System.out.println("=========================");String s3 = "通话";String s4 = "重地";System.out.println(s3.hashCode());//1179395System.out.println(s4.hashCode());//1179395}
}如果不重写hashCode方法,默认计算对象的哈希值 如果重写了hashCode方法,计算的是对象内容的哈希值
5.字符串的哈希值时如何算出来的
String s = "abc"
byte[] value = {97,98,99}
public int hashCode() {int h = hash;if (h == 0 && !hashIsZero) {h = isLatin1() ? StringLatin1.hashCode(value): StringUTF16.hashCode(value);if (h == 0) {hashIsZero = true;} else {hash = h;}}return h;
}
====================================================
StringLatin1.hashCode(value)底层源码,String中的哈希算法public static int hashCode(byte[] value) {int h = 0;for (byte v : value) {h = 31 * h + (v & 0xff);}return h;
}
直接跑到StringLatin1.hashCode(value)底层源码,计算abc的哈希值-> 0xff这个十六进制对应的十进制255
任何数据和255做&运算,都是原值第一圈:h = 31*0+97 = 97
第二圈:h = 31*97+98 = 3105
第三圈:h = 31*3105+99 = 96354
问题:在计算哈希值的时候,有一个定值就是31,为啥?31是一个质数,31这个数通过大量的计算,统计,认为用31,可以尽量降低内容不一样但是哈希值一样的情况内容不一样,哈希值一样(哈希冲突,哈希碰撞)
6.HashSet的存储去重复的过程
1.先计算元素的哈希值(重写hashCode方法),再比较内容(重写equals方法)
2.先比较哈希值,如果哈希值不一样,存
3.如果哈希值一样,再比较内容a.如果哈希值一样,内容不一样,存b.如果哈希值一样,内容也一样,去重复
public class Test02 {public static void main(String[] args) {HashSet<String> set = new HashSet<>();set.add("abc");set.add("通话");set.add("重地");set.add("abc");System.out.println(set);//[通话, 重地, abc]}
}7.HashSet存储自定义类型如何去重复
public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class Test03 {public static void main(String[] args) {HashSet<Person> set = new HashSet<>();set.add(new Person("涛哥",16));set.add(new Person("金莲",24));set.add(new Person("涛哥",16));System.out.println(set);}
}
总结:
1.如果HashSet存储自定义类型,如何去重复呢?重写hashCode和equals方法,让HashSet比较属性的哈希值以及属性的内容
2.如果不重写hashCode和equals方法,默认调用的是Object中的,不同的对象,肯定哈希值不一样,equals比较对象的地址值也不一样,所以此时即使对象的属性值一样,也不能去重复
Map嵌套Map
- JavaSE 集合 存储的是 学号 键,值学生姓名- 1 张三- 2 李四
- JavaEE 集合 存储的是 学号 键,值学生姓名- 1 王五- 2 赵六
public class Demo03MapInMap {public static void main(String[] args) {//1.创建两个map集合HashMap<Integer, String> map1 = new HashMap<>();map1.put(1,"张三");map1.put(2,"李四");HashMap<Integer, String> map2 = new HashMap<>();map2.put(1,"王五");map2.put(2,"赵六");HashMap<String, HashMap<Integer, String>> map = new HashMap<>();map.put("javase",map1);map.put("javaee",map2);Set<Map.Entry<String, HashMap<Integer, String>>> set = map.entrySet();for (Map.Entry<String, HashMap<Integer, String>> entry : set) {HashMap<Integer, String> hashMap = entry.getValue();Set<Integer> set1 = hashMap.keySet();for (Integer key : set1) {System.out.println(key+"..."+hashMap.get(key));}}}
