第一章、RTP时间戳与NTP时间戳
1.1 RTP时间戳
时间戳,用来定义媒体负载数据的采样时刻,从单调线性递增的时钟中获取,时钟的精度由 RTP 负载数据的采样频率决定。
音频和视频的采样频率是不一样的,一般音频的采样频率有 8KHz、16KHz、48KHz等,而视频反映在采样帧率上,一般帧率有 20fps、24fps、30fps等。
音视频采样后会给每个音频采样、视频帧打一个时间戳,打包成RTP后放在RTP头中,称为RTP时间戳,RTP时间戳的单位依赖于音视频流各自的采样率。
1.1.1 RTP Header
RTP Header格式如下:
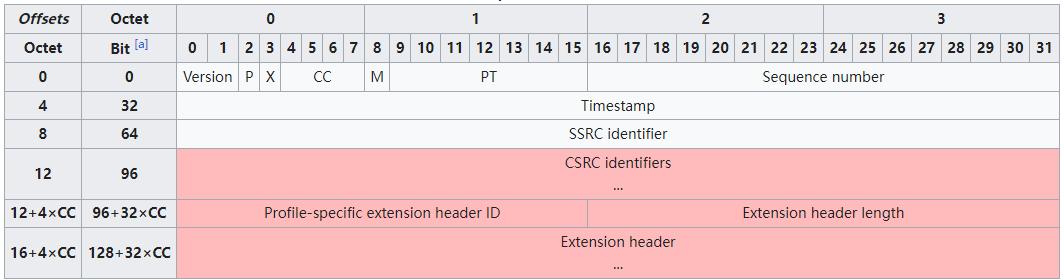
V:RTP协议的版本号,占2位,当前协议版本号为2
P(Padding):填充标志,占1位,如果P=1,则在该报文的尾部填充一个或多个额外的八位组,它们不是有效载荷的一部分
X:扩展标志,占1位,如果X=1,则在RTP报头后跟有一个扩展报头
CC:CSRC计数器,占4位,指示CSRC 标识符的个数
M: 标记,占1位,不同的有效载荷有不同的含义,对于视频,标记一帧的结束;对于音频,标记会话的开始
PT: 有效荷载类型,占7位,用于说明RTP报文中有效载荷的类型,如GSM音频、JPEG图像等,在流媒体中大部分是用来区分音频流和视频流的,这样便于客户端进行解析
序列号:占16位,用于标识发送者所发送的RTP报文的序列号,每发送一个报文,序列号增1。这个字段当下层的承载协议用UDP的时候,网络状况不好的时候可以用来检查丢包。同时出现网络抖动的情况可以用来对数据进行重新排序,序列号的初始值是随机的,同时音频包和视频包的sequence是分别记数的。
时间戳(Timestamp):占32位,每个流中的时间戳可以是独立的,时间戳反映了该RTP报文的第一个八位组的采样时刻。接收者使用时间戳来计算延迟和延迟抖动,并进行同步控制。视频流通常使用 90 kHz 时钟频率
同步信源(SSRC)标识符:占32位,用于标识同步信源。该标识符是随机选择的,参加同一视频会议的两个同步信源不能有相同的SSRC
特约信源(CSRC)标识符:每个CSRC标识符占32位,可以有0~15个。每个CSRC标识了包含在该RTP报文有效载荷中的所有特约信源
1.1.2音频时间戳
音频时间戳的单位就是采样率的倒数,例如采样率48000Hz,即48000个采样/秒,每个采样1/48ms,每个采样对应一个时间戳。RTP音频包一般打包20ms的数据,对应的采样数为 48000 * 20 / 1000 = 960,也就是说每个音频包里携带960个音频采样(即n为960),因为1个采样对应1个时间戳,那么相邻两个音频RTP包的时间戳之差就是960。
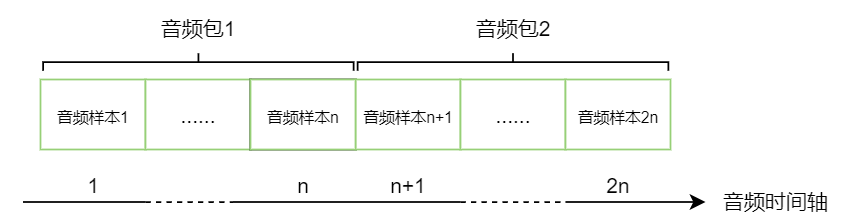
1.1.3 音频时间戳生成
WebRTC的音频帧的时间戳,未打包之前是从第一个包为0开始累加,每一帧增加编码帧长(ms) x采样率/ 1000,如果采样率48000Hz,编码帧长20ms,则每个音频帧的时间戳递增960(即20 x 48000/1000),若采样率为16000Hz,则每个音频帧的时间戳是320。
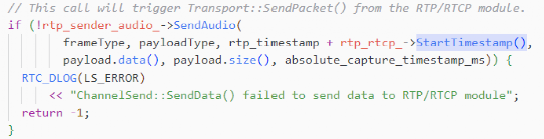
封装到 RTP 包里面的时候,会将这个音频帧的时间戳再累加上一个随机偏移量(构造函数里生成),然后作为此 RTP 包的时间戳,发送出去。
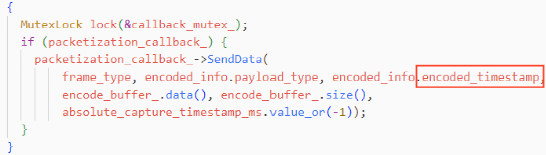
音频时间戳生成代码实现:
1)采集的时间戳

2)封装到RTP包累加上一个随机偏移量
1.1.4 视频时间戳
视频时间戳一般是采用90kHz时钟频率,即单位为1/90000秒,但是90000并不是视频的采样率,而只是一个单位,帧率才是视频的采样率。
1)视频帧(H.264)打包方式不同
单NALU分组(Single NAL Unit Packet):一个分组只包含一个NALU,单独打包成一个RTP包那么RTP时间戳就对应这个帧的采集时间。
聚合分组(Aggregation Packet):一个分组包含多个
NALU。如果某帧较大不能单独打包,但是该帧内部单独的NALU比较小,可以使用STAP-A方式合并多个NALU打包发送,但是这些NALU的时间戳必须一致,打包后的RTP时间戳也必须一致。
分片分组(Fragmentation Unit):一个视频帧的NALU过大(超过MTU)需要拆分成多个包,可以使用FU-A方式来拆分并打到不同的RTP包里,那么这几个包的RTP时间戳是一样的。
2)视频时间戳生成
生成机制跟音频帧完全不同。视频帧的时间戳来源于系统时钟,采集完成后至编码之前的某个时刻,获取当前系统的时间timestamp_us_,然后算出此系统时间对应的ntp_time_ms_,再根据此ntp时间算出原始视频帧的时间戳 timestamp_rtp_。
采集时间:

视频时间戳生成流程:
记录系统NTP和系统时间的差delta_ntp_internal_ms_,即:
clock_->CurrentNtpInMilliseconds() - clock_->TimeInMilliseconds()
将采集时间转为NTP时间戳,再转为RTP时间戳,RTP time = NTP time * 90000Hz / 1000 = NTP time * 90
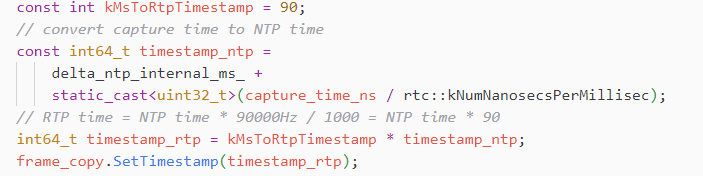
设置RTP时间戳到视频帧,再进行编码,编码后,封装到RTP包里面的时候,在设置的RTP时间戳基础上加上一个随机偏移。

1.2 NTP时间戳
NTP时间戳,是从1900年1月1日00:00:00以来经过的秒数,NTP时间戳的作用就是作为音视频时间基准。
RTP的标准并没有规定音频、视频流的第一个包必须同时采集、发送,比如开始的一小段时间内只有音频或者视频,或因网络丢包,不可认为第一个音频包和视频包是对齐的,需要一个共同的时间基准来做时间对齐,而NTP时间戳就是这个时间基准。
发送端以一定的频率发送SR(Sender Report)RTCP包,分为视频SR和音频SR,SR包内包含一个RTP时间戳和对应的NTP时间戳,接收端可以确定某个流的RTP时间戳和NTP时间戳的对应关系,因此音频和视频的时间戳可统一到同一个时间基准下。
在接收端中,收到音视频帧后,将RTP时间戳转为NTP时间戳,进行音视频同步。
1.3 RTP与NTP时间戳的关系
在计算视频的RTP时间戳,通过采集时间(即系统时间)转为NTP时间,再转为RTP时间,可见两者存在某种关系,又因为发送端的音频流与视频流是独立的,两者非一开始就同时采集且对应,所以发送端的音视频流是没有对齐的,需要接收端对齐,为了让接收端知道RTP与NTP的关系,发送会定期的发送SR包,描述了RTP与NTP的关系,再经过线性回归,得到RTP与NTP对应关系。
但是非常遗憾的是,RTP包中无法带上NTP时间戳,只能带RTP时间戳。
第二章、音视频同步原理介绍
2.1 音视频同步定义及同步方法
音视频同步是指在播放音视频时,音频和视频的播放进度保持一致,不会出现音频和视频不同步。
音视频同步一般有以下三种方法:
1)音频同步到视频
2)视频同步到音频
3)音视频均同步到系统时间
对于WebRTC中音频流与视频流互相独立的,在播放时尽量让同时刻采集的音频帧和视频帧,在接收端上的同一时刻去播放和显示,才能保证同步。
2.2 NTP与RTP相互转换
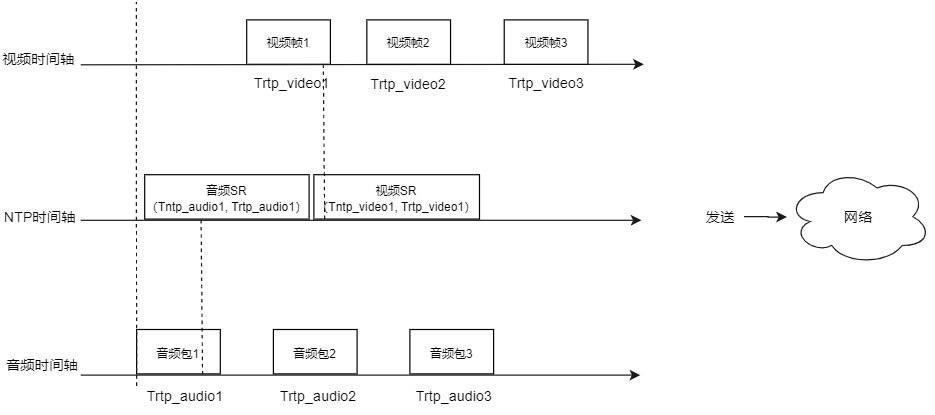
Tntp_audio = f(Trtp_audio)
Tntp_video = f(Trtp_video)
其中f为线性函数,即Tntp = f(Trtp) = kTrtp + b
由于NTP与RTP是线程关系,可以使用坐标系来表示,同一台机器上音频流和视频流的系统时间是一样的,系统时间对应的 NTP 时间也是一样的,在坐标系中横轴X,RTP时间戳在坐标系中纵轴Y
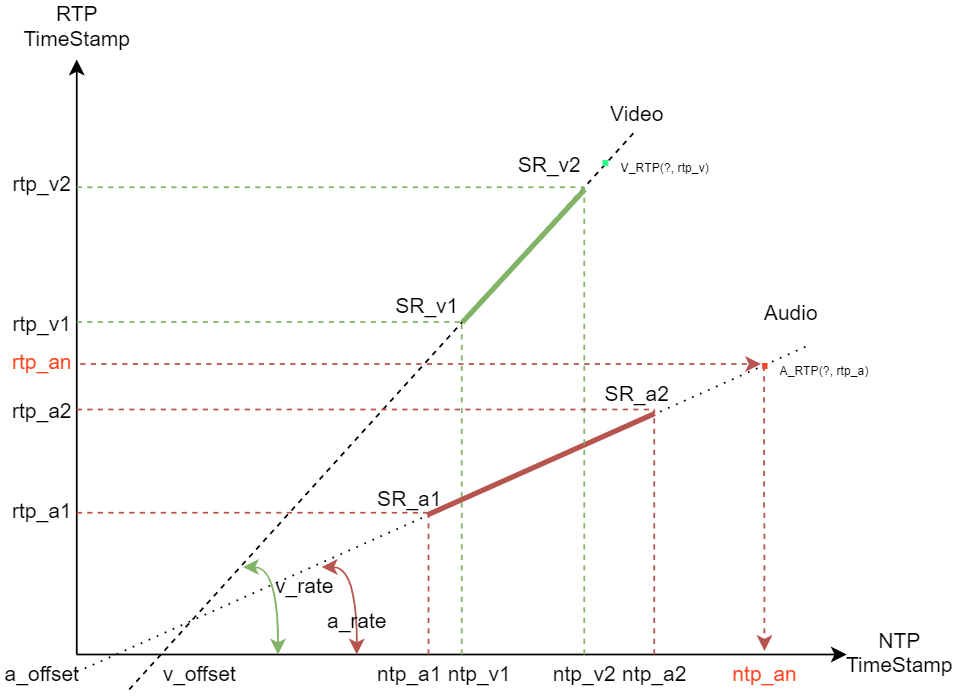
在发送端分别发送音频和视频的SR包,接收端收到2个SR包以上就可以确定一条直线,然后可以确定RTP与NTP的关系。
以Audio为例(红色线):
在接收端收到SR_a1和SR_a2两个包后,可以通过2点确定一线,即
Y = kX + b,其中k为斜率, b为偏移量
斜率a_rate = (rtp_a2 - rtp_a1) / (ntp_a2 - ntp_a1)
偏移量a_offset = rtp_a2 - a_rate * ntp_a2
得到斜率和偏移量后,任意X可以求Y,任意Y可以求X:
rtp_an = a_rate * ntp_an + a_offset
ntp_an = (rtp_an) / a_rate
同理,Video也是一样的求法。
2.3 线性回归
线性回归是一种统计学方法,用于研究两个或多个变量之间的关系,通过拟合一条直线来描述它们之间的关系,接收多个SR后,进行线性回归,线程回归计算步骤如下:
1)求所有SR的RTP和NTP的平均值
2)求每个SR样本的方差和协方差
方差是每个数据与其平均值之差的平方的平均值,方差越大,说明数据的离散程度越大,数据的分布越分散;方差越小,说明数据的离散程度越小,数据的分布越集中。
用variance_x表示x的方差:
variance_x = 1/n * Σ(x[i] - avg_x)^2
协方差是每个变量与其平均值之差的乘积的平均值,是用来衡量两个变量之间线性关系的强度和方向的统计量,表示两个变量之间的相关程度。
用covariance_xy表示x和y的协方差:
covariance_xy = 1/n * Σ(x[i] - avg_x) * (y[i] - avg_y)
3)求所有SR样本的方差和与协方差和,再除以样本数量n
代码实现如下:
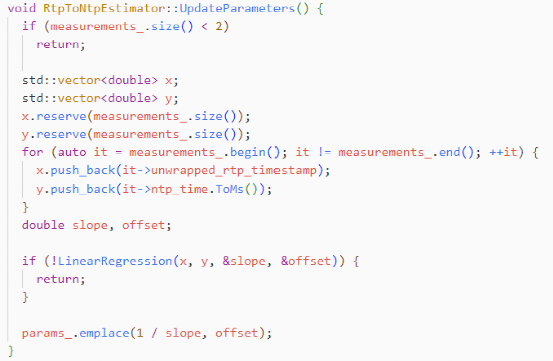
measurements_.size()是样本点数,要确定一条直线,至少需要2个点,小于2就直接返回。
x是所有的rtp值,y是所有ntp值。

