我自己的原文哦~ https://blog.51cto.com/whaosoft/12320875
#自动泊车
自动泊车系统是指在没有人工干预的情况下,车辆本身可以自主的实现停车位的寻找并完成准确的泊车,同时该系统也可以根据用户的需求准确移动到用户指定的位置上。如果自动泊车技术成熟后,可以极大缓解人们在泊车过程中的诸多不便,比如:长时间搜寻停车位置浪费时间、在寻找停车位的过程中易出现事故(车辆碰撞、摩擦)等问题。
所以目前很多技术公司和高校的实验室都正在探索这个领域,比如,奔驰和博世等公司已经为自动泊车系统建立了泊车基础设施、NVIDIA正在开发一种在停车场的自动驾驶算法以及关于停车位的检测方法、宝马公司也准备将自动泊车模块安装在其生产的汽车上。
考虑到自动泊车技术在工业界的广泛需求,我们对自动泊车系统的发展状态进行系统性的调研。包括自动泊车系统的行业标准趋势、性能评测指标、自动泊车系统各个子模块设计到的技术等。
目前自动泊车行业的标准趋势
由于目前自动泊车系统受到了来自工业界和学术界的广泛关注,各个国家和公司都在不断的开发自动泊车技术。所以对于制定自动泊车技术的标准就变的格外重要。目前已经制定的技术标准包括地理信息、室外定位、室内空间定位、停车标准以及车辆通信标准几个方面的内容
- 地理信息和定位标准为室外空间的命名、定义和格式建立了原则和依据,此类标准包括 ISO 14825、ISO 17572 和 ISO TC204 177438等。
- 室内空间定位的标准化也在制定当中,包括ISO TC211以及OGC标准。
- ISO/DIS 16787 APS停车标准提出了停车所需要的信息类型,并定义了控制车辆的技术名称。此外,该标准还定义了实施辅助停车系统所需要的功能以及执行车辆的转向控制功能。
自动泊车系统的评测标准
目前自动泊车系统的评测包括两部分,分别是自动驾驶部分的评测以及自动泊车部分的评测。
自动驾驶部分的评测标准
自动驾驶部分的评测遵循汽车工程协会制定的“自动驾驶技术阶段”。该阶段目前被划分为六个层级。其中六个层级的划分是基于技术水平、控制主体以及驱动能力进行分类的。目前正在研发的ISO/WD 34501和ISO/WD 34502标准就用于去更加方便的评估各个层级。ISO/WD 34501标准适用于第三级系统中测试场景的术语和定义,ISO/WD 34502标准定义了测试场景的指南和安全评估过程。
自动泊车部分的评测标准
虽然自动泊车技术目前受到了非常广泛的关注,但是对于评估自动驾驶停车区域的国际标准的制定却刚刚开始。所以与自动驾驶中的评测标准不同,针对自动泊车的技术水平是根据开发人员的评估标准来衡量的。
下表展示了交通状况场景系统中自主停车场景的样例,该停车场景就是根据性能级别进行划分的。
在交通状况场景系统评估包括自动驾驶和停车两部分场景,并且使用汽车工程协会定义的“自动驾驶技术阶段“来指出自动泊车的能力。目前该系统当中包含三个层级。
- 第二级别(Lv2):称为泊车辅助系统用于帮助人们更方便的泊车。在Lv2级别中,通常车辆会配有障碍物距离预警系统以及后视相机。
- 第三级别(Lv3):Lv3级别可以实现指定场景下的自动泊车。比如在车库中停车的这一类简单的泊车场景。
- 第四级别(Lv4):Lv4级别中可以执行Lv3级别中的所有场景。除此之外,当车辆遇到障碍物的时候,车辆可以在停止或者避开障碍物后返回目的地。
自动泊车系统详解
目前自动泊车系统当中主要包括三部分的内容,如下图所示,分别是搜索驾驶过程,自动泊车过程以及返回驾驶过程。我们先对每个过程做一个大致的介绍,然后再介绍每个过程目前各自的发展趋势。
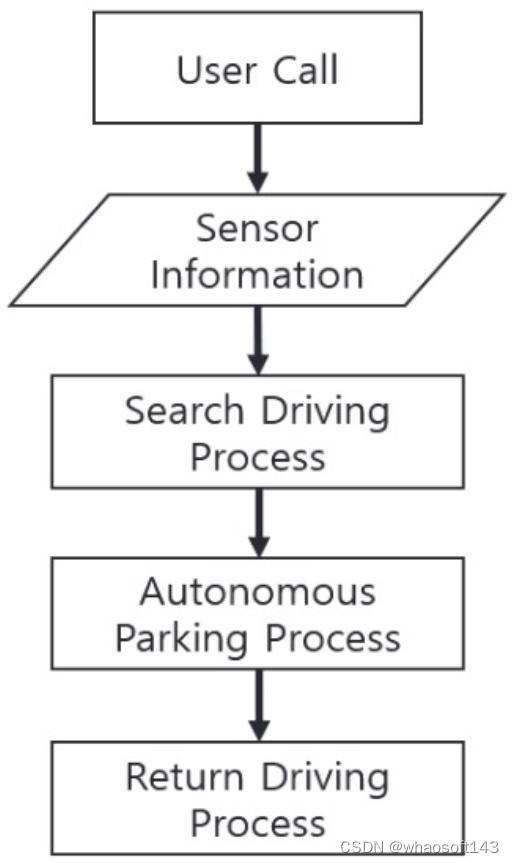
自动泊车系统的工作流程
搜索驾驶过程
搜索驾驶过程的最终目标就是在停车场当中汽车可以自主的找到一个停车位,所以该过程需要用
定位、防撞以及停车位检测技术。
定位技术介绍
在自动泊车系统当中,可以使用GPS或者车辆自带的IMU传感器来确认车辆的速度和姿态并且纠正车辆的位置估计误差。但是在某些室内场景,是无法接收到GPS信号的。所以自动驾驶车辆就需要配备相机、激光雷达以及毫米波雷达进行辅助。下图是车辆上配备的一些传感器信息的介绍。
- 激光雷达传感器使用激光来检测物体。现在主要流行的激光雷达主要分为16、32、64和128线的激光雷达。其测量范围约为200米,垂直视场为30到50度。
- 相机传感器则可以大致分成单目、双目以及鱼眼类型。通常自动驾驶车辆配备的相机其水平视场为90到210度,垂直视场为90到180度。
- 毫米波雷达根据距离可以划分成短程雷达和长距雷达。其中,短程雷达的范围大约到5米,水平视场为5到20度,垂直视场为10到35度。长距雷达的范围大约可以到200米,水平和垂直视场为35到80度。
再获得了这些不同传感器采集到的信息之后,就可以利用SLAM建图技术对自动驾驶车辆周围的环境进行重建,从而实现对车辆的定位。而SLAM建图技术又可以分成以下两大类
- 直接建图法:跟踪传感器移动时变化的数据的强度来估计传感器的姿态。但由于该类方法容易受到光照变化的影响,不能实现重定位,导致目前的建图方法很少基于此类方法。
- 基于特征的建图法:该类方法首先从传感器信息中获得周围物体的特征点。从同一对象接收到的特征点投影到两个不同的传感器坐标,通过计算投影点的几何关系来估计目标的位置。
防碰撞技术介绍
由于自动泊车系统的主要应用场景是在停车场,而停车场中会停有很多车辆,所以防碰撞技术非常重要。在防碰撞技术中,主要会使用超声波传感器、短波雷达传感器、激光雷达传感器以及相机传感器。声波以及雷达传感器主要是用来实现准确的测距。相机传感器主要是利用同一物体在连续图像中位置的差异来估计深度上的距离。
停车位检测技术
停车位检测是在搜索驾驶的过程中不断执行的,通常会包括传统的计算机视觉、深度学习以及两种方法的混合实现。
传统的计算机视觉主要是指定和识别停车位的形状,如车位线检测以及特征点检测,如下图所示。
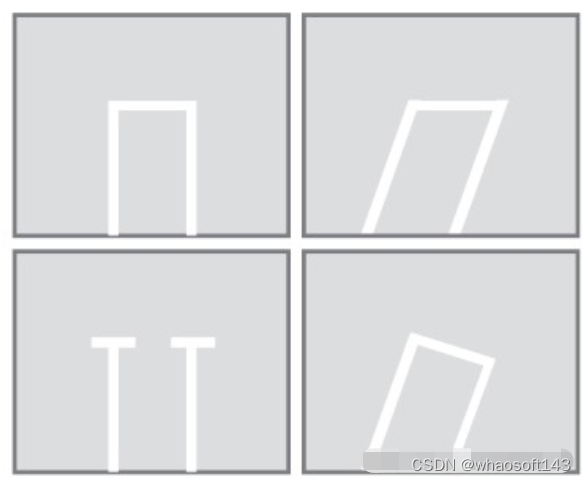
车位形状的例子说明
得益于深度学习的快速发展,目前基于CNN网络的方法被广泛应用于停车位检测当中。下图表示了用于停车位检测的代表性卷积神经网络结构。卷积层学习输入图像的特征,特征数据通过全连接层得到输出。由于这是一个完全监督的学习过程,输出由训练数据中的标记来直接决定。
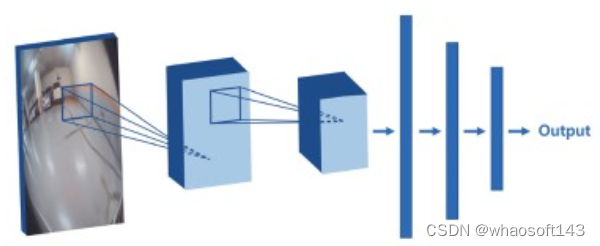
基于卷积神经网络的停车位检测流程
自动泊车过程
如果上一步的搜索驾驶过程找到了可用的停车位后,系统就会调用自动泊车过程。一般来说,我们会使用路径生成方法实现自主泊车过程。目前主流的路径生成方法主要有基于算法的方法以及基于强化学习的方法。
基于算法的方法涉及计算停车位的位置和形状的路径以及车辆的当前位置。算法为了计算出合适的停车路径会涉及最优控制问题、基于网格的路径规划方法以及快速探索随机树等算法。
基于强化学习的方法可以为自动泊车模拟器中的自主停车过程生成最优路径。在自动泊车模拟器中,车辆会学习一个通用的停车过程。该学习方法通过重复路径的生成过程和评估来不断获得停车精度最高的最优路径,如下图所示。
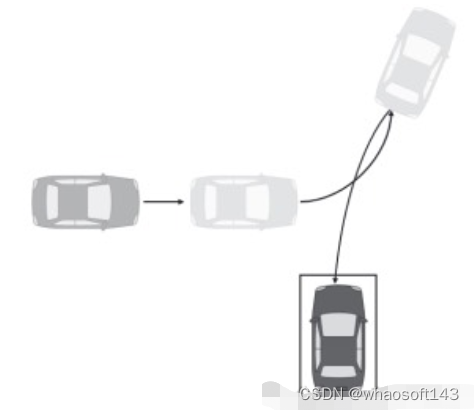
返回驾驶过程
返回驾驶过程是指在自动驾驶车辆驶入停车位进行等待的时候,用户可以对车辆进行调用,使其移动到用户指定好的地方。在这个过程当中,我们需要使用到路径跟踪技术。
目前而言,路径跟踪技术包括跟踪行进路径的方法以及跟踪修改路径的方法。但是这两种方法都使用了类似的车辆控制算法,具体可以参考论文【1-2】。其大体思路就是在考虑车辆当前位置和转向角条件的情况下,执行沿着生成路径移动车辆的控制命令。
结论
由于目前自动泊车技术的需求逐渐增加,各个国家和厂商都在大力发展自动泊车系统。考虑到自动泊车技术的快速发展,在这篇文章中,我们总结了自动泊车系统当中的标准化趋势、评测标准以及自动泊车各个组成系统的进行详细的介绍,希望可以给大家带来帮助~
#4D毫米波雷达
4D毫米波雷达是相对于3D毫米波雷达的叫法,可以说2023年及之前,大部分量产方案都采用了3D毫米波雷达,今年听说某新势力已经开始将4D Radar量产到车上了,行业给出的时间点是2025年大批量量产,这家公司提前一年上车,上汽也公布了采用4D Radar的量产方案。
4D指的是在原有3D雷达的距离、方位、速度检测的基础上增加了高度信息,为啥需要高度呢?3D毫米波雷达由于自身限制,在很多场景中限制了其发挥。例如地面上的井盖、人行天桥这些在雷达眼里都是一个水平面上的东西,它也不知道到底能不能通过!经典的如带AEB功能的车每次碰到减速带都要刹一下,其实就是毫米波雷达在搞鬼,因为它不确定这个东西有多高,万一是个障碍物,撞上去咋办。
4D毫米波雷达的另外一个叫法为4D成像毫米波雷达(其实业内基本将这两个称呼等同了),为啥叫成像呢?参考相机成像,传统3D雷达点云非常稀疏,你甚至无法看出一辆车的形态。而4D毫米波雷达,可以对一个cyclist甚至行人建模,就像图像中的特征一样,点云密集了很多。
目前市场上,4D毫米波雷达的玩家有大陆、采埃孚、安波福、Waymo、Mobileye、Arbe、傲酷、森思泰克、纳瓦电子、几何伙伴这些公司入局。据说特斯拉的方案将采用4D Radar,解决视觉传感器无法完全handle的case。
4D Radar的优势
价格便宜,只有激光雷达成本的十分之一,如果说Lidar是30w以上车型的专属,那么4D Radar能够更好服务中低端车型。所以很多车企,在竞争压力越来越大的情况下,不得不降低定价,慢慢转向更有性价比的4D Radar。
结合了激光雷达和3D毫米波雷达,可以做到点云和方位、速度信息共用,一个雷达多个用处;
角分辨率更高,相比于3D雷达,可以提高5-10倍,对小目标感知友好;
4D Radar目前的问题
点云仍然不够稠密,勉强对齐8-16线激光雷达,和稠密线束的激光雷达还差距很大;
进一步的提升点云密度,在成本和技术上都面临较大挑战;
激光雷达的价格也在不断下降,4D毫米波雷达如果无法真正突破壁垒,也会面临窘境。
目前很多公司都在试用阶段,还是无法真正替换掉激光雷达,但4D毫米波雷达的市场还是很有前景的,希望能够早日上位,发挥最大价值。
#基于大语言模型赋能智体的建模和仿真~综述和展望
23年12月论文“Large Language Models Empowered Agent-based Modeling and Simulation: A Survey and Perspectives“,来自清华大学。
基于智体的建模和仿真已经发展成为复杂系统建模的强大工具,为不同智体之间的紧急行为和交互提供了洞察。将大语言模型集成到基于智体的建模和仿真中,为增强仿真能力提供了一条很有前途的途径。本文综述在基于智体的建模和仿真中大语言模型的前景,研究了它们的挑战和有前景的未来方向。在这篇综述中,由于是一个跨学科的领域,首先介绍基于智体的建模和仿真以及大语言模型赋能智体的背景。然后,讨论将大语言模型应用于基于智体模拟的动机,并系统地分析环境感知、与人类协调、动作生成和评估方面的挑战。最重要的是,全面概述最近在多个场景中基于大语言模型的智体建模和仿真的工作,这些工作可以分为四个领域:网络、物理、社会及其混合,涵盖了真实世界和虚拟环境的仿真。最后,由于这一领域是一个新的、快速发展的领域,讨论悬而未决的问题和有希望的未来方向。
基于智体的模拟通过集中于智体的单个实体来捕捉复杂系统中固有的复杂动力学[135]。这些智体是异构的,具有特定的特征和状态,并根据上下文和环境自适应地行为,做出决策和采取行动[65]。环境,无论是静态的还是进化的,都会引入条件,引发竞争,定义边界,偶尔还会提供影响智体行为的资源[48]。交互包括与环境和其他智体的交互,目标是基于预定义或自适应规则反映现实中的行为[64,135]。总之,基于智体的模拟的基本组件包括:
- 智体是基于智体模拟的基本实体。它们表示正在建模的系统个体、实体或元素。每个智体都有自己的一组属性、行为和决策过程。
- 环境是智体操作和交互的空间。它包括物理空间,以及影响智体行为的任何外部因素,如天气条件、经济变化、政治变化和自然灾害。智体可能会受到环境的约束或影响,它们的相互作用可能会对环境本身产生影响。
- 智体通过预定义的机制进行交互,并与环境交互。交互可以是直接的(代理对智体)或间接的(智体到环境或环境对智体)。
有了上述组件,基于智体的建模和仿真提供了一个自下而上的视角,从个体相互作用的角度研究宏观层面的现象和动力学。
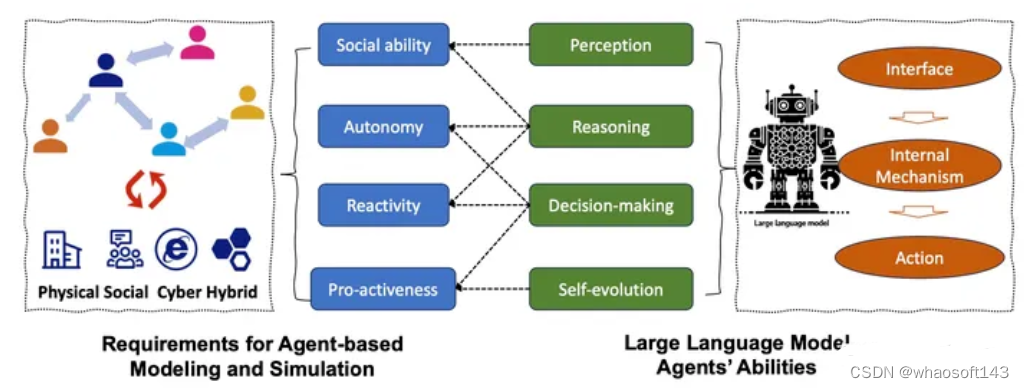
为了在广泛的应用领域实现逼真的模拟,智体在感知、决策和行动方面应具有以下能力[217]:
- 自治。智体应该能够在没有人类或其他人直接干预的情况下运行,这在微观交通流模拟[131]和行人运动模拟[20]等现实世界应用中很重要。
- 社交能力。代理应该能够与其他智体进行(可能还有人类)交互,完成指定的目标。在研究社会现象、群体行为或社会结构时,智体的社交能力是关键。这包括模拟社交网络的形成、观点的动态、文化的传播等等。智体之间的社会交互可以是合作的,也可以是竞争的,这在模拟市场行为、消费者决策等经济活动时至关重要。
- 反应性。智体应该能够感知环境,并对环境的变化做出快速反应。这种能力在需要模拟实时响应的系统中尤其重要,如交通控制系统和自动化生产线,以及在灾害响应场景中,智体需要能够立即对环境变化做出反应,以有效地进行预警和疏散。更重要的是,智体应该能够从以前的经验中学习,并自适应地改善其反应,类似于强化学习的想法[126]。
- 主动性。智体应该能够通过采取主动而不是仅仅对环境做出反应来表现出目标导向的行为。例如,智体需要在智能助理等应用程序中主动提供帮助、建议和信息,并在自动驾驶机器人和自动驾驶汽车等领域积极探索环境、规划路径和执行任务。
值得一提的是,与人类一样,由于知识和计算能力的限制,智体无法做出完全理性的选择[185]。相反,可以根据不完美的信息做出次优但可接受的决策。这种能力对于在经济市场[13]和管理组织[162]中实现类人模拟尤为关键。例如,在模拟消费者行为、市场交易和商业决策时考虑智体的有限理性,可以更准确地反映真实的经济活动。此外,在模拟组织内的决策、团队合作和领导力时,有限理性有助于揭示真实工作环境中的行为动态。
在基于智体的模拟中建模技术的发展,也经历了知识驱动方法的早期阶段和数据驱动方法的最近阶段。具体而言,前者包括基于预定义规则或符号方程的各种方法,后者包括随机模型和机器学习模型。
- 预定义规则。这种方法包括定义管理智体行为的显式规则。这些规则通常基于逻辑或条件语句,这些语句规定了智体对特定情况或输入的反应。最著名的例子是细胞自动机[216],它利用简单的局部规则来模拟复杂的全球现象,这些现象不仅存在于自然世界中,也存在于复杂的城市系统中。
- 符号方程。与预定义的规则相比,符号方程用于以更正式的数学方式表示关系或行为。这些可以包括代数方程、微分方程或其他数学公式。一个典型的例子是广泛用于行人运动模拟的社会力模型[93]。它假设行人运动是由类似牛顿定律驱动的,该定律由目的地驱动的吸引力和来自相邻行人或障碍物的排斥力决定。
- 随机建模。这种方法将随机性和概率引入到智体决策中,有助于捕捉许多现实世界系统中固有的不确定性和可变性[70]。例如,为了考虑源自人类决策随机性的影响,可以利用离散选择模型来模拟行人走路行为[9]。
- 机器学习模型。机器学习模型允许智体从数据中学习或通过与环境的交互进行学习。监督学习方法通常用于估计基于智体的模型参数,而强化学习方法在模拟阶段被广泛使用,增强了智体在动态环境中的适应能力[107,108,160]。
基于智体的建模和仿真在许多领域都是仿真中采用的基本方法[135,65],但仍然面临着几个关键挑战。大语言模型赋能智体不仅满足了基于智体模拟的要求,而且依靠其强大的感知、推理、决策和自我进化能力解决了这些限制,如图所示。
与传统的模拟方法相比,基于智体的模拟,其适应不同规则或参数的能力。
第一个问题是现有方法的参数设置极其复杂[64,135]。在这些模型中,影响智体行为的大量变量——从个人特征到环境因素——使得选择和校准这些参数变得困难。这种复杂性往往导致过于简单化,损害了模拟在描绘真实异质性方面的准确性[135]。此外,获取准确和全面的数据以告知参数选择是另一个挑战。也就是说,在不同背景下捕捉不同个体行为的真实世界数据可能收集起来有限或具有挑战性。此外,根据真实世界的观测结果验证所选参数以确保其可靠性增加了另一层复杂性。
其次,规则或模型不能涵盖异质性的所有维度,因为现实世界中的个体非常复杂[135]。使用规则来驱动智体行为只能捕捉到异质性的某些方面,但可能缺乏封装各种行为、偏好和决策过程的深度。此外,作为模型容量,试图在单个模型覆盖异质性的所有维度是过于理想化了。因此,在基于智体的建模和仿真中,在模型的简单性和准确智体建模进行平衡是一个关键挑战,导致智体异构性某些方面过于简单化或直接被忽视。
与传统方法不同,基于LLM的智体支持:1)捕捉具有内部类人认知复杂性的内部特征,以及2)通过提示、上下文学习或微调的特殊和定制特征。
基于智体的建模和模拟的核心是智体如何对环境做出反应,以及智体如何相互作用,在这种情况下,智体的行为应该尽可能真实地接近具有人类知识和规则的真实世界个人。因此,在构建用于模拟的大语言模型赋能智体时,存在四大挑战,包括感知环境、与人类知识和规则保持一致、选择合适的动作和评估模拟。
对于具有大语言模型基于智体的模拟,第一步是构建虚拟或真实的环境,然后设计智体如何与环境和其他智体交互。因此,需要为LLM感知和交互的环境提出适当的方法。
尽管LLM在许多方面已经表现出显著的类人特征,但基于LLM的智体在特定领域仍然缺乏必要的领域知识,造成决策不合理。因此,将LLM智体与人类知识和价值观、特别是领域专家的知识和价值观念保持一致,是实现更现实域模拟的一个重要挑战。然而,智体的异质性作为基于智体建模(ABM)的一个基本特征,对传统模型来说既是优势也是挑战。同时,LLM具有强大的模拟异构智体的能力,确保了可控的异构性。然而,使LLM能够扮演不同的角色以满足个性化模拟需求,是一个重大挑战。挑战的讨论包括两方面:提示过程和微调。
LLM智体的复杂行为应该反映现实世界的认知过程。这涉及到理解和实现一些机制,这些人工智体以此可以保留和利用过去的经验(记忆)[152,73,241],根据其结果(反思)反省和调整其行为[152,181],执行一系列模仿人类工作流程的相互关联任务(规划)[213]。
基于LLM智体的基本评估协议是将模拟的输出与现有的真实世界数据进行比较。评估可以在两个层面进行:微观层面和宏观层面。与传统的基于规则或神经网络的智体相比,基于大语言模型智体的主要优势之一是它具有较强的交互式对话和文本推理能力。
除了基于大语言模型赋能的智体模拟准确性或可解释性之外,伦理问题也非常重要。第一个是偏见和公平,评估语言、文化、性别、种族或其他敏感属性中的偏见模拟,评估生成的内容是否会延续或缓解社会偏见,这一点至关重要。另一个令人担忧的问题是有害的输出检测,因为与传统方法相比,生成人工智能的输出很难控制。
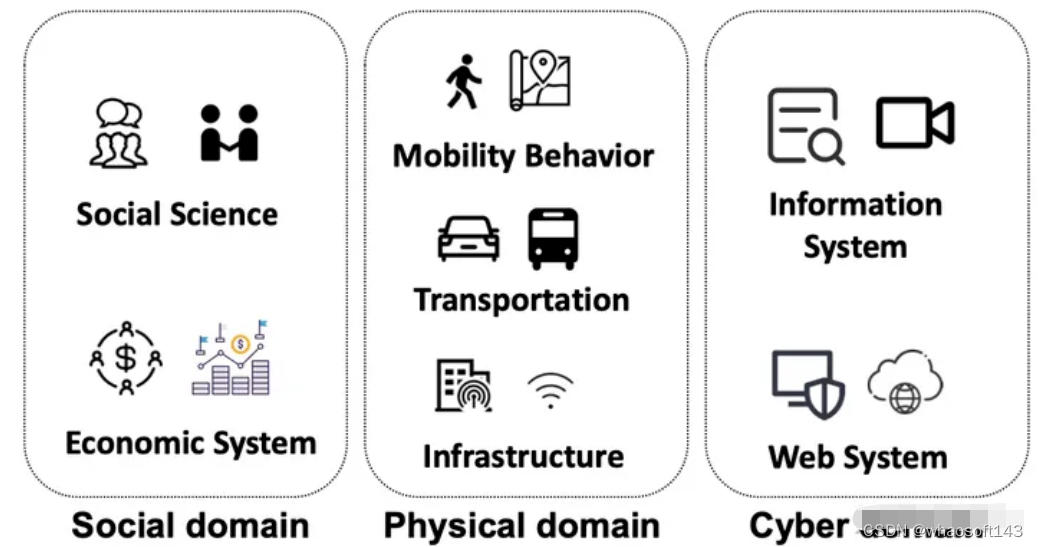
基于LLM智体的建模和仿真,其典型应用域包括社会、物理和网络及其混合,如图所示,细节见下表。
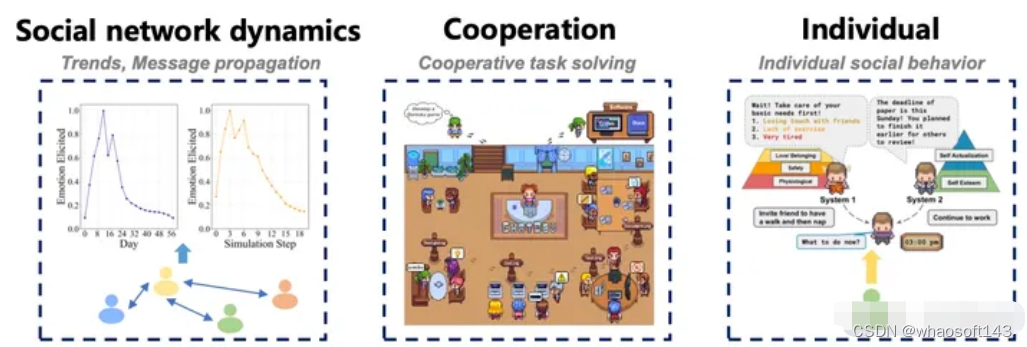
在经济域的应用类别:
在物理领域,基于LLM智体的建模和仿真应用包括移动行为、交通、无线网络等。
在一些研究中,模拟同时考虑多个域,如物理和社会域,这些模拟称为混合域。
#自动驾驶的Daily内容
端到端自动驾驶
- Recent Advancements in End-to-End Autonomous Driving using Deep Learning: A Survey
- End-to-end Autonomous Driving: Challenges and Frontiers
在线高精地图
- HDMapNet:基于语义分割的在线局部高精地图构建 (ICRA2022)
- VectorMapNet:基于自回归方式的端到端矢量化地图构建(ICML2023)
- MapTR :基于固定数目点的矢量化地图构建 (ICLR2023)
- MapTRv2:一种在线矢量化高清地图构建的端到端框架
- PivotNet:基于动态枢纽点的矢量化地图构建 (ICCV2023)
- LATR: 无显式BEV 特征的3D车道线检测 (ICCV2023)
- TopoMLP: 先检测后推理(拓扑推理 strong pipeline)
- LaneGAP:连续性在线车道图构建
- Neural Map Prior: 神经地图先验辅助在线建图 (CVPR2023)
- MapEX:现有地图先验显著提升在线建图性能
大模型与自动驾驶
- CLIP:Learning Transferable Visual Models From Natural Language Supervision
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
- ADAPT: Action-aware Driving Caption Transformer
- BEVGPT:Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning
- DriveGPT4:Interpretable End-to-end Autonomous Driving via Large Language Model
- Drive Like a Human Rethinking Autonomous Driving with Large Language Models
- Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
- HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving
- LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
- Planning-oriented Autonomous Driving
Nerf与自动驾驶
- NeRF: Neural Radiance Field in 3D Vision, A Comprehensive Review
- MobileNeRF:移动端实时渲染,Nerf导出Mesh(CVPR2023)
- Co-SLAM:实时视觉定位和NeRF建图(CVPR2023)
- Neuralangelo:当前最好的NeRF表面重建方法(CVPR2023)
- MARS:首个开源自动驾驶NeRF仿真工具(CICAI2023)
- UniOcc:NeRF和3D占用网络(AD2023 Challenge)
- Unisim:自动驾驶场景的传感器模拟(CVPR2023)
世界模型与自动驾驶
- World Models
- SEM2: Enhance Sample Efficiency andRobustness ofEnd-to-end Urban Autonomous
- FIERY: Future Instance Prediction in Bird’s-Eye Viewfrom Surround Monocular Cameras(ICCV2021)
- MILE: Model-Based lmitation Learning for UrbanDriving (NeurlPS 2022)
- GAIA-1:Wayve的自动驾驶生成式世界模型
- DriveDreamer:走向真实世界驱动的自动驾驶世界模型
- OccWorld:自动驾驶中的3D占用世界模型
- ADriver-l:通用自动驾驶世界模型
- Driving into the Future:端到端自动驾驶世界模型
- MUVO:多模态生成式自动驾驶世界模型
- Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
轨迹预测与自动驾驶
- Machine Learning for Autonomous Vehicle’s Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions
- Situation Assessment of an Autonomous Emergency Brake for Arbitrary Vehicle-to-Vehicle Collision Scenarios
- Vehicle Trajectory Prediction by Integrating Physics- and Maneuver-Based Approaches Using Interactive Multiple Models
- A Self-Adaptive Parameter Selection Trajectory Prediction Approach via Hidden Markov Models
- Vehicle Trajectory Prediction Considering Driver Uncertainty and Vehicle Dynamics Based on Dynamic Bayesian Network
- Naturalistic Driver Intention and Path Prediction Using Recurrent Neural Networks
- Intention-Aware Vehicle Trajectory Prediction Based on Spatial-Temporal Dynamic Attention Network for Internet of Vehicles
- Trajectory Prediction for Autonomous Driving Using Spatial-Temporal Graph Attention Transformer
- Multi-Vehicle Collaborative Learning for Trajectory Prediction With Spatio-Temporal Tensor Fusion
- STAG: A novel interaction-aware path prediction method based on Spatio-Temporal Attention Graphs for connected automated vehicles
- TNT: Target-driveN Trajectory Prediction
- DenseTNT: End-to-end Trajectory Prediction from Dense Goal Sets
Occupancy占用网络
- Grid-Centric Traffic Scenario Perception for Autonomous Driving: A Comprehensive Review
BEV感知
- Vision-Centric BEV Perception: A Survey
- Vision-RADAR fusion for Robotics BEV Detections: A Survey
- Surround-View Vision-based 3D Detection for Autonomous Driving: A Survey
- Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe
多模态融合
针对Lidar、Radar、视觉等数据方案进行融合感知;
- A Survey on Deep Domain Adaptation for LiDAR Perception
- MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving:A Review
- Multi-modal Sensor Fusion for Auto Driving Perception:A Survey
- Multi-Sensor 3D Object Box Refinement for Autonomous Driving
- Multi-View Fusion of Sensor Data for Improved Perception and Prediction in Autonomous Driving
3D检测
对基于单目图像、双目图像、点云数据、多模态数据的3D检测方法进行了梳理;
- 3D Object Detection for Autonomous Driving:A Review and New Outlooks
- 3D Object Detection from Images for Autonomous Driving:A Survey
- A Survey of Robust LiDAR-based 3D Object Detection Methods for autonomous driving
- A Survey on 3D Object Detection Methods for Autonomous Driving Applications
- Multi-Modal 3D Object Detection in Autonomous Driving:a survey
目标检测综述
主要涉及通用目标检测任务、检测任务中的数据不均衡问题、伪装目标检测、自动驾驶领域检测任务、anchor-based、anchor-free、one-stage、two-stage方案等;
- A Survey of Deep Learning-based Object Detection
- Deep Learning for Generic Object Detection:A Survey
- Imbalance Problems in Object Detection:A survey
- Object Detection in Autonomous Vehicles:Status and Open Challenges
分割综述
主要对实时图像分割、视频分割、实例分割、弱监督/无监督分割、点云分割等方案展开讨论;
- A Review of Point Cloud Semantic Segmentation
- A SURVEY ON DEEP LEARNING METHODS FOR SEMANTIC IMAGE SEGMENTATION IN REAL-TIME
- A SURVEY ON DEEP LEARNING METHODS FOR SEMANTIC
- A Survey on Deep Learning Technique for Video Segmentation
- A Survey on Instance Segmentation State of the art
目标跟踪
对单目标和多目标跟踪、滤波和端到端方法进行了汇总;
- Deep Learning on Monocular Object Pose Detection and Tracking:A Comprehensive Overview
- Detection, Recognition, and Tracking:A Survey
- Recent Advances in Embedding Methods for Multi-Object Tracking:A Survey
- Single Object Tracking:A Survey of Methods, Datasets, and Evaluation Metrics
- Visual Object Tracking with Discriminative Filters and Siamese Networks:A Survey and Outlook
深度估计
针对单目、双目深度估计方法进行了汇总,对户外常见问题与精度损失展开了讨论;
- A Survey on Deep Learning Techniques for Stereo-based Depth Estimation
- Deep Learning based Monocular Depth Prediction:Datasets, Methods and Applications
- Monocular Depth Estimation Based On Deep Learning:An Overview
- Outdoor Monocular Depth Estimation:A Research Review
Transformer综述
视觉transformer、轻量级transformer方法汇总;
- A Survey of Visual Transformers
- A Survey on Visual Transformer
- Efficient Transformers:A Survey
车道线检测
对2D/3D车道线检测方法进行了汇总,基于分类、检测、分割、曲线拟合等;
- CLRNet:Cross Layer Refinement Network for Lane Detection
- End-to-End Deep Learning of Lane Detection and Path Prediction for Real-Time Autonomous Driving
- LaneNet:Real-Time Lane Detection Networks for Autonomous Driving
- Towards End-to-End Lane Detection:an Instance Segmentation Approach
- Ultra Fast Structure-aware Deep Lane Detection
- 3D-LaneNet+:Anchor Free Lane Detection using a Semi-Local Representation
- Deep Multi-Sensor Lane Detection
- FusionLane:Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks
- Gen-LaneNet:A Generalized and Scalable Approach for 3D Lane Detection
- ONCE-3DLanes:Building Monocular 3D Lane Detection
- 3D-LaneNet:End-to-End 3D Multiple Lane Detection
SLAM综述
定位与建图方案汇总;
- A Survey on Active Simultaneous Localization and Mapping-State of the Art and New Frontiers
- The Revisiting Problem in Simultaneous Localization and Mapping-A Survey on Visual Loop Closure Detection
- From SLAM to Situational Awareness-Challenges
- Simultaneous Localization and Mapping Related Datasets-A Comprehensive Survey
模型量化
- A Survey on Deep Neural Network CompressionChallenges, Overview, and Solutions
- Pruning and Quantization for Deep Neural Network Acceleration A Survey
#开环端到端自动驾驶
UniAD[1]获得CVPR Best Paper Award后毫无疑问给自动驾驶领域带来了又一个热点: 端到端自动驾驶。同时马老师也在极力的宣传自己的端到端FSD。不过本篇文章只把讨论限定在一个很小的学术方向,基于nuScenes的开环端到端自动驾驶,会给出一些细节的东西,不讨论其它假大空的东西。
因为不能闭环所以被迫选择了开环
以能否得到反馈为标准,端到端自动驾驶的学术研究主要分为两类,一类是在模拟器比如CARLA中进行,规划的下一步指令可以被真实的执行。第二类主要是在已经采集的现实数据上进行端到端研究,主要是模仿学习,参考UniAD。开环的缺点就是无法闭环(好像是废话),不能真正看到自己的预测指令执行后的效果。由于不能得到反馈,开环自动驾驶的测评极其受限制,现在文献中常用的两种指标分别是
•L2 距离:通过计算预测轨迹和真实轨迹之间的L2距离来判断预测轨迹的质量•Collision Rate: 通过计算预测轨迹和其他物体发生碰撞的概率,来评价预测轨迹的安全性
事实上我们发现这两个指标完全不足以评判预测的轨迹的质量,一些技术看似提高了模型在这些指标上的表现,实则带来了其他没有被发现的问题,后续会介绍到。
nuScenes不是为planning设计的
关于开环端到端自动驾驶的测评问题最早在这篇文章[2] 中提到。在这篇文章中他们仅使用Ego Status就能够获得和现有Sota相比较的结果。但是第一次文章放出来的时候他们的数据好像用错了[3] 。同时他们错误的认为VAD也用了history trajectory, 但其实VAD[4]并没有使用历史轨迹。在AD-MLP中历史轨迹是一个默认使用的选项,当时本人理所应当的认为AD-MLP可能是受益于历史轨迹的使用,并没有特别在意这篇文章的结论。
不过后来实验受挫之后,心态发生了:”从相信端到端到怀疑端到端“的转变后,开始觉得AD-MLP的结论应该是对的。通过可视化很多nuScenes的整体场景,会发现相当比例的场景都是直行,而且速度变化不大,交互很少,如图1所示。考虑到我们对于AD-MLP使用历史轨迹的顾虑,我们复现了一版仅使用当前速度,加速度,转向角和转向指令的MLP网络。如图2所示,为了区分,将我们复现的这个网络记为Ego-MLP。Ego-MLP不使用任何传感器感知信息,监督loss仅为一个L2 Loss。同时我们还有一个更基础的驾驶策略Go Stright: 保持当前速度继续前进。
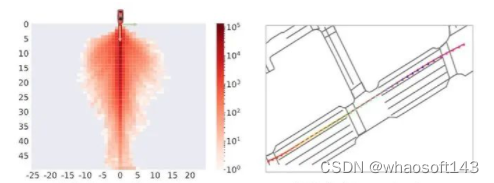
图1: nuScenes的场景相对简单,直行占比过大

