引言
好像很多朋友对AI绘图有兴趣,AI绘画背后,依旧是大模型的训练。但绘图类AI对计算机显卡有较高要求。建议先了解基本原理及如何使用,在看看如何实现自己垂直行业的绘图AI逻辑。或者作为使用者,调用已有的server接口。
首先需要说明的是,AI绘图和AI识图是不一样的两类训练模型。当然从原理上讲,你可以很范的认为他们都是从训练集中训练神经网络,经过正向传播,反向计算,调整参数,降低loss,并不断迭代。在验证集验证模型,并在测试集上测试模型。但实际上在实作的时候,AI绘图对显卡等硬件资源要求相对更高,且模型在前期,中期,后期的处理手法也不一样。今天以 stable diffusion 为例,看看他的基本原理和怎么用。
Stable Diffusion 主要技术
VAE(变分自编码器)
stable diffusion 采用了VAE模型的预加载方式,在训练过程中,通常会采用预训练的通用VAE(变分自编码器)或自己训练的VAE模型。
他使用Encoder部分对原图片进行处理,将输入图片信息降维到latent space(潜在空间)。
在latent space上应用Diffusion Model进行正向采样和逆向预测。
总的来说,有如下步骤:
数据预处理:使用预训练的VAE模型对输入图片进行编码,将其映射到潜在空间。
正向扩散:在潜在空间上,对编码后的数据添加噪声,模拟扩散过程。
逆向预测:训练模型从含噪声的数据中恢复出原始图像,即逆向扩散过程。
参数调整:通过调整学习率、正则化参数等,控制神经网络参数的变化范围,提高模型的稳定性和收敛性。
结合其他技巧:应用批标准化、残差网络等训练技巧,进一步提高模型的稳定性和训练效果。
使用
github 下载project,进行build
如果你自己的GPU很好,你可以本地搭建stable diffusion,比如你的pc或台式机配了GeForce RTX 高端型号显卡。你可以在github 下载 stable diffusion 项目进行 build。
build 前会自动 pip 相关依赖
使用已搭建完成的 stable diffusion
