目录
- 摘要
- Abstract
- 1. 文献阅读
- 1.1 RNN
- 1.2 Deep Recurrent Neural Networks
- 1.3 实验
- 1.4 讨论
- 2. AI虚拟主播生成
- 总结
摘要
本周的主要任务是阅读了一篇关于循环神经网络的论文,该论文旨在探索将RNN扩展到深度RNN的不同方法。论文通过对RNN结构的理解和分析,发现从三个方面入手可以使网络变得更深, 输入到隐含函数,隐含到隐含转换函数以及隐含到输出函数。基于此类观察结果,论文提出了几种新颖的深度RNN结构,并通过实验验证了深度RNN优于传统的浅层RNN。
Abstract
The main task of this week is to read a paper on recurrent neural networks, which aims to explore different methods for extending RNNs to deep RNNs. Through understanding and analyzing the structure of RNN, the paper finds that starting from three aspects can make the network deeper: input-to-hidden function, hidden-to-hidden transition and hidden-to-output function.Based on such observation results, the paper proposes several novel deep RNN structures and verifies through experiments that deep RNN is superior to traditional shallow RNN.
1. 文献阅读
本周阅读了一篇关于RNN方面的论文,名为How to Construct Deep Recurrent Neural Networks。
(1)论文背景
论文中提到RNN和前馈神经网络一样去堆叠网络深度,可以产生具有影响力的模型,但不一样的是RNN的深度是比较模糊的,因为RNN的隐藏层在时间上展开时,可以表示为多个非线性层的组合,因此RNN已经足够深了。
(2)论文思路
作者研究了将RNN扩展到深层RNN的方法,首先研究了RNN的哪些部分可能被认为是浅层的,然后对每一个浅层部分,提出一种可以替代的更深层的设计,这会导致RNN出现很多更深的变体。
1.1 RNN
RNN是模拟具有输入xt,输出yt和隐含状态ht的离散时间动态系统,动态系统被定义为:

其中:下标t表示时间,fh表示状态转换函数,fo表示输出函数,每个函数由一组参数(θh和θo)进行优化。
给定一组有N个参数的训练序列,通过最小化代价函数去更新RNN的参数:
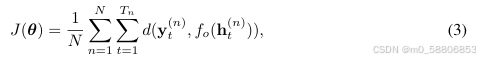
其中d(a, b)是a和b之间的预定义散度测度,例如欧式距离或者交叉熵。
Conventional Recurrent Neural Networks
将转换函数和输出函数定义为:
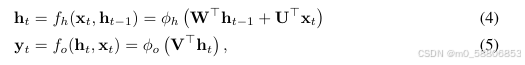
其中:W,U和V分别为转换矩阵,输入矩阵和输出矩阵,Φh和Φo是逐元素的非线性函数。通常,对于Φh使用饱和非线性函数,例如sigmoid函数或tanh函数。
1.2 Deep Recurrent Neural Networks
在前馈神经网络中,深度被定义为在输入和输出之间具有的多个非线性层。但不幸的是,由于RNN的时间结构,该定义不适用在RNN中。如下图所示,在时间上展开的RNN都很深,因为在时间k<t的输入到时间t的输出之间的传播路径跨越了几个非线性层。
