FlinkX学习
FlinkX安装
由于flinkx已经改名chunjun 官网已不存在
(https://gitee.com/lugela/flinkx#flinkx)这里可以看到flinkx的操作文档
1、上传并解压
unzip flinkx-1.10.zip -d /usr/local/soft/
2、配置环境变量
FLINKX_HOME=/usr/local/soft/flinkx-1.10
export PATH=$FLINKX_HOME/bin:$PATH
3、给bin/flinkx这个文件加上执行权限
chmod +x flinkx
4、修改配置文件,设置运行端口
vim flinkconf/flink-conf.yaml## web服务端口,不指定的话会随机生成一个
rest.bind-port: 8888
启动
命令行参数选项
- model
- 描述:执行模式,也就是flink集群的工作模式
- local: 本地模式
- standalone: 独立部署模式的flink集群
- yarn: yarn模式的flink集群,需要提前在yarn上启动一个flink session,使用默认名称"Flink session cluster"
- yarnPer: yarn模式的flink集群,单独为当前任务启动一个flink session,使用默认名称"Flink per-job cluster"
- 必选:否
- 默认值:local
- 描述:执行模式,也就是flink集群的工作模式
- job
- 描述:数据同步任务描述文件的存放路径;该描述文件中使用json字符串存放任务信息。
- 必选:是
- 默认值:无
- pluginRoot
- 描述:插件根目录地址,也就是打包后产生的pluginRoot目录。
- 必选:是
- 默认值:无
- flinkconf
- 描述:flink配置文件所在的目录(单机模式下不需要),如/opt/dtstack/flink-1.8.1/conf
- 必选:否
- 默认值:无
- yarnconf
- 描述:Hadoop配置文件(包括hdfs和yarn)所在的目录(单机模式下不需要),如/hadoop/etc/hadoop
- 必选:否
- 默认值:无
- flinkLibJar
- 描述:flink lib所在的目录(单机模式下不需要),如/opt/dtstack/flink-1.8.1/lib
- 必选:否
- 默认值:无
- confProp
- 描述:flink相关参数,如{“flink.checkpoint.interval”:200000}
- 必选:否
- 默认值:无
- queue
- 描述:yarn队列,如default
- 必选:否
- 默认值:无
- pluginLoadMode
- 描述:yarnPer模式插件加载方式:
- classpath:提交任务时不上传插件包,需要在yarn-node节点pluginRoot目录下部署插件包,但任务启动速度较快
- shipfile:提交任务时上传pluginRoot目录下部署插件包的插件包,yarn-node节点不需要部署插件包,任务启动速度取决于插件包的大小及网络环境
- 必选:否
- 默认值:classpath
- 描述:yarnPer模式插件加载方式:
FlinkX概述
FlinkX是在是袋鼠云内部广泛使用的基于flink的分布式离线和实时的数据同步框架,实现了多种异构数据源之间高效的数据迁移。
不同的数据源头被抽象成不同的Reader插件,不同的数据目标被抽象成不同的Writer插件。理论上,FlinkX框架可以支持任意数据源类型的数据同步工作。作为一套生态系统,每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
FlinkX是一个基于Flink的批流统一体的数据同步工具,既可以采集静态的数据,比如MySQL,HDFS等,也可以采集实时变化的数据,比如MySQL binlog,Kafka等
在底层实现上,FlinkX依赖Flink,数据同步任务会被翻译成StreamGraph在Flink上执行.
