note
- 从通用大模型到金融大模型
- 金融大模型的训练技术创新
- 金融大模型的评测方法创新
- 金融大模型的应用实践创新
- 总结:金融大模型迭代路径
一、轩辕大模型
二、垂直大模型训练
1. 数据准备
数据质量是模型效果的保障。首先数据要丰富,这是必备的条件。我们在这一环节做了非常多的工作,也设计了一套通用的数据流水线。从文本的抽取到数据的清洗,再到最后做一些人工的校验和评估,不断反复迭代。原始的中文数据,通过篇章级的过滤,一直到最后质量模型的排序,大概可以形成 32% 的中文数据。最后,形成了 10TB 的通用语料,加上 1TB 的金融语料。当然我们还在做更多的数据,特别是一些行业领域内专有数据的清洗。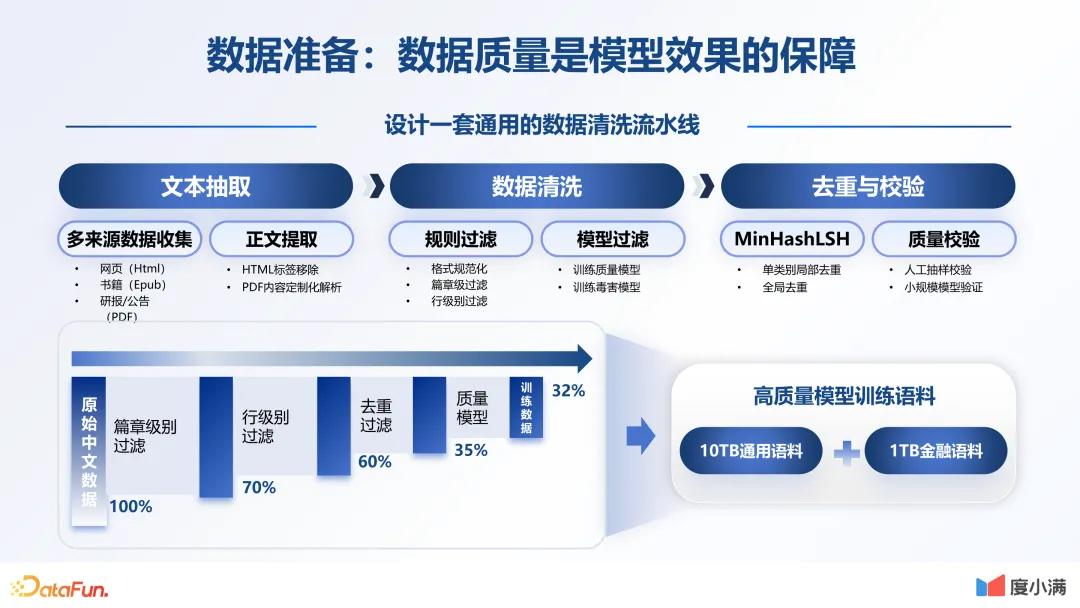
2. 增量预训练:
在数据准备完之后,就要去做预训练。需要针对中文场景做词表构建,对此,行业内大概有两种解决方案。一种是通过字粒度去扩充,因为汉字只看一个单词的话相对有限,大概数量是 5K 到 8K。另外一种就是很多中文大模型所采用的方法,即大量引入中文词汇,这样词表会比较大。考虑到对原有模型要尽量减少破坏,所以我们最终采用了字粒度扩容的方式,加入了 7K 的中文字符。这使得我们的整个词表大小达到 39K,词表压缩率为 48%。