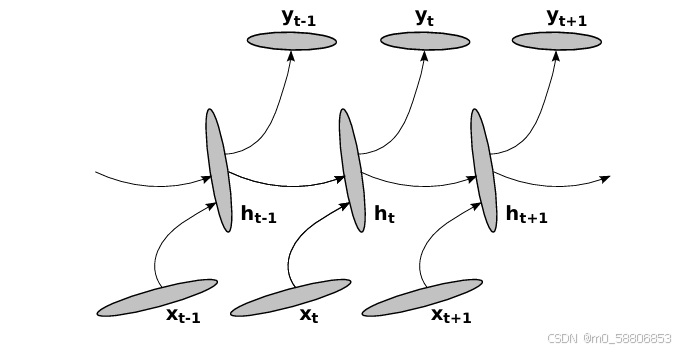
然而,对于RNN在每个时间步上的分析表明,某些转换并不深,而仅仅是线性投影的结果。因此,在没有中间非线性隐含层的情况下,隐含-隐含(ht-1 → ht),隐含-输出(ht → yt)和输入-隐含(xt → ht)函数都是浅的。
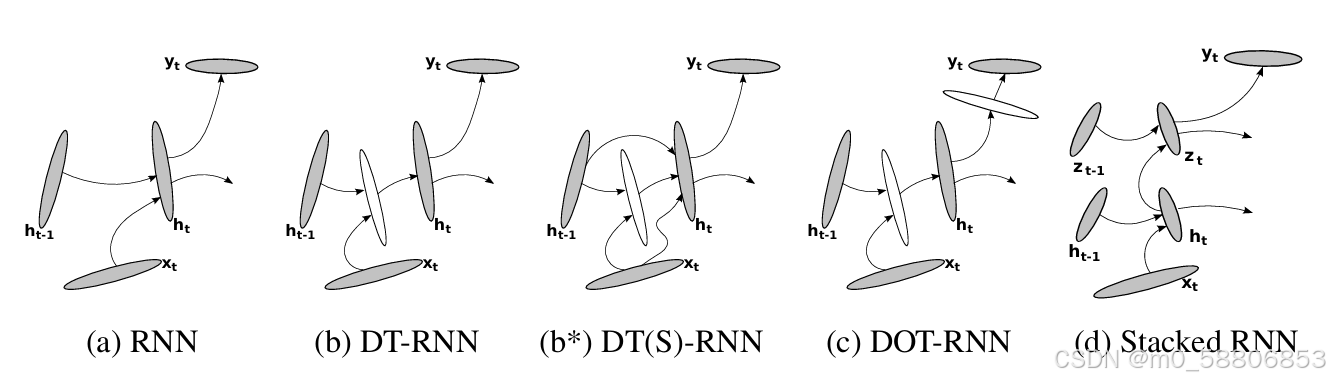
论文中提到可以通过这些转换来思考RNN深度的不同类型,通过在两个连续的隐含状态(ht-1和ht)之间具有一个或多个中间非线性层,可以使隐含-隐含的转换更深。同时,通过在隐含状态ht和输出yt之间插入多个中间非线性层,可以使隐含-输出函数更深。
Deep Transition RNN
从RNN模拟的动态系统的状态转移方程中可以发现,fh的形式没有限制。因此,论文中建议使用多层感知器来代替fh。
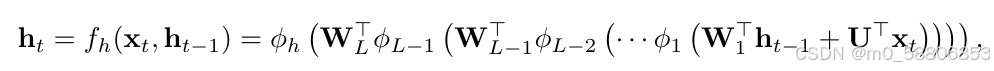
其中:Φl表示第l层的单元非线性函数,Wl表示第l层的权重矩阵。
Deep Output
与上述类似,论文中提出可以使用具有L个中间层的多层感知器来建立下图中的输出函数fo:
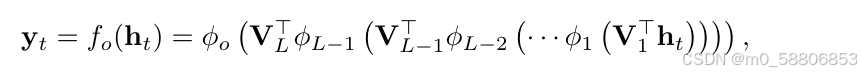
其中:Φl表示第l层的单元非线性函数,Vl表示第l层的权重矩阵。
Stacked RNN
堆叠式RNN具有多个层次的转换函数,其定义为:
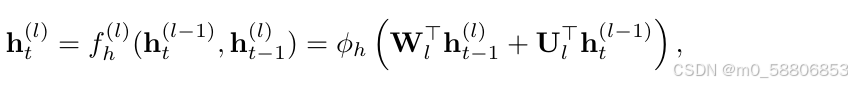
其中:ht,l表示在时间t时,第l层的隐含状态。当l = 1时,使用xt代替ht,l来计算状态。
1.3 实验
论文实验比较了RNN、DT(S)-RNN、DOT(S)-RNN和sRNN 2 layers这4种模型,其中每个模型的大小的选择都给定了范围,以保证实验结果的准确性。
(1)训练
本实验使用了随机梯度下降法和裁剪梯度的策略,当代价函数停止降低时,训练结束。
在Polyphonic Music Prediction实验中,为了正则化模型,论文在每次计算梯度时,将标准偏差0.075的高斯白噪声添加到每个权重参数中。
在Language Modeling实验中,学习率从初始值开始,每次代价函数没有显著降低时,学习率减半。实验中不使用任何正则化来进行字符级建模,但对于单词级建模,实验会添加权重噪声。
(2)结果与分析
如下图所示,展示了四种不同模型在同一数据集上的表现结果。

从上图的数据可以表明,深度RNN的表现都优于传统的浅层RNN,但每个深度RNN的适用性取决于其所训练的数据。
1.4 讨论
论文中提到在实验中遇到了一个实际问题是训练深度RNN的难度。训练传统的RNN是比较容易的,但训练深度RNN是比较困难的,因此论文中提出使用short connection以及常规RNN对它们进行预处理。然而,作者认为随着模型的大小和深度的增加,训练可能会变得更加困难。因此,在未来发现这一困难的根本原因和探索潜在的解决方案将非常重要,论文中提出可以使用advanced regularization methods和advanced optimization algorithms等有效的方法。
2. AI虚拟主播生成
随着人工智能技术的不断进步,AI虚拟主播正逐渐成为内容创作领域的一大热点。通过AI技术生成的虚拟形象不仅能够高度还原真人的外观,还能够与观众进行互动,提供更加个性化的内容体验。无论是在广告宣传、教育培训,还是在直播与社交平台上,AI虚拟主播都展现出了巨大的潜力。
使用AI绘画工具生成数字人
首先,我们要使用AI绘画工具为我们生成一个虚拟的数字人形象,这种数字人会非常接近真人的形象。这里使用的AI绘画工具比较推荐Midjourney,如果没有Midjourney也没关系,也可以使用在线网页版的文生图的国内AI网站。