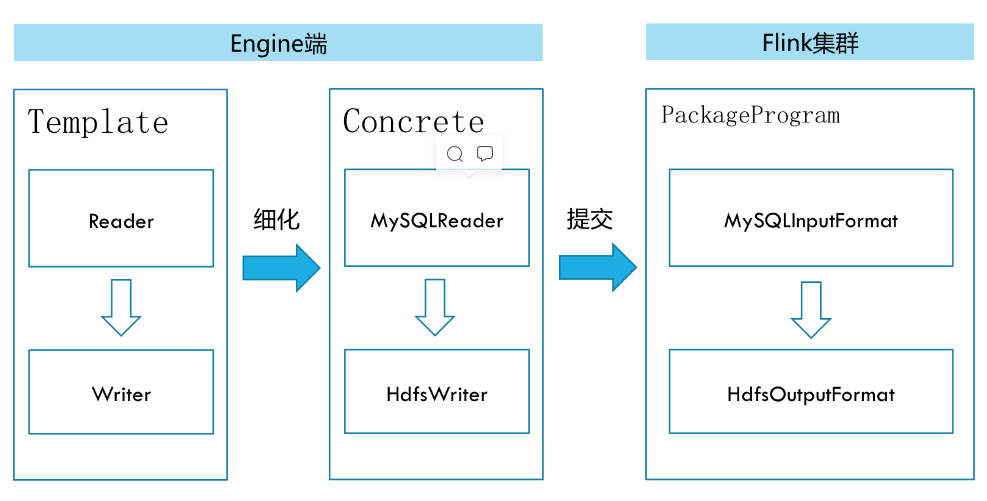
FlinkX的简单使用
MySQL2HDFS
场景
将mysql Y1数据库下的Student表数据写入HDFS上的指定路径中
参考文档
mysqlreader:(https://gitee.com/lugela/flinkx/blob/1.10_release/docs/offline/reader/mysqlreader.md)
hdfswriter:(https://gitee.com/lugela/flinkx/blob/1.10_release/docs/offline/writer/hdfswriter.md)
创建mysql2hdfs.json文件
{"job": {"content": [{"reader": {"parameter": {"username": "root","password": "123456","connection": [{"jdbcUrl": ["jdbc:mysql://master:3306/Y1?useUnicode=true&characterEncoding=utf8&useSSL=false"],"table": ["Student"]}],"column": ["*"],"where": "Sid > 05 ","requestAccumulatorInterval": 2},"name": "mysqlreader"},"writer": {"name": "hdfswriter","parameter": {"path": "hdfs://master:9000/bigdata30/flinkx/out1","defaultFS": "hdfs://master:9000","column": [{"name": "col1","index": 0,"type": "string"},{"name": "col2","index": 1,"type": "string"},{"name": "col3","index": 2,"type": "string"},{"name": "col4","index": 3,"type": "string"}],"fieldDelimiter": ",","fileType": "text","writeMode": "append"}}}],"setting": {"restore": {"isRestore": false,"isStream": false},"errorLimit": {},"speed": {"channel": 1}}}