第一步,判断x和y的大小,是否相等。
第二步,求x和y各自的平均值。
第三步,求x的方差,x和y的协方差。
第四步,判断x的方差是否接近于0的,接近0才是稳定的。
第五步,求得k和b值,得到线性函数。
由此,得到了线性函数,后续任何一个样本,都可以求得对应的NTP值。
2.4 Sender Report
Sender Report,简称SR包,是RTCP(Real-Time Transport Control Protocol,实时数据传输的控制协议)协议的一种。
SR包是发送端报告,PT值为200,用于报告发送端的统计信息,如发送端的时间戳、发送端的包数量、发送端的字节数等。SR包可以让接受端计算往返延迟、计算丢包等。
Sender Report头格式:

NTP timestamp:从第9个字节开始,共64bit是存放NTP时间戳,表示绝对时间戳,高32位是seconds,表示从1900年1月1日到现在经历的秒数,ntp.seconds = ms / 1000,低32位是fractions,用于表示剩余微秒部分,其值为剩余的微秒部分乘以2^32后四舍五入的结果值。
比如NTP时间为123456789.123456s,则seconds = 123456789,fractions = 0.123456 * 2^32 + 0.5,再四舍五入是530239482
RTP timestamp:是相对时间戳,音频和视频的计算是不同的,见第一章内容。
sender's packet count:发送的总包数
sender's octet count:发送的总字节数
2.5 音视频同步原理
SR包是音视频同步的手段,同步的原理在于计算音频包与视频包的时间差别,结合前面介绍的RTP与NTP的关系,接收端收到任意包都可以映射到NTP时间上。
在WebRTC中计算的是:最新收到的音频RTP包和最新收到的视频RTP包的对应的NTP时间,作为网络传输引入的不同步时长,然后又根据当前音频和视频的JitterBuffer和播放缓冲区的大小,得到了播放引入的不同步时长,根据两个不同步时长,得到了最终的音视频不同步时长。
简单的说,要计算出音频帧什么时候播放,视频帧什么时候渲染,音频和视频流才是同步的。

第三章、音视频相对延时与目标延时
3.1 音视频延时
前面已讲到音视频同步的核心就是计算音频帧什么时候播放,视频帧什么时候渲染,既要保证同步,也要保证流畅,换个角度就是计算各自的延时。
