🔍 探索MySQL的强大功能,它是如何帮助开发者和企业高效存储、检索和管理数据的。MySQL以其可靠性、易用性和灵活性而闻名,是Web应用开发的首选数据库解决方案。
1. 存储引擎
1.1 InnoDB:
-
InnoDB是MySQL的默认存储引擎,从MySQL 5.5.5版本开始。
-
支持事务处理、行级锁定和外键约束。
-
使用B+树作为索引结构。
-
提供崩溃恢复能力。
-
适合需要事务支持和高并发操作的应用。
1.2 MyISAM:
-
MyISAM是MySQL早期的默认存储引擎。
-
不支持事务处理,但提供全文索引。
-
使用B+树作为索引结构。
-
支持表级锁定。
-
适合读密集型的应用。
还有其他的如Memory、Archive、MariaDB 等一些引擎,本文只叙说当前热门两种。
2. 索引结构
2.1 B+树:
-
InnoDB和MyISAM存储引擎都使用B+树作为索引结构,它允许高效的全键值搜索、键值搜索和范围查询。
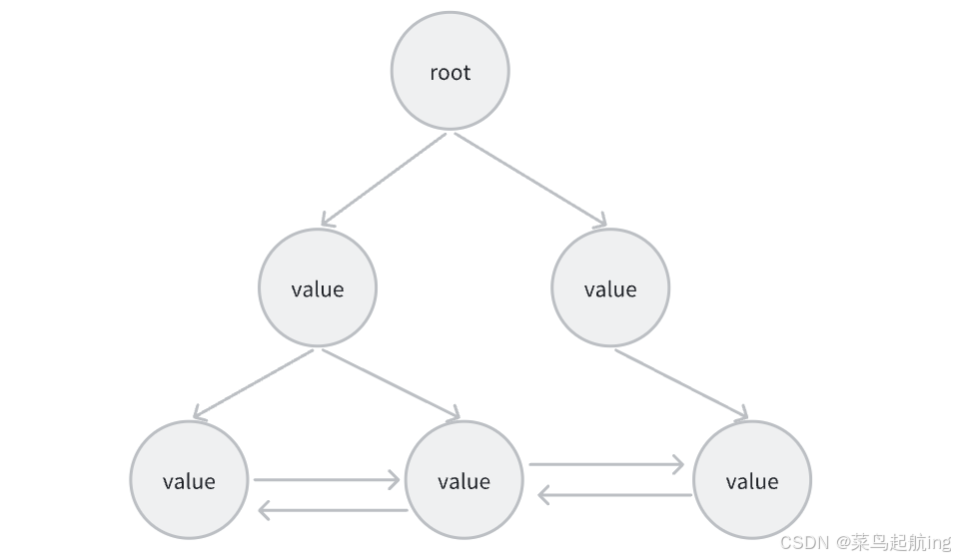
B+树被广泛用作数据库索引的数据结构:
1.高效的磁盘I/O:
-
B+树的节点可以包含更多的键值,这意味着在相同数据量的情况下,B+树比B树有更浅的树高,减少了查找数据时所需的磁盘I/O次数。
2. 查询性能稳定:
-
由于B+树的所有叶子节点都位于同一层,并且数据存储在叶子节点中,查询性能更加稳定,查询任何数据的最坏情况与最好情况的磁盘I/O次数相同。
3. 适合页式存储:
- 数据库系统通常以页(page)为单位存储数据,B+树的结构可以很好地适应页式存储,提高存储效率。
4. 写操作优化:
-
B+树的更新操作(如插入和删除)时,更不容易发生页分裂和页合并,因为非叶子节点不存储数据,只有叶子节点存储数据,减少了页分裂和页合并的需要。
5. 范围查询高效:
-
B+树的叶子节点形成了一个链表,使得范围查询更加高效。对于需要顺序访问大量数据的查询,如“找出所有年龄在20到30之间的用户”,B+树可以快速定位到第一个符合条件的记录,并顺序访问所有后续记录。
6. 高扇出性:
-
B+树具有高扇出性,即每个节点可以有多个子节点,这减少了树的高度,提高了查询速度。
7. 局部性原理:
-
B+树的访问模式符合局部性原理,即相邻数据更可能被频繁地一起访问。由于B+树叶子节点的链表结构,相邻数据的访问速度更快。
8. 可预测的性能:
-
B+树的高度较低,使得查询路径长度可预测,这对于数据库性能调优非常重要。
9. 并发控制:
-
在并发环境下,B+树的结构可以更容易地实现锁策略,因为它的节点结构和访问模式可以减少锁竞争。
2.2 哈希索引:
-
Memory存储引擎使用哈希索引,适用于等值查询操作。

哈希具有相应的优点:
1. 快速查找:
- 哈希表提供了平均情况下常数时间复杂度(O(1))的数据访问性能,这意味着无论表中有多少数据,查找速度都非常快。
2. 简单高效:
- 哈希表的实现相对简单,不需要复杂的平衡树结构,这使得哈希表在实现上更加高效。
3. 插入和删除操作快速:
-
除了查找之外,哈希表的插入和删除操作也通常非常快,这些操作的时间复杂度也是平均O(1)。
4. 键到值的直接映射:
-
哈希表通过哈希函数将键直接映射到存储位置,这种直接映射减少了查找路径,提高了检索效率。
5. 动态扩展:
-
许多哈希表实现支持动态扩展,当负载因子(已存储元素数量与哈希表大小的比例)超过一定阈值时,哈希表可以自动增加大小,以保持操作的效率。
6. 无序性:
-
哈希表不保持任何元素顺序,这对于只需要快速访问而不需要顺序处理的应用来说是有利的。
7. 适合实现缓存:
-
哈希表因其快速的访问速度,常被用于实现缓存系统,如内存缓存、数据库查询缓存等。
8. 处理大量数据:
-
在内存中处理大量数据时,哈希表可以提供快速的数据访问,尤其是在数据集远大于可用内存时,哈希表可以通过溢出处理(如链表或开放寻址法)来管理数据。
尽管哈希表在很多情况下都非常有用,但它们也有一些局限性,比如哈希冲突、哈希表的动态扩容可能导致性能问题、以及在处理范围查询时不如B树或B+树高效。
2.3 全文索引:
-
MyISAM和InnoDB存储引擎支持全文索引,用于文本搜索。MySQL的全文索引使用倒排索引(Inverted Index)实现
ALTER TABLE table_name ADD FULLTEXT(index_name) (column_name);全文索引(Full-Text Index)是一种特殊的索引类型,它用于对文本数据中的单词或短语进行索引,以支持高效的全文搜索查询。这种索引允许用户搜索存储在数据库中的大量文本数据,类似于互联网搜索引擎的工作方式。全文索引特别适用于需要执行复杂文本搜索的场景,比如搜索引擎、文档管理系统和数据分析应用。
3. 储存结构
3.1 物理存储结构
3.1.1 磁盘文件
-
数据文件:存储实际的数据和索引。对于MyISAM存储引擎,数据文件通常以
.MYD(MyData)和.MYI(MyIndex)扩展名结尾。对于InnoDB存储引擎,数据和索引都存储在一个或多个.ibd(InnoDB tablespace)文件中。 -
日志文件:记录数据库操作,用于恢复和复制。
-
重做日志(Redo Log):InnoDB存储引擎用来保证事务的持久性。
-
归档日志(Binary Log):记录数据库更改的日志,用于复制和数据恢复。
-
错误日志(Error Log):记录MySQL服务器启动和运行时的错误信息。
-
慢查询日志(Slow Query Log):记录执行时间超过特定阈值的查询。
-
回滚日志(Undo Log):MyISAM引擎独有。回滚事务,在无redo log时可以做数据恢复,在MVCC中用于读取已提交数据的历史版本。
-
3.1.2 表空间(Tablespace)
-
InnoDB存储引擎使用表空间来管理数据和索引的存储。表空间可以是系统表空间(包含所有未明确指定表空间的表)或者文件表空间(由单独的文件组成,可以为特定的表指定)。
3.2 逻辑存储结构
3.2.1 数据库(Database)
-
最高的逻辑层次,包含一组相关的表、视图、存储过程等。
3.2.2 表(Table)
-
由行(Row)和列(Column)组成的数据结构,用于存储数据。
3.2.3 索引(Index)
-
用于提高数据检索效率的数据结构,如B+树索引。
3.2.4 视图(View)
-
基于SQL查询的虚拟表,不存储数据。
3.2.5 存储过程和函数(Stored Procedure and Function)
-
存储过程是一组为了执行特定任务而预编译的SQL语句。函数是返回单个值的存储过程。
3.2.6 触发器(Trigger)
-
由特定数据库操作触发的数据库操作。
3.3 内存结构
3.3.1 缓冲池(Buffer Pool)
-
InnoDB存储引擎使用缓冲池来缓存数据和索引,提高数据访问速度。
3.3.2 重做日志缓冲(Redo Log Buffer)
-
存储重做日志信息的内存区域,用于事务的持久性。
3.3.3 查询缓存(Query Cache)
-
缓存SELECT查询的结果,以加速重复查询的执行。(在MySQL 8.0中已被移除)
对于数据库相关操作会单独出一篇推文!!!
不积跬步,无以至千里 --- xiaokai






JavaScript库(防抖、节流、函数柯里化)JS库)