}模块20.Map集合
模块19回顾:1.Collections集合工具类方法:addAll-> 批量添加元素shuffle-> 元素打乱sort->排序-> asciisort(集合,比较器)-> 按照指定的顺序排序2.泛型:a.含有泛型的类:public class 类名<E>{}new对象的时候确定类型b.含有泛型的方法:修饰符 <E> 返回值类型 方法名(E e){}调用的时候确定类型c.含有泛型的接口public interface 接口名<E>{}在实现类的时候确定类型在实现类的时候还没有确定类型,只能new对象的时候确定d.泛型通配符<? extends 类型> ?接收的泛型类型是后面类的本类以及子类<? super 类型> ?接收的泛型类型是后面类的本类以及父类3.哈希值:计算机计算出来的十进制数,可以看成是对象的地址值a.要是没有重写hashCode方法,默认调用Object中的hashCode方法,计算的是对象的哈希值b.要是重写了hashCode方法,计算的是对象内容的哈希值4.HashSet集合特点: 元素唯一 无序 无索引 线程不安全数据结构: 哈希表 = 数组+链表+红黑树5.LinkedHashSet特点:元素唯一 有序 无索引 线程不安全 数据结构: 哈希表+双向链表6.set存储自定义对象怎么去重复 -> 重写hashCode和equals方法7.去重复过程:先比较元素哈希值,再比较内容如果哈希值不一样,存如果哈希值一样,再比较内容->哈希值一样,内容不一样,存;哈希值一样,内容一样,去重复模块20重点:1.会使用HashMap和LinkedHashMap以及知道他们的特点2.会使用Properties属性集3.会操作集合嵌套4.知道哈希表结构存储元素过程
第一章.Map集合
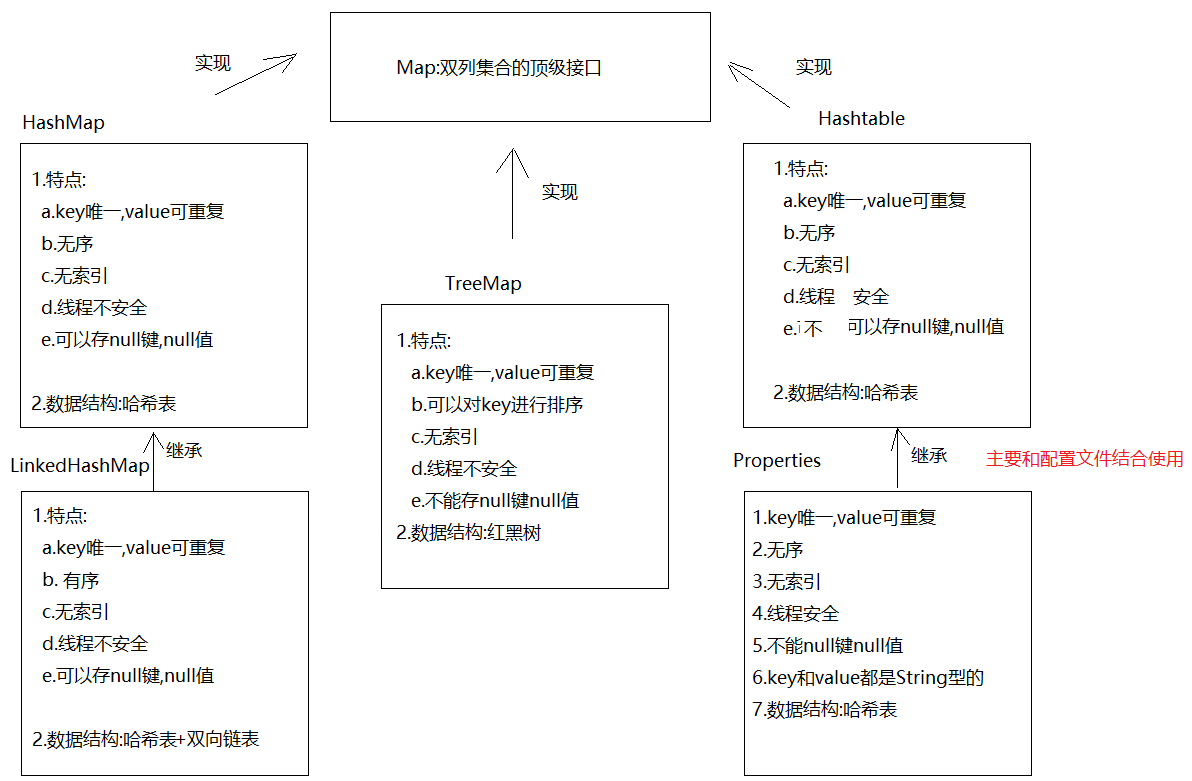
1.Map的介绍
1.概述:是双列集合的顶级接口
2.元素特点:元素都是由key(键),value(值)组成 -> 键值对
2.HashMap的介绍和使用
1.概述:HashMap是Map的实现类
2.特点:a.key唯一,value可重复 -> 如果key重复了,会发生value覆盖b.无序c.无索引d.线程不安全e.可以存null键null值
3.数据结构:哈希表
4.方法:V put(K key, V value) -> 添加元素,返回的是V remove(Object key) ->根据key删除键值对,返回的是被删除的valueV get(Object key) -> 根据key获取valueboolean containsKey(Object key) -> 判断集合中是否包含指定的keyCollection<V> values() -> 获取集合中所有的value,转存到Collection集合中Set<K> keySet()->将Map中的key获取出来,转存到Set集合中 Set<Map.Entry<K,V>> entrySet()->获取Map集合中的键值对,转存到Set集合中
public class Demo01HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();//V put(K key, V value) -> 添加元素,返回的是被覆盖的valueString value1 = map.put("猪八", "嫦娥");System.out.println(value1);String value2 = map.put("猪八", "高翠兰");System.out.println(value2);System.out.println(map);map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");map.put(null,null);System.out.println(map);//V remove(Object key) ->根据key删除键值对,返回的是被删除的valueString value3 = map.remove("涛哥");System.out.println(value3);System.out.println(map);//V get(Object key) -> 根据key获取valueSystem.out.println(map.get("唐僧"));//boolean containsKey(Object key) -> 判断集合中是否包含指定的keySystem.out.println(map.containsKey("二郎神"));//Collection<V> values() -> 获取集合中所有的value,转存到Collection集合中Collection<String> collection = map.values();System.out.println(collection);}
}1.概述:LinkedHashMap extends HashMap
2.特点:a.key唯一,value可重复 -> 如果key重复了,会发生value覆盖b.有序c.无索引d.线程不安全e.可以存null键null值
3.数据结构:哈希表+双向链表
4.使用:和HashMap一样