音视频延时,整个处理和传输过程都会产生延时,比如采集、编码、分包、网络传输、缓存、组包、解码、播放/渲染,而且音频与视频各个环节的延时不同,导致接收端需要正确设置好音视频各自的播放延迟后,音视频达到同步的效果。对音频来说,施加的延迟直接影响到音频缓存的大小,音频缓存的大小就体现了音频的播放延迟。对视频来说,施加的延迟影响到视频帧的渲染时间,通过比较渲染时间和当前时间来决定解码后的视频帧需要等待还是需要立刻渲染。
音视频同步中主要需要做到三点:
1)正确计算音视频相对延迟
2)正确计算音视频各自的网络目标时延
3)正确设置音视频各自的播放延迟
3.2 最近一对音视频包的相对延迟
相对延迟是指在进行音视频通信时,音频和视频数据在网络中传输的时间、编解码器对音视频数据进行编码和解码的时间、网络传输过程中的丢包和重传等因素的总和。相对延迟越小,音视频通信的质量就越高,用户的体验也就越好。
最近一对音视频包的相对延迟:
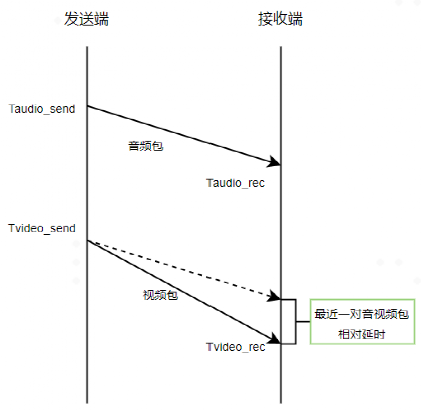
计算公式:
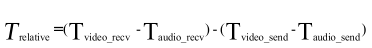
其中,Tvideo_recv、Taudio_recv分别是接收端收到视频包、音频包记录的本地时间,可以直接获取,而Tvideo_send,Taudio_send作为视频包、音频包的发送时间无法直接获取,因为接收到的RTP包只有RTP时间戳,无法直接作为本地时间来与Tvideo_recv、Taudio_recv进行运算,通过SR包中携带的NTP时间戳和RTP的对应关系来进行换算。
最近一对音视频包的相对延时,代码实现:
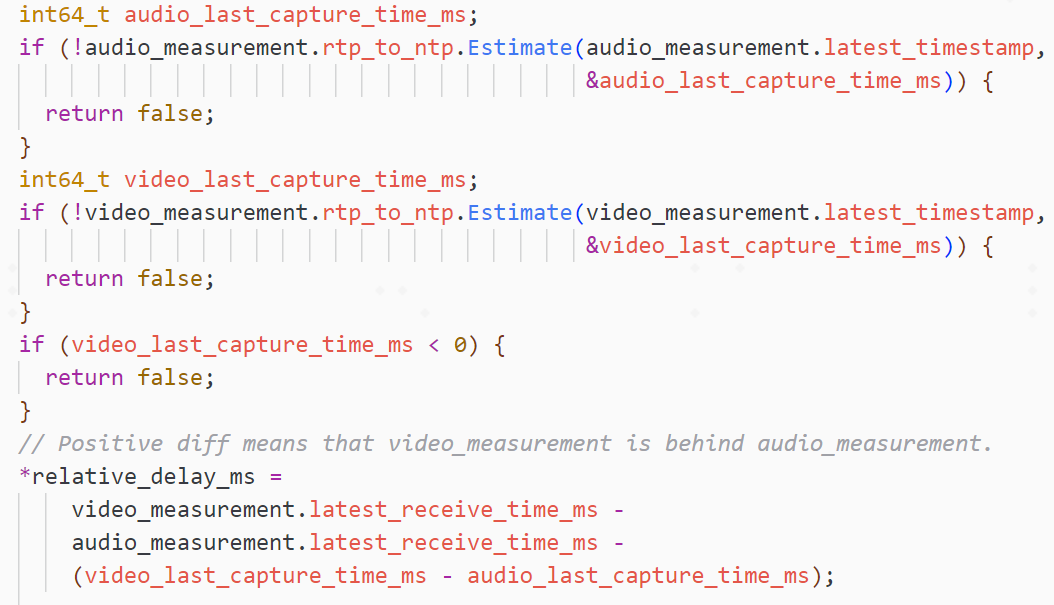
audio_measurement和video_measurement分别是记录音频和视频最新收到的包信息,每次收到包都会更新RTP时间和接收时间。
1)将音频包RTP时间戳,换成成对应的NTP时间(发送端本地时间)
2)将视频包RTP时间戳,换成成对应的NTP时间(发送端本地时间)
3)使用相对延迟公式计算出相对延迟
3.3 期望目标延迟
期望目标延迟就是保证音频流、视频流各自流畅播放的期望延迟、
对视频来说,期望目标延迟即为网络延迟、解码延迟、渲染延迟之和。
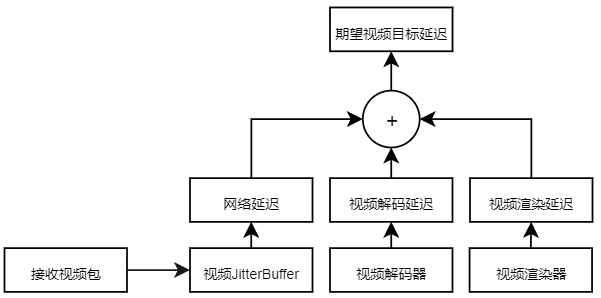
对音频来说,期望目标延迟即为前后两个音频包之间的到达间隔的期望值。
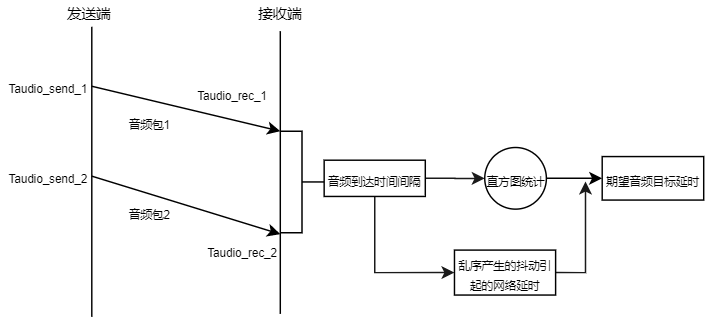
在接收时间的基础上,加上各自的期望目标延迟进行播放,可以保证音频、视频流可以按照各自的步调进行流畅无卡顿的播放。