}
运行模式
- 单机模式:对应Flink集群的单机模式
- standalone模式:对应Flink集群的分布式模式
- yarn模式:对应Flink集群的yarn模式
- yarnPer模式: 对应Flink集群的Per-job模式
运行:
flinkx -mode local -job ./mysql2hdfs.json -pluginRoot /usr/local/soft/flinkx-1.10/syncplugins/ -flinkconf /usr/local/soft/flinkx-1.10/flinkconf/
监听日志:
flinkx 任务启动后,会在执行命令的目录下生成一个nohup.out文件
tail -f nohup.out
通过web界面查看任务运行情况
http://master:8888
hdfs上出现文件:
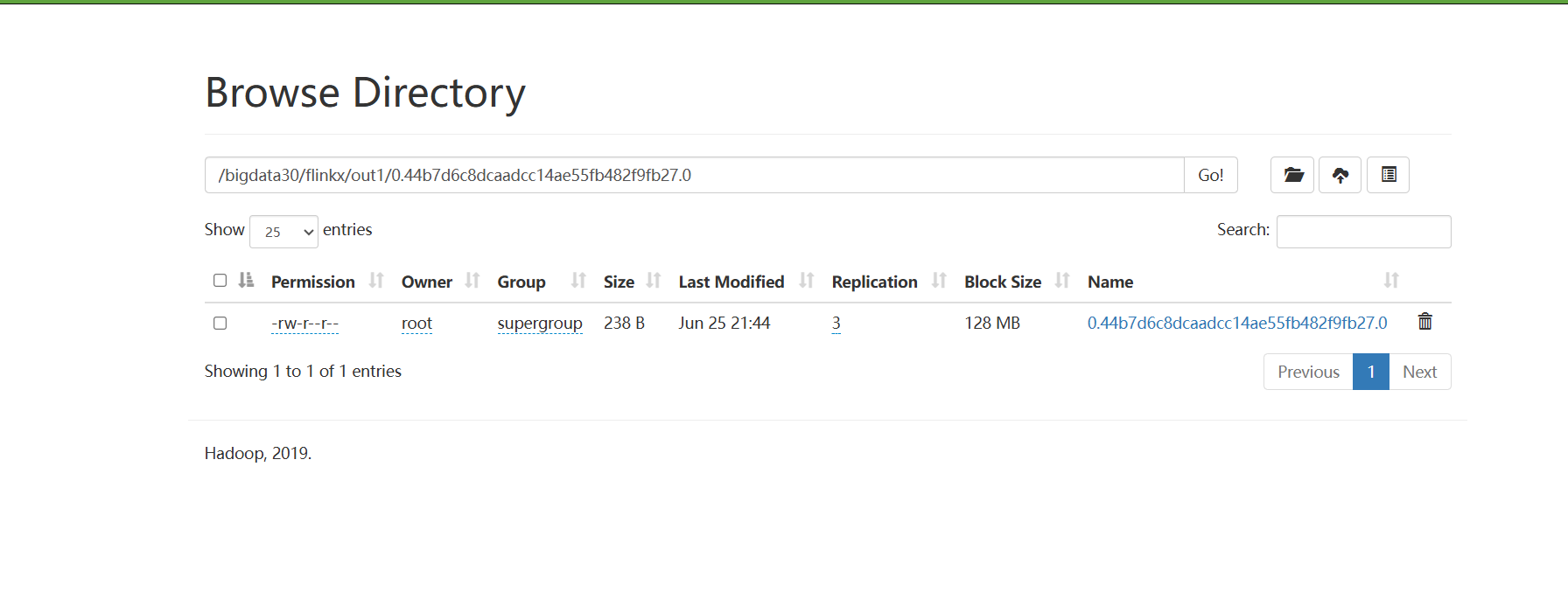
查看该文件:
hdfs dfs -cat /bigdata30/flinkx/out1/0.44b7d6c8dcaadcc14ae55fb482f9fb27.0
出现Sid大于05的学生:

MySQLToHive
hivewrite:(https://github.com/oceanos/flinkx/blob/1.8_release/docs/hivewriter.md)
配置文件:
{"job": {"content": [{"reader": {"parameter": {"username": "root","password": "123456","connection": [{"jdbcUrl": ["jdbc:mysql://master:3306/Y1?useUnicode=true&characterEncoding=utf8&useSSL=false"],"table": ["Student"]}],"column": ["*"],"where": "Sid > 05 ","requestAccumulatorInterval": 2},"name": "mysqlreader"},"writer": {"name": "hivewriter","parameter": {"jdbcUrl": "jdbc:hive2://master:10000/bigdata30","username": "","password": "","fileType": "text","fieldDelimiter": ",","writeMode": "overwrite","compress": "","charsetName": "UTF-8","maxFileSize": 1073741824,"tablesColumn": "{\"Student\":[{\"key\":\"SId\",\"type\":\"string\"},{\"key\":\"Sname\",\"type\":\"string\"},{\"key\":\"Sage\",\"type\":\"string\"},{\"key\":\"Ssex\",\"type\":\"string\"}]}","defaultFS": "hdfs://master:9000"}}}],"setting": {"restore": {"isRestore": false,"isStream": false},"errorLimit": {},"speed": {"channel": 1}}}
}
在hive中建表:
CREATE TABLE `bigdata30`.`Student`(`SId` STRING,`Sname` STRING,`Sage` STRING,`Ssex` STRING)
PARTITIONED BY ( `pt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
启动hiveserver2
启动任务
flinkx -mode local -job ./mysql2hive.json -pluginRoot /usr/local/soft/flinkx-1.10/syncplugins/ -flinkconf /usr/local/soft/flinkx-1.10/flinkconf/
运行发现报错 无法解决。
翻阅chunjun官网 在hive-sink中发现 只支持hive1.x hive2.x 现hive版本为3.1.2 不支持 猜测报错原因
尝试使用chunjun 解决
MySQLToHBase
场景
将mysql Y1数据库中的Student表数据写入HBase flinkx_Student表中
配置文件
{"job": {"content": [{"reader": {"parameter": {"username": "root","password": "123456","connection": [{"jdbcUrl": ["jdbc:mysql://master:3306/Y1?useUnicode=true&characterEncoding=utf8&useSSL=false"],"table": ["Student"]}],"column": ["*"],"where": "Sid > 05 ","requestAccumulatorInterval": 2},"name": "mysqlreader"},"writer": {"name": "hbasewriter","parameter": {"hbaseConfig": {"hbase.zookeeper.property.clientPort": "2181","hbase.rootdir": "hdfs://master:9000/hbase","hbase.cluster.distributed": "true","hbase.zookeeper.quorum": "master,node1,node2","zookeeper.znode.parent": "/hbase"},"table": "flinkx_Student","rowkeyColumn": "$(cf1:SId)","column": [{"name": "cf1:SId","type": "string"},{"name": "cf1:Sname","type": "string"},{"name": "cf1:Sage","type": "string"},{"name": "cf1:Ssex","type": "string"}]}}}],"setting": {"restore": {"isRestore": false,"isStream": false},"errorLimit": {},"speed": {"channel": 1}}}
}
在hbase中创建flinkx_Student表
create 'flinkx_Student','cf1'
启动
flinkx -mode local -job ./mysql2hbase.json -pluginRoot /usr/local/soft/flinkx-1.10/syncplugins/ -flinkconf /usr/local/soft/flinkx-1.10/flinkconf/
hbase中的flinkx_Student表出现数据
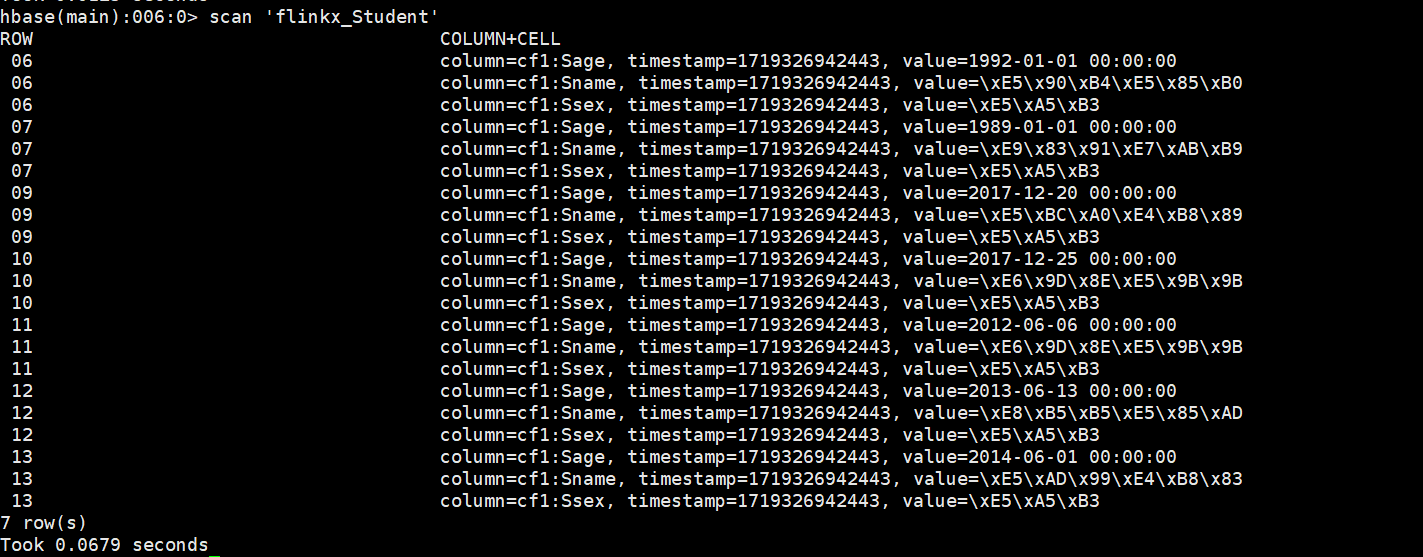
MySQLToMySQL
场景
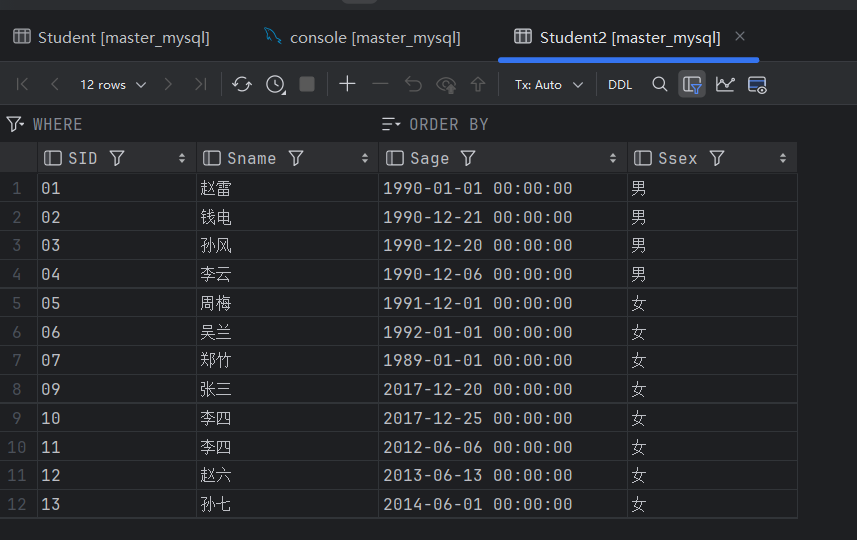
将mysql Y1数据库中的Student表数据写入datax1数据库中的Student2表中
配置文件 mysql2mysql.json
