JUC
Future接口理论知识复习
Future接口(FutureTask实现类)定义了操作异步任务执行一些方法,如获取异步任务的执行结果、取消任务的执行、判断任务是否被取消、判断任务执行是否完毕等
比如主线程让一个子线程去执行任务,子线程可能比较耗时,启动子线程开始执行任务后,主线程就去做其他事情了,忙其它事情或者先执行完,过了一会才去获取子任务的执行结果或变更的任务状态。
一句话:Future接口可以为主线程开一个分支任务,专门为主线程处理耗时和费力的复杂业务
Future接口能干什么
Future是Java5新加的一个接口,它提供了一种异步并行计算的功能。
如果主线程需要执行一个很耗时的计算任务,我们就可以通过future把这个任务放到异步线程中执行。
主线程继续处理其他任务或者先行结束,再通过Future获取计算结果。
代码说话:
Runnable接口
Callable接口
Future接口和FutureTask实现类
目的:异步多线程任务执行且返回有结果,三个特点:多线程/有返回/异步任务(班长为老师去买水作为新启动的异步多线程任务且买到水有结果返回)
本源的Future接口相关架构

Future编码实战和优缺点分析
优点:Future+线程池异步多线程任务配置,能显著提高程序的执行效率
上述案例case
package com.juc.cf;import java.util.concurrent.*;public class FutureThreadPoolDemo {public static void main(String[] args) throws ExecutionException, InterruptedException {ExecutorService threadPool = Executors.newFixedThreadPool(3);long startTime = System.currentTimeMillis();FutureTask<String> futureTask1 = new FutureTask<String>(() -> {TimeUnit.MICROSECONDS.sleep(500);return "task1 over";});threadPool.submit(futureTask1);FutureTask<String> futureTask2 = new FutureTask<String>(() -> {TimeUnit.MICROSECONDS.sleep(300);return "task2 over";});threadPool.submit(futureTask2);// 加上下面这两个获取异步线程的结果,会比不获取结果要耗时一点但是也比完全同步执行耗时强很多System.out.println(futureTask1.get());System.out.println(futureTask2.get());FutureTask<String> futureTask3 = new FutureTask<String>(() -> {TimeUnit.MICROSECONDS.sleep(300);return "task3 over";});threadPool.submit(futureTask3);long endTime = System.currentTimeMillis();System.out.println("-------costTime: " + (endTime - startTime) + "毫秒");threadPool.shutdown();}
}
缺点:
get()阻塞:
一旦调用get()方法求结果,如果计算没有完成容易导致程序阻塞,他会一直等待异步结果的返回。所以在get()方法里面我们一般会设置等待超时时间。到了指定时间还未获取到结果,直接抛出 java.util.concurrent.TimeoutExce ption。
isDone()轮询:
轮询的方式会耗费无谓的CPU资源,而且也不见得能及时地得到计算结果
如果想要异步获取结果,通常都会以轮询的方式去获取结果尽量不要阻塞
public static void FutureDone() throws ExecutionException, InterruptedException {ExecutorService threadPool = Executors.newFixedThreadPool(3);FutureTask<String> futureTask = new FutureTask<String>(() -> {TimeUnit.SECONDS.sleep(5);return "task over";});threadPool.submit(futureTask);System.out.println("-----执行其他任务");while (true) {if (futureTask.isDone()) {System.out.println(futureTask.get());break;} else {TimeUnit.MILLISECONDS.sleep(500);System.out.println("异步线程暂未执行完毕");}}threadPool.shutdown();}public static void FutureBlock() throws InterruptedException, ExecutionException, TimeoutException {ExecutorService threadPool = Executors.newFixedThreadPool(3);FutureTask<String> futureTask = new FutureTask<String>(() -> {TimeUnit.SECONDS.sleep(5);return "task over";});threadPool.submit(futureTask);System.out.println("-----执行其他任务");futureTask.get(3, TimeUnit.SECONDS);threadPool.shutdown();}
结论
Future对于结果的获取不是很友好,只能通过阻塞或轮询的方式得到任务的结果。
对于想完成一些复杂的业务
对于简单的业务场景使用Future完全OK
回到通知:对应Future的完成时间,完成了可以告诉我,也就是我们的回调通知,通过轮询的方式去判断任务是否完成这样非常占用CPU并且代码也不优雅
创建异步任务:Future+线程池配合
多个任务前后依赖可以组合处理:
-
想要将多个异步任务的计算结果组合起来,后一个异步任务的计算结果需要前一个异步任务的值。
-
将两个或多个异步计算合成一个异步计算,这几个异步计算互相独立,同时后面这个又依赖前一个处理的结果。
使用Future之前提供的那点API就囊中羞涩,处理起来不够优雅,这时候还是让CompletableFuture声明式的方式优雅的处理这些需求
Future能干的,CompletableFuture都能干
CompletableFuture
为什么出现
get()方法在Future 计算完成之前会一直处在阻塞状态下,
isDone()方法容易耗费CPU资源,
对于真正的异步处理我们希望是可以通过传入回调函数,在Future结束时自动调用该回调函数,这样,我们就不用等待结果。
阻塞的方式和异步编程的设计理念相违背,而轮询的方式会耗费无谓的CPU资源。因此,JDK8设计出CompletableFuture。
CompletableFuture提供了一种观察者模式类似的机制,可以让任务执行完成后通知监听的一方。
CompletableFuture和CompletionStage源码介绍
架构说明

接口CompletionStage

代表异步计算过程中的某一个阶段,一个阶段完成以后可能会触发另外一个阶段,有些类似Linux系统的管道分隔符传参数。
类CompletableFuture

核心的四个静态方法,来创建一个异步任务
runAsync 无返回值
public static CompletableFuture runAsync(Runnable runnable)
public static CompletableFuture runAsync(Runnable runnable, Executor executor)
supplyAsync 有返回值
public static CompletableFuture supplyAsync(Supplier supplier)
public static CompletableFuture supplyAsync(Supplier supplier, Executor executor
上述Executor executor参数说明
没有指定Executor的方法,直接使用默认的ForkJoinPool.commonPool()作为它的线程池执行异步代码。
如果指定线程池,则使用我们自定义的或者特别指定的线程池执行异步代码
代码展示:
package com.juc.cf;import java.util.concurrent.*;public class CompletableFutureDemo {public static void main(String[] args) throws ExecutionException, InterruptedException {runAsyncNoExecutor();runAsync();supplyAsyncNoExecutor();supplyAsync();}public static void supplyAsync() throws ExecutionException, InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(3);CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {// pool-1-thread-1System.out.println(Thread.currentThread().getName());try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}return "hello supplyAsyncNoExecutor";}, executorService);// hello supplyAsyncNoExecutorSystem.out.println(completableFuture.get());executorService.shutdown();}public static void supplyAsyncNoExecutor() throws ExecutionException, InterruptedException {CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {// ForkJoinPool.commonPool-worker-1System.out.println(Thread.currentThread().getName());try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}return "hello supplyAsyncNoExecutor";});// hello supplyAsyncNoExecutorSystem.out.println(completableFuture.get());}public static void runAsync() throws ExecutionException, InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(3);CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {// pool-1-thread-1System.out.println(Thread.currentThread().getName());try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}, executorService);// nullSystem.out.println(completableFuture.get());executorService.shutdown();}public static void runAsyncNoExecutor() throws ExecutionException, InterruptedException {CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {// ForkJoinPool.commonPool-worker-1System.out.println(Thread.currentThread().getName());try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}});// nullSystem.out.println(completableFuture.get());}
}
code之通用演示,减少阻塞和轮询
从Java8开始引入了CompletableFuture,它是Future的功能增强版,减少阻塞和轮询,可以传入回调对象,当异步任务完成或者发生异常时,自动调用回调对象的回调方法
public static void supplyAsync1() {ExecutorService executorService = Executors.newFixedThreadPool(3);CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(() -> {// pool-1-thread-1System.out.println(Thread.currentThread().getName() + "come in");int result = ThreadLocalRandom.current().nextInt(10);try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}return result;}, executorService).whenComplete((v, e) -> {if (null == e) {System.out.println("------计算完成,未发生异常,结果为:" + v);}}).exceptionally(e -> {e.printStackTrace();System.out.println("系统发生异常" + e.getCause() + "\t" + e.getMessage());return null;});System.out.println("main主线程执行自己的其他逻辑");executorService.shutdown();
}
CompletableFuture的优点
- 异步任务结束时,会自动回调某个对象的方法;
- 主线程设置好回调后,不再关心异步任务的执行,异步任务之间可以顺序执行
- 异步任务出错时,会自动回调某个对象的方法
场景
1 需求说明
1.1 同一款产品,同时搜索出同款产品在各大电商平台的售价;
1.2 同一款产品,同时搜索出本产品在同一个电商平台下,各个入驻卖家售价是多少
2 输出返回:
出来结果希望是同款产品的在不同地方的价格清单列表,返回一个List
《mysql》in jd price is 88.05
《mysql》in dangdang price is 86.11
《mysql》in taobao price is 90.43
3 解决方案,比对同一个商品在各个平台上的价格,要求获得一个清单列表,
1 step by step,按部就班,查完京东查淘宝,查完淘宝查天猫…
2 all in,万箭齐发,一口气多线程异步任务同时查询。。 。 。 。
package com.juc.cf;import java.util.Arrays;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;public class CompletableFutureMallDemo {static List<NetMall> list = Arrays.asList(new NetMall("jd"),new NetMall("dangdang"),new NetMall("taobao"));public static List<String> getPrice(List<NetMall> list, String productName) {return list.stream().map(netMall ->String.format(productName+" in %s price is %.2f",netMall.getNetMallName(),netMall.calcPrice(productName))).collect(Collectors.toList());}public static List<String> getPriceByCompletableFuture(List<NetMall> list, String productName) {return list.stream().map(netMall ->CompletableFuture.supplyAsync(() ->String.format(productName+" in %s price is %.2f",netMall.getNetMallName(),netMall.calcPrice(productName)))).collect(Collectors.toList()).stream().map(s -> s.join()).collect(Collectors.toList());}public static void main(String[] args) {long startTime = System.currentTimeMillis();List<String> list1 = getPrice(list, "mysql");for (String element: list1) {System.out.println(element);}long endTime = System.currentTimeMillis();// 串行编程调用需要耗时3秒以上System.out.println("-----costTime: " + (endTime - startTime) + "毫秒");System.out.println("-------------------");long startTime2 = System.currentTimeMillis();List<String> list2 = getPriceByCompletableFuture(list, "mysql");for (String element: list2) {System.out.println(element);}long endTime2 = System.currentTimeMillis();// 并行编程调用需要耗时仅需要1秒以上System.out.println("-----costTime2: " + (endTime2 - startTime2) + "毫秒");}}class NetMall{private String netMallName;public NetMall(String netMallName) {this.netMallName = netMallName;}public String getNetMallName() {return netMallName;}public double calcPrice(String productName) {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}return ThreadLocalRandom.current().nextDouble() * 2 + productName.charAt(0);}
}
常用方法
1.获得结果和触发计算
获得结果
public T get()
不见不散,一直等到结果才返回,会一直阻塞
public T get(long timeout, TimeUnit unit)
过时不候,在指定的timeout时间范围内可以正常返回,超过timeout时间,会报异常
public T join()
作用和get()方法一致,只是不抛出异常
public T getNow(T valueIfAbsent)
在异步线程计算还未完成的情况下,直接将入参返回,即:
计算完,返回计算完成后的结果;没算完,返回设定的valueIfAbsent值
主动触发计算
public boolean complete(T value)
是否打断get方法立即返回括号中的值,返回true表示打断了获取异步线程结果的操作,直接返回value值
2.对计算结果进行处理
public CompletableFuture thenApply(Function<? super T,? extends U> fn)
计算结果存在依赖关系,将这两个线程串行化

**异常相关:**由于存在依赖关系(当前步错,不走下一步),当前步骤有异常的话就叫停。
public CompletableFuture handle(BiFunction<? super T, Throwable, ? extends U> fn)
计算结果存在依赖关系,将这两个线程串行化

**异常相关:**有异常也可以往下一步走,根据带的异常参数可以进一步处理
总结:
3.对计算结果进行消费
接收任务的处理结果,并消费处理,无返回结果
public CompletableFuture thenAccept(Consumer<? super T> action)
对比补充:Code之任务之间的顺序执行
- thenRun(Runnable runnable):任务A执行完执行B,并且B不需要A的结果无返回值
- thenAccept(Consumer<? super T> action):任务A执行完执行B,B需要A的结果,但是任务B无返回值
- thenApply(Function<? super T,? extends U> fn):任务A执行完执行B,B需要A的结果,同时任务B有返回值
CompletableFuture和线程池说明
- 没有传入自定义线程池,都用默认线程池ForkJoinPoal;
- 传入了一个自定义线程池,如果你执行第一个任务的时候,传入了一个自定义线程池:
调用thenRun方法执行第二个任务时,则第二个任务和第一个任务是共用同一个线程池。
调用thenRunAsync执行第二个任务时,则第一个任务使用的是你自己传入的线程池,第二个任务使用的是ForkJoin线程池 - 备注
有可能处理太快,系统优化切换原则,直接使用main线程处理
其它如: thenAccept和thenAcceptAsync,thenApply和thenApplyAsync等,它们之间的区别也是同理
4.对计算速度进行选用
谁快用谁 applyToEither
public CompletableFuture applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn)

5.对计算结果进行合并
两个completionStage任务都完成后,最终能把两个任务的结果一起交给thenCombine来处理
先完成的先等着,等待其他分支任务
public <U,V> CompletableFuture thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)

锁
悲观锁
认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。
synchronized关键字和Lock的实现类都是悲观锁
适合写操作多的场景,先加锁可以保证写操作时数据正确。显式的锁定之后再操作同步资源
一句话:狼性锁
乐观锁
认为自己在使用数据时不会有别的线程修改数据或资源,所以不会添加锁。
在Java中是通过使用无锁编程来实现,只是在更新数据的时候去判断,之前有没有别的线程更新了这个数据。
如果这个数据没有被更新,当前线程将自己修改的数据成功写入。
如果这个数据已经被其它线程更新,则根据不同的实现方式执行不同的操作,比如放弃修改、重试抢锁等等
判断规则
1 版本号机制Version
2 最常采用的是CAS算法,Java原 子类中的递增操作就通过CAS自旋实现的。
使用场景:
适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
乐观锁则直接去操作同步资源,是一种无锁算法,得之我幸不得我命
一句话:佛系锁
乐观锁一般有两种实现方式:采用Version版本号;CAS(Compare-and-Swap),即比较并交换算法

实例
演示代码
package com.juc.lock;import java.util.concurrent.TimeUnit;/*** 对多线程的理解,8锁案例说明* 1.标准访问ab两个线程,a线程后面休眠200毫秒 -> 执行结果:先打印邮件后打印短信* 2.在sendEmail 发送邮件方法里面休眠500毫秒 -> 执行结果:先打印邮件后打印短信* 3.在Phone类中新增一个无锁的hello方法,将原来的发送短信线程换成hello方法 -> 执行结果:先打印hello后打印邮件* 4.有两个phone对象,两个线程分别调用发短信和邮件 -> 执行结果:先打印短信后打印邮件* 5.将原来电话中的两个锁方法变成静态方法,只创建一个手机对象 -> 执行结果:先打印邮件后打印短信* 6.还是两个静态方法,创建两个手机对象 -> 执行结果:先打印邮件后打印短信* 7.发送邮件还是静态加锁方法,发送短信变成锁方法,只创建一个手机对象 -> 执行结果:先打印短信后打印邮件* 8.发送邮件还是静态加锁方法,发送短信变成锁方法,创建两个个手机对象 -> 执行结果:先打印短信后打印邮件*/
public class lock8Demo {public static void main(String[] args) throws InterruptedException {Phone phone = new Phone();Phone phone2 = new Phone();new Thread(() -> {phone.sendEmail();}, "a").start();TimeUnit.MILLISECONDS.sleep(200);new Thread(() -> {phone2.sendSMS();// phone.sendSMS();// phone2.sendSMS();// phone.sendSMS();// phone2.sendSMS();// phone.hello();}, "b").start();}
}class Phone {public static synchronized void sendEmail() {try {TimeUnit.MILLISECONDS.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("----- sendEmail");}public synchronized void sendSMS() {System.out.println("----- sendSMS");}public void hello() {System.out.println("----- hello");}
}
总结:
1.标准访问ab两个线程,a线程后面休眠200毫秒 -> 执行结果:先打印邮件后打印短信
2.在sendEmail 发送邮件信方法里面休眠500毫秒(同一个phone对象) -> 执行结果:先打印邮件后打印短信
一个对象里面如果有多个synchronized方法,某一个时刻内,只要一个线程去调用其中的一个synchronized方法了,其它的线程都只能等待,换句话说,某一个时刻内,只能有唯一的一个线程去访向这些synchronized方法
锁的是当前对象this,被锁定后,其它的线程都不能进入到当前对象的其它的synchronized方法
3.在Phone类中新增一个无锁的hello方法,将原来的发送短信线程缓存hello方法 -> 执行结果:先打印hello后打印邮件
4.有两个phone对象,两个线程分别调用发短信和邮件 -> 执行结果:先打印短信后打印邮件
加个普通方法后发现和同步锁无关
换成两个对象后,不是同一把锁了,情况立刻变化。
5.将原来电话中的两个锁方法变成静态方法,只创建一个手机对象 -> 执行结果:先打印邮件后打印短信
6.还是两个静态方法,创建两个手机对象 -> 执行结果:先打印邮件后打印短信
都换成静态同步方法后,情况又变化了,三种 synchronized锁的内容有一些差别:
对于普通同步方法,锁的是当前实例对象,通常指this,具体的一部部手机,所有的普通同步方法用的都是同一把锁—>实例对象本身
对于静态同步方法,锁的是当前类的Class对象,如Phone.cLass唯一的一个模板
对于同步方法块,锁的是synchronized括号内的对象
synchronized(o) {}
7.发送邮件还是静态加锁方法,发送短信变成锁方法,只创建一个手机对象 -> 执行结果:先打印短信后打印邮件
8.发送邮件还是静态加锁方法,发送短信变成锁方法,创建两个个手机对象 -> 执行结果:先打印短信后打印邮件
当一个线程试图访问同步代码时它首先必须得到锁,正常退出或抛出异常时必须释放锁。
所有的普通同步方法用的都是同一把锁—实例对象本身,就是new出来的具体实例对象本身,本类this,也就是说如果一个实例对象的普通同步方法获取锁后,该实例对象的其他普通同步方法必须等待获取锁的方法释放锁后才能获取锁。
所有的静态同步方法用的也是同一把锁,即类对象本身,就是我们说过的唯一模板Class
具体实例对象this和唯一模板Class,这两把锁是两个不同的对象,所以静态同步方法与普通同步方法之间是不会有竞态条件的但是一旦一个静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取锁。
synchronized有三种应用方式
作用于实例方法,当前实例加锁,进入同步代码前要获得当前实例的锁;
作用于代码块,对括号里配置的对象加锁;
作用于静态方法,当前类加锁,进去同步代码前要获得当前类对象的锁。
synchronized源码分析
javap -c ***.class 文件反编译
-c 对代码进行反汇编
如果需要获取更多的信息:
javap -v ***.class文件反编译 -> -v 指的是verbose 输出附加信息(包括行号、本地变量表、反汇编等详细信息)
synchronized同步代码块
package com.juc.lock;public class LockSyncDemo {private final Object object = new Object();public void m1() {synchronized (object) {System.out.println("---------hello synchronized code block---------");}}public static void main(String[] args) {}
}
运行上面的main方法,生成class文件,进入对应class文件,执行反编译命令,javap -c ***.class

synchronized同步代码块,实现使用的是monitorenter和monitorexit指令
一定是一个enter两个exit吗?一般情况是1个enter对应2个exit,极端情况下,在synchronized里面手动抛异常

synchronized普通同步方法(对象锁)
反编译文件

调用指令将会检查方法的ACC_SYNCHRONIZED访问标志是否被设置。如果设置了,执行线程会将先持有monitor锁,然后再执行方法,最后在方法完成(无论是正常完成还是非正常完成)时释放 monitor
synchronized静态同步方法(类锁)
javap -v ***.class文件反编译

ACC_STATIC,ACC_SYNCHRONIZED访问标志区分该方法是否静态同步方法
面试题:为什么任何一个对象都可以成为一个锁
什么是管程monitor
管程(英语:Monitors,也称为监视器)是一种程序结构,结构内的多个子程序(对象或模块)形成的多个工作线程互斥访问共享资源。
这些共享资源一般是硬件设备或一群变量。对共享变量能够进行的所有操作集中在一个模块中。(把信号量及其操作原语“封装”在一个对象内部)管程实现了在一个时间点,最多只有一个线程在执行管程的某个子程序。管程提供了一种机制,管程可以看做一个软件模块,它是将共享的变量和对于这些共享变量的操作封装起来,形成一个具有一定接口的功能模块,进程可以调用管程来实现进程级别的并发控制。

在HotSpot虚拟机中,monitor采用ObjectMonitor实现
ObjectMonitor.java 一> ObjectMonitor.cpp 一> objectMonitor.hpp
ObjectMonitor.hpp,每个对象天生都带着一个对象监视器,每一个被锁住的对象都会和Monitor关联起来
ReentrantLock演示公平锁和非公平锁
从ReentrantLock卖票demo演示公平和非公平
package com.juc.lock.ReentrantLock;import java.util.concurrent.locks.ReentrantLock;public class SaleTickDemo {public static void main(String[] args) {Ticket ticket = new Ticket();new Thread(() -> {for (int i = 0; i < 55; i++) ticket.sale();}, "a").start();new Thread(() -> {for (int i = 0; i < 55; i++) ticket.sale();}, "b").start();new Thread(() -> {for (int i = 0; i < 55; i++) ticket.sale();}, "c").start();}
}class Ticket {// 资源类,模拟3个售票员卖完50张票private int number = 50;ReentrantLock lock = new ReentrantLock();public void sale() {lock.lock();try {if (number > 0) {System.out.println(Thread.currentThread().getName() + "卖出第:\t" + number-- + "\t还剩下:" + number);}} finally {lock.unlock();}}
}
| 公平锁 | 是指多个线程按照申请锁的顺序来获取锁,这里类似排队买票,先来的人先买后来的人在队尾排着,这是公平的 Lock lock = new ReentrantLock(true);//true表示公平锁,先来先得 |
|---|---|
| 非公平锁 | 是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,在高并发环境下,有可能造成优先级翻转或者饥饿的状态(某个线程一直得不到锁) Lock lock =new ReentrantLock(false);//false表示非公平锁,后来的也可能先获得锁 Lock lock=new ReentrantLock();//默认非公平锁 |
何为公平锁/非公平锁
为什么会有公平锁/非公平锁的设计?为什么默认非公平锁
- 恢复挂起的线程到真正锁的获取还是有时间差的,从开发人员来看这个时间微乎其微,但是从CPU的角度来看,这个时间差存在的还是很明显的。所以非公平锁能更充分的利用CPU的时间片,尽量减少CPU空闲状态时间。
- 使用多线程很重要的考量点是线程切换的开销,当采用非公平锁时,当1个线程请求锁获取同步状态,然后释放同步状态,所以刚释放锁的线程在此刻再次获取同步状态的概率就变得非常大,所以就减少了线程的开销。
什么时候用公平,什么时候用非公平
如果为了更高的吞吐量,很显然非公平锁是比较合适的,因为节省很多线程切换时间,吞吐量白然就上去了;否则那就用公平锁,大家公平使用。
可重入锁
可重入锁又名递归锁
是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提,锁对象得是同一个对象),不会因为之前已经获取过还没释放而阻塞。
如果是1个有synchronized修饰的递归调用方法,程序第2次进入被自己阻塞了岂不是天大的笑话,出现了作茧自缚。
所以Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。
可:可以
重:再次
入:进入
锁:同步锁
进入什么:进入同步域(即同步代码块/方法或显示锁锁定的代码)
一句话:一个线程中的多个流程可以获取同一把锁,持有这把同步锁可以再次进入。自己可以获取自己的内部锁
可重入锁种类
隐式锁(即synchronized关键字使用的锁)默认是可重入锁
指的是可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不发生死锁,这样的锁就叫做可重入锁。
简单的来说就是:在一个synchronized修饰的方法或代码块的内部调用本类的其他synchronized修饰的方法或代码块时,是永远可以得到锁的
synchronized的重入实现机理
每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
当执行monitorenter时,如果目标锁对象的计数器为零,那么说明它没有被其他线程所持有,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。
在目标锁对象的计数器不为零的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其计数器加1,否则需要等待,直至持有线程释放该锁。
当执行monitorexit时,Java虚拟机则需将锁对象的计数器减1。计数器为零代表锁已被释放。
显示锁(即Lock)也有ReentrantLock这样的可重入锁