3.4 期望音频目标延迟
网络抖动延时:target_buffer_level(初始值为80ms),网络抖动延时的更新流程:
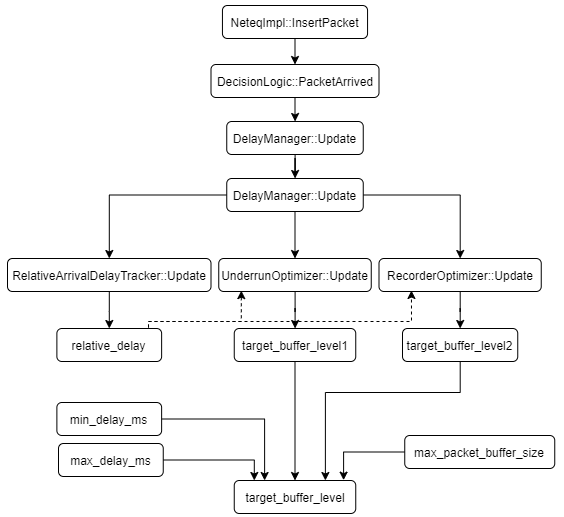
1)将当前达到包的timestamp,更新到RelativeArrivalDelayTracker,与上一个达到包比较,算出当前的抖动relative_delay。
2)将当前的抖动relative_delay更新到UnderrunOptimizer,算出当前的估算的网络抖动target_buff_level1(95分位柱状图),如果当前有乱序发生,将当前的抖动relative_delay更新到ReorderOptimizer,算出因乱序产生的抖动target_buffer_level2。
3)通过算出来的target_buffer_level1、target_buffer_level2、min_delay_ms、max_delay_ms及max_packet_buffer_size(最大包数量,比如50),算出最终的target_buffer_level,取值如下:
target_buffer_level = max(target_buffer_level1, target_buffer_level2)
target_buffer_level = max(target_buffer_level, min_delay_ms)
target_buffer_level =
min(target_buffer_level, max_delay_ms, 0.75 * max_packet_buffer_size)
4)用新的target_buffer_level更新遗忘因子
5)平滑jitter buffer大小,得到jitter buffer大小filtered_current_level
3.5 期望视频目标延迟
3.5.1 视频期望目标延迟计算
视频期望目标延迟,即为网络延迟、解码延迟、渲染延迟之和。

3.5.2 视频网络延迟
视频网络延迟即JittterBuffer延迟。
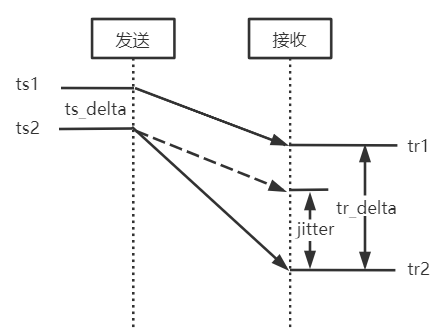
帧间延迟计算,即两帧的接收时间差和两帧的发送时间之差
jitter = tr_delta - ts_delta = (tr2 - tr1) - (ts2 - ts1)