public class Demo02LinkedHashMap {public static void main(String[] args) {LinkedHashMap<String, String> map = new LinkedHashMap<>();map.put("八戒","嫦娥");map.put("涛哥","金莲");map.put("涛哥","三上");map.put("唐僧","女儿国国王");System.out.println(map);}
}3.HashMap的两种遍历方式
3.1.方式1:获取key,根据key再获取value
Set<K> keySet()->将Map中的key获取出来,转存到Set集合中
public class Demo03HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();map.put("猪八", "嫦娥");map.put("猪八", "高翠兰");map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");Set<String> set = map.keySet();//获取所有的key,保存到set集合中for (String key : set) {//根据key获取valueSystem.out.println(key+".."+map.get(key));}}
}
3.2.方式2:同时获取key和value
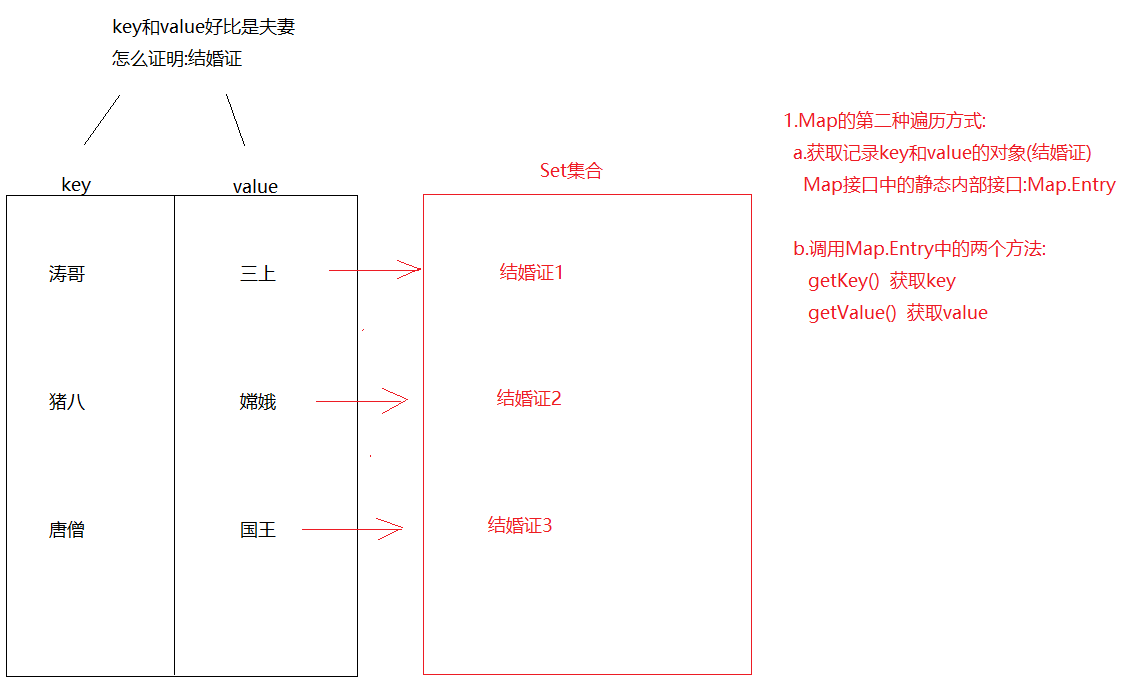
Set<Map.Entry<K,V>> entrySet()->获取Map集合中的键值对,转存到Set集合中
public class Demo04HashMap {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();map.put("猪八", "嫦娥");map.put("猪八", "高翠兰");map.put("后裔","嫦娥");map.put("二郎神","嫦娥");map.put("唐僧","女儿国国王");map.put("涛哥","金莲");/*Set集合中保存的都是"结婚证"-> Map.Entry我们需要将"结婚证"从set集合中遍历出来*/Set<Map.Entry<String, String>> set = map.entrySet();for (Map.Entry<String, String> entry : set) {String key = entry.getKey();String value = entry.getValue();System.out.println(key+"..."+value);}}
}
1.Map存储自定义对象时如何去重复
public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo05HashMap {public static void main(String[] args) {HashMap<Person, String> map = new HashMap<>();map.put(new Person("涛哥",18),"河北省");map.put(new Person("三上",26),"日本");map.put(new Person("涛哥",18),"北京市");System.out.println(map);}
}
如果key为自定义类型,去重复的话,重写hashCode和equals方法,去重复过程和set一样一样的
因为set集合的元素到了底层都是保存到了map的key位置上
2.Map的练习
需求:用Map集合统计字符串中每一个字符出现的次数
步骤:1.创建Scanner和HashMap2.遍历字符串,将每一个字符获取出来3.判断,map中是否包含遍历出来的字符 -> containsKey4.如果不包含,证明此字符第一次出现,直接将此字符和1存储到map中5.如果包含,根据字符获取对应的value,让value++6.将此字符和改变后的value重新保存到map集合中7.输出
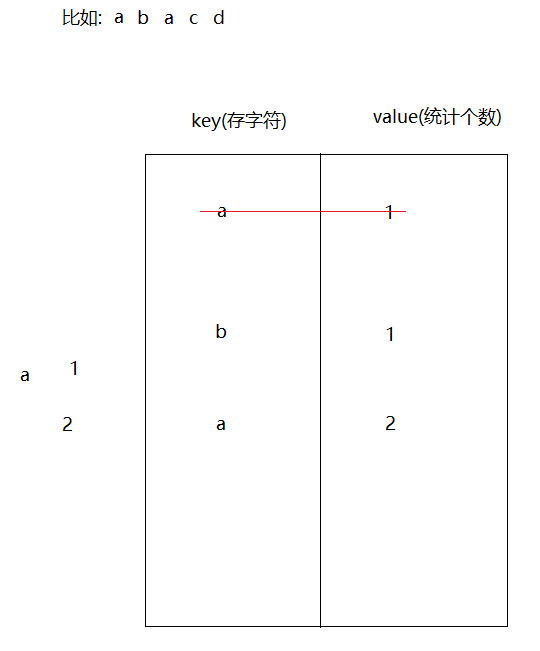
public class Demo06HashMap {public static void main(String[] args) {//1.创建Scanner和HashMapScanner sc = new Scanner(System.in);HashMap<String, Integer> map = new HashMap<>();String data = sc.next();//2.遍历字符串,将每一个字符获取出来char[] chars = data.toCharArray();for (char aChar : chars) {String key = aChar+"";//3.判断,map中是否包含遍历出来的字符 -> containsKeyif (!map.containsKey(key)){//4.如果不包含,证明此字符第一次出现,直接将此字符和1存储到map中map.put(key,1);}else{//5.如果包含,根据字符获取对应的value,让value++//6.将此字符和改变后的value重新保存到map集合中Integer value = map.get(key);value++;map.put(key,value);}}//7.输出System.out.println(map);}
}3.斗地主_Map版本