图2:复现的AD-MLP,去掉历史轨迹输入,记为Ego-MLP
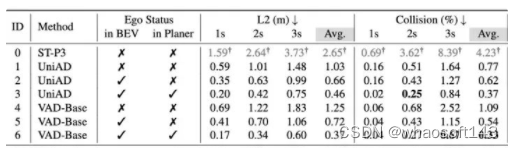
表2 实验结果由我们使用统一的Eval代码和策略获得,与之前文献中会有不一样的地方. ID-1,3,4为我们根据开源代码简单修改复现的结果, UniAD和VAD使用BEVFormer生成BEV特征,BEVFormer默认在BEV初始阶段引入can_bus (可以理解为ego status)信息
如表2所示,我们会有如下发现
•简单的直行策略(ID-7)在2s内的指标都挺高的。•Ego-MLP 不使用感知也能取得和现有sota差不多的结果。
第二条其实还可以换个角度这样理解,现有方法比如VAD, UniAD只有在Planner上引入Ego Status才能取得和Ego-MLP相似的效果。所以自然而然有了下面的问题:

Ego Status 引入会降低对感知的依赖
为了探究Perception 和Ego Status的效果,我们向这两个输入分别加扰动。如表3所示,在Planner中已经使用了Ego Status的情况下,就算把所有相机输入全部去掉,感知模块全部崩溃(结果变成0),模型的planning效果依然会在一个非常好的水平。我们相信这并不是一个正常的现象。与之对比的是模型会过渡依赖Ego Status的信息,假如我们改变输入模型的速度,会发现模型预测的轨迹基本会按照我们输入的假的速度去走,哪怕输入图像中事实上隐式地包含了ego的真实速度。如果输入速度全部设置成0的话,模型预测的轨迹基本处于原地不动的状态。
结合上面我们所讨论的仅使用Ego-Status的MLP网络就能获得sota效果,说明对于nuScenes来说,Ego Status就是预测轨迹的一条shortcut, 当模型引入Ego status的时候,自然会降低对于感知信息的利用。这样的表现很难让人相信端到端模型在复杂场景下的表现。
设计一个高效的Baseline 来验证Ego Status的效果
首先,我们实在负担不起在VAD或者UniAD上来做验证实验,举例来说UniAD的第二阶段训练在我们的8*V100上就需要10天。同时,ST-P3[5],一个经常被拿来比较的方法使用了部分不正确的训练和测试数据,产生的结果数值上是不准确的。
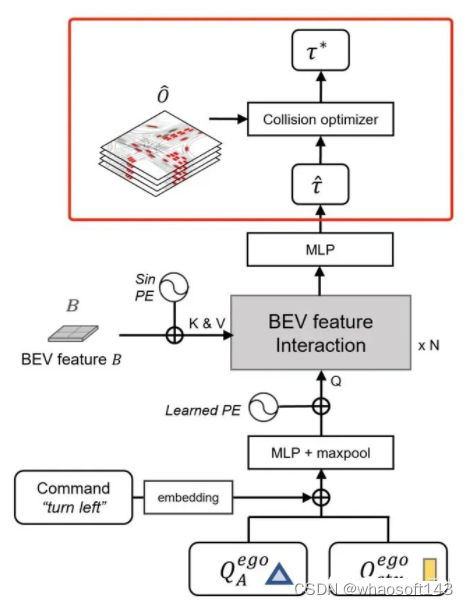
因此我们认为我们需要设计一个相对简洁高效的baseline方法能够快速验证我们的想法,并且能够跟现有方法进行有效对比。不同于UniAD的模块化设计,我们使用了一个非常非常简单的设计,如下图所示,我们提出的baseline网络直接使用生成的BEV特征与一个Ego query发生交互,然后通过MLP预测最终的轨迹。与UniAD等方法不同,我们的baseline方法不使用其他任何中间监督,包括但不限于Depth, Detection, Map, Motion 等。最终模型仅使用一个L2 loss来进行轨迹的监督。Ego Status可以在BEV阶段或者最终的MLP阶段选择性加入。我们的模型训练12ep需要大概6个小时。
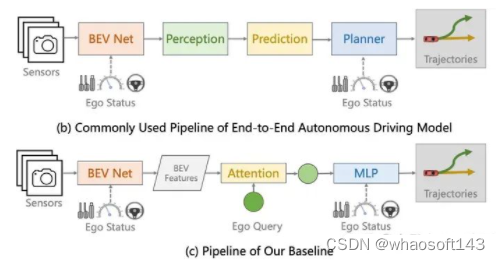
最终的结果如下表,在BEV和Planner中都使用Ego staus时,我们的方法(ID-12)和VAD-Base(ID-6)基本一致,这能说明我们的方法简单却有效吗?显然不能,这也正是Ego status主导planning性能所带来的影响,使用Ego status后,根本无需复杂设计就能取得和现有sota差不多的结果。在Ego status占据主导地位后,不同方法之间的差异根本体现不出来。事实上我们已经看到了类似的论文把使用ego status所带来的性能提升包装进自己方法里,用来展现自己方法的有效性。这是极其误导人的行为。
看似我们的方法在使用Ego Status时取得了不错的结果,但是从下图中可以看到,在Planner中使用Ego status的方法(Baseline++)似乎只用3k个iter就能收敛了,这显然是模型学到了Ego status到planning的short cut而非从视觉信息中获得有效线索。可视化BEV特征也发现,模型几乎没有从视觉分支中学习到什么有意义的表征。
我们暂时先不讨论为什么我们的方法在不使用ego status的情况下(ID-10)效果也不错的这个现象。
不用Ego Status不就完事了?
既然引入Ego Status会主导planning的学习,假如我们不想让这样的现象发生,那我们不用Ego Status不就完事了吗?第一时间这么想肯定没问题,但是
真的没有使用Ego Status吗?
为什么会有这个问题呢?因为我们发现很多方法会无意识的引入Ego Status。例如,BEVFormer默认使用了can_bus信息,这里面包含了跟自车速度,加速度,转向角相关的信息。这个东西对BEVFormer做感知其实是没啥用的,但是VAD和UniAD拿过来直接做planning话,can_bus就会发挥作用了。类似的Ego信息在感知方法中也经常被使用用来做时序对齐之类的事情。我们重新训练了去掉了can_bus的UniAD 和VAD模型,会发现明显的性能下降。考虑到ego status信息在最新的BEV方法中都被广泛使用,去掉这些信息的使用或者保证不同方法之间的公平比较都是非常困难的事情。一点点Ego status的泄漏都会对最终的planning性能产生巨大的影响。
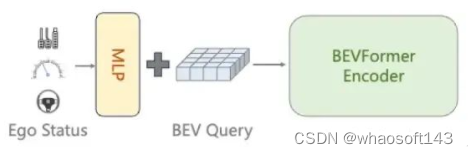
BEVFormer默认使用的can_bus_info包含ego status
去掉Ego Stutus仍存在的问题
讨论到现在,可能只是简单的认为责任全在ego status,很可惜并不是这样。当我们观察上面的表4,会看到我们的方法Baseline(ID-10)在不使用任何ego status的信息的情况下,可以取得和UniAD(ID-2), VAD(ID-5)这些在BEV上用了ego status的,使用了额外感知,预测任务的模型差不多的效果。 我们再回顾一下我们的Baseline (ID-4)的设置,输入图像256x704, 仅使用GT轨迹,不使用其他中间标注,仅使用L2 loss训练12ep。 为什么这样一个朴素到极致的方法会取得这样的效果?在这里我只给出我的一个猜想,不一定正确。 既然我们能够用ego status几个数值就拟合nuScenes大多数简单场景,说明学习nuScenes 大多数简单场景的planning本身就不是一件具有挑战性的事情,学习这些简单场景下的planning根本就不需要perception map等信息。其他方法使用了更多其他模块,带来更复杂的多任务学习,事实上反而影响了planning 本身的学习,我们也做了一个简单的实验来验证我们的猜想。

表5
如上表所示,Baseline 是原来的(ID-10)的结果,我们在Baseline上添加了一个MapFormer,具体实现做法和UniAD/VAD差不多,这个Baseline+Map模型的初始化是经过Map预训练的。我们可以看到Baseline+Map的结果远远逊色于Baseline。 原因是啥呢?为了消除Map预训练的影响,我们也使用Map预训练的权重作为(ID-10)这个setting的初始化得到了Baseline(init*)这个结果,通过对比Baseline不同初始化,我们可以发现,预训练的Map权重不会导致性能下降,反而会提升性能。问题只会出现在引入Map任务本身了。
我们对比了Baseline和Baseline+Map 在直行命令下的 L2 指标:L2-ST 和左右转指令下的L2指标: L2-LR。 同样还有在直行命令下的碰撞率指标Collision-ST, 在转弯场景下的碰撞率指标Collision-LR。 我们会发现在转弯场景下引入Map只是轻微增加L2距离,并且能够大幅度降低转弯场景下的碰撞率。与之对应的是直行场景下的L2和Collision被double了。考虑到转弯场景通常是更复杂,更需要操作的,而直行场景相对简单,我们猜测是因为引入Map 带来多任务学习的干扰反而影响了这些简单场景的学习。在nuScenes验证集上,直行命令占比87%,因此主导可最终的平均指标。我们可以看到Map引入在转弯场景下实际是没什么负面效果的,但是被平均之后Map的积极效果根本彰显不出来。
如果我们的猜想成立,这说明nuScenes做planning不单单是一个ego status的问题,而是本身全方面的不靠谱。
开环Planning指标
碰撞率指标的多个问题
我们暂时先不讨论L2 distance的问题, 因为好像更多的文章倾向于认可collision rate这个指标。实际上这个指标非常不靠谱,原因有:
•计算碰撞的时候,其他车的未来轨迹都是回放,没有任何reaction,单从这一点上讲,这个指标就很不靠谱。•实际实现的问题,由于预测的轨迹只是一堆xy坐标,没有考虑ego 的yaw angle在未来的变化,计算碰撞的时候也是假设ego car的yaw angle永远保持不变,会造成很多错误的碰撞计算。我们这次也是通过轨迹估算yaw, 统一解决了这个问题。
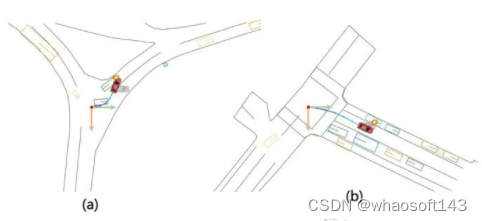
不考虑yaw angle变化的灰色小汽车会造成很多错误的碰撞计算

•Collision Rate可以被后处理进行攻击, UniAD中最有效的模块是一个后处理模块,在端到端模型给出一个初始的预测结果后,使用一个optimizer 来使得轨迹在满足一定约束条件下尽可能的远离其他物体,从而避免碰撞。从指标上讲,这个trick可以显著降低collision rate。然而看似合理的模块其实只是对于collision rate的一个hack, 原因在于约束条件不够多,例如没有考虑到地图信息。可以简单理解为:为了躲其他车,这个模块会选择打方向盘,冲到马路牙子上。但是根据现有指标,撞马路牙子是没有啥大问题的。
引入新指标
上面我们讨论了,汽车撞到马路牙子时,现在的指标是不会有什么显著惩罚的,造成一些方法可以通过用撞马路牙子的手段来降低与其他车发生碰撞的概率。所以我们使用了一个新的指标用来统计ego和road boundary(马路牙子)发生交集的概率。具体实现方法和collision rate的方法一致。经过统计,使用UniAD的后处理,降低0.1 %的碰撞概率的代价是增加5%以上与道路边界(马路牙子)发生交互的概率。这一后处理显然是不合理的,我们汇报UniAD的结果时,也都是默认不使用后处理的。
UniAD的后处理显著增加了与马路边间发生交互的概率
开环的DEMO真的可靠吗
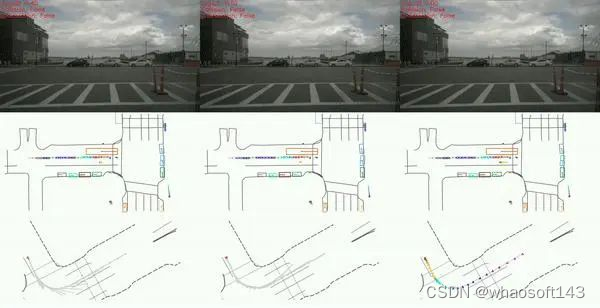
左:根据当前速度直行,中:Ego-MLP 右: GT
我们可以看到左边这列使用最简单的按照当前速度直行的策略,也会减速让行,避让车辆。这其实这都是human driver 的操作。 对于开环方法,每一时刻都会刷新回human driver驾驶的安全轨迹,沿用human driver的驾驶策略。因此开环端到端方法每时每刻都是在一个安全的轨迹之上做未来的预测,不受到累计误差的影响。再难的路, 0.5s后 human driver总会给你正确答案。
你的开环端到端模型能学会转弯吗?

我们发现似乎所有的开环模型都没有学会怎么转弯,转弯的时候预测的轨迹和真实轨迹差别很大,而且前后预测的轨迹不smooth,也就是前后不一致。
总结
基于nuScenes的开环端到端自动驾驶,所面临的问题太多了,心累了。
参考
[1] : https://arxiv.org/pdf/2212.10156.pdf[2] : https://arxiv.org/pdf/2305.10430.pdf[3] : https://github.com/E2E-AD/AD-MLP/issues/4[4] : https://github.com/hustvl/VAD[5] : https://github.com/OpenDriveLab/ST-P3
# 开源驾驶仿真平台推荐
沉寂快两年之后,终于开始重新更新知乎。这是对于开源驾驶仿真平台测评 - 2021 的更新、扩展与补充,也是个人工作的介绍和宣传。
本文的详细版本敬请期待 Choose Your Simulator Wisely: A Review on Open-source Simulators for Autonomous Driving。这篇论文中:
- 回顾了驾驶仿真器至今为止发展历史,预测了之后可能的发展趋势;
- 调研了截止2023年为止具有一定影响力的开源驾驶仿真器的维护状态、功能、性能、适用场景,基于用途,对现有驾驶仿真器进行了分类和推荐;
- 论证了目前开源驾驶仿真器中存在的关键问题,主要划分为真实性和仿真性能两大方面,讨论了这些关键问题的重要性,并调研了可能的解决方案。
论文目前处于Early Access状态,完整版估计要下个月才会上线。
动机
博士生涯之初,因为对CV不是那么感兴趣,我强转去研究驾驶决策算法,并一度沉迷强化学习。然而,在验证算法性能之前,找到合适的实验平台和benchmark是非常重要的。而调研过程中,我发现开源驾驶仿真器充斥着各式各样的问题,导致基于仿真验证的驾驶决策算法在投稿时容易因为不具有实用性遭到质疑。近年来,开源的驾驶仿真平台层出不穷,但是由于性能、维护状态等问题,它们不一定有让研究者能更轻松地在这个领域起步,反而是多了一个个需要亲自趟过的坑。
这种情况下,我们有必要对适用于自动驾驶相关任务的仿真器进行较为全面的调研,检查目前仍然值得使用的开源驾驶仿真器还有哪些,并讨论现有开源仿真器中存在的局限,从而有意识地避免由于相关方面的算法验证实验不够充分导致的质疑。另一方面,本文也可以视为对开源驾驶仿真器的开发者的建议,从用户的角度列举许愿了目前呼声较高的待解决的关键问题,有利于开发者们更有针对性地优化自己的仿真器。
历史
驾驶仿真器的发展历史与本篇博客的关联性不大,在此略过。
总览
筛选标准
在回顾仿真器历史和分类仿真器的过程中,由于商业仿真器在某些任务上具有开源仿真器不可比拟的优势——有些领域中甚至是商业仿真器独大的,因此我们必须将它们纳入调研范围。但是在推荐工具和讨论现有不足的环节,考虑本文主要面对的是广大资源体量较小的学术实验室和个人研究者(而且我也没有拿到那么多授权),所以会回退到仅讨论开源仿真器的状态。
因为近年来发布的仿真器数量较多,而我们人手有限,所以在调研过程开始前,设置了几条较为简单粗暴的基准来筛选候选仿真器,若有遗漏还请多多包涵:
- 商业仿真器的调研主要基于工业界合作方和专家推荐,需要该仿真器有可访问的官方网站;
- 开源仿真器的论文在google scholar上已有大于等于100的引用量;
- 开源仿真器的仓库有大于100的star;
考虑到手头资源的局限性,我们没有实际测试各个仿真器的硬件在环测试(Hardware-in-the-loop testing)能力,而是总结了软件所有者在网站/论文中自我声明的支持水平。
目前不同类型的仿真器大致情况如表所示。我们判定维护状态的方式是检查该软件在一年的时间内是否有进行过任何类型的更新,若没有则视为不再积极维护,若最近更新恰好是在一年左右,则标注为问号,一年以内有更新则视为正常维护状态。完整表格请见正式发表的论文。
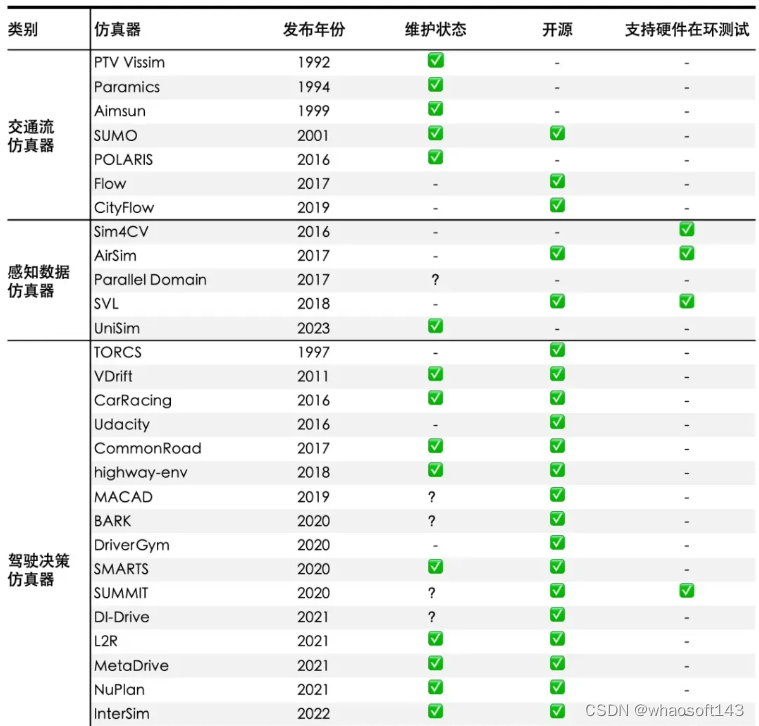
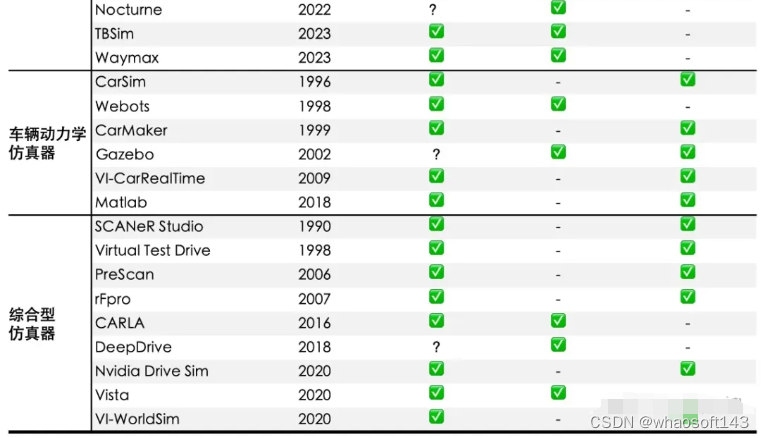
常见开源/商用仿真器的状态一览
分类
本节对于上表中的仿真器类别定义进行简单的说明,并基于相关任务推荐开源仿真器(在正式论文中有更详细的表格列举不同类型仿真器的具体功能)。
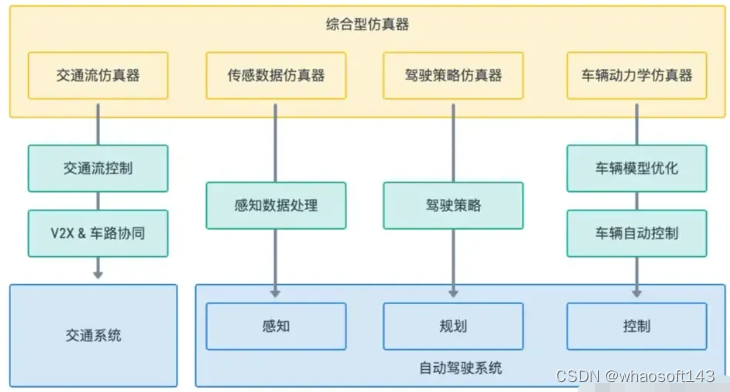
仿真器分类与任务的关联
交通流仿真器
这类仿真器主要用于模拟大规模的车流在交通系统中的运行状态,它们的特征一般包括可以编辑的路网结构、微观交通流,并通常采用模式较为单一的驾驶行为模型操纵车辆。自动驾驶中研究车路协同、车队、联网智能车(Connected and Autonomous Vehicle, CAV) 相关的任务可以用到这类仿真器。这类仿真器中,目前还处于积极维护状态的热门开源仿真器只有SUMO。
传感数据仿真器
这类仿真器的目的是弥补真实数据中缺少极端天气样本,增强感知模型的泛化性。它们追求的是在各类不同光照、能见度、反光率等状态下,通过渲染或学习类方法生成高真实性的光学类感知数据(RGB图像、语义分割、实例分割、甚至是激光雷达)。因为这类仿真器的开发成本高、难度大,而实际收益较低,相关的开源仿真器已经基本停止维护。如果有利用仿真器生成训练/测试感知数据的需求,目前较为合适的选项是综合型仿真器CARLA。
驾驶决策仿真器
驾驶决策仿真器是指用途仅为验证驾驶决策算法的仿真器,它们与综合型仿真器的主要区别在于,为了节约开发成本,这些仿真器往往省略或简化了车辆动力学模型的建模,也无法生成真实的原始感知数据。大部分驾驶决策仿真器只提供了鸟瞰视角的语义分割数据,不过,相应地,在多智能体并行仿真、交通参与物行为模式模拟方面,它们往往有更好的表现。对于模仿学习算法的研究者来说,只要保证环境能够提供理想的环境感知结果,决策模型的运行基本可以脱离环境,所以选择仿真器时会有更大的自由度。除了VDrift,其他积极维护中的仿真环境基本都提供了原生的RL训练支持,所以也可以基于需求选择。MetaDrive作为一款轻量级的、有3D图像界面、可以无限生成交通场景的仿真器,在训练端对端的驾驶决策模型时较为推荐。
车辆动力学仿真器
这类仿真器主要模拟的是车辆的物理运动表现,早早在车辆设计工程中有所应用,因此历史悠久。在自动驾驶相关的任务中,车辆控制通常需要在高真实性的车辆动力学仿真器上验证。这类仿真器需要收集大量实车在各类极限状态下的行为数据,这意味着,如果没有与车辆制造商的紧密合作,想凭空建模一个准确的车辆物理模型是几乎不可能的。这类仿真器的开发也不出意外地被一些老牌商业软件所垄断。开源软件中,机器人学中常用的Gazebo是为数不多可用的选项,而基于Matlab的车辆动力学在学界的实践中也较为常见(工业界的请不要来得瑟了,卑微.jpg)。
综合型仿真器
综合型仿真器是能为多个自动驾驶相关任务提供仿真验证的软件。在Nvidia Drive Sim可能的开源之前,开源软件中,能够独占鳌头的工作,毫无悬念地是CARLA。
说起来也挺好笑的,前几年调研时看好的LGSVL和AirSim都转成Archive模式了,只能说仿真本身是真的难做 ಥ_ಥ
关键问题
目前开源仿真器普遍面临真实性、仿真效率方面的问题。这里提供对关键问题的简单描述,对于可能改进方法的调研请见论文。
真实性-感知数据
感知模块面临一大挑战是算法的泛化性。即使是物体检测这类基础任务,在极端天气时,感知模型的性能也会大幅度下降。通过收集真实数据确实可以解决这个问题,但是极端天气在现实中的出现往往非常随机,想创造相关的大规模数据集对时间和成本要求都很高。有必要充分发挥仿真器的优势,去生成更真实的不同模态的原始感知数据。
其实,在游戏开发领域,已经积累了大量渲染相关的技术基础,如果能在仿真器中应用这些技术自然是最好的。但考虑到游戏的图像渲染未必能在真实性上达到要求,另外一种思路是仿真器提供原生接口,允许接入基于学习的图像生成/风格处理类型的算法,访问三维建模,并直接对其进行处理。
真实性-交通场景
交通场景中主要可以分成几个部分:静态的地图和交通标志、随时间规律变化的交通规则(指红绿灯等)、和随机性强的交通参与物。地图和交通规则主要是在自动构建方面存在瓶颈,影响了仿真器的发展,这个之后会说明。而影响交通场景真实性的主要因素是交通参与物的行为模型。前几年,大部分仿真器中要么提供基于统一规则的行为模型,仅在参数上有一定多样性;要么直接规避掉这个问题,只提供记录回放功能。近年来,InterSim,TBSim的出现反应了相关问题在逐渐得到重视,但仍然需要进一步的研究。
真实性-车辆模型
车辆模型的真实性一直是阻碍基于仿真器验证的自动驾驶系统直接上实车的拦路虎。正如前文提到的,独立的研究者们想要分头解决这个问题是不现实的,理想主义的情况下,要么等待车辆制造商良心发现,公布他们的核心机密,或者大家可以基于手头的实车,共享一些实体个例实验车辆的运行记录,创建符合某种社区规范的公共数据集。事实上,在现实中这两种模式都基本是幻想,这边也就做做梦。
仿真效率-数据准备-格式不一致性
现在很多开源仿真器对于公开轨迹数据集、地图格式的支持还有所不足,导致研究者们反复造轮子,或者为了使用特定的数据集/地图格式而在某几个仿真器之间跳来跳去。这极大地拖慢了仿真数据的准备过程。
仿真效率-数据准备-手动地图标注
目前的地图标注过程中仍有大量手工劳动的成分,OpenDRIVE地图如此,三维高精地图更是如此。这对于批量创造多样化的交通场景来说是一个瓶颈。近年来,快速自动构建地图的算法在大力发展,NeRF基本可以说是无人不晓,但是NeRF在数据格式和粒度方面显然都还无法达到工程要求,需要进一步发展。
仿真效率-运行速度
因为开源仿真器的开发者大部分是在为爱发电,势单力薄,在仿真软件的性能、远程/分布式部署、并行运算等方面显然难以做到尽善尽美。甚至有一部分开源仿真器不一定能够实时运行,想要以现实的多倍速加速训练和测试过程更是相当困难,但这往往是用户需求最强烈的问题,所以有必要进行优化。
仿真效率-迁移-HIL测试
开源仿真器与商业软件的一大差距也在于对HIL测试的支持。从表格中可以看出,有这一功能的开源仿真器寥寥无几。不过这主要是一个工程问题,搭建和维护HIL测试的接口都需要大量人力物力,只能说,用户在进行仿真测试的时候,需要注意被测算法往往距离上实车存在差距,并在描述实验设计时需要注意防范可能的漏洞。
开源仿真器联合宣传
以下是与正文有关的广告环节~
这些描述均为我带着个人感情色彩的一家之言,并没有被任何期刊正式收录,所以请仔细甄别,自行判断信息价值。
Tactics2D
这是我正在开发的驾驶策略仿真器。沿袭我们朴素型决策模型研究者的风格,提供BEV视角的语义分割图作为环境反馈,除此之外,还添加了单线激光雷达的感知结果。
github链接:https://link.zhihu.com/?target=https%3A//github.com/WoodOxen/tactics2d
- 疯狂的轨迹数据集兼容:如果大家有对其他数据集的解析需求,欢迎提issue~
- Argoverse;
- DLP泊车场景数据集 (这位作者人超好,帮忙写了个自动下载数据的脚本,指路数据的下载网址;
- INTERACTION
- LevelX系列(highD, inD, rounD, uniD, exiD):这两天因为数据提供方要求,移除了数据集中的原始数据样本,但我自己标注的地图应该很快会重新放出来
- NuPlan
- Waymo Motion Open Dataset(地图处理还有一些bug要修)
- 花式地图格式兼容:V1.0.0中会提供对OSM,Lanelet2标注风格OSM,OpenDRIVE的解析支持。基于现在为数不多的用户的反馈,之后计划添加地图&场景导出为SUMO路网的支持。
- 泊车/赛车场景生成:自制了一个无限生成泊车场景的RL环境,还基于Gym-box2d优化了一下CarRacing,打算继承维护。
- 基于log replay的可交互场景生成:通过加载上述数据集中的场景,随机选取车辆作为决策模型控制的代理,并对其他场景内车辆注入行为模型,在代理车辆影响log轨迹时接管车辆并进行交互。
- 高度自定义性:你几乎可以自定义交通场景中的任何部件——交通参与物、地图元素、环境的奖惩函数、新的行为模型导入。我们非常欢迎新功能的加入。目前智能体交互模块还没调试好,打包发布的流程也还在测试,预计在这个月底前正式发布V1.0.0版本。欢迎大家早早关注,加入discord社群来帮忙内测 QAQ。
MetaDrive
这是 @Blackmore 大神主导开发的仿真器,是一份非常nb的工作,唯一的缺点是我的仿真器在某些方面的性能干不过他的,只好灰溜溜去开发其他特色,避免成为竞品(手动狗头)。
github链接:https://link.zhihu.com/?target=https%3A//github.com/metadriverse/metadrive
特色:
- 非常轻量级,多智能体模式下仿真效率非常高,我拿2080的显卡,跑30 agent的场景,还能保持20Hz的运行速度。
- 无限的交通场景生成:Open-Source Platform for Large-Scale Traffic Scenario Simulation and Modeling
- 支持远程部署和并行计算。
- 还有很多其他功能,欢迎大家自行探索。
Tactics
显然,这是Tactics2D的兄弟。很不幸的是,它的完成度非常低,在我博士毕业之前,基本不要指望它能发布。
它的建设目标是一个高真实度但是轻量级的三维仿真器,能够满足对极端天气的传感数据模拟需求,内带拖拽式地图编辑功能(参考city skyline),基于感知数据自动生成3D高精地图(这一部分将由我明年入学的学弟主导进行,可想而知这个仿真器的开发周期),也会提供对于一些冷门类型,如二截式拖挂车的动力学模型仿真。
它的最大特色同样也包括了高度的自定义性,我打算尽可能地保持软件本身的鲁棒性,允许它接入各式各样的渲染后处理模型、交通参与物行为模型、动力学模型。作为理想主义的神经病,我真的在考虑围绕Tactics搭建一个类似Steam创意工坊的平台,允许大家共享各式各样的车辆、标志、道路类型参数——说不定最后你就是通过Steam下载它。
因为这个项目的常驻开发者只有我一个人,前面三年我只设计好了整个系统的架构,搞明白了开发它需要哪些方面的专业知识,功能实现目前还是鸡零狗碎的,只做了极端天气和动力学模型。如果有对这个项目感兴趣的朋友,非常欢迎私信我,大家一起来堆城堡~
gitlab链接:https://link.zhihu.com/?target=https%3A//github.com/WoodOxen/tactics

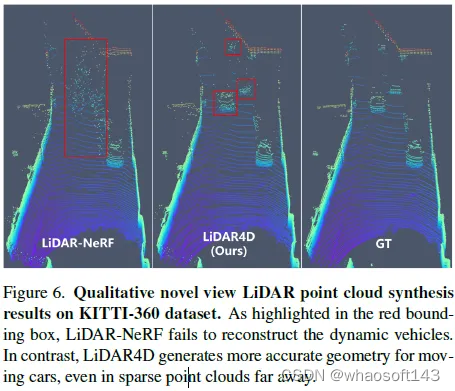
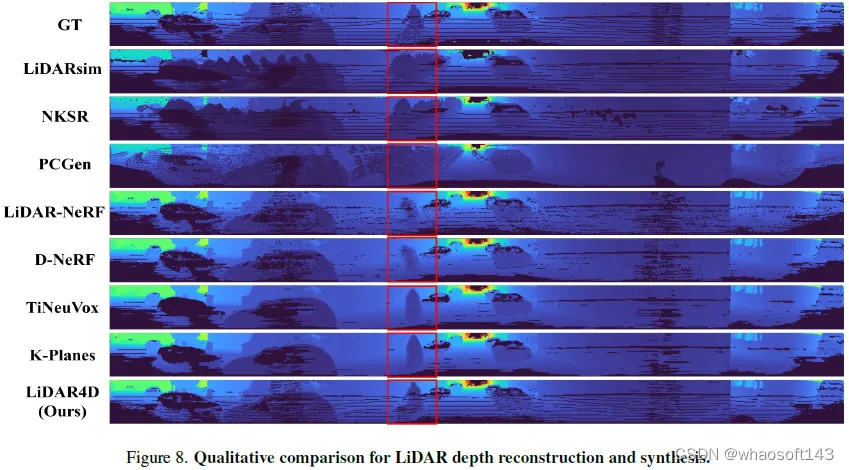
# LiDAR4D会是LiDAR重建的答案么
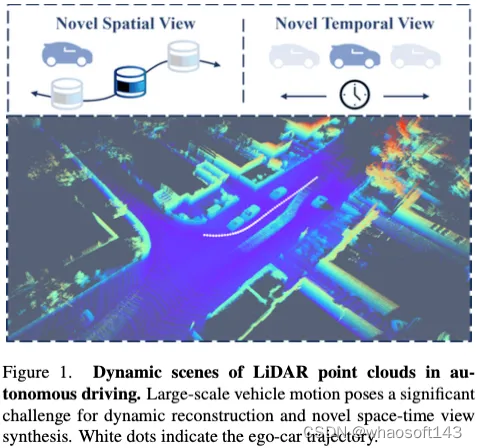
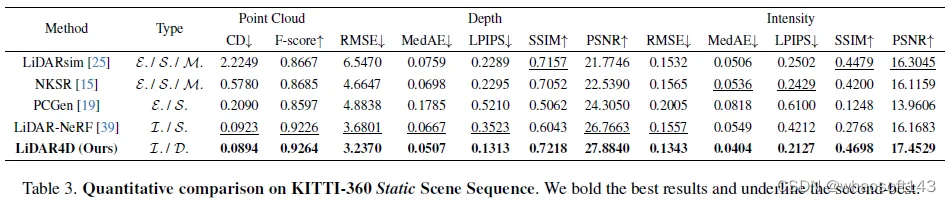
尽管神经辐射场(NeRFs)在图像新视角合成(NVS)方面取得了成功,但激光雷达NVS的发展却相对缓慢。之前的方法follow图像的pipeline,但忽略了激光雷达点云的动态特性和大规模重建问题。有鉴于此,我们提出了LiDAR4D,这是一种用于新的时空LiDAR视图合成的LiDAR-only的可微分框架。考虑到稀疏性和大规模特征,进一步设计了一种结合多平面和网格特征的4D混合表示,以实现从粗到细的有效重建。此外引入了从点云导出的几何约束,以提高时序一致性。对于激光雷达点云的真实重建,我们结合了ray-drop概率的全局优化,以保持cross-region模式。在KITTI-360和NuScenes数据集上进行的大量实验证明了我们的方法在实现几何感知和时间一致的动态重建方面的优越性。
开源地址:https://github.com/ispc-lab/LiDAR4D
总结来说,本文的主要贡献如下:
- 提出了LiDAR4D,这是一种用于新的时空LiDAR视图合成的LiDAR-only的可微分框架,它重建动态驾驶场景并端到端生成逼真的LiDAR点云。
- 介绍了4D混合神经表示和从点云导出的运动先验,用于几何感知和时间一致的大规模场景重建。
- 综合实验证明了LiDAR4D在具有挑战性的动态场景重建和新颖视图合成方面的SOTA性能。
相关工作回顾
激光雷达仿真。CARLA等传统仿真器基于物理引擎,可以在手工制作的虚拟环境中通过光线投射生成激光雷达点云。然而,它有多样性限制,并且严重依赖昂贵的3D资产。与真实世界的数据相比,domain gap仍然很大。因此,最近的几项工作通过在仿真之前从真实数据重建场景,进一步缩小了这一差距。LiDARsim重建网格表面表示,并使用神经网络来学习光线下降特性。此外,值得注意的是,还有其他表面重建工作,如NKSR,可以将激光雷达点云转换为网格表示。尽管如此,这些显式重建工作对于在大规模复杂场景中恢复精确的曲面来说是麻烦的,这进一步导致点云合成的精度下降。相反,PCGen直接从点云进行重建,然后以类似光栅化的方式进行渲染并进行第一次峰值平均。尽管它更好地保留了原始信息,但渲染点云仍然相对嘈杂。此外,上述所有这些显式方法仅适用于静态场景。相反,我们的方法通过时空神经辐射场隐式重建连续表示,实现了更高质量的真实点云合成,摆脱了静态重建的局限。
神经辐射场。最近基于神经辐射场的大量研究在新视图合成(NVS)任务中取得了突破和显著成就。基于MLP、体素网格、三平面、向量分解和多级哈希网格的各种神经表示已被充分用于重建和合成。然而,大多数工作都集中在以目标为中心的室内小场景重建上。随后,几部作品逐渐将其扩展到大型户外场景。尽管如此,神经辐射场通常在RGB图像输入的情况下存在几何模糊性。因此,DS-NeRF和DDP-NeRF在提高效率之前引入了深度,URF还利用激光雷达点云来促进重建。在本文中,我们使用新的混合表示和神经激光雷达场来重建激光雷达NVS的大规模场景。
用于激光雷达NVS的NeRF。最近,一些研究开创了基于神经辐射场的激光雷达点云新视图合成的先河,大大超过了传统的仿真方法。其中,NeRF-LiDAR和UniSim需要RGB图像和LiDAR点云作为输入,并在具有光度损失和深度监督的情况下重建驾驶场景。随后,可以通过神经深度渲染生成新的视图LiDAR点云。在仅使用LiDAR的方法中,LiDAR-NeRF和NFL首次提出了可微分LiDAR-NVS框架,该框架同时重建了深度、强度和raydrop概率。然而,这些方法仅限于静态场景重建,并且不能处理诸如移动车辆之类的动态目标。尽管UniSim确实支持动态场景,但它在很大程度上受到3D目标检测的地面实况标记以及重建前背景和动态目标解耦需求的限制。相反,我们的研究专注于仅用于动态场景重建和新颖时空视图合成的激光雷达输入,而无需RGB图像或地面实况标签的帮助。值得注意的是,NFL对激光雷达的详细物理建模做出了重大贡献,如光束发散和二次返回,这与我们的正交,可能有利于所有激光雷达NVS工作。
动态场景重建。大量的研究致力于扩展神经辐射场,以涵盖动态场景重建。一般来说,动态NeRF可以大致分为两组。一种是通过连续变形场将坐标映射到规范空间的可变形神经辐射场。虽然变形场和辐射场的解耦简化了优化,但建立准确的远距离对应仍然具有挑战性。另一个是时空神经场,它将时间视为构建4D时空表示的额外维度输入。因此,可以灵活地将外观、几何结构和运动同时建模为连续的时变函数。之前的大多数工作都集中在室内相对较小的位移上,而自动驾驶场景中的大规模车辆移动则更具挑战性。此外,我们的工作也是首次将动态神经辐射场引入激光雷达NVS任务。
详解LiDAR4D
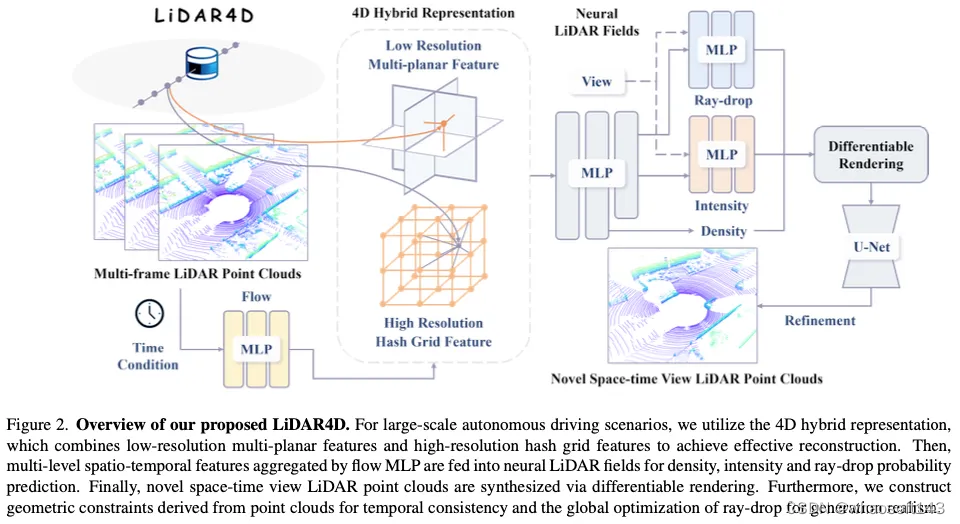
本节从新型激光雷达视图合成的问题公式和NeRF的初步问题开始。在此之后,提供了我们提出的LiDAR4D框架的详细描述。
问题公式。在动态驾驶场景中,给定收集的激光雷达点云序列,以及相应的传感器姿态和时间戳作为输入。每个单个激光雷达帧Si包含3D坐标x和1D反射强度ρ的K个点。

LiDAR4D概述
根据神经辐射场,我们提出的LiDAR4D将点云场景重建为隐式连续表示。与RGB图像具有光度损失的原始NeRF不同,我们重新定义了基于激光雷达的神经场,称为神经激光雷达场。如图2所示,它专注于对激光雷达点云的几何深度、反射强度和光线下降概率进行建模。对于大规模动态驾驶场景,LiDAR4D将粗分辨率多平面特征与高分辨率哈希网格表示相结合,实现高效有效的重建。然后,我们将其提升到4D,并将时间信息编码引入到新的时空视图合成中。为了确保几何感知和时间一致的结果,我们还引入了从点云导出的显式几何约束。最终,我们预测每条光线的raydrop概率,并使用运行时优化的U-Net执行全局细化,以提高生成真实性。
4D Hybrid Planar-Grid Representation
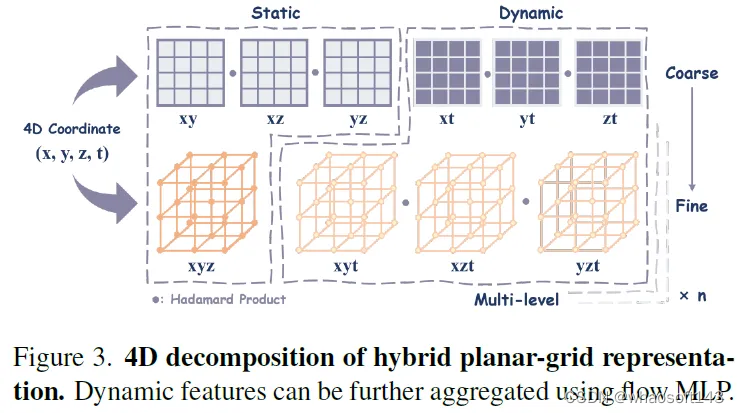
图3说明了我们提出的新的混合表示如何将4D空间分解为平面和哈希网格特征,这些特征进一步细分为静态和动态特征。与室内小物体的重建不同,大规模自动驾驶场景对特征的表示能力和分辨率提出了更高的要求。然而,TiNeuVox等密集网格表示由于其立方体增长的复杂性,对于大规模场景是不可缩放的。因此,我们遵循K平面,将场景空间分解为多个正交平面中的特征组合,以大幅减少参数量。平面特征可以如下获得:

其中密集网格G将通过散列映射被进一步压缩到有限的存储器中以用于参数缩减。类似地,在三线性插值和级联之前,4D坐标被投影到静态(xyz)和动态(xyt,xzt,yzt)多级哈希网格中,其中使用Hadamard乘积来乘以动态特征。
然而,值得注意的是,纯哈希网格表示仍然存在视觉伪影和噪声重建结果(如图4所示),这阻碍了精确对象几何结构的构建。有鉴于此,我们采用低分辨率的多平面特征进行整体平滑表示,并采用高分辨率的哈希网格来处理更精细的细节,最终在大规模场景重建中实现高精度和高效率。
Scene Flow Prior
为了增强当前4D时空表示的时间一致性,我们进一步引入了用于运动估计的流MLP。它将编码的时空坐标作为输入,并构建从坐标场R4到运动场R3的映射。

Neural LiDAR Fields

Ray-drop Refinement
在激光测距过程中,一部分发射的光线不会反射回传感器,这被称为光线下降特性。事实上,激光雷达的射线降受到各个方面的显著影响,包括距离、表面特性和传感器噪声。与LiDAR-NeRF中一样,ray-drop预测是直接用逐点MLP头来完成的,这本质上是有噪声和不可靠的。为了解决这个问题,我们使用具有残差的U-Net来全局细化ray-drop掩模,并更好地保持跨区域的一致图案。它以LiDAR4D的全射线下降概率、深度和强度预测为输入(与之前的工作不同),并通过二进制交叉熵损失细化最终掩模,如下所示:

Optimization
对于LiDAR4D的优化,总重建损失是深度损失、强度损失、ray-drop损失、流量损失和精细化损失的加权组合,可以形式化为:
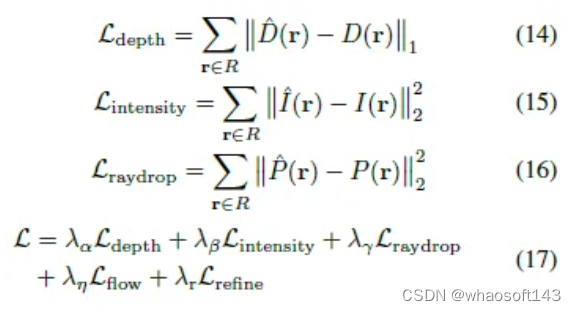
实验
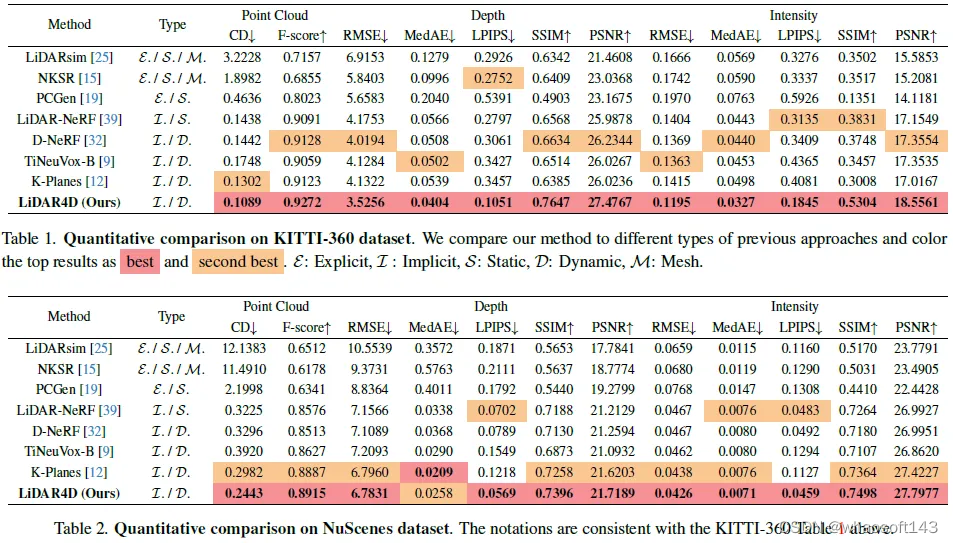
LiDAR4D在KITTI-360和NuScenes上展开实验。

限制
尽管LiDAR4D在大量实验中表现出了非凡的性能,但点云的远距离车辆运动和遮挡问题仍然是悬而未决的问题。与静态对象相比,动态对象的重建仍然存在显著差距。此外,前景和背景可能难以很好地分离。此外,基于真实世界的数据集,NVS的定量评估仅限于自车轨迹,不允许新的空间和时间视图合成的解耦。
结论
本文重新审视了现有激光雷达NVS方法的局限性,并提出了一个新的框架来应对三大挑战,即动态重建、大规模场景表征和逼真合成。我们提出的方法LiDAR4D在大量实验中证明了其优越性,实现了大规模动态点云场景的几何感知和时间一致性重建,并生成了更接近真实分布的新时空视图LiDAR点云。我们相信,未来更多的工作将集中在将激光雷达点云与神经辐射场相结合,探索动态场景重建和合成的更多可能性。
# 如何利用transformer有效关联激光雷达-毫米波雷达-视觉特征
自动驾驶的基础任务之一是三维目标检测,而现在许多方法都是基于多传感器融合的方法实现的。那为什么要进行多传感器融合?无论是激光雷达和相机融合,又或者是毫米波雷达和相机融合,其最主要的目的就是利用点云和图像之间的互补联系,从而提高目标检测的准确度。随着Transformer架构在计算机视觉领域的不断应用,基于注意力机制的方法提高了多传感器之间融合的精度。分享的两篇论文便是基于此架构,提出了新颖的融合方式,以更大程度地利用各自模态的有用信息,实现更好的融合。
TransFusion:
主要贡献
激光雷达和相机是自动驾驶中两种重要的三维目标检测传感器,但是在传感器融合上,主要面临着图像条件差导致检测精度较低的问题。基于点的融合方法是将激光雷达和相机通过硬关联(hard association)进行融合,会导致一些问题:a)简单地拼接点云和图像特征,在低质量的图像特征下,检测性能会严重下降;b)寻找稀疏点云和图像的硬关联会浪费高质量的图像特征并且难以对齐。
因此,此论文提出一种激光雷达和相机的融合框架TransFusion,来解决两种传感器之间的关联问题,主要贡献如下:
- 提出一种基于transformer的激光雷达和相机的3D检测融合模型,对较差的图像质量和传感器未对齐表现出优异的鲁棒性;
- 为对象查询引入了几个简单而有效的调整,以提高图像融合的初始边界框预测的质量,还设计了一个图像引导查询初始化模块来处理在点云中难以检测到的对象;
- 不仅在nuScenes实现了先进的三维检测性能,还将模型扩展到三维跟踪任务,并取得了不错的成果。
模块详解
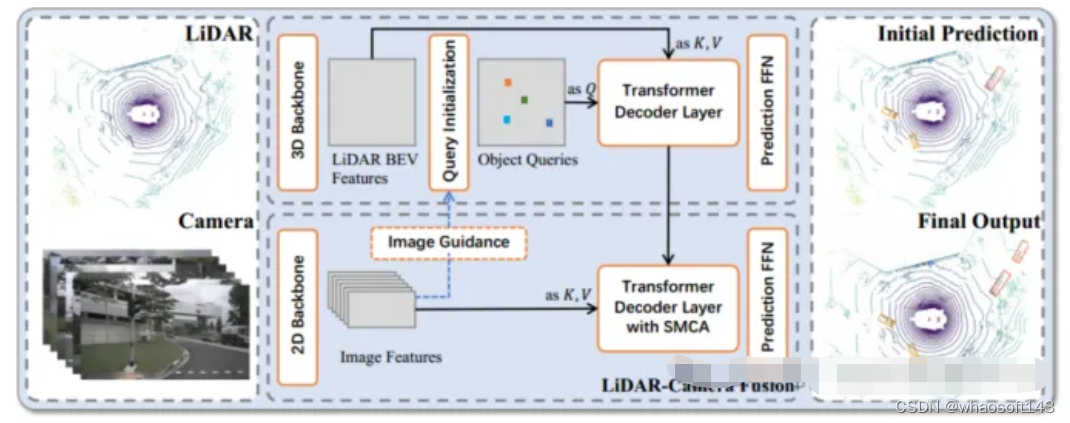
图1 TransFusion的整体框架
为了解决上述的图像条件差以及不同传感器之间的关联问题,提出了一个基于Transformer的融合框架——TransFusion。该模型依赖标准的3D和2D主干网络提取LiDAR BEV特征和图像特征,然后检测头上采用两层transformer解码器组成:第一层解码器利用稀疏的点云生成初始边界框;第二层解码器将第一层的对象查询与图像特征相关联,以获得更好的检测结果。其中还引入了空间调制交叉注意力机制(SMCA)和图像引导的查询初始化策略以提高检测精度。
Query Initialization(查询初始化)

LiDAR-Camera Fusion
如果一个物体只包含少量的激光雷达点时,那么只能获得相同数量的图像特征,浪费了高质量的图像语义信息。所以该论文保留所有的图像特征,使用Transformer中交叉注意机制和自适应的方式进行特征融合,使网络能够自适应地从图像中提取位置和信息。为了缓解LiDAR BEV特征和图像特征来自不同的传感器的空间不对齐问题,设计了一个空间调制交叉注意模块(SMCA),该模块通过围绕每个查询投影的二维中心的二维圆形高斯掩模对交叉注意进行加权。
Image-Guided Query Initialization(图像引导查询初始化)
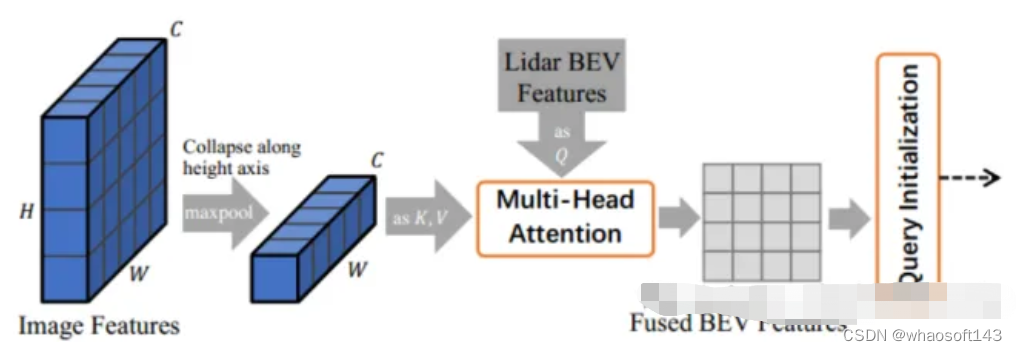
图2 图像引导查询模块

实验
数据集和指标
nuScenes数据集是一个用于3D检测和跟踪的大规模自动驾驶数据集,包含700、150和150个场景,分别用于训练、验证和测试。每帧包含一个激光雷达点云和六个覆盖360度水平视场的校准图像。对于3D检测,主要指标是平均平均精度(mAP)和nuScenes检测分数(NDS)。mAP是由BEV中心距离而不是3D IoU定义的,最终mAP是通过对10个类别的0.5m, 1m, 2m, 4m的距离阈值进行平均来计算的。NDS是mAP和其他属性度量的综合度量,包括平移、比例、方向、速度和其他方框属性。。
Waymo数据集包括798个用于训练的场景和202个用于验证的场景。官方的指标是mAP和mAPH (mAP按航向精度加权)。mAP和mAPH是基于3D IoU阈值定义的,车辆为0.7,行人和骑自行车者为0.5。这些指标被进一步分解为两个难度级别:LEVEL1用于超过5个激光雷达点的边界框,LEVEL2用于至少有一个激光雷达点的边界框。与nuScenes的360度摄像头不同,Waymo的摄像头只能覆盖水平方向的250度左右。
训练 在nuScenes数据集上,使用DLA34作为图像的2D骨干网络并冻结其权重,将图像大小设置为448×800;选择VoxelNet作为激光雷达的3D骨干网络。训练过程分成两个阶段:第一阶段仅以激光雷达数据作为输入,以第一层解码器和FFN前馈网络训练3D骨干20次,产生初始的3D边界框预测;第二阶段对LiDAR-Camera融合和图像引导查询初始化模块进行6次训练。左图是用于初始边界框预测的transformer解码器层架构;右图是用于LiDAR-Camera融合的transformer解码器层架构。
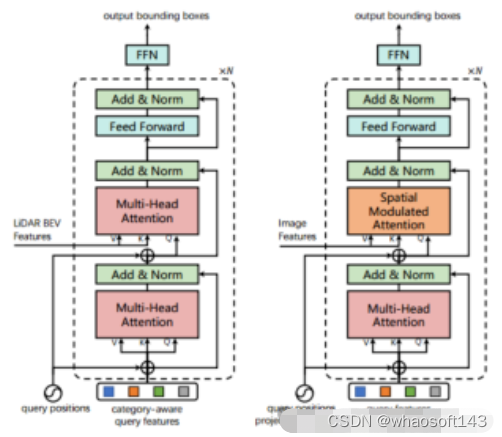
图3 解码器层设计
与最先进方法比较
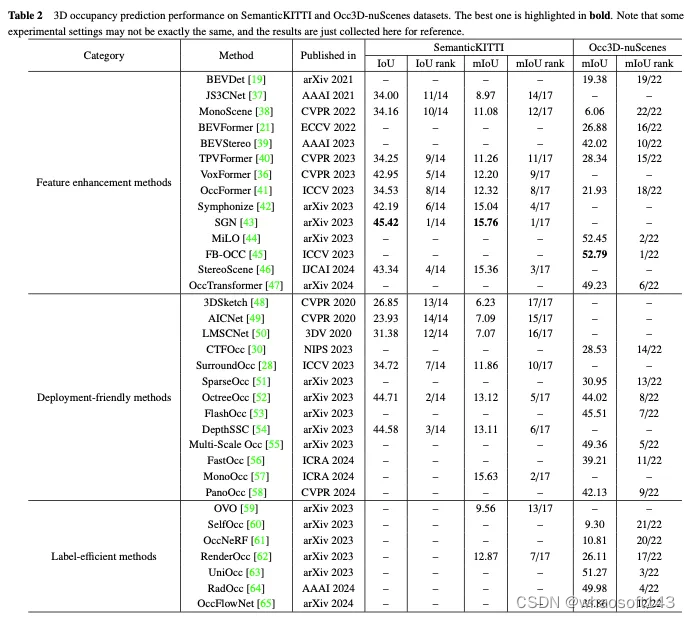
首先比较TransFusion和其他SOTA方法在3D目标检测任务的性能,如下表1所示的是在nuScenes测试集中的结果,可以看到该方法已经达到了当时的最佳性能(mAP为68.9%,NDS为71.7%)。而TransFusion-L是仅使用激光雷达进行检测的,其检测的性能明显优于先前的单模态检测方法,甚于超过了一些多模态的方法,这主要是由于新的关联机制和查询初始化策略。而在表2中则是展示了在Waymo验证集上LEVEL 2 mAPH的结果。
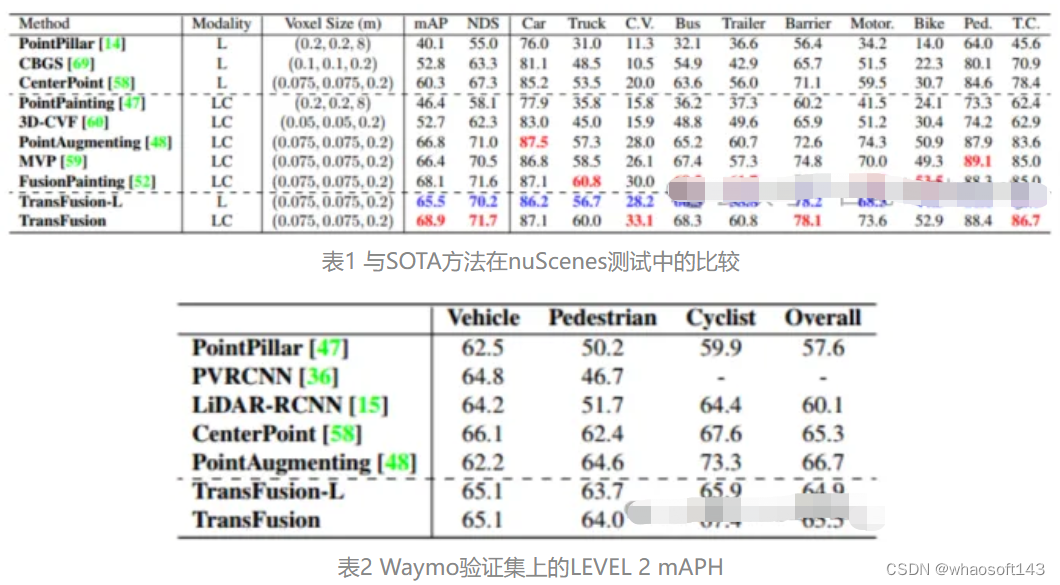
对恶劣图像条件的鲁棒性
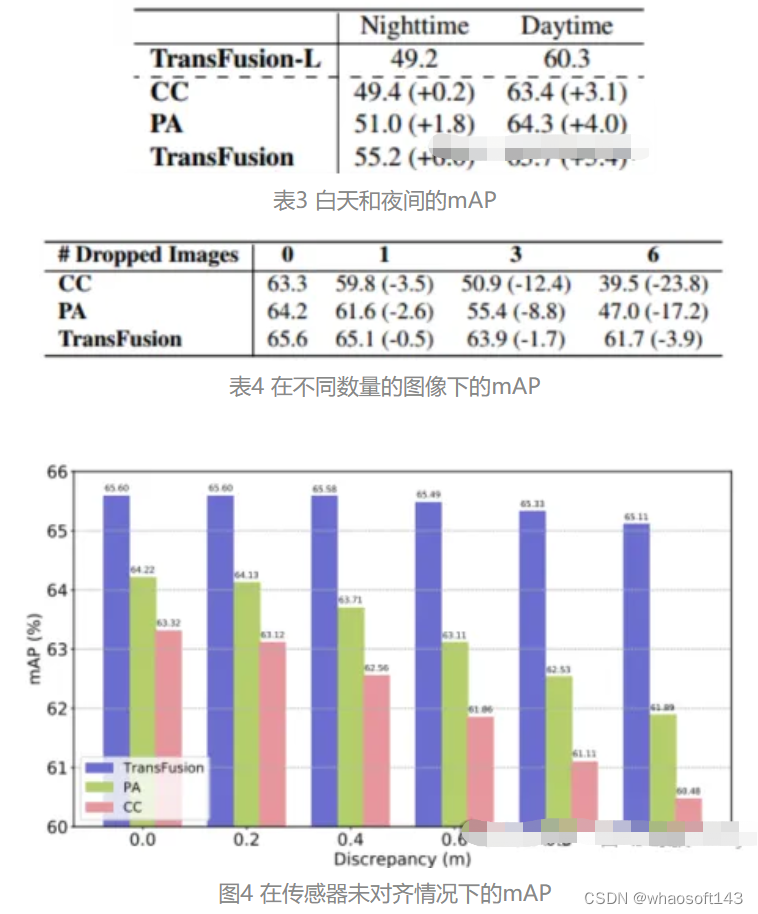
以TransFusion-L为基准,设计不同的融合框架来验证鲁棒性。其中三种融合框架分别是逐点拼接融合激光雷达和图像特征(CC)、点增强融合策略(PA)和TransFusion。如表3中显示,将nuScenes数据集划分成白天和黑夜,TransFusion的方法在夜间将会带来更大的性能提升。在推理过程中将图像的特征设置为零,以达到在每一帧随机丢弃若干图像的效果,那么在表4中可以看到,在推理过程中某些图像不可用时,检测的性能会显著下降,其中CC和PA的mAP分别下降23.8%和17.2%,而TransFusion仍保持在61.7%。传感器未校准的情况也会大大影响3D目标检测的性能,实验设置从相机到激光雷达的变换矩阵中随机添加平移偏移量,如图4所示,当两个传感器偏离1m时,TransFusion的mAP仅下降0.49%,而PA和CC的mAP分别下降2.33%和2.85%。
消融实验
由表5 d)-f)的结果可看出,在没有进行查询初始化的情况下,检测的性能下降很多,虽然增加训练轮数和解码器层数可以提高性能,但是仍旧达不到理想效果,这也从侧面证明了所提出来的初始化查询策略能够减小网络层数。而如表6所示,图像特征融合和图像引导查询初始化分别带来4.8%和1.6%的mAP增益。在表7中,通过在不同范围内精度的比较,TransFusion与仅激光雷达的检测相比,在难以检测的物体或者遥远区域的检测的性能都得到了提升。
结论
设计了一个有效且稳健的基于Transformer的激光雷达相机3D检测框架,该框架具有软关联机制,可以自适应地确定应该从图像中获取的位置和信息。TransFusion在nuScenes检测和跟踪排行榜上达到最新的最先进的结果,并在Waymo检测基准上显示了具有竞争力的结果。大量的消融实验证明了该方法对较差图像条件的鲁棒性。
DeepInteraction:
主要贡献:
主要解决的问题是现有的多模态融合策略忽略了特定于模态的有用信息,最终阻碍了模型的性能。点云在低分辨率下提供必要的定位和几何信息,图像在高分辨率下提供丰富的外观信息,因此跨模态的信息融合对于增强3D目标目标检测性能尤为重要。现有的融合模块如图1(a)所示,将两个模态的信息整合到一个统一的网络空间中,但是这样做会使得部分信息无法融合到统一的表示里,降低了一部分特定于模态的表示优势。为了克服上述限制,文章提出了一种新的模态交互模块(图1(b)),其关键思想是学习并维护两种特定于模态的表示,从而实现模态间的交互。主要贡献如下:
- 提出了一种新的多模态三维目标检测的模态交互策略,旨在解决以前模态融合策略在每个模态中丢失有用信息的基本限制;
- 设计了一个带有多模态特征交互编码器和多模态特征预测交互解码器的DeepInteraction架构。
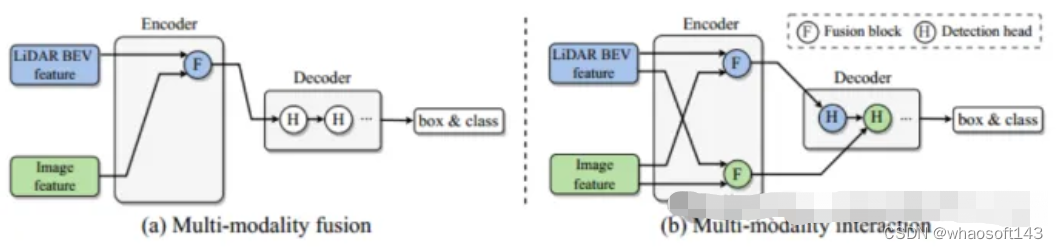
图1 不同的融合策略
模块详解
多模态表征交互编码器 将编码器定制为多输入多输出(MIMO)结构:将激光雷达和相机主干独立提取的两个模态特定场景信息作为输入,并生成两个增强后的特征信息。每一层编码器都包括:i)多模态特征交互(MMRI);ii)模态内特征学习;iii)表征集成。
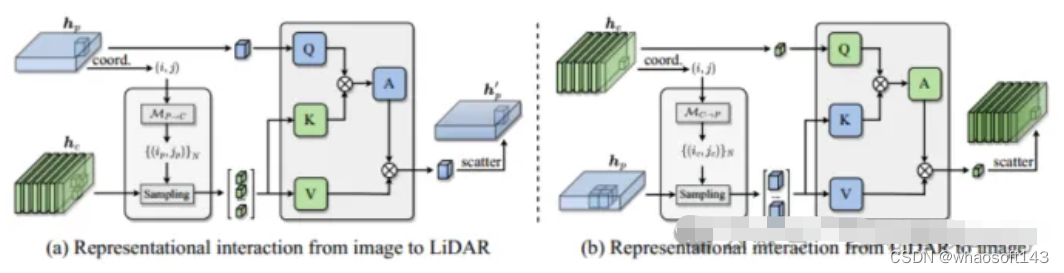
图2 多模态表征交互模块


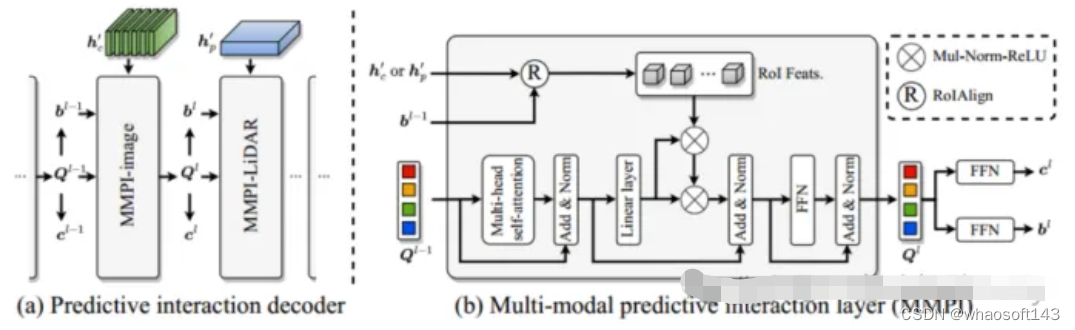
图3 多模态预测交互模块
实验
数据集和指标同TransFusion的nuScenes数据集部分。
实验细节 图像的主干网络是ResNet50,为了节省计算成本,在输入网络之前将输入图像重新调整为原始大小的1/2,并在训练时冻结图像分支的权重。体素大小设置为(0.075m,0.075m,0.2m),检测范围设为X轴和Y轴是[-54m,54m],Z轴是[-5m,3m],设计2层编码器层和5层级联的解码器层。另外还设置了两种在线提交测试模型:测试时间增加(TTA)和模型集成,将两个设置分别称为DeepInteraction-large和DeepInteraction-e。其中DeepInteraction-large使用Swin-Tiny作为图像骨干网络,并且将激光雷达骨干网络中卷积块的通道数量增加一倍,体素大小设置为[0.5m,0.5m,0.2m],使用双向翻转和旋转偏航角度[0°,±6.25°,±12.5°]以增加测试时间。DeepInteraction-e集成了多个DeepInteraction-large模型,输入的激光雷达BEV网格尺寸为[0.5m,0.5m]和[1.5m,1.5m]。
根据TransFusion的配置进行数据增强:使用范围为[-π/4,π/4]的随机旋转,随机缩放系数为[0.9,1.1],标准差为0.5的三轴随机平移和随机水平翻转,还在CBGS中使用类平衡重采样来平衡nuScenes的类分布。和TransFusion一样采用两阶段训练的方法,以TransFusion-L作为仅激光雷达训练的基线。使用单周期学习率策略的Adam优化器,最大学习率1×10−3,权衰减0.01,动量0.85 ~ 0.95,遵循CBGS。激光雷达基线训练为20轮,激光雷达图像融合为6轮,批量大小为16个,使用8个NVIDIA V100 GPU进行训练。
与最先进方法比较
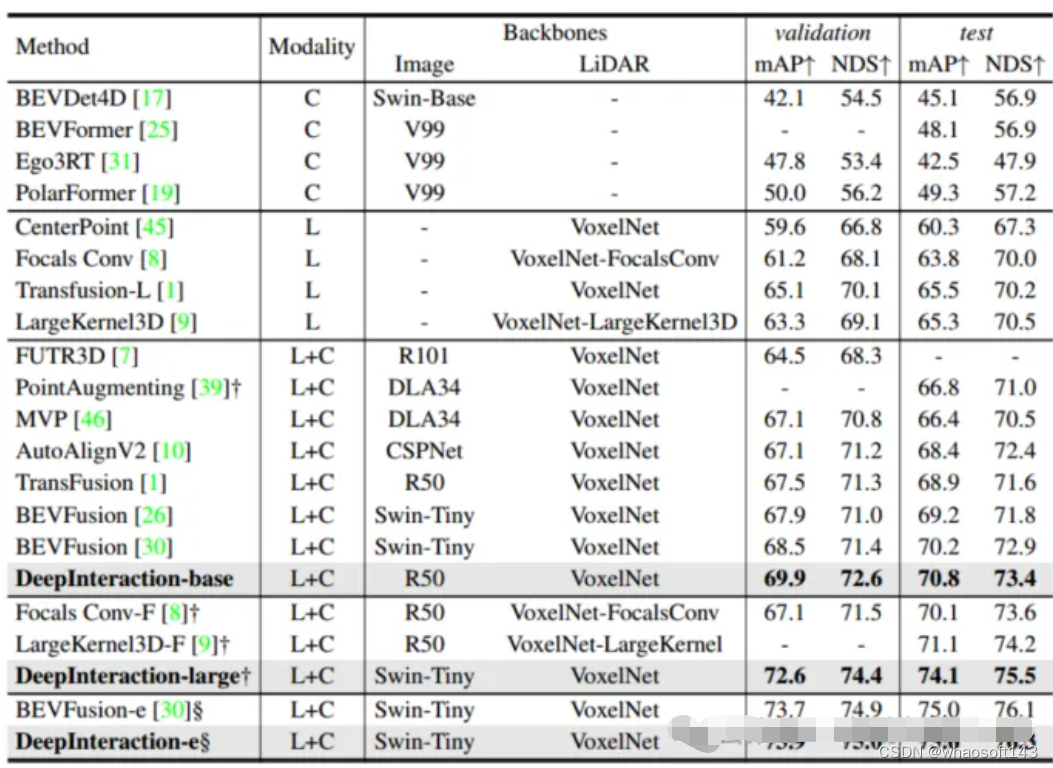
表1 在nuScenes测试集上与最先进方法的比较
如表1所示,DeepInteraction在所有设置下都实现了最先进的性能。而在表2中分别比较了在NVIDIA V100、A6000和A100上测试的推理速度。可以看到,在取得高性能的前提下,仍旧保持着较高的推理速度,验证了该方法在检测性能和推理速度之间实现了优越权衡。