死锁
死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力干涉那它们都将无法推进下去,如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。

死锁产生的主要原因
系统资源不足
进程运行推进的顺序不合适
资源分配不当
如何排查死锁
纯命令:jps -l 查出程序进程号,jstack 进程编号
图形化:jconsole
线程中断

如何中断一个运行中的线程?
如何停止一个运行中的线程?
什么是中断机制
首先
一个线程不应该由其他线程来强制中断或停止,而是应该由线程自己自行停止,自己来决定自己的命运。所以,Thread.stop,Thread.suspend,Thread.resume 都已经被废弃了。
其次
在Java中没有办法立即停止一条线程,然而停止线程却显得尤为重要,如取消一个耗时操作。因此,Java提供了一种用于停止线程的协商机制一一中断,也即中断标识协商机制。
中断只是一种协作协商机制,Java没有给中断增加任何语法,中断的过程完全需要程序员自己实现。
若要中断一个线程,你需要手动调用该线程的interrupt方法,该方法也仅仅是将线程对象的中断标识设成true;接着你需要自己写代码不断地检测当前线程的标识位,如果为true,表示别的线程请求这条线程中断,此时究竟该做什么需要你自己写代码实现。
每个线程对象中都有一个中断标识位,用于表示线程是否被中断,该标识位为tue表示中断,为false表示未中断;通过调用线程对象的interrupt方法将该线程的标识位设为tue; 可以在别的线程中调用,也可以在自己的线程中调用。
中断的相关API方法之三大方法说明
| public void interrupt() | 实例方法,just to set the interrupt flag 实例方法interrupt()仅仅是设置线程的中断状态为true,发起一个协商而不会立刻停止线程 |
|---|---|
| public static boolean interrupted() | 静态方法,Thread.interrupted(); 判断线程是否被中断并清楚当前中断状态 这个方法做了两件事: 返回当前线程的中断状态,测试当前线程是否已被中断 将当前线程的中断状态清零并重新设置为false,清除线程的中断状态 |
| public boolean isInterrupted() | 实例方法,判断当前线程是否被中断(通过检查中断标志) |
如何停止中断运行中的线程
-
通过一个volatile变量实现

-
通过AtomicBoolean

-
通过Thread类自带的中断API实例方法实现

在需要中断的线程中不断监听中断状态,一旦发生中断,就执行相应的中断处理业务逻辑stop线程
说明:
具体来说,当对一个线程,调用 interrupt() 时:
-
如果线程处于正常活动状态,那么会将该线程的中断标志设置为 true,仅此而己。
被设置中断标志的线程将继续正常运行,不受影响。
所以, interrupt() 并不能真正的中断线程,需要被调用的线程自己进行配合才行。
-
如果线程处于被阻塞状态(例如处于sleep, wait, jin 等状态),在别的线程中调用当前线程对象的interrupt方法,那么线程将立即退出被阻塞状态,并抛出一个InterruptedException异常。
当前线程的中断标识为true,是不是线程就立刻停止?

sleep方法抛出InterruptedException后,中断标识也被清空置为false,我们在
catch没有通过调用th.interrupt()方法再次将中断标识置为true,这就导致无限循
环了
小总结
中断只是一种写上机制,修改中断标识位仅此而已,不是立刻stop打断
静态方法Thread.interrupted(),谈谈你的理解
说明:

都是返回中断状态,静态方法interrupted和实例方法isInterrupted两者对比:


方法的注释也清晰的表达了“中断状态将会根据传入的Clearinterrupted参数值确定是否重置“。
所以,静态方法interrupted将会清除中断状态(传入的参数Clearlnterrupted为true),实例方法isinterrupted则不会(传入的参数Clearinterrupted为false)。
总结
线程中断相关的方法:
public void interrupt(),interrupt()方法是一个实例方法,它通知目标线程中断,也仅是设置目标线程的中断标志位为true。
public boolean islnterrupted(),islnterrupted()方法也是一个实例方法,它判断当前线程是否被中断(通过检查中断标志位)并获取中断标志
public static boolean interrupted(),Thread类的静态方法interrupted(),返回当前线程的中断状态真实值(boolean类型)后会将当前线程的中断状态设为false,此方法调用之后会清除当前线程的中断标志位的状态(将中断标志置为false了),返回当前值并清零置false
LockSupport是什么


3种让线程等待和唤醒的方法
线程等待和唤醒的方法
- 使用Object中的wait()方法让线程等待,使用Object中的notify()方法唤醒线程
- 使用JUC包中Condition的await()方法让线程等待,使用signal()方法唤醒线程
- LockSupport类可以阻塞当前线程以及唤醒指定被阻塞的线程
Object类中的wait和notify方法实现线程等待和唤醒
正常:wait和notify都包裹在synchronized代码块里面,休眠和唤醒都是正常的
异常1:wait和notify方法,两个都去掉同步代码块,会报异常

异常2:程序先notify后wait,程序无法向后执行,线程无法被唤醒
Condition接口中的await和signal方法实现线程的等待和唤醒
正常:await和signal都在lock锁里面,休眠和唤醒都是正常的
异常1:await和signal方法,两个都去掉加锁解锁方法块,会报异常
异常2:程序先signal后await,程序无法向后执行,线程无法被唤醒
即Condition中的线程等待和唤醒方法,需要先获取锁,一定要先await后signal,一定不能反了
上述两个对象Object和Condition使用的限制条件:线程先要获得并持有锁,必须在锁块(synchronized或lock)中,必须要先等待后唤醒,线程才能够被唤醒
LockSupport类中的park等待和unpark唤醒
是什么
它是通过park()和unpark(thread)方法来实现阻塞和唤醒线程的操作
官网解锁:

LockSupport是用来创建锁和其他同步类的基本线程阻塞原语。
LockSupport类使用了一种名为Permit(许可)的概念来做到阻塞和唤醒线程的功能,每个线程都有一个许可(permit)。
但与Semaphore不同的是,许可的累加上限是1。
主要方法
API:
阻塞:park()/park(Object blocker),阻塞线程/阻塞传入的具体线程
唤醒:unpark(Thread thread),唤醒处于阻塞状态的指定线程。调用unpark(Thread thread)后,就会将thread线程的许可证permit发放,会自动唤醒park线程,即之前阻塞中的LockSupport.park()方法会立即返回。
LockSupport加锁解锁说明
-
正常+无锁块要求
-
之前错误的先唤醒后等待,LockSupport照样支持

-
成双成对要牢记
重点说明
LockSupport是用来创建锁和其他同步类的基本线程阻塞原语。
LockSupport是一个线程阻塞工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,阻塞之后也有对应的唤醒方法。归根结底,LockSupport调用的Unsafe中的native代码。
LockSupport 提供park()和unpark()方法实现阻塞线程和解除线程阻塞的过程
LockSupport和每个使用它的线程都有一个许可(permit)关联。
每个线程都有一个相关的permit,permit最多只有一个,重复调用unpark也不会积累凭证。
形象的理解
线程阻塞需要消耗凭证(permit),这个凭证最多只有1个。
当调用 park方法时
*如果有凭证,则会直接消耗掉这个凭证然后正常退出;
*如果无凭证,就必须阻塞等待凭证可用;
而unpark则相反,它会增加一个凭证,但凭证最多只能有1个,累加无效。
面试总结
为什么可以突破wait/notify的原有调用顺序?
因为unpark获得了一个凭证,之后再调用park方法,就可以名正言顺的凭证消费,故不会阻塞。
先发放了凭证后续可以畅通无阻。
为什么唤醒两次后阻塞两次,但最终结果还会阻塞线程?
因为凭证的数量最多为1,连续调用两次unpark和调用一次unpark效果一样,只会增加一个凭证;
而调用两次park却需要消费两个凭证,证不够,不能放行。
计算机硬件存储体系

推导出我们需要知道JMM
因为有这么多级的缓存(cpu和物理主内存的速度不一致的),
CPU的运行并不是直接操作内存而是先把内存里边的数据读到缓存,而内存的读和写操作的时候就会造成不一致的问题

JVM规范中试图定义一种Java内存模型(Java Memory Model,简称JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。
所以,推导出我们需要知道JMM
Java内存模型 Java Memory Model
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在它仅仅描述的是一组约定或规范,通过这组规范定义了程序中(尤其是多线程)各个变量的读写访问方式并决定一个线程对共享变量的写入何时以及如何变成对另一个线程可见,关键技术点都是围绕多线程的原子性、可见性和有序性展开的。
原则:
JMM的关键技术点都是围绕多线程的原子性、可见性和有序性展开的
能干嘛?
1通过JMM来实现线程和主内存之间的抽象关系。
2屏蔽各个硬件平台和操作系统的内存访问差异以实现让Java程序在各种平台下都能达到一致的内存访问效果。
可见性
是指当一个线程修改了某一个共享变量的值,其他线程是否能够立即知道该变更,JMM规定了所有的变量都存储在主内存中。

系统主内存共享变量数据修改被写入的时机是不确定的,多线程并发下很可能出现“脏读”,所以每个线程都有自己的工作内存,线程自己的工作内存中保存了该线程使用到的变量的 。线程对变量的所有操作(读取,赋值等)都必需在线程自己的工作内存中进行,而不能够直接读写主内存中的变量。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成

线程脏读
- 主内存中有变量x,初始值为0
- 线程A要将x加1,先将x=0拷贝到自己的私有内存中,然后更新x的值
- 线程A将更新后的x值回刷到主内存的时间是不固定的
- 刚好在线程A没有回刷x到主内存时,线程B同样从主内存中读取x,此时为0,和线程A一样的操作,最后期盼的x=2就会变成x=1
原子性
指一个操作是不可打断的,即多线程环境下,操作不能被其他线程干扰
有序性
是什么
对于一个线程的执行代码而言,我们总是习惯性认为代码的执行总是从上到下,有序执行。但为了提升性能,编译器和处理器通常会对指令序列进行重新排序。Java规范规定JVM线程内部维持顺序化语义,即只要程序的最终结果与它顺序化执行的结果相等,那么指令的执行顺序可以与代码顺序不一致,此过程叫指令的重排序。
优缺点
JVM能根据处理器特性(CPU多级缓存系统、多核处理器等)适当的对机器指令进行重排序,使机器指令能更符合CPU的执行特性,最大限度的发挥机器性能。但是,指令重排可以保证串行语义一致,但没有义务保证多线程间的语义也一致(即可能产生“脏读”),简单说,两行以上不相干的代码在执行的时候有可能先执行的不是第一条,不见得是从上到下顺序执行,执行顺序会被优化。
从源码到最终执行示例图:

单线程环境里面确保程序最终执行结果和代码顺序执行的结果一致。
处理器在进行重排序时必须要考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
总结
我们定义的所有共享变量都储存在物理主内存中
每个线程都有自己独立的工作内存,里面保存该线程使用到的变量的副本(主内存中该变量的一份拷贝)
线程对共享变量所有的操作都必须先在线程自己的工作内存中进行后写回主内存,不能直接从主内存中读写(不能越级)
不同线程之间也无法直接访问其他线程的工作内存中的变量,线程间变量值的传递需要通过主内存来进行(同级不能相互访问)
在JMM中,如果一个操作执行的结果需要对另一个操作有可见性或者代码重排序,那么这两个操作之间必须存在happens-before(先行发生)原则。即逻辑上的先后关系
现行发生原则说明
如果Java内存模型中所有的有序性都仅靠volatile和synchronized来完成,那么有很多操作都将会变得非常啰嗦,但是我们在编写Java并发代码的时候并没有察觉到这一点。
我们没有时时、处处、次次,添加volatile和synchronized来完成程序,这是因为Java语言中JMM原则下有一个“先行发生”(Happens-Before)的原则限制和规矩,给你立好了规矩!
这个原则非常重要:
它是判断数据是否存在竞争,线程是否安全的非常有用的手段。依赖这个原则,我们可以通过几条简单规则一揽子解决并发环境下两个操作之间是否可能存在冲突的所有问题,而不需要陷入Java内存模型苦涩难懂的底层编译原理之中。
Happens-Before总原则
如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
happens-before之8条
-
次序规则:
一个线程内,按照代码顺序,写在前面的操作先行发生于写在后面的操作。
-
锁定规则:
一个unLock操作先行发生于后面((这里的“后面”是指时间上的先后))对同一个锁的lock操作;(前面的锁必须解锁了,后面才能继续加锁)。
-
volatile变量规则:
对一个volatile变量的写操作先行发生于后面对这个变量的读操作,前面的写对后面的读是可见的,这里的“后面”同样是指时间上的先后。
-
传递规则:
如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C 。
-
线程启动规则(Thread Start Rule):
Thread对象的start()方法先行发生于此线程的每一个动作
-
线程中断规则(Thread Interruption Rule):
对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
可以通过Thread interrupted()检测到是否发生中断;
也就是说你要先调用interrupt()方法设置过中断标志位,我才能检测到中断发送
-
线程终止规则(Thread Termination Rule):
线程中的所有操作都先行发生于对此线程的终止检则,我们可以通过isAlive()等手段检测线程是否已经终止执行。
-
对象终结规则(Finalizer Rule):
一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始,即对象没有完成初始化之前,是不能调用finalized()方法的
happens-before小总结
在Java语言里面,Happens-Before 的语义本质上是一种可见性
A Happens-Before B意味着A发生过的事情对B来说是可见的,无论A事件和B事件是否发生在同一个线程里。
JMM的设计分为两部分:
一部分是面向我们程序员提供的,也就是happens-before规则,它通俗易懂的向我们程序员阐述了一个强内存模型,我们只要理解happens-before规则,就可以编写并发安全的程序了。
另一部分是针对JVM实现的,为了尽可能少的对编译器和处理器做约束从而提高性能,JMM在不影响程序执行结果的前提下对其不做要求,即允许优化重排序。我们只需要关注前者就好了,也就是理解happens-before规则即可,其它繁杂的内容有JMM规范结合操作系统给我们搞定,我们只写好代码即可。

Volatile
特点
-
可见性
写完后立即刷新回主内存并及时发出通知,大家可以去主内存拿最新版,前面的修改对后面的线程可见
-
有序性:有时禁止指令重排
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段,有时候会改变程序语句的先后顺序;
不存在数据依赖关系,可以重排序;
存在数据依赖关系,禁止重排序。但重排后的指令绝对不能改变原有的串行语义!这点在并发设计中必须要重点考虑!
-
不支持原子性
volatile的内存语义
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值立即刷新回主内存中。
当读一个volatile变量时,JMM会把该线程对应的本地内存设置为无效,重新回到主内存中读取最新共享变量。
所以volatile的写内存语义是直接刷新到主内存中,读的内存语义是直接从主内存中读取。
volatile凭什么可以保证可见性和有序性?
内存屏障Memory Barrier
内存屏障是什么
内存屏障(也称内存栅栏,屏障指令等,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作),避免代码重排序。内存屏障其实就是一种JVM指令,Java内存模型的重排规则会要求Java编译器在生成JVM指令时插入特定的内存屏障指令,通过这些内存屏障指令,volatile实现了Java内存模型中的可见性和有序性(禁重排),但volatile 无法保证原子性。
内存屏障之前的所有写操作都要回写到主内存,
内存屏障之后的所有读操作都能获得内存屏障之前的所有写操作的最新结果(实现了可见性)。
写屏障( Store Memory Barrier) :告诉处理器在写屏障之前将所有存储在缓存(store bufferes)中的数据同步到主内存。也就是说当看到Store屏障指令,就必须把该指令之前所有写入指令执行完毕才能继续往下执行。
读屏障(LoadMemoryBarrier):处理器在读屏障之后的读操作,都在读屏障之后执行。也就是说在Load屏障指令之后就能够保证后面的读取数据指令一定能够读取到最新的数据。

因此重排序时,不允许把内存屏障之后的指令重排序到内存屏障之前。一句话:对一个volatile变量的写,先行发生于任意后续对这个volatile变量的读,也叫写后读。
内存屏障分类
粗分2种
读屏障(Load Barrier):在读指令之前插入读屏障,让工作内存或CPU高速缓存当中的缓存数据失效,重新回到主内存中获取最新数据
写屏障(Store Barrier):在写指令之后插入写屏障,强制把写缓冲区的数据刷回到主内存中
细分4种


保证可见性
保证不同线程对某个变量完成操作后结果及时可见,即该共享变量一旦改变所有线程立即可见



没有原子性
volatile变量的复合操作不具有原子性,比如number++
对于volatile变量具备可见性,JVM只是保证从主内存加载到线程工作内存的值是最新的,也仅是数据加载时是最新的。但是多线程环境下,"数据计算"和"数据赋值"操作可能多次出现,若数据在加载之后,若主内存volatile修饰的变量发生修改后,线程工作内存中的操作将会作废去读主内存最新值,操作出现写丢失问题。即各线程私有内存和主内存公共内存中变量不同步,进而导致数据不一致。由此可见volatile解决的是变量读时的可见性问题,但无法保证原子性,对于多线程修改主内存共享变量的场景必须使用加锁同步。

字节码角度看i++


禁止指令重排
说明与案例
重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段,有时候会改变程序语句的先后顺序
不存在数据依赖关系,可以重排序;
存在数据依赖关系,禁止重排序;
但重排后的指令绝对不能改变原有的串行语义!这点在并发设计中必须要重点考虑!
重排序的分类和执行流程

编译器优化的重排序:编译器在不改变单线程串行语义的前提下,可以重新调整指令的执行顺序
指令级并行的重排序:处理器使用指令级并行技术来讲多条指令重叠执行,若不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
内存系统的重排序:由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是乱序执行
数据依赖性:若两个操作访问同一变量,且这两个操作中有一个为写操作,此时两操作间就存在数据依赖性。
案例:
不存在数据依赖关系,可以重排序===>重排序OK。

若存在数据依赖关系,禁止重排序===>重排序发生,会导致程序运行结果不同。
编译器和处理器在重排序时,会遵守数据依赖性,不会改变存在依赖关系的两个操作的执行,但不同处理器和不同线程之间的数据性不会被编译器和处理器考虑,其只会作用于单处理器和单线程环境,下面三种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。



应用场景
单一赋值可以,but含复合运算赋值不可以(i++之类)
例如volatile int a = 10, volatile boolean flag = false;是可以的
状态标志,判断业务是够结束

开销较低的读,写锁策略

DCL双端锁的发布
问题

单线程看问题代码
单线程环境下(或者说正常情况下),在"问题代码处",会执行如下操作,保证能获取到已完成初始化的实例

多线程看问题代码
隐患:多线程环境下,在"问题代码处",会执行如下操作,由于重排序导致2,3乱序,后果就是其他线程得到的是null而不是完成初始化的对象

这种场景在著名的双重检查锁定(double-checked-locking)中会出现:

解决:加volatile

总结
volatile可见性
| volatile关键字保证可见性: | 对一个被volatile关键字修改的变量 |
|---|---|
| 1 | 写操作的话,这个变量的最新值会立即刷新回到主内存中 |
| 2 | 读操作的话,总是能够读取到这个变量的最新值,也就是这个变量最后被修改的值 |
| 3 | 当某个线程收到通知,去读取volatile修饰的变量的值的时候,线程私有工作内存的数据失效,需要重新回到主内存中去读取最新的数据。 |
不保证原子性
volatile禁止指令重排
内存屏障是什么
内存屏障︰是一种屏障指令,它使得CPU 或编译器对屏障指令的前和后所发出的内存操作执行一个排序的约束。也叫内存栅栏或栅栏指令
内存屏障能干嘛
阻止屏障两边的指令重排序
写数据时加入屏障,强制将线程私有工作内存的数据刷回主物理内存
读数据时加入屏障,线程私有工作内存的数据失效,重新到主物理内存中获取最新数据
内存屏障四大指令
在每一个volatile写操作前面插入一个StoreStore屏障
在每一个volatile写操作后面插入一个StoreLoad屏障
在每一个volatile读操作后面插入一个LoadLoad屏障
在每一个volatile读操作后面插入一个LoadStore屏障
三句话总结
volatile 写之前的操作,都禁止重排序到volatile之后
volatile 读之后的操作,都禁止重排序到volatile 之前
volatile 写之后volatile读,禁止重排序
CAS

原子类
java.util.concurrent.atomic
没有CAS之前
多线程环境不使用原子类保证线程安全i++(基本数据类型)

有了CAS之后
多线程环境使用原子类保证线程安全i++ (基本数据类型),类似我们的乐观锁

CAS
compare and swap的缩写,中文翻译成比较并交换,实现并发算法时常用到的一种技术。
它包含三个操作数 一一 内存位置、预期原值及更新值。
执行CAS操作的时候,将内存位置的值与预期原值比较:
如果相匹配,那么处理器会自动将该位置值更新为新值,
如果不匹配,处理器不做任何操作,多个线程同时执行CAS操作只有一个会成功。
原理
CAS ( CompareAndSwap )
CAS有3个操作数,位置内存值V,旧的预期值A,要修改的更新值B。
当且仅当旧的预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做或重来,当它重来重试的这种行为成为------自旋!

硬件级别的保证
CAS是JDK提供的非阻塞原子性操作,它通过硬件保证了比较—更新的原子性。
它是非阻塞的且自身具有原子性,也就是说这玩意效率更高且通过硬件保证,说明这玩意更可靠。
CAS是一 条CPU的原子指令(cmpxchg指令),不会造成所谓的数据不一致问题,Unsafe提供的CAS方法(如compareAndSwapXXX) 底层实现即为CPU指令cmpxchg。
执行cmpxchg指令的时候,会判断当前系统是否为多核系统,如果是就给总线加锁,只有一个线程会对总线加锁成功,加锁成功之后会执行cas操作,也就是说CAS的原子性实际上是CPU实现独占的,比起用synchronized重量级锁,这里的排他时间要短很多,所以在多线程情况下性能会比较好。
源码分析compareAndSet(int expect, int update)

Unsafe类

1 Unsafe是CAS的核心类,由于Java方法无法直接访问底层系统,需要通过本地(native) 方法来访问,Unsafe相当于一个后门,基于该类可以直接操作特定内存的数据。Unsafe类存在于sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存。
注意Unsafe类中的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务
2 变量valueOffset,表示该变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的。
3 变量value用volatile修饰,保证了多线程之间的内存可见性。
i++线程不安全,那atomicInteger.getAndIncrement()呢
CAS的全称为Compare-And-Swap,它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
AtomicInteger类主要利用CAS (compare and swap) + volatile和native方法来保证原子操作,从而避免synchronized的高开销,执行效率大为提升。



原子引用AutomicReference

CAS是实现自旋锁的基础,CAS利用CPU指令保证了操作的原子性,以达到锁的效果,至于自旋呢,看字面意思也很明白,自己旋转。是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,当线程发现锁被占用时,会不断循环判断锁的状态,直到获取。这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU
手写自旋锁