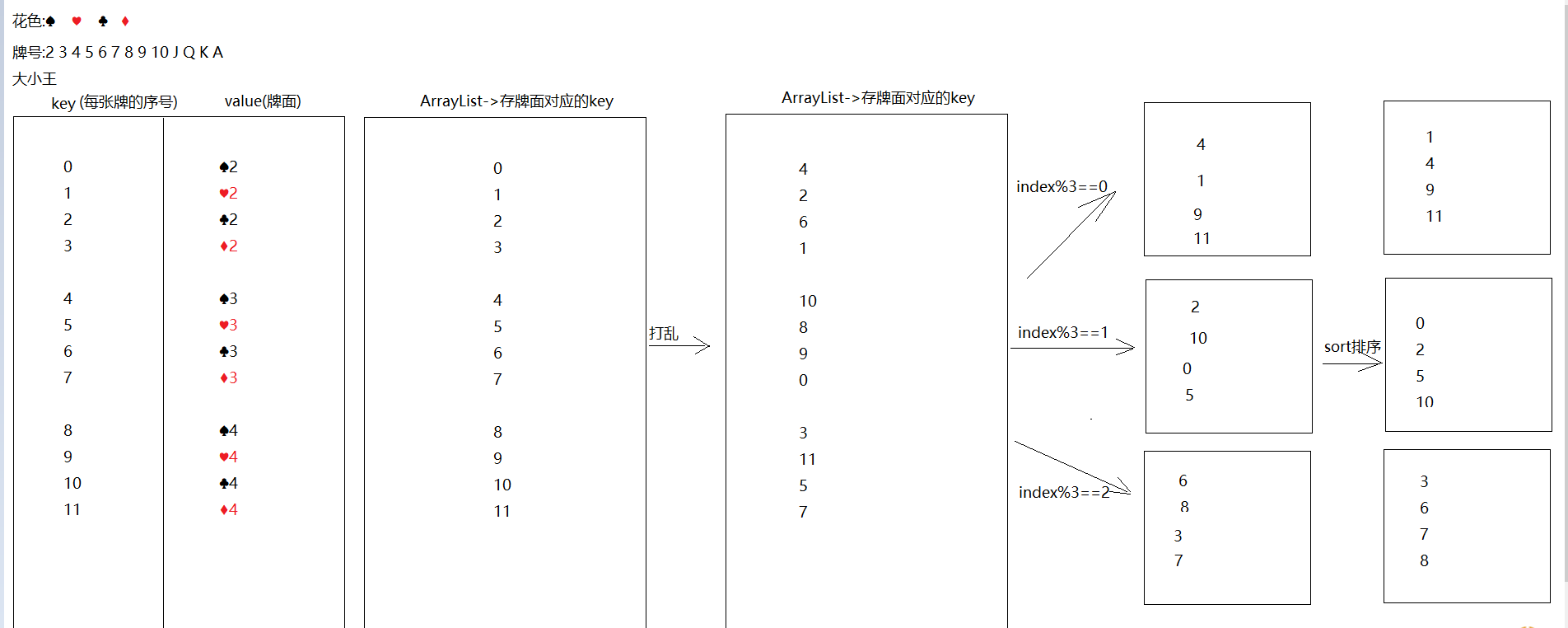
public class Demo07Poker {public static void main(String[] args) {//1.创建数组-> color -> 专门存花色String[] color = "♠-♥-♣-♦".split("-");//2.创建数组 -> number -> 专门存牌号String[] number = "2-3-4-5-6-7-8-9-10-J-Q-K-A".split("-");//3.创建map集合,key为序号,value为组合好的牌面HashMap<Integer, String> poker = new HashMap<>();//4.创建一个ArrayList,专门存储keyArrayList<Integer> list = new ArrayList<>();list.add(0);list.add(1);//5.组合牌,存储到map中int key = 2;for (String num : number) {for (String huaSe : color) {String pokerNumber = huaSe+num;poker.put(key,pokerNumber);list.add(key);key++;}}poker.put(0,"😊");poker.put(1,"☺");//6.洗牌,打乱list集合中的keyCollections.shuffle(list);//7.创建四个list集合ArrayList<Integer> p1 = new ArrayList<>();ArrayList<Integer> p2 = new ArrayList<>();ArrayList<Integer> p3 = new ArrayList<>();ArrayList<Integer> dipai = new ArrayList<>();//8.发牌for (int i = 0; i < list.size(); i++) {Integer key1 = list.get(i);if (i>=51){dipai.add(key1);}else if (i%3==0){p1.add(key1);}else if (i%3==1){p2.add(key1);}else if (i%3==2){p3.add(key1);}}//9.排序Collections.sort(p1);Collections.sort(p2);Collections.sort(p3);Collections.sort(dipai);lookPoker("涛哥",p1,poker);lookPoker("三上",p2,poker);lookPoker("金莲",p3,poker);lookPoker("大郎",dipai,poker);}private static void lookPoker(String name, ArrayList<Integer> list, HashMap<Integer, String> map) {System.out.print(name+":");for (Integer key : list) {String value = map.get(key);System.out.print(value+" ");}System.out.println();}
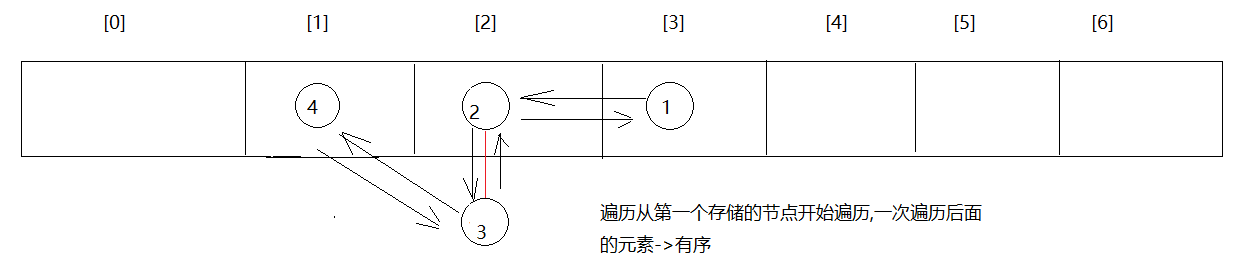
}第二章.哈希表结构存储过程
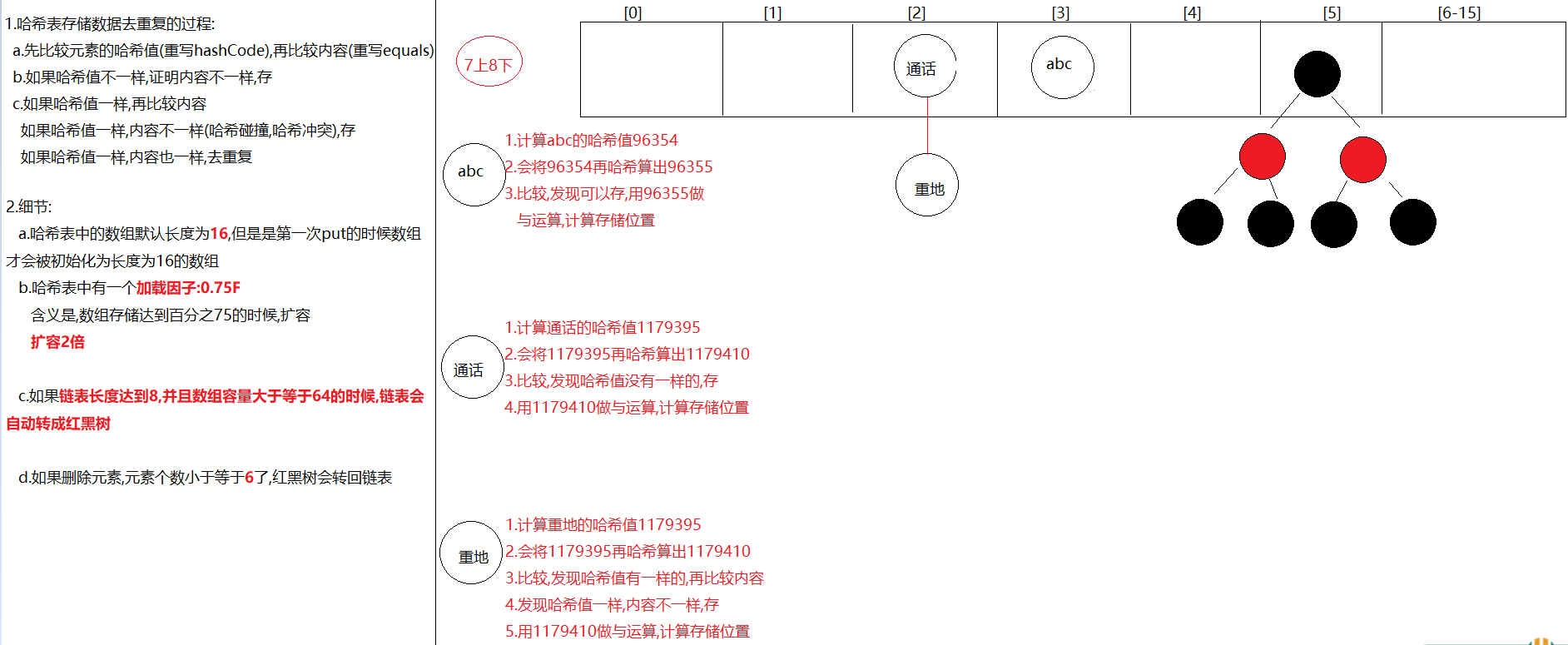
1.HashMap底层数据数据结构:哈希表
2.jdk7:哈希表 = 数组+链表jdk8:哈希表 = 数组+链表+红黑树
3.先算哈希值,此哈希值在HashMap底层经过了特殊的计算得出如果哈希值不一样,直接存如果哈希值一样,再去比较内容,如果内容不一样,也存如果哈希值一样,内容也一样,直接去重复(后面的value将前面的value覆盖)哈希值一样,内容不一样->哈希冲突(哈希碰撞)
4.要知道的点:a.在不指定长度时,哈希表中的数组默认长度为16,HashMap创建出来,一开始没有创建长度为16的数组b.什么时候创建的长度为16的数组呢?在第一次put的时候,底层会创建长度为16的数组c.哈希表中有一个数据加[加载因子]->默认为0.75(加载因子)->代表当元素存储到百分之75的时候要扩容了->2倍d.如果对个元素出现了哈希值一样,内容不一样时,就会在同一个索引上以链表的形式存储,当链表长度达到8并且当前数组长度>=64时,链表就会改成使用红黑树存储如果后续删除元素,那么在同一个索引位置上的元素个数小于6,红黑树会变回链表e.加入红黑树目的:查询快
外面笔试时可能会问到的变量
default_initial_capacity:HashMap默认容量 16
default_load_factor:HashMap默认加载因子 0.75f
threshold:扩容的临界值 等于 容量*0.75 = 12 第一次扩容
treeify_threshold:链表长度默认值,转为红黑树:8
min_treeify_capacity:链表被树化时最小的数组容量:64
1.问题:哈希表中有数组的存在,但是为啥说没有索引呢?
哈希表中虽然有数组,但是set和map却没有索引,因为存数据的时候有可能在同一个索引下形成链表,如果2索引上有一条链表,那么我们要是按照索引2获取,咱们获取哪个元素呢?所以就取消了按照索引操作的机制
2.问题:为啥说HashMap是无序的,LinkedHashMap是有序的呢?