初学者总是站在巨人的肩上,来看下 stable diffusion 怎么用。我这里采用的是baidu 飞浆 AI进行使用讲解。我们先进入 stable diffsuion 的应用页:
大模型社区-飞桨星河AI Studio大模型社区
先尝试下文字转图的效果:
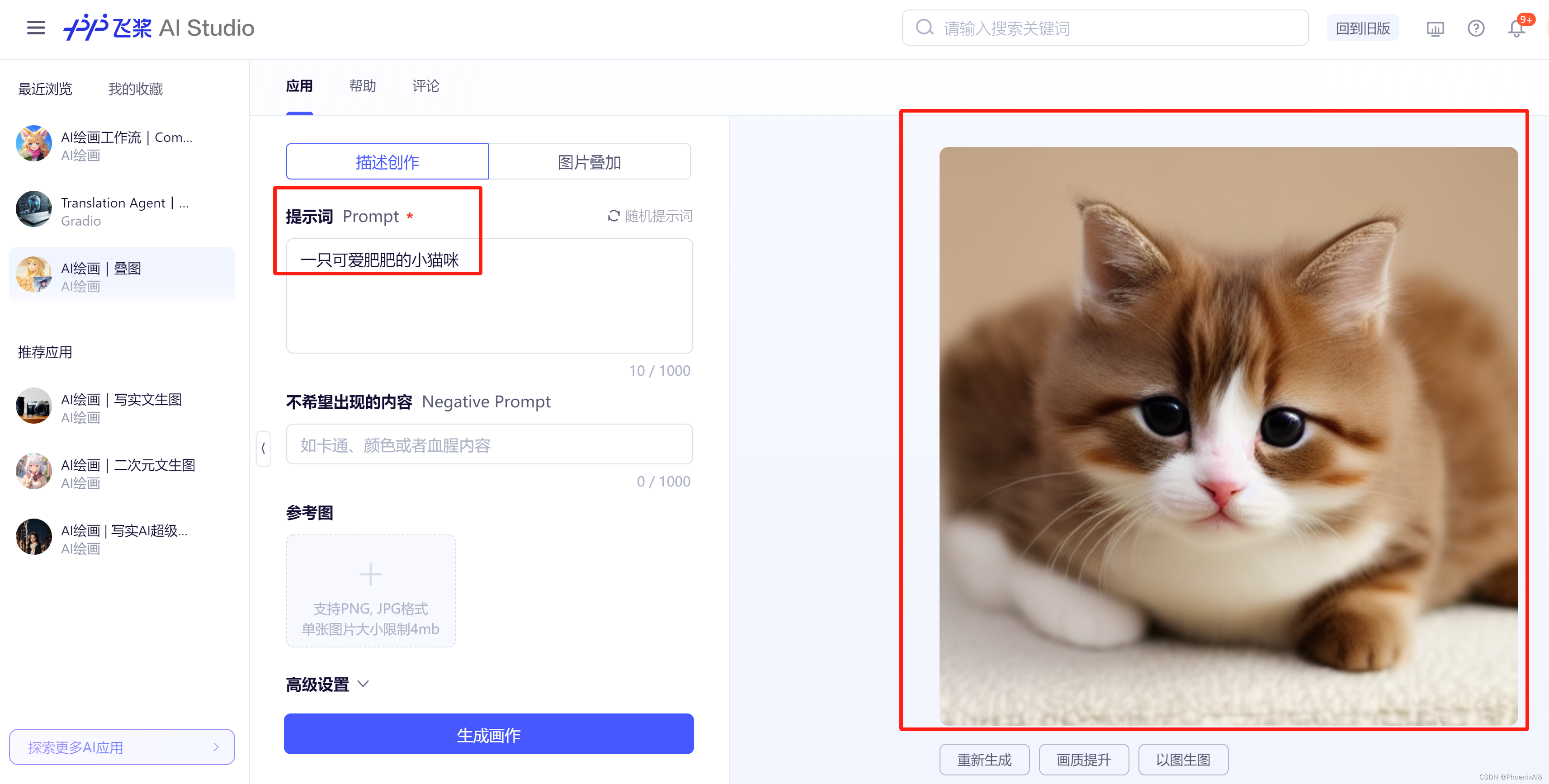
效果还行。
我们再尝试生成一只小老虎
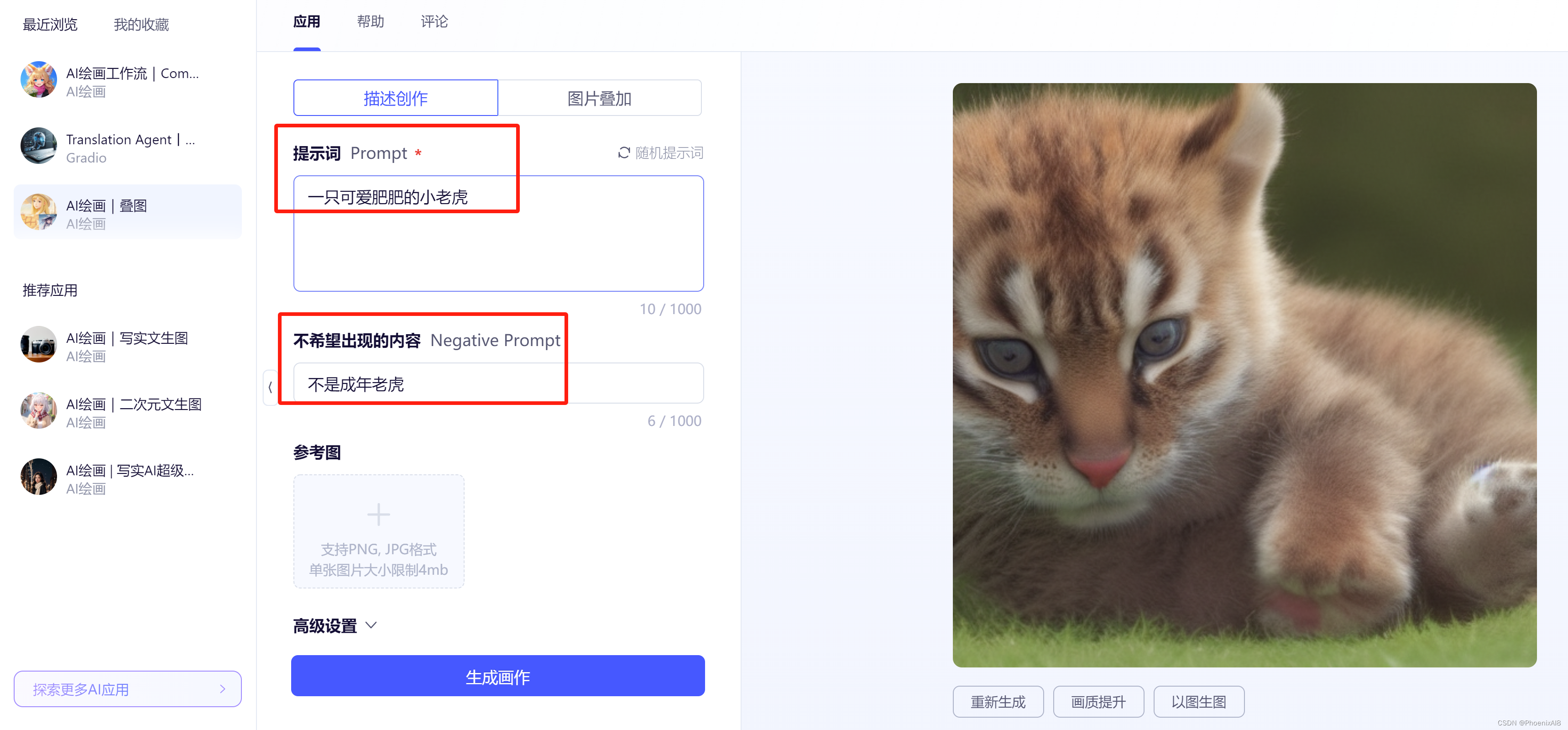
我们发现其实并不是非常完美,如果没有下面的 不出现内容,该stable diffusion 生成的是一只成年老虎。
其实里面提供了API,你可以通过API调用的方式实现。
你需要构造的request:
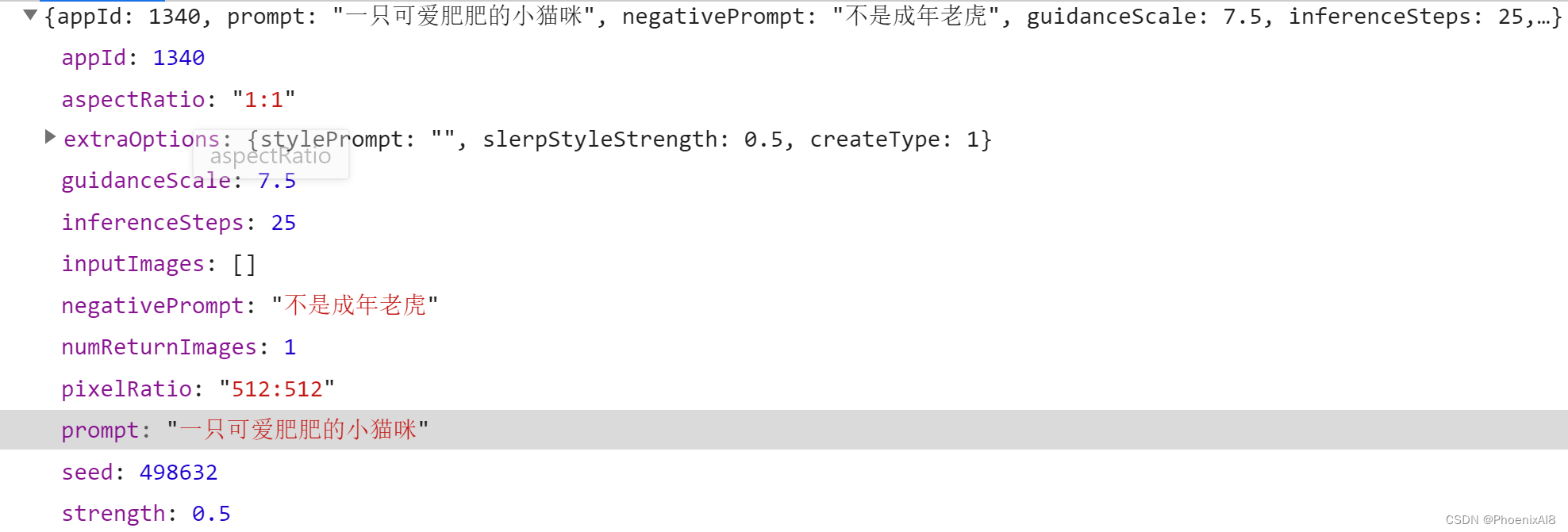
你得到的response:

实际上生成的图是一个imgurls的数组,里面就是生成的结果,你可以单独打开这个url:
好了,就先写到这里吧