在预训练阶段词表优化完之后,训练采用的是两阶段的优化方式,使得收敛更加稳定。第一阶段主要还是解决新加词表的泛化能力,我们仅更新模型词表的 embedding 以及解码线性层,使模型能够适应新的词表。在整个过程中,数据分布与原始的数据分布基本是一致的,就是为了保证模型的稳定性。在训练过程中我们发现,通过少量数据,能够使模型的 loss 达到平稳。所以第一阶段只训练了 40B 的 token。第二阶段对模型进行全量的更新,这时会训练大量的中文语料和英文语料。在这一阶段,我们训练了 300B 的 token。
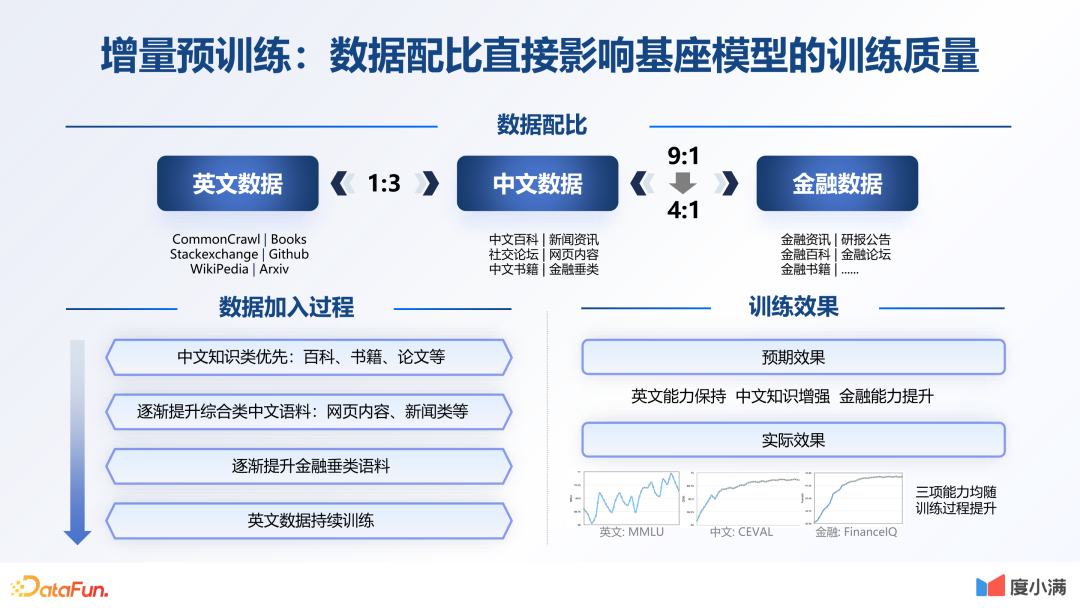
数据配比直接影响基座模型的训练质量。开始时整体的中英语料是 3 比 1。在英文数据上,一开始仅加入了少量的金融数据。随着整个训练过程的不断优化,金融数据的比例也越来越高。在训练过程中,要保证原有的英文能力。
3. 指令微调
指令微调:SFT 数据的丰富性和多样性直接影响对齐效果。在数据生成上,分为通用数据生成和金融专业领域数据生成。整体配比大概是 4 比 1。我们通过不同方式的自动生成以及人工改写,最后生成一个包含许多种类的 SFT 数据结果。
