0. 简介
作为基于视觉感知的基本任务,3D占据预测重建了周围环境的3D结构。它为自动驾驶规划和导航提供了详细信息。然而,大多数现有方法严重依赖于激光雷达点云来生成占据地面真实性,而这在基于视觉的系统中是不可用的。之前我们介绍了《经典文献阅读之—RenderOcc(使用2D标签训练多视图3D Occupancy模型)》。这里本文《OccNeRF: Self-Supervised Multi-Camera Occupancy Prediction with Neural Radiance Fields》提出了一种名为OccNeRF的方法,用于自监督多相机3D占用预测。该方法通过参数化重建的占用场来表示无限空间,并通过神经渲染将占用场转换为多相机深度图。为了提供几何和语义监督,该方法利用多帧图像之间的光度一致性进行监督。代码可在Github找到。
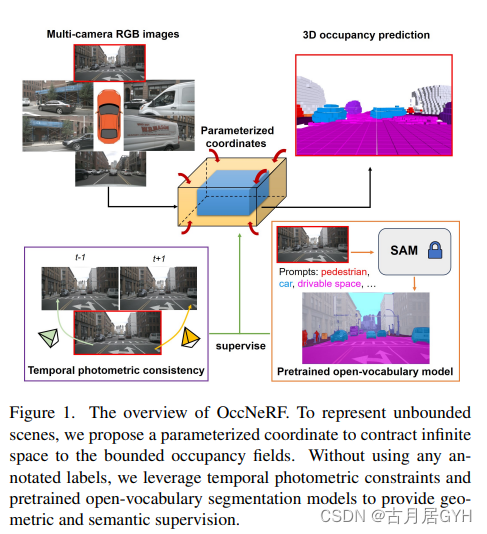
图1. OccNeRF概述。为了表示无界场景,我们提出了一个参数化坐标,将无限空间压缩到有界的占据场。在不使用任何标注标签的情况下,我们利用时间光度约束和预训练的开放词汇分割模型,提供几何和语义监督。
1. 主要贡献
- 我们使用2D骨干来提取多摄像头的2D特征。为了节省内存,我们直接插值2D特征,以获取3D体积特征,而不是使用繁重的跨视图注意力。
- 我们设计了特定的采样策略,将参数化占用场转换为具有神经渲染的多摄像头深度图。我们利用时间光度损失作为监督信号,这在自监督深度估计方法中常用 [21, 22, 46, 82, 89]。为了更好地利用时间线索,我们执行多帧光度约束
- 对于语义占用,我们提出了三种策略,将类名映射到提示词,这些提示词被馈送到预训练的开放词汇分割模型 [33, 43],以获取2D语义标签。

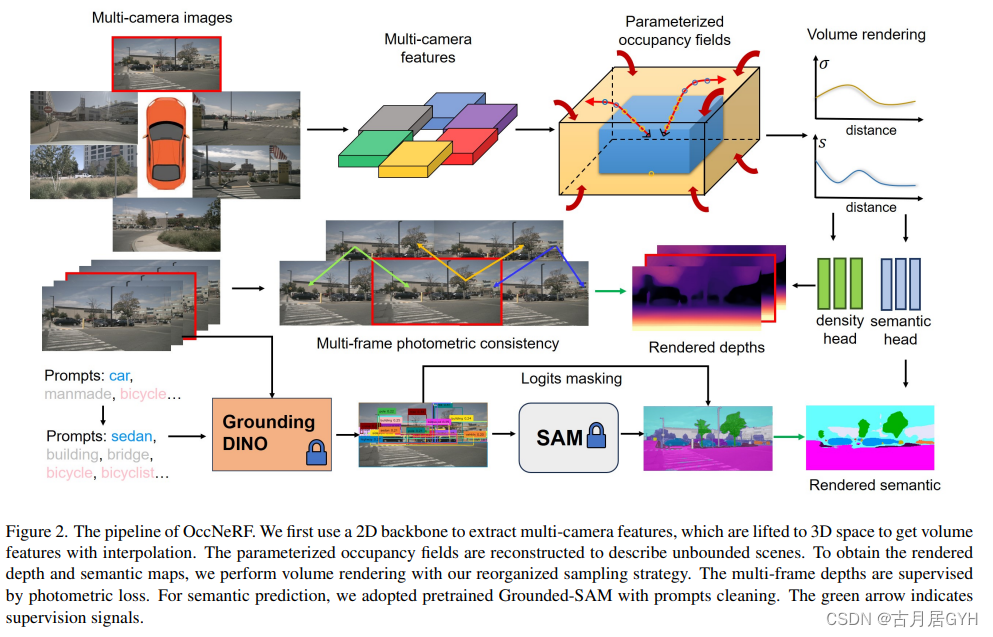 图2. OccNeRF的流程。我们首先使用2D主干网络提取多摄像头特征,然后将这些特征提升到3D空间,通过插值得到体积特征。参数化的占据场被重建以描述无界场景。为了获得渲染的深度和语义地图,我们采用了重新组织的采样策略进行体积渲染。多帧深度受光度损失监督。对于语义预测,我们采用了预训练的Grounded-SAM模型,并进行提示清理。绿色箭头表示监督信号。
图2. OccNeRF的流程。我们首先使用2D主干网络提取多摄像头特征,然后将这些特征提升到3D空间,通过插值得到体积特征。参数化的占据场被重建以描述无界场景。为了获得渲染的深度和语义地图,我们采用了重新组织的采样策略进行体积渲染。多帧深度受光度损失监督。对于语义预测,我们采用了预训练的Grounded-SAM模型,并进行提示清理。绿色箭头表示监督信号。
3. 参数化占据场
点击经典文献阅读之--OccNeRF(基于神经辐射场的自监督多相机占用预测) - 古月居可查看全文




冲刺考研复试中的面试问答,来看看我是怎么回答的吧!)