通过卡尔曼滤波器平滑处理,综合帧间延迟的观测值、预测值,获得最优的帧间延迟,将视频帧的到达延迟差(抖动),作为网络的延迟。
3.5.3 解码时间
解码时间采用统计方法来计算,统计最近最多10000次解码的时间消耗,计算其95百分位数Tdecode,也就是说最近95%的帧的解码时间都小于Tdecode,以之作为解码时间。

3.5.4. 视频渲染延迟
初始化代码:render_delay_ms_(kDefaultRenderDelayMs)
其中kDefaultRenderDelayMs为10。

WebRTC中视频渲染时间默认为10ms。
3.6 音视频相对延迟
音视频相对延迟:最近一对音频相对延迟与音视频目标延迟差之和。
音视频目标延迟差:视频目标延迟与音频目标延迟之差。
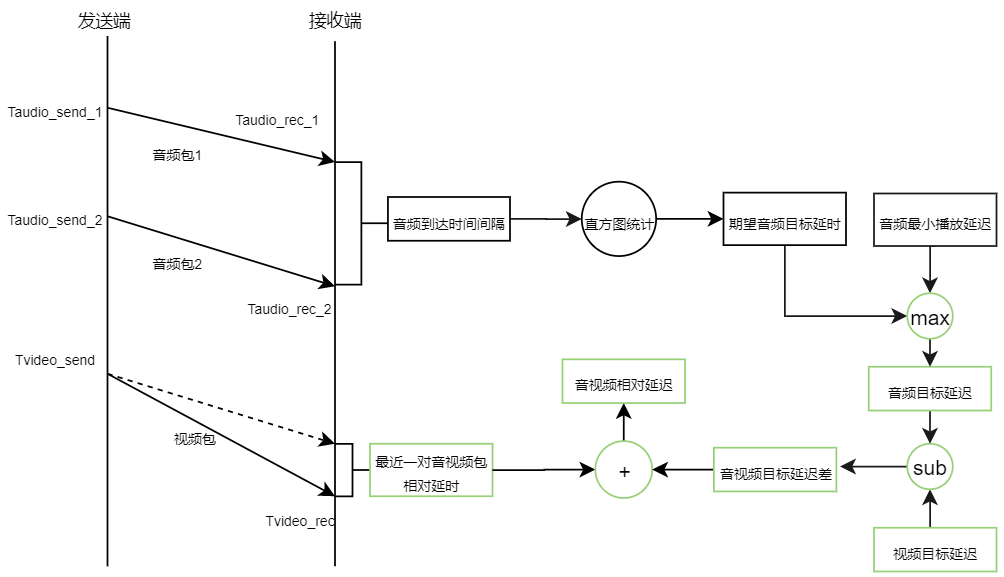
3.7 音视频目标延迟
音视频目标延迟,取期望目标延迟与最小播放延迟的最大值。最小播放延迟是音视频保证同步的最小延迟,而期望目标延迟是保证音视频流畅播放的延时。
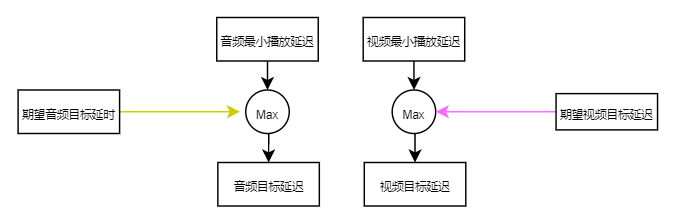
音频目标延迟计算,取期望目标延迟与最小播放延迟的最大值,且限制不大于最大buffer的75%。

视频目标延迟计算,取期望目标延迟与最小播放延迟的最大值

本文从RTP及NTP时间戳、音视频同步原理、目标延迟及同步实现4个方面,由简入繁地讲解WebRTC音视频同步的原理与实现。
本文篇幅过长,下期将第四章、第五章内容进行详解,感谢关注~
第四章、音视频同步实现详解
第五章、音画同步测量方法
参考文献
(1)《RTCP协议与实战》
https://blog.csdn.net/weixin_38102771/article/details/121866968
(2)《WebRTC音视频同步》
https://blog.csdn.net/xiehuanbin/article/details/133810695
(3)《WebRTC音视频同步详解》
https://blog.csdn.net/sonysuqin/article/details/107297157
(4)WebRTC源码https://webrtc.googlesource.com
(5)RTP官方文档 https://datatracker.ietf.org/doc/html/rfc3551

往
期
推
荐
Google VINTF机制经验总结
10分钟了解OPPO中间件容器化实践
利用ADPF性能提示优化Android应用体验





)