A线程如果不释放的话,B无法获取只能自旋等待
CAS缺点
循环时间长开销很大

容易出现ABA问题
ABA问题怎么产生的
CAS会导致“ABA问题”。
CAS算法实现一个重要前提需要取出内存中某时刻的数据并在当下时刻比较并替换,那么在这个时间差类会导致数据的变化。
比如说一个线程1从内存位置V中取出A,这时候另一个线程2也从内存中取出A,并且线程2进行了一些操作将值变成了B,然后线程2又将V位置的数据变成A,这时候线程1进行CAS操作发现内存中仍然是A,预期OK,然后线程1操作成功。
尽管线程1的CAS操作成功,但是不代表这个过程就是没有问题的。
版本号时间戳原子引用
使用AtomicStampedReference,带版本号解决ABA的问题




atomic
-
AtomicBoolean
-
Atomiclnteger
-
AtomiclntegerArray
-
AtomiclntegerFieldUpdater
-
AtomicLong
-
AtomicLongArray
-
AtomicLongFieldUpdater
-
AtomicMarkableReference
-
AtomicReference
-
AtomicReferenceArray
-
AtomicReferenceFieldUpdater
-
AtomicStampedReference
-
DoubleAccumulator
-
DoubleAdder
-
LongAccumulator
-
LongAdder
基本类型原子类
AtomicInteger
AtomicBoolean
AtomicLong
常见API简介
- public final int get()//获取当前的值
- public final int getAndSet(int newValue)//获取当前的值,并设置新的值
- public final int getAndlncrement()//获取当前的值,并自增
- public final int getAndDecrement()//获取当前的值,并自减
- public final int getAndAdd(int delta)//获取当前的值,并加上预期的值
- boolean compareAndSet(int expect,int update)/如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
案例
package com.juc.atomic;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;public class AtomicIntegerDemo {public static final int SIZE = 50;public static void main(String[] args) throws InterruptedException {MyNumber myNumber = new MyNumber();//countdownlatch分解时间CountDownLatch countDownLatch = new CountDownLatch(SIZE);for (int i = 0; i < SIZE; i++) {new Thread(() -> {try {for (int j = 0; j < 1000; j++) {myNumber.addPlusPlus();}} finally {countDownLatch.countDown();}}, String.valueOf(i)).start();}// 保证线程的全部顺利计算完成// 使用countDownLatch替换容易出错的sleepcountDownLatch.await();System.out.println(Thread.currentThread().getName() + "\t" + myNumber.atomicInteger.get());}
}class MyNumber {AtomicInteger atomicInteger = new AtomicInteger(0);public int addPlusPlus() {return atomicInteger.getAndIncrement();}
}
数组类型原子类
- AtomiclntegerArray
- AtomicLongArray
- AtomicReferenceArray
案例
package com.juc.atomic;import java.util.concurrent.atomic.AtomicIntegerArray;public class AtomicIntegerArrayDemo {public static void main(String[] args) {AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[5]);// AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(5);// AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[]{1, 2, 3, 4, 5});for (int i = 0; i < atomicIntegerArray.length(); i++) {System.out.println(atomicIntegerArray.get(i));}int tmpInt = 0;// 设置下标为1的数据,值为1122tmpInt = atomicIntegerArray.getAndSet(0, 1122);System.out.println("tmpInt = " + tmpInt + "\t" + atomicIntegerArray.get(0));tmpInt = atomicIntegerArray.getAndIncrement(0);System.out.println("tmpInt = " + tmpInt + "\t" + atomicIntegerArray.get(0));}
}
引用类型原子类

-
AtomicReference
自旋锁

-
AtomicStampedReference
携带版本号的引用类型原子类,可以解决ABA问题
解决修改过几次的问题
-
AtomicMarkableReference
原子更新带有标记位的引用类型对象
解决是否修改过
它的定义就是将状态戳简化为truelfalse
类似一次性筷子
案例
package com.juc.atomic;import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicMarkableReference;public class AtomicMarkableReferenceDemo {public static AtomicMarkableReference markableReference = new AtomicMarkableReference(100, false);public static void main(String[] args) {new Thread(() -> {boolean marked = markableReference.isMarked();System.out.println(Thread.currentThread().getName() + "\t" + "默认标识:" + marked);try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}markableReference.compareAndSet(100, 1000, marked, !marked);}, "t1").start();new Thread(() -> {boolean marked = markableReference.isMarked();System.out.println(Thread.currentThread().getName() + "\t" + "默认标识:" + marked);try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}boolean b = markableReference.compareAndSet(100, 2000, marked, !marked);System.out.println(Thread.currentThread().getName() + "\t" + "t2线程CASresult: " + b);System.out.println(Thread.currentThread().getName() + "\t" + markableReference.getReference());}, "t2").start();} }


DoubleAccumulator
DoubleAdder
LongAccumulator
LongAdder
入门讲解
LongAdder只能用来计算加法,且从零开始计算
LongAccumulator提供了自定义的函数操作
案例:

package com.juc.atomic;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAccumulator;
import java.util.concurrent.atomic.LongAdder;class ClickNumber {int number = 0;public synchronized void clickBysynchronized() {number++;}AtomicLong atomicLong = new AtomicLong(0);public void clickAtomicLong() {atomicLong.getAndIncrement();}LongAdder longAdder = new LongAdder();public void clickLongAdder() {longAdder.increment();}LongAccumulator longAccumulator = new LongAccumulator((x, y) -> x + y, 0);public void clickLongAccumulator() {longAccumulator.accumulate(1);}}
/*** 需求:50个线程,每个线程100W次,求总点赞数*/
public class AccumulatorCompreDemo {public static final int _1W = 10000;public static final int threadNum = 50;public static void main(String[] args) throws InterruptedException {ClickNumber clickNumber = new ClickNumber();long startTime;long endTime;CountDownLatch countDownLatch1 = new CountDownLatch(threadNum);CountDownLatch countDownLatch2 = new CountDownLatch(threadNum);CountDownLatch countDownLatch3 = new CountDownLatch(threadNum);CountDownLatch countDownLatch4 = new CountDownLatch(threadNum);startTime = System.currentTimeMillis();for (int i = 0; i < threadNum; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * _1W; j++) {clickNumber.clickBysynchronized();}} finally {countDownLatch1.countDown();}}, String.valueOf(i)).start();}countDownLatch1.await();endTime = System.currentTimeMillis();System.out.println("-----------costTime: " + (endTime - startTime) + "毫秒 \t clickBysynchronized: " + clickNumber.number);startTime = System.currentTimeMillis();for (int i = 0; i < threadNum; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * _1W; j++) {clickNumber.clickAtomicLong();}} finally {countDownLatch2.countDown();}}, String.valueOf(i)).start();}countDownLatch2.await();endTime = System.currentTimeMillis();System.out.println("-----------costTime: " + (endTime - startTime) + "毫秒 \t clickAtomicLong: " + clickNumber.atomicLong.get());startTime = System.currentTimeMillis();for (int i = 0; i < threadNum; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * _1W; j++) {clickNumber.clickLongAdder();}} finally {countDownLatch3.countDown();}}, String.valueOf(i)).start();}countDownLatch3.await();endTime = System.currentTimeMillis();System.out.println("-----------costTime: " + (endTime - startTime) + "毫秒 \t clickLongAdder: " + clickNumber.longAdder.sum());startTime = System.currentTimeMillis();for (int i = 0; i < threadNum; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * _1W; j++) {clickNumber.clickLongAccumulator();}} finally {countDownLatch4.countDown();}}, String.valueOf(i)).start();}countDownLatch4.await();endTime = System.currentTimeMillis();System.out.println("-----------costTime: " + (endTime - startTime) + "毫秒 \t clickLongAccumulator: " + clickNumber.longAccumulator.get());}
}-----------costTime: 1756毫秒 clickBysynchronized: 50000000
-----------costTime: 1084毫秒 clickAtomicLong: 50000000
-----------costTime: 435毫秒 clickLongAdder: 50000000
-----------costTime: 369毫秒 clickLongAccumulator: 50000000

阿里巴巴手册推荐Java8之后,使用LongAdder,性能更好

一句话

LongAdder的基本思路就是分散热点,将value值分散到一个Cell数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
sum()会将所有Cell数组中的value和base累加作为返回值,核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点。

数学表达
内部有一个base变量,一个Cell[]数组
base变量:低并发,直接累加到该变量上
Cell[]:高并发,累加进各个线程自己的槽Cell[i]中
源码
LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用化整为零分散热点的做法,用空间换时间,用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和base都加起来作为最终结果。

add(1L)

条件递增,逐步解析
- 最初无竞争时只更新base;
- 如果更新base失败后,首次新建一个cell[数组]
- 当多个线程竞争同一个Cell比较激烈时,可能就要对Cell[]扩容
上述小总结


1如果Cells表为空,尝试用CAS更新base字段,成功则退出;
2如果Cells表为空,CAS更新base字段失败,出现竞争,uncontended为true,调用
longAccumulate;
3如果Cells表非空,但当前线程映射的槽为空,uncontended为true,调用longAccumulate;
4如果Cells表非空,且前线程映射的槽非空,CAS更新Cell的值,成功则返回,否则,
uncontended设为false,调用longAccumulate。
longAccumulate
longAccumulate入参说明
- longx需要增加的值,一般默认都是1
- LongBinaryOperator fn 默认传递的是null
- wasUncontended竞争标识,如果是false则代表有竞争。只有cells初始化之后,并且当前线程CAS竞争修改失败,才会是talse
Striped64中一些变量或者方法的定义
- base:类似于AtomicLong中全局的value值。在没有竞争情况下数据直接累加到base上,或者cells扩容时,也需要将数据写入到base上
- collide:表示扩容意向,false一定不会扩容,true可能会扩容。
- cellsBusy:初始化cells或者扩容cells需要获取锁,0:表示无锁状态1:表示其他线程已经持有了锁
- casCellsBusy():通过CAS操作修改cellsBusy的值,CAS成功代表获取锁,返回true
- NCPU:当前计算机CPU数量,Cell数组扩容时会使用到
- getProbe():获取当前线程的hash值
- advanceProbe():重置当前线程的hash值
步骤
线程hash值:probe


总纲

上述代码首先给当前线程分配一个hash值,然后进入一个for(;;)自旋,这个自旋分为三个分支:
CASE1:Cell[]数组已经初始化
CASE2:Cell[]数组未初始化(首次新建)
CASE3:Cell[]数组正在初始化中
计算
刚刚要初始化Cell[]数组(首次新建),未初始化过Cell[]数组,尝试占有锁并首次初始化cells数组

兜底:多个线程尝试CAS修改失败的线程会走到这个分支

Cell数组不再为空且可能存在Cell数组扩容
解释一:

上面代码判断当前线程hash后指向的数据位置元素是否为空,如果为空则将Cell数据放入数组中,跳出循环。如果不空则继续循环。
解释二:

解释三:

说明当前线程对应的数组中有了数据,也重置过hash值,这时通过CAS操作会试对当前数中的value值进行累加x操作,x默认为1,如果CAS成功则直接姚出循环。
解释四:

解释五:

解释六:


sum
sum()会将所有Cell数组中的value和base累加作为返回值。
核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点。
为什么在并发情况下sum的值不精确
sum执行时,并没有限制对base和cells的更新(一句要命的话)。所以LongAdder不是强一致性的,它是最终一致性的。
首先,最终返回的sum局部变量,初始被复制为base,而最终返回时,很可能base已经被更新了,而此时局部变量sum不会更新,造成不一致。
其次,这里对cell的读取也无法保证是最后一次写入的值。所以,sum方法在没有并发的情况下,可以获得正确的结果。
AtomicLong
线程安全,可允许一些性能损耗,要求高精度时可使用
保证精度,性能代价
AtomicLong是多个线程针对单个热点值value进行原子操作
原理
CAS+自旋,incrementAndGet
场景
低并发下的全局计算
AtomicLong能保证并发情况下计数的准确性,其内部通过CAS来解决并发安全性的问题。
缺陷
高并发后性能急剧下降
why? AtomicLong的自旋会成为瓶颈
N个线程CAS操作修改线程的值,每次只有一个成功过,其它N-1失败,失败的不停的自旋直到成功,这样大量失败自旋的情况,一下子cpu就打高了。
LongAdder
当需要在高并发下有较好的性能表现,且对值的精确度要求不高时,可以使用
保证性能,精度代价
LongAdder是每个线程拥有自己的槽,各个线程一般只对自己槽中的那个值进行CAS操作
原理
CAS+Base+Cell数组分散
空间换时间并分散了热点数据
场景
高并发下的全局计算
缺陷
sum求和后还有计算线程修改结果的话,最后结果不够准确
ThreadLocal
ThreadLocal中ThreadLocalMap的数据结构和关系?
ThreadLocal的key是弱引用,这是为什么?
ThreadLocal内存泄露问题你知道吗?
ThreadLocal中最后为什么要加remove方法?
是什么
ThreadLocal提供线程局部变量。这些变量与正常的变量不同,因为每一个线程在访问ThreadLocal实例的时候(通过其get或set方法)都有自己的、独立初始化的变量副本。ThreadLocal实例通常是类中的私有静态字段,使用它的目的是希望将状态(例如,用户ID或事务ID)与线程关联起来。
能干嘛
实现每一个线程都有自己专属的本地变量副本(自己用自己的变量不麻烦别人,不和其他人共享,人人有份,人各一份),主要解决了让每个线程绑定自己的值,通过使用get()和set()方法,获取默认值或将其值更改为当前线程所存的副本的值从而避免了线程安全问题,比如我们之前讲解的8锁案例,资源类是使用同一部手机,多个线程抢夺同一部手机使用,假如人手一份是不是天下太平??