补充:D-ID内也可直接生成数字人形象。

借助GPT生成数字人所需的提示词
首先我们要去构思如何编写创建数字人形象的提示词,我们通常会设定一些条件,比如他所从事的行业、年龄范围以及五官的具体特征等。这些设定有助于生成一个更符合我们需求的虚拟形象。
以下是一些参数可以参考:
基础: 国家、身份(学生/上班族/明星/网红/女装模特)、年龄
容貌 :面部(眼睛/鼻子/嘴巴/脸型)、肤色、身材、追加附魔词
服装 :面部(眼睛/鼻子/嘴巴/脸型)、肤色、身材、追加附魔词
场景 :地点、时间、天气、光线
摄影 :现实、人像摄影、构图 (占比)
动作 :默认也可以设定
比例 :9:16或3:4宽高比
这里提供一个现成模板用于测试
中国、网红
女明星,五官立体,身材好,
白色连衣裙
街拍,购物街道,
索尼,85mm
走路,
9:16我们可以使用通用大模型帮我生成提示词:
现在你是一名基于输入描述的提示词生成器,你会将我输入的自然语言想象为完整的画面生成提示词。请注意,你生成后的内容服务于一个绘画AI,它只能理解具象的提示词而非抽象的概念。我将提供简短的中文描述,生成器需要为我提供准确的提示词,必要时优化和重组以提供更准确的内容,也只输出翻译后的英文内容。
请模仿示例的结构生成完美的提示词。
示例输入:“一个坐在路边的办公室女职员”
示例输出:1 girl, office lady, solo, 16yo,beautiful detailed eyes, light blush, black hair, long hair, mole under eye, nose blush , looking at viewer, suits, white shirt, striped miniskirt, lace black pantyhose, black heels, LV bags,
thighhighs,sitting, street, shop border, akihabara , tokyo, tree, rain, cloudy, beautifully detailed background, depth of field, loli, realistic, ambient light, cinematic composition, neon lights, HDR, Accent Lighting, pantyshot, fish eye lens.
请仔细阅读我的要求,并严格按照规则生成提示词,如果你明白了,请回复"我准备好了",当我输入中文内容后,请生成我需要的英文内容。注意,英文连着写,不要标序号。示例过程如下:
使用KIMI、文心一言等AI工具也同样可以帮助我们生成提示词,这里以GPT为例:


以下是生成好的提示词,已加上分辨率9:16
Chinese celebrity, internet star, female, detailed facial features, attractive body, white dress, street photography, shopping street, Sony 85mm lens, walking, realistic, urban background, fashion, vibrant colors, natural lighting, candid moment. --ar 9:16在生成了提示词后,后续就可以在Midjourney中或者使用TensAI在线AI网站进行数字人的生成。
总结
本周看了一篇关于RNN方向上的论文,论文提出了几种新颖的深度RNN结构,并通过实验验证了深度RNN优于传统的浅层RNN。此外还简单学习了一下AI虚拟主播是如何制作的,后续会对其制作原理进行学习。