表2 推理速度比较
消融实验
解码器的消融实验
在表3(a)中比较了多模态交互预测解码器和DETR解码器层的设计,并且使用了混合设计:使用普通的DETR解码器层来聚合激光雷达表示中的特征,使用多模态交互预测解码器(MMPI)来聚合图像表示中的特征(第二行)。MMPI明显优于DETR,提高了1.3% mAP和1.0% NDS,具有设计上的组合灵活性。表3(c)进一步探究了不同的解码器层数对于检测性能的影响,可以发现增加到5层解码器时性能是不断提升的。最后还比较了训练和测试时采用的查询数的不同组合,在不同的选择下,性能上稳定的,但以200/300作为训练/测试的最佳设置。
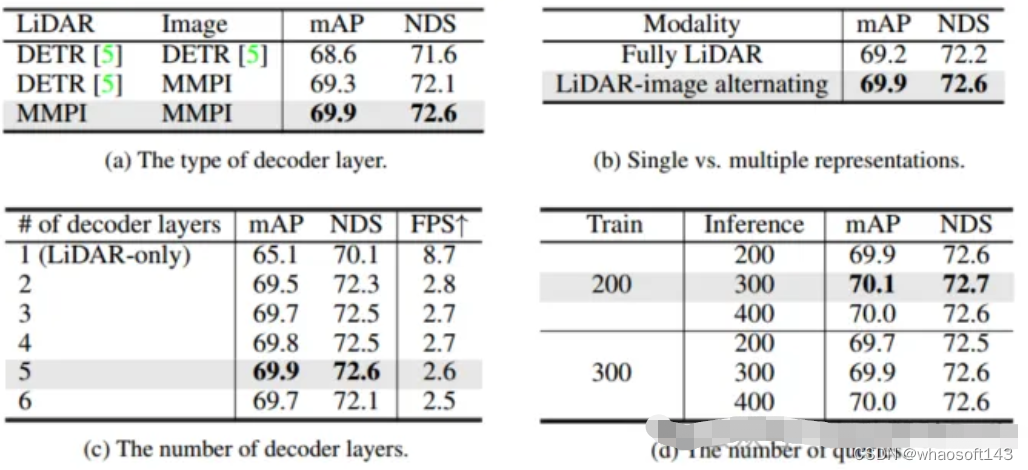
表3 解码器的消融实验
编码器的消融实验
从表4(a)中可以观察到:(1)与IML相比,多模态表征交互编码器(MMRI)可以显著提高性能;(2) MMRI和IML可以很好地协同工作以进一步提高性能。从表4(b)中可以看出,堆叠编码器层用于迭代MMRI是有益的。
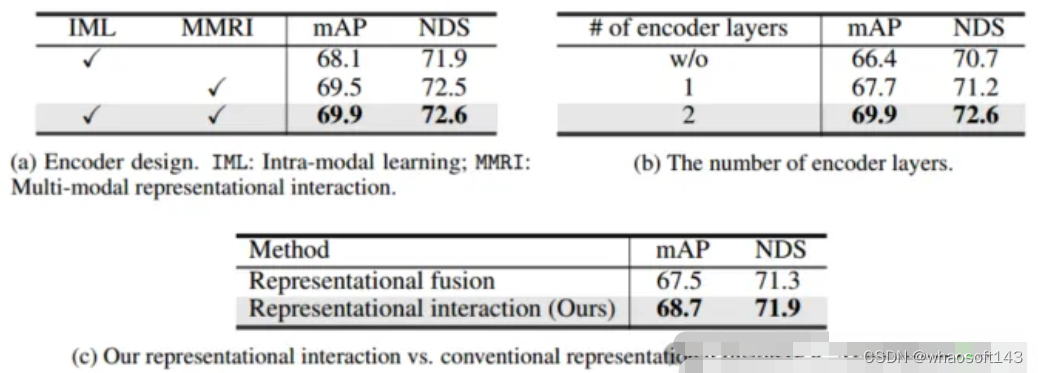
表4 编码器的消融实验
激光雷达骨干网络的消融实验
使用两种不同的激光雷达骨干网络:PointPillar和VoxelNet来检查框架的一般性。对于PointPillars,将体素大小设置为(0.2m, 0.2m),同时保持与DeepInteraction-base相同的其余设置。由于提出的多模态交互策略,DeepInteraction在使用任何一种骨干网时都比仅使用lidar基线表现出一致的改进(基于体素的骨干网提高5.5% mAP,基于支柱的骨干网提高4.4% mAP)。这体现了DeepInteraction在不同点云编码器中的通用性。
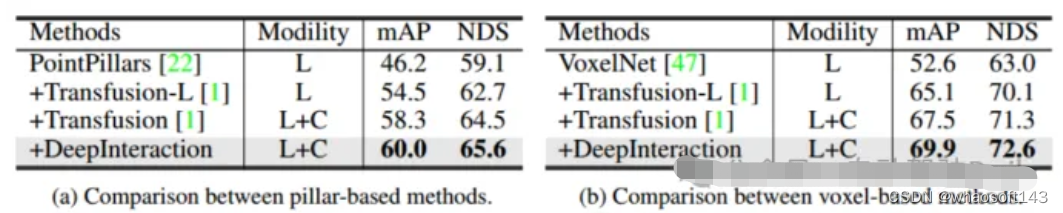
表5不同激光雷达主干网的评估
结论
在这项工作中,提出了一种新的3D目标检测方法DeepInteraction,用于探索固有的多模态互补性质。这一关键思想是维持两种特定于模态的表征,并在它们之间建立表征学习和预测解码的相互作用。该策略是专门为解决现有单侧融合方法的基本限制而设计的,即由于其辅助源角色处理,图像表示未得到充分利用。
两篇论文的总结:
以上的两篇论文均是基于激光雷达和相机融合的三维目标检测,从DeepInteraction中也可以看到它是借鉴了TransFusion的进一步工作。从这两篇论文中可以总结出多传感器融合的一个方向,就是探究更高效的动态融合方式,以关注到更多不同模态的有效信息。当然了,这一切建立在两种模态均有着高质量的信息。多模态融合在未来的自动驾驶、智能机器人等领域都会有很重要的应用,随着不同模态提取的信息逐渐丰富起来,我们能够利用到的信息将会越来越多,那么如何将这些数据更高效的运用起来也是一个值得思考的问题。
# 如何像人一样理解交通场景?大步迈向智慧交通
笔者是做规划的,所以下面思考是从规划角度出发。目前learning-based方法,尤其是end2end特别流行。这种直接从传感器数据到trajectory或最终的控制信号的方式,相较于传统模块化方法能够一定程度上减少人工调试成本,且直接将最终的规控作为优化目标,减少了算力浪费。
在end2end方法的众多网络结构中,基本遵循范式:传感器数据->特征提取->场景编码->规划结果输出。往往交通场景中存在大量的动静态障碍物,静态障碍物还好说,动态障碍物的行为则存在大量不确定性,极大程度影响最后的规划结果。所以,上述范式中的场景编码尤为重要,如果能很好地捕捉各个动静态交通要素之间的时空耦合关系,则自然而然利于最后规划结果的输出,反之亦然。
目前的一些方法,大多数直接提取动静态交通场景要素如人、车、车道线和道路边界等特征,然后使用Transformer隐式进行时空建模。这种让模型自己去学习交通要素复杂耦合关系的思路确实比较直观,但可能会存在泛化能力不足的问题。今天分享的这篇文章,针对上述问题,提出了一种比较新颖的解决思路,事先根据人类先验知识建立场景关系图,然后再通过数据驱动,学习图中各个要素的注意力权重,这种显示构建交通要素时空耦合关系图的方式能在一定程度上给我们带来一些启发。
文章主要贡献
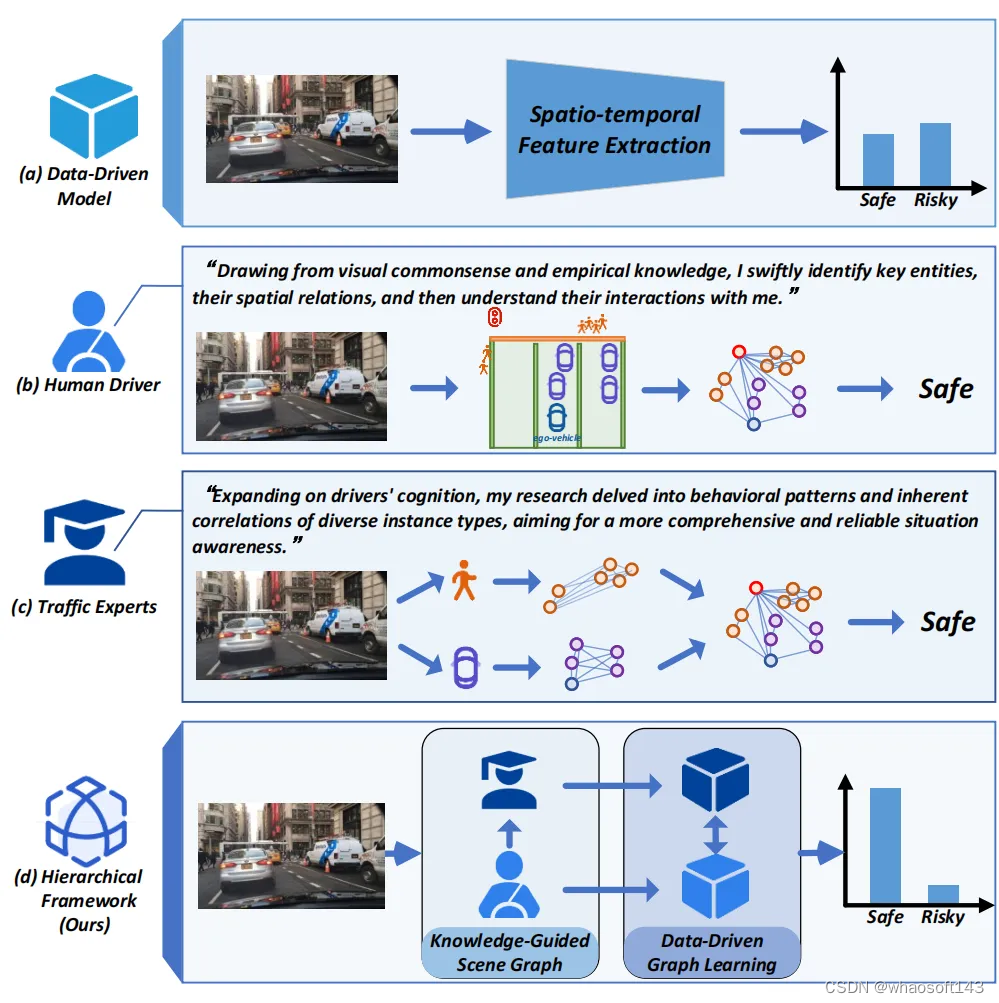
Fig.1. 以风险评估任务为例。(a)数据驱动模型通过CNN、Transformer等通用结构提取抽象时空特征。(b)人类驾驶员可以快速识别关键实例和空间关系,并根据他们的常识进一步理解交互关系。(c)在驾驶员认知的基础上,交通专家对驾驶场景的理解更加细粒度和全面,研究各类交通实例的行为模式和内在关联。(d)HKTSG共同利用人类驾驶员和交通专家的知识,在分层框架内指导数据驱动的学习过程,以实现更全面、更可靠的态势感知。whaoの开发板商城aiot物联网设备
- 受人类认知启发,作者提出了一个分层知识引导的交通场景图表示学习框架,用于智能车辆。该框架充分利用了通用领域知识和特定领域知识来引导动态交通场景的整个认知过程。
- 构建了针对行人和车辆的特定图,引导学习过程捕捉每种交通实例类型的运动模式和内在关联。
- 将全局环境的视觉特征整合到局部实例级场景图中,实现了对行人、车辆、道路、环境动态的全面而鲁棒的理解。
- 在两个典型的驾驶场景理解任务上实现了该框架,并进行了大量的实验来验证其有效性。实验结果证明该方法在多个数据集:IESG, Non-IESG, 571-Honda, 和1043-Carla上实现了SOTA表现。
详解HKTSG
问题定义
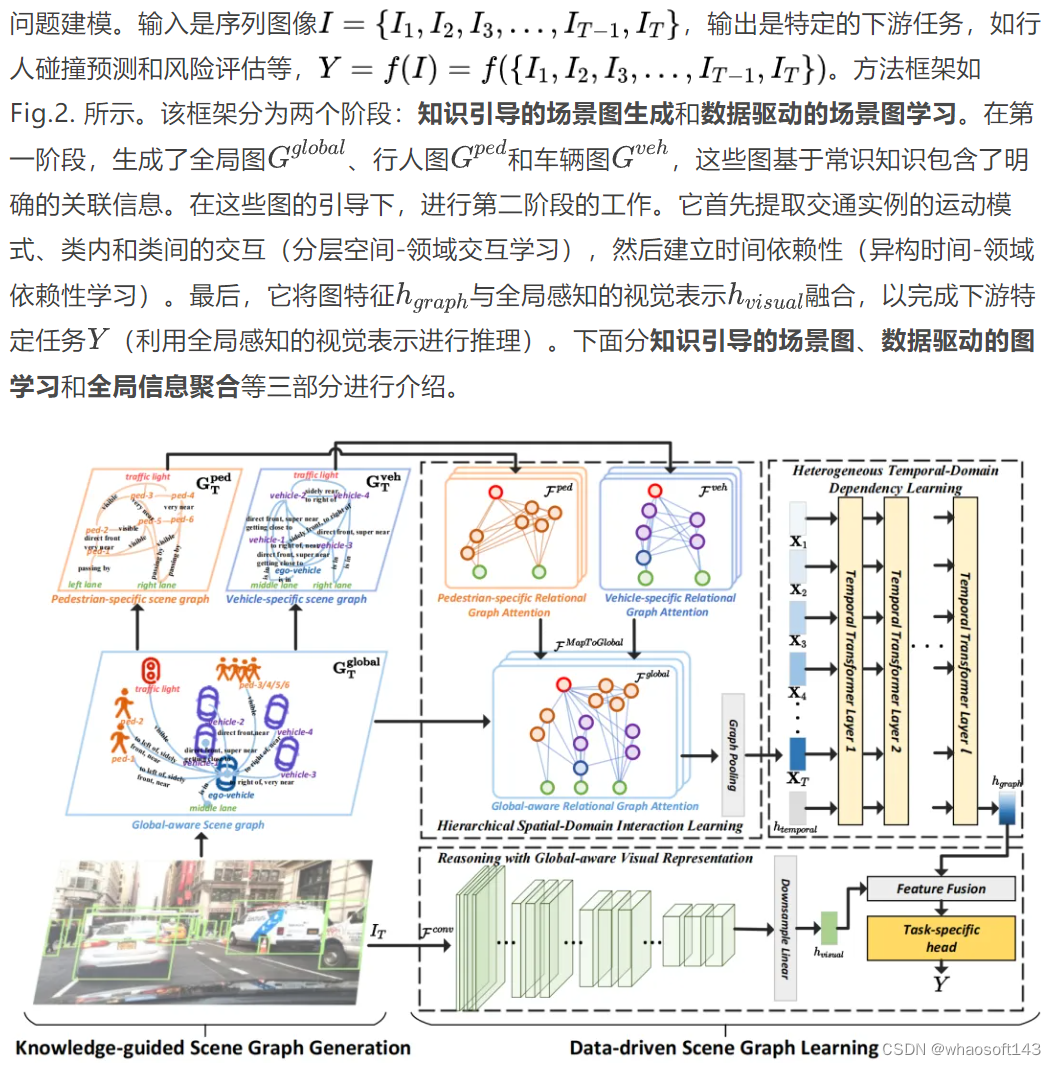
Fig.2. HKTSG框架。HKTSG包括两个阶段:知识引导的场景图生成和数据驱动的场景图学习。在第一阶段,全局图、行人图和车辆图是通过人类驾驶员和交通专家的知识引导生成的。在第二阶段,HKTSG通过分层空间-领域交互学习、时域交互学习和全局感知的视觉表示进行推理。
知识引导的场景图

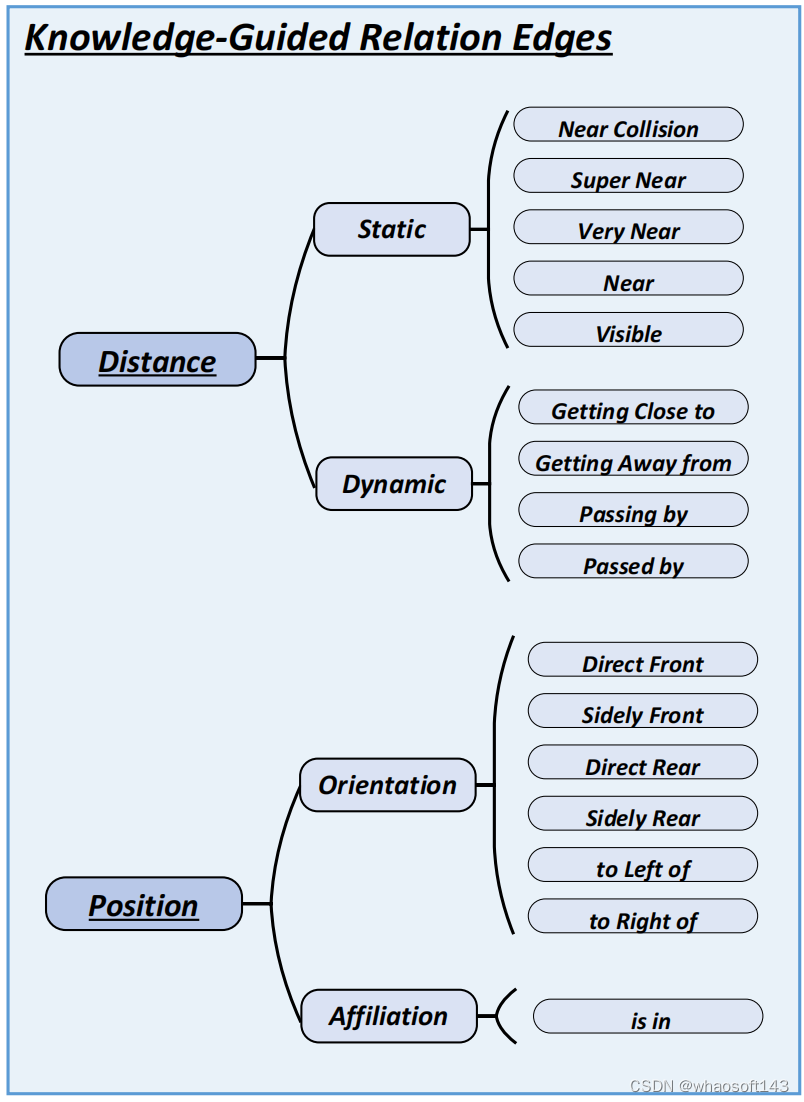
Fig.3. 实例之间的关系
关系分为两大类:距离(Distance)和位置(Position),距离又包含静态(Static)和动态(Dynamic),位置又包含方向(Orientation)和归属关系(Affiliation)。
静态距离直接由实例之间的BEV坐标计算得到,有very near、near和visable等,动态距离则是根据相邻帧的实例间距离变化计算,有getting close to、getting away from和passing by等。方向关系根据实例之间的航向角计算,有direct front、sidely front和direct rear等。归属关系根据实例与车道的位置关系计算,有is in。Fig.4. 展示了(a)和(b)两种典型场景下建立的场景图。(上述建立关系图的方式适用于全局、车辆和行人场景图。)
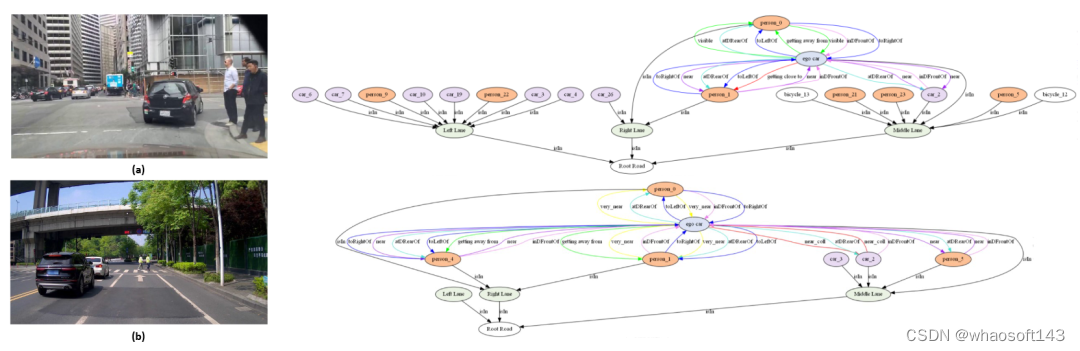
Fig.4. 场景图展示
数据驱动的场景图学习
经过上述知识引导的场景图,一个实例间基本框架已经构建完成,接下来需要在这个框架基础上学习实例间动态的时空交互关系 。这里采用数据驱动的方法,具体地分为分层的空域交互学习和时域依赖学习,对应Fig.2. 的右半部分。
分层的空域交互学习


时域交互学习

实验
作者在两种任务的场景理解上评估模型:行人碰撞预测(pedestrian collision prediction)和主观风险评估(subjective risk assessment)。前者预测自车与行人发生潜在碰撞的场景,后者则定性评估了交通场景中的潜在风险。这两种任务都有助于自动驾驶系统规避风险,提高驾驶的安全性和有效性。
定量结果
数据集。作者在 IESG、Non-IESG、571-Honda和1043-Carla数据集上进行了实验。指标。精度(accuracy ,Acc),曲线下面积( area under the curve,AUC)和F1分数(F1 score,F1)。
对比实验
对比的Baseline有CNN-LSTM、MRGCN-Mean、MRGCN-LSTM-last、MRGCN+LSTM-attn、MRGIN和PCRA。如Table I和Table II所示,我们在IESG和Non-IESG数据集上进行了行人碰撞预测任务的测试,在571-honda-sg1043-carla-sg数据集上进行了主观风险评估测试。可以看到,HKTSG在两种任务上均达到SOTA水平。