采用两阶段指令微调,保证通用能力的同时,提升金融问答能力。第一阶段是通过混合微调,用海量开源指令数据,同时加入一些预训练数据,保证其泛化性,并且可以有效减少幻觉问题。第二阶段是通过高质量的指令微调数据,提升整体的对话能力。整体的训练方式与预训练是一致的。

4. 强化学习对齐
价值对齐:通过强化学习对齐价值偏好
接下来要做的是价值对齐,就是使模型的三观与我们一致,我们使用强化学习技术来对齐价值偏好。首先基于人类反馈做 reward model,这里我们选择 pair wise 的方式,并通过大量的人工标注排序。之后用 PPO 算法进行优化。未来,价值对齐会是做大模型非常核心的一个壁垒。
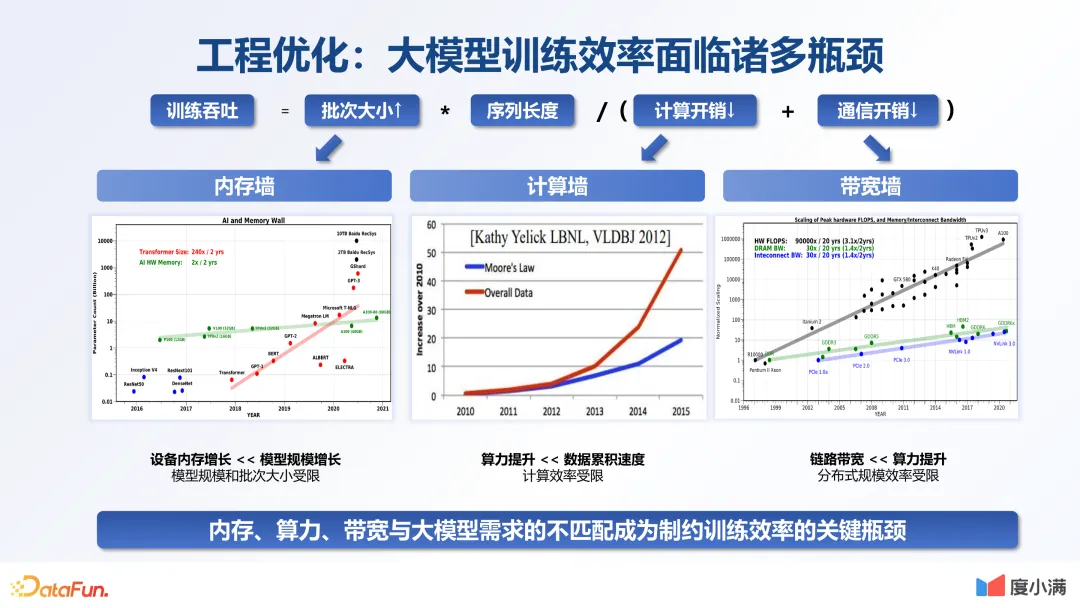
三、工程能力的优化
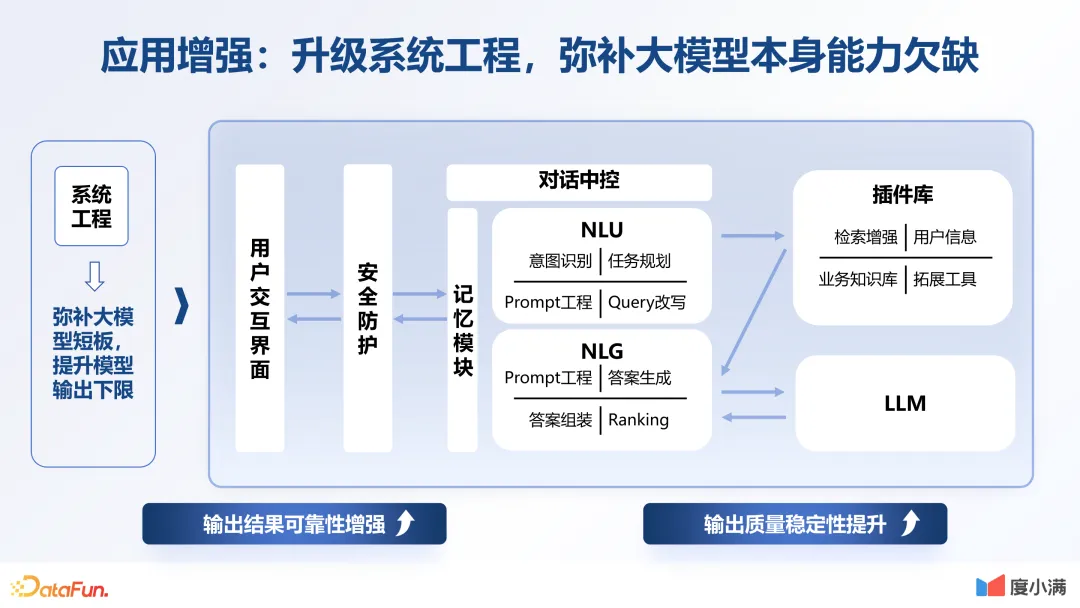
优化:
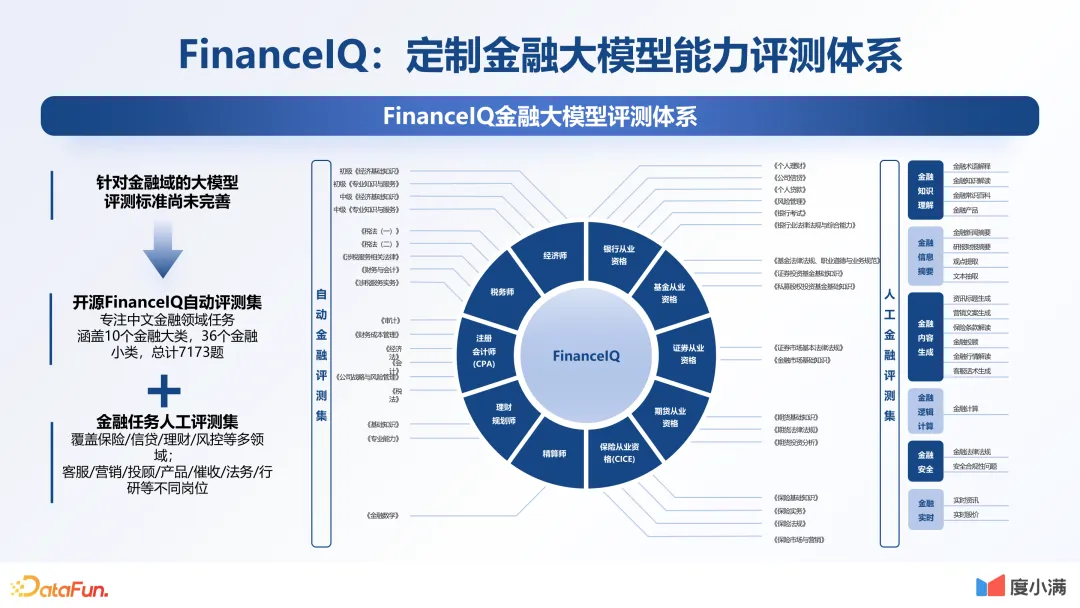
四、模型评测

FinanceIQ评测体系:
备注:大模型的训练少不了算力资源,博主和一些平台有合作~
高性价比4090算力租用,注册就送20元代金券,更有内容激励活动,点击。
GPU云服务器租用,P40、4090、V100S多种显卡可选,点击。
Reference
[1] 度小满金融大模型技术创新与应用探索



