1.索引是什么:
- 1.索引是
存储引擎用于快速查找数据记录的一种数据结构,索引好比一本书的目录部分,可以通过目录找到对应文章的页码,便可以快速定位需要的文章,MySQL中索引与书本的目录是一样的道理,在数据查找的时候,首先查看查询条件是否命中某条索引,符合索引则查找相关的数据,如果不符合则需要全表扫描,即需要一条一条的查找记录,直到找到与条件符合的记录为止
2.索引的分类:
2.1.按照功能逻辑来划分索引:
1.按照
功能逻辑上说,索引包括四种:普通索引、唯一索引、主键索引、全文索引
a.普通索引:
- 1.在创建普通索引时,不附加任何限制条件,只是用于提高查询效率
- 2.这类索引可以创建在任何数据类型中,其值是否唯一和非空,要由字段本身的完整性约束条件决定。
- 3.建立索引以后,可以通过索引进行查询
- 4.例如,
在表 student 的字段 name 上建立一个普通索引,查询记录时就可以根据该索引进行查询
b.唯一性索引:
- 1.使用
UNIQUE 参数可以设置索引为唯一性索引,在创建唯一性索引时,限制该索引的值必须是唯一的,但允许有空值 - 2.在一张数据表里可以有多个唯一索引
- 3.例如,在表 student 的字段 email 中创建唯一性索引,那么字段 email 的值就必须是唯一的。
- 4.通过唯一性索引,可以更快速地确定某条记录
c.主键索引:
- 1.主键索引就是一种特殊的唯一性索引,在
唯一索引的基础上增加了不为空的约束,也就是NOTNULL + UNIQUE - 2.一张表里最多只有一个主键索引。这是由主键索引的物理实现方式决定的,因为数据存储在文件中只能按照一种顺序进行存储
d.全文索引:
- 1.全文索引(也称全文检索)是
目前搜索引擎使用的一种关键技术。它能够利用分词技术等多种算法智能分析出文本文字中关键词的频率和重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。全文索引非常适合大型数据集,对于小的数据集,它的用处比较小。 - 2.使用
参数 FULLTEXT可以设置索引为全文索引。在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引只能创建在 CHAR、VARCHAR 或 TEXT 类型及其系列类型的字段上,查询数据量较大的字符串类型的字段时,使用全文索引可以提高查询速度。例如,表 student 的字段 information 是 TEXT 类型,该字段包含了很多文字信息。在字段 information 上建立全文索引后,可以提高查询字段 information 的速度 - 3.全文索引典型的有两种类型:
自然语言的全文索引和布尔全文索引。- 自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。
在整个索引中出现次数越少的词语,匹配时的相关度就越高。相反,非常常见的单词将不会被搜索,如果一个词语的在超过 50% 的记录中都出现了,那么自然语言的搜索将不会搜索这类词语。
- 自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。
- 4.MySQL数据库从 3.23.3 版开始支持全文索引,但 MySQ L5.6.4 以前只有 MyISAM 支持,5.6.4 版本以后 InnoDB 才支持,但是
官方版本不支持中文分词,需要第三方分词插件。在 5.7.6 版本,MySQL 内置了 ngram 全文解析器,用来支持亚洲语种的分词。测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。而随着大数据时代的到来,关系型数据库应对全文索引的需求已力不从心,逐渐被 solr、ElasticSearch 等专门的搜索引擎所替代。
2.2.按照物理实现方式分类各索引:
- 1.按照物理实现方式分类,索引可以分为 2 种,分别是
聚簇(聚集):针对主键构建的索引称之为聚簇索引
和非聚簇(非聚集)索引:也把非聚集索引称为二级索引或者辅助索引,是针对非主键构建的索引
a.聚簇索引相关:
a1.聚簇索引概念:
- 1.聚簇索引并不是一种单独的索引类型,而
是一种数据存储方式(所有的用户记录都存储在叶子节点),也就是索引即数据,数据即索引,聚簇表示的就是数据行和相邻的键值聚簇的存储在一起
a2.聚簇索引特点:
- 1.使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。- 各个存放
用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。 - 存放
目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表
- 2.B+树的 叶子节点 存储的是完整的用户记录。所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)
- 我们把具有上述这两种特性的 B+ 树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。
这种聚簇索引并不需要我们在MySQL 语句中显式的使用 INDEX 语句去创建,InnoDB 存储引擎会自动的为我们创建聚簇索引
a3.聚簇索引优点:
- 1.
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快 - 2.聚簇索引对于主键的
排序查找和范围查找速度非常快 - 3.按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以
节省了大量的io操作
a4.聚簇索引缺点:
- 1.
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键 - 2.
更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新 - 3.二级索引访问需要两次索引查找 ,第一次找到主键值,第二次根据主键值找到行数据
a5.聚簇索引限制:
- 1.对于 MySQL 数据库目前只有 InnoDB 数据引擎支持聚簇索引,而 MylSAM 并不支持聚簇索引。
- 2.由于数据物理存储排序方式只能有一种,所以
每个 MySQL 的表只能有一个聚簇索引。一般情况下就是该表的主键。 - 3
.如果没有定义主键,InnoDB 会选择非空的唯一索引代替。如果没有这样的索引,InnoDB 会隐式的定义一个主键来作为聚簇索引。 - 4.为了充分利用聚簇索引的聚簇的特性,所以
InnoDB 表的主键列尽量选用有序的顺序 ID,而不建议用无序的 ID,比如 UUID、MD5、HASH、字符串列作为主键无法保证数据的顺序增长
b.非聚簇(非聚集)索引
非聚集索引称为
b.当查找的条件不再是主键的时候:
- 1.上边介绍的聚簇索引只能在搜索条件是主键值时才能发挥作用,因为 B+ 树中的数据都是按照主键进行排序的。那如果想
以其他的列作为搜索条件该怎么办呢?肯定不能是从头到尾沿着链表依次遍历记录一遍 - 2.答案:
我们可以多建几棵 B+ 树,不同的 B+ 树中的数据采用不同的排序规则。比方说我们用 c2 列的大小作为数据页、页中记录的排序规则,再建一棵 B+ 树,效果如下图所示

b2.这个 B+ 树与聚簇索引不同:
- 1.使用记录 c2 列的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照 c2 列的大小顺序排成一个单向链表。- 各个存放用户记录的页也是根据页中记录的 c2 列大小顺序排成一个双向链表。
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的 c2 列大小顺序排成一个双向链表
- 2.B+ 树的叶子节点存储的并不是完整的用户记录,而
只是 c2 列 + 主键这两个列的值。 - 3.目录项记录中不再是主键 + 页号的搭配,而变成了
c2 列 + 页号的搭配。
b3.举例说明非聚簇索引查找过程:
如果我们现在想通过 c2 列的值查找某些记录的话就可以使用我们刚刚建好的这个 B+ 树了。以查找 c2 列的值为 4 的记录为例,查找过程如下:
- 1.确定目录项记录页。根据根页面,也就是页 44,可以快速定位到目录项记录所在的页为页 42(因为 2 < 4 < 9)。
- 2.通过目录项记录页确定用户记录真实所在的页。在页 42 中可以快速定位到实际存储用户记录的页,但是
由于 c2 列并没有唯一性约束,所以 c2 列值为 4 的记录可能分布在多个数据页中,又因为 2 < 4 ≤ 4,所以确定实际存储用户记录的页在页 34 和页 35 中。 - 3.在真实存储用户记录的页中定位到具体的记录。到页 34 和页 35 中定位到具体的记录。
- 4.但是这个 B+ 树的叶子节点中的记录只存储了 c2 和 c1(也就是主键)两个列,所以我们
必须再根据主键值去聚簇索引中再查找—遍完整的用户记录。
b4.什么是回表:
- 1.我们根据这个以 c2 列大小排序的 B+ 树只能确定我们要查找记录的主键值,所以如果我们想根据 c2 列的值查找到完整的用户记录的话,仍然需要到聚簇索引中再查一遍,这个过程称为
回表。也就是根据 c2列的值查询一条完整的用户记录需要使用到 2 棵B+ 树!
b5.为什么我们还需要一次回表操作呢?
问题:为什么我们还需要一次回表操作呢?直接把完整的用户记录放到叶子节点不 OK 吗?
