1. 项目主页

Imagen: Text-to-Image Diffusion Models

我们推出了 Imagen,这是一种文本到图像的扩散模型,具有前所未有的照片级真实感和深层次的语言理解能力。Imagen 建立在大型 Transformer 语言模型在文本理解方面的强大功能之上,并依赖于扩散模型在高保真图像生成方面的强大功能。我们的主要发现是,在纯文本语料库上进行预训练的通用大型语言模型(例如 T5)在对文本进行图像合成编码方面出奇地有效:增加 Imagen 中语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像文本对齐。Imagen 在 COCO 数据集上获得了 7.27 的全新最佳 FID 分数,而无需在 COCO 上进行训练,并且人类评分者发现 Imagen 样本在图像文本对齐方面与 COCO 数据本身相当。为了更深入地评估文本到图像模型,我们引入了 DrawBench,这是一个全面且具有挑战性的文本到图像模型基准。使用 DrawBench,我们将 Imagen 与最近的方法(包括 VQ-GAN+CLIP、潜在扩散模型和 DALL-E 2)进行比较,并发现在并排比较中,人类评估者更喜欢 Imagen 而不是其他模型,无论是在样本质量还是图像文本对齐方面。
论文: https://arxiv.org/abs/2205.11487

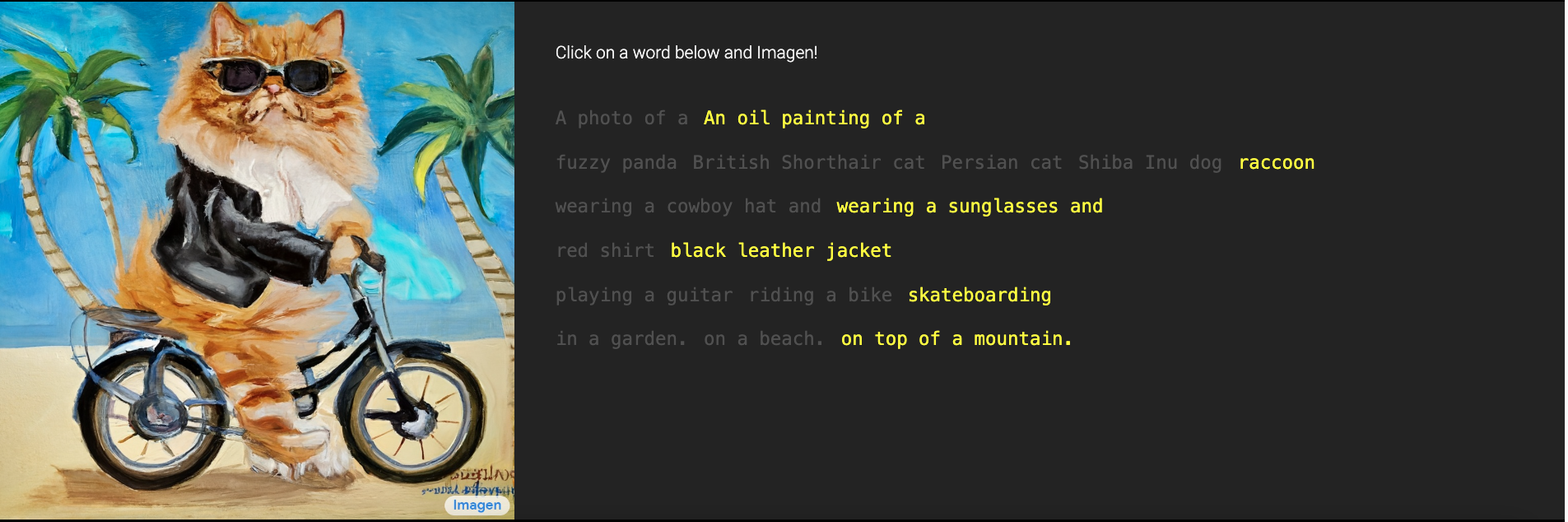
模型效果示意图:

2. 技术细节
Imagen 是一个可以根据输入文本创建逼真图像的人工智能系统
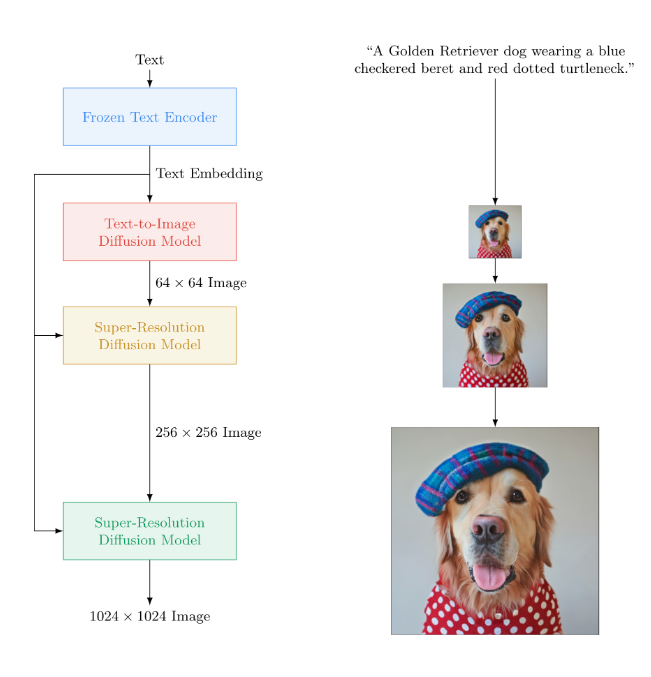
Imagen 的可视化。Imagen 使用大型冻结 T5-XXL 编码器将输入文本编码为嵌入。条件扩散模型将文本嵌入映射到 64×64 图像中。Imagen 进一步利用文本条件超分辨率扩散模型对图像进行上采样 64×64→256×256 和 256×256→1024×1024。
核心点:
- 大型预训练语言模型 × 级联扩散模型
- 深度文本理解 → 逼真生成
Imagen 研究亮点
- 我们表明,大型预训练冻结文本编码器对于文本转图像任务非常有效。
- 我们表明,缩放预训练文本编码器大小比缩放扩散模型大小更重要。
- 我们引入了一种新的阈值扩散采样器,它可以使用非常大的无分类器指导权重。
- 我们引入了一种新的高效 U-Net 架构,它计算效率更高、内存效率更高、收敛速度更快。
- 在 COCO 上,我们实现了 7.27 的全新先进 COCO FID;人类评分者发现 Imagen 样本在图像-文本对齐方面与参考图像相当。

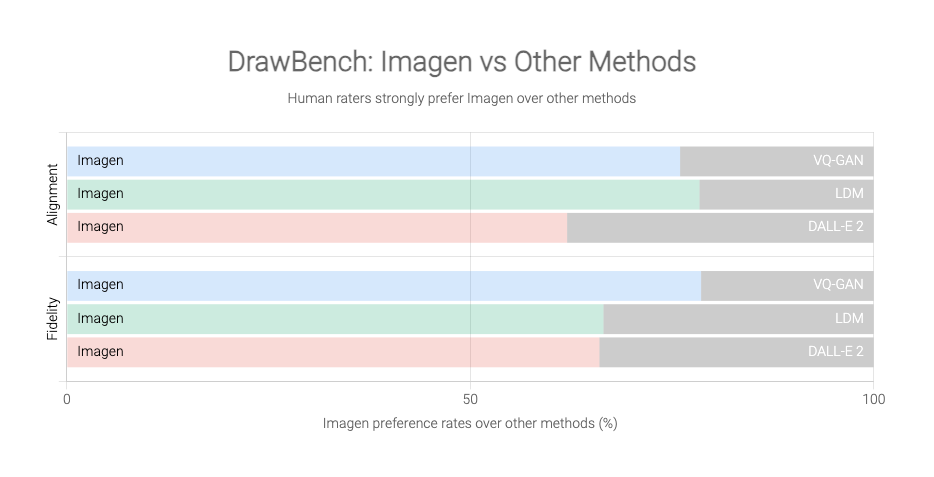
DrawBench:全新综合挑战性基准
- 并行人工评估。
- 系统地测试:组合性、基数性、空间关系、长篇文本、生僻词和挑战性提示。
- 在图像文本对齐和图像保真度方面,人工评分者强烈倾向于 Imagen 而非其他方法。
State-of-the-art text-to-image: