前言:为什么要用链路追踪
微服务架构是一个分布式架构,按照规则划分服务单元,一个分布式系统往往有很多个服务单元。服务单元数量多,业务复杂,出现错误和异常往往很难定位问题。主要体现在,一个请求可能需要调用多个服务,而内部服务的调用复杂,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进请求有哪些服务参与,参与的顺序是怎样的,从而达到每个请求的步骤都是清晰可见的,能够快速定位问题。
一、Spring Cloud Sleuth简介
Spring Cloud Sleuth 为Spring Cloud提供了分布式跟踪解决方案的 API 。它与OpenZipkin Brave集成
Spring Cloud Sleuth 能够跟踪您的请求和消息,以便您可以将该通信与相应的日志条目关联起来。您还可以将跟踪信息导出到外部系统以可视化延迟。Spring Cloud Sleuth 直接支持OpenZipkin兼容系统。
基本术语
Spring Cloud Sleuth 借用了Dapper 的术语。
Span:基本工作单元。例如,发送 RPC 是一个新的 span,发送对 RPC 的响应也是如此。Span 还包含其他数据,例如描述、带时间戳的事件、键值注释(标签)、导致它们的 span 的 ID 以及进程 ID(通常是 IP 地址)。
Span 可以启动和停止,并且会跟踪其时间信息。创建 Span 后,您必须在未来某个时间点停止它。
跟踪:一组跨度,形成树状结构。例如,如果您运行分布式大数据存储,则跟踪可能由请求形成PUT。
注释/事件:用于记录某个事件在某个时间点的存在。
从概念上讲,在典型的 RPC 场景中,我们标记这些事件以突出显示发生了什么样的动作(这并不意味着物理上会在跨度上设置这样的事件)。
-
cs:客户端已发送。客户端已发出请求。此注释表示 span 的开始。
-
sr:服务器已接收:服务器端收到请求并开始处理。
cs从此时间戳中减去时间戳即可得出网络延迟。 -
ss:服务器已发送。在请求处理完成时(响应发送回客户端时)进行注释。
sr从此时间戳中减去时间戳即可得出服务器端处理请求所需的时间。 -
cr:客户端已接收。表示跨度结束。客户端已成功接收来自服务器端的响应。
cs从此时间戳中减去时间戳即可得出客户端从服务器接收响应所需的全部时间。
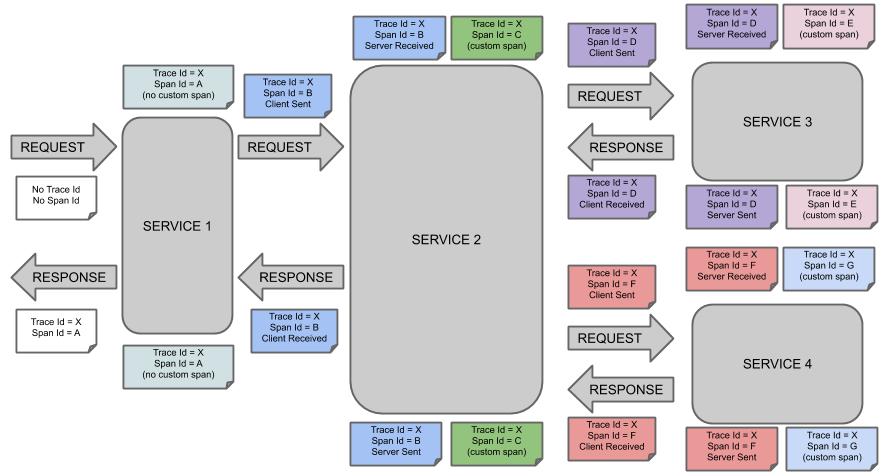
下图显示了Span和Trace在系统中的样子。
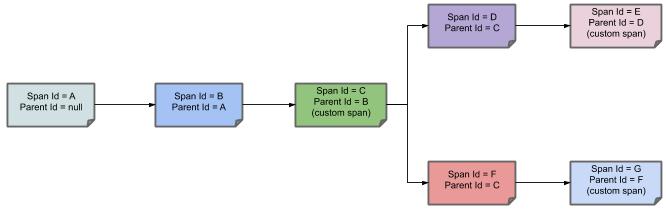
下图展示了 span 的父子关系:
二、整合Sleuth
1.服务的提供者与消费者导入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
三、整合Zipkin可视化
通过Sleuth产生的调用链监控信息,可以得知微服务之间的调用链路,但是监控信息只能输出到控制台不方便查看。需要一个图形化的工具-zipkin。Zipkin是Twitter开源的分布式跟踪系统,主要用来收集系统的时序数据,从而跟踪系统的调用问题。
Zipkin官方:OpenZipkin · A distributed tracing system

1.安装zipkin服务器
docker安装:
docker run -d -p 9411:9411 openzipkin/zipkinjava安装:
如果你安装了 Java 17 或更高版本,最快的入门方法是将最新版本作为一个独立的可执行 jar 来获取:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar2.项目导入依赖
<!-- 链路追踪zipkin--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-zipkin</artifactId></dependency>
说明:spring-cloud-starter-zipkin的最新版本是2.2.8.RELEASE,之后就没有更新了。较新版本的Spring Cloud已经不再支持spring-cloud-starter-zipkin依赖.现在使用的是spring-cloud-sleuth-zipkin依赖。
3.添加zipkin相关配置
spring:zipkin:#zipkin服务器地址base-url: http://120.46.40.171:9411/# 关闭服务发现,否则spring cloud会把zipkin的url当作服务名称discoveryClientEnabled: falsesender:# 设置使用http的方式传输数据type: websleuth:sampler:# 设置抽样采集率为100%,默认为0.1,10%probability: 1 4.验证,启动服务,访问端口
打开zipkin的访问地址:http://localhost:9411/

4.Zipkin数据持久化
官方:https://github.com/openzipkin/zipkin
Zipkin默认是将监控数据存储在内存中,如果Zipkin重启数据将会丢失。Zipkin支持将数据存储在:内存(默认)、Mysql、Elasticsearch、Cassandra中。
Elasticsearch为最优选择。
通过docker方式 :
docker run -d -p 9411:9411 -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=192.168.0.184:9200 openzipkin/zipkin
查看持久化情况:

已经生成了索引以及文档数据。


)