原因:HashMap底层哈希表为单向链表
LinkedHashMap底层在哈希表的基础上加了一条双向链表

1.HashMap无参数构造方法的分析
//HashMap中的静态成员变量
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
解析:使用无参数构造方法创建HashMap对象,将加载因子设置为默认的加载因子,loadFactor=0.75F。
2.HashMap有参数构造方法分析
HashMap(int initialCapacity, float loadFactor) ->创建Map集合的时候指定底层数组长度以及加载因子public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);//10
}
解析:带有参数构造方法,传递哈希表的初始化容量和加载因子
- 如果initialCapacity(初始化容量)小于0,直接抛出异常。
- 如果initialCapacity大于最大容器,initialCapacity直接等于最大容器
- MAXIMUM_CAPACITY = 1 << 30 是最大容量 (1073741824)
- 如果loadFactor(加载因子)小于等于0,直接抛出异常
- tableSizeFor(initialCapacity)方法计算哈希表的初始化容量。
- 注意:哈希表是进行计算得出的容量,而初始化容量不直接等于我们传递的参数。
3.tableSizeFor方法分析
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}8 4 2 1规则->无论指定了多少容量,最终经过tableSizeFor这个方法计算之后,都会遵循8421规则去初始化列表容量为了存取高效,尽量较少碰撞
解析:该方法对我们传递的初始化容量进行位移运算,位移的结果是 8 4 2 1 码
- 例如传递2,结果还是2,传递的是4,结果还是4。
- 例如传递3,结果是4,传递5,结果是8,传递20,结果是32。
4.Node 内部类分析
哈希表是采用数组+链表的实现方法,HashMap中的内部类Node非常重要,证明HashSet是一个单向链表
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;
}
解析:内部类Node中具有4个成员变量
- hash,对象的哈希值
- key,作为键的对象
- value,作为值得对象(讲解Set集合,不牵扯值得问题)
- next,下一个节点对象
5.存储元素的put方法源码
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}
解析:put方法中调研putVal方法,putVal方法中调用hash方法。
- hash(key)方法:传递要存储的元素,获取对象的哈希值
- putVal方法,传递对象哈希值和要存储的对象key
6.putVal方法源码
Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;
解析:方法中进行Node对象数组的判断,如果数组是null或者长度等于0,那么就会调研resize()方法进行数组的扩容。
7.resize方法的扩容计算
if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold
}
解析:计算结果,新的数组容量=原始数组容量<<1,也就是乘以2。
8.确定元素存储的索引
if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);
解析:i = (数组长度 - 1) & 对象的哈希值,会得到一个索引,然后在此索引下tab[i],创建链表对象。
不同哈希值的对象,也是有可能存储在同一个数组索引下。
其中resize()扩容的方法,默认是16tab[i] = newNode(hash, key, value, null);->将元素放在数组中 i就是索引i = (n - 1) & hash0000 0000 0000 0000 0000 0000 0000 1111->15& 0&0=0 0&1=0 1&1=10000 0000 0000 0001 0111 1000 0110 0011->96355
--------------------------------------------------------0000 0000 0000 0000 0000 0000 0000 0011->3
0000 0000 0000 0000 0000 0000 0000 1111->15& 0&0=0 0&1=0 1&1=10000 0000 0001 0001 1111 1111 0001 0010->1179410
--------------------------------------------------------0000 0000 0000 0000 0000 0000 0000 0010->2
9.遇到重复哈希值的对象
Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;
解析:如果对象的哈希值相同,对象的equals方法返回true,判断为一个对象,进行覆盖操作。
else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}