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": [{"name": "SId","type": "string"},{"name": "Sname","type": "string"},{"name": "Sage","type": "string"},{"name": "Ssex","type": "string"}],"username": "root","password": "123456","connection": [{"jdbcUrl": ["jdbc:mysql://master:3306/Y1?useSSL=false"],"table": ["Student"]}]}},"writer": {"name": "mysqlwriter","parameter": {"username": "root","password": "123456","connection": [{"jdbcUrl": "jdbc:mysql://master:3306/datax1?useSSL=false","table": ["Student2"]}],"writeMode": "insert","column": [{"name": "SId","type": "string"},{"name": "Sname","type": "string"},{"name": "Sage","type": "string"},{"name": "Ssex","type": "string"}]}}}],"setting": {"speed": {"channel": 1,"bytes": 0}}}}
在mysql datax1数据库中建表:
create table if not exists datax1.Student2(SID varchar(10),Sname varchar(100),Sage varchar(100),Ssex varchar(10)
)CHARSET = utf8 COLLATE utf8_general_ci;
运行:
flinkx -mode local -job ./mysql2mysql.json -pluginRoot /usr/local/soft/flinkx-1.10/syncplugins/ -flinkconf /usr/local/soft/flinkx-1.10/flinkconf/
进入网页查看:
master:8888
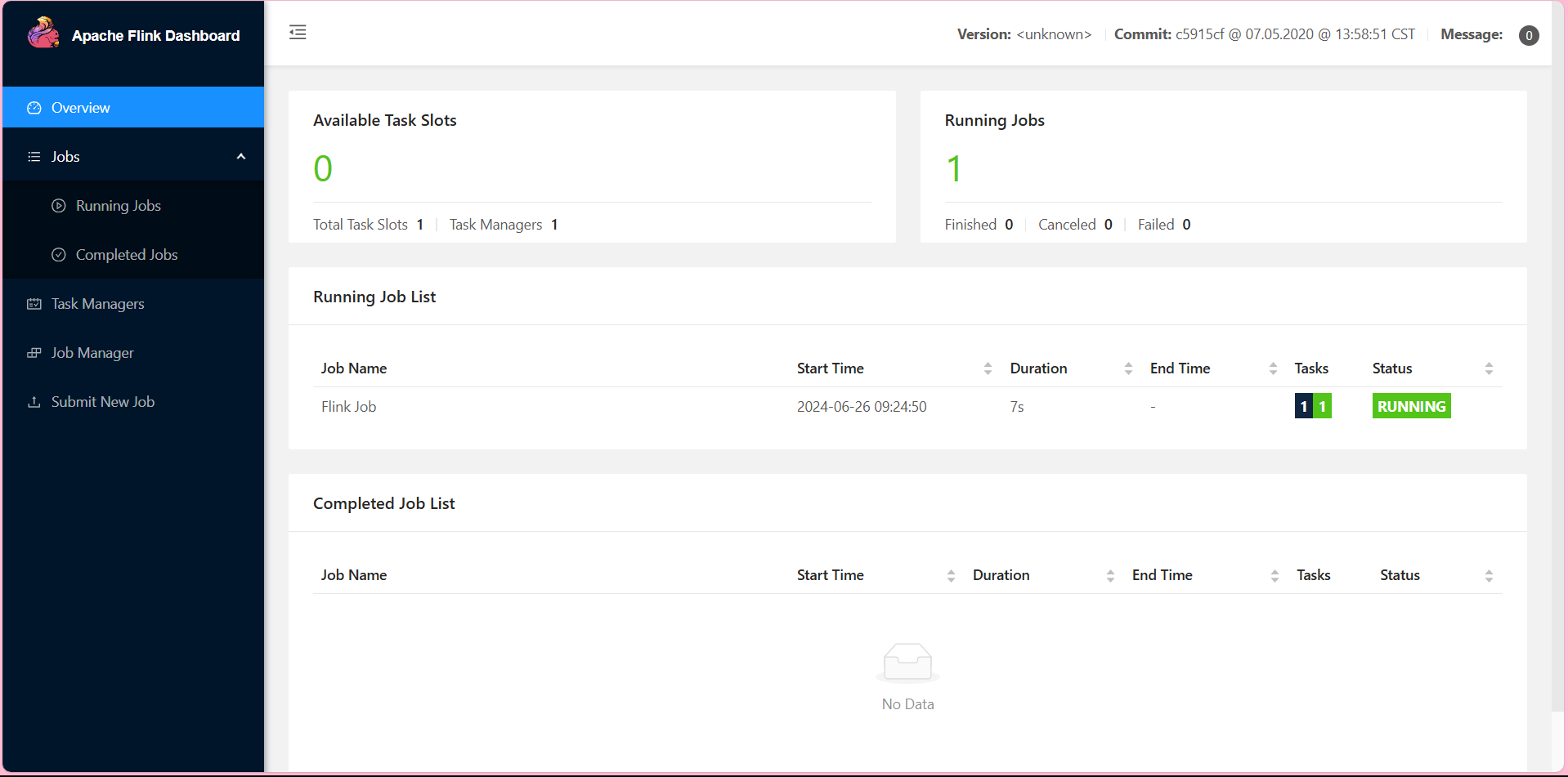
查看Student2表 数据已导入:



)