因为每个Thread内有自己的实例副本且该副本只由当前线程自己使用
既然其它Thread不可访问,那就不存在多线程间共享的问题。
统一设置初始值,但是每个线程对这个值的修改都是各自线程互相独立的
一句话
- 加入synchronized或者Lock控制资源的访问顺序
- 人手一份,大家各自安好,没必要抢夺
Thread,ThreadLocal,ThreadLocalMap关系
Thread和ThreadLocal

再次体会,各自线程,人手一份
ThreadLocal和ThreadLocalMap

三者总概括

threadLocalMap实际上就是一个以threadLocal实例为key,任意对象为value的Entry对象。
void createMap(Thread t, T firstValue) {t.threadLocals = new ThreadLocalMap(firstKey: this, firstValue);
}
当我们为threadLocal变量赋值,实际上就是以当前threadLocal实例为key,值为value的Entry往这个threadLooallMap中存放
小总结
近似的可以理解为:
ThreadLocallMap从字面上就可以看出这是一个保存ThreadLocal对象的map(其实是以ThreadLocal为Key),不过是经过了两层包装的ThreadLocal对象:

JVM内部维护了一个线程版的Map<ThreadLocal,Value>(通过ThreadLocal对象的set方法,结果把ThreadLocal对象自己当做key,放进了ThreadLoalMap中),每个线程要用到这个T的时候,用当前的线程去Map里面获取,通过这样让每个线程都拥有了自己独
的变量,人手一份,竞争条件被彻底消除,在并发模式下是绝对安全的变量。
从阿里规范开始说起

为什么要用到弱引用?不用会如何?
什么是内存泄露
不再会被使用的对象或者变量占用的内存不能被回收,就是内存泄露。
内存泄露是谁惹的祸
在回顾ThreadLocalMap

强引用、软引用、弱引用、虚引用分别是什么
整体架构

强引用
当内存不足,JVM开始垃圾回收,对于强引用的对象,就算是出现了OOM也不会对该对象进行回收,死都不收。
强引用是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。
在Java中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。
当一个对象被强引用变量引用时,它处于可达状态,它是不可能被垃圾回收机制回收的,即使该对象以后永远都不会被用到,JVM也不会回收。因此强引用是造成Java内存泄漏的主要原因之一。
对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为null,一般认为就是可以被垃圾收集的了(当然具体回收时机还是要看垃圾收集策略)。
软引用
软引用是一种相对强引用弱化了一些的引用,需要用java.lang.ref.SoftReference类来实现,可以让对象豁免一些访圾收集。
对于只有软引用的对象来说,当系统内存充足时它不会被回收,当系统内存不足时它会被回收。
软引用通常用在对内存敏感的程序中,比如高速缓存就有用到软引用,内存够用的时候就保留,不够用就回收!
弱引用
弱引用需要用java.lang.ref.WeakReference类来实现,它比软引用的生存期更短,对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管JVM的内存空间是否足够,都会回收该对象占用的内存。
软引用和弱引用的适用场景
假如有一个应用需要读取大量的本地图片:
如果每次读取图片都从硬盘读取则会严重影响性能,
如果一次性全部加载到内存中又可能造成内存溢出。
此时使用软引用可以解决这个问题。
设计思路是:用一个HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免了OOM的问题。
Map<String, SoftReference> imageCache = new HashMap<String, SoftReference>();
虚引用
1 虚引用必须和引用队列(ReferenceQueue)联合使用
虚引用需要java.lang.ref.PhantomReference类来实现,顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收,它不能单独使用也不能通过它访问对象,虚引用必须和引用队列(ReferenceQueue)联合使用。
2 PhantomReference的get方法总是返回null
虚引用的主要作用是跟踪对象被垃圾回收的状态。仅仅是提供了一种确保对象被finalize以后,做某些事情的通知机制。PhantomReference的get方法总是返回null,因此无法访问对应的引用对象。
3处理监控通知使用
换句话说,设置虚引用关联对象的唯一目的,就是在这个对象被收集器回收的时候收到一个系统通知或者后续添加进一步的处理,用来实现比finalize机制更灵活的回收操作
GCRoot和四大引用类型小总结


ThreadLocal是一个壳子,真正的存储结构是ThreadLocal里有ThreadLocalMap这么个内部类,每个Thread对象维护着一个ThreadLocalMap的引用,ThreadLocallMap是ThreadLocal的内部类,用Entry来进行存储。
1)调用ThreadLocal的set()方法时,实际上就是往ThreadLocalMap设置值,key是ThreadLocal对象,值Value是传递进来的对象
2)调用ThreadLocal的get()方法时,实际上就是往ThreadLocalMap获取值,key是ThreadLocal对象
ThreadLocal本身并不存储值(ThreadLocal是一个壳子).它只是自己作为一个key来让线程从ThreadLocalMap获取value。

正因为这个原理,所以ThreadLocal能够实现“数据隔离”,获取当前线程的局部变量值,不受其他线程影响~
为什么要使用弱引用?不用如何?

为什么源代码用弱引用
为什么源代码用弱引用?
当function01方法执行完毕后,栈帧销毁强引用t1也就没有了。但此时线程的ThreadLocallMap里某个entry的key引用还指向这个对象
若这个key引用是强引用,就会导致key指向的ThreadLocal对象及v指向的对象不能被gc回收,造成内存泄漏;
若这个key引用是弱引用就大概率会减少内存泄漏的问题(还有一个key为null的雷)。使用弱引用,就可以使ThreadLocal对象在方法执行完毕后顺利被回收且Entry的key引用指向为null。

此后我们调用get,set或remove方法时,就会尝试删除key对null的entry,可以释放value对象所占用的内存
弱引用就万事大吉了吗?
1当我们为threadLocal变量赋值,实际上就是当前的Entry(threadLocal实例为key,值为value)往这个threadLocalMap中存放。Entry中的key是弱引用,当threadLocal外部强引用被置为null(t1=null),那么系统GC的时候,根据可达性分析,这个threadLocal实例就没有任何一条链路能够引用到它, 这个ThreadLocal势必会被回收。这样一来,ThreadLocalMap中就会出现key为null的Entry, 就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话, 这些key为null的Entry的value就会一直存在一条强引用链: Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
2当然,如果当前thread运行结束,threadLocal,threadLocalMap,Entry没有引用链可达,在垃圾回收的时候都会被系统进行回收。
3但在实际使用中我们有时候会用线程池去维护我们的线程,比如在Executors.newFixedThreadPool()时创建线程的时候,为了复用线程是不会结束的,所以threadLocal内存泄漏就值得我们小心
key为null的entry,原理解析

ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统gc的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的
value,如果当前线程再迟迟不结束的话(比如正好用在线程池),这些key为null的Entry的value就会一直存在一条强引用链。
虽然弱引用,保证了key指向的ThreacLocal对象能被及时回收,但是v指向的value对象是需要ThreadLocalMap调用get、set时发现key为null时才会去回收整个entry、value。因此弱引用不能100%保证内存不泄露。我们要在不使用某个ThreadLocal对象后,手动调用remoev方法来删除它,尤其是在线程池中,不仅仅是内存泄露的问题,因为线程池中的线程是重复使用的,意味着这个线程的ThreadLocalMap对象也是重复使用的,如果我们不手动调用remove方法,那么后面的线程就有可能获取到上个线程遗留下来的value值,造成bug。
set、get方法会去检查所有键为null的Entry对象
expungeStaleEntry(),主要的清理方法
set()方法解析:





结论
从前面的set,getEntry,remove方法看出,在threadLocal的生命周期里,针对threadLocal存在的内存溃漏的问题,都会通过expungeStaleEntry,cleanSomeSlots,replaceStaleEntry这三个方法清理掉key为null的entry。
最佳实践
-
ThreadLocal.withInitial(()-> 初始化值);
-
建议把ThreadLocal修饰成static

-
Threadlocal能实现了线程的数据隔离,不在于它自己本身,而在于Thread的ThreadLocalMap,所以 ThreadLocal可以只初始化一次,只分配一块存储空间就足以了,没必要作为成员变量多次被初始化。
-
用完记得手动remove
-

对象布局
权威定义
周志明老师JVM第三版

对象在堆内存中的存储布局

对象内部结构分为:对象头、实例数据、对齐填充(保证8个字节的倍数)。
对象头分为对象标记(markOop)和类元信息(klassOop),类元信息存储的是指向该对象类元数据(klass)的首地址。
-
对象头
对象标记 Mark Word
它保存的是什么:


在64位系统中,Mark Word占了8个字节,类型指针占了8个字节,共是16个字节


默认存储对象的HashCode、分代年龄和锁标志位等信息。
这些信息都是与对象自身定义无关的数据,所以MarkWord被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。
它会根据对象的状态复用自己的存储空间,也就是说在运行期间MarkWord里存储的数据会随着锁标志位的变化而变化。
类元信息(又叫类型指针)

-
对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例
对象头多大
在64位系统中,Mark Word占了8个字节,类型指针占了8个字节,一共是16个字节。
-
实例数据
存放类的属性(Field)数据信息,包括父类的属性信息
-
对齐填充
虚拟机要求对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐这部分内存按8字节补充对齐。

再说对象头MarkWord
32位,了解即可

64位



聊聊Object obj = new Object()
JOL证明
JOL = Java Object Layout
引入的POM文件
<!--
官网: http://openjdk.java.net/projects/code-tools/jol/
定位:分析对象在JVM的大小和分布
-->
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.9</version>
</dependency>


GC年龄采用4位bit存储,最大为15,如MaxTenuringThreshold参数默认值就是15
尾巴参数说明
压缩指针相关说明命令
-
java -XX:+PrintCommandLineFlags -version
-
默认开启压缩说明
-XX:+UseCompressedClassPointers
-
手动关闭压缩再看看情况
-XX:-UseCompressedClassPointers

谈谈对synchronized的理解
synchronized的锁升级

大纲总结
阿里巴巴规约:
【强制】高并发时,同步调用应该去考量锁的性能损耗。能用无锁数据结构,就不要用锁;能锁区块,就不要锁整个方法体;能用对象锁,就不要用类锁。
说明:尽可能使加锁的代码块工作量尽可能的小,避免在锁代码块中调用RPC方法。
synchronized 锁优化的背景
用锁能够实现数据的安全性,但是会带来性能下降。
无锁能够基于线程并行提升程序性能,但是会带来安全性下降,
锁的升级过程

synchronized锁:
由对象头中的Mark Word根据锁标志位的不同而被复用及锁升级策略
java5以前,只有Synchronized,这个是操作系统级别的重量级操作
重量级锁,假如锁的竞争比较激烈的话,性能下降
Java5之前,用户态和内核态之间的切换

java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在户态与核心态之间切换,这种切换会消耗
大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
在Java早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的Mutex Lock(系统互斥量)来实现的,挂起线程和恢复线程都需要转入内核态去完成,阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态切换需要耗费处理器时间,如果同步代码块中内容过于简单,这种切换的时间可能比用户代码执行的时间还长”,时间成本相对较高,这也是为什么早期的synchronized效率低的原因。Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁
为什么每一个对象都可以成为一个锁?
markoop.hpp

Monitor可以理解为一种同步工具,也可理解为一种同步机制,常常被描述为一个Java对象。Java对象是天生的Monitor,每一个Java对象都有成为Monitor的潜质,因为在Java的设计中,每一个Java对象自打娘胎里出来就带了一把看不见的锁,它叫做内部锁或者Monitor锁。

Monitor的本质是依赖于底层操作系统的Mutex Lock实现,操作系统实现线程之间的切换需要从用户态到内核态的转换,成本非常高。
Monitor(监视器锁)
JVM中的同步就是基于进入和退出管程(Monitor)对象实现的。每个对象实例都会有一个Monitor,Monitor可以和对象一起创建、销毁。
Monitor是由ObjectMonitor实现,而ObjectMonitor是由C++的ObjectMonitor.hpp文件实现,如下所示:


Mutex Lock
Monitor是在jvm底层实现的,底层代码是c++。本质是依赖于底层操作系统的Mutex Lock实现,操作系统实现线程之间的切换需要从用户态到内核态的转换,状态转换需要耗费很多的处理器时间成本非常高。所以synchronized是Java语言中的一个重量级操作。
Monitor与java对象以及线程是如何关联?
1.如果一个java对象被某个线程锁住,则该java对象的Mark Word字段中LockWord指向monitor的起始地址。
2.Monitor的Owner字段会存放拥有相关联对象锁的线程id。
Mutex Lock的切换需要从用户态转换到核心态中,因此状态转换需要耗费很多的处理器时间。
结合之前的synchronized和对象头说明