解析:如果对象哈希值相同,但是对象的equals方法返回false,将对此链表进行遍历,当链表没有下一个节点的时候,创建下一个节点存储对象.
第三章.TreeSet
1.概述:TreeSet是Set的实现类
2.特点:a.对元素进行排序b.无索引c.不能存nulld.线程不安全e.元素唯一
3.数据结构:红黑树
构造:TreeSet() -> 构造一个新的空 set,该 set 根据其元素的自然顺序进行排序 -> ASCII TreeSet(Comparator<? super E> comparator)构造一个新的空 TreeSet,它根据指定比较器进行排序
public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}
public class Demo01TreeSet {public static void main(String[] args) {TreeSet<String> set1 = new TreeSet<>();set1.add("c.白毛浮绿水");set1.add("a.鹅鹅鹅");set1.add("b.曲项向天歌");set1.add("d.红掌拨清波");System.out.println(set1);System.out.println("=====================");TreeSet<Person> set2 = new TreeSet<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge()-o2.getAge();}});set2.add(new Person("柳岩",18));set2.add(new Person("涛哥",12));set2.add(new Person("三上",20));System.out.println(set2);}
}第四章.TreeMap
1.概述:TreeMap是Map的实现类
2.特点:a.对key进行排序b.无索引c.key唯一d.线程不安全e.不能存null
3.数据结构:红黑树
构造:TreeMap() -> 使用键的自然顺序构造一个新的、空的树映射 -> ASCII TreeMap(Comparator<? super E> comparator)构造一个新的、空的树映射,该映射根据给定比较器进行排序
public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo02TreeMap {public static void main(String[] args) {TreeMap<String, String> map1 = new TreeMap<>();map1.put("c","白毛浮绿水");map1.put("a","鹅鹅鹅");map1.put("b","曲项向天歌");map1.put("d","红掌拨清波");System.out.println(map1);System.out.println("=============");TreeMap<Person, String> map2 = new TreeMap<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge()-o2.getAge();}});map2.put(new Person("柳岩",18),"北京");map2.put(new Person("涛哥",12),"北京");map2.put(new Person("三上",20),"北京");System.out.println(map2);}
}
第五章.Hashtable和Vector集合(了解)
1.Hashtable集合
1.概述:Hashtable是Map的实现类
2.特点:a.key唯一,value可重复b.无序c.无索引d.线程安全 e.不能存储null键,null值
3.数据结构:哈希表
public class Demo01Hashtable {public static void main(String[] args) {Hashtable<String, String> table = new Hashtable<>();table.put("迪丽热巴","马尔扎哈");table.put("古力娜扎","涛哥思密达");table.put("古力娜扎","雷霆嘎巴");table.put("玛卡巴卡","哈哈哈哈");//table.put(null,null);System.out.println(table);}
}
HashMap和Hashtable区别:
相同点:元素无序,无索引,key唯一
不同点:HashMap线程不安全,Hashtable线程安全
HashMap可以存储null键null值;Hashtable不能
2.Vector集合
1.概述:Vector是List接口的实现类
2.特点:a.元素有序b.有索引c.元素可重复d.线程安全
3.数据结构:数组4.源码分析:a.如果用空参构造创建对象,数组初始容量为10,如果超出范围,自动扩容,2倍b.如果用有参构造创建对象,如果超出了范围,自动扩容,扩的是老数组长度+指定的容量增强
public class Demo02Vector {public static void main(String[] args) {Vector<String> vector = new Vector<>();vector.add("张三");vector.add("李四");for (String s : vector) {System.out.println(s);}}