回答:如果把完整的用户记录放到叶子节点确实是可以不用回表。但是太占地方了,相当于每建立一棵 B+ 树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了。
- 1.因为这种按照非主键列建立的 B+ 树需要一次回表操作才可以定位到完整的用户记录,所以这种 B+ 树也被称为二级索引,英文名secondary index,或者辅助索引。
- 2.由于我们使用的是 c2 列的大小作为 B+ 树的排序规则,所以我们也称这个 B+ 树是为 c2 列建立的索引。
- 3.非聚簇索引的存在不影响数据在聚簇索引中的组织,所以
一张表可以有多个非聚簇索引。

b6.小结:聚簇索引与非聚簇索引在使用上的区别:
- 1.聚簇索引的
叶子节点存储的就是我们的数据记录,非聚簇索引的叶子节点存储的是数据位置。非聚簇索引不会影响数据表的物理存储顺序 - 2.一个表
只能有一个聚簇索引,因为只能有一种排序存储的方式,但可以有多个非聚簇索引,也就是多个索引目录提供数据检索 - 3.使用
聚簇索引的时候,数据的查询效率高,但如果对数据进行插入、删除、更新等操作,效率会比非聚簇索引低
b7.联合索引
联合 索引就是属于非聚簇索引
联合索引概念:
- 1.我们也可以同时
以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让 B+ 树按照 c2 和 c3 列的大小进行排序,这个包含两层含义:- 先把各个记录和页按照 c2 列进行排序。
- 在记录的 c2 列相同的情况下,采用 c3 列进行排序。
2.为 c2 和 c3 列建立的索引的示意图如下:

3.如图所示,我们需要注意以下几点:
- 1.每条目录项记录都由
c2、c3、页号这三个部分组成,各条记录先按照 c2 列的值进行排序,如果记录的c2 列相同,则按照 c3 列的值进行排序。 - 2.B+ 树
叶子节点处的用户记录由c2、c3 和主键 c1列组成。
4.联合索引本质:
- 1.以 c2 和 c3 列的大小为排序规则建立的 B+ 树称为联合索引,本质上也是一个二级索引。它的意思与分别为 c2 和 c3 列分别建立索引的表述是不同的,不同点如下:
- 建立联合索引只会建立如上图一样的 1 棵 B+ 树。
- 为 c2 和 c3 列分别建立索引会分别以 c2 和 c3 列的大小为排序规则建立 2 棵 B+ 树。
2.3.按照字段个数划分来介绍索引:
- 按照作用的
字段个数来划分为单列索引、联合索引
a.单列索引:
- 1.在表中的
单个字段上创建索引。单列索引只根据该字段进行索引。单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引 - 2.只要保证该索引只对应一个字段即可。一个表可以有多个单列索引
b.联合索引:
- 1.多列索引是在表的
多个字段组合上创建一个索引 - 2.该索引指向创建时对应的多个字段,可以通过这几个字段进行查询,但是只有查询条件中使用了这些字段中的第一个字段时才会被使用
- 3.例如,在表中的字段 id、name 和 gender 上建立一个多列索引 idx_id_name_gender,只有在查询条件中使用了字段 id 时该索引才会被使用。
使用组合索引时遵循最左前缀集合
2.4.空间索引:
- 1.使用
参数 SPATIAL可以设置索引为空间索引。 - 2.空间索引只能建立在空间数据类型上,这样可以提高系统获取空间数据的效率。
- 3.MySQL 中的空间数据类型包括
GEOMETRY、POINT、LINESTRING 和 POLYGON等。 - 4.目
前只有 MyISAM 存储引擎支持空间检索,而且索引的字段不能为空值
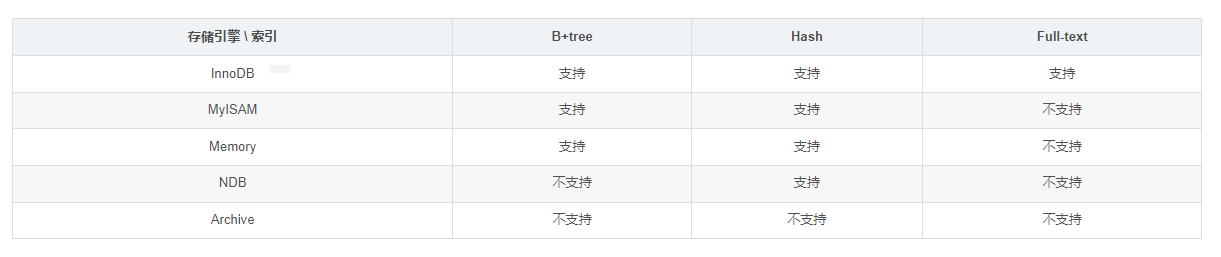
3.各存储引擎对索引类型的的支持情况:




)