Table I. 在数据集IESG和Non-IESG上的结果

Table II. 在数据集571-Honda和571-Honda上的结果
消融实验
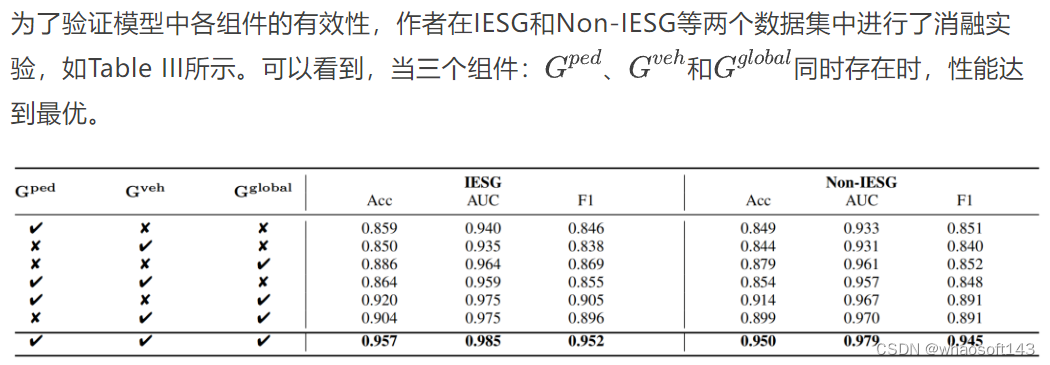
Table III. 分层场景图(HIERARCHICAL SCENE GRAPH DESIGN)的消融
可视化
可视化结果如Fig.5. 所示,在两种场景下的结果,场景图中每个节点具有不同的注意力权重。
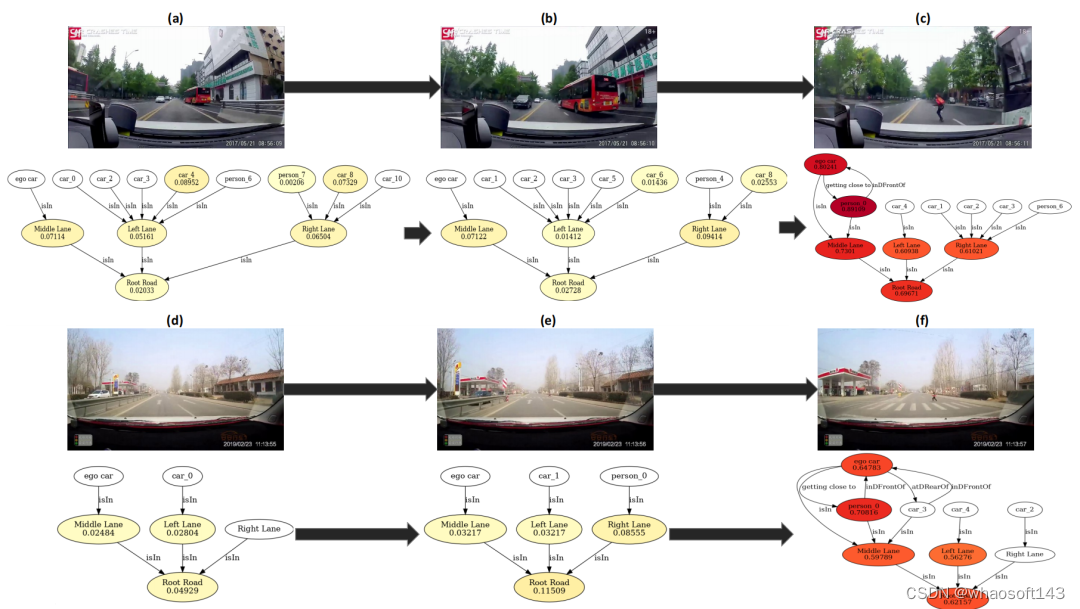
ig.5. 以两种行人安全关键场景为例的节点注意权可视化。颜色较深的节点表示它们在风险评估中更重要
# 自动驾驶系统:全景概览
从Gartner官方的最新技术成熟度曲线可以看出,自动驾驶目前处在技术发展的中后段,正逐渐走向普及应用的成熟期。
自动驾驶,已经成为汽车的一个重要的功能属性,或许不久的将来,人们的生活将离不开自动驾驶功能。
因此,为了和大家一起更全面深入的学习和理解自动驾驶系统,“雪岭飞花”计划编写一个系列文章,一共十篇,涵盖自动驾驶系统架构,感知系统,控制系统,执行系统,支持系统,开发体系,以及目前主要主机厂和科技公司的自动驾驶产品方案,以及系统特点。
00 编写方案
自动驾驶系统产业链长,系统复杂,相关的论文浩如烟海。因此,即便是分为十篇文章,每篇万字以上,也很难讲的很深。“雪岭飞花”结合多年一线的工作经验,以及业内多位资深专家的支持,尽量把每个方面最精华的内容提炼出来,尝试用最通俗易懂的方式做一些介绍。
该系列文章是希望描述自动驾驶的全景图,主要追求“广”,而不是“深”。同时,在“广”的基础上,尽量覆盖各技术点的关键点。而对于每个具体技术点的深入描述,在后续的其他文章系列中再做展开。
因此本系列文章,对于下面情况可能会带来帮助:
- 初出校门的大学生或者希望转行到自动驾驶的职场人:将本系列文章作为可选就业方向的索引,结合自己专业和优势,选择适合的从业方向。
- 投资经理:了解目标公司所在赛道的竞争态势和优势对比,以及所在行业的上下游,协助分析投资价值。
- 相关行业产品经理:了解本公司产品在市场上的定位和竞争优势,对于定义或者调整产品策略做参考。
- 其他对于自动驾驶感兴趣的行业内外专家:了解自动驾驶全景图,熟悉自动驾驶行业的体系结构和发展现状,协助洞察可能的合作机会。
对于下面情况,可能没有太大帮助:
- 细分领域的研发工程师:如果想了解某个具体技术点的深入专业分析,本系列文件无法提供太多帮助。建议直接阅读相关论文,或者可以留言或者私信,在雪岭飞花专家微信群中交流,协助对接对应领域的专家。
- 没有自动驾驶背景的一般汽车消费者。文章会有一定的专业深度,有些内容需要一定的专业背景可能才能理解。如果仅仅是希望买一辆具备自动驾驶功能的汽车,可以直接在体验店进行实车的功能体验,体验店的用户主理会有更适合的自动驾驶功能介绍。
定义:
- 自动驾驶的概念:文中提到的“自动驾驶”,涵盖L0到L5的驾驶辅助、高级驾驶辅助、智能驾驶、自动驾驶、无人驾驶。在一定语境情况下,“自动驾驶”上述其他几个名词含义相通,除非必要,否则文中不做特别区分。
- 自动驾驶的搭载对象:系列文章所描述的自动驾驶系统主要是应用在普通消费者的乘用车上,并非是面向矿区、园区或者港口无人车等。不过,由于其技术方案有一定的通用性,需要的话,读者可以做一些选择性的参考。
初步规划的十篇文章,主要提纲如下。
01 第一篇:自动驾驶:系统架构
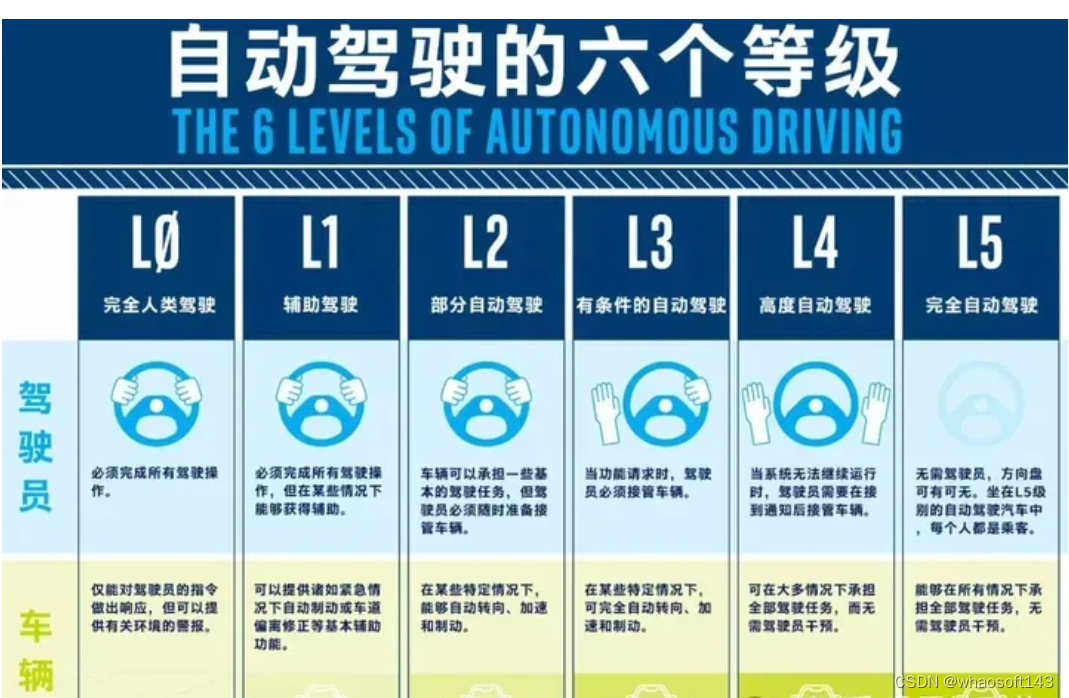
第一部分:描述自动驾驶的基本概念、分级、应用场景以及常见自动驾驶功能的介绍,例如ACC,AEB,LKA,ICC,NOA等。
第二部分:云管端架构方案,不同级别自动驾驶功能的系统架构,尤其重点介绍L3级自动驾驶系统方案,包括冗余系统设计、功能安全策略等。
第三部分:智能汽车电子电器架构的演进路线,舱驾融合的技术方案,以及工程化挑战。
02 第二篇:自动驾驶:感知系统
主要介绍自动驾驶的感知系统(传感器),感知是自动驾驶系统的眼睛,其性能会决定整个自动驾驶系统性能的上限。
第一部分:车外目标感知单元,包括摄像头、毫米波雷达、激光雷达、超声波雷达等。
毫米波雷达和激光雷达在之前的文章中介绍的较多,本篇会将之前的内容做汇总和提炼,同时站在整个感知系统的角度,补充新的交叉内容。
第二部分:高精地图(“先验”感知)、定位和惯导系统(自车感知)的应用现状和目前发展趋势。
第三部分:讨论自动驾驶的感知系统发展趋势,“纯视觉路线”是终极解决方案吗?“激光雷达路线”和“高精地图”真的能“去”吗?
03 第三篇:自动驾驶:控制系统硬件
介绍自动驾驶系统的“大脑”:域控制器。域控制器是整个自动驾驶系统的核心,也是最为复杂的部分,因此分硬件和软件两篇介绍。
第一部分:介绍域控制器的硬件架构,域集中和舱驾融合需求下的硬件方案。
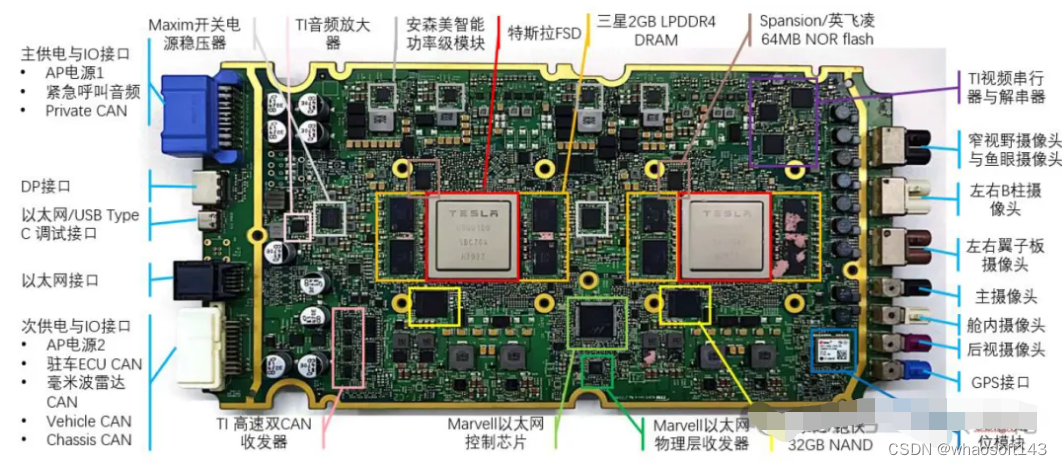
第二部分:域控制器主控SoC芯片的主要玩家、Roadmap和技术特点。包括英伟达(Orin、Thor),高通(8650、8775、8797),地平线(J3、J5、J6),Mobileye(EQ5、EQ6),华为(MDC510、610、810),黑芝麻(A1000L,A1000Pro),芯驰科技等。
第三部分:电源管理、MCU、SerDes、Switch等关键器件介绍。
04 第四篇:自动驾驶:控制系统软件
控制系统软件是自动驾驶系统的“灵魂”。
第一部分:软件架构、操作系统和中间件解决方案。
第二部分:感知软件,包括BEV、Transformer、Occupancy Network等最新发展现状。
第三部分:规控软件,常见的规划算法和控制算法介绍。端到端大模型的应用介绍。
05 第五篇:自动驾驶:执行系统
第一部分:驱动系统架构方案,混合动力/纯电系统的分类,优劣势以及应用现状。汽车增程器和驱动电机特点、发展现状和主要玩家。
第二部分:动力电池发展现状和主要玩家,全固态电池原理和发展趋势。
第三部分:线控制动、线控转向、主动悬架产品特点和技术发展现状。
06 第六篇:自动驾驶:支持系统
第一部分:云端设计架构,OTA方案,无线通信,DSSAD数据记录系统等。
第二部分:域内关键技术,包括电子配电、时间同步、时间敏感网络、LVDS、车载以太网技术方案和发展。
第三部分:自动驾驶中的诊断技术,汽车功能安全、预期功能安全和信息安全,安全刷写和安全启动技术方案。
07 第七篇:自动驾驶:开发体系
第一部分:整车开发流程,自动驾驶系统的开发流程介绍。汽车智能化对于开发体系带来的挑战,瀑布还是敏捷?
第二部分:自动驾驶系统中的数据闭环系统。
第三部分:自动驾驶真值系统的构建方法,硬件在软、软件在环、控制器在环等测试方法,自动驾驶智驾性能评价体系。
08 第八篇:自动驾驶:主要玩家(传统主机厂)
主要介绍下面玩家的自动驾驶方案:
一汽、东风(岚图)、长安(深蓝、阿维塔),上汽(乘用车、智己、五菱、华域)、北汽(极狐、享界)、广汽(埃安、昊铂)、比亚迪(腾势、仰望)、吉利(极氪、极越、亿咖通、吉咖智能、福瑞泰克)、长城(毫末)、奇瑞(大卓智能)、赛力斯(问界)、江淮(X6平台)等;
以及,奔驰、宝马、大众/奥迪、丰田、本田等;
09 第九篇:自动驾驶:主要玩家(新势力主机厂)
主要介绍下面玩家的自动驾驶方案:特斯拉(FSD)、蔚来(NOP)、小鹏(XNGP)、理想(AD Max)、零跑、哪吒、小米等。
10 第十篇:自动驾驶:主要玩家(方案供应商)
主要介绍下面玩家的自动驾驶方案:华为(ADS)、Momenta(Mpolit、MSD)、卓驭科技(成行)、百度 Appolo、知行科技(iDC)、宏景智驾、轻舟智航(轻舟乘风)、元戎启行(DeepRoute-Driver)、Pony(小马识途)、商汤绝影、畅行智驾、德赛西威、均联智行、易航智能、纽劢科技(MaxDrive)、魔视智能(MagicPilot)、旷视科技等。
# 汇总特征增强/量产部署/高效标注三大主题
近年来,自动驾驶因其在减轻驾驶员负担和提高驾驶安全方面的潜力而越来越受到关注。基于视觉的三维占用预测是一种新兴的感知任务,适用于具有成本效益的自动驾驶感知系统,它可以根据图像输入预测自动驾驶汽车周围三维体素网格的空间占用状态和语义。尽管许多研究已经证明,与以物体为中心的感知任务相比,3D占用预测具有更大的优势,但仍缺乏专门针对这一快速发展的领域的综述。本文首先介绍了基于视觉的三维占用预测的背景,并讨论了这项任务中的挑战。其次,我们从特征增强、部署友好性和标签效率三个方面全面调查了基于视觉的3D占用预测的进展,并深入分析了每类方法的潜力和挑战。最后总结了当前的研究趋势,并提出了一些鼓舞人心的未来展望。
开源链接:https://github.com/zya3d/Awesome-3D-Occupancy-Prediction
总结来说,本文的主要贡献如下:
- 据我们所知,这篇论文是第一篇针对基于视觉的自动驾驶3D占用预测方法的全面综述。
- 本文从特征增强、计算友好和标签高效三个角度对基于视觉的三维占用预测方法进行了结构总结,并对不同类别的方法进行了深入分析和比较。
- 本文提出了基于视觉的3D占用预测的一些鼓舞人心的未来展望,并提供了一个定期更新的github存储库来收集相关论文、数据集和代码。
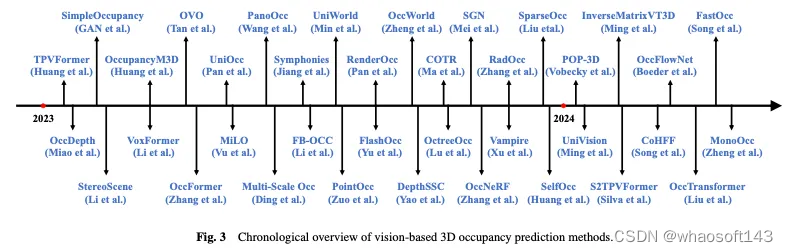
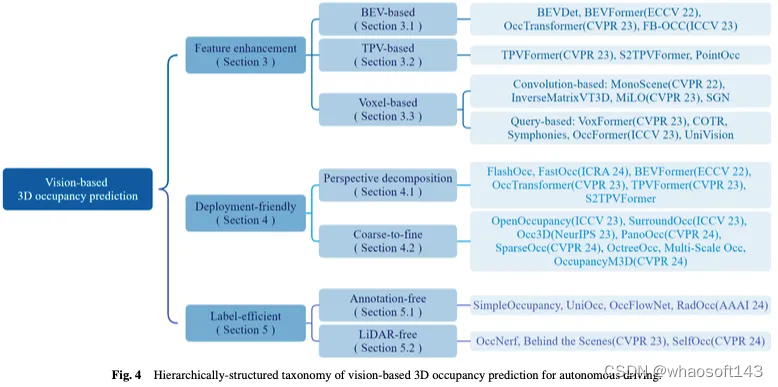
图3显示了基于视觉的3D占用预测方法的时序概述,图4显示了相应的分层结构分类法。
相关背景
真值生成
生成GT标签是3D占用预测的一个挑战。尽管许多3D感知数据集,如nuScenes和Waymo,提供了激光雷达点分割标签,但这些标签是稀疏的,难以监督密集的3D占用预测任务。Wei等人已经证明了使用密集占用作为GT的重要性。最近的一些研究集中在使用稀疏激光雷达点分割注释生成密集的3D占用注释,为3D占用预测任务提供一些有用的数据集和基准。
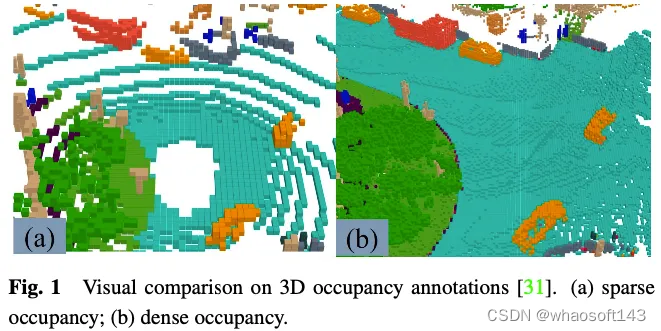
3D占用预测任务中的GT标签表示3D空间中的每个体素是否被占用以及被占用体素的语义标签。由于三维空间中有大量的体素,因此很难手动标记每个体素。一种常见的做法是对现有的3D点云分割任务的地面实况进行体素化,然后根据体素中点的语义标签通过投票生成3D占用预测的GT。然而,通过这种方式生成的地面实况是稀疏的。如图1所示,在道路等未标记为已占用的地方,仍有许多已占用的体素。监督具有这种稀疏地面实况的模型将导致模型性能下降。因此,一些工作研究如何自动或半自动生成高质量的密集3D占用注释。
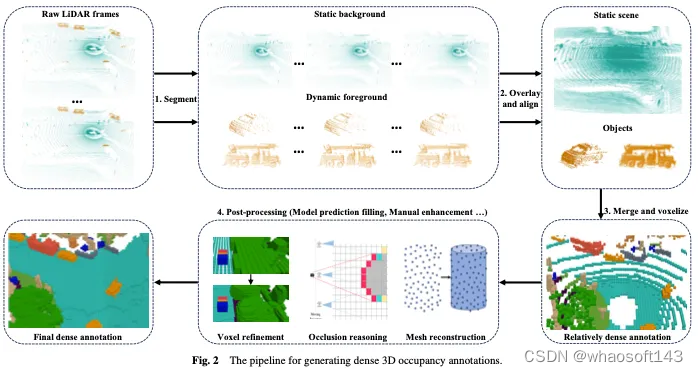
如图2所示,生成密集的三维占用注释通常包括以下四个步骤:
- 取连续的原始激光雷达帧,将激光雷达点分割为静态背景和动态前景。
- 在静态背景上叠加连续的激光雷达帧,并基于定位信息进行运动补偿,以对齐多帧点云,从而获得更密集的点云。在动态前景上叠加连续的激光雷达帧,根据目标帧和目标id对齐动态前景的点云,使其更加密集。注意,尽管点云相对密集,但体素化后仍有一些间隙,需要进一步处理。
- 合并前景和背景点云,然后对它们进行体素化,并使用投票机制来确定体素的语义,从而产生相对密集的体素注释。
- 通过后处理对上一步中获得的体素进行细化,以实现更密集、更精细的注释,作为GT。
数据集
在本小节中,我们介绍了一些常用于3D占用预测的开源、大规模数据集,表1中给出了它们之间的比较。
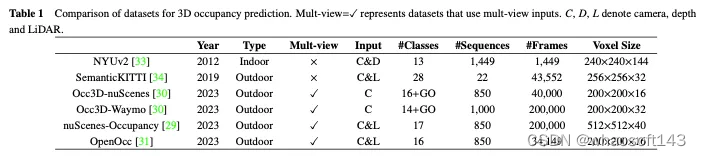
NUYv2数据集由来自各种室内场景的视频序列组成,由Microsoft Kinect的RGB和Depth相机拍摄。它包含1449对密集标记的对齐RGB和深度图像,以及来自3个城市的407024个未标记帧。虽然主要用于室内使用,不适合自动驾驶场景,但一些研究已将该数据集用于3D占用预测。
SemanticKITTI是一个广泛用于3D占用预测的数据集,包括来自KITTI数据集的22个序列和43000多个帧。它通过覆盖未来的帧、分割体素和通过点投票分配标签来创建密集的3D占用注释。此外,它通过追踪光线来检查汽车的每个位姿,传感器可以看到哪些体素,并在训练和评估过程中忽略不可见的体素。然而,由于它是基于KITTI数据集的,因此它只使用来自前置摄像头的图像作为输入,而后续数据集通常使用多视图图像。如表2所示,我们在SemanticKITTI数据集上收集了现有方法的评估结果。
NuScenes占用率是基于户外环境的大规模自动驾驶数据集NuScenes构建的3D占用率预测数据集。它包含850个序列、200000个帧和17个语义类别。数据集最初使用增强和净化(AAP)管道生成粗略的3D占用标签,然后通过手动增强来细化标签。此外,它还引入了OpenOccupancy,这是周围语义占用感知的第一个基准,以评估先进的3D占用预测方法。
随后,Tian等人在nuScenes和Waymo自动驾驶数据集的基础上,进一步构建了用于3D占用预测的Occ3D nuScene斯和Occ3D Waymo数据集。他们引入了一种半自动标签生成管道,该管道利用现有的标记3D感知数据集,并根据其可见性识别体素类型。此外,他们还建立了大规模3D占用预测的Occ3d基准,以加强不同方法的评估和比较。如表2所示,我们在Occ3D nuScenes数据集上收集了现有方法的评估结果。
此外,与Occ3D裸体和裸体占用类似,OpenOcc也是一个基于裸体数据集为3D占用预测构建的数据集。它包含850个序列、34149个帧和16个类。请注意,该数据集提供了八个前景目标的额外注释,这有助于下游任务,如运动规划。
关键挑战
尽管近年来基于视觉的三维占用预测取得了重大进展,但它仍然面临着来自特征表示、实际应用和注释成本的限制。对于这项任务,有三个关键挑战:(1)从2D视觉输入中获得完美的3D特征是困难的。基于视觉的3D占有率预测的目标是仅从图像输入实现对3D场景的详细感知和理解,然而图像中固有的深度和几何信息的缺失对直接从中学习3D特征表示提出了重大挑战。(2)三维空间中繁重的计算负载。3D占用预测通常需要使用3D体素特征来表示环境空间,这不可避免地涉及用于特征提取的3D卷积等操作,这大大增加了计算和内存开销,并阻碍了实际部署。(3)昂贵的细粒度注释。3D占用预测涉及预测高分辨率体素的占用状态和语义类别,但实现这一点通常需要对每个体素进行细粒度的语义注释,这既耗时又昂贵,给这项任务带来了瓶颈。
针对这些关键挑战,基于视觉的自动驾驶三维占用预测研究工作逐步形成了特征增强、部署友好和标签高效三条主线。特征增强方法通过优化网络的特征表示能力来缓解3D空间输出和2D空间输入之间的差异。部署友好的方法旨在通过设计简洁高效的网络架构,显著降低资源消耗,同时确保性能。即使在注释不足或完全不存在的情况下,高效标签方法也有望实现令人满意的性能。接下来,我们将围绕这三个分支全面概述当前的方法。
特征增强方法
基于视觉的3D占用预测的任务涉及从2D图像空间预测3D体素空间的占用状态和语义信息,这对从2D视觉输入获得完美的3D特征提出了关键挑战。为了解决这个问题,一些方法从特征增强的角度改进了占用预测,包括从鸟瞰图(BEV)、三视角图(TPV)和三维体素表示中学习。
BEV-based methods
一种有效的学习占用率的方法是基于鸟瞰图(BEV),它提供了对遮挡不敏感的特征,并包含一定的深度几何信息。通过学习强BEV表示,可以实现稳健的3D占用场景重建。首先使用2D骨干网络从视觉输入中提取图像特征,然后通过视点变换获得BEV特征,并最终基于BEV特征表示完成3D占用预测。基于BEV的方法如图5所示。
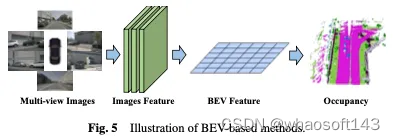
一种直接的方法是利用来自其他任务的BEV学习,例如在3D对象检测中使用BEVDet和BEVFormer等方法。为了扩展这些占用学习方法,可以在训练过程中加入或更换占用头,以获得最终结果。这种自适应允许将占用估计集成到现有的基于BEV的框架中,从而能够同时检测和重建场景中的3D占用。基于强大的基线BEVFormer,OccTransformer采用数据增强来增加训练数据的多样性,以提高模型泛化能力,并利用强大的图像主干从输入数据中提取更多信息特征。它还引入了3D Unet Head,以更好地捕捉场景的空间信息,并引入了额外的损失函数来改进模型优化。
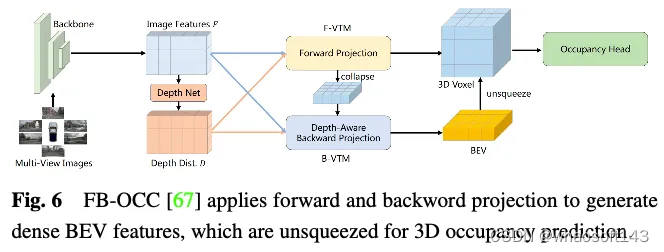
TPV-based methods
虽然与图像相比,基于BEV的表示具有某些优势,因为它们本质上提供了3D空间的自上而下的投影,但它们固有地缺乏仅使用单个平面来描述场景的细粒度3D结构的能力。基于三视角(TPV)的方法利用三个正交投影平面对3D环境进行建模,进一步增强了视觉特征对占用预测的表示能力。首先,使用2D骨干网络从视觉输入中提取图像特征。随后,将这些图像特征提升到三视图空间,最终基于三个投影视点的特征表示实现3D占用预测。基于BEV的方法如图7所示。
除了BEV功能外,TPVFormer还以相同的方式生成前视图和侧视图中的功能。每个平面从不同的视角对3D环境进行建模,并且它们的组合提供了对整个3D结构的全面描述。具体来说,为了获得三维空间中一个点的特征,我们首先将其投影到三个平面中的每一个平面上,并使用双线性插值来获得每个投影点的特征。然后,我们将三个投影特征总结为三维点的合成特征。因此,TPV表示可以以任意分辨率描述3D场景,并为3D空间中的不同点生成不同的特征。它进一步提出了一种基于变换器的编码器(TPVFormer),以有效地从2D图像中获得TPV特征,并在TPV网格查询和相应的2D图像特征之间执行图像交叉关注,从而将2D信息提升到3D空间。最后,TPV特征之间的交叉视图混合注意力实现了三个平面之间的交互。TPVFormer的总体架构如图8所示。