Java6开始,优化synchronized
Java6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁
需要有个逐步升级的过程,别一开始就捅到重量级锁
多线程访问情况,3种
只有一个线程来访问,有且唯一Only One
有多个线程(2个线程A、B来交替访问)
竞争激烈,更多个线程来访问
升级流程
synchronized用的锁是存在Java对象头里的Mark Word中,锁升级功能主要依赖MarkWord中锁标志位和释放偏向锁标志位
64位标记图再看


锁指向,请牢记
偏向锁:MarkWord存储的是偏向的线程ID;
轻量锁:MarkWord存储的是指向线程栈中Lock Record的指针;
重量锁:MarkWord存储的是指向堆中的monitor对象的指针;
无锁
无锁:初始状态,一个对象被实例化后,如果还没有被任何线程竞争锁,那么它就为无锁状态(001)


偏向锁
是什么
偏向锁:单线程竞争
当线程A第一次竞争到锁时,通过操作修改Mark Word中的偏向线程ID、偏向模式。如果不存在其他线程竞争,那么持有偏向锁的线程将永远不需要进行同步。
主要作用
当一段同步代码一直被同一个线程多次访问,由于只有一个线程那么该线程在后续访问时便会自动获得锁
小结论
Hotspot的作者经过研究发现,大多数情况下:
多线程的情况下,锁不仅不存在多线程竞争,还存在锁由同一个线程多次获得的情况,偏向锁就是在这种情况下出现的,它的出现是为了解决只有在一个线程执行同步时提高性能。
备注:
偏向锁会偏向于第一个访问锁的线程,如果在接下来的运行过程中,该锁没有被其他的线程访问,则持有偏向锁的线程将永远不需要触发同步。也即偏向锁在资源没有竞争情况下消除了同步语句,懒的连CAS操作都不做了,直接提高程序性能

说明
理论落地:
在实际应用运行过程中发现,“锁总是同一个线程持有,很少发生竞争”,也就是说锁总是被第一个占用他的线程拥有,这个线程就是锁的偏向线程。
那么只需要在锁第一次被拥有的时候,记录下偏向线程ID。这样偏向线程就一直持有着锁(后续这个线程进入和退出这段加了同步锁的代码块时,不需要再次加锁和释放锁。而是直接会去检查锁的MarkWord里面是不是放的自己的线程ID)。
如果相等,表示偏向锁是偏向于当前线程的,就不需要再尝试获得锁了,直到竞争发生才释放锁。以后每次同步,检查锁的偏向线程ID与当前线程ID是否一致,如果一致直接进入同步。无需每次加锁解锁都去CAS更新对象头。如果自始至终使用锁的线程只有一个,很明显偏向锁几乎没有额外开销,性能极高。
如果不等,表示发生了竞争,锁已经不是总是偏向于同一个线程了,这个时候会尝试使用CAS来替换MarkWord里面的线程ID为新线程的ID,
竞争成功,表示之前的线程不存在了,MarkWord里面的线程ID为新线程的ID,锁不会升级,仍然为偏向锁;
竞争失败,这时候可能需要升级变为轻量级锁,才能保证线程间公平竞争锁。
注意,偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程是不会主动释放偏向锁的。
技术实现:
一个synchronized方法被一个线程抢到了锁时,那这个方法所在的对象就会在其所在的Mark Word中将偏向锁修改状态位,同时还会有占用前54位来存储线程指针作为标识。若该线程再次访问同一个synchronized方法时,该线程只需去对象头的Mark Word 中去判断一下是否有偏向锁指向本身的ID,无需再进入Monitor去竞争对象了。


开启偏向锁显示

偏向锁的撤销
当有另外线程逐步来竞争锁的时候,就不能再使用偏向锁了,要升级为轻量级锁
竞争线程尝试CAS更新对象头失败,会等待到全局安全点(此时不会执行任何代码)撤销偏向锁

偏向锁的撤销
偏向锁使用一种等到竞争出现才释放锁的机制,只有当其他线程竞争锁时,持有偏向锁的原来线程才会被撤销。
撤销需要等待全局安全点(该时间点上没有字节码正在执行),同时检查持有偏向锁的线程是否还在执行:
①第一个线程正在执行synchronized方法(处于同步块),它还没有执行完,其它线程来抢夺,该偏向锁会被取消掉并出现锁升级。此时轻量级锁由原持有偏向锁的线程有,继续执行其同步代码,而正在竞争的线程会进入自旋等待获得该轻量级锁。
② 第一个线程执行完成synchronized方法(退出同步块),则将对象头设置成无锁状态并撤销偏向锁,重新偏向。

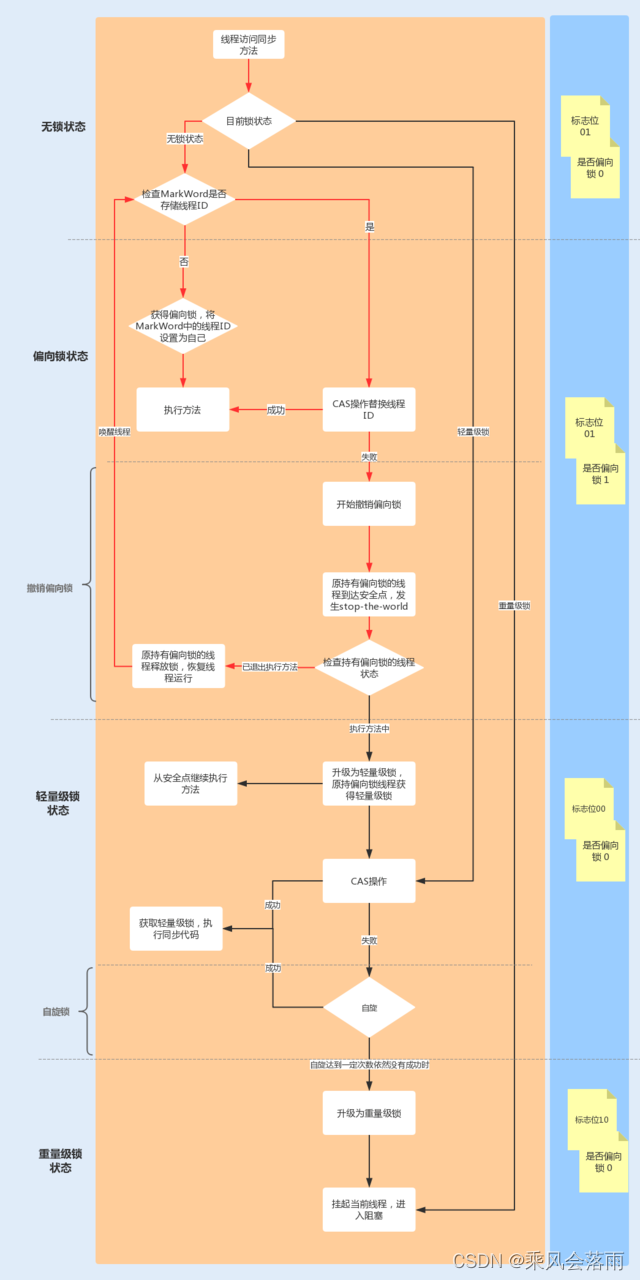
Java15逐步废弃偏向锁… …
轻锁
是什么
轻量级锁:多线程竞争,但是任意时刻最多只有一个线程竞争,即不存在锁竞争太过激烈的情况,也就没有线程阻塞。
主要作用
有线程来参与锁的竞争,但是获取锁的冲突时间极短,本质就是自旋锁CAS
轻量级锁的获取
轻量级锁是为了在线程近乎交替执行同步块时提高性能。
主要目的:在没有多线程竞争的前提下,通过CAS减少重量级锁使用操作系统互斥量产生的性能消耗,说白了先自旋,不行才升级阻塞。
升级时机:当关闭偏向锁功能或多线程竞争偏向锁会导致偏向锁升级为轻量级锁
假如线程A已经拿到锁,这时线程B又来抢该对象的锁,由于该对象的锁已经被线程A拿到,当前该锁已是偏向锁了。
而线程B在争抢时发现对象头Mark Word中的线程ID不是线程B自己的线程ID(而是线程A),那线程B就会进行CAS操作希望能获得锁。
此时线程B操作中有两种情况:
如果锁获取成功,直接替换Mark Word中的线程ID为B自己的ID(A→B),重新偏向于其他线程(即将偏向锁交给其他线程,相当于当前线程“被"释放了锁),该锁会保持偏向锁状态,A线程Over,B线程上位;

如果锁获取失败,则偏向锁升级为轻量级锁(设置偏向锁标识为0并设置锁标志位为00),此时轻量级锁由原持有偏向锁的线程持有,继续执行其同步代码,而正在竞争的线程B会进入自旋等待获得该轻量级锁。

自旋达到一定次数和程度
Java6之前:默认启用,默认情况下自旋的次数是10次或者自旋线程数超过cpu核数一半
Java6之后:自适应自旋锁
自适应意味着自旋的次数不是固定不变的。而是根据:同一个锁上一次自旋的时间;拥有锁线程的状态来决定
轻量锁与偏向锁的区别和不同
争夺轻量级锁失败时,自旋尝试抢占锁
轻量级锁每次退出同步块都需要释放锁,而偏向锁是在竞争发生时才释放锁
重锁

有大量的线程参与锁的竞争,冲突性很高
锁标志位
重量级锁原理
Java中synchronized的重量级锁,是基于进入和退出Monitor对象实现的。在编译时会将同步块的开始位置插入monitor enter指令,在结束位置插入monitor exit指令。
当线程执行到monitor enter指令时,会尝试获取对象所对应的Monitor所有权,如果获取到了,即获取到了锁,会在Monitor的owner中存放当前线程的id,这样它将处于锁定状态,除非退出同步块,否则其他线程无法获取到这个Monitor。
小总结
锁升级发生后,hashcode去哪了
锁升级为轻量级或重量级锁后,Mark Word中保存的分别是线程栈帧里的锁记录指针和重量级锁指针,已经没有位置再保存哈希码,GC年龄了,那么这些信息被移动到哪里去了呢?

在无锁状态下,Mark Word中可以存储对象的identity hash code值。当对象的hashCode()方法第一次被调用时,JVM会生成对应的identity hash code值并将该值存储到Mark Word中。
对于偏向锁,在线程获取偏向锁时,会用Thread D和epoch值覆盖identity hash code所在的位置。如果一个对象的hashCode0万法已经被调用过一次之后,这个对象不能被设置偏向锁。因为如果可以的化,那Mark Word中的identity hash code必然会被偏向线程ld给覆盖,这就会造成同一个对象前后两次调用hashCode()方法得到的结果不一致。
升级为轻量级锁时,JVM会在当前线程的栈帧中创建一个锁记录(Lock Record)空间,用于存储锁对象的Mak Word拷贝,该据贝中可以包含identity hash code,所以轻量级锁可以和identity hash code共存,哈希码和GC年龄自然保存在此,释放锁后会将这些信息写回到对象头。
升级为重量级锁后,Mark Word保在的重量级锁指针,代表重量级锁的ObiectMonitor类里有字段记录非加锁状态下的Mark Word,锁释放后也会将信息写回到对象头。
各种锁优缺点、synchronized锁升级和实现原理

synchronized锁升级过程总结:一句话,就是先自旋,不行再阻塞。
实际上是把之前的悲观锁(重量级锁)变成在一定条件下使用偏向锁以及使用轻量级(自旋锁CAS)的形式
synchronized在修饰方法和代码块在字节码上实现方式有很大差异,但是内部实现还是基于对象头的MarkWord来实现的。
JDK1.6之前synchronized使用的是重量级锁,JDK1.6之后进行了优化,拥有了无锁->偏向锁->轻量级锁->重量级锁的升级过程,而是无论什么情况都使用重量级锁。
偏向锁:适用于单线程适用的情况,在不存在锁竞争的时候进入同步方法/代码块则使用偏向锁。
轻量级锁:适用于竞争较不激烈的情况(这和乐观锁的使用范围类似),存在竞争时升级为轻量级锁,轻量级锁采用的是自旋锁,如果同步方法/代码块执行时间很短的话,采用轻量级锁虽然会占用cpu资源但是相对比使用重量级锁还是更高效。
重量级锁:适用于竞争激烈的情况,如果同步方法/代码块执行时间很长,那么使用轻量级锁自旋带来的性能消耗就比使用重量级锁事严重,这时候就需要升级为重量级锁。
ReentrantReadLock
是什么
读写锁说明
ReentrantReadWriteLock
读写锁定义为:一个资源能够被多个读线程访问,或者被一个写线程访问,但是不能同时存在读写线程。即读写互斥,读读共享。
读写锁ReentrantReadWriteLock的意义和特点
它只允许读读共存,而读写和写写依然是互斥的,大多实际场景是“读/读”线程间并不存在互斥关系,
只有"读/写”线程或”写/写”线程间的操作需要五斥的。因此引入ReentrantReadWriteLock。
一个ReentrantReadWriteLock同时只能存在一个写锁但是可以存在多个读锁,但不能同时存在写锁和读锁,也即一个资源可以被多个读操作访问或一个写操作访问,但两者不能同时进行。
只有在读多写少情景之下,读写锁才具有较高的性能体现。
特点
一体两面,读写互斥,读读共享,读没有完成时候其他线程写锁无法获得
写锁 -> 读锁,ReentrantReadWriteLock可以降级
《Java并发编程的艺术》中关于锁降级的说明
ReentrantReadWriteLock锁降级: 将写入锁降级为读锁(类似Linux文件读写权限理解,就像写权限要高于读权限一样),锁的严苛程度变强叫做升级,反之叫做降级。