}
Vector底层源码分析
Vector() 构造一个空向量,使其内部数据数组的大小为 10,其标准容量增量为零 Vector(int initialCapacity, int capacityIncrement)使用指定的初始容量和容量增量构造一个空的向量Vector<String> vector = new Vector<>(); public Vector() {this(10); } public Vector(int initialCapacity->10) {this(initialCapacity, 0); } public Vector(int initialCapacity->10, int capacityIncrement->0) {super();if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);this.elementData = new Object[initialCapacity];//长度为0的数组this.capacityIncrement = capacityIncrement;//0 } ===================================================== vector.add("李四");-> 假设李四是第11个元素 public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true; } private void ensureCapacityHelper(int minCapacity->11) {// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity->11); } private void grow(int minCapacity->11) {// overflow-conscious codeint oldCapacity = elementData.length;//10int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);//10+10=20if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); }Vector<String> vector = new Vector<>(10,5); public Vector(int initialCapacity->10, int capacityIncrement->5) {super();if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);this.elementData = new Object[initialCapacity];this.capacityIncrement = capacityIncrement;//5 }====================================================== vector.add("李四");-> 假设李四是第11个元素 public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true; } private void ensureCapacityHelper(int minCapacity->11) {// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity); }private void grow(int minCapacity->11) {// overflow-conscious codeint oldCapacity = elementData.length;//10int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); }
第六章.Properties集合(属性集)
1.概述:Properties 继承自 Hashtable
2.特点:a.key唯一,value可重复b.无序c.无索引d.线程安全e.不能存null键,null值f.Properties的key和value类型默认为String
3.数据结构:哈希表
4.特有方法:Object setProperty(String key, String value) -> 存键值对String getProperty(String key) ->根据key获取value的Set<String> stringPropertyNames() -> 获取所有的key,保存到set集合中,相当于keySet方法void load(InputStream inStream) -> 将流中的数据加载到Properties集合中(IO部分讲)