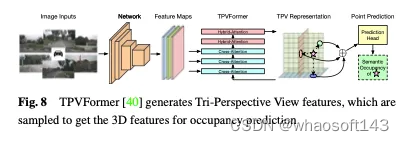
Voxel-based methods
除了将3D空间转换为投影透视(如BEV或TPV)之外,还存在直接对3D体素表示进行操作的方法。这些方法的一个关键优势是能够直接从原始3D空间学习,最大限度地减少信息损失。通过利用原始三维体素数据,这些方法可以有效地捕捉和利用完整的空间信息,从而更准确、更全面地了解占用情况。首先,使用2D骨干网络提取图像特征,然后,使用专门设计的基于卷积的机制来桥接2D和3D表示,或者使用基于查询的方法来直接获得3D表示。最后,基于所学习的3D表示,使用3D占用头来完成最终预测。基于体素的方法如图9所示。
Convolution-based methods
一种方法是利用专门设计的卷积架构来弥合从2D到3D的差距,并学习3D占用表示。这种方法的一个突出例子是采用U-Net架构作为特征桥接的载体。U-Net架构采用编码器-解码器结构,在上采样和下采样路径之间具有跳跃连接,保留低级别和高级别特征信息以减轻信息损失。通过不同深度的卷积层,U-Net结构可以提取不同尺度的特征,帮助模型捕捉图像中的局部细节和全局上下文信息,从而增强模型对复杂场景的理解,从而进行有效的占用预测。
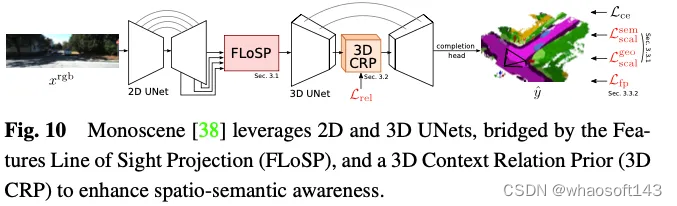
Monoscene利用U-net进行基于视觉的3D占用预测。它引入了一种称为二维特征视线投影(FLoSP)的机制,该机制利用特征透视投影将二维特征投影到三维空间上,并根据成像原理和相机参数计算二维特征上三维特征空间中每个点的坐标,以对三维特征空间的特征进行采样。这种方法将2D特征提升到统一的3D特征图中,并作为连接2D和3D U-net的关键组件。Monoscene还提出了一个插入在3D UNet瓶颈处的3D上下文关系先验(3D CRP)层,该层学习n向体素到体素的语义场景关系图。这为网络提供了一个全局感受场,并由于关系发现机制而提高了空间语义意识。Monoscene的总体架构如图10所示。
Query-based methods
从3D空间学习的另一种方式涉及生成一组查询以捕捉场景的表示。在该方法中,使用基于查询的技术来生成查询建议,然后将其用于学习3D场景的综合表示。随后,应用图像上的交叉注意和自注意机制来细化和增强所学习的表征。这种方法不仅增强了对场景的理解,而且能够在3D空间中进行准确的重建和占用预测。此外,基于查询的方法提供了更大的灵活性来基于不同的数据源和查询策略进行调整和优化,从而能够更好地捕获本地和全局上下文信息,从而促进3D占用预测表示。
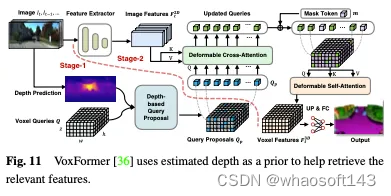
深度可以作为选择占用查询的有价值的先验,在Voxformer中,估计的深度被用作预测占用和选择相关查询的先验。只有占用的查询用于使用可变形注意力从图像中收集信息。更新后的查询提议和掩蔽的令牌然后被组合以重建体素特征。Voxformer从RGB图像中提取2D特征,然后利用一组稀疏的3D体素查询来索引这些2D特征,使用相机投影矩阵将3D位置链接到图像流。具体而言,体素查询是3D网格形状的可学习参数,旨在使用注意力机制将图像中的特征查询到3D体积中。整个框架是由类不可知的提议和特定于类的分段组成的两阶段级联。阶段1生成类不可知的查询建议,而阶段2采用类似于MAE的架构将信息传播到所有体素。最后,对体素特征进行上采样以进行语义分割。VoxFormer的总体架构如图11所示。
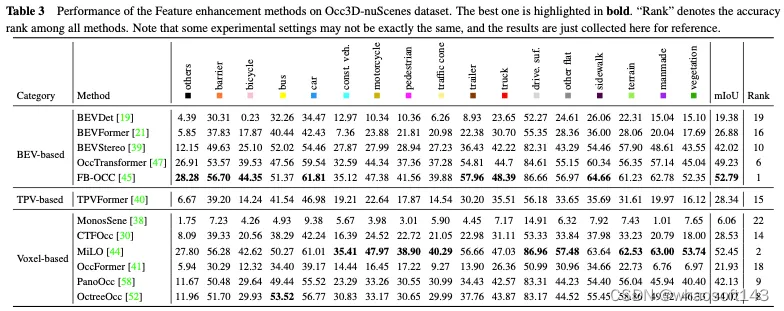
Occ3D nuScenes数据集上特征增强方法的性能比较如表3所示。结果表明,直接处理体素表示的方法通常能够实现强大的性能,因为它们在计算过程中不会遭受显著的信息损失。此外,尽管基于BEV的方法只有一个投影视点用于特征表示,但由于鸟瞰图中包含的丰富信息以及它们对遮挡和比例变化的不敏感性,它们仍然可以实现可比较的性能。此外,通过从多个互补视图重建3D信息,基于三视角视图(TPV)的方法能够减轻潜在的几何模糊性,并捕捉更全面的场景背景,从而实现有效的3D占用预测。值得注意的是,FB-OCC同时利用了前向和后向视图转换模块,使它们能够相互增强,以获得更高质量的纯电动汽车表示,并取得了优异的性能。这表明,通过有效的特征增强,基于BEV的方法在改善3D占用预测方面也有很大的潜力。
部署友好方法
由于其广泛的范围和复杂的数据性质,直接从3D空间学习占用表示是极具挑战性的。与3D体素表示相关的高维度和密集的计算使得学习过程对资源的要求很高,这不利于实际部署应用。因此,设计部署友好的3D表示的方法旨在降低计算成本并提高学习效率。本节介绍了解决3D场景占用估计中计算挑战的方法,重点是开发准确高效的方法,而不是直接处理整个3D空间。所讨论的技术包括透视分解和从粗到细的细化,这些技术已在最近的工作中得到证明,以提高3D占用预测的计算效率。
Perspective decomposition methods
通过将视点信息从3D场景特征中分离出来或将其投影到统一的表示空间中,可以有效地降低计算复杂度,使模型更加稳健和可推广。这种方法的核心思想是将三维场景的表示与视点信息解耦,从而减少特征学习过程中需要考虑的变量数量,降低计算复杂度。解耦视点信息使模型能够更好地泛化,适应不同的视点变换,而无需重新学习整个模型。
为了解决从整个3D空间学习的计算负担,一种常见的方法是使用鸟瞰图(BEV)和三视角图(TPV)表示。通过将3D空间分解为这些单独的视图表示,计算复杂度显著降低,同时仍然捕获用于占用预测的基本信息。关键思想是首先从BEV和TPV的角度学习,然后通过结合从这些不同视图中获得的见解来恢复完整的3D占用信息。与直接从整个3D空间学习相比,这种透视分解策略允许更高效和有效的占用估计。
Coarse-to-fine methods
直接从大规模3D空间学习高分辨率细粒度全局体素特征是耗时且具有挑战性的。因此,一些方法已经开始探索采用从粗到细的特征学习范式。具体而言,网络最初从图像中学习粗略的表示,然后细化和恢复整个场景的细粒度表示。这两步过程有助于实现对场景占用率的更准确和有效的预测。
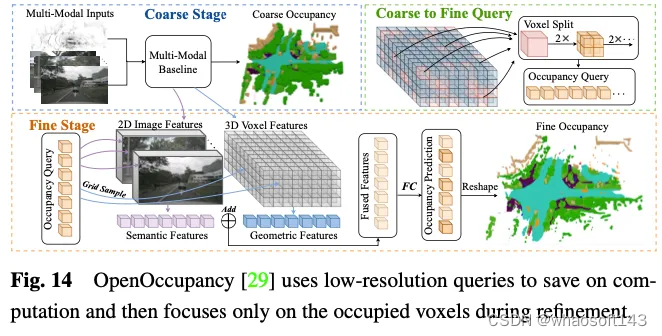
OpenOccupancy采用两步方法来学习3D空间中的占用表示。如图14所示。
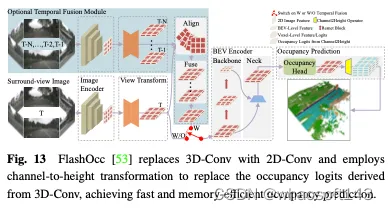
预测3D占用率需要详细的几何表示,并且利用所有3D体素标记与多视图图像中的ROI进行交互将产生显著的计算和内存成本。如图15所示,Occ3D提出了一种增量令牌选择策略,在交叉注意力计算过程中选择性地选择前景和不确定的体素令牌,从而在不牺牲精度的情况下实现自适应高效计算。具体地,在每个金字塔层的开始,每个体素标记被输入到二进制分类器中,以预测体素是否为空,由二进制地面实况占用图来监督以训练分类器。PanoOcc提出在联合学习框架内无缝集成对象检测和语义分割,促进对3D环境的更全面理解。该方法利用体素查询来聚合来自多帧和多视图图像的时空信息,将特征学习和场景表示合并为统一的占用表示。此外,它通过引入占用稀疏性模块来探索3D空间的稀疏性,该模块在从粗到细的上采样过程中逐渐稀疏占用,显著提高了存储效率。
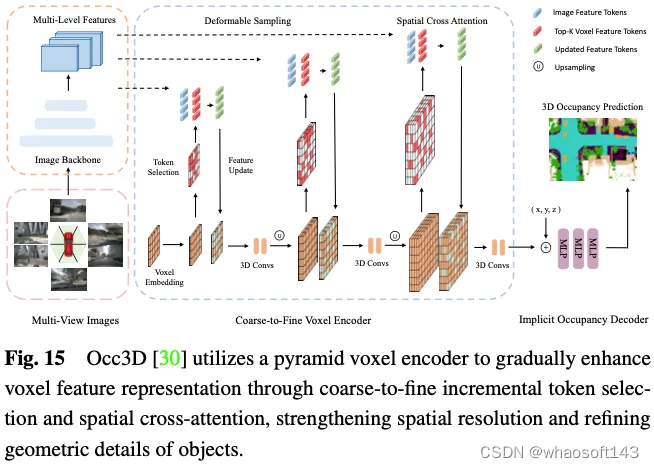
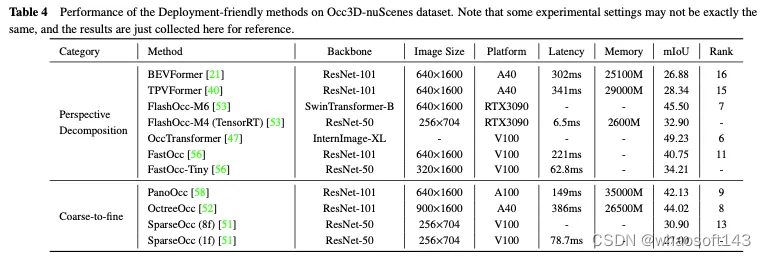
Occ3D nuScenes数据集上部署友好方法的性能比较如表4所示。由于结果是从不同的论文中收集的,在主干、图像大小和计算平台方面存在差异,因此只能得出一些初步结论。通常,在类似的实验设置下,由于信息丢失较少,从粗到细的方法在性能方面优于透视分解方法,而透视分解通常表现出更好的实时性能和更低的内存使用率。此外,采用较重主干和处理较大图像的模型可以获得更好的精度,但也会削弱实时性能。尽管FlashOcc和FastOcc等方法的轻量级版本已经接近实际部署的要求,但它们的准确性还需要进一步提高。对于部署友好的方法,透视分解策略和从粗到细策略都致力于在保持3D占用预测准确性的同时,不断减少计算负载。
Label-efficient methods
在现有的创建精确占用标签的方法中,有两个基本步骤。第一个是收集与多视图图像相对应的激光雷达点云,并进行语义分割注释。另一种是利用动态物体的跟踪信息,通过复杂的算法融合多帧点云。这两个步骤都相当昂贵,这限制了占用网络利用自动驾驶场景中大量多视图图像的能力。近年来,神经辐射场(Nerf)在二维图像绘制中得到了广泛的应用。有几种方法以类似Nerf的方式将预测的三维占用绘制成二维地图,并在没有细粒度标注或激光雷达点云参与的情况下训练占用网络,这显著降低了数据标注的成本。
Annotation-free methods
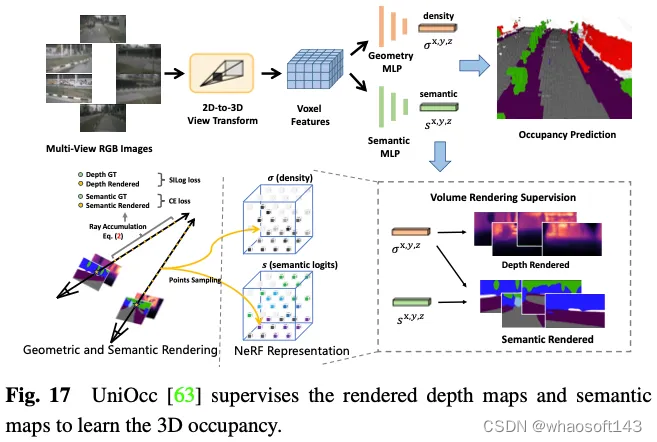
SimpleOccupancy首先通过视图变换从图像特征中生成场景的显式3D体素特征,然后按照Nerf风格的方式将其渲染为2D深度图。二维深度图由激光雷达点云生成的稀疏深度图监督。深度图还用于合成用于自我监督的环绕图像。UniOcc使用两个单独的MLP将3D体素logits转换为体素的密度和体素的语义logits。之后,UniOCC按照一般的体积渲染来获得多视图深度图和语义图,如图17所示。这些2D地图由分割的LiDAR点云生成的标签进行监督。RenderOcc从多视图图像中构建类似于NeRF的3D体积表示,并使用先进的体积渲染技术来生成2D渲染,该技术可以仅使用2D语义和深度标签来提供直接的3D监督。通过这种2D渲染监督,该模型通过分析来自各种相机截头体的光线交点来学习多视图一致性,从而更深入地了解3D空间中的几何关系。此外,它引入了辅助光线的概念,以利用来自相邻帧的光线来增强当前帧的多视图一致性约束,并开发了一种动态采样训练策略来过滤未对准的光线。为了解决动态和静态类别之间的不平衡问题,OccFlowNet进一步引入了占用流,基于3D边界框预测每个动态体素的场景流。使用体素流,可以将动态体素移动到时间帧中的正确位置,从而无需在渲染过程中进行动态对象过滤。在训练过程中,使用流对正确预测的体素和边界框内的体素进行转换,以与时间帧中目标位置对齐,然后使用基于距离的加权插值进行网格对齐。
上述方法消除了对显式3D占用注释的需要,大大减少了手动注释的负担。然而,他们仍然依赖激光雷达点云来提供深度或语义标签来监督渲染的地图,这还不能实现3D占用预测的完全自监督框架。
LiDAR-free methods
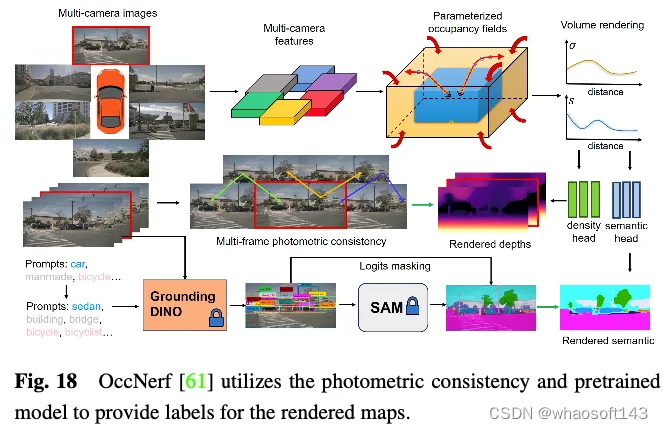
OccNerf不利用激光雷达点云来提供深度和语义标签。相反,如图18所示,它使用参数化占用字段来处理无边界的室外场景,重新组织采样策略,并使用体积渲染将占用字段转换为多相机深度图,最终通过多帧光度一致性进行监督。此外,该方法利用预先训练的开放词汇语义分割模型来生成2D语义标签,监督该模型将语义信息传递给占用字段。幕后使用单一视图图像序列来重建驾驶场景。它将输入图像的截头体特征视为密度场,并渲染其他视图的合成。通过专门设计的图像重建损失来训练整个模型。SelfOcc预测BEV或TPV特征的带符号距离场值,以渲染2D深度图。此外,原始颜色和语义图也由多视图图像序列生成的标签进行渲染和监督。
这些方法避开了对来自激光雷达点云的深度或语义标签的必要性。相反,他们利用图像数据或预训练的模型来获得这些标签,从而实现3D占用预测的真正的自监督框架。尽管这些方法可以实现最符合实际应用经验的训练模式,但仍需进一步探索才能获得令人满意的性能。
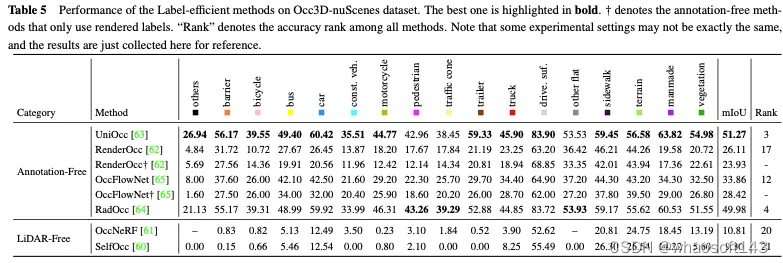
表5显示了Occ3D nuScenes数据集上标签高效方法的性能比较。大多数无注释方法使用2D渲染监督作为显式3D占用监督的补充,并获得了一定的性能改进。其中,UniOcc和RadOcc甚至在所有方法中分别获得了3和4的优异排名,充分证明了无注释机制可以促进额外有价值信息的提取。当仅采用2D渲染监督时,它们仍然可以实现相当的精度,说明了节省显式3D占用注释成本的可行性。无激光雷达的方法为3D占用预测建立了一个全面的自我监督框架,进一步消除了对标签和激光雷达数据的需求。然而,由于点云本身缺乏精确的深度和几何信息,其性能受到极大限制。
未来展望
在上述方法的推动下,我们总结了当前的趋势,并提出了几个重要的研究方向,这些方向有可能从数据、方法和任务的角度显著推进基于视觉的自动驾驶3D占用预测领域。
数据层面
获取充足的真实驾驶数据对于提高自动驾驶感知系统的整体能力至关重要。数据生成是一种很有前途的途径,因为它不会产生任何获取成本,并提供了根据需要操纵数据多样性的灵活性。虽然一些方法利用文本等提示来控制生成的驾驶数据的内容,但它们不能保证空间信息的准确性。相比之下,3D Occupancy提供了场景的细粒度和可操作的表示,与点云、多视图图像和BEV布局相比,有助于可控的数据生成和空间信息显示。WoVoGen提出了体积感知扩散,可以将3D占用映射到逼真的多视图图像。在对3D占用进行修改后,例如添加一棵树或更换一辆汽车,扩散模型将合成相应的新驾驶场景。修改后的三维占用记录了三维位置信息,保证了合成数据的真实性。
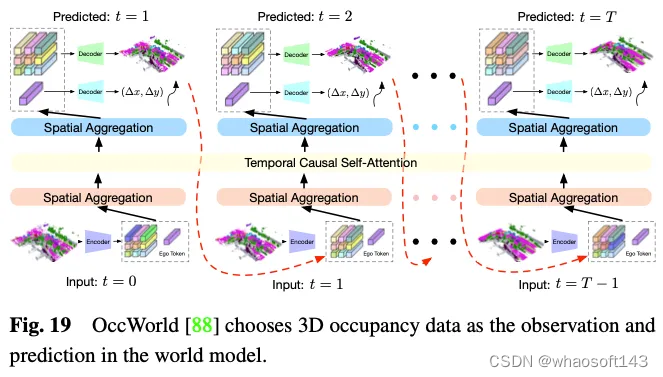
自动驾驶的世界模型越来越突出,它提供了一个简单而优雅的框架,增强了模型基于环境输入观测来理解整个场景并直接输出合适的动态场景演化数据的能力。鉴于其能够熟练地详细表示整个驾驶场景数据,利用3D占用率作为世界模型中的环境观测具有明显的优势。如图19所示,OccWorld选择3D占用率作为世界模型的输入,并使用类似GPT的模块来预测未来的3D占用率数据应该是什么样子。UniWorld利用了现成的基于BEV的3D occ-pancy模型,但通过处理过去的多视图图像来预测未来的3D占用数据,这也构建了一个世界模型。然而,无论机制如何,生成的数据和真实数据之间不可避免地存在领域差距。为了解决这个问题,一种可行的方法是将3D占用预测与新兴的3D人工智能生成内容(3D AIGC)方法相结合,以生成更真实的场景数据,而另一种方法是将领域自适应方法相结合以缩小领域差距。
方法论层面
当涉及到3D占用预测方法时,在我们之前概述的类别中,存在着需要进一步关注的持续挑战:功能增强方法、部署友好方法和标签高效方法。特征增强方法需要朝着显著提高性能的方向发展,同时保持可控的计算资源消耗。部署友好的方法应该记住,减少内存使用和延迟,同时确保将性能下降降至最低。标签高效的方法应该朝着减少昂贵的注释需求的方向发展,同时实现令人满意的性能。最终目标可能是实现一个统一的框架,该框架结合了功能增强、部署友好性和标签效率,以满足实际自动驾驶应用的期望。
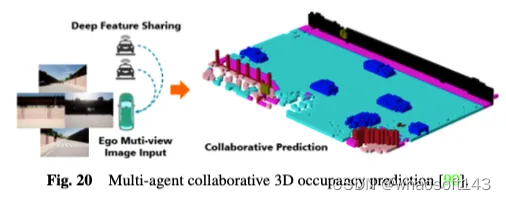
此外,现有的单智能体自动驾驶感知系统天生无法解决关键问题,如对遮挡的敏感性、远程感知能力不足和视野有限,这使得实现全面的环境意识具有挑战性。为了克服单智能体的瓶颈,多智能体协同感知方法开辟了一个新的维度,允许车辆与其他交通元素共享互补信息,以获得对周围环境的整体感知。如图20所示,多智能体协同3D占用预测方法利用协同感知和学习的力量进行3D占用预测,通过在连接的自动化车辆之间共享特征,能够更深入地了解3D道路环境。CoHFF是第一个基于视觉的协作语义占用预测框架,它通过语义和occupancy任务特征的混合融合,以及车辆之间共享的压缩正交注意力特征,改进了局部3D语义占用预测,在性能上显著优于单车系统。然而,这种方法往往需要同时与多个代理进行通信,面临准确性和带宽之间的矛盾。因此,确定哪些代理最需要协调,以及确定最有价值的协作领域,以实现准确性和速度之间的最佳平衡,是一个有趣的研究方向。
任务层面
在当前的3D占用基准中,某些类别具有明确的语义,如“汽车”、“行人”和“卡车”。相反,“人造”和“植被”等其他类别的语义往往是模糊和笼统的。这些类别包含了广泛的未定义语义,应该细分为更细粒度的类别,以提供驾驶场景的详细描述。此外,对于以前从未见过的未知类别,它们通常被视为一般障碍,无法根据人类提示灵活扩展新的类别感知。对于这个问题,开放词汇任务在2D图像感知方面表现出了强大的性能,并且可以扩展到改进3D占用预测任务。OVO提出了一个支持开放词汇表3D占用预测的框架。它利用冻结的2D分割器和文本编码器来获得开放词汇的语义参考。然后,采用三个不同级别的比对来提取3D占用模型,使其能够进行开放词汇预测。POP-3D设计了一个自监督框架,在强大的预训练视觉语言模型的帮助下,结合了三种模式。它方便了诸如零样本占用分割和基于文本的3D检索之类的开放式词汇任务。
感知周围环境的动态变化对于自动驾驶中下游任务的安全可靠执行至关重要。虽然3D占用预测可以基于当前观测提供大规模场景的密集占用表示,但它们大多局限于表示当前3D空间,并且不考虑周围物体沿时间轴的未来状态。最近,人们提出了几种方法来进一步考虑时间信息,并引入4D占用预测任务,这在真实的自动驾驶场景中更实用。Cam4Occ首次使用广泛使用的nuScenes数据集为4D占用率预测建立了一个新的基准。该基准包括不同的指标,用于分别评估一般可移动物体(GMO)和一般静态物体(GSO)的占用预测。此外,它还提供了几个基线模型来说明4D占用预测框架的构建。尽管开放词汇3D占用预测任务和4D占用预测任务旨在从不同角度增强开放动态环境中自动驾驶的感知能力,但它们仍然被视为独立的任务进行优化。模块化的基于任务的范式,其中多个模块具有不一致的优化目标,可能导致信息丢失和累积错误。将开集动态占用预测与端到端自动驾驶任务相结合,将原始传感器数据直接映射到控制信号是一个很有前途的研究方向。

)
)


虚拟地址与页表)