写锁的降级,降级成为了读锁
1 如果同一个线程持有了写锁,在没有释放写锁的情况下,它还可以继续获得读锁。这就是写锁的降级,降级成为了读锁。
2 规则惯例,先获取写锁,然后获取读锁,再释放写锁的次序。
3 如果释放了写锁,那么就完全转换为读锁。
读写锁降级演示
写锁可以降级,锁降级是为了让当前线程感知到数据的变化,目的是保证数据可见性。
锁降级:遵循获取写锁 -> 再获取读锁 -> 再释放写锁的次序,写锁能够降级成为读锁。
如果一个线程占有了写锁,在不释放写锁的情况下,它还能占有读锁,即写锁降级为读锁。

如果有线程在读,那么写线程是无法获取写锁的,是悲观锁的策略
线程获取读锁是不能直接升级为写入锁的

写锁和读锁是互斥的
写锁和读锁是互斥的(这里的互斥是指线程间的互斥,当前线程可以获取到写锁又获取到读锁,但是获取到了读锁不能继续获取写锁》,这是因为读写锁要保持写操作的可见性。因为,如果允许读锁在被获取的情况下对写锁的获取,那么正在运行的其他读线程无法感知到当前写线程的操作。
因此,分析读写锁ReentrantReadWriteLock,会发现它有个潜在的问题:
读锁结束,写锁有望;写锁独占,读写全堵!
如果有线程正在读,写线程需要等待读线程释放锁后才能获取写锁。
即ReentrantReadWriteLock读的过程中不允许写,只有等待线程都释放了读锁,当前线程才能获取写锁,也就是写入必须等待,这是一种悲观的读锁。
后续讲解StampedLock时再详细展开
分析StampedLock,会发现它改进之处在于:
读的过程中也允许获取写锁介入(相当牛B,读和写两个操作也让你“共享”(注意引号)),这样会导致我们读的数据就可能不一致,所以,需要额外的方法来判断读的过程中是否有写入,这是一种乐观的读锁。
显然乐观锁的并发效率更高,但一旦有小概率的写入导致读取的数据不一致,需要能检测出来,再读一遍就行。
读写锁之读写规矩,解释为什么要锁降级
Oracle公司ReentrantWriteReadLock源码总结
锁降级 下面的示例代码摘自ReentrantWVriteReadLock源码中:
ReentrantWriteReadLock支持锁降级,遵循按照获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁,不支持锁升级。

1 代码中声明了一个volatile类型的cacheValid变量,保证其可见性。
2 首先获取读锁,如果cache不可用,则释放读锁。获取写锁,在更改数据之前,再检查一次cacheValid的值,然后修改数据,将cacheValid置为true,然后在释放写锁前立刻抢夺获取读锁;此时,cache中数据可用,处理cache中数据,最后释放读锁。这个过程就是一个完整的锁降级的过程,目的是保证数据可见性。
总结:一句话,同一个线程自己持有写锁时再去拿读锁,其本质相当于重入。
如果违背锁降级的步骤,如果违背锁降级的步骤,如果话背锁障级的步骤
如果当前的线程C在修改完cache中的数据后,没有获取读锁而是直接释放了写锁,那么假设此时另一个线程D获取了写锁并修改了数据,那么C线程无法感知到数据已被修改,则数据出现错误。
如果遵循锁降级的步骤
线程C在释放写锁之前获取读锁,那么线程D在获取写锁时将被阻塞,直到线程C完成数据处理过程,释放读锁。这样可以保证返回的数据是这次更新的数据,该机制是专门为了缓存设计的。
无锁 -> 独占锁 -> 读写锁 -> 邮戳锁
StampedLock
是什么
StampedLock是JDK1.8中新增的一个读写锁,也是对JDK1.5中的读写锁ReentrantReadWriteLock的优化
邮戳锁也叫票据锁
stamp(戳记,long类型),代表了锁的状态。当stamp返回零时,表示线程获取锁失败。并且,当释放锁或者转换锁的时候,都要传入最初获取的stamp值。
邮戳锁是由饥饿问题引出
锁饥饿问题
ReentrantReadWriteLock实现了读写分离,但是一旦读操作比较多的时候,想要获取写锁就变得比较困难了,假如当前1000个线程,999个读,1个写,有可能999个读取线程长时间抢到了锁,那1个写线程就悲剧了,因为当前有可能会一直存在读锁,而无法获得写惯,根本没机会写。
如何缓解锁饥饿问题?
使用“公平”策略可以一定程度上缓解这个问题 -> new ReentrantReadWriteLock(true);
但是“公平”策略是以牺牲系统吞吐量为代价的。
StampedLock类的乐观锁闪亮登场
ReentrantReadWriteLock
允许多个线程同时读,但是只允许一个线程写,在线程获取到写锁的时候,其他写操作和读操作都会处于阻塞状态,读锁和写锁也是互斥的,所以在读的时候是不允许写的,读写锁比传统的synchronized速度要快很多,原因就是在于ReentrantReadWriteLock支持读并发,读读可以共享
StampedLock横空出世
ReentrantReadWriteLock的读锁被占用的时候,其他线程尝试获取写锁的时候会被阻塞。但是,StampedLock采取乐观获取锁后,其他线程尝试获取写锁时不会被阻室,这其实是对读锁的优化,所以,在获取乐观读锁后,还需要对结果进行校验。
一句话:对短的只读代码段,使用乐观锁模式通常可以减少争用并提高吞吐量
StampedLock的特点
-
所有获取锁的方法,都返回一个邮戳(Stamp),Stamp为零表示获取失败,其余都表示成功;
-
所有释放锁的方法,都需要一个邮戳 (Stamp),这个Stamp必须是和成功获取锁时得到的Stamp一致
-
StampedLock是不可重入的,危险(如果一个线程已经持有了写锁,再去获取写锁的话就会造成死锁)
-
StampedLock有三种访问模式
Reading(读模式悲观) :功能和ReentrantReadWriteLock的读锁类似
Writing(写模式) :功能和ReentrantReadWriteLock的写锁类似
Optimistic reading (乐观读模式) :无锁机制,类似于数据库中的乐观锁,支持读写并发,很乐观认为读取时没人修改,假如被修改再实现升级为悲观读模式
乐观锁模式
读的过程中也允许获取写锁介入
StampedLock的缺点
stampedLock 不支持重入,没有Re开头
StampedLock 的悲观读锁和写锁都不支持条件变量 (Condition),这个也需要注意
使用stampedLock一定不要调用中断操作,即不要调用interrupt() 方法
牛B,读和写两个操作也让你“共享”(注意引号)),这样会导致我们读的数据就可能不一致,所以,需要额外的方法来判断读的过程中是否有写入,这是一种乐观的读锁。
显然乐观锁的并发效率更高,但一旦有小概率的写入导致读取的数据不一致,需要能检测出来,再读一遍就行。
读写锁之读写规矩,解释为什么要锁降级
Oracle公司ReentrantWriteReadLock源码总结
锁降级 下面的示例代码摘自ReentrantWVriteReadLock源码中:
ReentrantWriteReadLock支持锁降级,遵循按照获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁,不支持锁升级。
[外链图片转存中…(img-63aZaMQl-1739706218053)]
1 代码中声明了一个volatile类型的cacheValid变量,保证其可见性。
2 首先获取读锁,如果cache不可用,则释放读锁。获取写锁,在更改数据之前,再检查一次cacheValid的值,然后修改数据,将cacheValid置为true,然后在释放写锁前立刻抢夺获取读锁;此时,cache中数据可用,处理cache中数据,最后释放读锁。这个过程就是一个完整的锁降级的过程,目的是保证数据可见性。
总结:一句话,同一个线程自己持有写锁时再去拿读锁,其本质相当于重入。
如果违背锁降级的步骤,如果违背锁降级的步骤,如果话背锁障级的步骤
如果当前的线程C在修改完cache中的数据后,没有获取读锁而是直接释放了写锁,那么假设此时另一个线程D获取了写锁并修改了数据,那么C线程无法感知到数据已被修改,则数据出现错误。
如果遵循锁降级的步骤
线程C在释放写锁之前获取读锁,那么线程D在获取写锁时将被阻塞,直到线程C完成数据处理过程,释放读锁。这样可以保证返回的数据是这次更新的数据,该机制是专门为了缓存设计的。
无锁 -> 独占锁 -> 读写锁 -> 邮戳锁
StampedLock
是什么
StampedLock是JDK1.8中新增的一个读写锁,也是对JDK1.5中的读写锁ReentrantReadWriteLock的优化
邮戳锁也叫票据锁
stamp(戳记,long类型),代表了锁的状态。当stamp返回零时,表示线程获取锁失败。并且,当释放锁或者转换锁的时候,都要传入最初获取的stamp值。
邮戳锁是由饥饿问题引出
锁饥饿问题
ReentrantReadWriteLock实现了读写分离,但是一旦读操作比较多的时候,想要获取写锁就变得比较困难了,假如当前1000个线程,999个读,1个写,有可能999个读取线程长时间抢到了锁,那1个写线程就悲剧了,因为当前有可能会一直存在读锁,而无法获得写惯,根本没机会写。
如何缓解锁饥饿问题?
使用“公平”策略可以一定程度上缓解这个问题 -> new ReentrantReadWriteLock(true);
但是“公平”策略是以牺牲系统吞吐量为代价的。
StampedLock类的乐观锁闪亮登场
ReentrantReadWriteLock
允许多个线程同时读,但是只允许一个线程写,在线程获取到写锁的时候,其他写操作和读操作都会处于阻塞状态,读锁和写锁也是互斥的,所以在读的时候是不允许写的,读写锁比传统的synchronized速度要快很多,原因就是在于ReentrantReadWriteLock支持读并发,读读可以共享
StampedLock横空出世
ReentrantReadWriteLock的读锁被占用的时候,其他线程尝试获取写锁的时候会被阻塞。但是,StampedLock采取乐观获取锁后,其他线程尝试获取写锁时不会被阻室,这其实是对读锁的优化,所以,在获取乐观读锁后,还需要对结果进行校验。
一句话:对短的只读代码段,使用乐观锁模式通常可以减少争用并提高吞吐量
StampedLock的特点
-
所有获取锁的方法,都返回一个邮戳(Stamp),Stamp为零表示获取失败,其余都表示成功;
-
所有释放锁的方法,都需要一个邮戳 (Stamp),这个Stamp必须是和成功获取锁时得到的Stamp一致
-
StampedLock是不可重入的,危险(如果一个线程已经持有了写锁,再去获取写锁的话就会造成死锁)
-
StampedLock有三种访问模式
Reading(读模式悲观) :功能和ReentrantReadWriteLock的读锁类似
Writing(写模式) :功能和ReentrantReadWriteLock的写锁类似
Optimistic reading (乐观读模式) :无锁机制,类似于数据库中的乐观锁,支持读写并发,很乐观认为读取时没人修改,假如被修改再实现升级为悲观读模式
乐观锁模式
读的过程中也允许获取写锁介入
StampedLock的缺点
stampedLock 不支持重入,没有Re开头
StampedLock 的悲观读锁和写锁都不支持条件变量 (Condition),这个也需要注意
使用stampedLock一定不要调用中断操作,即不要调用interrupt() 方法

)



—— LuaJIT介绍)