public class Demo01Properties {public static void main(String[] args) {Properties properties = new Properties();//Object setProperty(String key, String value) -> 存键值对properties.setProperty("username","root");properties.setProperty("password","1234");System.out.println(properties);//String getProperty(String key) ->根据key获取value的System.out.println(properties.getProperty("username"));//Set<String> stringPropertyNames() -> 获取所有的key,保存到set集合中,相当于keySet方法Set<String> set = properties.stringPropertyNames();for (String key : set) {System.out.println(properties.getProperty(key));}}
}第七章.集合嵌套
1.List嵌套List
需求:创建2个List集合,每个集合中分别存储一些字符串,将2个集合存储到第3个List集合中
public class Demo01ListInList {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();list1.add("杨过");list1.add("小龙女");list1.add("尹志平");ArrayList<String> list2 = new ArrayList<>();list2.add("涛哥");list2.add("金莲");list2.add("三上");/*list中的元素是两个 ArrayList<String>所以泛型也应该是 ArrayList<String>*/ArrayList<ArrayList<String>> list = new ArrayList<>();list.add(list1);list.add(list2);/*先遍历大集合,将两个小集合遍历出来再遍历两个小集合,将元素获取出来*/for (ArrayList<String> arrayList : list) {for (String s : arrayList) {System.out.println(s);}}}
}
2.List嵌套Map
1班级有第三名同学,学号和姓名分别为:1=张三,2=李四,3=王五,2班有三名同学,学号和姓名分别为:1=黄晓明,2=杨颖,3=刘德华,请将同学的信息以键值对的形式存储到2个Map集合中,在将2个Map集合存储到List集合中。
public class Demo02ListInMap {public static void main(String[] args) {//1.创建两个map集合HashMap<Integer, String> map1 = new HashMap<>();map1.put(1,"张三");map1.put(2,"李四");map1.put(3,"王五");HashMap<Integer, String> map2 = new HashMap<>();map2.put(1,"黄晓明");map2.put(2,"杨颖");map2.put(3,"刘德华");//2.创建一个存储map集合的list集合ArrayList<HashMap<Integer, String>> list = new ArrayList<>();list.add(map1);list.add(map2);//3.先遍历list集合,再遍历map集合for (HashMap<Integer, String> map : list) {Set<Map.Entry<Integer, String>> set = map.entrySet();for (Map.Entry<Integer, String> entry : set) {System.out.println(entry.getKey()+"..."+entry.getValue());}}}
}3.Map嵌套Map
- JavaSE 集合 存储的是 学号 键,值学生姓名- 1 张三- 2 李四
- JavaEE 集合 存储的是 学号 键,值学生姓名- 1 王五- 2 赵六
public class Demo03MapInMap {public static void main(String[] args) {//1.创建两个map集合HashMap<Integer, String> map1 = new HashMap<>();map1.put(1,"张三");map1.put(2,"李四");HashMap<Integer, String> map2 = new HashMap<>();map2.put(1,"王五");map2.put(2,"赵六");HashMap<String, HashMap<Integer, String>> map = new HashMap<>();map.put("javase",map1);map.put("javaee",map2);Set<Map.Entry<String, HashMap<Integer, String>>> set = map.entrySet();for (Map.Entry<String, HashMap<Integer, String>> entry : set) {HashMap<Integer, String> hashMap = entry.getValue();Set<Integer> set1 = hashMap.keySet();for (Integer key : set1) {System.out.println(key+"..."+hashMap.get(key));}}}
}


